
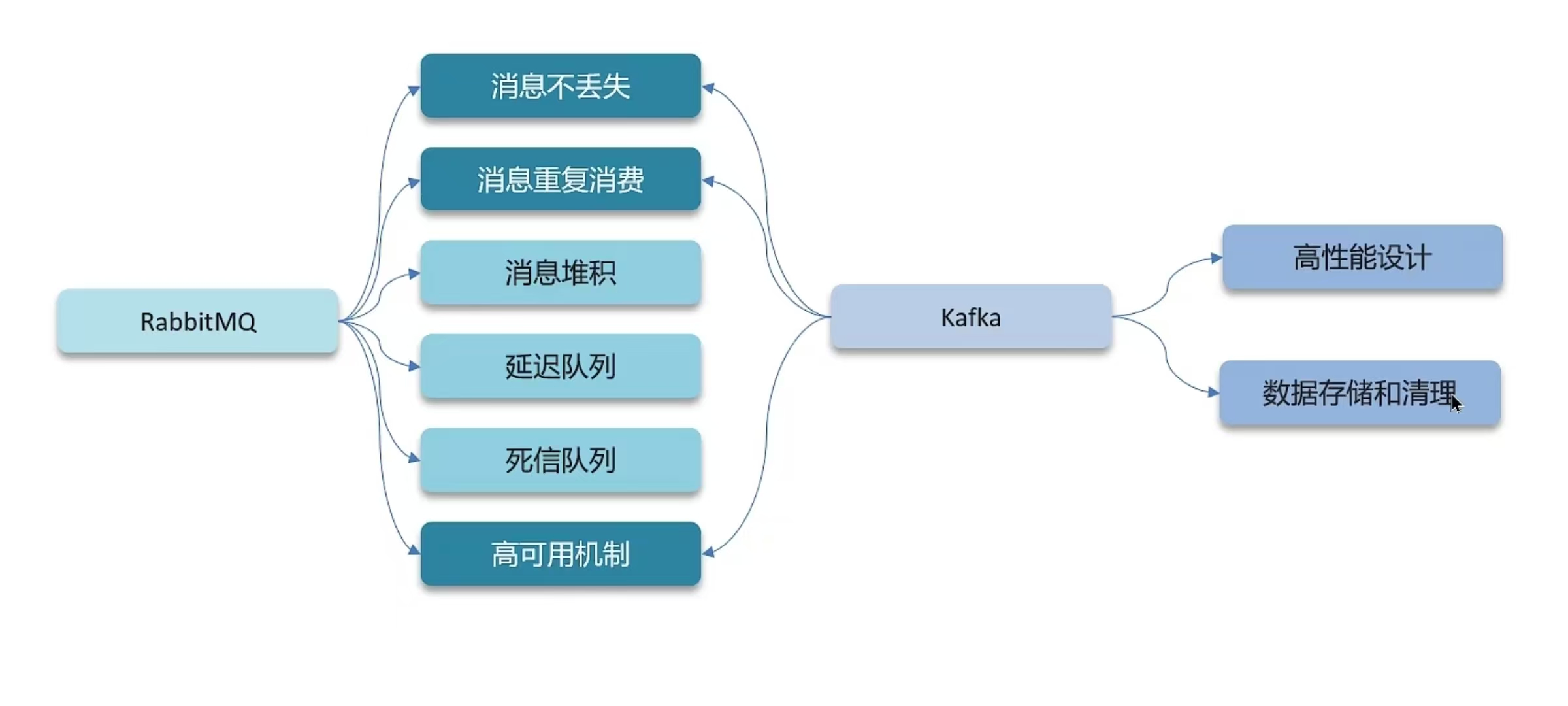
六 RabbitMQ Kafka
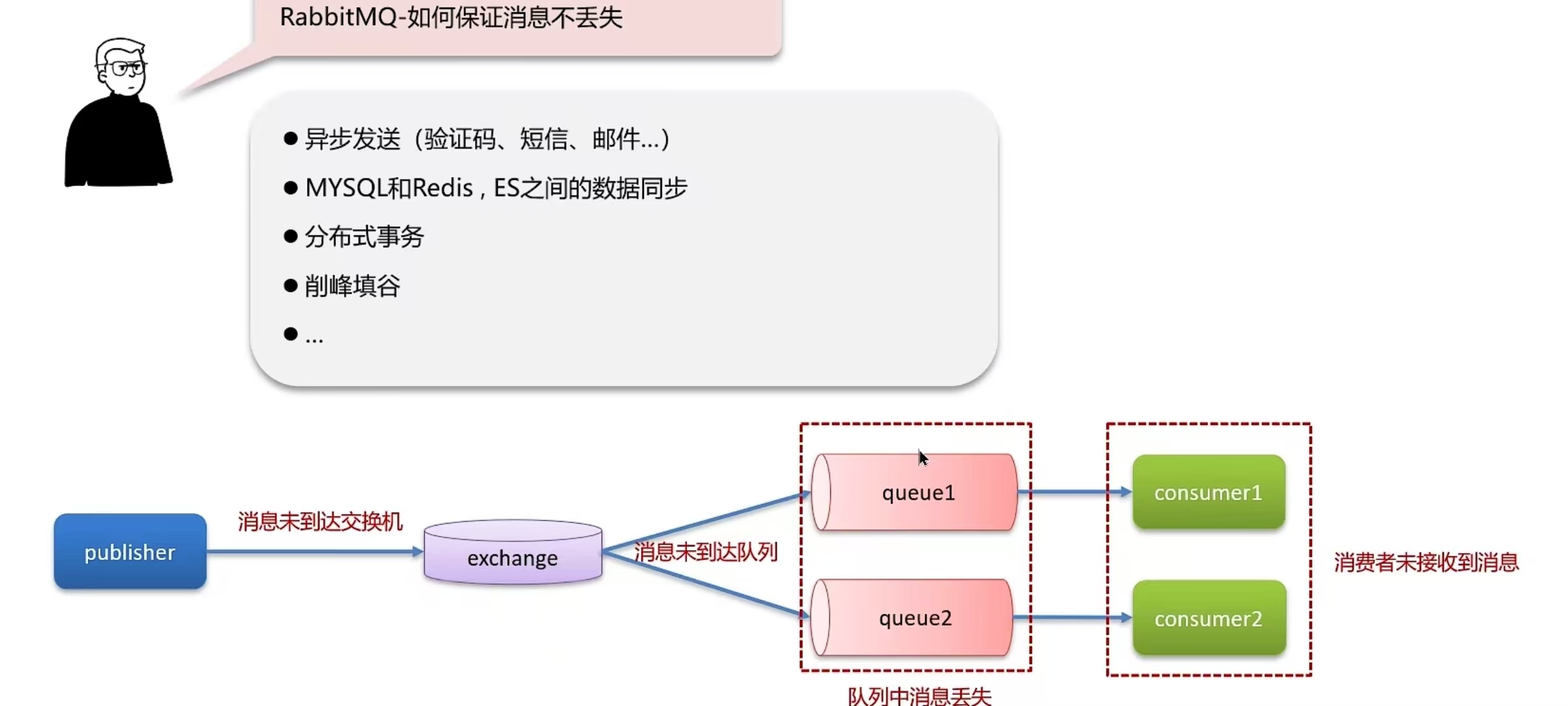
6.1 RabbitMQ-如何保证消息不丢失
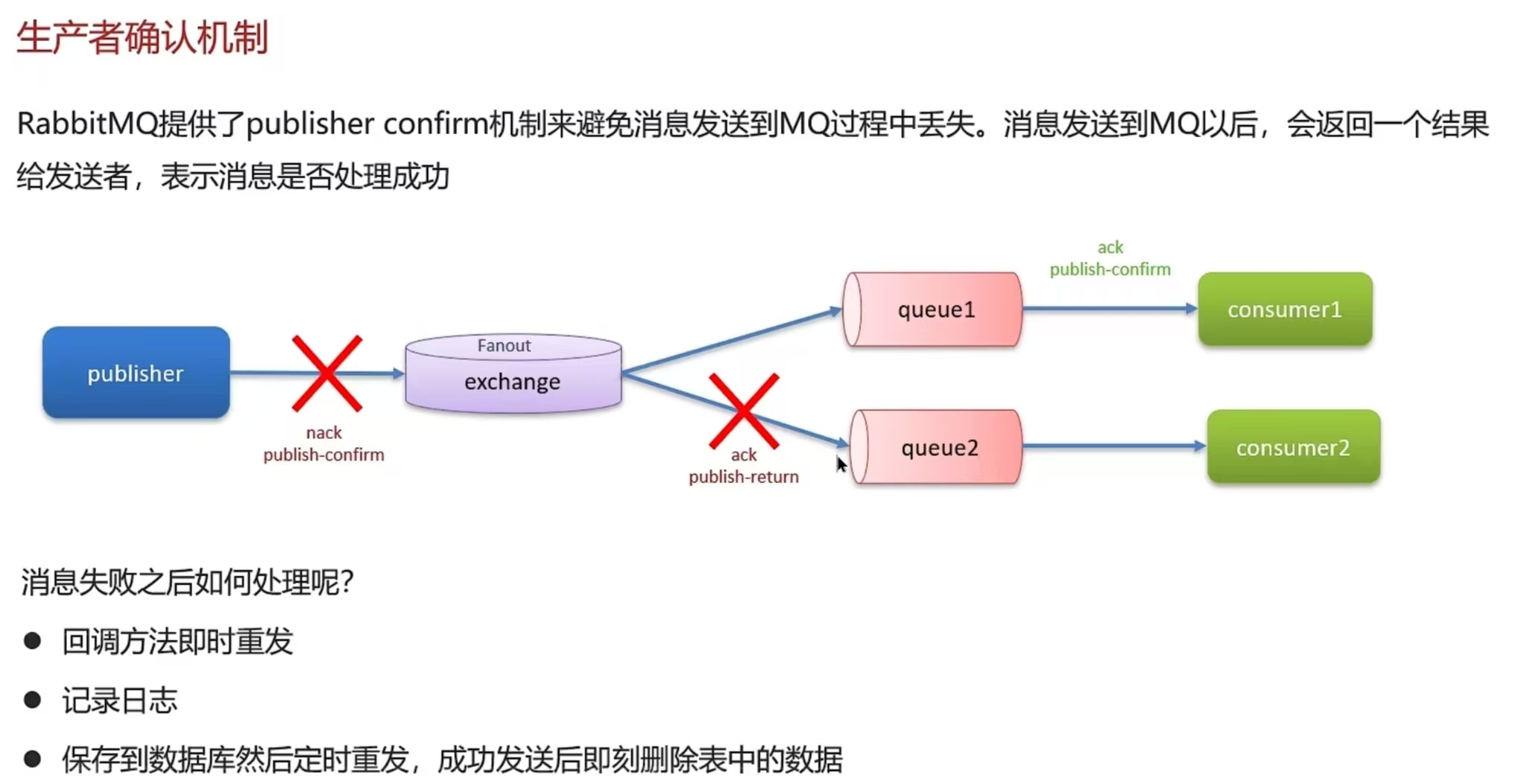
- 开启生产者确认机制,确保生产者的消息能到达队列
- 开启持久化功能,确保消息未消费前在队列中不会丢失
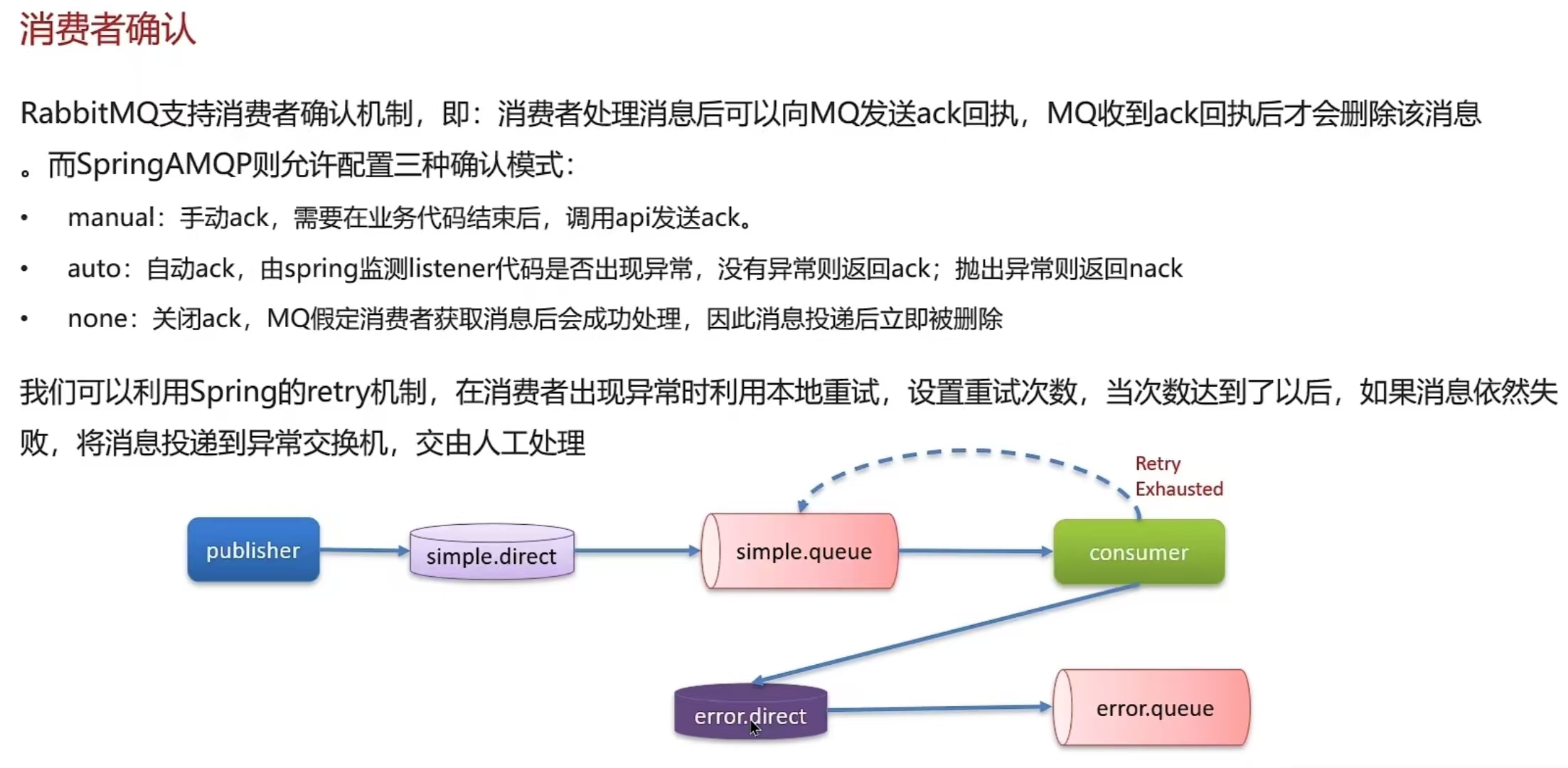
- 开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
- 开启消费者失败重试机制,多次重试失败后将消息投递到异常交换机,交由人工处理


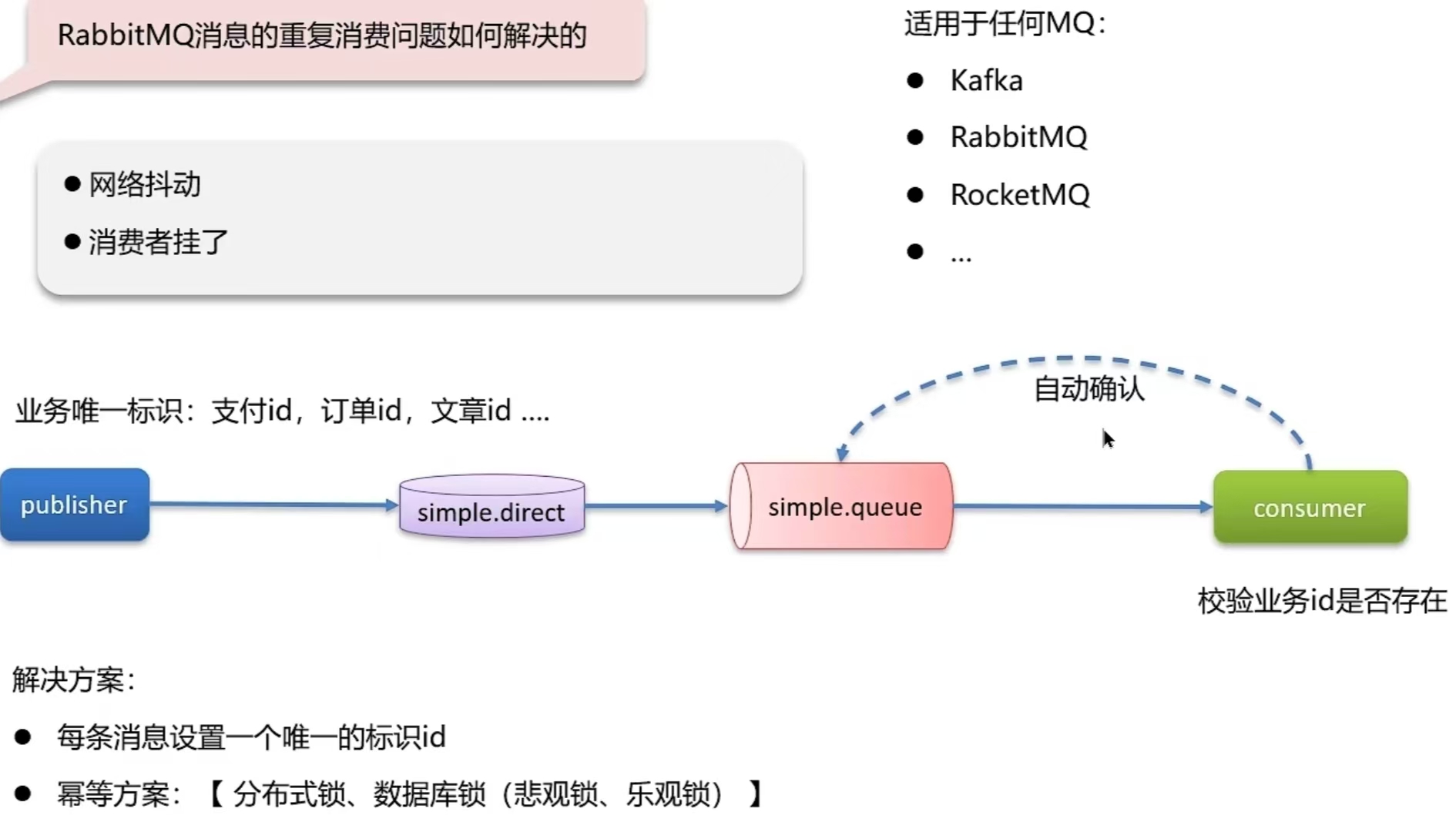
6.2 RabbitMQ消息的重复消费问题如何解决的

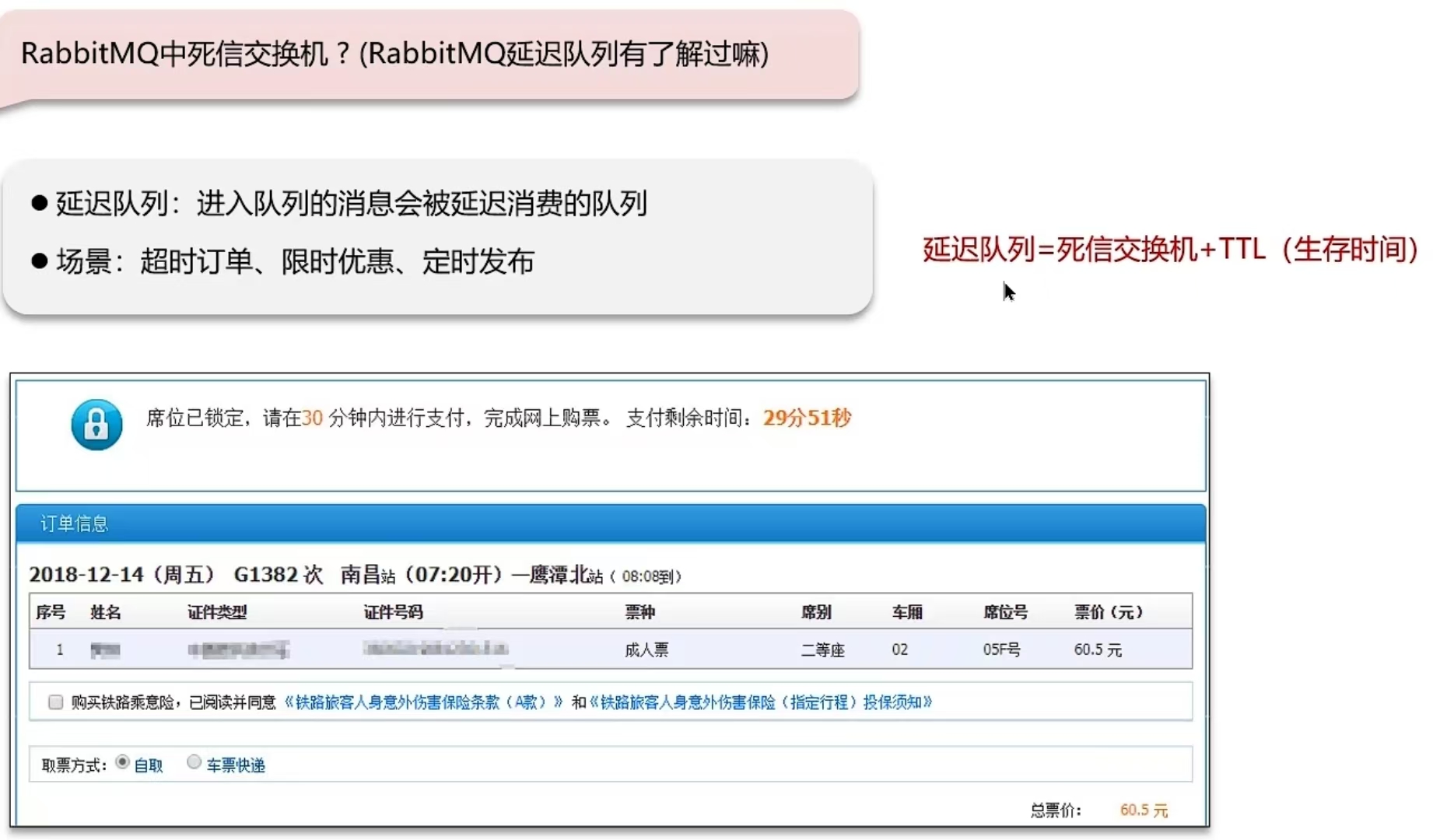
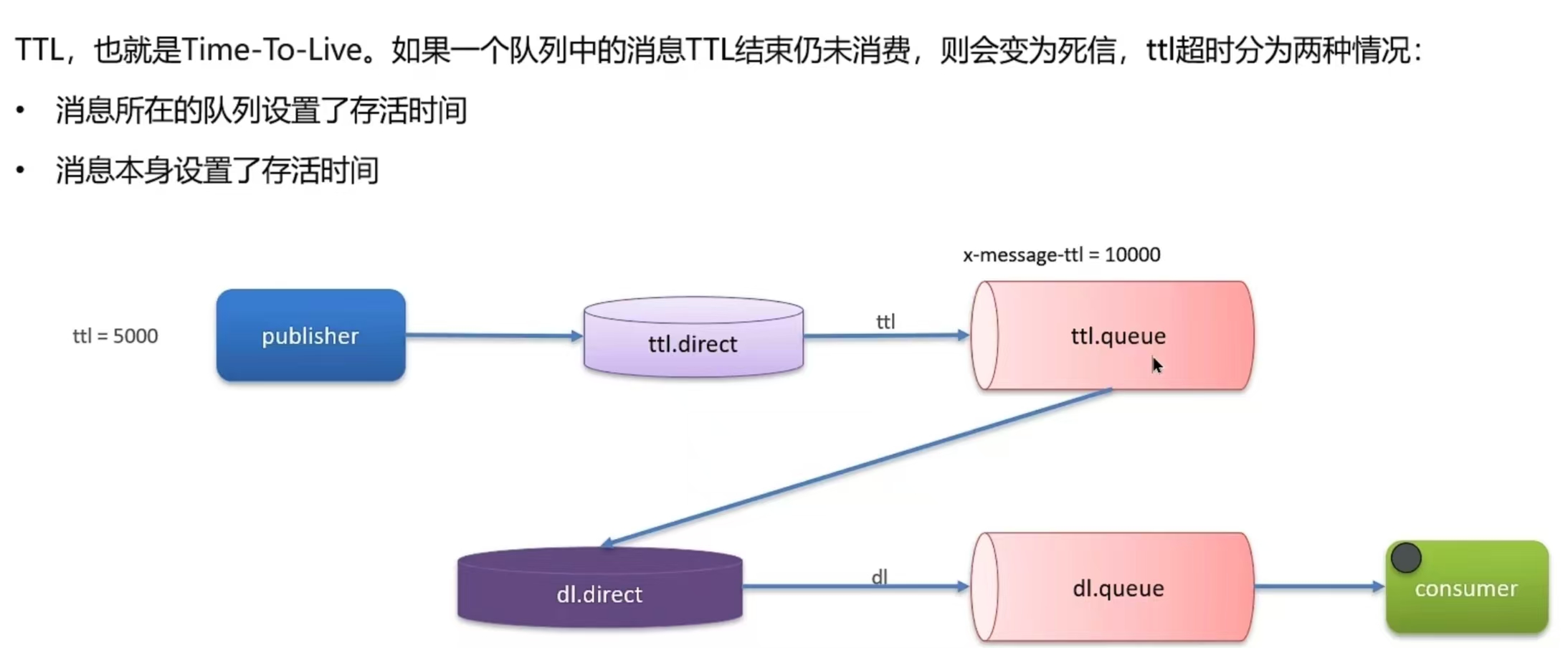
6.3 RabbitMQ中死信交换机?(RabbitMQ延迟队列有了解过嘛)
- 我们当时一个什么业务使用到了延迟队列(超时订单、限时优惠、定时发布...)
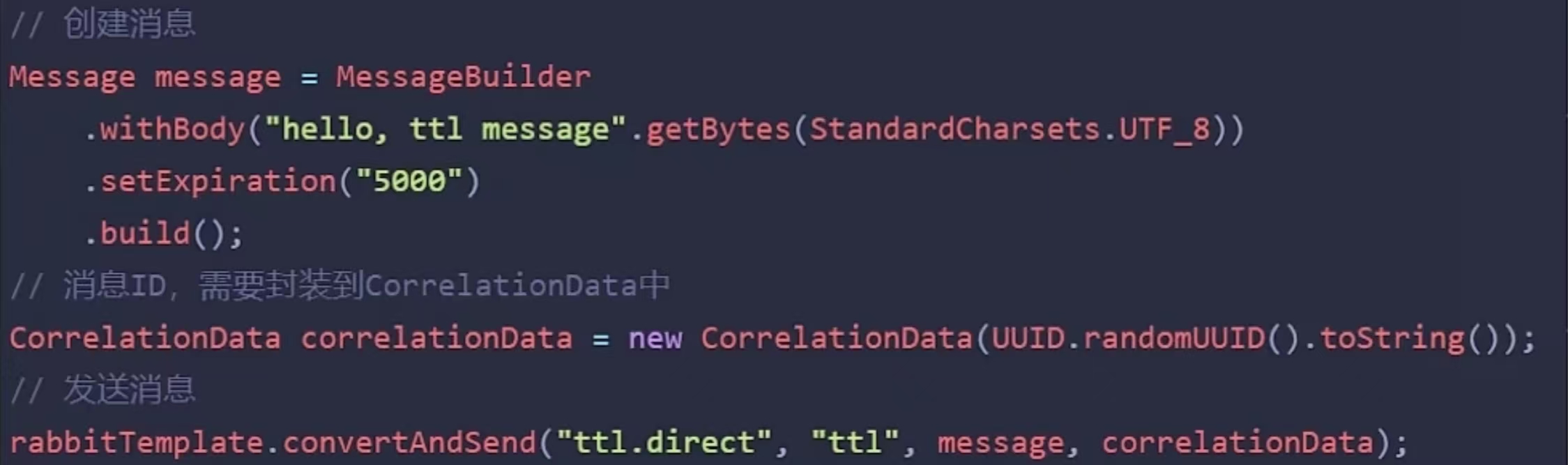
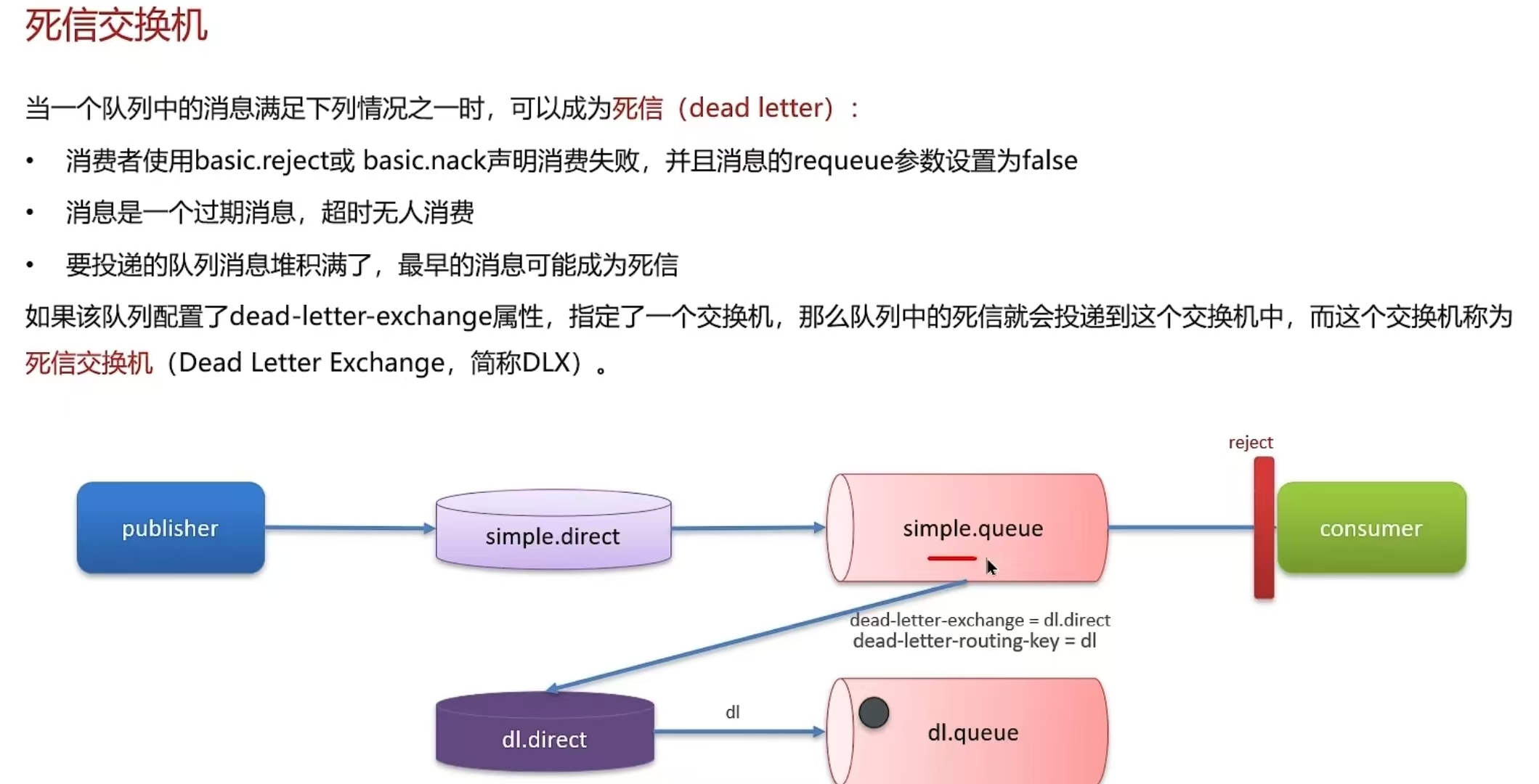
- 其中延迟队列就用到了******死信交换机和TTL(消息存活时间)******实现的
- 消息超时未消费就会变成死信(死信的其他情况:拒绝被消费,队列满了)

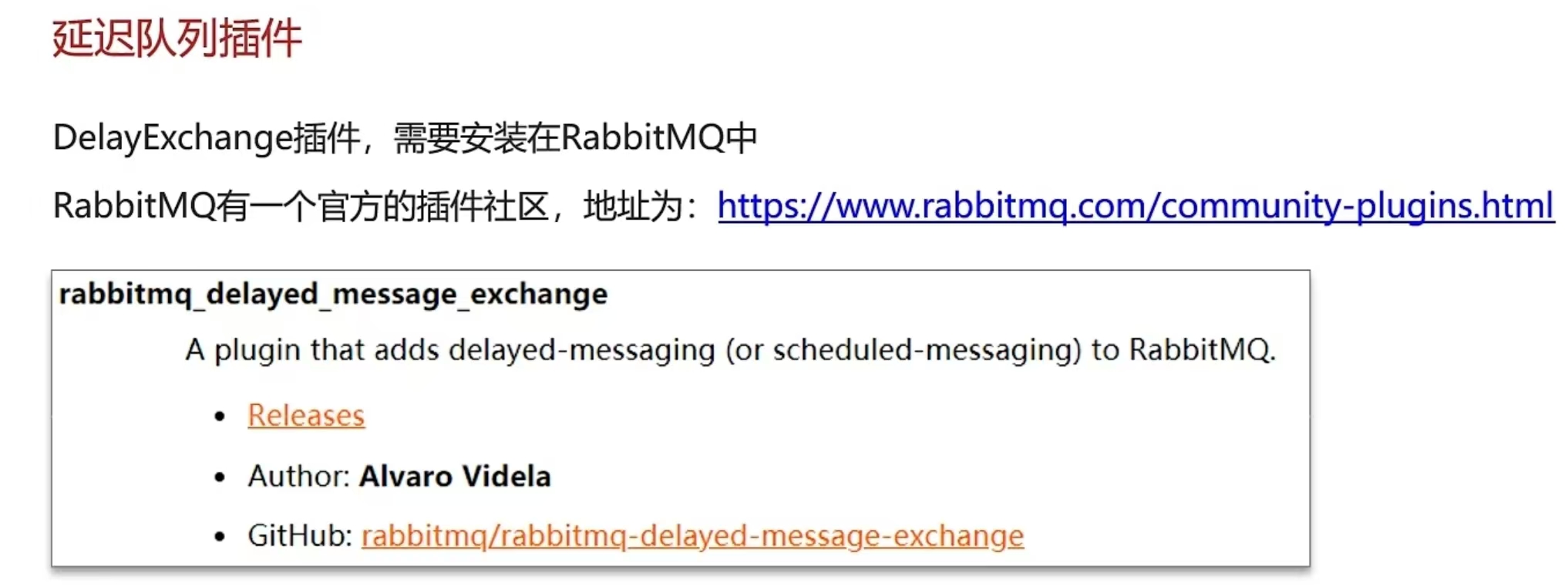
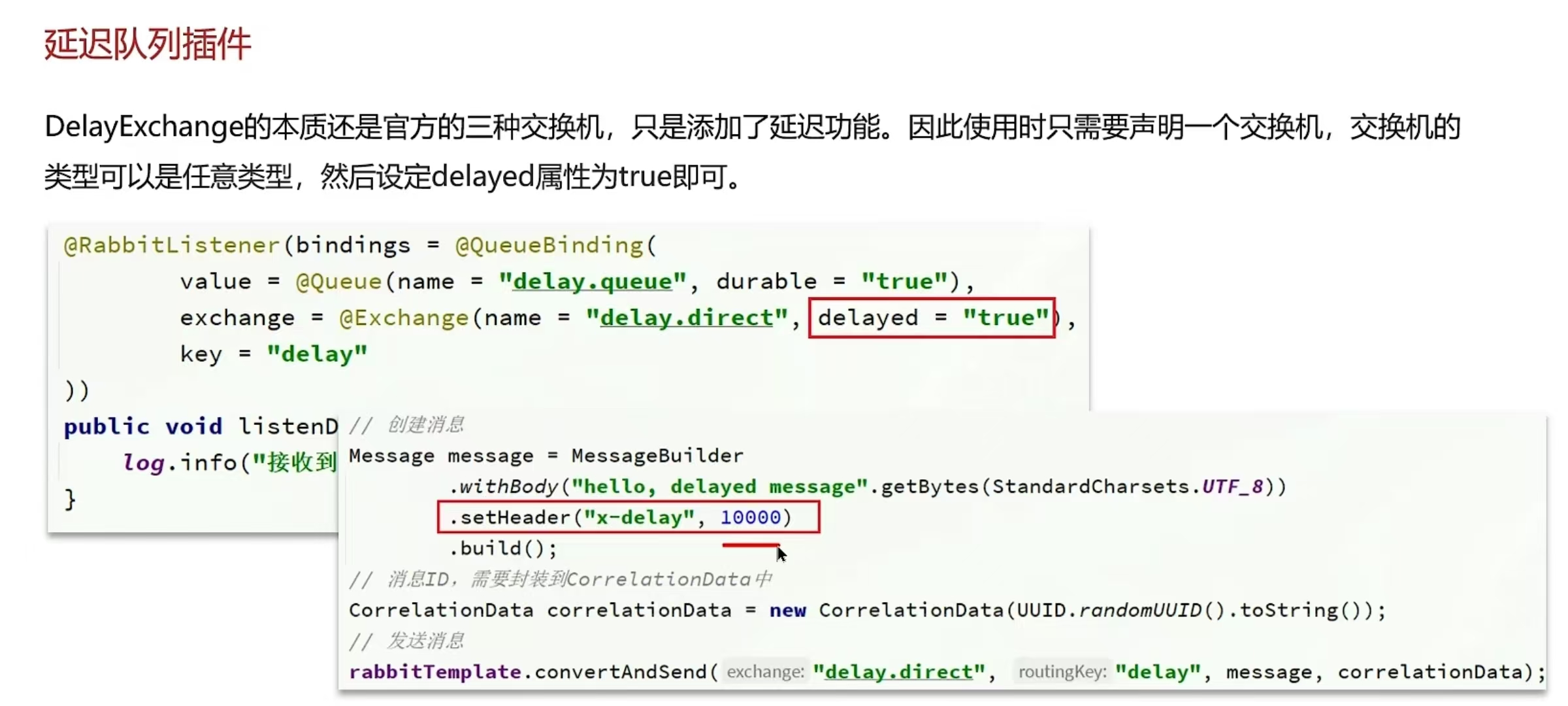
延迟队列插件实现延迟队列DelayExchange
- 声明一个交换机,添加delayed属性为true
- 发送消息时,添加x-delay头,值为超时时间

6.4 RabbitMQ如果有100万消息堆积在MQ,如何解决(消息堆积怎么解决)
惰性队列
惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储


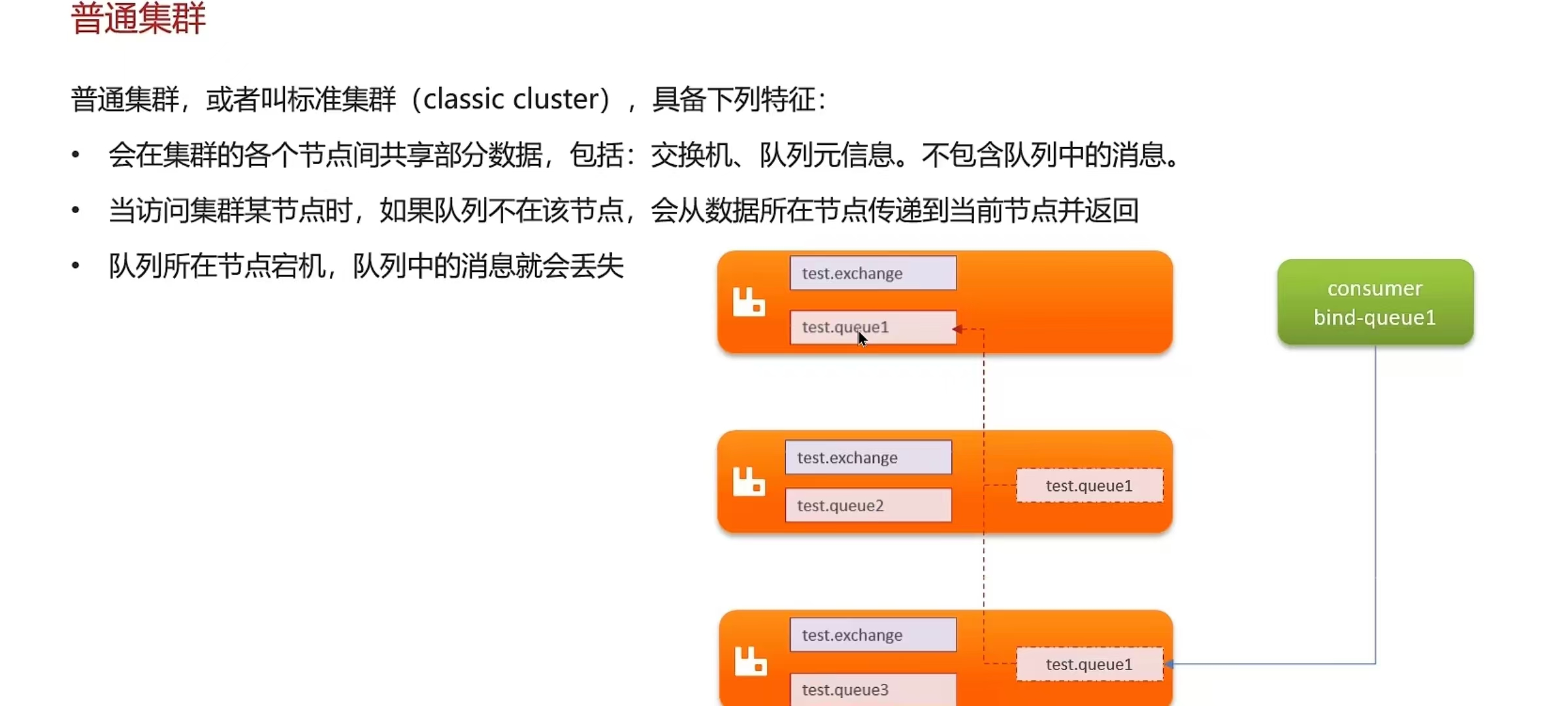
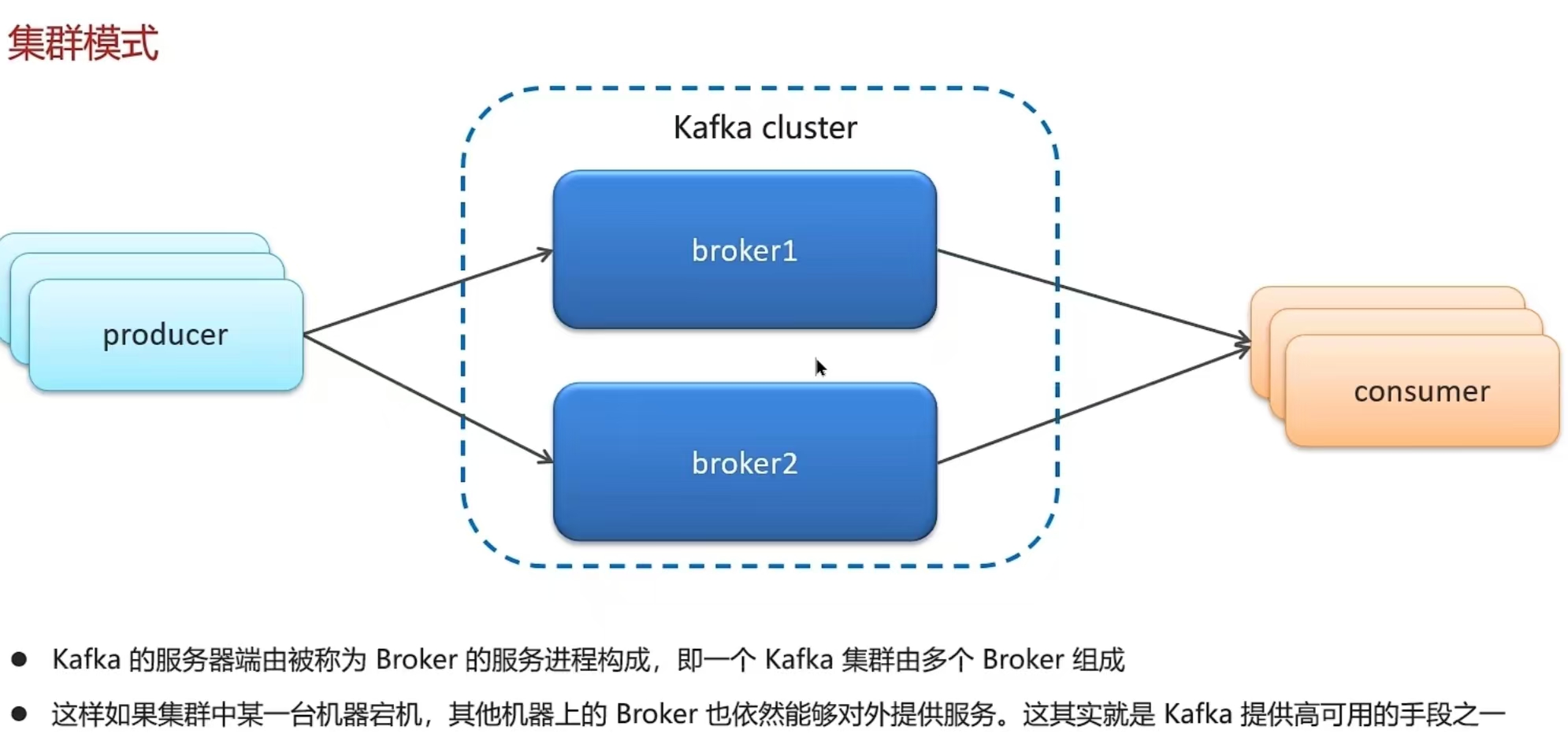
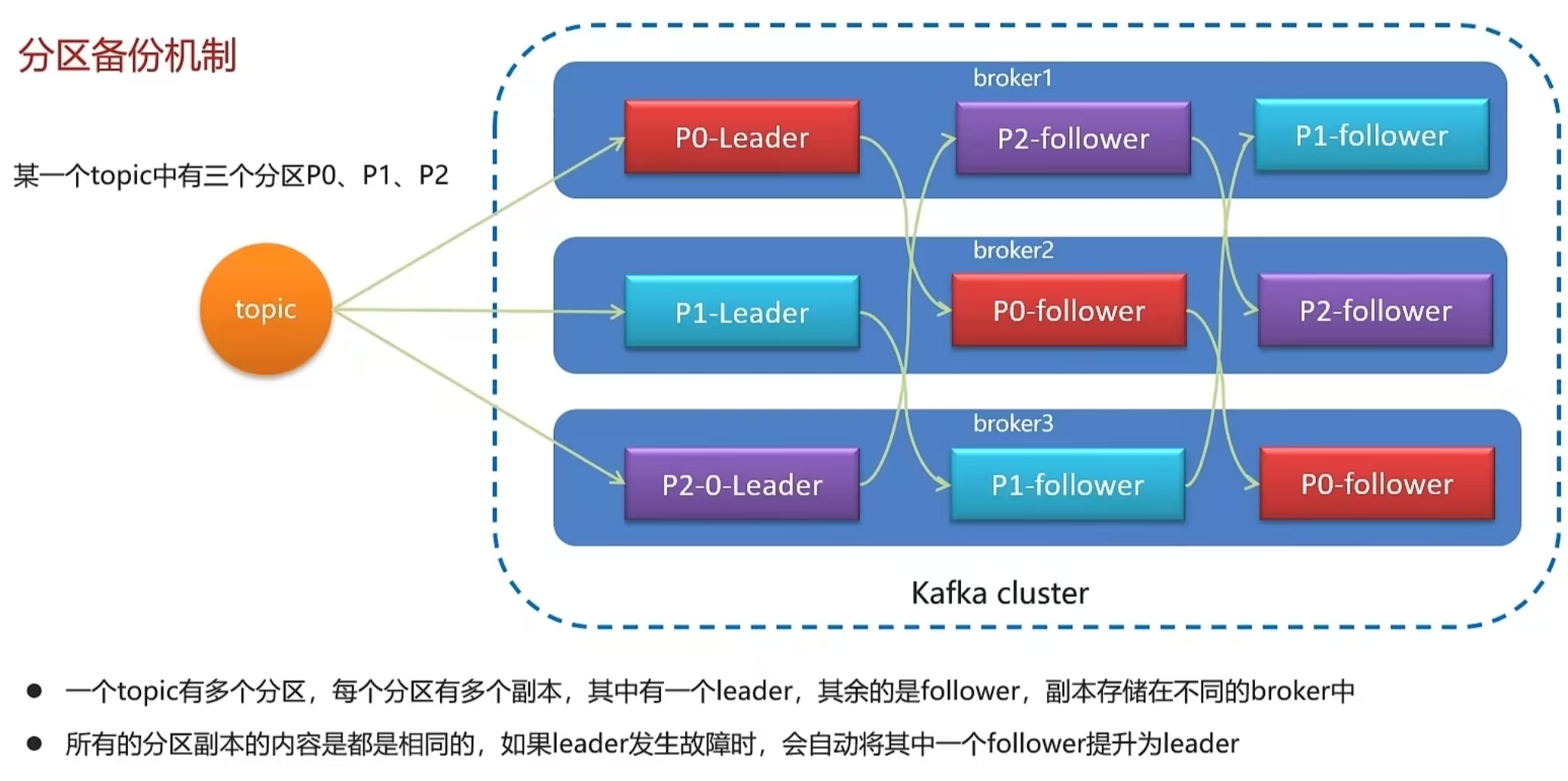
6.5 RabbitMQ的高可用机制有了解过嘛
- 在生产环境下,使用集群来保证高可用性:普通集群、镜像集群、仲裁队列
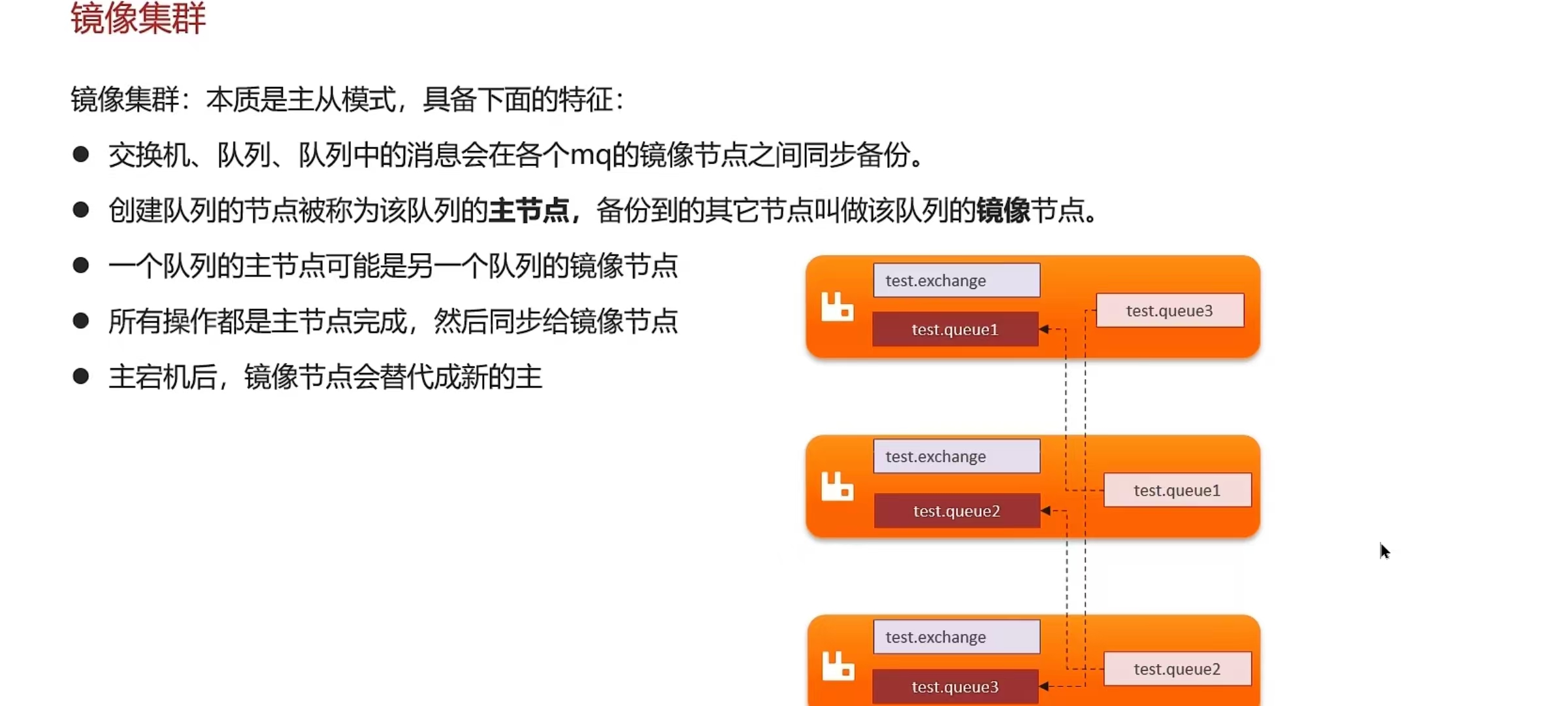
- 我们当时采用的镜像模式搭建的集群,共有3个节点
- 镜像队列结构是一主多从(从就是镜像),所有操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主(如果在主从同步完成前,主就已经宕机,可能出现数据丢失)
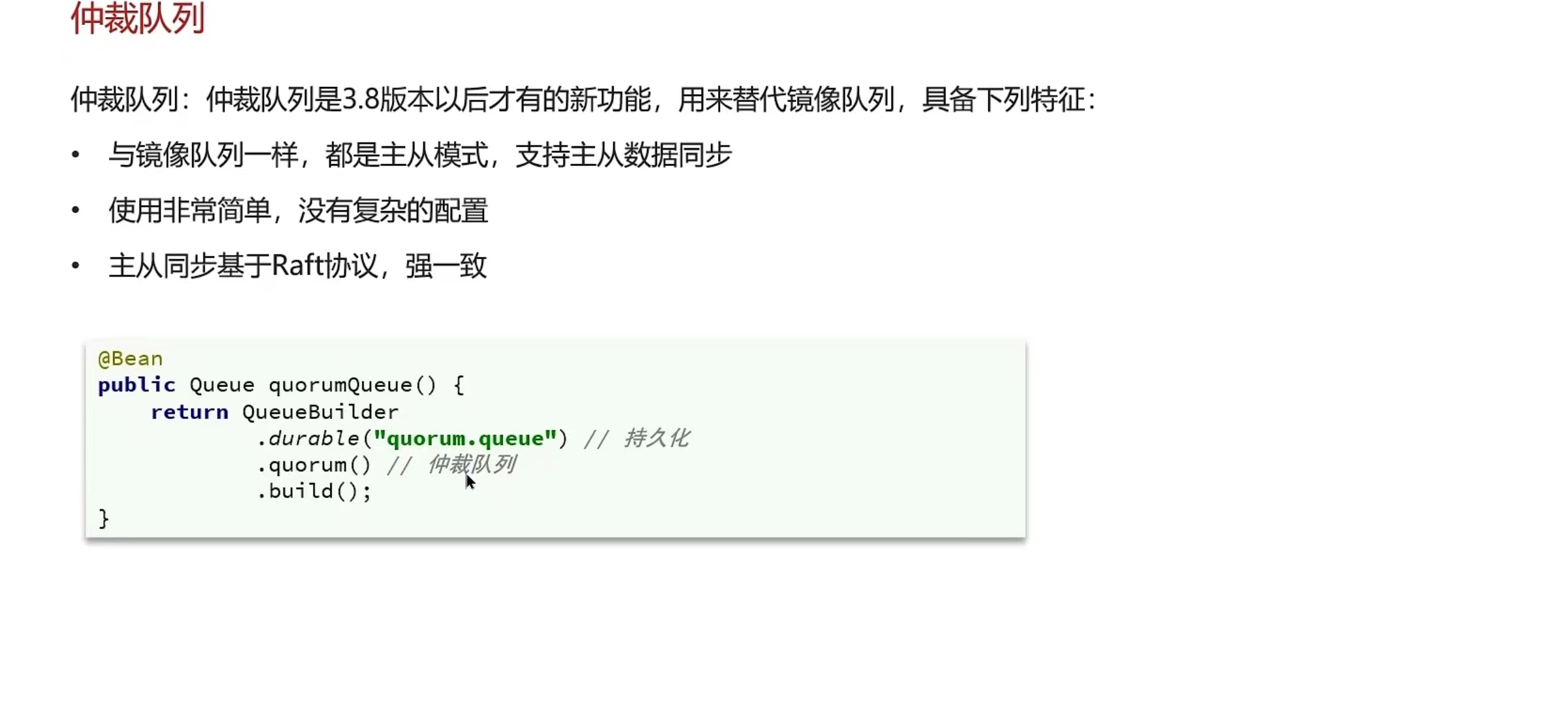
那出现丢数据怎么解决呢?
我们可以采用仲裁队列,与镜像队列一样,都是主从模式,支持主从数据同步,主从同步基于Raft协议,强一致。并且使用起来也非常简单,不需要额外的配置,在声明队列的时候只要指定这个是仲裁队列即可
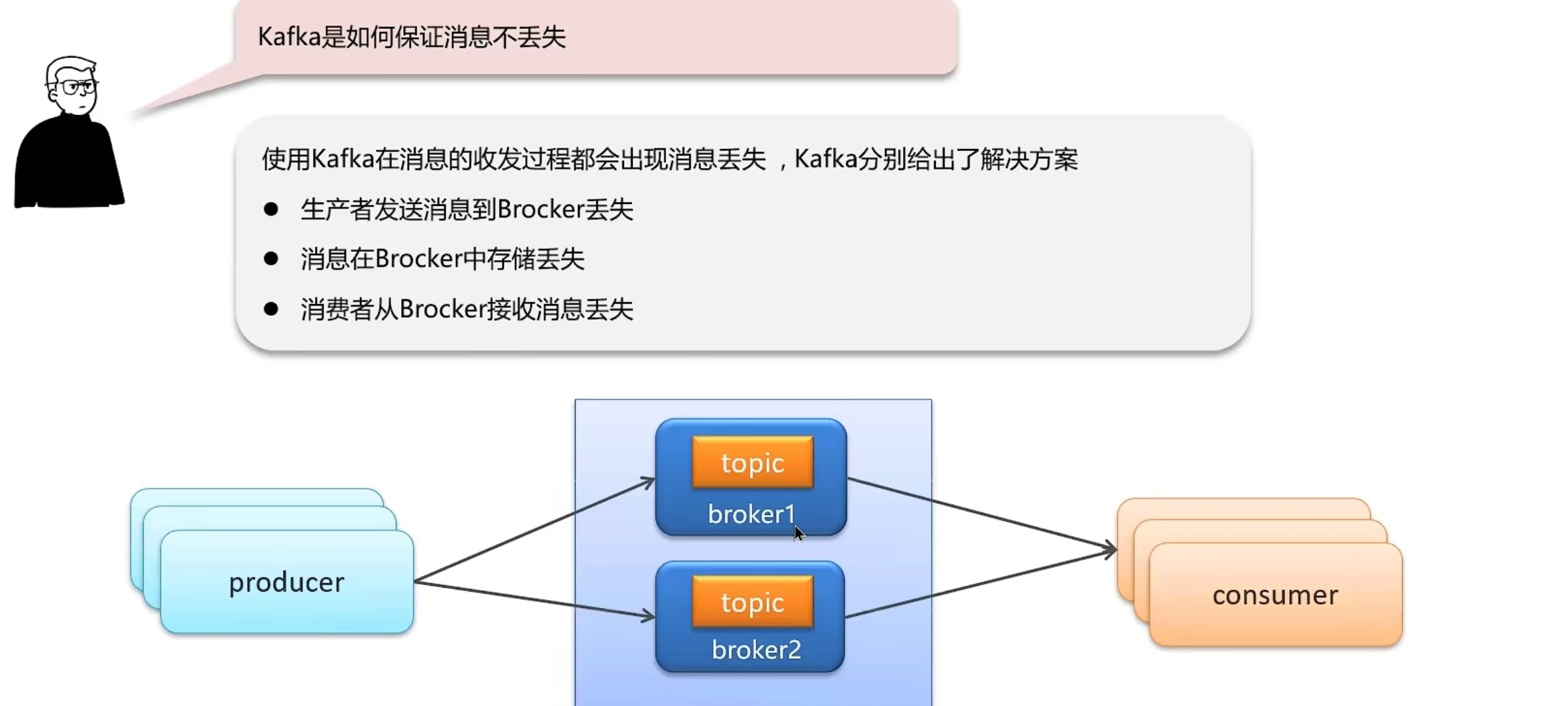
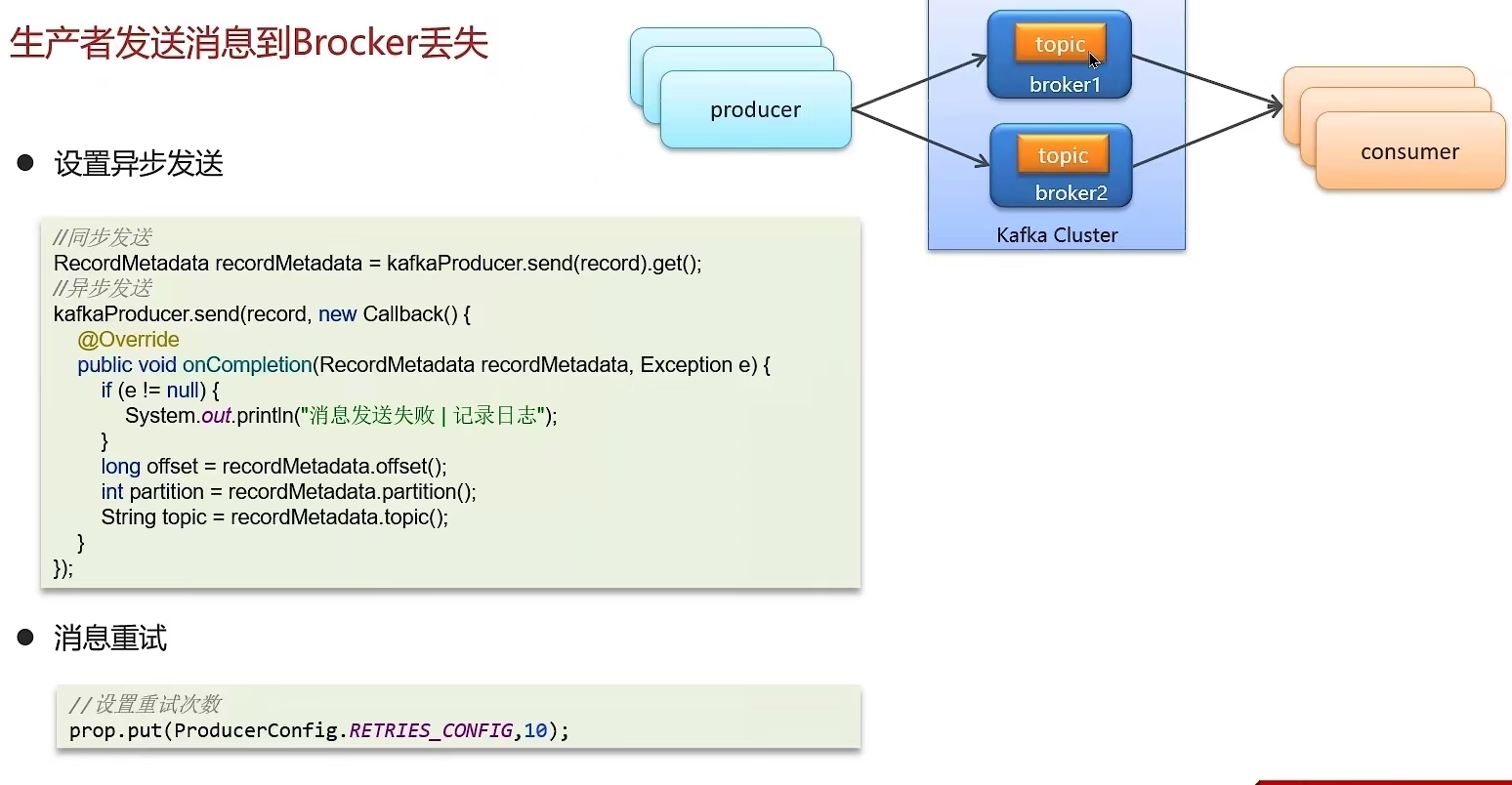
6.6 Kafka是如何保证消息不丢失
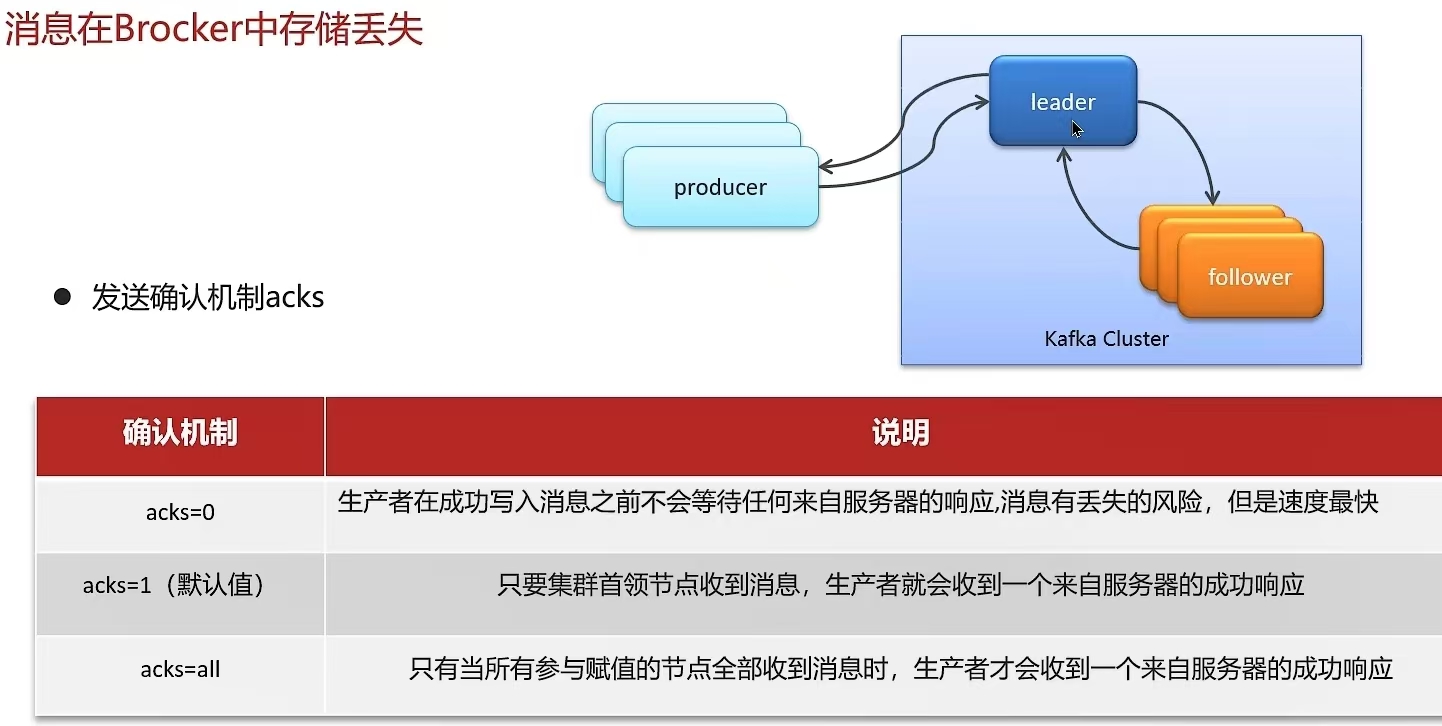
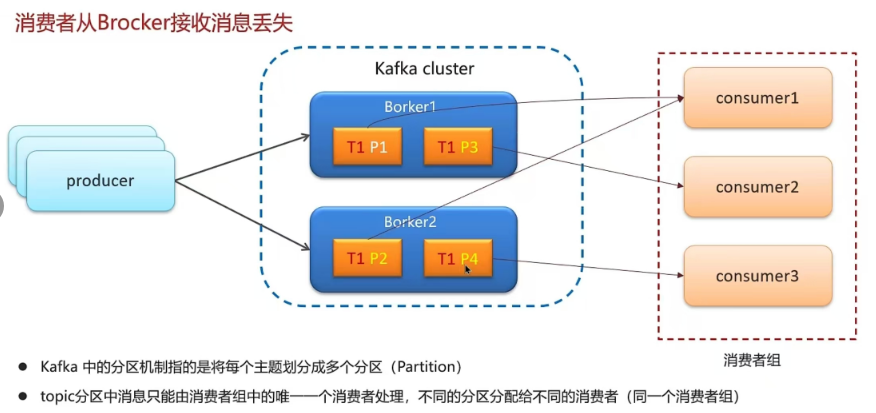
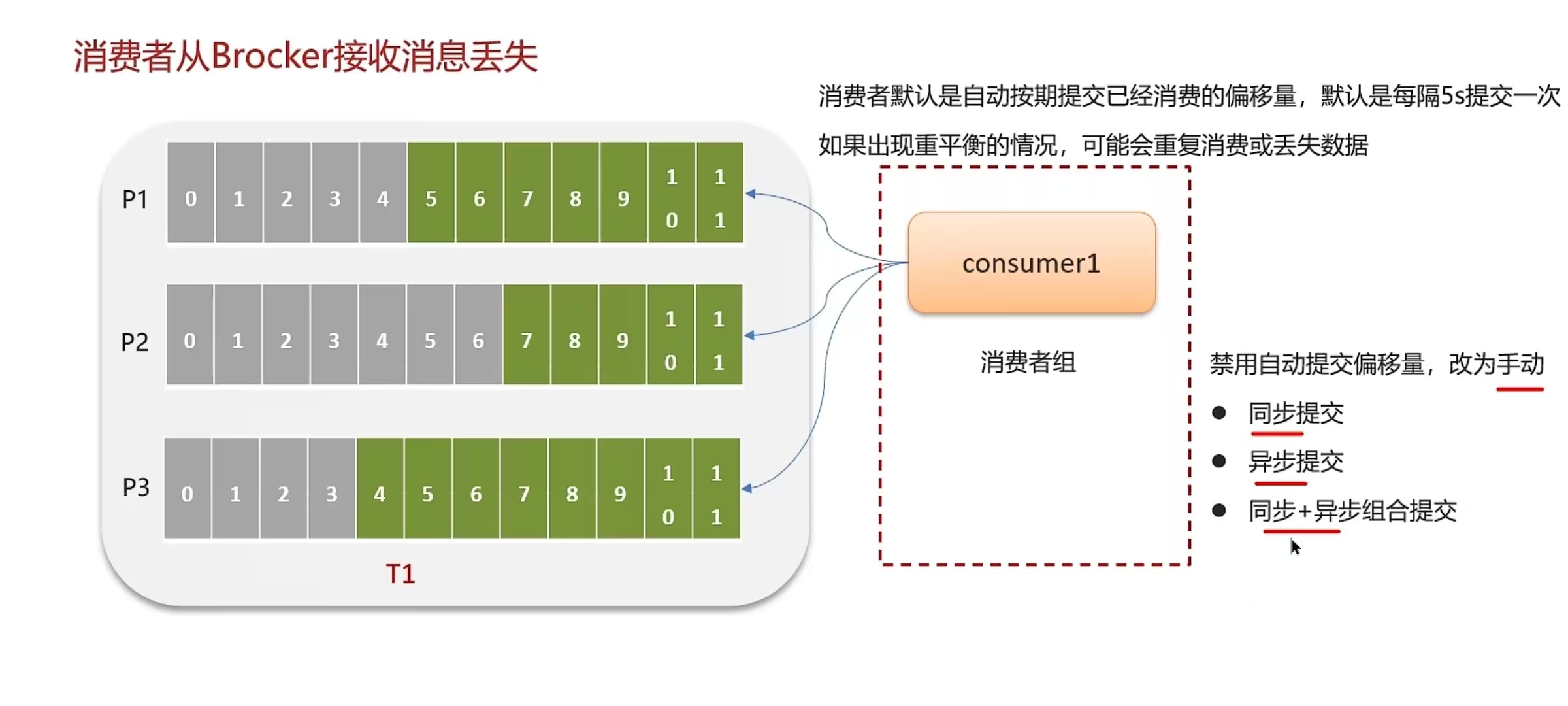
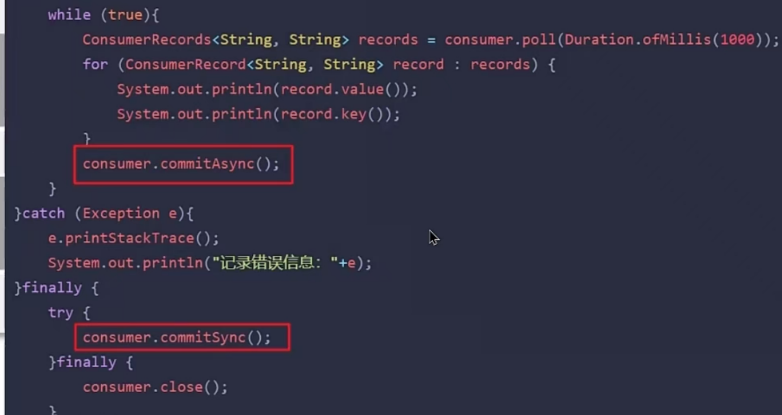


6.7 Kafka是如何保证消费的顺序性
应用场景:
- ·即时消息中的单对单聊天和群聊,保证发送方消息发送顺序与接收方的顺序一致
- ·充值转账两个渠道在同一个时间进行余额变更,短信通知必须要有顺序
问题原因:
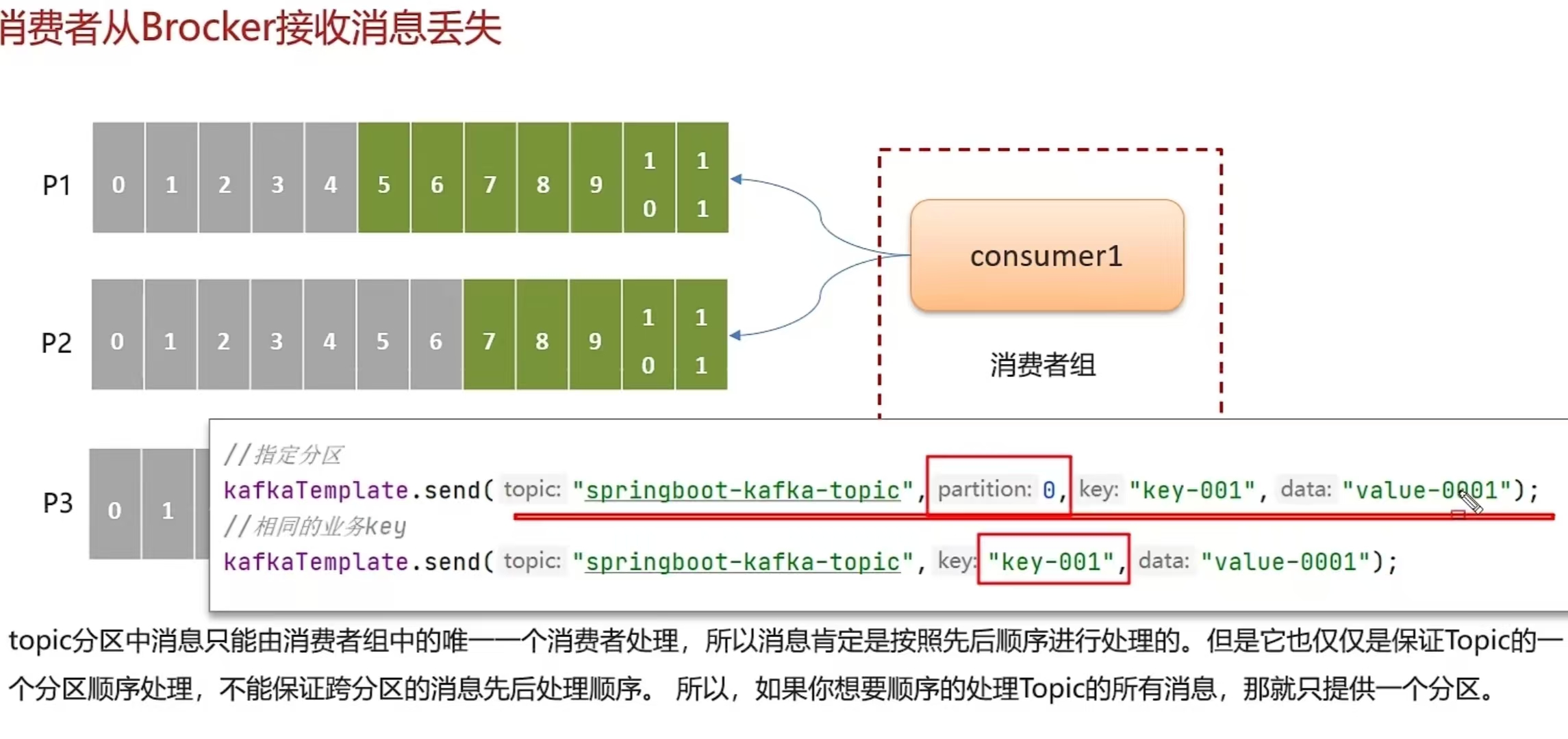
一个topic的数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个,分区不能保证顺序性,,
解决方案:
- 发送消息时指定分区号
- 发送消息时按照相同的业务设置相同的key

6.8 Kafka的高可用机制有了解过嘛


6.9 Kafka数据清理机制了解过嘛
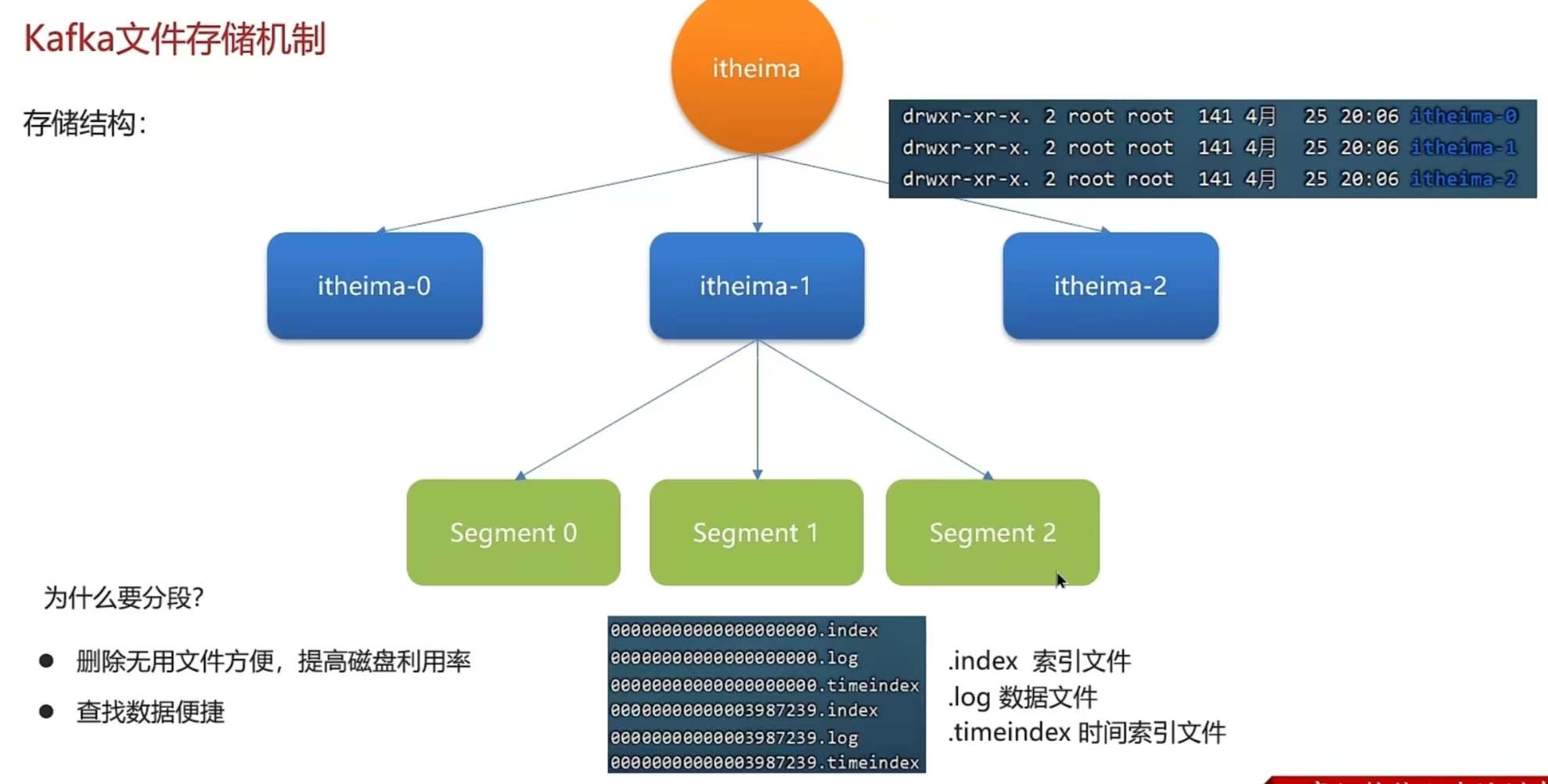
Kafka文件存储机制- Kafka存储结构,Kafka中topic的数据存储在分区上,分区如果文件过大会分段存储segment- 每个分段都在磁盘上以索引(xxxx.index)和日志文件(xxxx.1og)的形式存储- 分段的好处是,第一能够减少单个文件内容的大小,查找数据方便,第二方便kafka进行日志清理。
数据清理机制- 日志的清理策略有两个:- 根据消息的保留时间,当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时(7天)- 根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。******(默认关闭)******


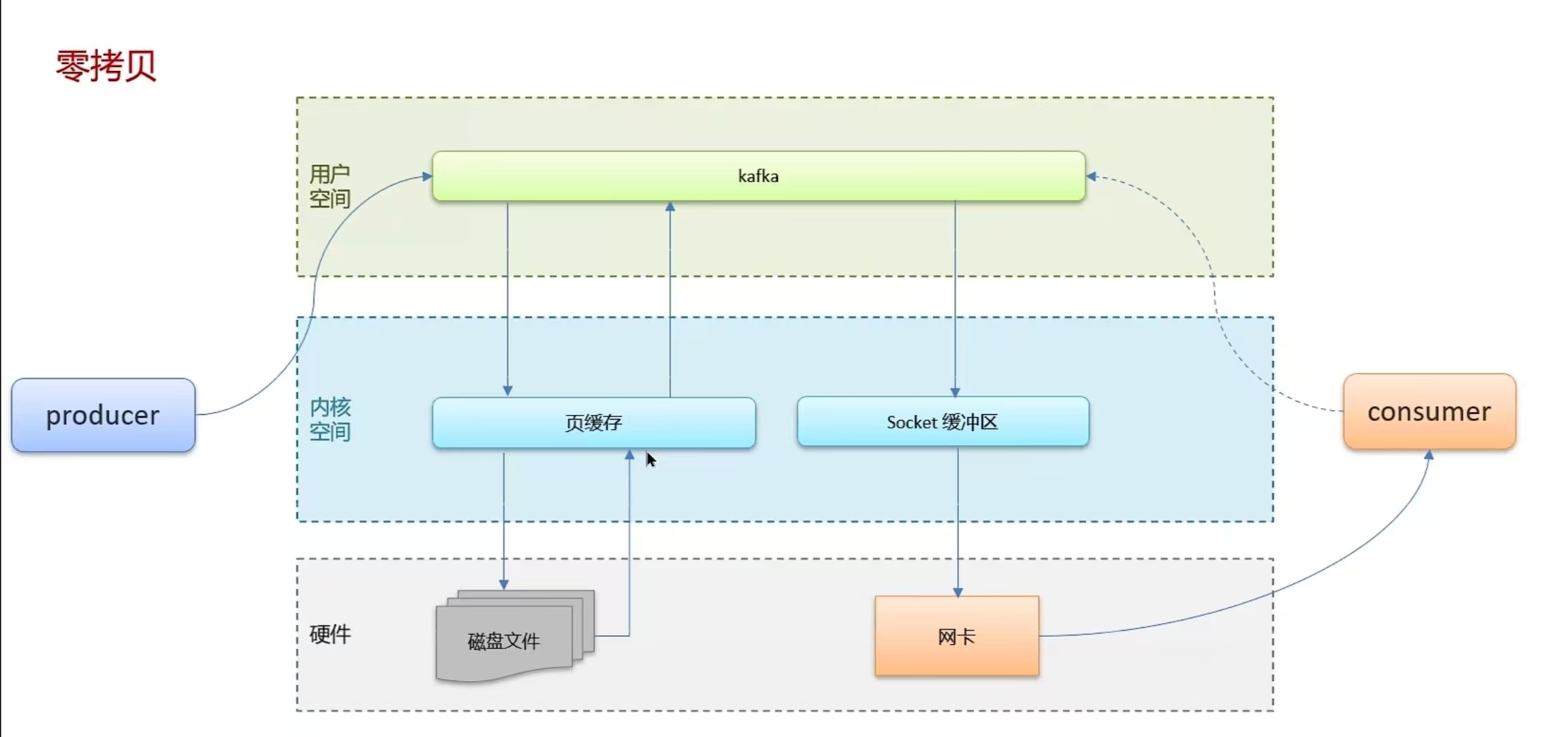
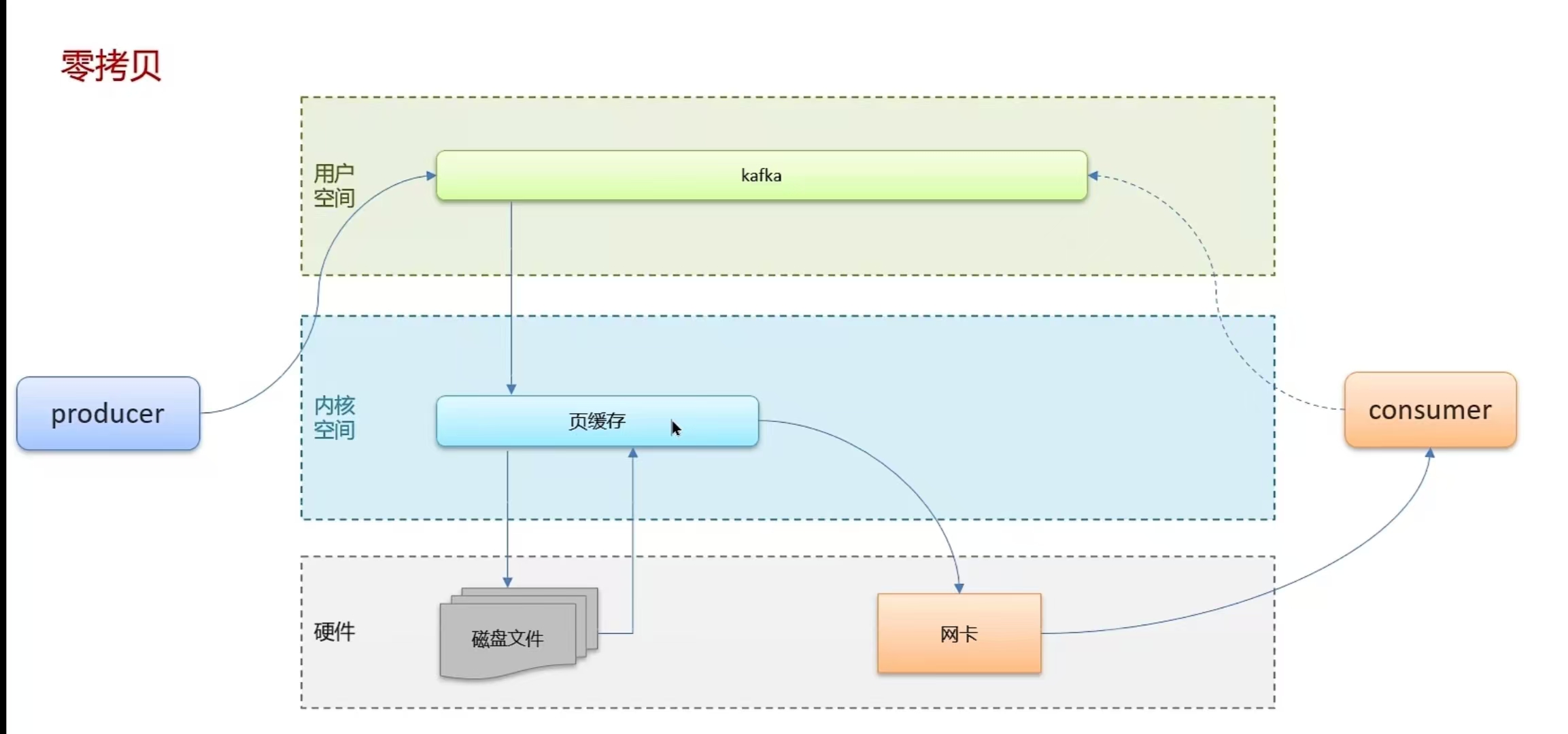
6.10 Kafka中实现高性能的设计有了解过嘛
- ·消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
- 顺序读写:磁盘顺序读写,提升读写效率
- ·页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
- 零拷贝:减少上下文切换及数据拷贝
- ·消息压缩:减少磁盘I0和网络I0
- 分批发送:将消息打包批量发送,减少网络开销

本文转载自: https://blog.csdn.net/qq_40453972/article/details/142080483
版权归原作者 18你磊哥 所有, 如有侵权,请联系我们删除。
版权归原作者 18你磊哥 所有, 如有侵权,请联系我们删除。