
学习视频链接:图像分类项目实战-深度学习框架应用开发-TensorFlow 2.0 | 百科荣创在线学习平台
迁移学习
把已训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习可以将已经学到的模型参数通过某种方式来分享给新模型从而加快并优化模型的学习效率,而不用像大多数网络那样从零学习。
迁移学习常见的策略是采用在ImageNet上预训练好的模型,然后通过微调整个模型的结构来适应新任务。
tf.keras.applications
tf.keras的应用模块提供了带有预训练权值的深度学习模型,这些模型可以用来进行预测、特征提取和微调。
def mobilenetv2(input_shape=(224, 224, 3), classes_num=len(cfg["labels_list"])):
#导入MobileNetV2的预训练模型
base_model = keras.applications.MobileNetV2(
weights='imagenet',
input_shape=input_shape,
include_top=False)
base_model.trainable = False
#使用全连接层作为模型输出层
inputs = keras.Input(input_shape)
x = base_model(inputs, training=False)
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dropout(0.2)(x)
outputs = keras.layers.Dense(classes_num, activation='softmax')(x)
model = keras.Model(inputs, outputs)
return base_model, model
模型训练与部署
1.数据集采集
2.生成TFRecord文件
3.搭建神经网络
4.读取TFRecord文件
5.模型训练
6.转换为tflite模型
7.模型推理(加载tflite模型)
代码实现案例
1.自建猫狗分类数据集,定义文件路径、标签名称和各种参数
labels = {
"cat_dog_labels": ["巴曼猫", "孟买猫", "英短", "比格猎犬", "沙皮狗", "柴犬"],
}
cfg = {
"datas_path": './dataset/cat_dog/',
"tfrecord_file": "./dataset/cat_dog.tfrecord",
"tflite_model_path": "./models/cat_dog_model.tflite",
"model_path": "./models/cat_dog_model.h5",
"labels_list": labels["cat_dog_labels"],
"camera_id": 0,
"width": 224,
"height": 224,
"color_channel": 3,
"batch_size": 32,
"epoch": 5,
"lr": 1e-2,
"save_freq": 1,
}
2.生成TFRecord文件
import tensorflow as tf
import config as config
from tqdm import tqdm
import os
cfg = config.cfg
writer = tf.io.TFRecordWriter(cfg["tfrecord_file"])
for index, name in enumerate(os.listdir(cfg["datas_path"])): # enumerate(): 将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
# print('index', index, name)
class_path = cfg["datas_path"] + name + '/'
for img_name in tqdm(os.listdir(class_path)): # os.listdir: 返回指定的文件夹包含的文件或文件夹的名字的列表。这个列表以字母顺序
img_path = class_path + img_name
image = open(img_path, 'rb').read() # 读取数据集图片到内存,image 为一个 Byte 类型的
example = tf.train.Example(features=tf.train.Features(feature={
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[index])),
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image]))
}))
writer.write(example.SerializeToString()) # 将一个example写入TFRecord文件
writer.close()
3.搭建神经网络
from tensorflow import keras
import config as config
cfg = config.cfg
def mobilenetv2(input_shape=(224, 224, 3), classes_num=len(cfg["labels_list"])):
base_model = keras.applications.MobileNetV2(
weights='imagenet',
input_shape=input_shape,
include_top=False)
base_model.trainable = False
inputs = keras.Input(input_shape)
x = base_model(inputs, training=False)
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dropout(0.2)(x)
outputs = keras.layers.Dense(classes_num, activation='softmax')(x)
model = keras.Model(inputs, outputs)
return base_model, model
4.读取TFRecord文件
import tensorflow as tf
import config as config
import cv2
cfg = config.cfg
def getDataset(tfrecord_file=cfg["tfrecord_file"]):
raw_dataset = tf.data.TFRecordDataset(tfrecord_file) # 读取 TFRecord 文件
feature_description = { # 定义Feature结构,告诉解码器每个Feature的类型是什么
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64),
}
def _parse_example(example_string): # 将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
feature_dict = tf.io.parse_single_example(example_string, feature_description)
feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码JPEG图片
return feature_dict['image'], feature_dict['label']
# 数据预处理
def preprocess(x, y):
"""
x is a simple image, not a batch
"""
x = tf.cast(x, dtype=tf.float32)
x = tf.image.resize(x, [224, 224]) # 原始图片大小为(266, 320, 3),重设为(192, 192)
# x = tf.expand_dims(x, 0)
x /= 255.0 # 归一化到[0,1]范围
y = tf.cast(y, dtype=tf.int32)
# y = tf.one_hot(y, depth=6)
return x, y
def normal(img, xy):
_mean = tf.constant([0.485, 0.456, 0.406], dtype=tf.float32)
_std = tf.constant([0.229, 0.224, 0.225], dtype=tf.float32)
img = tf.cast(img, dtype=tf.float32)
img = img - _mean / _std
return img, xy
raw_dataset = raw_dataset.map(_parse_example)
raw_dataset = raw_dataset.map(preprocess)
# raw_dataset = raw_dataset.map(normal)
return raw_dataset
def main():
dataset = getDataset()
for image, label in dataset:
# label = np.asarray(label, np.int32)
print("image.shape", image.shape, "label", label.shape, type(label))
image = image.numpy()
# print(image)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
cv2.imshow("image", image)
print("lable", label)
# print("label", cfg["labels_list"][label])
cv2.waitKey(100)
if __name__ == "__main__":
main()
5.模型训练
from tensorflow import keras
from network import mobilenetv2
import read_tfrecord
import tensorflow as tf
import config
cfg = config.cfg
def mobilenetv2_train(train_ds):
base_model, model = mobilenetv2()
model.summary()
model.compile(
optimizer=keras.optimizers.Adam(cfg["lr"]),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=["sparse_categorical_accuracy"]
)
model.fit(train_ds, epochs=cfg["epoch"])
model.save(cfg["model_path"])
train_db = read_tfrecord.getDataset()
train_db = train_db.shuffle(1000).batch(cfg["batch_size"])
mobilenetv2_train(train_db)
预测
import cv2 as cv
import numpy as np
from PIL import ImageFont, ImageDraw, Image
import tensorflow as tf
import cv2
import config as config
cfg = config.cfg
font_path = 'simsun.ttc'
# 在图像中显示中文
def putText(img, text, org=(0, 0), color=(0, 0, 255), font_size=80):
font = ImageFont.truetype(font_path, font_size)
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
draw.text(org, text, fill=color, font=font)
img = np.array(img_pil)
return img
def loadModel(model_path=cfg["model_path"]):
model = tf.keras.models.load_model(model_path, compile=False)
return model
def do_predict(model, img):
img_src = cv2.resize(img, (cfg["height"], cfg["width"]))
img = cv2.cvtColor(img_src, cv2.COLOR_BGR2RGB)
image = img / 255.0
image = image.reshape(1, cfg["height"], cfg["width"], cfg["color_channel"])
result = model.predict(image)[0]
lable_index = np.argmax(result)
return lable_index
def main():
cap = cv2.VideoCapture(cfg["camera_id"])
model = loadModel()
while True:
_, img = cap.read()
if _:
label = do_predict(model, img)
out_img = putText(img, cfg["labels_list"][label])
out_img = cv2.resize(out_img, (320, 280))
cv.imshow('predict', out_img)
cv2.waitKey(10)
if __name__ == '__main__':
main()
预测效果
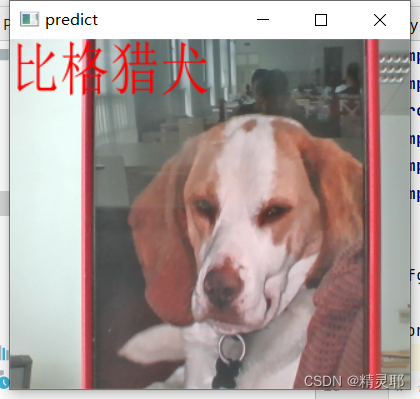
6.转换为tflite模型
import tensorflow as tf
import config as config
cfg = config.cfg
model = tf.keras.models.load_model(cfg["model_path"], compile=False)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_quant_model = converter.convert()
open(cfg["tflite_model_path"], "wb").write(tflite_quant_model)
7.模型推理(加载tflite模型)
import numpy as np
import tensorflow as tf
import cv2
import time
from PIL import ImageFont, ImageDraw, Image
import config as config
cfg = config.cfg
class tflite:
def __init__(self):
self.interpreter = tf.lite.Interpreter(model_path=cfg["tflite_model_path"]) # 读取模型
self.interpreter.allocate_tensors() # 分配张量
def inference(self, img):
# 获取输入层和输出层维度
input_details = self.interpreter.get_input_details()
output_details = self.interpreter.get_output_details()
# print("input_details", input_details)
# print("output_datalis", output_details)
# 设置输入数据
input_shape = input_details[0]['shape']
input_data = img
self.interpreter.set_tensor(input_details[0]['index'], input_data)
self.interpreter.invoke() # 推理
output_data = self.interpreter.get_tensor(output_details[0]['index']) # 获取输出层数据
return output_data
font_path = 'simsun.ttc'
# 在图像中显示中文
def putText(img, text, org=(0, 0), color=(0, 0, 255), font_size=80):
font = ImageFont.truetype(font_path, font_size)
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
draw.text(org, text, fill=color, font=font)
img = np.array(img_pil)
return img
capture = cv2.VideoCapture(cfg["camera_id"])
start = time.time()
model = tflite()
while True:
_, frame = capture.read()
if frame is None:
print('No camera found')
img = cv2.resize(frame, (224, 224))
h, w, _ = frame.shape
img = np.float32(img.copy())
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img / 255.0
img = img[np.newaxis, ...]
start = time.time()
y_pred = model.inference(img)
frame = putText(frame, cfg["labels_list"][np.argmax(y_pred)], org=(0, 0))
# fps_str = "FPS: %.2f" % (1 / (time.time() - start))
# cv2.putText(frame, fps_str, (0, 25), cv2.FONT_HERSHEY_DUPLEX, 0.75, (0, 255, 0), 2)
frame = cv2.resize(frame, (320, 280))
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
exit()

程序源文件网盘链接:
链接:https://pan.baidu.com/s/1nISLTDWWo-ai2ciTJVu3dw
提取码:0000
本文转载自: https://blog.csdn.net/weixin_45949082/article/details/124940734
版权归原作者 精灵耶 所有, 如有侵权,请联系我们删除。
版权归原作者 精灵耶 所有, 如有侵权,请联系我们删除。