
1. 背景
Kafka是一个流行队列组件(在AWS上叫MSK),其他的队列还有rocketMQ、rabbitMQ。就我个人而言,我只是一个使用者(调包侠),很多技术细节我记不住,尤其是这几个MQ有什么优势和缺点,只能尴尬一笑。所以快速记录一下kafka的核心属性,方便查阅。
2. Kafka的核心属性
2.1. Broker
Broker是Kafka中的一个服务器实例,包含了一些消息和数据。Broker用来存储收到的消息,并处理消费者和生产者的请求。Kafka集群通常由多个Broker组成。
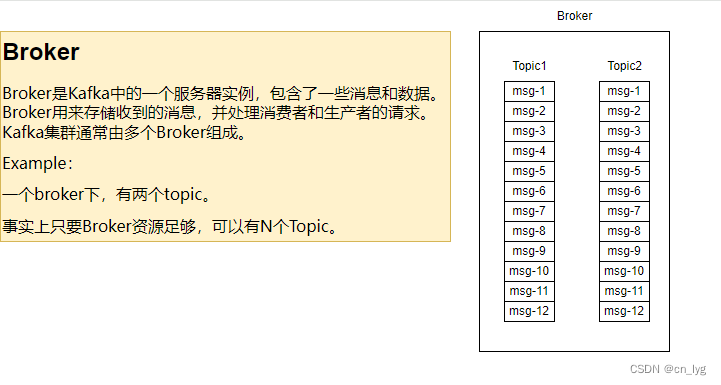
图2.1-1 Broker和Topic
2.2. Partitions
在Kafka中,每个topic被分割成一个或多个分区(partition),每个分区都是一个有序的消息队列。生产者可以对一个topic的多个分区同时进行写操作,消费者也可以对多个分区进行读操作,使得系统的吞吐量得到提升。
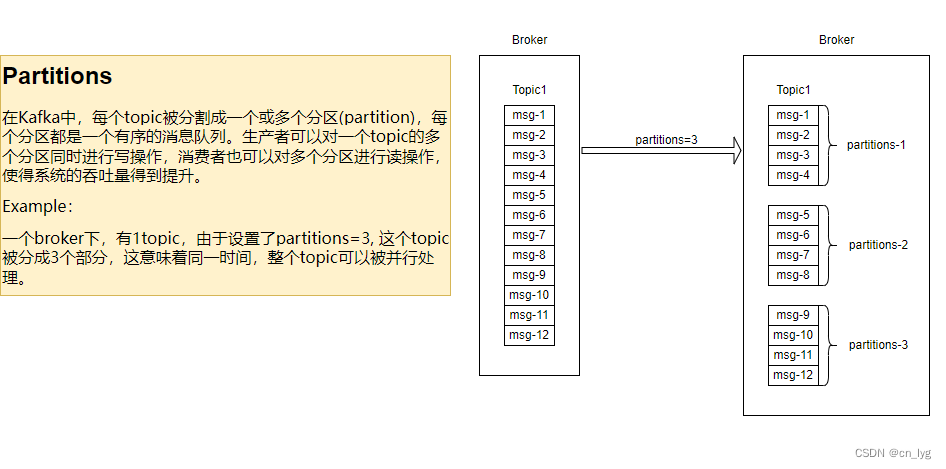
图2.2-1 Partitions=3,一个Topic被分成3个部分
2.3. Replicas
为了确保数据的可靠性和高可用性,Kafka会对每一个分区(partition)进行备份,每个分区有一个或多个副本(replica)。这些副本分布在不同的Broker上,其中一个副本作为主副本(leader),接收所有的读写请求,其他副本为备份副本(follower),只负责复制主副本中的数据。
总的来说,Broker是Kafka的基本组成单位,其中存储了topic的数据,每个topic又被分成一个或多个分区,为了使数据不丢失,每个分区会在不同的Broker上保存副本,这就是数据的复制机制。
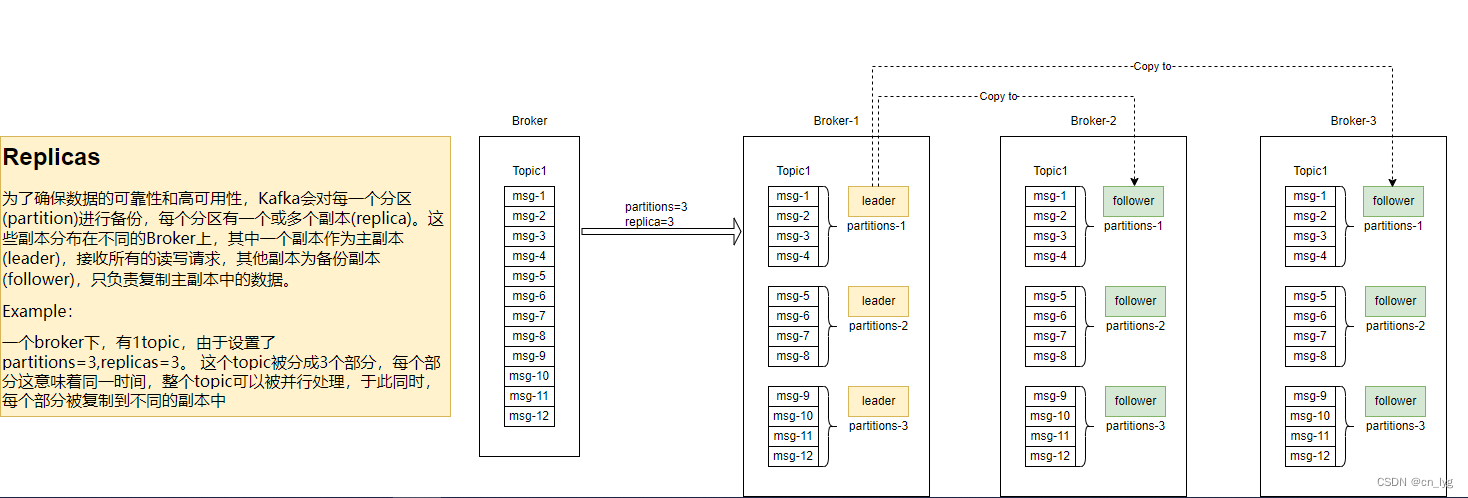
图2.3-1 Partitions=3,Replicas=3. 每个部分有3个副本,以作主备
3. 实践
我们可以使用流行的开源Kafka portal UI工具,在创建Topic界面(如图-3),我们可以看到如下图的每一个属性。

图-3 Kafka新建Topic的属性设置
Broker:集群配置,由Kafka服务提供时就需要决定,至于配置者,由服务提供商设置,当然,这取决于使用者的需求和预算。
Topic Name:必填项,定义这个Topic的名字,Topic名字是区分不同业务的重要凭证。
Number of partitions:对应核心属性Partitions。Kafka的topic由一个或多个分区组成,这个数值表示你希望为当前topic创建的分区数量。每个分区都是消息的有序且不可变的序列,这些消息连续的写入分区并被赋予一个连续的id号,称为offset。
Cleanup policy:控制了Kafka如何处理日志。具体来说,这涉及到Kafka如何管理存储空间,包括删除旧消息以释放空间。有两种可用的清理策略,分别是 "delete" 和 "compact"。
delete
这是默认策略,当日志达到一定的大小或者一段时间后(根据你的配置设定),旧的记录会被删除,以释放空间。这个策略对于那些只对近期数据感兴趣的用例来说非常有用。compact
这个策略会保留最近的每一个唯一键的记录,换句话说,对于具有相同键的记录,只有最近的记录会被保留。这个策略对于那些希望保留所有状态更新的用例来说是有用的,例如在流处理中的状态存储。 你可以在创建主题的时候选择清理策略,在创建之后也可以通过修改配置来改变策略。
Replication Factor
复制因子,对应核心属性**Replicas**。是一个设置项,用来指定我们希望为每一个 partition 创建多少个副本。举个例子,如果我们设置 Replication Factor 为 3,那么每当生产者向 Kafka 发送一条消息时,Kafka 会在 3 个 broker 上分别存储这条消息的副本。这样,即使有 1 或者 2 个 broker 宕机,我们仍然可以从剩余的 broker 上获取这条消息。 当然,这个 "Replication Factor" 的设定需要考虑实际情况。比如说,如果我们的 Kafka 集群只有两个 broker,那么 replication factor 的值设定就不能超过 2,因为没有足够的 broker 来存储更多的副本。同样,如果我们的 Kafka 集群 broker 非常多,例如有 10 台,那么我们可能就不需要把 replication factor 设得太大,如设为 10,因为这会增加 Kafka 的存储负担和网络传输压力,而且大多数场景下,10 台 broker 不会同时宕机,可以适当降低这个值。Min In Sync Replicas
此值是关于数据可用性和持久性的设置。它定义了Producer在认为写操作成功前需要等待多少个副本在同步状态,即已经接收到写操作。例如,如果你将其设置为2,那在一个写操作完成并返回ACK成功之前,至少需要有两个副本(包括Leader本身)将数据写入。 使用一个现实世界的比喻来理解的话,可以将"Replication Factor"想象成你家有多少把钥匙,而"Min In Sync Replicas"则是在你离家时,你希望至少有几把钥匙放在安全的地方。所以,虽然这两个设置都涉及到副本,但它们关注的是不同的方面并起到各自的作用。
Time to retain data (in ms)
这个设置项决定了每一条消息在Kafka中被保存的时间。超过这个时间,消息将会被清理掉以释放空间。单位是毫秒。例如,如果你设置的是86400000毫秒,那么数据会被保存24小时。Max size on disk in GB
这个设置项决定了一个topic能占用的磁盘空间的大小。如果一个topic的大小超过了这个设置,那么Kafka会开始删除这个topic的旧消息,直到其大小低于设置的最大值。单位是GB。Maximum message size in bytes
这个设置项限制了Kafka接收的单条消息的最大大小。如果生产者试图发送大于这个设置值的消息,那么消息将不会被接收。单位是字节。这个设置需要根据你的使用场景来进行调整。如果你的应用需要发送较大的消息,那么你可能需要调高这个值。
4. 参考
ChatGPT
标签:
kafka
本文转载自: https://blog.csdn.net/cn_lyg/article/details/138811304
版权归原作者 cn_lyg 所有, 如有侵权,请联系我们删除。
版权归原作者 cn_lyg 所有, 如有侵权,请联系我们删除。