
在构建和部署机器学习模型时,最佳好的方法是使它们尽可能的成为端到端的工作,这意味着尝试将大多数与模型相关的数据转换分组到一个对象中。
在ML世界中,采用pipeline的最简单方法是使用Scikit-learn。如果你不太了解它们,这篇文章就是为你准备的。我将通过一个简单的用例,首先尝试通过采用一个简单的机器学习工作流来解决这个问题,然后我将通过使用Scikit-Learn pipeline来解决这个问题,这样就能看出差异。
pipeline
pipeline允许你封装所有的预处理步骤,特性选择,扩展,特性编码,最重要的是它帮助我们防止数据泄漏,主要的好处是:
方便和封装:您只需要对数据调用fit和预测一次,就可以拟合整个估计序列。
联合参数选择:可以一次对pipeline中所有估计器的参数进行网格搜索。
在交叉验证中,安全pipeline有助于避免将测试数据中的统计信息泄漏到训练好的模型中
下面Scikit-learn pipelines流程图

一个转换序列(预处理,特征工程),和一个单一实体组装和执行的估计器(ML模型等)组成了pipelines。
转换对象(Transformers )是包含 FIT 和TRANSFORM方法的对象,例如one-hot encoder, simple imputer,等
估计器对象(Estimator )具有FIT和PREDICT方法的对象:(比如回归模型和分类模型等)
注意:在上面我已经连续放置了多个Transformers ,但它们不必这样设置,根据您的需要,您可以并行地实现它们。(你会在下面的例子中看到更多)
本例数据说明
我将使用来自Kaggle的数据集:Telco-Customer-Churn practice problem.
# Importing the Dependencies
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
import warnings
warnings.filterwarnings('ignore')
df=pd.read_csv("/kaggle/input/telco-customer-churn/WA_Fn-UseC_-Telco-Customer-Churn.csv")
df

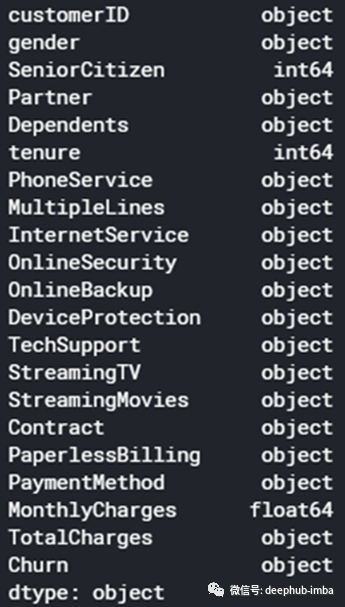
查看特征和数据类型
df.dtypes
#Defining Dependent Variables
X=df.drop(columns= ['Churn','customerID','gender','PhoneService',
'MultipleLines', 'PaperlessBilling','PaymentMethod'], axis=1)
#Independent Variable
y=df['Churn']
# Converting this variable to object, it is deifined as int64
df['SeniorCitizen']=df['SeniorCitizen'].astype(object)
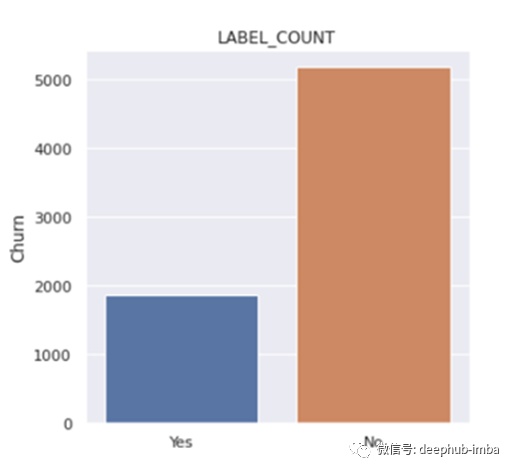
我们将专注于获得一个可行的模型,而不是专注于如何针对用例提出最佳模型。这里没有做任何EDA,而只是考虑不需要任何预处理的功能。
# Split Train Test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=124)
#Numeric Feature
numeric_features = ['tenure']
#Categorical Features
categorical_features = ['SeniorCitizen', 'Partner', 'Dependents', 'PhoneService',
'InternetService','OnlineSecurity','OnlineBackup',
'DeviceProtection','TechSupport','StreamingTV',
'StreamingMovies','Contract']
这里作为演示仅将准确性作为测试指标。
方案1:不使用pipeline的用例(典型ML工作流程)
# Importing the Dependencies
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
在下面的第一个解决方案中,我将实现一个典型的机器学习工作流程,首先从定义转换对象开始,然后将这些对象拟合(FIT)到训练数据中(从数据中学习),然后应用这些转换 (TRANSFORM)功能训练数据 接下来,我们在转换后的数据上训练模型,现在我们将所有这些转换再一次应用于测试集。这里我们不应用任何FIT(因为它不必从数据中学习),我们仅应用TRANSFORM函数来防止数据的泄露
对训练数据使用“fit & transform”
在测试/新数据上使用“transform”。这样可以防止数据泄漏并将相同的转换应用于这两组数据。

得到结果如下

方案2:采用Scikit-learn pipeline
现在,让我们尝试使用Scikit-learn pipeline执行相同的操作,我将进行相同的转换并应用相同的算法
建立pipeline的第一步是定义每个转换器。约定是为我们拥有的不同变量类型创建转换器。脚步:
1)数值转换器:创建一个数值转换器,该转换器首先估算所有缺失值。然后应用StandardScaler。
2)分类转换器:创建一个分类转换器,该转换器采用OneHotEncoder将分类值转换为整数(1/0)。
3)列转换器:ColumnTransformer用于将上述转换应用于数据帧中的正确列,我将它们传递给我,这是我在上一节中定义的数字和分类特征的两个列表。
4)使用Estimator(Classifier)进行流水线操作:在这里,我将Column Transformer与最终的Transformer进行流水线化,后者是Estimator(我选择Logistic回归作为二进制分类器)
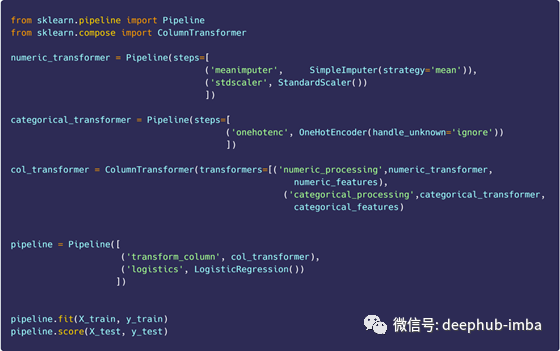
得到结果如下
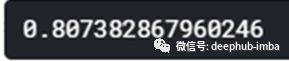
我们得到了相同的准确率。这里没有多次进行拟合和变换,我们使用转换器和最终估计器对整个pipeline进行了一次拟合,并且我们应用了计算分数的方法(score) 以获得模型的准确率。如果要可视化我们创建的pipeline,我们可以使用以下命令将其可视化。
from sklearn import set_config
set_config(display='diagram')
pipeline

访问pipeline的元素
我们可以使用以下命令访问每个元素
pipeline.named_steps

pipeline.named_steps['transform_column'].transformers_[0]

pipeline.named_steps['transform_column'].transformers_[1]
方案2改进:采用Scikit-learn pipeline (最少代码)
在Scikit-learn中,还有两个以上的函数与我们在上述实现中使用的函数(Column Transformer和pipeline)相同:
- make_column Transformer
- make_pipeline
这两个函数允许我们简化到更少的代码,它们有什么不同?
实现结构与前面完全相同,唯一的区别是,我们只传递需要的对象,而不是在函数内部传递元组。正如您在下面看到的,我没有给(SimpleImputer、standardscaler和Onehotencoder)对象指定特定的名称,而是直接将它们输入到pipeline中。

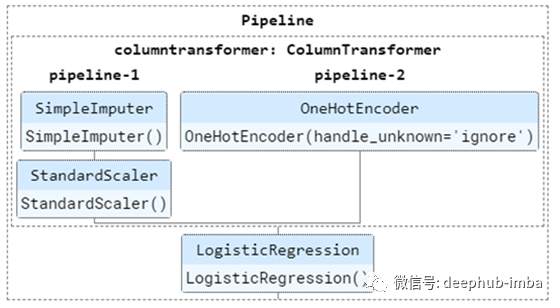
我们没有对pipeline做任何结构上的改变。唯一的区别是解决方案2我们没有任何名称传递给对象,这可以看到可视化的pipeline(下图),我们可以看到,这两个pipeline我们默认为数值和分类处理创建命名pipeline1和2,而上面的实现我们选择设置pipeline的名称。
快速比较上述解决方案
方案1:标准的基本ML工作流
# Replaces missing values
imputer = SimpleImputer(strategy="median")
# scales the numerical feature
scaler = StandardScaler()
# one-hot the categorical features
one_hot=OneHotEncoder(handle_unknown='ignore',sparse=False)
# Define the classifier
lr = LogisticRegression()
# learn/train/fit from the data
imputer.fit(X_train[numeric_features])
imputed=imputer.transform(X_train[numeric_features])
scaler.fit(imputed)
scaled=scaler.transform(imputed)
one_hot.fit(X_train[categorical_features])
cat=one_hot.transform(X_train[categorical_features])
# Concatenating the scaled and one hot matrixes
Final_train=pd.DataFrame(np.concatenate((scaled, cat), axis=1))
lr.fit(Final_train, y_train)
# Predict on the test set-using the trained classifier-still need to do the transformations
X_test_filled = imputer.transform(X_test[numeric_features])
X_test_scaled = scaler.transform(X_test_filled)
X_test_one_hot = one_hot.transform(X_test[categorical_features])
X_test=pd.DataFrame(np.concatenate((X_test_scaled, X_test_one_hot), axis=1))
lr.score(X_test,y_test)
方案2:采用Scikit-learn pipeline
from sklearn.pipeline import pipeline
from sklearn.compose import ColumnTransformer
numeric_transformer = pipeline(steps=[
('meanimputer', SimpleImputer(strategy='mean')),
('stdscaler', StandardScaler())
])
categorical_transformer = pipeline(steps=[
('onehotenc', OneHotEncoder(handle_unknown='ignore'))
])
col_transformer = ColumnTransformer(transformers=[('numeric_processing',numeric_transformer, numeric_features),
('categorical_processing', categorical_transformer, categorical_features)
pipeline = pipeline([
('transform_column', col_transformer),
('logistics', LogisticRegression())
])
pipeline.fit(X_train, y_train)
pipeline.score(X_test, y_test)
方案2改进
from sklearn.compose import make_column_transformer
from sklearn.pipeline import make_pipeline
numeric_transformer = make_pipeline((SimpleImputer(strategy='mean')),
(StandardScaler()))
categorical_transformer = make_pipeline(OneHotEncoder(handle_unknown='ignore'))
col_transformer = make_column_transformer((numeric_transformer, numeric_features),
(categorical_transformer, categorical_features))
pipeline = make_pipeline(col_transformer,LogisticRegression())
pipeline.fit(X_train, y_train)
pipeline.score(X_test, y_test)
通过查看以上代码片段,我们了解到如何在工作流程中采用pipeline,并得得到的更干净,维护良好的代码以及更少的代码行数:我们从大约30行代码减少到20行代码。
结论
在本文中,我尝试向您展示了pipeline的功能,特别是Scikit-learn库提供的pipeline的功能,一旦理解,后者将是非常通用且易于实现的。我开始使用Scikit-learnpipeline作为数据科学的最佳实践,
精通使用pipeline和更好的ML工作流并不需要太多的练习,但是一旦掌握了它,肯定会让您的生活更轻松。如果您已经了解它们并使用它们,那么我很高兴能刷新您的记忆和技能。谢谢阅读
作者:Sivakar Siva
原文地址:https://medium.com/swlh/how-to-use-scikit-learn-pipeline-for-your-ml-projects-e67d5a7e2c88
deephub翻译组