
使用pyspark编写StructStreaming的入门案例,如有雷同,纯属巧合,所有代码亲测可用。
一、SparkStreaming 的不足
1.基于微批,延迟高不能做到真正的实时
2.DStream基于RDD,不直接支持SQL
3.流批处理的API应用层不统一,(流用的DStream-底层是RDD,批用的DF/DS/RDD)
4.不支持EventTime事件时间
5.数据的Exactly-Once(恰好一次语义)需要手动实现
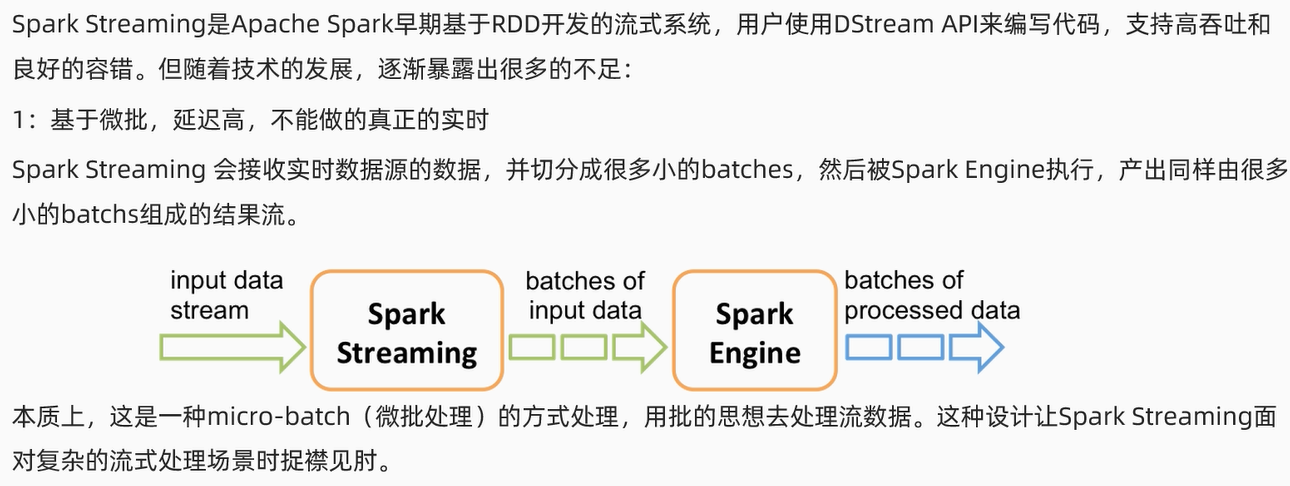


二、StructuredStreaming 的介绍
Spark在2016年Spark2.0版本中发布了新的流计算的API:Structured streaming结构化流。Structured streaming是一个基于SparkSOL引擎的可扩展、容错的全新的流处理引擎。
structured Streaming统一了流、批的编程模型,可以让用户像编写批处理程序一样简单地编写高性能的流处理程序Structured streaming并不是对Spark Streaming的简单改进,而是吸取了在开发SparkSQL和Sparkstreaming过程中的经验教训,以及Spark社区和Databricks众多客户的反馈,重新开发的全新流式引擎,致力于为批处理和流处理提供统一的高性能API。
在Structured streaming这个新的引擎中,也实现了之前在SparkStreaming中没有的一些功能,比如Event Time(事件时间)的支持,Stream-Streamjoin(2.3.0),Continuous Processing毫秒级延迟(2.3.0)。同时也考虑了和Spark 其他组件更好的集成。
Structured Streaming Programming Guide - Spark 3.5.3 Documentation
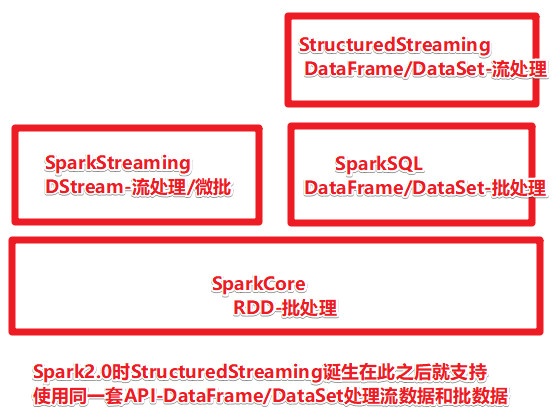
三、编程模型
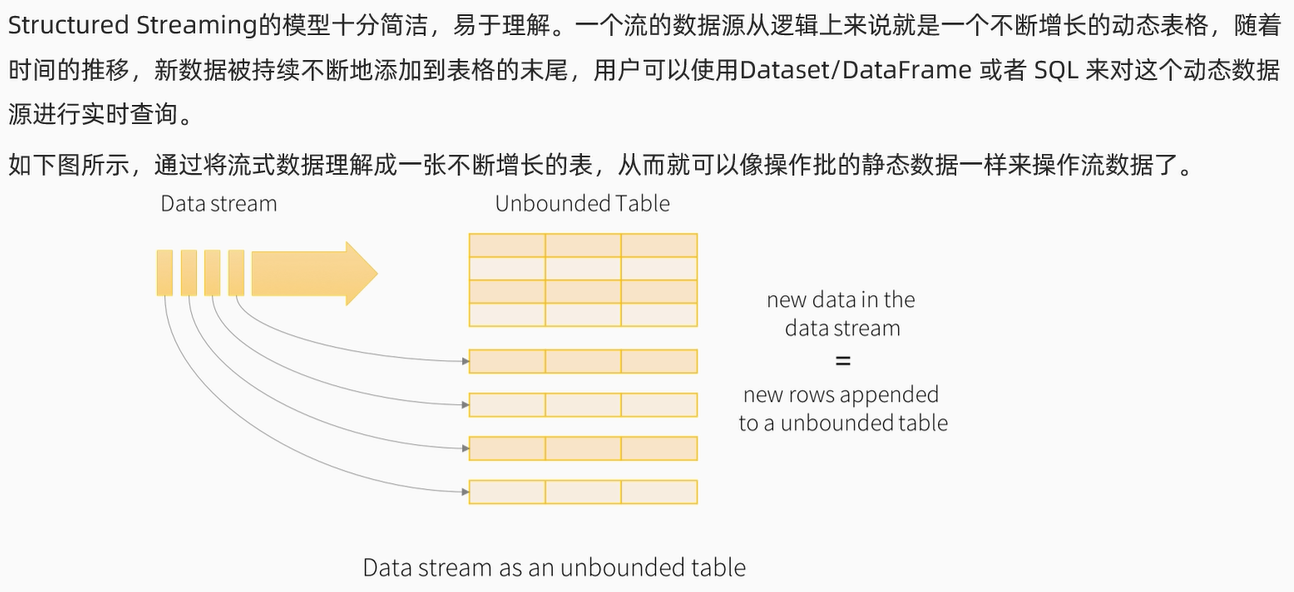
四、Source
Structured Streaming Programming Guide - Spark 3.5.3 Documentation

案例一:Socket
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
os.environ['HADOOP_USER_NAME'] = 'root'
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "bigdata01") \
.option("port", 9999) \
.load()
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
spa
版权归原作者 二进制_博客 所有, 如有侵权,请联系我们删除。