
相关导论大数据相关导论
** 首先我们要知道一切皆数据**
数据的作用
- 从海量数据中提取出有效的价值信息, 实现数据的商业化, 价值化, 给企业的决策者或者运营人员提供数据支持 或者 分析性报告.
- 更好的了解事与物的运行规律, 给生活赋能.
什么是大数据
- 数据的体量比较大, 2000年全球互联的概念提出及普及后, 数据量开始快速增长....
- 数据单位:bit, byte, kb, mb, gb, tb, pb, eb, zb, yb, bb, nb, db
大数据的特点
数据体量大
采集数据量大 存储数据量大 计算数据量大 TB、PB级别起步种类、来源多样化
种类:结构化、半结构化、非结构化 来源:日志文本、图片、音频、视频价值密度低
信息海量但是价值密度低
深度复杂的挖掘分析需要机器学习参与
速度快
数据增长速度快
获取数据速度快
数据处理速度快
数据质量高
数据的准确性
数据的可信赖度
大数据解决的问题
海量的数据存储
海量数据的计算
海量数据的传输
Hadoop简介
hadoop之父:道格 卡丁
Hadoop介绍
狭义上:
HDFS:hadoop distributed filesystem, hadoop的分布式文件存储系统.
MapReduce:分布式计算框架
Yarn:分布式任务接收和资源调度器
广义上:
指的是Hadoop生态圈, 包括但不限于周边所有的技术,
例如: Spark, Flink, Sqoop, Zookeeper...
分布式和集群:
分布式:分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。
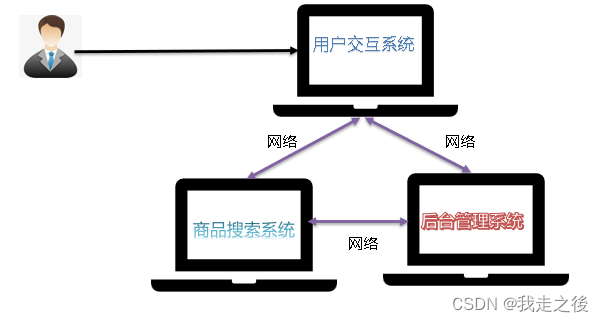
集群:所谓集群是指一组独立的计算机系统构成的一多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。
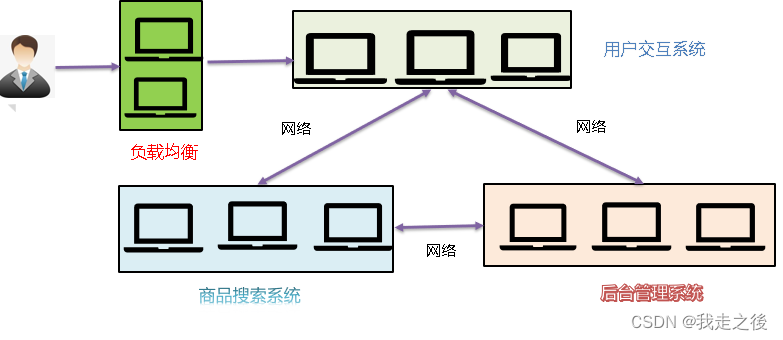
分布式和集群的区别
** 分布式 :分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事**
** 集群:集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事**
Hadoop是哪种分布式架构模式?
** 主从模式(中心化模式)的架构**
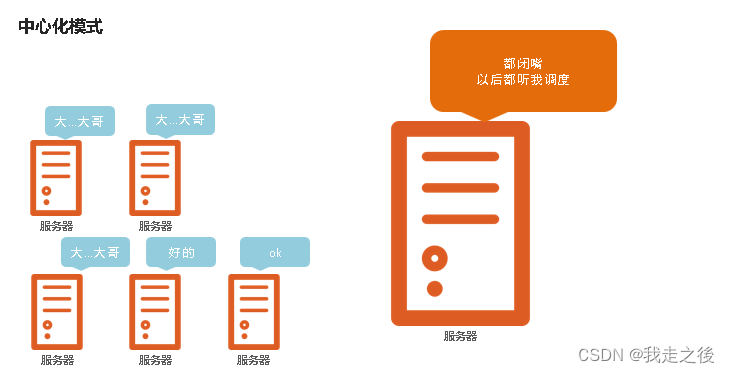
hadoop的架构
狭义解释
Hadoop指Apache这款开源框架,它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储
MAPREDUCE(分布式运算编程框架):解决海量数据计算
YARN(作业调度和集群资源管理的框架):解决资源任务调度
广义解释
Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
架构:
Hadoop1.X架构:HDFS集群 + MapReduce集群
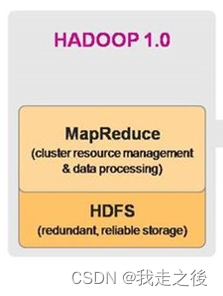
Hadoop2.X架构:HDFS集群 + Yarn集群 + MapReduce
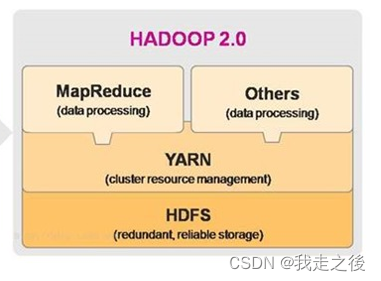
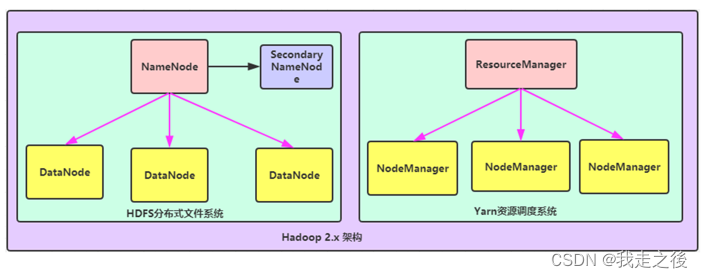
HDFS****模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager: 负责执行主节点分配的任务
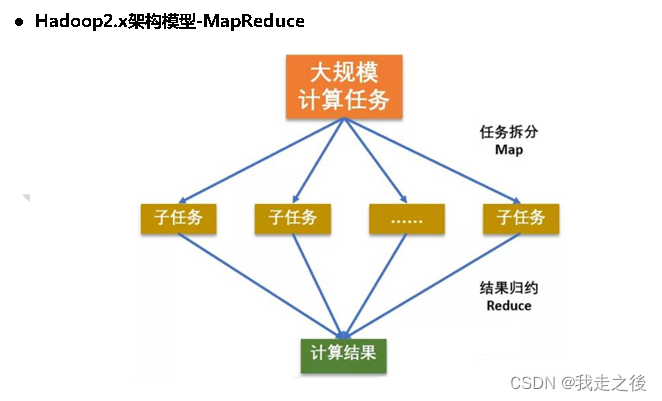
Hadoop****模块之间的关系
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储。
MapReduce的运行需要由Yarn集群来提供资源调度。
Hadoop****集群使用
Hadoop**启动和关闭-**集群模式
- 启动3台虚拟机
- 使用crt分别连接3台虚拟机
- 集群一键启动和关闭
#一键启动
star-all.sh
#一键关闭
stop-all.sh
#启动历史服务
mapred --daemon starthistoryserver
Hadoop页面访问**-**集群模式
#查看进程代码
jps

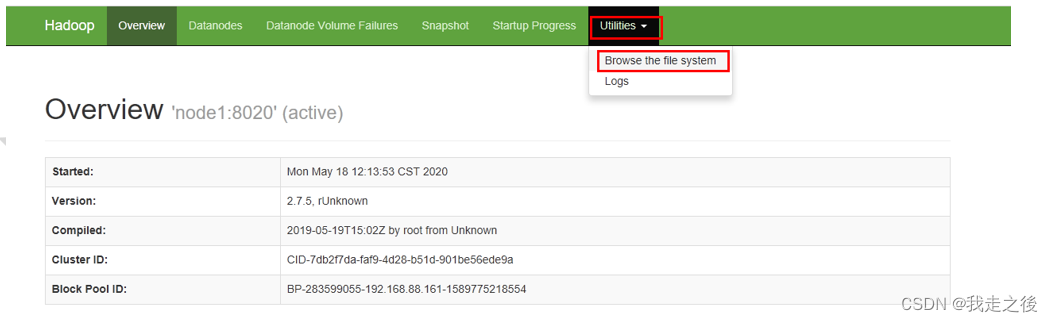
查看HDFS页面
启动NameNode.连接URL: http://192.168.88.161:9870
查看YARN页面
启动ResourceManager.连接URL:http://192.168.88.161:8088
查看已经finished的mapreduce运行日志
启动historyserver.连接URL:http://192.168.88.161:19888
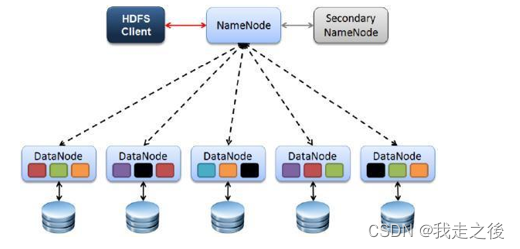
HDFS的架构
1.HDFS采用Master/Slave架构
2.一个HDFS集群有两个重要的角色,分别是Namenode和Datanode。
3.HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
Client
1.就是客户端。
2.文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
3.与 NameNode 交互,获取文件的位置信息。
4.与 DataNode 交互,读取或者写入数据。
5.Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
NameNode
1.就是 master,它是一个主管、管理者。
2.管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息….)。
3.配置副本策略。
4.处理客户端读写请求。
DataNode
1.就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
2.存储实际的数据块。
3.执行数据块的读/写操作。
4.定时向namenode汇报block信息。
Secondary NameNode
1.并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
2.辅助 NameNode,分担其工作量。
3.在紧急情况下,可辅助恢复 NameNode。
HDFS初体验--Shell命令
格式:hadoop fs | hdfs dfs -选项 参数
常用命令:
#-ls
hadoop fs -ls /
#显示文件列表
hadoop fs –ls -R /
#递归显示文件列表
#-mkdir
hadoop fs -mkdir /dir1
hadoop fs -mkdir -p /aaa/bbb/ccc
#-put
hadoop fs -put /root/1.txt /dir1
#上传文件
hadoop fs –put /root/dir2 /
#上传目录
#-get
hadoop fs -get /initial-setup-ks.cfg /opt
#-mv
hadoop fs -mv /dir1/1.txt /dir2
#-rm
hadoop fs -rm /initial-setup-ks.cfg
#删除文件
hadoop fs -rm -r /dir2
#删除目录
#-cp
hadoop fs -cp /dir1/1.txt /dir2
#-cat
hadoop fs -cat /dir1/1.txt
版权归原作者 我走之後 所有, 如有侵权,请联系我们删除。