
Actor-Critic强化学习记录
强化学习的算法大致分为三类,value-based、policy-based和两者的结合Actor-Critic,这里简单写一下近期对AC的学习心得。
一、环境介绍
这里使用的是gym环境的’CartPole-v1’,该环境和上篇文章的’CartPole-v0’几乎没有什么区别,主要区别在于每个回合的最大步数和奖励的有关定义,如下图所示。
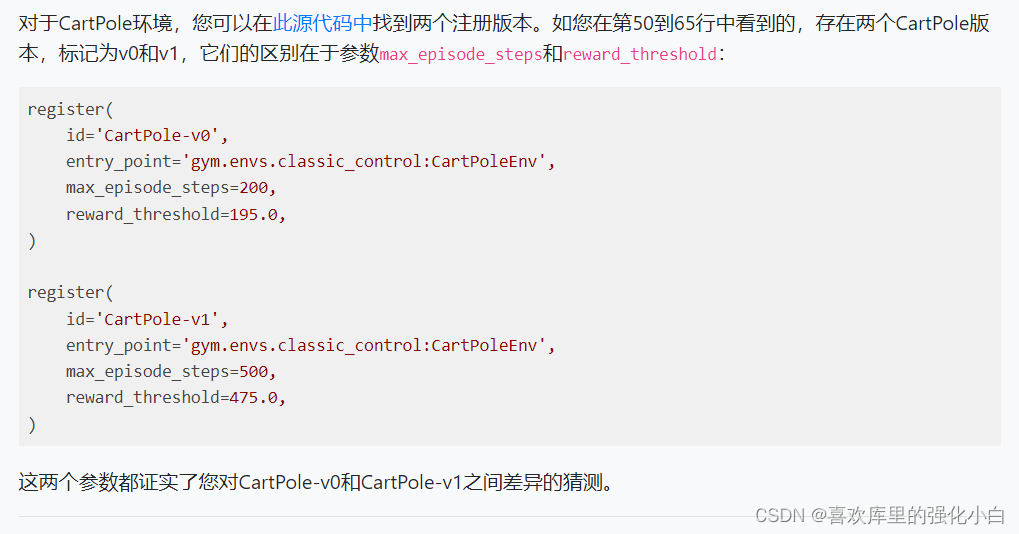
在本文中,想尝试结合On-Policy的算法,所以对单回合的的最大步数做了限制,大小为100。
'CartPole-v0’环境的详细介绍附上链接。
链接: OpenAI Gym 经典控制环境介绍——CartPole(倒立摆)
二、算法简单介绍
- Actor-Critic 该算法有两个框架,即策略相关的Actor网络和值相关的Critic网络。由于这里采用随机性策略,所以Actor网络利用了softmax函数将概率进行归一化;Critic为网络利用v值进行计算。此外,这里利用了A2C的优势函数(Advantage)。
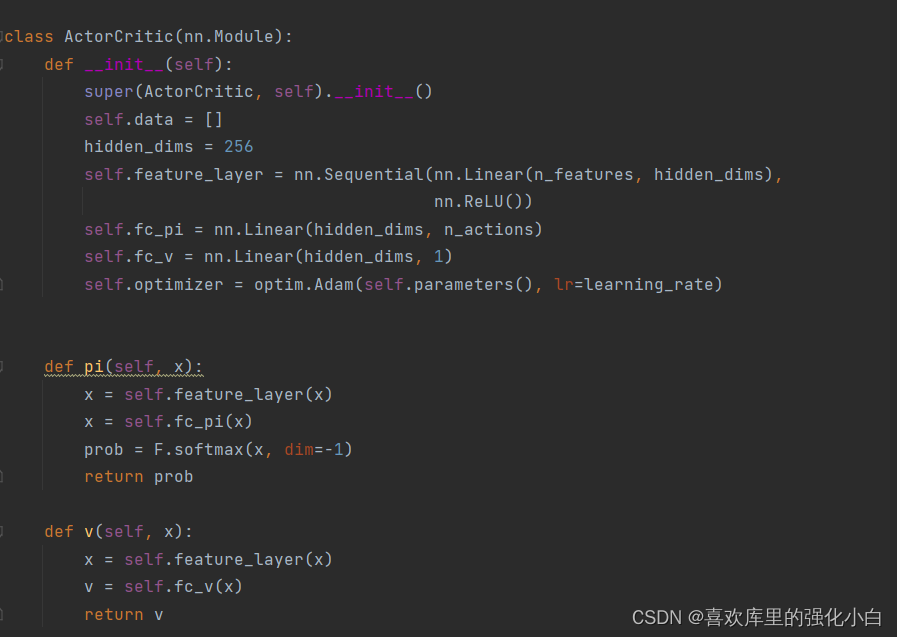
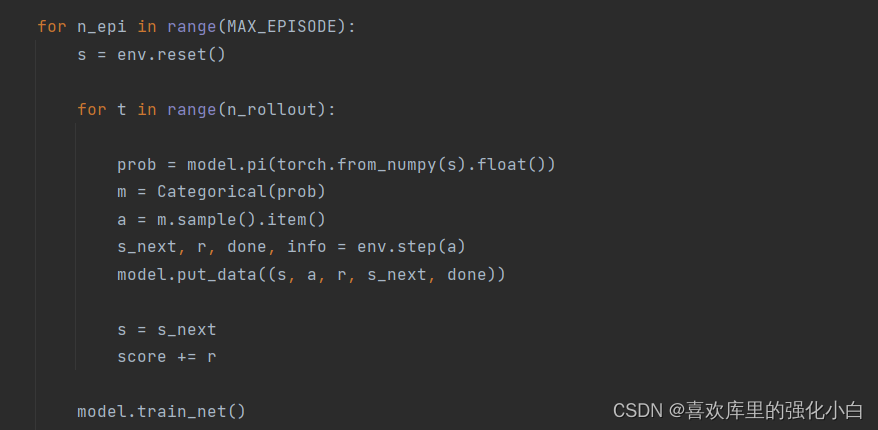
- On-Policy 这里采取了On-Policy的算法,注意每回合100步游戏,会产生100条transition,待将这些transition存储之后,开始学习,直接利用这100个样本,并且将样本清空,以便下一回合获得新的样本。
- AC(A2C)伪代码:


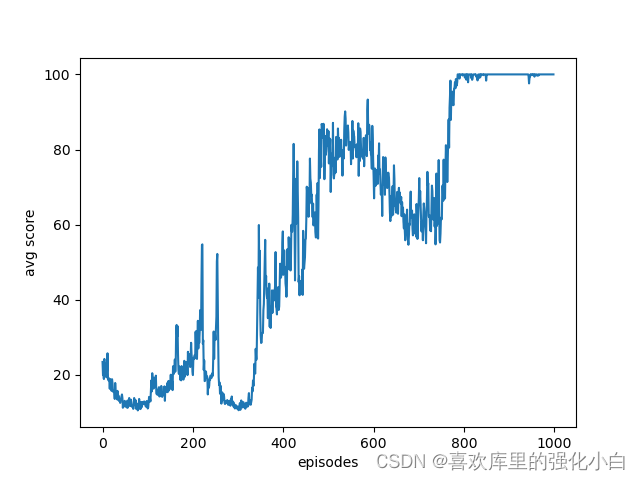
- 实现 这里的实现参考了网上的教程,但是源代码只是Policy-Gradient的方法,这里进行了简单修改。此外,这里是随机性策略,本身就增加了探索性,不同于之前的确定性策略,用到了torch的抽样函数,具体还没研究。结果也附在下图,可以看到经过训练后,奖励基本上收敛到100。
import gym
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
import matplotlib.pyplot as plt
# Hyperparameters
learning_rate =0.0002
gamma =0.98
n_rollout =100
MAX_EPISODE =20000
RENDER =False
env = gym.make('CartPole-v1')
env = env.unwrapped
env.seed(1)
torch.manual_seed(1)#print("env.action_space :", env.action_space)#print("env.observation_space :", env.observation_space)
n_features = env.observation_space.shape[0]
n_actions = env.action_space.n
classActorCritic(nn.Module):def__init__(self):super(ActorCritic, self).__init__()
self.data =[]
hidden_dims =256
self.feature_layer = nn.Sequential(nn.Linear(n_features, hidden_dims),
nn.ReLU())
self.fc_pi = nn.Linear(hidden_dims, n_actions)
self.fc_v = nn.Linear(hidden_dims,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)defpi(self, x):
x = self.feature_layer(x)
x = self.fc_pi(x)
prob = F.softmax(x, dim=-1)return prob
defv(self, x):
x = self.feature_layer(x)
v = self.fc_v(x)return v
defput_data(self, transition):
self.data.append(transition)defmake_batch(self):
s_lst, a_lst, r_lst, s_next_lst, done_lst =[],[],[],[],[]for transition in self.data:
s, a, r, s_, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r /100.0])
s_next_lst.append(s_)
done_mask =0.0if done else1.0
done_lst.append([done_mask])
s_batch, a_batch, r_batch, s_next_batch, done_batch = torch.tensor(numpy.array(s_lst),
dtype=torch.float), torch.tensor(
a_lst), torch.tensor(numpy.array(r_lst), dtype=torch.float), torch.tensor(
numpy.array(s_next_lst), dtype=torch.float), torch.tensor(
numpy.array(done_lst), dtype=torch.float)
self.data =[]return s_batch, a_batch, r_batch, s_next_batch, done_batch
deftrain_net(self):
s, a, r, s_, done = self.make_batch()
td_target = r + gamma * self.v(s_)* done
delta = td_target - self.v(s)defcritic_learn():
loss_func = nn.MSELoss()
loss1 = loss_func(self.v(s),td_target)
self.optimizer.zero_grad()
loss1.backward()
self.optimizer.step()defactor_learn():
pi = self.pi(s)
pi_a = pi.gather(1, a)
loss =-torch.log(pi_a)* delta.detach()+ F.smooth_l1_loss(self.v(s), td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
critic_learn()
actor_learn()defmain():
model = ActorCritic()
print_interval =20
score =0.0
avg_returns =[]for n_epi inrange(MAX_EPISODE):
s = env.reset()for t inrange(n_rollout):
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item()
s_next, r, done, info = env.step(a)
model.put_data((s, a, r, s_next, done))
s = s_next
score += r
model.train_net()if n_epi % print_interval ==0and n_epi !=0:
avg_score = score / print_interval
print("# of episode :{}, avg score : {:.1f}".format(n_epi, score / print_interval))
avg_returns.append(avg_score)
score =0.0
env.close()
plt.figure()
plt.plot(range(len(avg_returns)),avg_returns)
plt.xlabel('episodes')
plt.ylabel('avg score')
plt.savefig('./plt_ac.png',format='png')if __name__ =='__main__':
main()
本文转载自: https://blog.csdn.net/weixin_47471559/article/details/124784616
版权归原作者 喜欢库里的强化小白 所有, 如有侵权,请联系我们删除。
版权归原作者 喜欢库里的强化小白 所有, 如有侵权,请联系我们删除。