
简介
Flink JDBC 连接器允许使用 JDBC 驱动程序从任何关系数据库读取数据并将数据写入其中。本文档介绍如何设置 JDBC 连接器以针对关系数据库运行 SQL 查询。
Flink 读写MySQL 可以参考:Flink 读写MySQL数据(DataStream和Table API)_wank1259162的博客-CSDN博客Flink提供了基于JDBC的方式,可以将读取到的数据写入到MySQL中;本文通过两种方式将数据下入到MySQL数据库,其他的基于JDBC的数据库类似,另外,Table API方式的Catalog指定为Hive Catalog方式,持久化DDL操作。Maven依赖,包含了Hive Catalog的相关依赖 DataStream方式读写MySQL数据Table API的方式读写MySQL,其中Flink的Catalog使用Hive Catalog的方式MySQL中的数据..........https://blog.csdn.net/wank1259162/article/details/125442030?spm=1001.2014.3001.5502
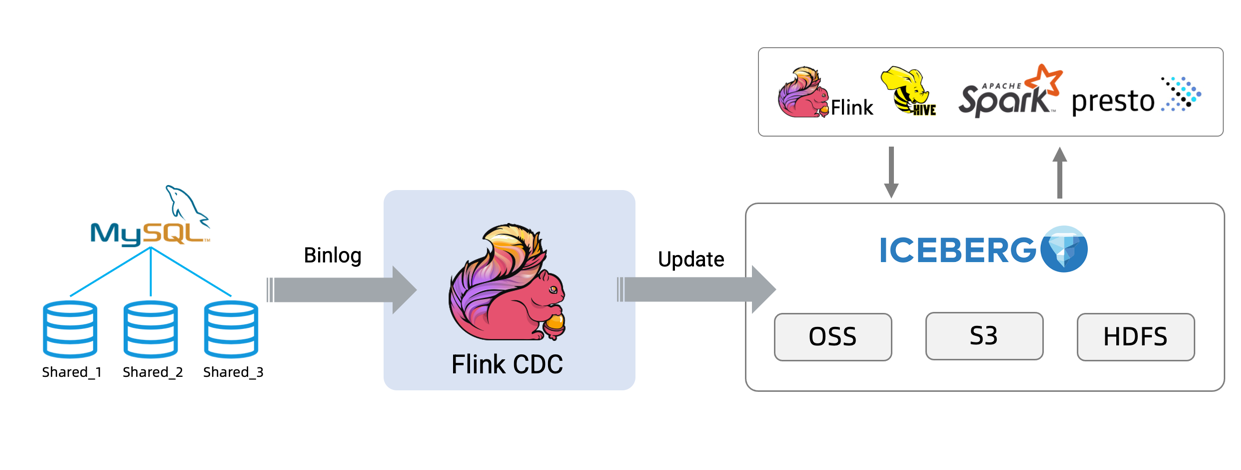
Flink-MySQL-CDC连接器允许实时同步MySQL数据 。
如果在 DDL 上定义了主键,则 JDBC sink 以 upsert 模式与外部系统交换 UPDATE/DELETE 消息,否则,它以 append 模式运行,不支持消费 UPDATE/DELETE 消息。
Apache Iceberg是一种表格式(table format)。我们可以简单理解为它是基于计算层(flink、spark)和存储层(orc、parquet)的一个中间层,我们可以把它定义成一种“数据组织格式”,Iceberg将其称之为“表格式”也是表达类似的含义。
它与底层的存储格式(比如ORC、Parquet之类的列式存储格式)最大的区别是,它并不定义数据存储方式,而是定义了数据、元数据的组织方式,向上提供统一的“表”的语义。它构建在数据存储格式之上,其底层的数据存储仍然使用Parquet、ORC等进行存储。在hive建立一个iceberg格式的表。用flink或者spark写入iceberg,然后再通过其他方式来读取这个表,比如spark、flink、presto等。
Iceberg 优势
增量读取处理能力:Iceberg支持通过流式方式读取增量数据,支持Structured Streaming以及Flink table Source;
支持事务(ACID),上游数据写入即可见,不影响当前数据处理任务,简化ETL;提供upsert和merge into能力,可以极大地缩小数据入库延迟;
可扩展的元数据,快照隔离以及对于文件列表的所有修改都是原子操作;
同时支持流批处理、支持多种存储格式和灵活的文件组织:提供了基于流式的增量计算模型和基于批处理的全量表计算模型。批处理和流任务可以使用相同的存储模型,数据不再孤立;Iceberg支持隐藏分区和分区进化,方便业务进行数据分区策略更新。支持Parquet、Avro以及ORC等存储格式。
支持多种计算引擎,优秀的内核抽象使之不绑定特定的计算引擎,目前Iceberg支持的计算引擎有Spark、Flink、Presto以及Hive。
代码依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.4</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop.version>3.1.2</hadoop.version>
<hive.version>3.1.2</hive.version>
</properties>
<!-- https://mvnrepository.com/artifact/org.apache.iceberg/iceberg-flink-runtime -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime</artifactId>
<version>0.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
测试代码
批量方式
/**
* MySQL数据导入iceberg
*/
public class JDBC2IcebergTable {
public static void main(String[] args) throws Exception {
// create environments of both APIs
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE IF NOT EXISTS EventTable (\n" +
"`user` STRING,\n" +
"url STRING,\n" +
"`timestamp` BIGINT\n" +
") WITH (\n" +
"'connector' = 'jdbc',\n" +
"'url' = 'jdbc:mysql://127.0.0.1:3306/flink',\n" +
"'table-name' = 'events',\n" +
"'username'='root',\n" +
"'password'='00000'\n" +
")");
Table eventTable = tableEnv.from("EventTable");
// Table aliceTable = tableEnv.sqlQuery("select * from EventTable ");
//创建CATALOG
tableEnv.executeSql("CREATE CATALOG hadoop_catalog WITH (\n" +
" 'type'='iceberg',\n" +
" 'catalog-type'='hadoop',\n" +
" 'warehouse'='file:///tmp/warehouse/iceberg',\n" +
" 'property-version'='1'\n" +
")");
tableEnv.executeSql("USE CATALOG hadoop_catalog");
//创建表
tableEnv.executeSql("CREATE TABLE IF NOT EXISTS eve (\n" +
" `user` STRING,\n" +
" url STRING,\n" +
" `timestamp` BIGINT \n" +
")");
Configuration configuration = new Configuration();
TableSchema schema = eventTable.getSchema();
DataStream<Row> input = tableEnv.toDataStream(eventTable);
// input.print();
TableLoader tableLoader = TableLoader.fromHadoopTable("file:///tmp/warehouse/iceberg/default/eve", configuration);
DataStreamSink<RowData> dataDataStreamSink = FlinkSink.forRow(input, schema)
.tableLoader(tableLoader)
.build();
//读数据
DataStream<RowData> batch = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(false)
.build();
batch.map(x -> x.getString(0)).print();
//batch.print();
env.execute("Test Iceberg Batch Read");
}
}
代码说明
1、hadoop catalog创建
创建脚本,warehouse的路径,它会自动创建HDFS路径里面 ns是命名空间,但namenode的使用ip:port代替。
//创建CATALOG
tableEnv.executeSql("CREATE CATALOG hadoop_catalog WITH (\n" +
" 'type'='iceberg',\n" +
" 'catalog-type'='hadoop',\n" +
" 'warehouse'='file:///tmp/warehouse/iceberg',\n" +
" 'property-version'='1'\n" +
")");
2.建表
在刚才构建的Catalog下面创建数据表
tableEnv.executeSql("USE CATALOG hadoop_catalog");
//创建表
//创建表
tableEnv.executeSql("CREATE TABLE IF NOT EXISTS eve (\n" +
" `user` STRING,\n" +
" url STRING,\n" +
" `timestamp` BIGINT \n" +
")");
3.查看目录
新创建的表数据和元数据。

4.读数据
DataStream<RowData> batch = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(false)
.build();
batch.print();
Idea的输出

MySQL CDC 方式实时写入Iceberg
Flink SQL和Table API两种方式都可以。
public class MysqlCDC2Iceberg {
public static void main(String[] args) throws Exception {
// create environments of both APIs
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setCheckpointInterval(1000);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// tableEnv.executeSql("CREATE TABLE order_info (\n" +
// " `id` BIGINT NOT NULL,\n" +
// " consignee STRING,\n" +
// " order_status STRING,\n" +
// " order_comment STRING,\n" +
// " payment_way STRING,\n" +
// " PRIMARY KEY (`id`) NOT ENFORCED\n" +
// " ) WITH (\n" +
// " 'connector' = 'mysql-cdc',\n" +
// " 'hostname' = '127.0.0.1',\n" +
// " 'port' = '3306',\n" +
// " 'username' = 'root',\n" +
// " 'password' = 'xxxx',\n" +
// " 'database-name' = 'gmall2021',\n" +
// " 'table-name' = 'order_info'\n" +
// " )");
//连接器为Mysql CDC
TableDescriptor tableDesc = TableDescriptor.forConnector("mysql-cdc")
.option("hostname", "127.0.0.1")
.option("port", "3306")
.option("username", "root")
.option("password", "xxxx")
.option("database-name", "gmall2021")
.option("table-name", "order_info")
.schema(
Schema.newBuilder()
.column("id", "BIGINT NOT NULL")
.column("consignee", DataTypes.STRING())
.column("order_status", DataTypes.STRING())
.column("order_comment", DataTypes.STRING())
.column("payment_way", DataTypes.STRING())
.primaryKey("id")
.build())
.build();
tableEnv.createTemporaryTable("order_info", tableDesc);
Table user_source = tableEnv.from("order_info");
DataStream<Row> input = tableEnv.toChangelogStream(user_source);
// input.print();
//创建CATALOG
tableEnv.executeSql("CREATE CATALOG hadoop_catalog WITH (\n" +
" 'type'='iceberg',\n" +
" 'catalog-type'='hadoop',\n" +
" 'warehouse'='file:///tmp/warehouse/iceberg',\n" +
" 'property-version'='1'\n" +
")");
tableEnv.executeSql("USE CATALOG hadoop_catalog");
//创建表
tableEnv.executeSql("CREATE TABLE IF NOT EXISTS all_order_sink (" +
" `id` BIGINT NOT NULL,\n" +
" consignee STRING,\n" +
" order_status STRING,\n" +
" order_comment STRING,\n" +
" payment_way STRING,\n" +
" PRIMARY KEY (`id`) NOT ENFORCED )\n");
Configuration configuration = new Configuration();
TableSchema schema = user_source.getSchema();
TableLoader tableLoader = TableLoader.fromHadoopTable("file:///tmp/warehouse/iceberg/default/all_order_sink", configuration);
DataStreamSink<RowData> dataDataStreamSink = FlinkSink.forRow(input, schema)
.tableLoader(tableLoader)
.overwrite(true)
.build();
env.execute();
}
}
版权归原作者 wank1259162 所有, 如有侵权,请联系我们删除。