
Hive
一、数仓的基础概念
1、hive产生的原因
方便对文件及数据的元数据进行管理,提供统一的元数据管理方式。提供更加简单的方式来访问大规模的数据集,使用SQL语言进行数据分析。
2、hive是什么?
Hive是基于Hadoop的一个数据仓库工具,Hive经常被大数据企业用做企业级数据仓库。
Hive在使用过程中是使用SQL语句来进行数据分析,由SQL语句到具体的任务执行还需要经过解释器,编译器,优化器,执行器四部分才能完成。
(1)解释器:调用语法解释器和语义分析器将SQL语句转换成对应的可执行的java代码或者业务代码
(2)编译器:将对应的java代码转换成字节码文件或者jar包
(3)优化器:从SQL语句到java代码的解析转化过程中需要调用优化器,进行相关策略的优化,实现最优的查询性能
(4)执行器:当业务代码转换完成之后,需要上传到MapReduce的集群中执行
3、数据库、数据仓库、数据集市的区别
数据仓库是为了分析数据而来,分析结果给企业决策提供支撑。
企业中,信息总是用作两个目的:
1、操作型记录的保存
联机事务处理系统(OLTP):执行联机事务处理,接收用户数据可立即传送到后台进行处理,并在很短的时间内给处理结果。
关系型数据库(RDBMS)是OLTP典型应用,如:Oracle,MySQL,SQL Server等
OLTP环境开展分析是可以的,但是没有必要


2、分析型决策的制定
面向分析,支持分析的系统称之为OLAP(联机分析处理)系统。
典型应用:数据仓库
基于业务数据开展数据分析,基于分析的结果给决策提供支撑。
3、OLTP和OLAP对比图

4、数据仓库和数据集市的区别
数据仓库(DW)是面向整个集团组织的数据,数据集市是面向单个部门使用的,可以认为数据集市是数据仓库的子集,也有把数据集市叫做小型数据仓库。
二、数据仓库主要特征
1、数据仓库目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)
2、数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;
3、数据仓库自身不需要“消费”任何数据
面向主题、集成性、非易失性、时变性。
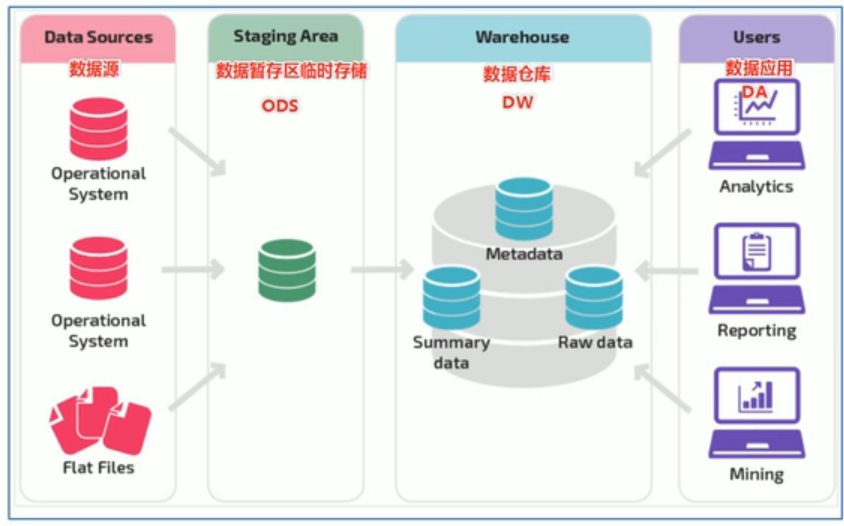
三、数据仓库分层架构
每个企业根据自己的业务需求可以分成不同的层次。但是最基础的分层思想理论上分为三个层:
操作型数据层(ODS):存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。
数据仓库层(DW):数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
数据应用层(DA):数据应用层,面向最终用户,面向业务定制提供给产品和数据分析使用的数据
分层好处:
清晰数据结构:每一层有它的作用域,方便定位和理解
数据血缘追踪:能够快速准确定位问题,清楚危害范围
减少重复开发:规范数据分层,开发一些通用的中间层数据,减少极大的重复计算。
把复杂问题简单化:将一个复杂的任务分解成多个步骤完成,每一层只处理单一的步骤,较为简单和容易理解,便于修复。
屏蔽原始数据的异常:不必改一次业务就需重新接入数据
四、ETL、ELT区别
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL
ETL:首先从数据源池中提取数据,将数据保存在临时暂存数据库中(ODS),然后执行转换为合适目标数据仓库系统的形式,然后将结构化数据加载到仓库中,已备分析。 (先拿数据转换)
ELT:先抽取后立即加载。没有专门的临时数据库(ODS)这意味着数据会立即加载到单一的集中存储库中。数据在数据仓库系统中进行转换,以便于商业智能工具一起使用。大数据时代的数仓这个特点很明显。
五、美团点评酒旅数仓建设实践视频解析(黑马程序员)
09--场景分析案例--美团点评酒旅数仓建设实践_哔哩哔哩_bilibili
版权归原作者 是晨洋呀 所有, 如有侵权,请联系我们删除。