
文章目录
1. 虚拟机的安装
1.1 下载VMware Workstation
VM16pro百度网盘下载地址:链接:https://pan.baidu.com/s/1Lvijuq8CBb6yil-WGukYjw 提取码:if1n
VM官方下载地址:https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html
选择windows或者linux进行下载: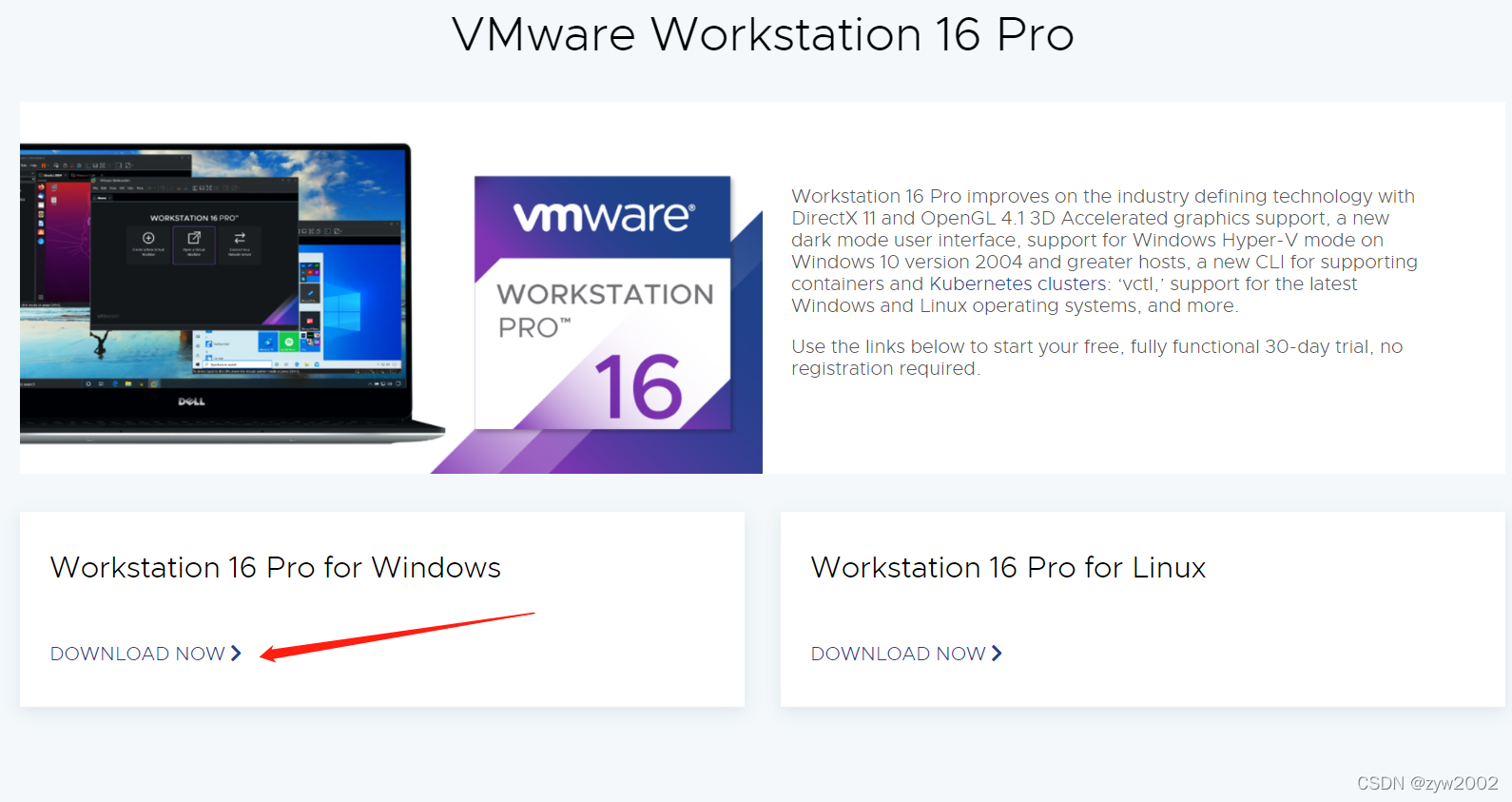
1.2 下载ubantu20.04
ubuntu20.04百度网盘下载链接:https://pan.baidu.com/s/1p2OwVDZ16H-Jh4NKCl4Vgw 提取码:8qjx
ubuntu 20.04.4LTS 官网下载地址:https://ubuntu.com/download/desktop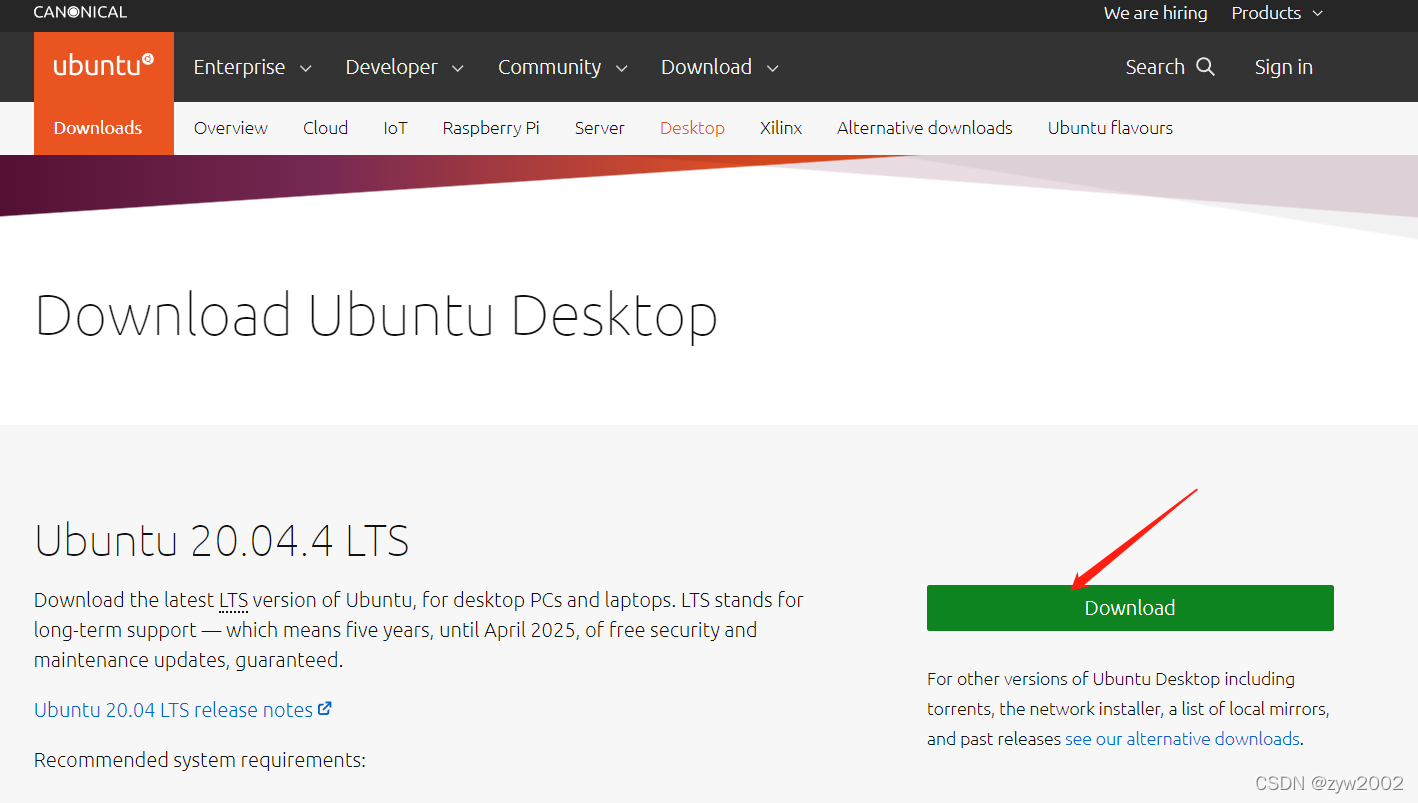
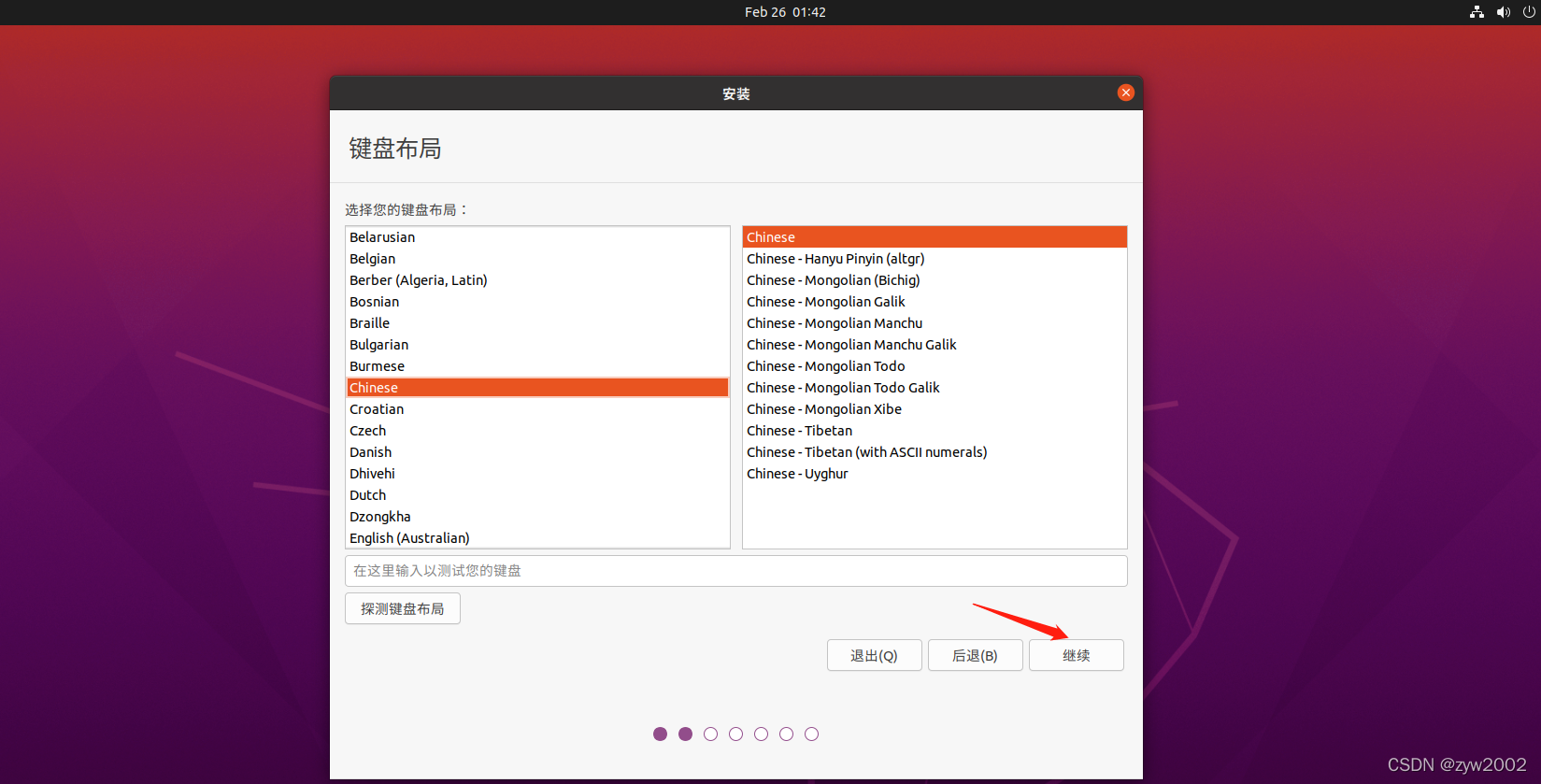
1.3 安装一台虚拟机


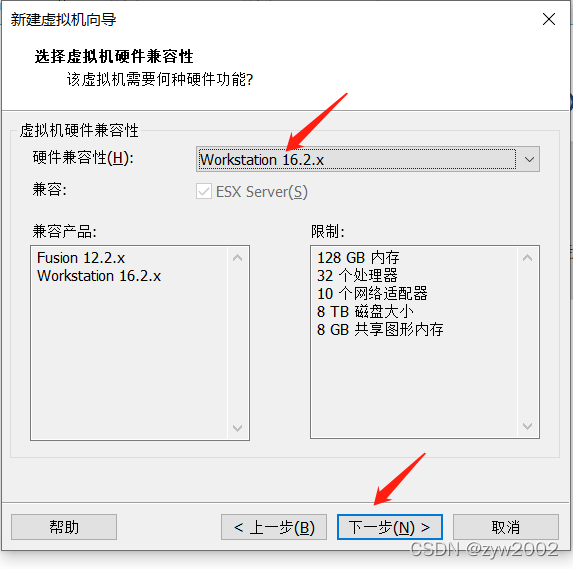
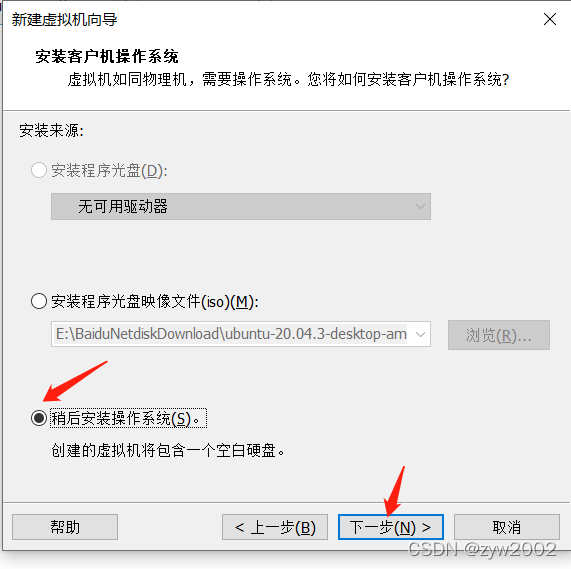
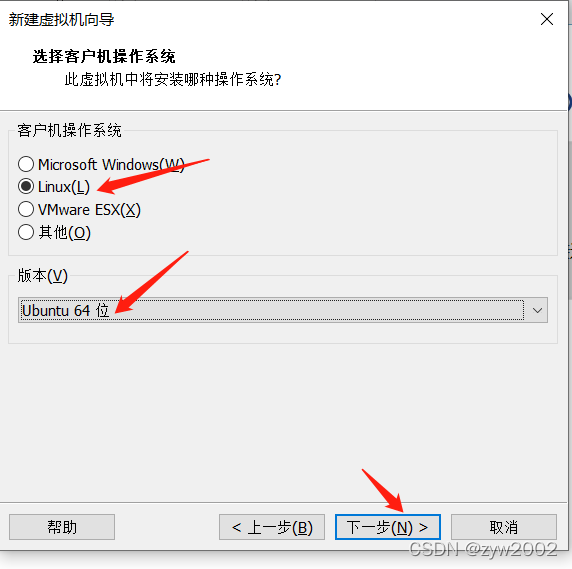
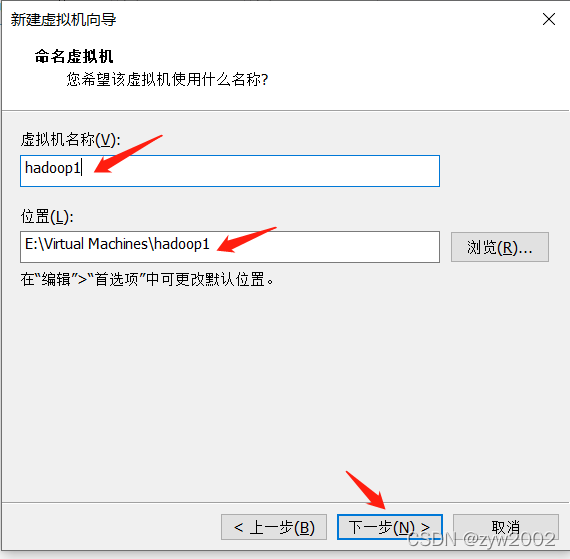

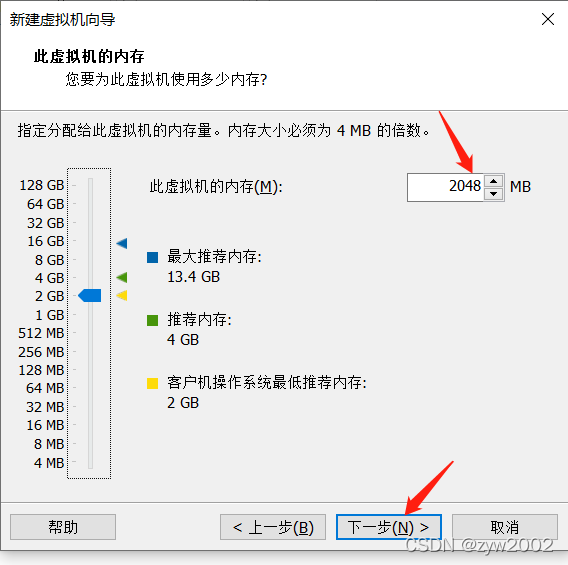
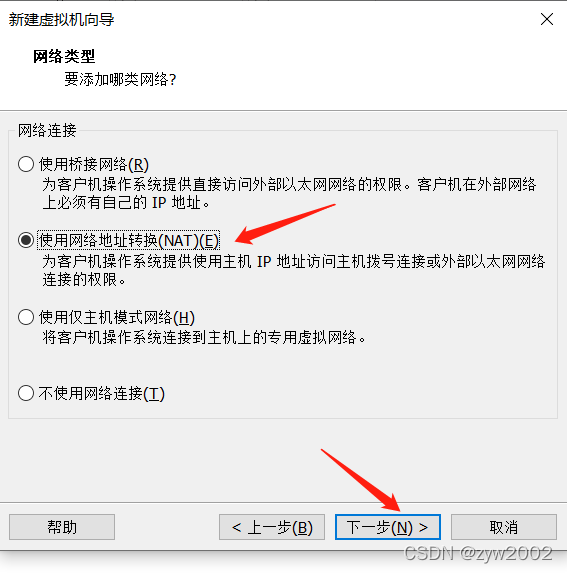
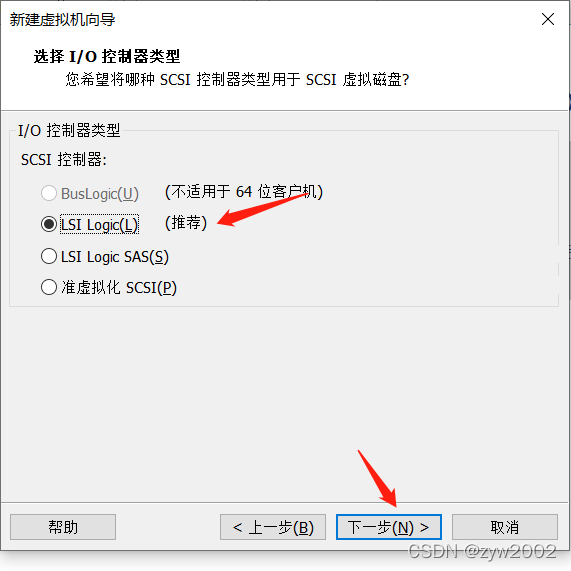
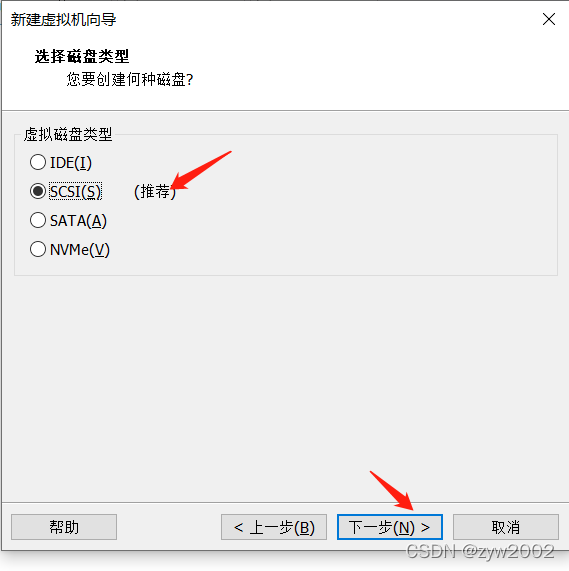
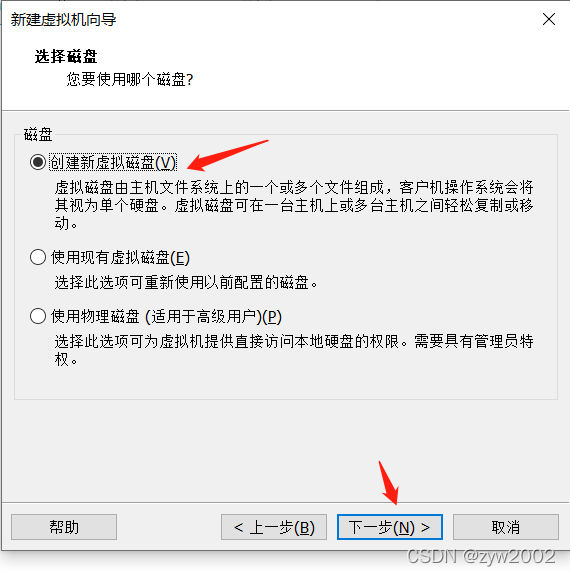
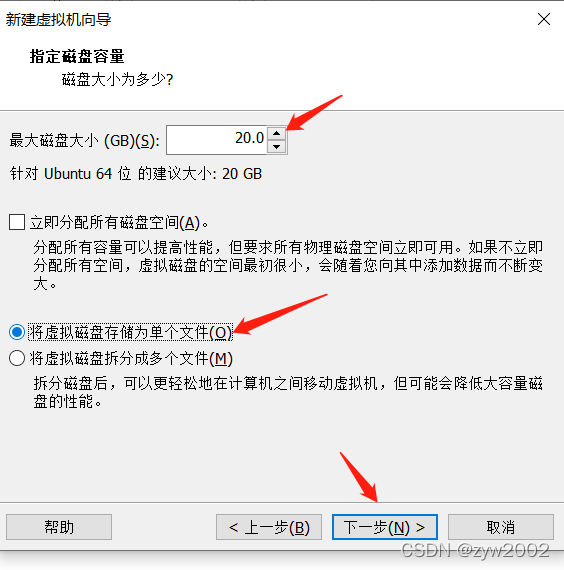
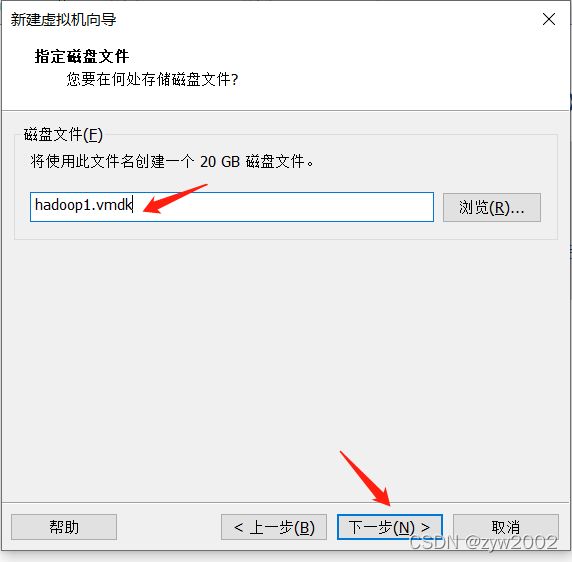
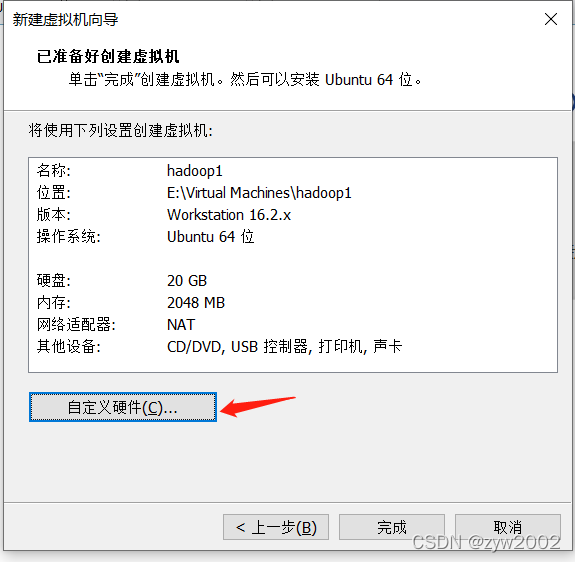
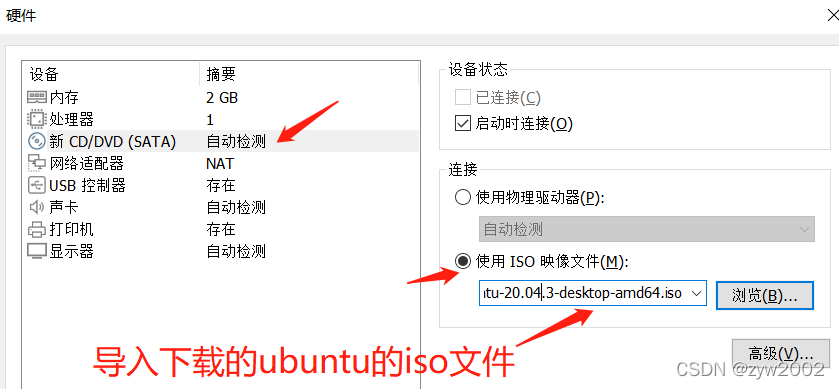
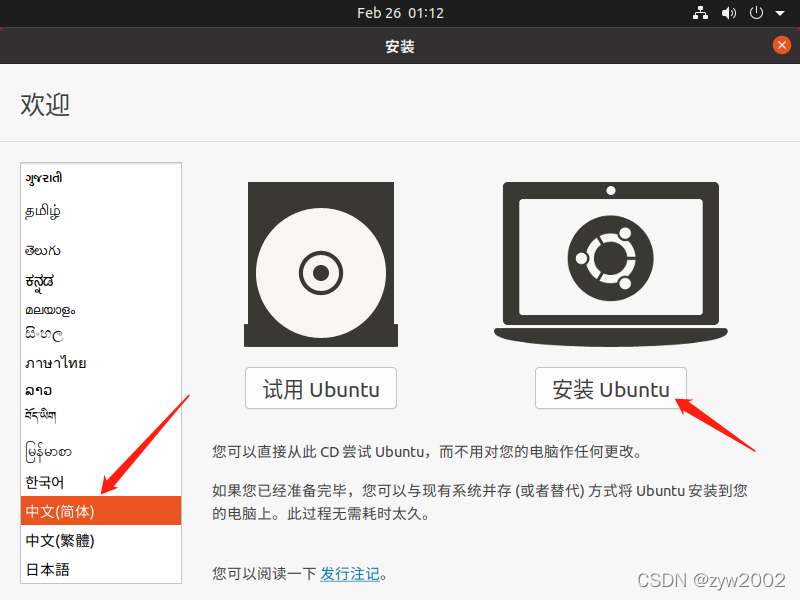
找不到下一步
接下来就会进入安装导航,一般这时界面很小,往往会找不到安装的下一步按钮。这时候有两种方法可以解决:
【方法1】
alt
+鼠标拖动界面
【方法2】如果方法1 无法解决,则我们可以直接改变屏幕的分辨率。
alt+ctrl+T
打开终端,输入
xrandr
查看支持的分辨率大小。然后右键copy
1680x1050
(方便下一条命令时输入)
然后改变分辨率的大小,终端输入
xrandr - s 1680x1050
, 然后关闭终端。
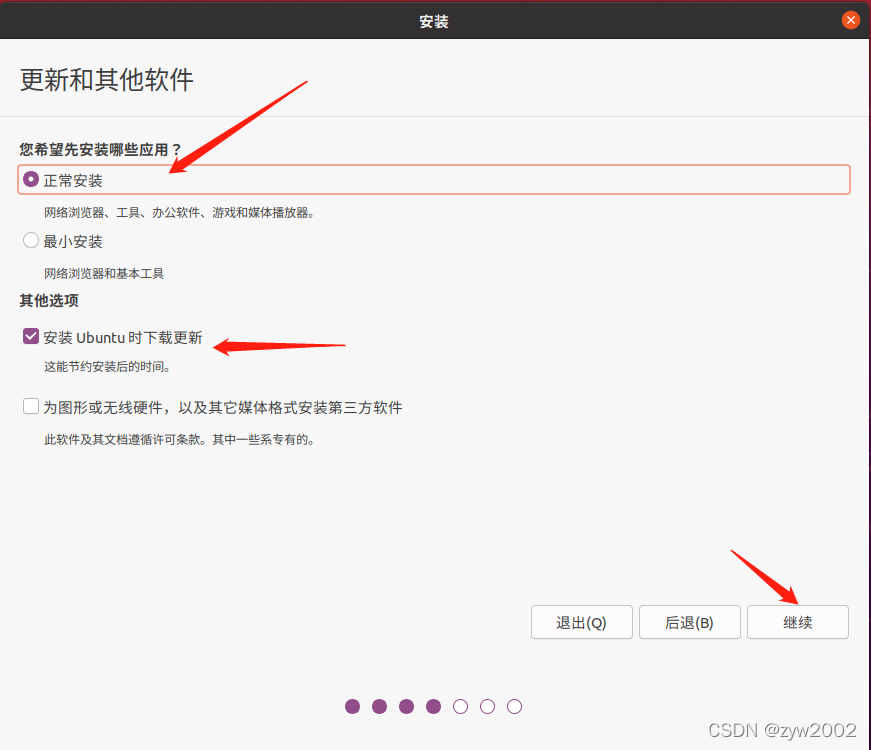

用户名可以随便起,但是要记住,因为后面的一些安装路径会用上。为了辨识三台主机,建议该主机名为hadoop1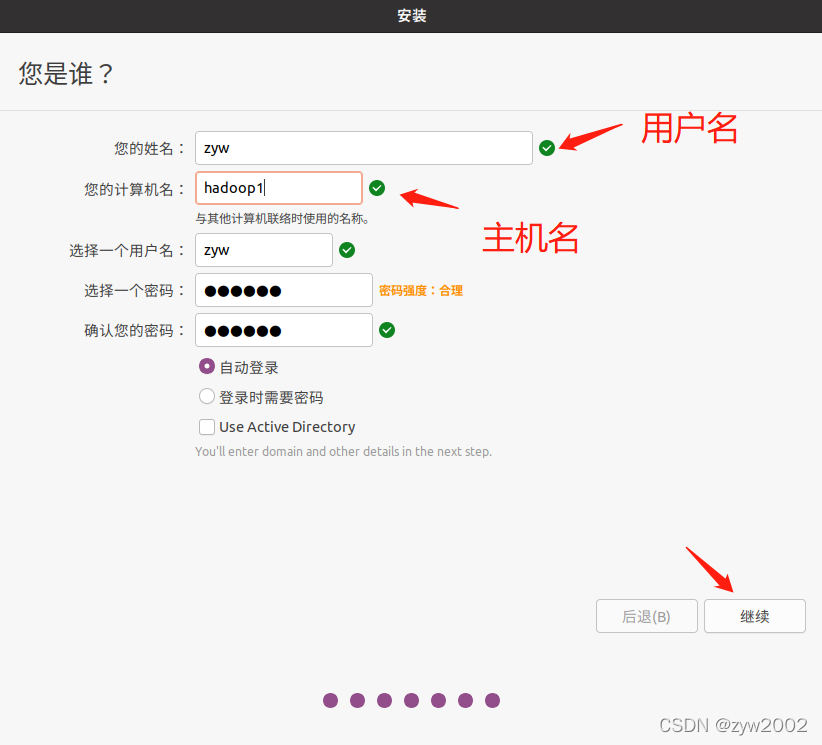
然后等待安装,最后重启后,按enter键。
1.4 安装Vmware Tools
安装VMwareTools方便真机和虚拟机之间传输文件(鼠标直接拖拽),以及复制粘贴(真机
ctrl+C\ctrl+V
, 虚拟机
ctrl+shift+C\ctrl+shift+V
)
ctrl+atrl+T
打开终端输入如下命令
sudo apt upgrade
sudo apt install open-vm-tools-desktop -y
sudo reboot
2. 网络配置
首先可以先ping 一下外网,测试联网情况
ping www.baidu.com
ping不通,域名解析失败。因为缺少inet地址(即ipv4的ip地址)
2.1 添加权限
我们创建的普通用户权限不足,不能修改网络配置信息,要先为普通用户赋予root权限,这需要切换到root用户下。首先为root用户设置一个密码并切换到root用户
sudo passwd root
su root
为用户增加权限, sudo命令不用密码
vi /etc/sudoers
然后添加一行 (输入
i
进入插入模式)
用户名 ALL=(ALL:ALL) ALL
修改一行
%sudo ALL=(ALL:ALL) NOPASSWD:ALL
然后保存退出(
shift+:
进入底行模式,然后输入
wq!
强制保存退出)
2.2 DHCP动态分配IP地址
sudo dhclient -v
这种方式可以正常ping通外网,但是有个弊端,每次重启虚拟机的时候,都要再次执行上面的指令
2.3 配置静态IP地址
点击该虚拟机的设置,选择NAT模式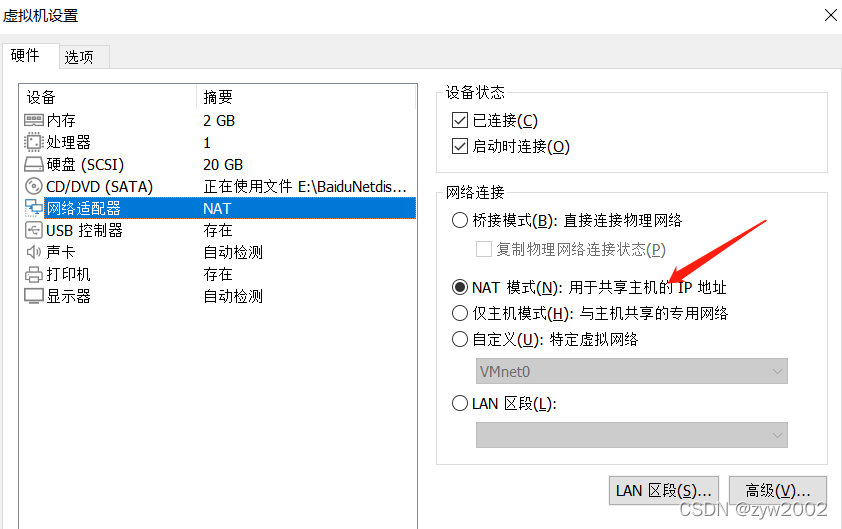
首先在真机上打开cmd,输入
ipconfig
,nat配置对应的是
vmnet8
, 我们需要让虚拟机的IP地址和
192.168.247.1
处于同一个网段下(你的电脑会是192.168.x.1)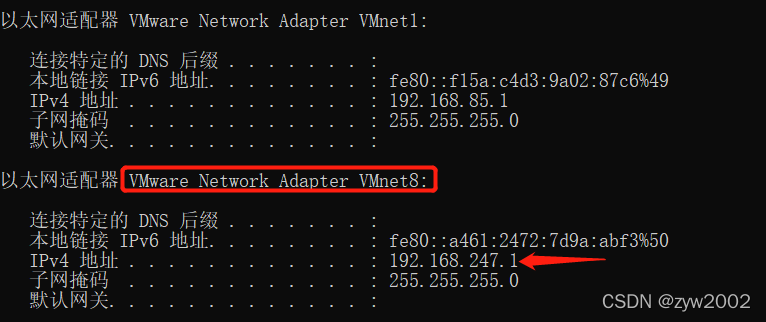
编辑网络配置信息文件
sudo gedit /etc/netplan/01-network-manager-all.yaml
注意不要直接复制粘贴!要修改下面的addresses 和 gateway4(原理参考 )
- 虚拟机ubuntu的ip与上文查到的
192.168.x.1(例如我的是192.168.247.1)处于同一网段即可(例如我的ubuntu可以选择的IP可以是192.168.247.***, 此处我选取的是192.168.247.124) - 此处的
192.168.x.1理解为主机的默认网关,在配置文件中的gateway4:192.168.x.2理解为虚拟机ubuntu的默认网关
network:
ethernets:
ens33:
dhcp4: no
addresses: [192.168.247.124/24]
optional: true
gateway4: 192.168.247.2
nameservers:
addresses: [8.8.8.8,8.8.8.4]
version: 2
renderer: NetworkManager
然后保存并退出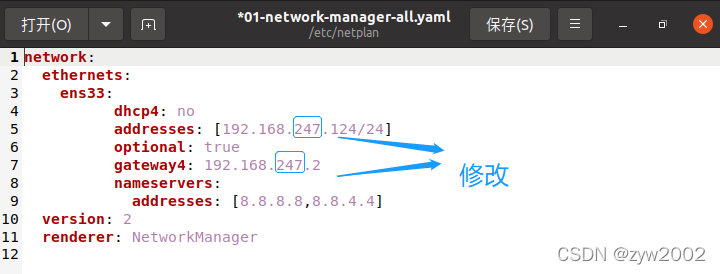
应用新的网络配置
sudo netplan apply
查看ip
ip addr
IP地址固定成功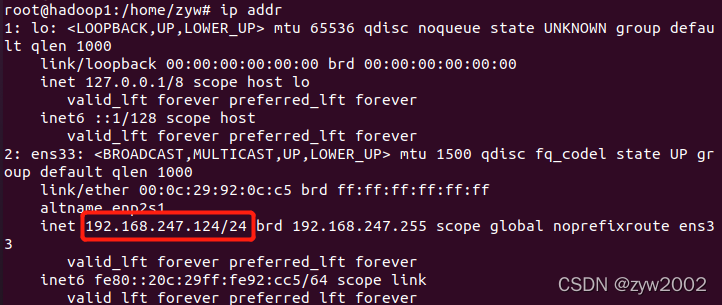
测试联网情况
ping www.baidu.com

2.4 主机名和IP地址映射
sudo gedit /etc/hosts
注释
#127.0.1.1 hadoop1
添加
注意不要直接复制粘贴,此处要修改第三段数字(你的不一定是247)
192.168.247.124 hadoop1
192.168.247.125 hadoop2
192.168.247.126 hadoop3
然后保存并退出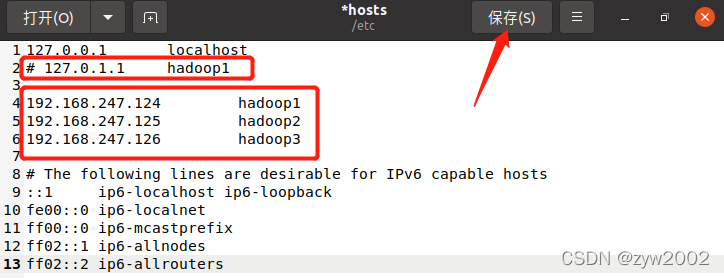
3. 安装必要工具
3.1 安装SSH
安装ssh-server 和 ssh-client
sudo apt-get install openssh-server
修改 /etc/ssh/sshd_config 文件
gedit /etc/ssh/sshd_config
将
PermitRootLogin prohibit-password
改为
PermitRootLogin yes
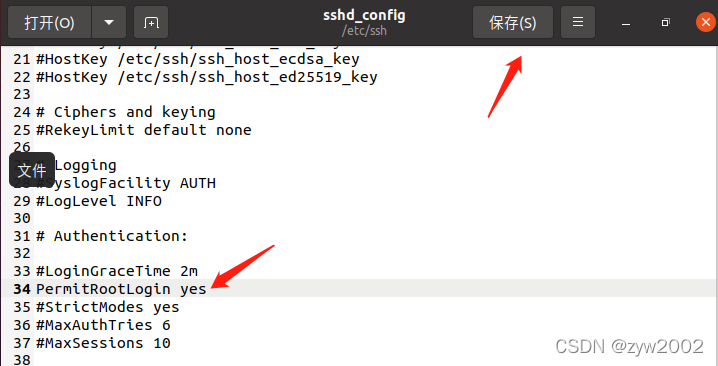
保存后重启ssh服务
3.2 安装JDK
参考:https://blog.csdn.net/weixin_38924500/article/details/106261971
安装openjdk-8-jdk
sudo apt-get install openjdk-8-jdk
查看java版本,看看是否安装成功
java -version

3.3 安装Mysql
安装mysql
#命令1 更新源
sudo apt-get update
#命令2 安装mysql服务
sudo apt-get install mysql-server
初始化设置
sudo mysql_secure_installation
#1
VALIDATE PASSWORD PLUGIN can be used to test passwords...
Press y|Y for Yes, any other key for No: N (选择N ,不会进行密码的强校验)
#2
Please set the password for root here...
New password: (输入密码)
Re-enter new password: (重复输入)
#3
By default, a MySQL installation has an anonymous user,
allowing anyone to log into MySQL without having to have
a user account created for them...
Remove anonymous users? (Press y|Y for Yes, any other key for No) : N (选择N,不删除匿名用户)
#4
Normally, root should only be allowed to connect from
'localhost'. This ensures that someone cannot guess at
the root password from the network...
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : N (选择N,允许root远程连接)
#5
By default, MySQL comes with a database named 'test' that
anyone can access...
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : N (选择N,不删除test数据库)
#6
Reloading the privilege tables will ensure that all changes
made so far will take effect immediately.
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : Y (选择Y,修改权限立即生效)
检查mysql 服务状态
systemctl status mysql.service
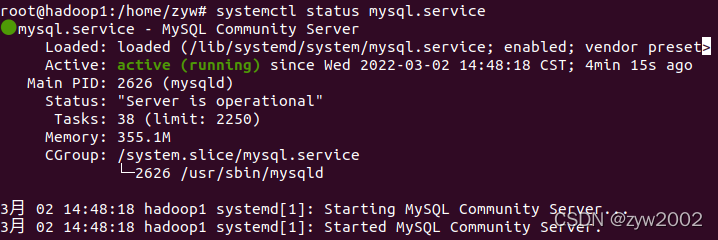
配置环境变量
vi /etc/profile
添加
export MYSQL_HOME=/usr/share/mysql
export PATH=$MYSQL_HOME/bin:$PATH
刷新环境变量
source /etc/profile
启动和停止mysql服务
#停止
sudo service mysql stop
#启动
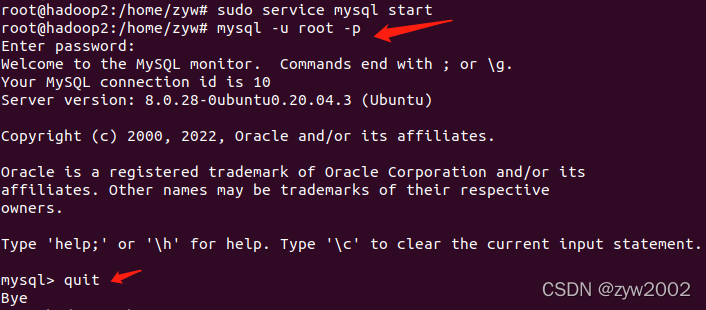
sudo service mysql start
进入mysql 数据库
mysql -u root -p
更多mysql相关操作:https://blog.csdn.net/weixin_38924500/article/details/106261971
3.4 安装ZooKeeper
ZooKeeper3.4.6 下载链接:https://pan.baidu.com/s/1gRfYdOTMJF4UMP3_JD9VWA
提取码:2nd8
将下载的安装包移动到
/opt
目录下
mv zookeeper-3.4.6.tar.gz /opt
解压
cd /opt
tar -zxvf zookeeper-3.4.6.tar.gz
在conf中新建zoo.cfg文件
cd /opt/zookeeper-3.4.6/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
添加如下内容
# 客户端心跳时间(毫秒)
tickTime=2000
# 允许心跳间隔的最大时间
initLimit=10
# 同步时限
syncLimit=5
# 数据存储目录
dataDir=/opt/zookeeper-3.4.6/tmp
# 端口号
clientPort=2181
# 集群节点和服务端口配置
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
注:
dataDir 是缓存数据路径
2888为组成zookeeper服务器之间的通信端口,3888为用来选举leader的端口
新建zookeeper缓存数据目录
mkdir tmp
同步到hadoop2 和hadoop3
xsync /opt/zookeeper-3.4.6/
然后分别在三台虚拟机上执行如下操作:
添加环境变量
vi /etc/profile
最下面加上两行
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH
刷新环境变量
source /etc/profile
在hadoop1上执行
cd /opt/zookeeper-3.4.6/tmp
touch myid
echo 1 > myid
在hadoop2上执行
cd /opt/zookeeper-3.4.6/tmp
touch myid
echo 2 > myid
在hadoop3上执行
cd /opt/zookeeper-3.4.6/tmp
touch myid
echo 3 > myid
在三台虚拟机上启动zookeeper
cd /opt/zookeeper-3.4.6/bin
./zkServer.sh start
hadoop1启动成功
hadoop2启动成功
hadoop3启动成功
在三台虚拟机上查看节点状态
./zkServer.sh status



从上面的执行结果可以看出,zookeeper集群已经启动成功了。
3.6 安装Hadoop
【下载方法1】
百度网盘下载hadoop3.2.2:https://pan.baidu.com/s/1rX9aAkKzh-VTFtWAf3gurg 提取码:lc6x
【下载方法2】
hadoop 官网下载地址
下载hadoop3.2.2 安装包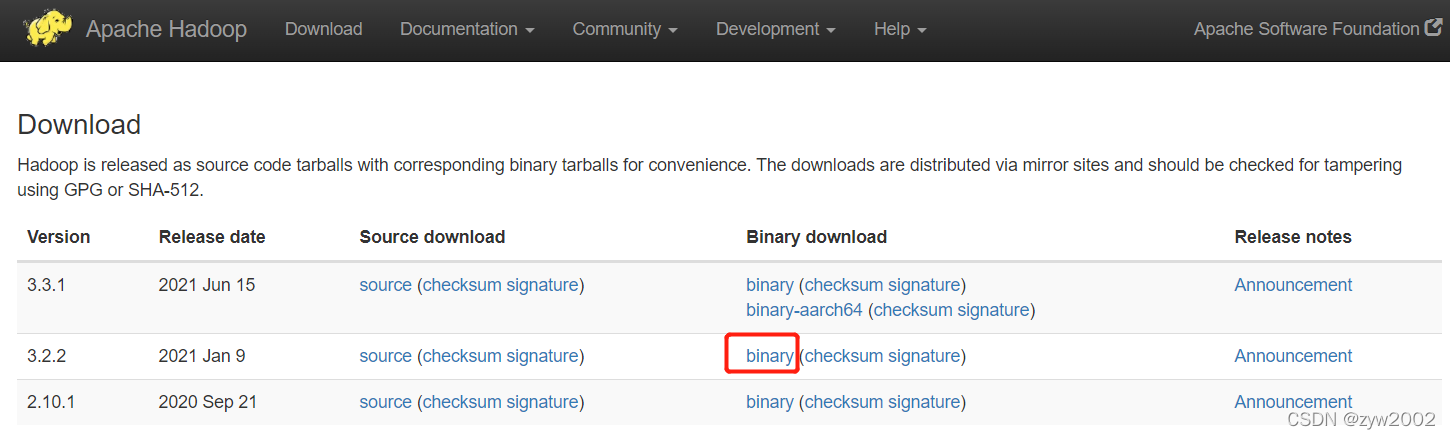

wget https://dlcdn.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz

解压
tar xzf hadoop-3.2.2.tar.gz
先切换到用户目录下(zyw是我、的用户名),添加环境变量
cd /home/zyw
sudo vi .bashrc
注意不要直接粘贴,修改HADOOP_HOME的路径(zyw是我的用户名)
#Hadoop Related Options
export HADOOP_HOME=/home/zyw/hadoop-3.2.2
export HADOOP_INS、TALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/nativ"
保存并退出
配置生效 (添加完成后一定不要忘记这个)
source .bashrc
修改环境变量
gedit ~/.profile
在末尾添加
# hadoop
export HADOOP_HOME=/home/zyw/hadoop-3.2.2
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source .profile
修改 hadoop-env.sh
不要直接复制粘贴,zyw是我的用户名
gedit /home/zyw/hadoop-3.2.2/etc/hadoop/hadoop-env.sh
在首行添加JAVA_HOME (如果不确定自己的JAVA_HOME,先按照后面的方法查看一下)
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/zyw/hadoop-3.2.2
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HDFS_DATANODE_USER=root
export HADOOP_SECURE_DN_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
保存并退出
JAVA_HOME的查看方式
which javac
readlink -f /usr/bin/javac

检查hadoop是否安装成功
hadoop version
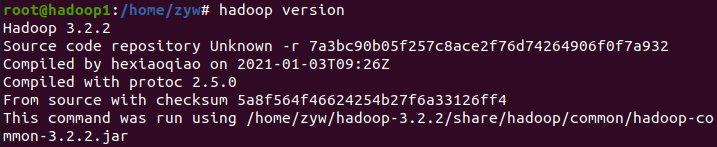
4. 配置相关文件
4.1 修改hadoop 的配置文件
进入配置文件目录(zyw是我的用户名)
cd /home/zyw/hadoop-3.2.2/etc/hadoop/
4.1.1 core-site.xml
新建一个空文件夹
/home/zyw/hadoop-3.2.2/tmp
vi core-site.xml
在<configuration>中添加
不要直接复制粘贴
/home/zyw/tmpdata
是我在本地新建的一个空目录
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 告诉 NN 在那个机器,NN 使用哪个端口号接收客户端和 DN 的RPC请求-->
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zyw/hadoop-3.2.2/tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
4.1.2 hdfs-site.xml
新建两个空文件夹
/home/zyw/hadoop-3.2.2/hdfs/name
/home/zyw/hadoop-3.2.2/hdfs/data
编辑 hdfs-site.xml
vi hdfs-site.xml
在<configuration>中添加
不要直接复制粘贴
/home/zyw/dfsdata/namenode
,
/home/zyw/dfsdata/datanode
是我本地创建的目录
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zyw/hadoop-3.2.2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zyw/hadoop-3.2.2/hdfs/data</value>
</property>
</configuration>
4.1.3 mapred-site.xml
gedit mapred-site.xml
在<configuration>中添加并保存
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
4.1.4 yarn-site.xml
gedit yarn-site.xml
在<configuration>中添加并保存
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.webapp.ui2.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
4.1.5 workers
gedit workers
hadoop1
hadoop2
hadoop3
4.2 文件分发和命令传输的脚本文件
在用户目录下创建一个bin目录 (zyw是我的用户名)
cd /home/zyw
mkdir bin
cd bin
4.2.1 xsync
在该目录下创建xsync文件,此脚本用于虚拟机之间通过scp传送文件
gedit xsync
添加内容如下
#!/bin/bash#校验参数是否合法
if(($#==0))thenecho 请输入要分发的文件!exit;fi#获取分发文件的绝对路径
dirpath=$(cd `dirname $1`;pwd -P)
filename=`basename $1`echo 要分发的文件的路径是:$dirpath/$filename#循环执行rsync分发文件到集群的每条机器for((i=1;i<=3;i++))doecho ---------------------hadoop$i---------------------
rsync -rvlt $dirpath/$filename hadoop$i:$dirpathdone
修改权限
chmod 777 xsync
拷贝到系统目录的bin下
sudo cp xsync /bin
4.2.2 xcall
然后在该目录下创建xcall文件,此脚本用于对所有声明的虚拟机进行命令的传输
gedit xcall
添加内容如下
#!/bin/bash#在集群的所有机器上批量执行同一个命令
if(($#==0))thenecho 请输入要操作的命令!exit;fiecho 要执行的命令是$*#循环执行此命令for((i=1;i<=3;i++))doecho --------------------hadoop$i--------------------
ssh hadoop$i$*done
修改权限
chmod 777 xcall
拷贝到系统目录的bin下
sudo cp xcall /bin
5. 配置分布式集群
5.1 虚拟机的克隆
在终端输入命令关闭虚拟机
shutdown -h now
克隆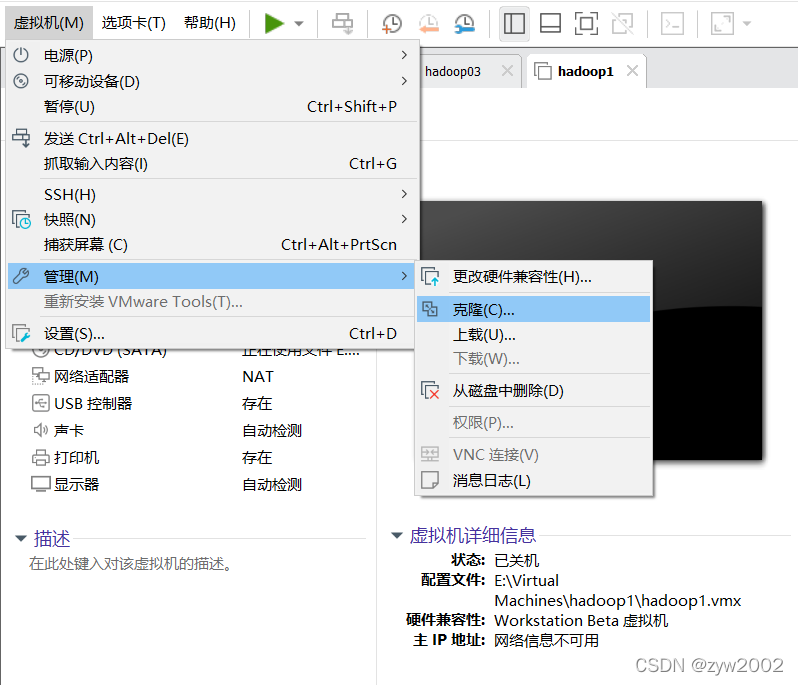
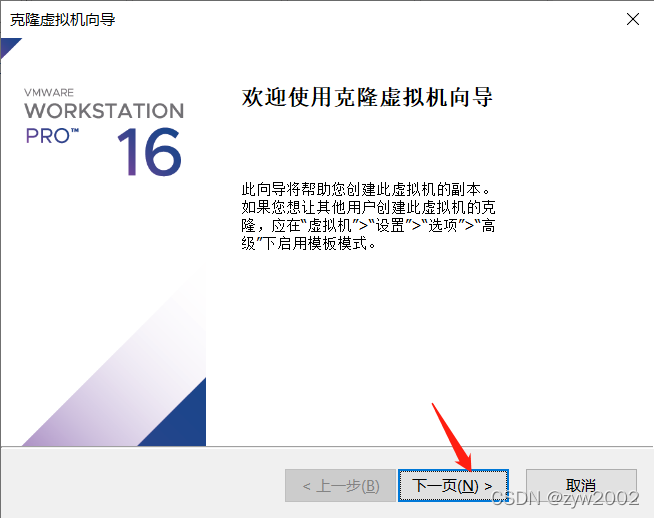
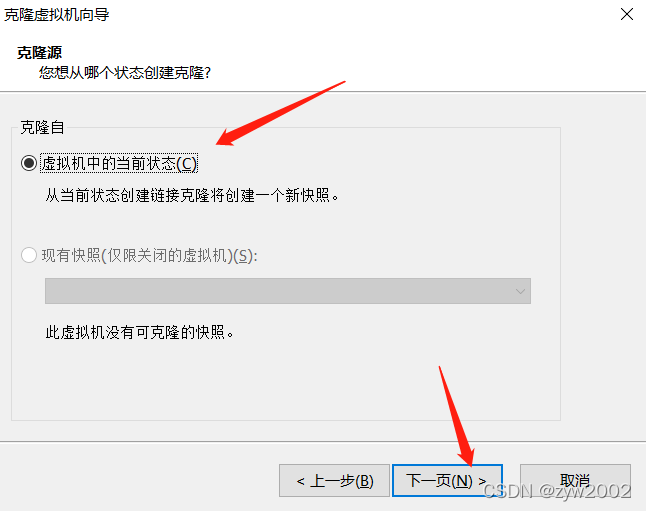
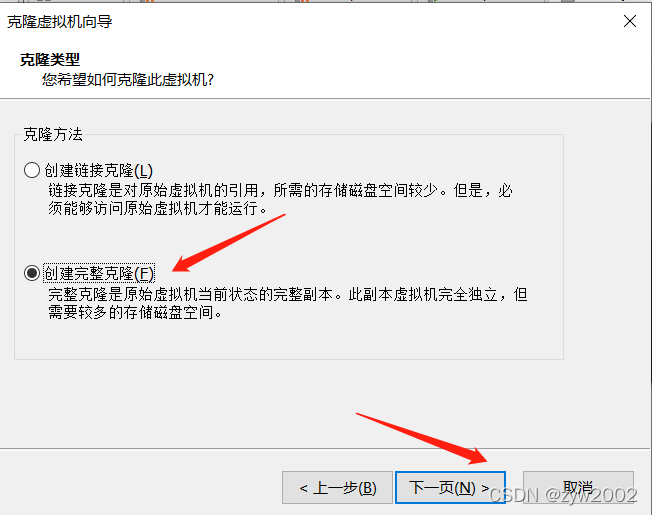
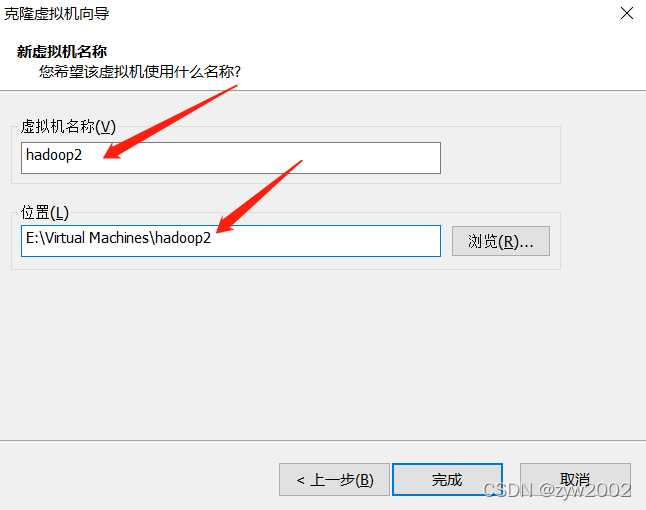
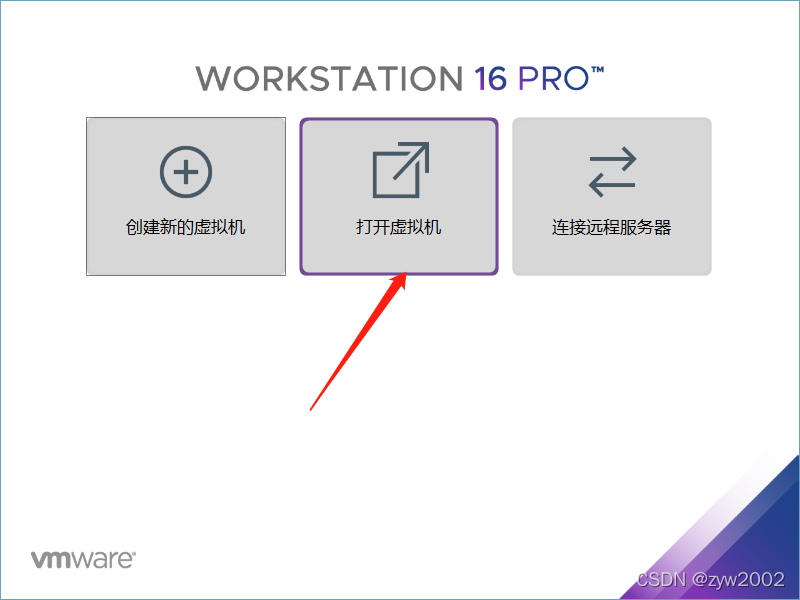
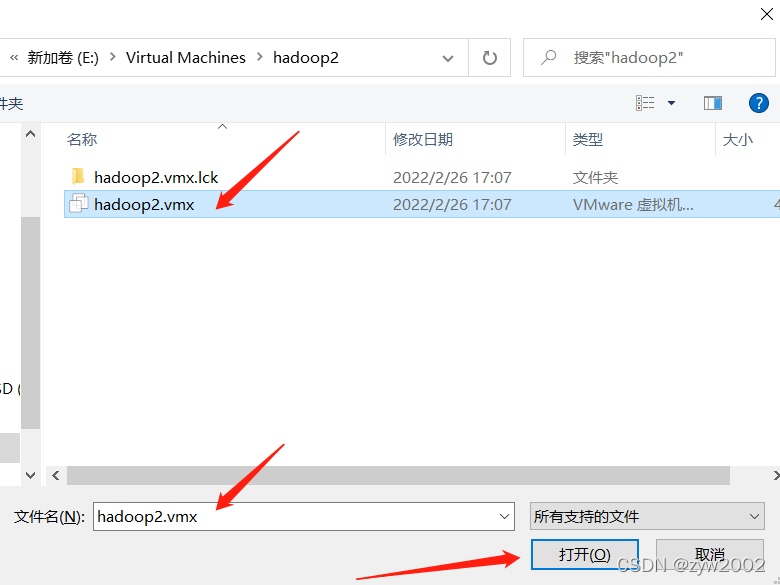
按照上面的步骤再克隆一台hadoop3
5.2 修改主机名
克隆的另外两台主机显示的仍是hadoop1
在两台被克隆的虚拟机上分别修改
sudo gedit /etc/hostname
在hadoop2上:
在hadoop3上:
保存后,关闭当前的终端。然后点击用户文件夹(刷新作用)
重新打开终端,修改成功

5.3 修改网络配置
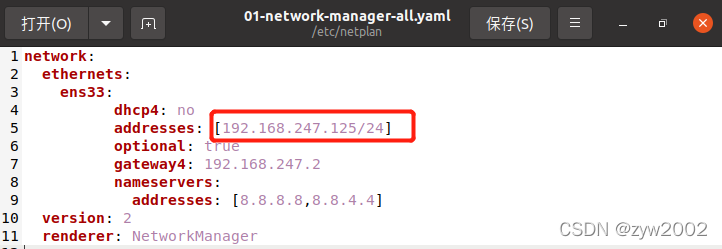
编辑网络配置信息文件
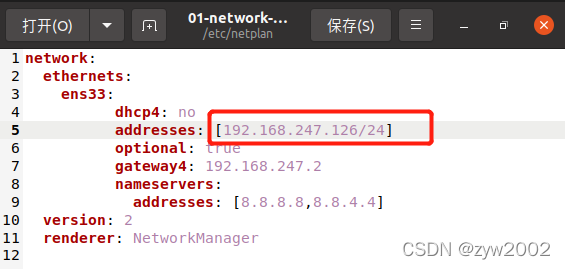
sudo gedit /etc/netplan/01-network-manager-all.yaml
修改IP地址的一行(注意你的ubuntu网段要和真机的网段匹配,比如说我的前三位一定是
192.168.247
最后一位分别是124、125、126)
hadoop2:
addresses: [192.168.x.125/24]
hadoop3:
addresses: [192.168.x.126/24]
不要忘记应用新的网络配置
sudo netplan apply
5.4 配置SSH免密登录
在三台虚拟机上分别执行:
ssh-keygen -t rsa
此处生成rsa密钥,一直回车即可
然后将这三个密钥在三台虚拟机上相互传输
首先,在hadoop1上向hadoop2、hadoop3发送
ssh-copy-id hadoop2
ssh-copy-id hadoop3
然后,在hadoop2上向hadoop1、hadoop3发送
ssh-copy-id hadoop1
ssh-copy-id hadoop3
最后,在hadoop3上向hadoop1、hadoop2发送
ssh-copy-id hadoop1
ssh-copy-id hadoop2

然后分别在三台主机上键入
ssh hadoop1
ssh hadoop2
ssh hadoop3
可以免密相互登录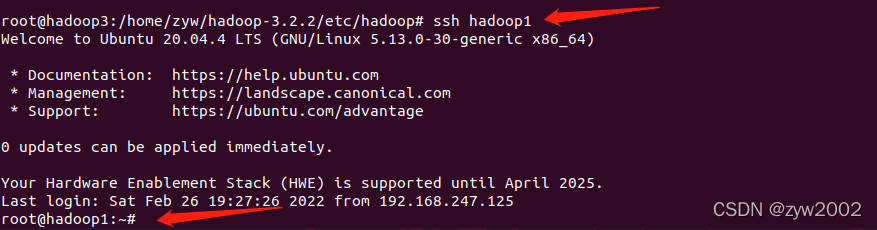
5.5 测试xcall 和xsync命令
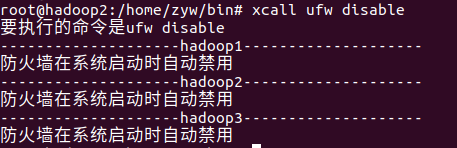
【测试xcall】
使用xcall来关闭三台虚拟机上的防火墙,在任意一台虚拟机的终端上输入
xcall ufw disable
【测试xsync】
在任意一台虚拟机上修改文件
slaves
cd /home/zyw/hadoop-3.2.2/etc/hadoop/
vi slaves
修改内容为:
hadoop1
hadoop2
hadoop3
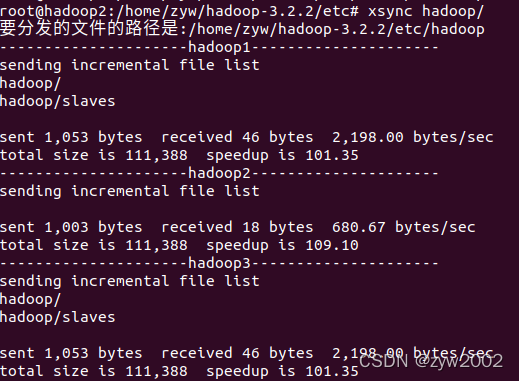
使用xsync脚本将修改的文件分发到另外两台虚拟机上
cd ../
xsync hadoop/
5.5 设置non-login 环境变量
我们使用的xcall脚本是以non-login的方式打开一个bash执行命令的,此时不会读取配置文件~/.profile,而是读取 ~/.bashrc。
先在hadoop1上修改配置文件~/.bashrc
gedit ~/.bashrc
在文件的首行加入
source ~/.profile
然后注释下面 ~/.profile的内容
#if [ -n "$BASH" ]; then
# include .bashrc if it exists
# if [ -f "$HOME/.bashrc" ]; then
# . "$HOME/.bashrc"
# fi
#fi
接着将修改过的
~/.profile
和
~/.bashrc
文件分发到另外两台虚拟机上
xsync ~/.profile
xsync ~/.bashrc
测试
xcall jps
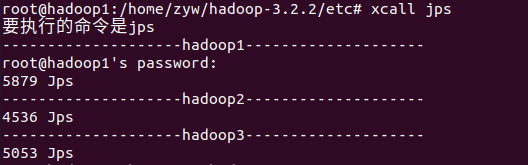
6. hadoop 的使用
hadoop初始化
在hadoop01中输入
hadoop namenode -format
6.1 开启HDFS
在hadoop01上开启hdfs
start-dfs.sh 或 start-all.sh
在这里插入图片描述
在hadoop1的浏览器上访问
http://192.168.247.124:50070 或者 http://localhost:50070
出现三个节点的信息,说明集群搭建成功。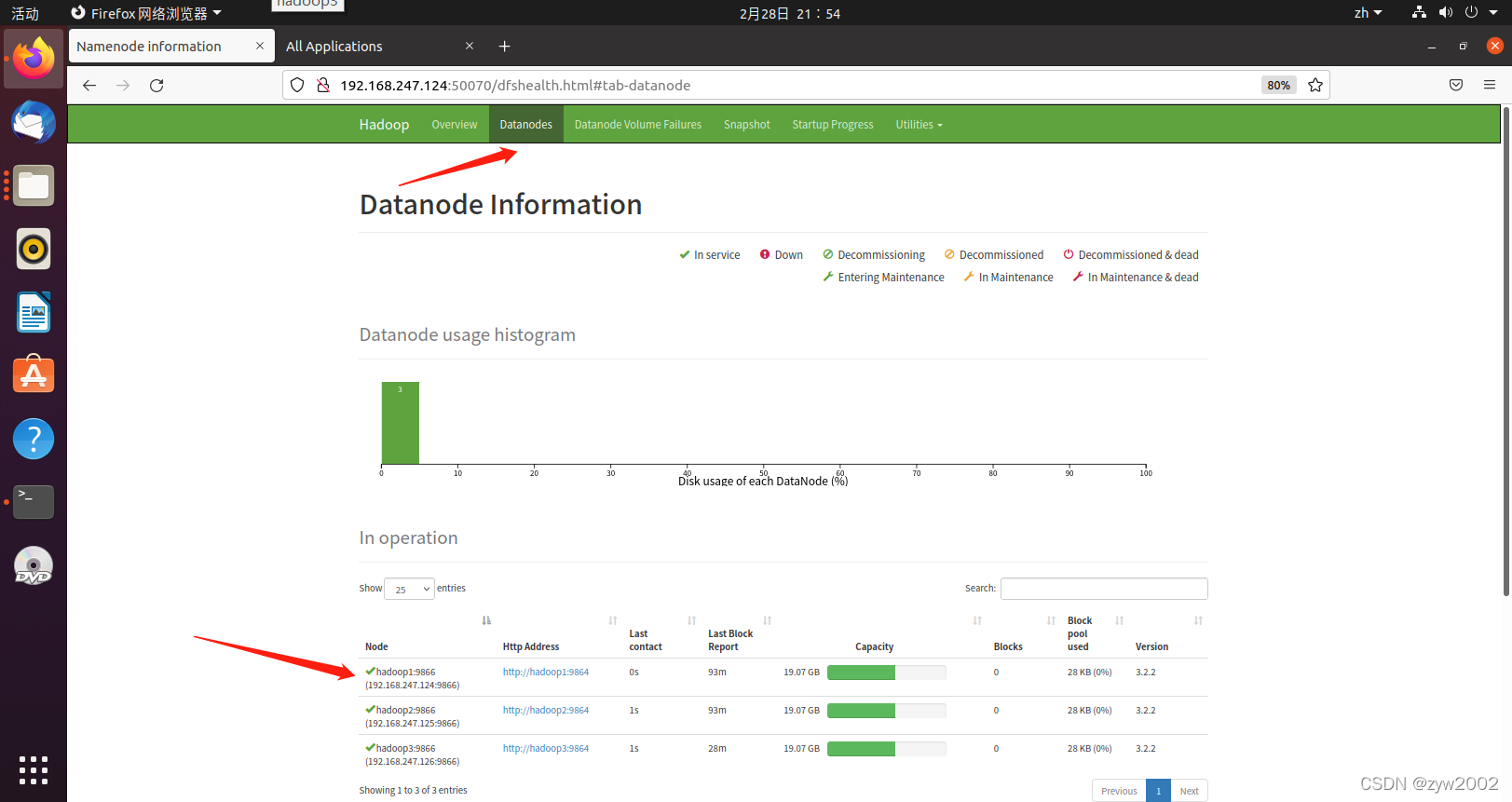
6.2 开启yarn
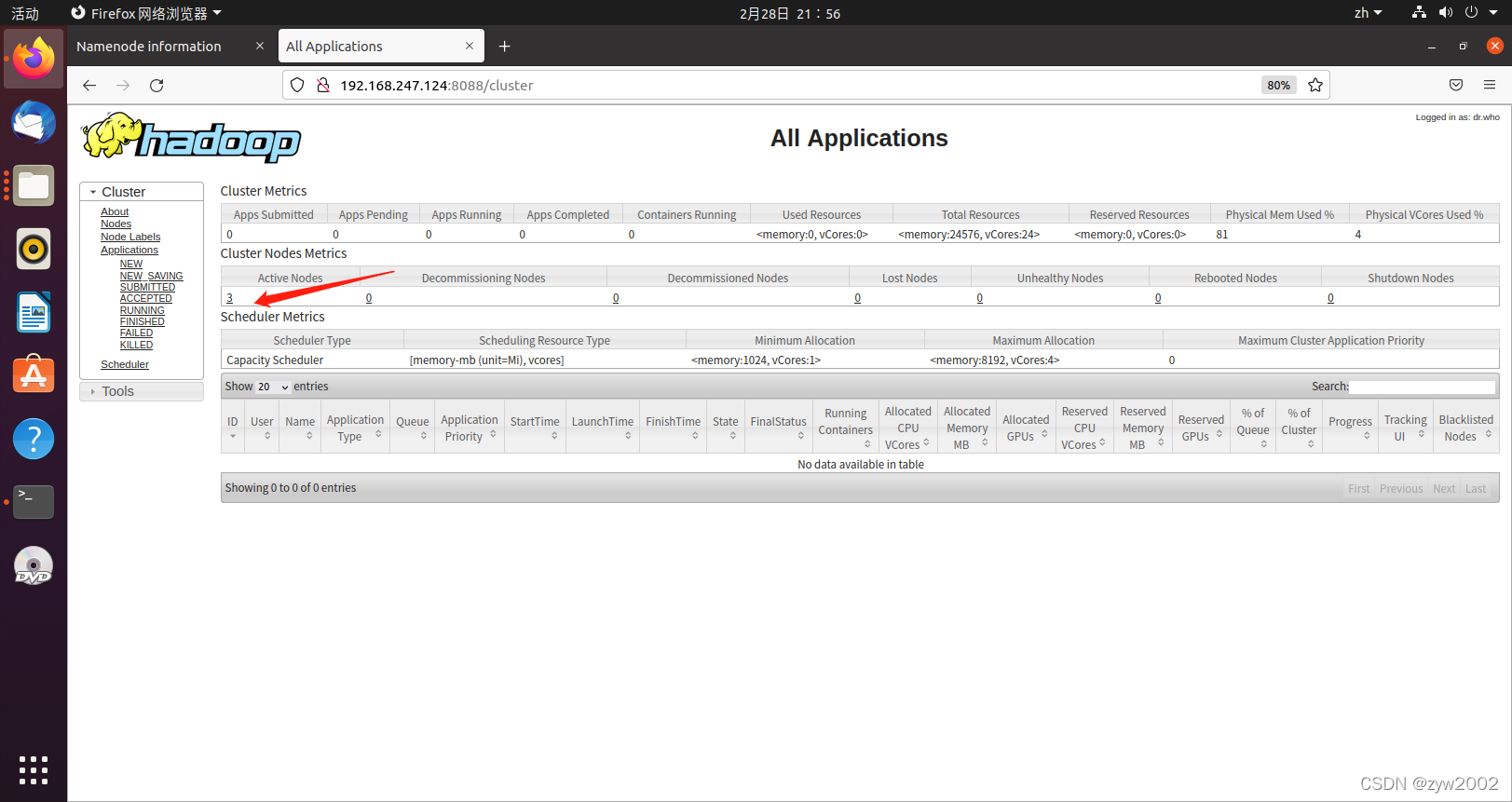
然后在hadoop1上开启yarn
start-yarn.sh
在hadoop1的浏览器上访问
http://192.168.247.124:8088 或者 http://localhost:8088
使用
xcall jps
查看所有节点的运行情况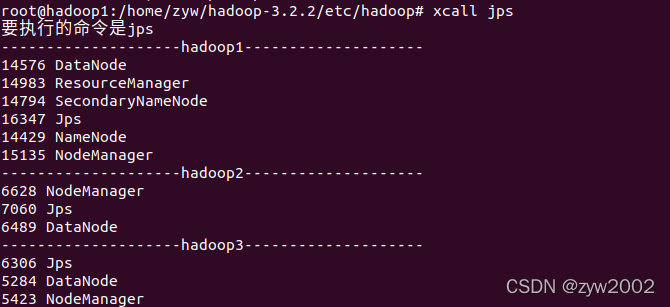
7. 安装Hbase
将压缩包拖动到虚拟机上的用户目录下
将下载的安装包移动到
/opt
目录下
mv hbase-1.2.6-bin.tar.gz /opt
解压
cd /opt
tar -zxvf hbase-1.2.6-bin.tar.gz
添加环境变量
vi /etc/profile
最下面加上两行
export SCALA_HOME=/opt/scala-2.13.0
export PATH=$SCALA_HOME/bin:$PATH
刷新环境变量
source /etc/profile
进入conf目录,修改hbase-env.sh
cd /opt/hbase-1.2.6/conf/
vi hbase-env.sh
将
JAVA_HOME, HADOOP_HOME, HBASE_LOG_DIR, HBASE_MANAGES_ZK
修改为以下内容:
# 配置JDK安装路径
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 配置Hadoop安装路径
export HADOOP_HOME=/home/zyw/hadoop-3.2.2
# 设置HBase的日志目录
export HBASE_LOG_DIR=/opt/hbase-1.2.6/logs
# 使用独立的ZooKeeper集群
export HBASE_MANAGES_ZK=false
# 设置pid的路径 (啥用?)
export HBASE_PID_DIR=/home/hadoop_files
配置hbase-site.xml
vi hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<!-- 此属性可省略,默认值就是2181 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/zookeeper-3.4.6/tmp</value>
</property>
<!-- 此属性可省略,默认值就是/hbase -->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
</configuration>
8. 踩坑记录
zyw@hadoop01:~/hadoop-3.2.2/etc/hadoop # .start-dfs.sh
Starting namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [slave1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
# Licensed to the Apache Software Foundation (ASF) under one or more
修改完成后,重新启动。
参考:
https://blog.csdn.net/qq_44937291/article/details/112298318
https://home.uncg.edu/cmp/downloads/files/Part%202.pdf
https://phoenixnap.com/kb/install-hadoop-ubuntu
版权归原作者 zyw2002 所有, 如有侵权,请联系我们删除。