

您是否曾经想过Netflix是如何向您推荐您感兴趣的电影?或者亚马逊如何向您推荐难以抵制购买的产品?
显然,这些网站已经弄清了您喜欢看或买的东西。他们在后台运行一段代码,该代码可以在线收集有关用户行为的数据,并预测该用户对特定内容或产品的喜好。这种系统称为“推荐系统。

广义上讲,有两种开发推荐系统的方法。在一种方法中,系统考虑个人消费的内容的属性。例如,如果您有一天在Netflix上观看了《黑客帝国》三部曲,那么Netflix就会了解到您喜欢科幻电影,因此更有可能向你推荐其他科幻电影。换句话说,给你的推荐基于电影类型—在这种情况下是科幻类型。
在另一种方法中,推荐系统会考虑与您的口味相似的其他人的喜好,并向您推荐他们所观看的电影。与第一种方法相反,给你的推荐是基于多个用户的行为,而不是基于正在观看的内容的属性。这种方法称为协同过滤。
在我们考虑的示例中,这两种方法最有可能向您推荐科幻电影,但它们将采取不同的途径得出结论。
效用矩阵
协同过滤的重要部分是识别出具有相似偏好的观众。尽管Netflix采用多种方式来收集有关用户喜好的信息,但为简单起见,我们假设它已要求观众以1-5的评分来评价电影。我们进一步假设只有7部电影需要考虑(哈利·波特三部曲,《暮光之城》和《星球大战》三部曲),并且只有四名观众被要求对其评分。
图1显示了四个精选观众提供的评分。这样的表(每一种产品的评分按列排列,每一位用户的评分按行排列)被称为效用矩阵。空格表示某些用户未对某些电影进行评分。
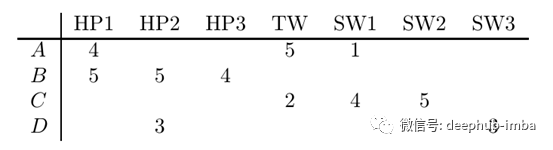
图1:一个实用矩阵,捕获四个用户对七部电影的评分。每一种电影的评分按列排列。
实际上,Netflix每天都有成千上万的节目供数百万观众使用。相应地,它的实际效用矩阵将具有数百万行,跨越数千列。此外,随着系统不断收集有关用户行为的信息,矩阵会动态更新。
通过查看图1中的效用矩阵,我们可以得出一些显而易见的结论:
· 观众A喜欢《哈利·波特1》和《暮光之城》,但不喜欢《星际大战1》
· 观众B喜欢《哈利·波特》三部曲的所有电影,但她不喜欢什么似乎是一个秘密
· 观众C喜欢《星球大战1》和《星球大战2》,但不喜欢《暮光之城》
· 观众D不介意在无聊的日子里观看《哈利·波特2》和《星球大战2》但他们都不是她的最佳选择。
总之,观众A和B的口味相似,就像他们都喜欢《哈利·波特1》。相反,观众A和C的口味不同,因为观众A喜欢暮光之城,但观众C根本不喜欢。同样,A不喜欢《星球大战》,但C喜欢。推荐系统需要用一种方法来比较不同观众的评分,并告诉我们他们的口味有多接近。
量化相似度
有很多不同的指标可以比较两个观众提供的评分,并判断他们是否具有相似的品味。在本文中,我们将学习其中两个:Jaccard距离和余弦距离,具有相似品味的观众距离更近。
Jaccard距离
Jaccard距离是另一个量的函数,这个量被称为Jaccard相似度。根据定义,集合S和T的Jaccard相似度是S和T的交集大小与它们的并集大小之比。从数学上讲,它可以写成:
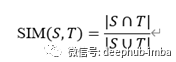
集合A和B之间的Jaccard距离d (x, y)由下式给出:

余弦距离
两个向量A和B之间的余弦距离是角度d (A,B),由下式给出:
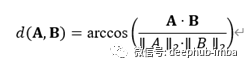
其中
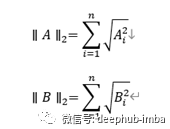
分别是向量A和B的范数,n是要考虑的产品(在这种情况下为电影)的数量。余弦距离在0到180度之间变化。
计算效用矩阵的距离度量
为了更好地理解这些距离度量,让我们使用效用矩阵(图1)中显示的数据来计算距离。
计算Jaccard距离
计算Jaccard距离的第一步是以集合的形式写出用户评过分的电影。与观众A和B对应的集合是:
A = {HP1, TW, SW1}
B = {HP1, HP2, HP3}
集合A和集合B的交集是这两个集合共有的元素集。A和B的并集是A和B中所有元素的集合。因此,
A∩B= {HP1}
A∪B= {HP1,HP2, HP3, TW, SW1}.
A和B之间的Jaccard距离为:

类似地,A和C之间的Jaccard距离。根据此度量,与观众A和B相比,观众A和C之间有更多相似之处。这与通过效用表直观分析所揭示的完全相反。因此,Jaccard 距离不适用于我们正在考虑的数据类型。
计算余弦距离:
现在让我们计算观众A和B之间以及观众A和C之间的余弦距离。为此,我们首先创建一个代表其评分的向量。为简单起见,我们假定空格等于零评分。这是一个值得商榷的选择,因为评分为零也可能表示观众给出的较差的评分。与观众A,B和C对应的向量为:
A=[4,0,0,5, 1,0,0]
B=[5,5,4,0,0,0,0]
C=[0,0,0,2,4,5, 0] .
A和B之间的余弦距离为:
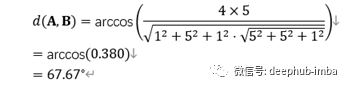
类似地,A和C之间的余弦距离为:
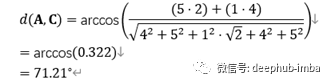
这是合理的,因为它表明A稍微靠近B比于与C的距离。
评分转换
通过对矩阵中的每个元素应用定义明确的规则,我们还可以转换效用矩阵中捕获的数据。在本文中,我们将学习两个转换:舍入和标准化。
输入数据
观众通常会对相似的电影给予类似的评分。例如,观众B对所有哈利.波特电影都给予了很高的评分,而观众C对“星球大战1”和“星球大战2”给予了很高的评价,可以通过将规则四舍五入来消除评分的相似性。例如,我们可以设置一个规则,将评分3、4和5舍入为1,并将等级1和2视为空白。应用此规则后,我们的效用矩阵变为:
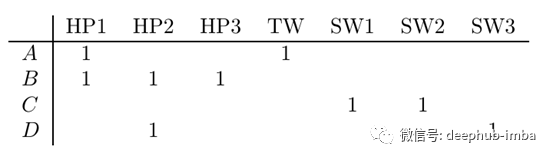
在评分舍入的情况下,观众A和C对应的集合的交集为空集合。这会将Jaccard相似度降低到最小值零,并且将Jaccard距离升高到最大值1。而且,与观众A和B对应的集合之间的Jaccard距离小于1,这使A比B更接近C。请注意,当使用原始用户评分来计算距离时,Jaccard距离度量无法提供这种对用户行为的了解。找到具有舍入值的余弦距离会得出相同的结论。
标准化评级
转换原始观众评分的另一种方法是对其进行标准化。通过标准化,我们的意思是从每个评分中减去该对应观众的平均评分。例如,让我们找到平均评分为10/3的观众A的标准化评分。因此,她的标准化评分为
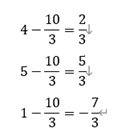
下面给出了所有值均经过标准化的效用矩阵。请注意,这会将较高的评分值转换为正值,而将较低的评分转换为负值。

图3:具有标准化值的效用矩阵
由于效用矩阵中的各个值都发生了变化,因此我们预期余弦距离会发生变化。但是,Jaccard 距离保持不变,因为它仅取决于两个用户都评价的电影数量,而不取决于给定的评价。
使用标准化值,对应于观众A,B和C的向量为:

A和B之间以及A和C之间的余弦距离为:

虽然针对标准化评分的余弦距离计算不会改变原始结论(A更接近B,而不是C),但确实会放大向量之间的距离。向量A和C似乎在标准化评分之下,距离特别远,尽管两者(B和C与A的距离)都不是很接近。
总结
推荐系统是互联网经济的核心。它们是使我们迷上社交媒体以及在线购物和娱乐平台的计算机程序。推荐系统的工作是预测特定用户可能会购买或消费的东西。做出预测所依赖的两种广泛方法之一是查看其他人(尤其是那些与所讨论的用户具有相似偏好的人)购买或消费的东西。该方法的关键部分是量化用户之间的相似性。
计算Jaccard和余弦距离是用来量化用户之间相似度的各种方法中的两种。Jaccard距离考虑了用户评分的产品数量,但未考虑评分本身的实际值。相反地,余弦距离会考虑评分的实际值,但不会考虑两个用户都评价的产品数量。由于在计算距离方面存在这种差异,因此,Jaccard 和余弦距离度量有时会导致相互矛盾的预测。在某些情况下,我们可以通过根据明确定义的舍入规则来避免此类冲突。
也可以从用户给出的每个评分中减去该用户给出的平均评分来转换评分,这个过程称为标准化,不会影响Jaccard距离,但是会放大余弦距离。
参考
1.Mining of Massive Datasets.
作者:Madhukara Putty
Deephub翻译组:shzhang
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********