
一、字段为NULL走不走索引?
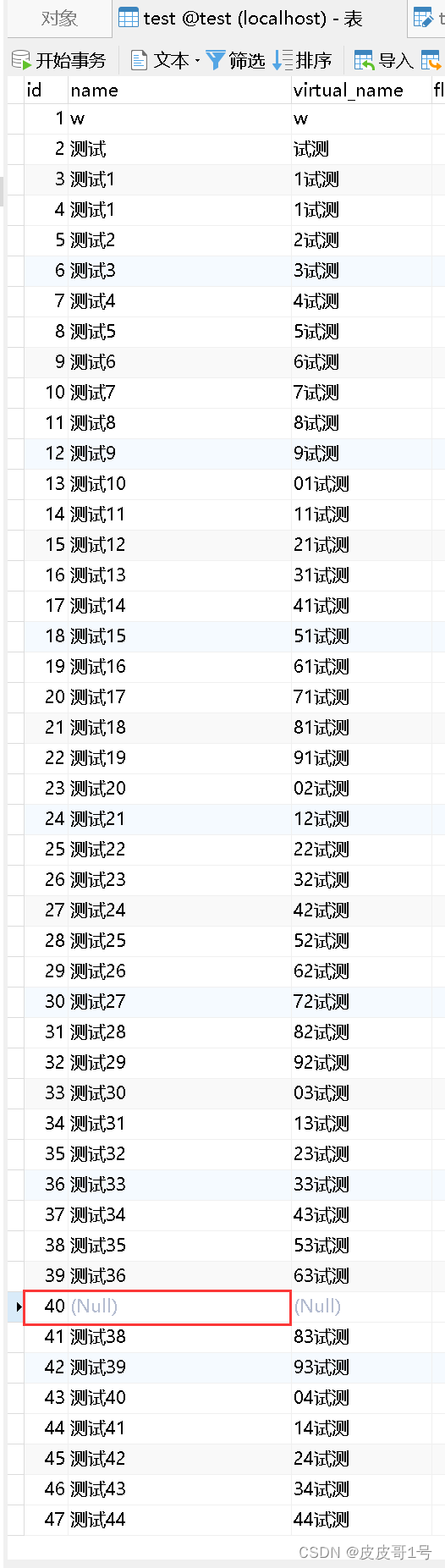
我先在本地建了一张叫test的表,用存储过程插入了一百五十多万的数据,并对code字段和name字段分别加了二级索引idx_code和idx_name。根据字段中null的占比,分两种情况讨论:
1.绝大多数是非NULL
name字段绝大多数都是非NULL,如下图所示。
(1)sql为:select * from test where name is null
用explain查看执行计划,如下图所示:
可看出,即使用了is null的查询条件,也是走了索引的;
(2)sql为:select * from test where name is not null
用explain查看执行计划,如下图所示:

可看出,is not null的查询条件,却没有走索引;
2.绝大多数是NULL
code字段绝大多数都是NULL,如下图所示。

(3)sql为:select * from test where code is not null
用explain查看执行计划,如下图所示:

可看出,is not null的查询条件,走了索引;
(4)sql为:select * from test where code is null
用explain查看执行计划,如下图所示:

可看出,is null的查询条件,竟然走了索引(下面讲原因);
总结:
对以上现象进行总结,可看出对于建了二级索引的字段:
(1)若绝大多数行都是非null, 则查询is null 走二级索引; (2)查询is not null走全表扫描;(3)相反,若绝大多数行都是null,则查询is not null走索引;(4)而is null 也走索引;
(1)、(2)、(3)的原因是:优化器认为,若按查询条件进行,扫描的行记录占总行记录数的比例太大,成本太高,则不走索引;相反,这个占比很小,则成本低,走索引。
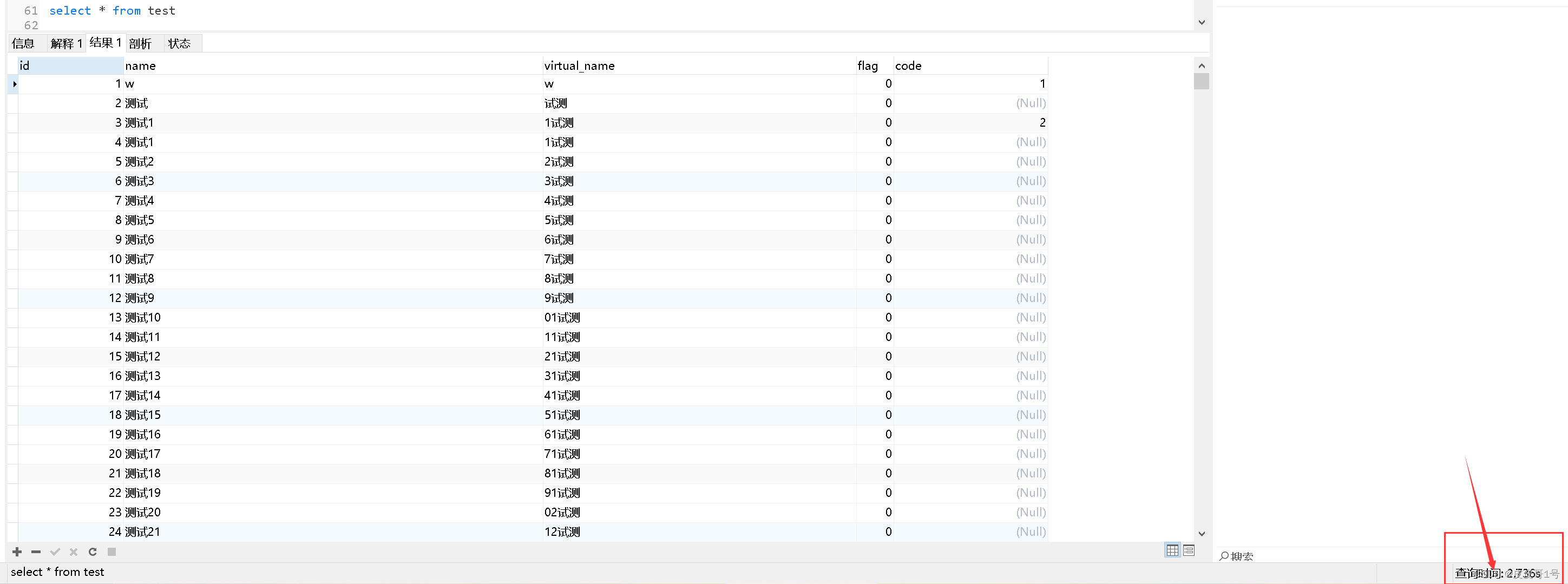
(4)的原因是:优化器统计错rows了(rows是一个估算值,在本例中,此rows相当不准),因此它认为若走idx_code索引,扫描的行记录数只有754715,大致是全表的一半(全表有一百五十万的数据),成本更低,所以它选择了走索引。其实经测试,走了索引,运行select * from test where code is null的时间为8.986s;而全表扫描,即运行select * from test的时间只有2.736s,时间还短些。
因此得出最终结论:走不走索引,还得看优化器自己算的成本;有时优化器会算错,即使走索引,时间比全表扫描还要长!

原理分析:
(1)null在B+树是如何存放的?
因为主键索引的键值必定不为null,所以讨论的索引都是二级索引。首先B+树最底层是叶子节点,叶子节点间由双向链表组织。叶子节点由行记录组成,行记录间由单向链表组织,且行记录是按二级索引的键值从左往右顺序排列的。而在MySQL里null被认为小于任何值,因此键值为null的行记录被排在行记录链表的最左侧,其对应的叶子节点也在所有叶子节点里的最左侧。
(2)如何识别null?
行记录的结构里,有NULL标识字段。若一行记录的某列值为null,则会被该标识标志。
(3)整个查找过程
首先在B+树里根据二叉查找法找到第一个键值为null的叶子节点(其实就是在所有叶子节点的最左端),到里面找到第一个键值为null的行记录。再根据第(1)点的链表从左往右挨个查找,直到不为键值null为止。到此,可以统计所有的键值为null的行记录数。
(4)为什么说有时走了二级索引还不如全表扫描?
** **上文提到过,根本原因在于成本!二级索引的叶子结点里,键是二级索引键值,值是主键值;因此用到select * 这样的想查所有字段的sql,还得通过二级索引定位到主键索引的具体行记录(回表);若扫描二级索引行记录数过多,则回表次数也更多,还不如直接全表扫描(扫描所有的主键索引的行记录)的成本低。
二、limit走不走索引?
1.介绍:
以select * from table_1 order by name limit 5000,1为例,table1表有一百五十多万数据,在name上建了二级索引。
此sql中有order by,二级索引的键值本身就是排序的,所以order by 的原理很好理解。
其执行过程如下,以此分析**limit的原理**:
a) 存储引擎层找在name二级索引找到第一条记录后,因为select * 要查所有字段的原因,得回表查询主键索引的记录,然后将其返回给server层。
b) server层发现有limit 5000,1要求,就脑残地让存储引擎执行a)步骤5000次,直到找到那第5001条数据。
2.总结:
存储引擎层并不是一次性到位地跳到第5001条行记录,而是逐个返回5001条行记录给server层。太憨了!这意味着要查询二级索引记录5001次,同时回表5001次!
3.案例及优化:
(1)优化器认为:范围较小,走二级索引可以接受,因为只需扫描5001条二级索引记录、回表5001次!走索引!
sql:select * from table_1 order by name limit 5000,1
运行时间:0.019s

(2)优化器认为:范围较大,走二级索引不可以接受,因为要扫描10001条二级索引记录、回表10001次!还不如直接走全表扫描10001条主键索引的行记录!不走索引!但全表扫描指的是扫描主键索引的所有行记录,代价仍然很大,因此查询效率很低!
sql:select * from table_1 order by name limit 10000,1
运行时间:4.5s

(3)人为地强制用索引,扫描10001条二级索引记录、回表10001次!
sql:select * from table_1 force index(idx_name) order by name limit 10000,1
运行时间:0.022s

(4) 最优解:用子查询的方式,更省时间!
sql:select * from table_1, (select id from table_1 order by name limit 5000, 1) as d
where table_1.id = d.id;
运行时间:0.015s, 比上面的都要短
过程分析:
a)先用子查询,在二级索引上扫描10001条行记录。因为是select id,id可直接在二级索引叶子节点里找出来,无需回表。这些行记录可直接返回给server层;
b)server层取得第10001条二级索引行记录后,再向存储引擎层讨要对应的主键索引的行记录;
c)存储引擎层回表主键索引,向server层返回第10001条行记录。
简而言之,二级索引扫描记录数仍是10001条,但回表只需要回1次!

其他判断走不走索引的场景,以后再补充,因为写博客好花时间喽~~~~
版权归原作者 皮皮哥1号 所有, 如有侵权,请联系我们删除。