
问题说明
一天下午,在北京客户现场的同学反馈我们elasticsearch出现的大量的异常,他反馈说他使用多线程写入大量数据到elasticsearch集群时,隔一段时间之后就会出现CircuitBreakingException,多尝试几次后,他就把问题反馈到我们这边了

解决思路
1.降低并发度
看到这个问题我首先想到的是减少写入的并发量,毕竟很明显是达到内存的阈值
ES 为了避免 OOM 会设置一些 circuit breaker (断路器),这些断路器的作用就是在内存不够的时候主动拒绝接下来的操作,而不是进一步的分配内存最终产生 OutOfMemoryError,断路器的作用就是保护整个进程不至于挂掉。
因此我就跟现场同学说,先把并发度降下来,我们是16个进程,先改为4个进程,发现问题还存在,于是我就跟现场同学说,把并发度降低为单线程,结果问题依然存在。
2.提高阈值
竟然降低并发解决不了,我们就想到能不能提高的elasticsearch熔断的阈值,给它更大的内存进行处理,当然这种方式是指标不治本的,于是我们参考官方熔断阈值设置,因此我将一些阈值动态的调大了,结果发现线程同学反馈问题依旧存在,调大了没有起到什么作用。而且过了一会,现场同学反馈我们集群状态变为yello了,出现了很多unassign的分片,而且此时kibana也变得很不稳定,经常性的卡死,同时还出现节点丢失的情况

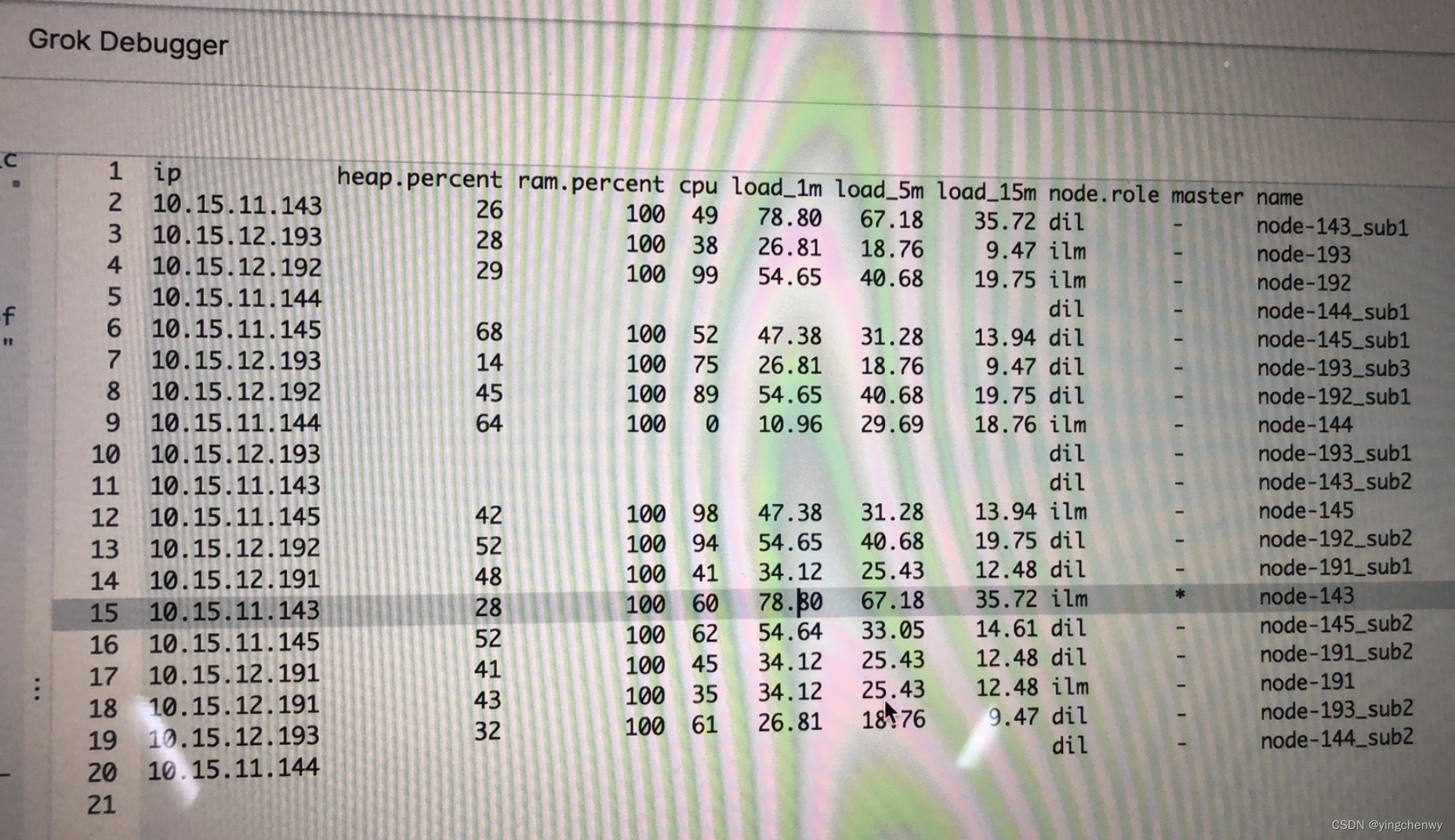
3.尝试解决未分配分片
因为,于是就让现场同学停止写入,先等待集群状态恢复为green,决定先等半个小时,让es集群自动进行平衡,结果半小时之后,es集群并没有恢复,此时觉得问题有些大了,感觉集群出了较大的问题,于是我们尝试分析unassign的原因,于是使用Cluster allocation explain API对这些unassign的分片进行分析,分析结果如下
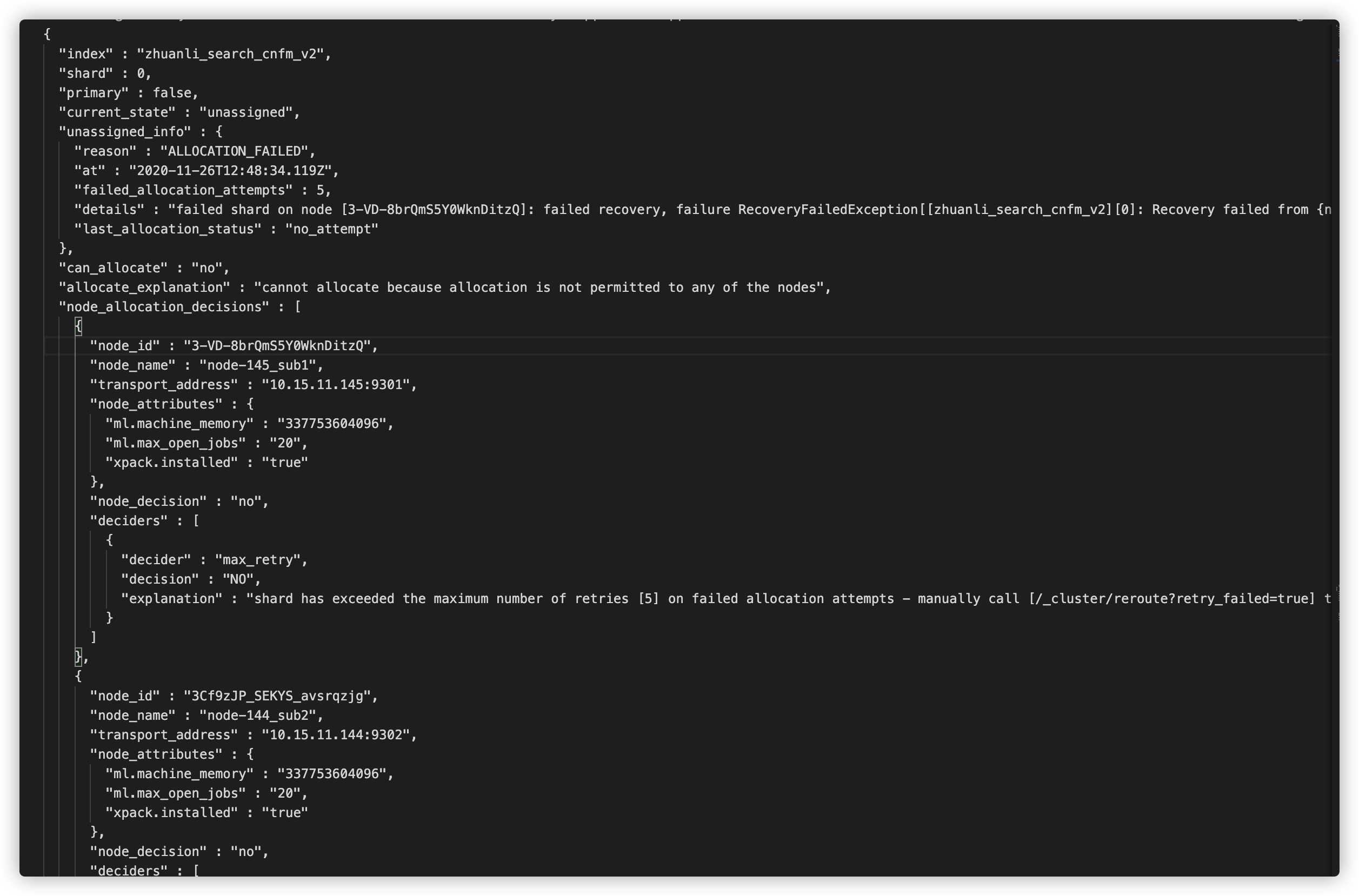
根据分析,大致是recover失败,超过了最大的尝试次数,建议我们通过手动的形式去处理,因此我们尝试通过Cluster reroute API进行手动迁移分片,当然是显而易见的失败了,错误如下
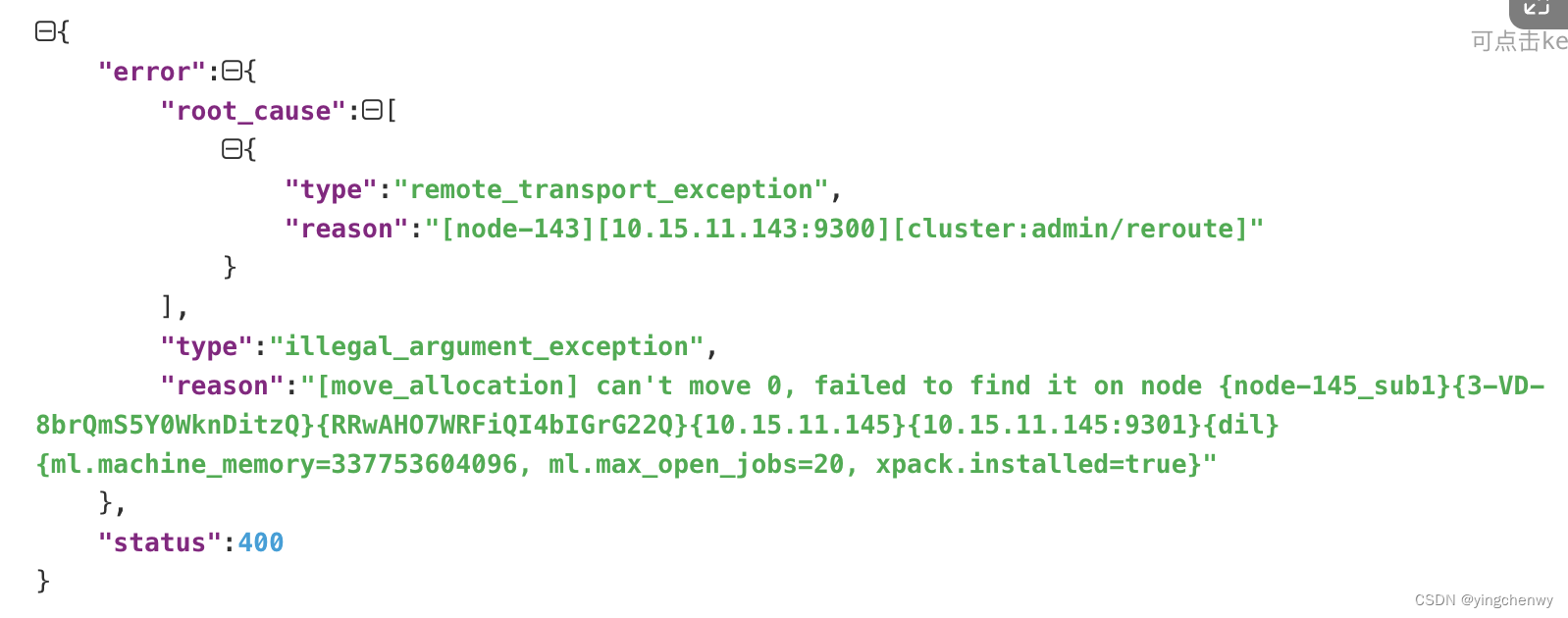
4.限制集群节点的流量
虽然觉察到可能是由于GC引起了,但我们首先希望能够通过非重启的方法先暂时去解决,然后再去分析原因,最后在最终找到解决方案,
因为我们此时节点是黄的,此时集群的容错率很低,万一为了修改某些参数在重启的过程中,存在或者某一台节点出现问题,无法正常启动,导致数据数据丢失,不到万不得已,不会重建集群。
于是我们就想到控制节点的流量,降低传输的速度,于是我们就做了如下事情
1.取消有问题的副本
2.使用Index Recover设置集群传输的速度
indices.recovery.max_bytes_per_sec:限制每个节点的出栈入站流量,默认40mb,我们这里改为20mb;indices.recovery.max_concurrent_file_chunks:每次恢复并行发送的文件块请求的数量,默认为2,这里改为1
3.重新将副本设置为1
及时,这样问题还是没有解决,过了一会依旧出现了这样的问题
5.GC参数调整
虽然之前认为GC可能存在问题,但我认为GC是果,不是因,尝试去解决让GC不正常的问题,当然都失败了。
查看kibana的监控,找到出现问题节点的监控,图如下
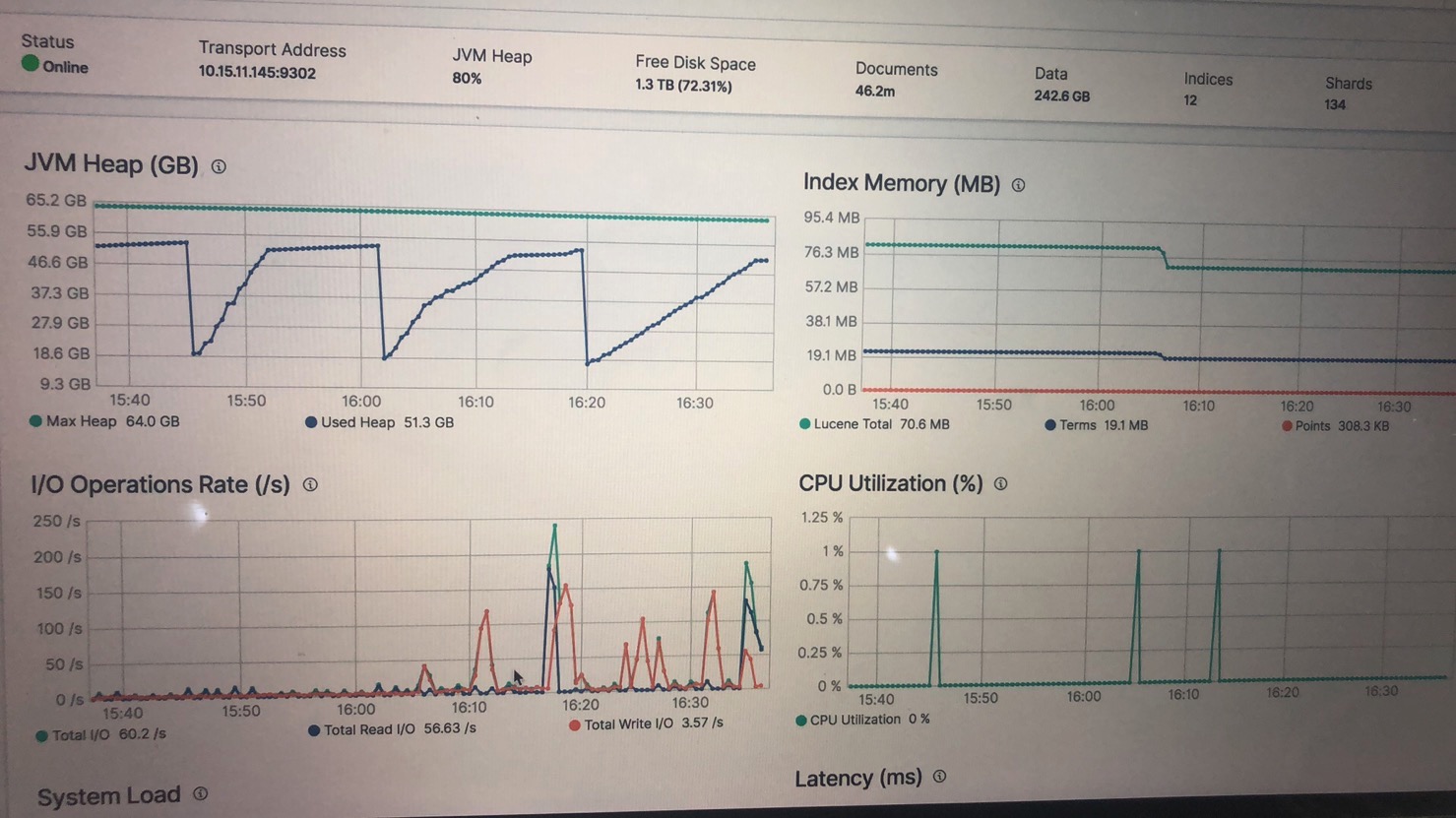
根据此图发现es节点内存占用率一直在上升,说明申请的内存大于回收的内存空间,那么到内存快满的时候还有请求进行,那么必然内存不足,触发CircuitBreakingException。那么此时会进行fullgc,导致节点假死,就出现图中的现象。
我们使用的是G1
因此,就这种情况我就提出了我的想法,能够提前GC,那么就能够降低内存不足状况的概率,当然这样子的话,GC会更加频繁,降低系统的吞吐量,对比现状,显然是保护es集群更加重要,于是我们就参照这个想法去调整G1回收器的参数
查询G1参数列表如下

-XX:InitiatingHeapOccupancyPercent=30 默认为45%,这里是为了让垃圾回收器提前进入垃圾回收周期
-XX:G1ReservePercent=25% 默认10%,保留更多的内存空间,避免内存不足导致错误
重启集群
此时由于集群时yello状态,表明集群万一有一台重启失败或者出现意外,那么就势必导致数据丢失,因此必要要慎重。于是,我们跟现场同步进行沟通,指定重启步骤
1.提前修改所有节点的配置
2.将有问题的索引的副本设置为0
3.限制节点流程和传输,参考上面
4.禁止集群自动分配,避免因为重启导致集群重启导致分片自动分配,同时也为了数据快速恢复,参考Cluster-level shard allocation and routing settings
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}
5.依次重启每一台几点
6.打开集群分片设置,设置策略为 "all"
7.恢复索引副本设置
上述步骤执行完成后,我们就等待集群恢复,发现副本能够正常恢复,同时并发写入也没有问题了,当然我们降低了并发度
总结
垃圾回收器改变带来的影响
一周前我们使用的垃圾回收器为CMS回收器,因为项目并发问题修改为G1,在使用CMS的时候这个问题并没有出现,但改成G1后出出现了
CMS和G1区别
CMS分为老年代和年轻代,当内存区域即将耗尽时会进行垃圾回收,回收时是线程停止的
G1内存是按region进行划分的,虽然也分年轻代和老年代,但并不严格,那块region是老年代或者新生代并非一成不变的,这是由垃圾回收器自动进行管理的,G1可以提供可预测的停顿,这是由region划分这个特性决定的
原因分析
索引数据体积过大,写入消耗内存过快,同时由于垃圾回收速度过慢,导致内存不停上涨,导致错误的发生
后续改进
1.由于应用直接多线程大量数据写入,导致es集群压力过大,中间缺少一层对写入流量进行控制,同时应当对集群进行压测,了解集群的写入状况,避免集群过载
2.GC改进,有上面总结,造成熔断的一个重要原因是垃圾回收过慢,为什么回收过慢,是因为我们设置-XX:MaxGCPauseMillis=200,这个参数表示最长垃圾回收时间,该属性设置过小,导致垃圾回收过慢,因此我们可以适当调大该属性,具体多少就该进行测试了
G1回收时并非我们常见那种对所有内存区域进行回收,而是选择一部分内存块进行回收,具体回收多少,有用户设置进行决定,这里由于设置过小,导致回收过慢,也是导致熔断的原因
参考
Elasticsearch新增节点引发CircuitBreakingException错误 - 御坂研究所
Elasticsearch Guide [8.6] | Elastic
版权归原作者 yingchenwy 所有, 如有侵权,请联系我们删除。