
一.RDD的分区
RDD的分区原则是分区的个数尽量等于集群中的CPU核心(Core)数目。
各种模式下的默认分区数目如下
(1) Local****模式:默认为本地机器的CPU数目,若设置了local[N].则默认为N.
(2) Standalone****或者Yarn模式:在“集群中所有CPU核数总和"和“2”这两者中取较大值作为默认值。
**(3) Mesos **模式:默认的分区数是8.
Spark****框架为RDD提供了两种分区方式,分别是哈希分区(HashPartitioner)和范围分区(RangePartitioner)。
Spark****也支持自定义分区方式,即通过一个自定义的Partitioner对象来控制RDD的分区,从而进一步减少通信开销。
如果想要实现自定义分区,就需要定义一个类,使得这个自定义的类继承org. apache. spark. Partitioner类,并实现其中的3个方法,具体如下:
**(1) def numPartitions:Int:**用于返回创建的分区个数。
**(2) def getPartition(Key:Any):**用于对输人的Key做处理,并返回该Key的分区ID, 分区ID的范围是0~ numPartitions 1.
**(3) equals (other: Any):**用于Spark判断自定义的Partitioner 对象和其他的 Partitioner对象是否相同,从而判断两个RDD的分区方式是否相同。
二.RDD的依赖关系
RDD****之间具有依赖的关系。
RDD****与它所依赖的RDD的依赖关系有两种类型,分别是
窄依赖(narrow dependency)****和宽依赖(wide dependency)。
**窄依赖是指父RDD的每一个分区最多被一个子RDD的分区使用,即OneToOneDependencies。窄依赖的表现一般分为两类:第一类表现为一个父RDD的分区对应于一个子RDD的分区;第二类表现为多个父RDD的分区对应于一个子RDD的分区,也就是说,一个父RDD的一个分区不可能对应一个子RDD的多个分区。 **
当RDD执行map、filter、union、和join操作时,都会产生窄依赖。
**宽依赖是指子RDD的每一个分区都会使用所有父RDD的所有分区或多个分区,即One ToManyDependecies。(当RDD进行groupByKey和join操作时,会产生宽依赖) **
join****算子操作既可以属于窄依赖,也可以属于宽依赖。当join算子操作后,分区数量没有变化则为窄依赖(如join with inputs co partitioned,输人协同划分);当join算子操作后,分区数量发生变化则为宽依赖(如join with inputs not corpartitioned,输人非协同划分)。
三.RDD机制
Spark****为RDD提供了两个重要的机制,分别是特久化机制(即缓存机制)和容错机制。
RDD****是采用惰性求值(即每次调用行动算子操作,都会从头开始计算)
RDD****的持久化操作有两种方法,分别是cache()方法和persist()方法。
①persist()方法的存储级别是通过StorageLevel对象(Scala Java、Python)设置的。
②cache()方法的存储级别是使用默认的存储级别(即StorageLevel. MEMORY ONLY(将反序列化的对象存人内存))。
** **持久化RDD的存储级别
MEMORY_ ONLY
默认存储级别。将RDD作为反序列化的Java对象,缓存到JVM中,若内存放不下(内存已满情况),则某些分区将不会被缓存,并且每次需要时都会重新计算
MEMORY_AND_DISK
将RDD作为反序列化的Java对象,缓存到JVM中,若内存放不下(内存已满情况),则将剩余分区存储到磁盘上,并在需要时从磁盘读取
MEMORY_ONLY_SER
将RDD作为序列化的Java对象(每个分区序列化为一个字节数组),比反序列化的Java对象节省空间,但读取时更占CPU
MEMORY_AND_DISK_SER
与MEMORY ONLY SER类似,但是当内存放不下时则溢出到磁盘,而不是每次需要时重新计算它们
DISK_ONLY
仅将RDD分区全部存储到磁盘上
MEMORY_ONLY_2 MEMORY_AND_DISK_2
与上面的级别相同。若加上后缀2,代表的是将每个持久化的数据都复制一份副本,并将副本保存到其他节点上
**OFF_HEAP(**实验性)
与MEMORY ONLY SER类似,但将数据存储在堆外内存中(这需要启用堆外内存)
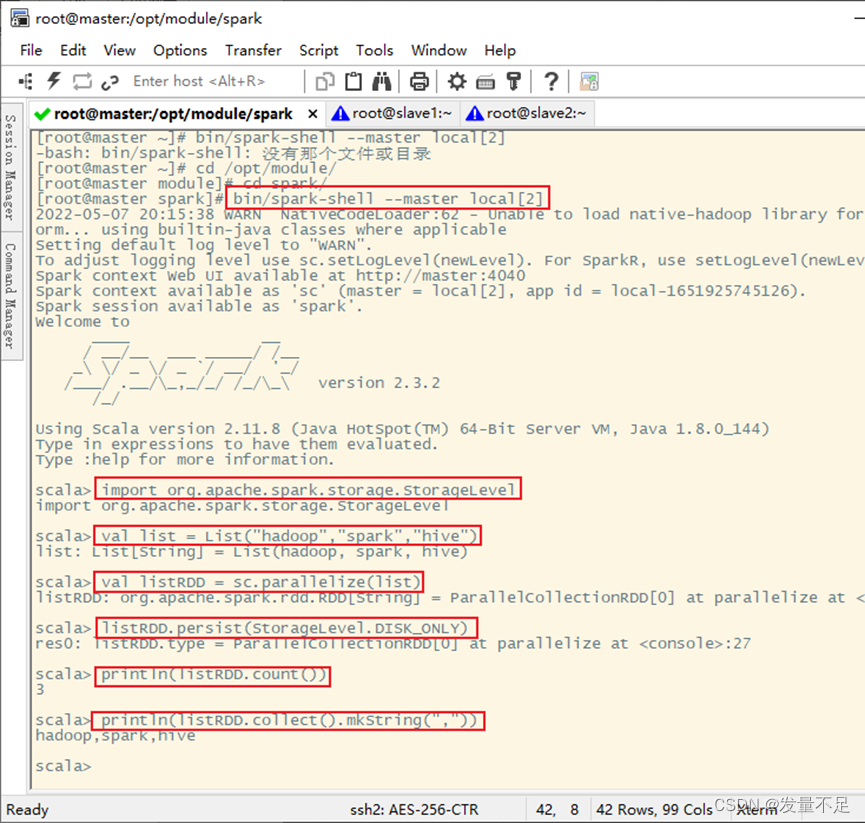
1、使用persist()方法对RDD进行持久化
定义一个列表list,通过该列表创建一个RDD,然后通过persist持久化操作和算子操作统计RDD中的元素个数以及打印输出RDD中所有的元素。
代码:
import org.apache.spark.storage.StorageLevel
val testlist = List("hadoop","Python","Spark","Java")
val listRDD = sc.parallelize(testlist)
listRDD.persist(StorageLevel.DISK_ONLY)
println(listRDD.count())
println(listRDD.collect().mkString(","))
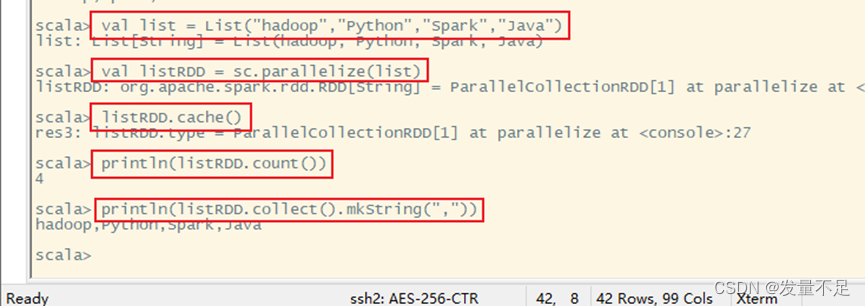
2、使用cache()方法对RDD进行持久化
代码:
val list = List("hadoop","Python","Spark","Java")
val listRDD = sc.parallelize(list)
listRDD.cache()
println(listRDD.count())
println(listRDD.collect().mkString(","))
三、容错机制
RDD****提供了两种故障恢复的方式,分别是血统(lineage)方式和设置检查点(checkpoint)方式。
①血统方式,主要是根据RDD之间的依赖关系对丢失数据的RDD进行数据恢复。
②设置检查点方式,本质上是将RDD写人磁盘进行存储。
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。