
设计
topic和channel
单个
nsqd
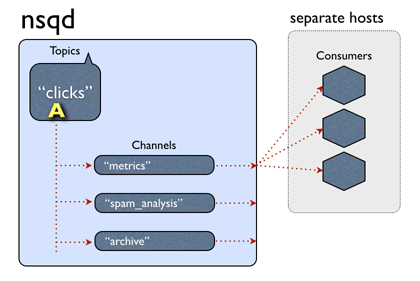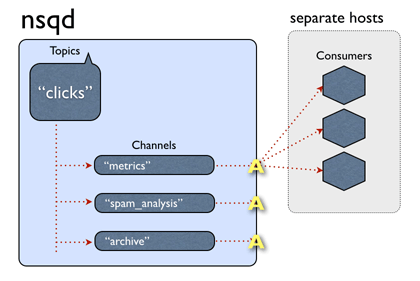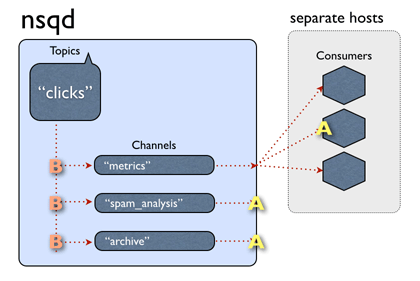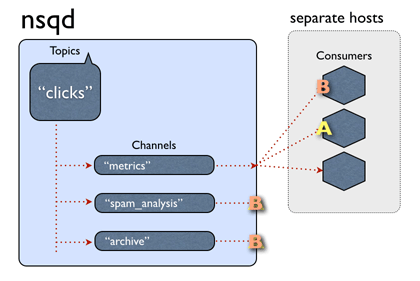
实例旨在一次处理多个数据流。流称为“主题”,一个主题有 1 个或多个“通道”。每个通道都会收到一个主题的所有消息的_副本_。
主题和通道道_不是_提前配置的。主题是在首次使用时通过发布到指定主题或订阅指定主题的通道来创建的。频道是通过订阅指定频道在首次使用时创建的。
主题和通道都相互独立地缓冲数据,防止缓慢的消费者导致其他通道的积压(同样适用于主题级别)。
一个通道可以并且通常确实连接了多个客户端。假设所有连接的客户端都处于准备接收消息的状态,则每条消息将被传递给随机客户端。
消息是从主题 -> 通道多播的(每个频道都接收该主题的所有消息的副本),但从通道 -> 消费者均匀分布(每个消费者接收该频道的部分消息)。
消息传递保证
NSQ保证一条消息至少被传递一次,尽管重复消息是可能的。消费者应该预料到这一点并进行重复数据删除或执行幂等操作。
工作方式(假设客户端已成功连接并订阅了主题):
- 客户端表示他们已准备好接收消息
- NSQ发送消息并将数据临时存储在本地(在重新排队或超时的情况下)
- 客户端回复 FIN(完成)或 REQ(重新排队)分别指示成功或失败。如果客户端没有回复NSQ将在可配置的持续时间后超时并自动重新排队消息)
这确保了唯一会导致消息丢失的边缘情况是
nsqd
进程的不正常关闭。在这种情况下,内存中的任何消息(或任何未刷新到磁盘的缓冲写入)都将丢失。
完全解决方案是:建立冗余
nsqd
对(在不同的主机上)接收相同部分消息的副本。因为您已将消费者编写为幂等,所以对这些消息执行双重时间不会对下游产生影响,并且允许系统承受任何单节点故障而不会丢失消息。
消息持久化
nsqd
提供了一个配置选项
--mem-queue-size
,用于确定队列在内存中保留的消息数量。如果队列的深度超过此阈值,消息将透明地写入磁盘。这将给定进程的内存占用限制为 :
nsqd mem-queue-size * #_of_channels_and_topics
通过将此值设置为较低的值(如 1 甚至 0),这是一种获得更高交付保证的便捷方法。磁盘支持的队列被设计为在不干净的重启后仍然存在(尽管消息可能会被传递两次)。
此外,与消息传递保证相关,干净关闭(通过向
nsqd
进程发送 TERM 信号)能够安全地将当前在内存中、运行中、延迟和各种内部缓冲区中的消息持久保存。
请注意,名称以字符串结尾的主题/频道
#ephemeral
的消息不会缓冲到磁盘,而是会在传递
mem-queue-size
. 这使得不需要消息保证的消费者能够订阅频道。这些临时通道也将在其最后一个客户端断开连接后消失。对于一个临时主题,这意味着至少有一个频道被创建、消费和删除(通常是一个临时频道)。
消息传输
NSQ旨在通过“类似 memcached”的命令协议与简单的大小前缀响应进行通信。所有消息数据都保存在核心中,包括尝试次数、时间戳等元数据。这消除了从服务器到客户端来回复制数据,这是重新排队消息时先前工具链的固有属性。这也简化了客户端,因为它们不再需要负责维护消息状态。
对于数据协议,我们做出了一个关键的设计决策,即通过将数据推送到客户端而不是等待它拉取来最大化性能和吞吐量。这个概念,我们称之为
RDY
状态,本质上是客户端流控制的一种形式。
当客户端连接
nsqd
并订阅通道时,它的
RDY
状态为 0。这意味着不会向客户端发送任何消息。当客户端准备好接收消息时,它会发送一条命令,将其
RDY
状态更新为它准备处理的某个 #,比如 100。如果没有任何其他命令,100 条消息将在可用时推送到客户端(每次递减该客户端的服务器端 RDY 计数)。
客户端库旨在在达到可配置设置的约 25% 时发送更新
RDY
计数的命令
max-in-flight
(并适当考虑到多个
nsqd
实例的连接,适当划分)。
值得注意的是,因为消息既是缓冲的又是基于推送的,能够满足对流(通道)的独立副本的需求,我们制作了一个行为类似于
simplequeue
和
pubsub
_组合_的守护进程。
nsqd
nsqd
是接收、排队和传递消息给客户端的守护进程。
它可以独立运行,但通常配置在带有
nsqlookupd
实例的集群中(在这种情况下,它将宣布主题和发现通道)。
它监听两个 TCP 端口,一个用于客户端,另一个用于 HTTP API。它可以选择在第三个端口上侦听 HTTPS。
nsqd监听两个端口:
4151 HTTP Producer使用HTTP协议的curl等工具生产数据;Consumer使用HTTP协议的curl等工具消费数据;
4150 TCP Producer使用TCP协议的nsq-j等工具生产数据;Consumer使用TCP协议的nsq-j等工具消费数据;
nsqlookupd
nsqlookupd
是管理拓扑信息的守护进程。客户端查询
nsqlookupd
以发现
nsqd
特定主题的生产者,
nsqd
节点广播主题和频道信息。
有两个端口:用于
nsqd
广播的 TCP 端口和用于客户端执行发现和管理操作的 HTTP 接口。
nsqlookupd 监听两个端口:
4160 TCP 用于接收nsqd的广播,记录nsqd的地址以及监听TCP/HTTP端口等。
4161 HTTP 用于接收客户端发送的管理和发现操作请求(增删话题,节点等管理查看性操作等)。当Consumer进行连接时,返回对应存在Topic的nsqd列表。
nsqadmin
nsqadmin监听一个端口
4171 HTTP 用于管理页面
代码分析
/ping
使用了装饰器模式
// http请求的各个handler,从这里创建请求处理的handler------------nsqd.go Main()
httpServer := newHTTPServer(n, false, n.getOpts().TLSRequired == TLSRequired)
router.Handle("GET", "/ping", http_api.Decorate(s.pingHandler, log, http_api.PlainText))
...
// 很多handler
//http_api.Decorate看一下这个方法:
func Decorate(f APIHandler, ds ...Decorator) httprouter.Handle {
decorated := f
for _, decorate := range ds {
decorated = decorate(decorated)
}
return func(w http.ResponseWriter, req *http.Request, ps httprouter.Params) {
decorated(w, req, ps)
}
}
//s.pingHandler
func (s *httpServer) pingHandler(w http.ResponseWriter, req *http.Request, ps httprouter.Params) (interface{}, error) {
health := s.nsqd.GetHealth()
if !s.nsqd.IsHealthy() {
return nil, http_api.Err{500, health}
}
return health, nil
}
//log
func Log(logf lg.AppLogFunc) Decorator {
return func(f APIHandler) APIHandler {
return func(w http.ResponseWriter, req *http.Request, ps httprouter.Params) (interface{}, error) {
start := time.Now()
response, err := f(w, req, ps)
elapsed := time.Since(start)
status := 200
if e, ok := err.(Err); ok {
status = e.Code
}
logf(lg.INFO, "%d %s %s (%s) %s",
status, req.Method, req.URL.RequestURI(), req.RemoteAddr, elapsed)
return response, err
}
}
}
//http_api.PlainText
func PlainText(f APIHandler) APIHandler {
return func(w http.ResponseWriter, req *http.Request, ps httprouter.Params) (interface{}, error) {
code := 200
data, err := f(w, req, ps)
if err != nil {
code = err.(Err).Code
data = err.Error()
}
switch d := data.(type) {
case string:
w.WriteHeader(code)
io.WriteString(w, d)
case []byte:
w.WriteHeader(code)
w.Write(d)
default:
panic(fmt.Sprintf("unknown response type %T", data))
}
return nil, nil
}
}
PUB
// tcp_server.go 文件中 使用协程创建这个连接的客户端
go func() {
handler.Handle(clientConn)
wg.Done()
}()
// 创建客户端
client := prot.NewClient(conn)
p.conns.Store(conn.RemoteAddr(), client)
err = prot.IOLoop(client)
// 开启一个消息泵
go p.messagePump(client, messagePumpStartedChan)
response, err = p.Exec(client, params)
// 根据参数执行对应的
case bytes.Equal(params[0], []byte("PUB")):
return p.PUB(client, params)
// PUB方法中:
topic := p.nsqd.GetTopic(topicName)//获取Topic,如果没有就会创建topic。在这里还会将所有的channel放到一个map里,如果channel还没有,那么就去创建出来
NewTopic(topicName, n, deleteCallback)//创建topic,创建之后会开启一个协程,循环从topic消息管道中放到channel中
t.waitGroup.Wrap(t.messagePump)// 开启一个协程 循环从topic消息管道中放到channel中
msg := NewMessage(topic.GenerateID(), messageBody) // 创建一个消息
err = topic.PutMessage(msg)// 将消息放到管道中
// 响应
p.Send(client, frameTypeResponse, response)
消息put到memoryMsgChan(主题的管道),管道满了之后,就会持久化到磁盘中。这个管道的大小由启动时参数MemQueueSize
func (t *Topic) put(m *Message) error {
select {
case t.memoryMsgChan <- m:
default:
将消息写入磁盘
err := writeMessageToBackend(m, t.backend)
t.nsqd.SetHealth(err)
if err != nil {
t.nsqd.logf(LOG_ERROR,
"TOPIC(%s) ERROR: failed to write message to backend - %s",
t.name, err)
return err
}
}
return nil
}
SUB
// 开始和上面相同,创建客户端,然后执行
//这个协程内,开启一个消息泵,循环从channel中获取消息,发送到客户端
go p.messagePump(client, messagePumpStartedChan)
// 匹配到SUB,执行
case bytes.Equal(params[0], []byte("SUB")):
return p.SUB(client, params)
//从参数中获取
topicName := string(params[1])
channelName := string(params[2])
topic := p.nsqd.GetTopic(topicName)
channel = topic.GetChannel(channelName)
channel.AddClient(client.ID, client)
推送消息
func (p *protocolV2) messagePump(client *clientV2, startedChan chan bool) {
var err error
var memoryMsgChan chan *Message
var backendMsgChan <-chan []byte
var subChannel *Channel
// NOTE: `flusherChan` is used to bound message latency for
// the pathological case of a channel on a low volume topic
// with >1 clients having >1 RDY counts
var flusherChan <-chan time.Time
var sampleRate int32
for {
// 判断客户端是 消费者 还是 生产者
if subChannel == nil || !client.IsReadyForMessages() {
// the client is not ready to receive messages...
memoryMsgChan = nil
backendMsgChan = nil
flusherChan = nil
// ....
select {
// 省略部分代码...
// 当memoryMsgChan管道满了之后,新来的消息会放到这个管道中
case b := <-backendMsgChan:
subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout)
client.SendingMessage()
err = p.SendMessage(client, msg)
case msg := <-memoryMsgChan:
if sampleRate > 0 && rand.Int31n(100) > sampleRate {
continue
}
msg.Attempts++
//在向客户端发送消息之前,将消息设置为在飞翔中,如果处理成功就把这个消息从飞翔中的状态中去掉,
//如果在规定的时间内没有收到客户端的反馈,则认为这个消息超时,然后重新归队。 其实就是将消息放到一个map中
subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout)
client.SendingMessage()
err = p.SendMessage(client, msg)
if err != nil {
goto exit
}
flushed = false
case <-client.ExitChan:
goto exit
}
}
}
如果不考虑负载情况,把随机的把消息发送到某一个客服端去处理消息,如果机器的性能不同,可能发生的情况就是某一个或几个客户端处理速度慢,但还有大量新的消息需要处理,其他的客户端处于空闲状态。理想的状态是,找到当前相对空闲的客户端去处理消息。
nsq
的处理方式是客户端主动向
nsqd
报告自已的可处理消息数量(也就是
RDY
命令)。
nsqd
根据每个连接的客户端的可处理消息的状态来随机把消息发送到可用的客户端,来进行消息处理
同时订阅同一
topic
的客户端(comsumer)有很多个,每个客户端根据自己的配置或状态发送
RDY
命令到
nsqd
表明自己能处理多少消息量nsqd服务端会检查每个客户端的的状态是否可以发送消息。也就是
IsReadyForMessages
方法,判断inFlightCount是否大于readyCount,如果大于或者等于就不再给客户端发送数据,等待
Ready
后才会再给客户端发送数据
func (c *clientV2) IsReadyForMessages() bool {
if c.Channel.IsPaused() {
return false
}
readyCount := atomic.LoadInt64(&c.ReadyCount)
inFlightCount := atomic.LoadInt64(&c.InFlightCount)
c.ctx.nsqd.logf(LOG_DEBUG, "[%s] state rdy: %4d inflt: %4d", c, readyCount, inFlightCount)
if inFlightCount >= readyCount || readyCount <= 0 {
return false
}
return true
func (p *protocolV2) messagePump(client *clientV2, startedChan chan bool) {
// ...
for {
// 检查订阅状态和消息是否可处理状态
if subChannel == nil || !client.IsReadyForMessages() {
// the client is not ready to receive messages...
memoryMsgChan = nil
backendMsgChan = nil
flusherChan = nil
// ...
flushed = true
} else if flushed {
memoryMsgChan = subChannel.memoryMsgChan
backendMsgChan = subChannel.backend.ReadChan()
flusherChan = nil
} else {
memoryMsgChan = subChannel.memoryMsgChan
backendMsgChan = subChannel.backend.ReadChan()
flusherChan = outputBufferTicker.C
}
select {
case <-flusherChan:
// ...
// 消息处理
case b := <-backendMsgChan:
client.SendingMessage()
// ...
case msg := <-memoryMsgChan:
client.SendingMessage()
//...
}
}
// ...
}
处理超时消息
nsq
启动的时候启动协程去处理channel的过期数据
func (n *NSQD) Main() error {
// ...
// 启动协程去处理channel的过期数据
n.waitGroup.Wrap(n.queueScanLoop)
n.waitGroup.Wrap(n.lookupLoop)
if n.getOpts().StatsdAddress != "" {
n.waitGroup.Wrap(n.statsdLoop)
}
err := <-exitCh
return err
}
func (n *NSQD) queueScanLoop() {
//resizePool调整queueScanWorker goroutines池的大小
// 随机选取一个channel放到workCh中,queueScanWorker()进行扫描
n.resizePool(len(channels), workCh, responseCh, closeCh)
}
// 随机
func (n *NSQD) queueScanWorker(workCh chan *Channel, responseCh chan bool, closeCh chan int) {
for {
select {
case c := <-workCh:
now := time.Now().UnixNano()
dirty := false
// 处理飞翔中的消息,如果过期了重新入队
if c.processInFlightQueue(now) {
dirty = true
}
// 处理延迟期的消息
if c.processDeferredQueue(now) {
dirty = true
}
responseCh <- dirty
case <-closeCh:
return
}
}
}
持久化消息
默认的情况下,只有内存队列不足时
MemQueueSize:10000
时,才会把数据保存到文件内进行持久到硬盘。
如果将 --mem-queue-size 设置为 0,所有的消息将会存储到磁盘。我们不用担心消息会丢失,nsq 内部机制保证在程序关闭时将队列中的数据持久化到硬盘,重启后就会恢复。
nsq
自己开发了一个库go-diskqueue来持久会消息到内存
func (t *Topic) put(m *Message) error {
select {
case t.memoryMsgChan <- m:
default:
// 持久化消息
err := writeMessageToBackend(m, t.backend)
t.nsqd.SetHealth(err)
if err != nil {
t.nsqd.logf(LOG_ERROR,
"TOPIC(%s) ERROR: failed to write message to backend - %s",
t.name, err)
return err
}
}
return nil
}
集群实现
nsqd 启动命令:
./nsqd -tcp-address ":8000" -http-address ":8001" --lookupd-tcp-address=127.0.0.1:8200 --lookupd-tcp-address=127.0.0.1:7200 -data-path=./a
--lookupd-tcp-address
用于指定
nsqlookupd
的
tcp
监听地址。
nsqd
启动后连接
nsqlookupd
,连接成功后,要发送一个魔法标识
nsq.MagicV1
,这个标识有啥魔法么,当然不是,他只是用于标明,客户端和服务端双方使用的信息通信版本,不能的版本有不同的处理方式,为了后期做新的消息处理版本方便.
func (p *tcpServer) Handle(clientConn net.Conn) {
// ...
buf := make([]byte, 4)
_, err := io.ReadFull(clientConn, buf)
// ...
protocolMagic := string(buf)
// ...
var prot protocol.Protocol
switch protocolMagic {
case " V1":
prot = &LookupProtocolV1{ctx: p.ctx}
default:
// ...
return
}
err = prot.IOLoop(clientConn)
//...
}
这个时候的
nsqd
已经和
nsqlookupd
建立好了连接,但是这时,仅仅说明他俩连接成功。
nsqlookupd
也并没有把这个连接加到可用的
nsqd
列表里。建立连接完成后,
nsqd
会发送
IDENTIFY
命令,这个命令里包含了nsq的基本信息
nsqd
的代码
ci := make(map[string]interface{})
ci["version"] = version.Binary
ci["tcp_port"] = n.RealTCPAddr().Port
ci["http_port"] = n.RealHTTPAddr().Port
ci["hostname"] = hostname
ci["broadcast_address"] = n.getOpts().BroadcastAddress
cmd, err := nsq.Identify(ci)
if err != nil {
lp.Close()
return
}
resp, err := lp.Command(cmd)
包含了
nsqd
提供的
tcp
和
http
端口,主机名,版本等等,发送给
nsqlookupd
,
nsqlookupd
收到
IDENTIFY
命令后,解析信息然后加到
nsqd
的可用列表里
nsqlookupd
的代码块
func (p *LookupProtocolV1) IDENTIFY(client *ClientV1, reader *bufio.Reader, params []string) ([]byte, error) {
var err error
if client.peerInfo != nil {
return nil, protocol.NewFatalClientErr(err, "E_INVALID", "cannot IDENTIFY again")
}
var bodyLen int32
err = binary.Read(reader, binary.BigEndian, &bodyLen)
// ...
body := make([]byte, bodyLen)
_, err = io.ReadFull(reader, body)
// ...
peerInfo := PeerInfo{id: client.RemoteAddr().String()}
err = json.Unmarshal(body, &peerInfo)
// ...
client.peerInfo = &peerInfo
// 把nsqd的连接加入到可用列表里
if p.ctx.nsqlookupd.DB.AddProducer(Registration{"client", "", ""}, &Producer{peerInfo: client.peerInfo}) {
p.ctx.nsqlookupd.logf(LOG_INFO, "DB: client(%s) REGISTER category:%s key:%s subkey:%s", client, "client", "", "")
}
// ...
return response, nil
}
然后每过15秒,nsqd会发送一个
PING
心跳命令给
nsqlookupd
,这样保持存活状态,
nsqlookupd
每次收到发过来的
PING
命令后,也会记下这个
nsqd
的最后更新时间,这样做为一个筛选条件,如果长时间没有更新,就认为这个节点有问题,不会把这个节点的信息加入到可用列表。
nsqlookupd 挂掉的处理方式
目前的处理方式是这样的,无论是心跳,还是其他命令,
nsqd
会给所有的
nsqlookup
发送信息,当
nsqd
发现
nsqlookupd
出现问题时,在每次发送命令时,会不断的进行重新连接:
func (lp *lookupPeer) Command(cmd *nsq.Command) ([]byte, error) {
initialState := lp.state
if lp.state != stateConnected {
err := lp.Connect()
if err != nil {
return nil, err
}
lp.state = stateConnected
_, err = lp.Write(nsq.MagicV1)
if err != nil {
lp.Close()
return nil, err
}
if initialState == stateDisconnected {
lp.connectCallback(lp)
}
if lp.state != stateConnected {
return nil, fmt.Errorf("lookupPeer connectCallback() failed")
}
}
// ...
}
如果连接成功,会再次调用
connectCallback
方法,进行
IDENTIFY
命令的调用等。
当有
nsqd
出现故障时怎么办?
nsqdlookupd会把这个故障节点从可用列表中去除,客户端从接口得到的可用列表永远都是可用的。- 客户端会把这个故障节点从可用节点上移除,然后要去判断是否使用了
nsqlookup进行了连接,如果是则case r.lookupdRecheckChan <- 1去刷新可用列表queryLookupd,如果不是,然后启动一个协程去定时做重试连接,如果故障恢复,连接成功,会重新加入到可用列表.客户端实现的代码
func (r *Consumer) onConnClose(c *Conn) {
// ...
// remove this connections RDY count from the consumer's total
delete(r.connections, c.String())
left := len(r.connections)
// ...
r.mtx.RLock()
numLookupd := len(r.lookupdHTTPAddrs)
reconnect := indexOf(c.String(), r.nsqdTCPAddrs) >= 0
// 如果使用的是nslookup则去刷新可用列表
if numLookupd > 0 {
// trigger a poll of the lookupd
select {
case r.lookupdRecheckChan <- 1:
default:
}
} else if reconnect {
// ...
}(c.String())
}
}
消息传输
生产者生产数据的过程 消息是字节流: 消息类型+" "+ 主题名 + " " + channel名 + “/n”
//将单条消息同步发送到指定主题,消息也可以异步/批量发送
err = producer.Publish(topicName, messageBody)
func (w *Producer) Publish(topic string, body []byte) error {
return w.sendCommand(Publish(topic, body))
}
//Publish创建一个新的命令来向给定的主题写入消息
func Publish(topic string, body []byte) *Command {
var params = [][]byte{[]byte(topic)}
return &Command{[]byte("PUB"), params, body}
}
// 省略一些代码片段。。。
// 下面时消息序列化代码 发送到服务端
func (c *Command) WriteTo(w io.Writer) (int64, error) {
var total int64
var buf [4]byte
// 1,写入消息的类型
n, err := w.Write(c.Name)
total += int64(n)
if err != nil {
return total, err
}
for _, param := range c.Params {
// 2,写入一个空字符串
n, err := w.Write(byteSpace)
total += int64(n)
if err != nil {
return total, err
}
// 3,写入 主题名称,这里循环写入是因为 params中 可能有主题名,通道名
n, err = w.Write(param)
total += int64(n)
if err != nil {
return total, err
}
}
// 4,写入 换行符
n, err = w.Write(byteNewLine)
total += int64(n)
if err != nil {
return total, err
}
if c.Body != nil {
bufs := buf[:]
binary.BigEndian.PutUint32(bufs, uint32(len(c.Body)))
// 5,写入 消息的内容的长度
n, err := w.Write(bufs)
total += int64(n)
if err != nil {
return total, err
}
// 6,写入 消息的内容
n, err = w.Write(c.Body)
total += int64(n)
if err != nil {
return total, err
}
}
return total, nil
}
服务端如何接收消息反序列化的, 按规定的格式读取字节
// 读取客户端发送来的消息,首先读取换行符前面的内容就是params
line, err = client.Reader.ReadSlice('\n')
if err != nil {
if err == io.EOF {
err = nil
} else {
err = fmt.Errorf("failed to read command - %s", err)
}
break
}
// trim the '\n'
line = line[:len(line)-1]
// optionally trim the '\r'
if len(line) > 0 && line[len(line)-1] == '\r' {
line = line[:len(line)-1]
}
params := bytes.Split(line, separatorBytes)// [消息类型, 主题名, channel名]
bodyLen, err := readLen(client.Reader, client.lenSlice)
messageBody := make([]byte, bodyLen) // 消息内容
_, err = io.ReadFull(client.Reader, messageBody)
服务端推送消息及消息如何序列化, 响应:data的长度+ data(消息的类型+ 消息)
type Message struct {
ID MessageID
Body []byte
Timestamp int64
Attempts uint16
// for in-flight handling
deliveryTS time.Time
clientID int64
pri int64
index int
deferred time.Duration
}
func (p *protocolV2) SendMessage(client *clientV2, msg *Message) error {
p.nsqd.logf(LOG_DEBUG, "PROTOCOL(V2): writing msg(%s) to client(%s) - %s", msg.ID, client, msg.Body)
buf := bufferPoolGet()
defer bufferPoolPut(buf)
_, err := msg.WriteTo(buf)// msg->字节流
if err != nil {
return err
}
err = p.Send(client, frameTypeMessage, buf.Bytes())
if err != nil {
return err
}
return nil
}
func (p *protocolV2) Send(client *clientV2, frameType int32, data []byte) error {
client.writeLock.Lock()
var zeroTime time.Time
if client.HeartbeatInterval > 0 {
client.SetWriteDeadline(time.Now().Add(client.HeartbeatInterval))
} else {
client.SetWriteDeadline(zeroTime)
}
_, err := protocol.SendFramedResponse(client.Writer, frameType, data)
if err != nil {
client.writeLock.Unlock()
return err
}
if frameType != frameTypeMessage {
err = client.Flush()
}
client.writeLock.Unlock()
return err
}
func SendFramedResponse(w io.Writer, frameType int32, data []byte) (int, error) {
beBuf := make([]byte, 4)
size := uint32(len(data)) + 4
binary.BigEndian.PutUint32(beBuf, size)
n, err := w.Write(beBuf)// 写入消息的长度
if err != nil {
return n, err
}
binary.BigEndian.PutUint32(beBuf, uint32(frameType))
n, err = w.Write(beBuf) // 写入frameType,这是响应的类型,有:三种类型
//frameTypeResponse int32 = 0
//frameTypeError int32 = 1
//frameTypeMessage int32 = 2
if err != nil {
return n + 4, err
}
n, err = w.Write(data) // 写入消息
return n + 8, err
}
// [x][x][x][x][x][x][x][x]...
// | (int32) || (binary)
// | 4-byte || N-byte
// ------------------------...
// size data
消费者接收消息如何反序列化
func ReadUnpackedResponse(r io.Reader) (int32, []byte, error) {
resp, err := ReadResponse(r)
if err != nil {
return -1, nil, err
}
return UnpackResponse(resp)
}
// [x][x][x][x][x][x][x][x]...
// | (int32) || (binary)
// | 4-byte || N-byte
// ------------------------...
// size data
func ReadResponse(r io.Reader) ([]byte, error) {
var msgSize int32
// message size
err := binary.Read(r, binary.BigEndian, &msgSize)
if err != nil {
return nil, err
}
if msgSize < 0 {
return nil, fmt.Errorf("response msg size is negative: %v", msgSize)
}
// message binary data
buf := make([]byte, msgSize) // data
_, err = io.ReadFull(r, buf)
if err != nil {
return nil, err
}
return buf, nil
}
//
// [x][x][x][x][x][x][x][x]...
// | (int32) || (binary)
// | 4-byte || N-byte
// ------------------------...
// frame ID data
//
// Returns a triplicate of: frame type, data ([]byte), error
func UnpackResponse(response []byte) (int32, []byte, error) {
if len(response) < 4 {
return -1, nil, errors.New("length of response is too small")
}
return int32(binary.BigEndian.Uint32(response)), response[4:], nil
}
常用工具
上游如何保证消息的可靠性?
- nsq_to _file:消费指定的话题(topic)/通道(channel),并写到文件中,有选择地滚动和/或压缩文件。
- nsq_to _http:消费指定的话题(topic)/通道(channel)和执行 HTTP requests (GET/POST) 到指定的端点。
- nsq_to _nsq:消费者指定的话题/通道和重发布消息到目的地 nsqd 通过 TCP。
消息备份/回放
消息是写到一个单一的 nsqd 的,如果那个 nsqd 部署机器挂掉无法恢复,可能会导致这个 nsqd 中积压的消息丢失。所以我们还需要设计消息备份和异常回放的机制。
- 备份
NSQ 提供了 nsq_to_file 工具,可以用来做消息备份。所有消息实时备份到本地文件,按小时切割文件,消息文件三备份,备份数据存储 n 天。
需要备份的消息使用 nsq_to_nsq 工具,同步写入备份队列,备份机器上运行 nsq_to_file 订阅备份队列的数据,写到磁盘备份。
- 回放
1.机器挂掉能重启恢复,重启恢复后重启服务即可,nsqd 的内存队列大小设置为 0,数据全部落盘,重启不会丢失数据。
2.机器不能重启恢复的情况下,从备份数据中回放该 nsqd 的备份消息。 需要注意回放时对消息去重,因为写备份时采用全部备份写成功才算成功的方案,可能会导致消息重复。
集群监控
同时我们还需要部署监控,实时监控 NSQ 集群的运行情况,以便出现问题时能技术感知修复。
机器状态:cpu、内存、磁盘、网络等。
服务状态:进程、端口存活等。
消息队列:队列数量、队列积压情况等。
这样就可以做到整个系统无单点,数据三备份,及时感知集群异常。做到一个基础的可用性要求,能够满足绝大部分的场景使用了。
高可用
队列长度设置为0,所有的消息都存到磁盘中
nsq_to_file,在一个主机上,消费指定主题的消息,按小时全部存到文件中
版权归原作者 echo洋阳 所有, 如有侵权,请联系我们删除。