
Autogen是一个卓越的人工智能系统,它可以创建多个人工智能代理,这些代理能够协作完成任务,包括自动生成代码,并有效地执行任务。
在本文中,我们将深入探讨Autogen,并介绍如何让AutoGen使用本地的LLM
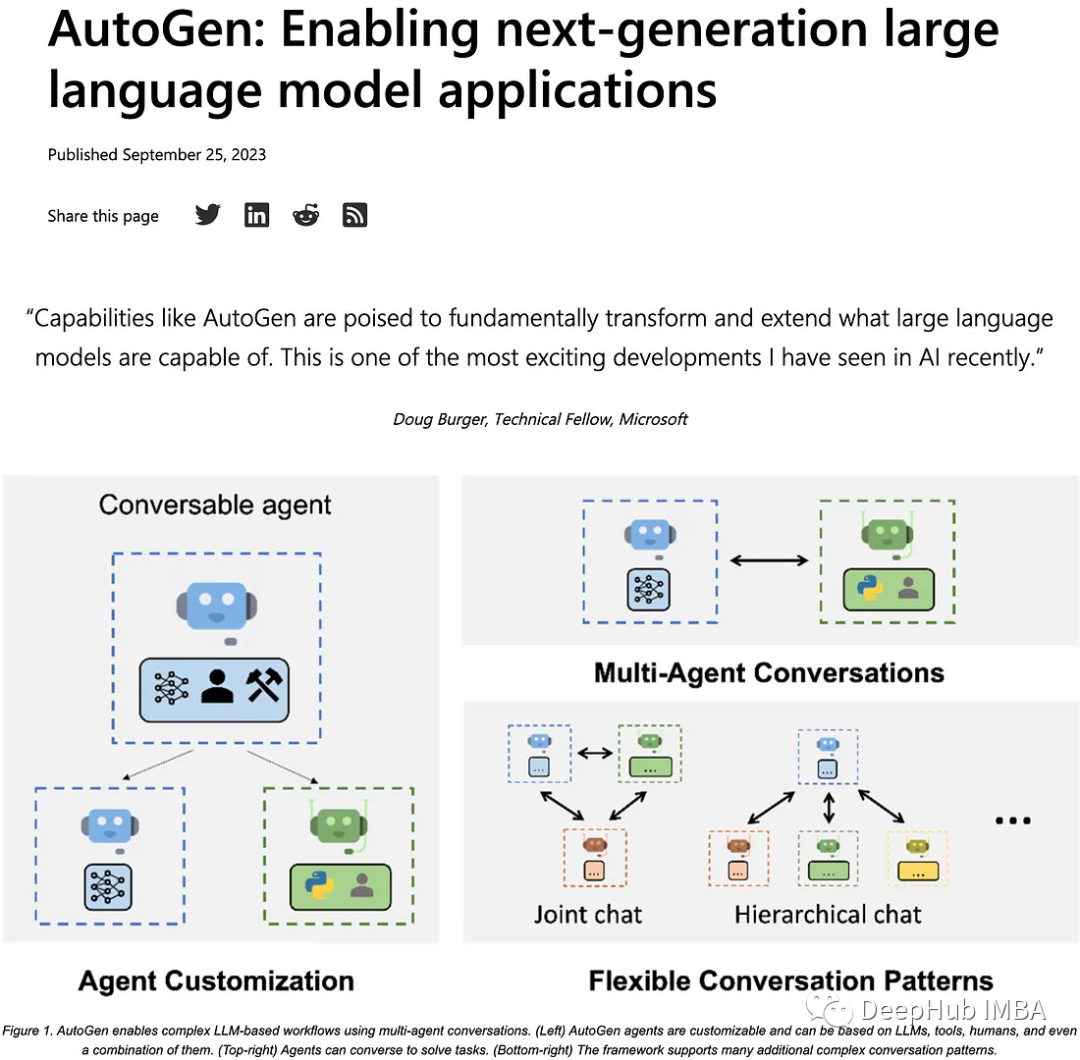
AutoGen
Autogen能够设置多个人工智能代理,它们协同工作以实现特定目标。以下截图来自微软官方博客
使用conda创建环境:
conda create -n pyautogen python=3.10
conda activate pyautogen
AutoGen需要Python版本>= 3.8。它可以从pip安装:
pip install pyautogen
编辑Python脚本(app.py),导入Autogen并设置配置。此配置包括定义想要使用的模型(例如,GPT 3.5 turbo)并提供API密钥。

目前AutoGen只能使用OpenAI的API,所以我们在后面介绍如何使用本地的LLM。
可以定义多个代理来处理不同的角色或任务,比如下面就创建了2个角色
autogen.AssistantAgent(assistantname="CTO",Illm_config=llm_config)
autogen.AssistantAgent(assistantname="CEO", Illm_config=llm_config)
定义任务和说明:希望代理执行的特定任务。这可以是任何指令,从编码到数据分析。

这样代理将根据指示开始执行任务。Assistant代理使用结果或代码片段进行响应。
使用本地的LLM
下面我们将演示如何让autogen使用本地的LLM。这里将使用FastChat作为LLM的本地媒介。
FastChat为其支持的模型提供了与OpenAI兼容的api,所以可以使用FastChat作为OpenAI api的本地替代。但是它的代码需要稍加修改才能正常工作。
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
ChatGLM-6B是基于通用语言模型(General language model, GLM)框架的开放式双语语言模型,具有62亿个参数。ChatGLM2-6B是其第二代产品。
git clone https://huggingface.co/THUDM/chatglm2-6b
都下载完成后就可以使用了,先启动控制器:
python -m fastchat.serve.controller
然后就是启动模型工作线程。
python -m fastchat.serve.model_worker --model-path chatglm2-6b
最后是API:
python -m fastchat.serve.openai_api_server --host localhost --port8000
注意:如果遇到这样的错误
/root/anaconda3/envs/fastchat/lib/python3.9/runpy.py:197in_run_module_as_main│
││
│194│main_globals=sys.modules["main"].dict│
│195│ifalter_argv: │
│196││sys.argv[0] =mod_spec.origin│
│❱197│return_run_code(code, main_globals, None, │
│198│││││"main", mod_spec) │
│199│
│200defrun_module(mod_name, init_globals=None, │
注释掉fastchat/protocol/ api_protocol.py和fastchat/protocol/openai_api_protocol.py中包含finish_reason的所有行将解决问题。修改后的代码如下:
classCompletionResponseChoice(BaseModel):
index: int
text: str
logprobs: Optional[int] =None
# finish_reason: Optional[Literal["stop", "length"]]
classCompletionResponseStreamChoice(BaseModel):
index: int
text: str
logprobs: Optional[float] =None
# finish_reason: Optional[Literal["stop", "length"]] = None
使用下面的配置,autogen.oai.Completion和autogen.oai.ChatCompletion可以直接访问模型。
fromautogenimportoai
# create a text completion request
response=oai.Completion.create(
config_list=[
{
"model": "chatglm2-6b",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL", # just a placeholder
}
],
prompt="Hi",
)
print(response)
# create a chat completion request
response=oai.ChatCompletion.create(
config_list=[
{
"model": "chatglm2-6b",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL",
}
],
messages=[{"role": "user", "content": "Hi"}]
)
print(response)
在本地也可以使用多个模型:
python -m fastchat.serve.multi_model_worker \
--model-path lmsys/vicuna-7b-v1.3 \
--model-names vicuna-7b-v1.3 \
--model-path chatglm2-6b \
--model-names chatglm2-6b
那么推理的代码如下(注意,你要有多卡或者显存足够):
fromautogenimportoai
# create a chat completion request
response=oai.ChatCompletion.create(
config_list=[
{
"model": "chatglm2-6b",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL",
},
{
"model": "vicuna-7b-v1.3",
"api_base": "http://localhost:8000/v1",
"api_type": "open_ai",
"api_key": "NULL",
}
],
messages=[{"role": "user", "content": "Hi"}]
)
print(response)
总结
Autogen代理可以根据需要执行代码、生成报告和自动执行任务。他们可以协同高效地工作,节省时间和精力,我们还介绍了如何在本地使用,这样可以在本地进行测试,而不需要OpenAI的API。
微软的Autogen官网
https://microsoft.github.io/autogen/docs/Examples/AutoGen-AgentChat/