
Ubuntu 中docker安装和使用
- 安装VMware16
- 安装Ubuntu22.04
- 安装docker
Docker的主要作用
起到一个“容器”(代码+环境)的作用,解决了软件跨环境迁移导致的版本不兼容等问题。使用沙箱机制,相互之间没有任何接口,且性能开销极低。
Docker的架构图

- 镜像(image):Docker镜像,相当于一个root文件系统。镜像相当于java中的一个类,是一个模板,一个镜像可以生成多个容器。 (镜像是一种轻量级的,可执行的独立软件包,用来打包软件运行环境和基于环境开发的软件,它包含运行某个软件的所需的所有内容,包括代码,运行时,库,环境变量和配置文件。)
- 容器(container):镜像和容器的关系就像是类与对象的关系一样,镜像是静态的定义,容器是镜像运行时的实体,容器可以被创建,启动,停止,删除,暂停等。 (Docker利用容器独立运行一个或一组应用。容器时是镜像创建的运行实例。可以把容器看成一个简易版本的linux的运行环境,包括运行在里面的应用程序。Docker启动是秒级的。容器只保留了内核,把硬件,网络,打印机等不相关的统统去除了,所以运行快。)
- 仓库(repository):仓库可以看成是一个代码控制中心,用来保存镜像。
Docker的安装
卸载系统自带的旧版本
sudo apt-get remove docker docker-engine docker.io containerd runc
获取软件最新源
sudo apt-get update
安装apt依赖包
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
安装几个工具软件
apt-get install ca-certificates curl gnupg lsb-release
安装GPG证书,使用阿里云的镜像源
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
下载仓库文件
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
安装docker软件
sudo apt-get install docker-ce docker-ce-cli containerd.io
sudo apt-get install docker-compose-plugin
图形化界面 Portainer
$ docker volume create portainer_data
$ docker run --name portainer
-d -p 8000:8000 -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock
-v portainer_data:/data portainer/portainer
打开localhost:9000
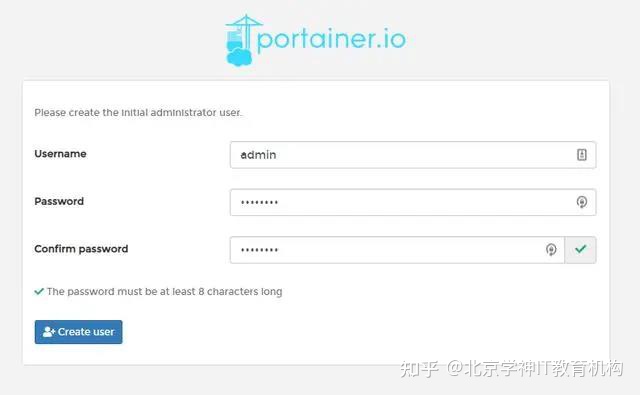
设置图形化界面Portainer开机自启动后可开机直接通过浏览器localhost:9000/访问docker:
1、设置docker开机自启动
systemctl disable docker.service
2、设置Portainer对应的容器开机自启动
docker update --restart=always <CONTAINER ID>
docker的使用
docker状态
启动docker
sudo service docker start
或
systemctl start docker
停止docker
sudo service docker stop
或
systemctl stop docker
重启docker
sudo service docker restart
或
systemctl restart docker
查看当前docker的状态
systemctl status docker
测试
sudo docker run hello-world
帮助命令
sudo docker version (查询版本号)
sudo docker info (查询docker系统信息)
sudo docker --help (指令)
镜像操作
列出镜像
sudo docker images
REPOSITORY:当前镜像的仓库源;
TAG:镜像的标签;
IMAGE ID:镜像的ID(唯一的主键);
CREATED:镜像的创建时间;
SIZE:镜像的大小。
docker images [参数]
-a #列出本地所有的镜像,含中间映像层
-q #只列出镜像ID
-qa #-a 与 -q 的组合参数
-digess #一些镜像的摘要说明
--no-trunc #显示完整的镜像信息
搜索镜像
镜像的官方网址:https://hub.docker.com/
docker search [镜像名]
获取镜像(不指定镜像版本,则默认下载最新版本)
sudo docker pull [镜像名]
或
docker pull [镜像名]:lastest
docker pull [镜像名]:[TAG] #使用版本标签号选择要下载的版本
sudo docker pull ubuntu:13.10
sudo docker pull mysql:5.7
使用镜像
sudo docker run [镜像名]
删除镜像
sudo docker rmi [镜像名]
或
docker rmi -f [镜像名] #强制删除某个镜像
docker rmi -f [镜像名1 镜像名2 镜像名3] #批量删除多个镜像
容器操作
启动容器,以下命令使用镜像启动一个容器,参数为以命令行模式进入该容器:
docker run [OPTIONS] IMAGE
OPTIONS说明:
--name [容器名] #为容器指定一个名字
-d #后台运行容器,并返回容器ID,也即启动守护式容器(使用exit退出后,容器在后台运行,不会真正退出)
-i #以交互模式运行容器,如果不加的话,容器没有使用时就会自动停止,通常和-t同时使用
-t #为容器重新分配一个伪输入终端,通常与-i同时使用
-p #随机端口映射
sudo docker run -it ubuntu:20.04 /bin/bash
docker run -it --name mycentos centos /bin/bash
-i: 交互式操作。
-t: 终端。
ubuntu: ubuntu 镜像。
/bin/bash:#进入容器的初始化指令
放在镜像名后的是命令,这里希望有个交互式Shell,因此用的是 /bin/bash。
启动容器
docker start [容器ID]
重启容器
docker restart [容器ID]
停止容器
docker stop [容器ID]
强制关闭容器
docker kill [容器ID]
查看容器
sudo docker ps -a # 查看所有容器
docker ps -q #查看当前运行着的容器,返回ID
docker ps -l #查看上一个容器
docker ps -n 3 #查看上三个运行过的容器
进入正在运行的环境
docker attach [容器ID] #直接进入容器,启动命令的终端,不会启动新的进程
docker exec -it [容器ID] /bin/bash #在容器中打开新的终端,并且可以启动新的进程
退出容器
exit #容器停止,但退出容器内部
ctrl+P+Q #容器不停止,但退出容器内部
停止容器
sudo docker stop <容器 ID>
删除已停止容器
sudo docker rm [容器ID] #删除已经停止的容器
docker rm -f [容器ID] #可强制删除没有停止的容器
docker rm -f $(docker ps -qa) #删除全部容器
数据卷
概念
数据卷是宿主机中的一个目录或文件,当容器目录和数据卷目录绑定后,对方的修改会立即同步,一个数据卷可以被多个容器同时挂载,一个容器可以挂载多个容器。
作用
- 容器数据持久化
- 外部机器和容器的间接通信
- 容器之间的数据交换
数据卷的配置
docker run -it -v [主机目录]:[容器目录]
#例如
docker run -it -v /home/cesi:/home --name mycentos centos /bin/bash
写入文件
ecoh "abcd" > a.txt
查看文件内容
cat [文件名]
新建 文件/文件夹
touch [文件名]
mkdir [文件夹名]
删除文件
rm -rf [文件名]
是否挂载成功
docker inspect [容器id] #返回容器日志,查看Mounts项的Source即可找到宿主机挂载点,Destination即为容器中对应的目录
注意事项
- 目录必须是绝对路径
- 目录不存在会自动创建
为自己的项目构建镜像
示例项目代码:https://github.com/gzyunke/test-docker
这是一个 Nodejs + Koa2 写的 Web 项目,提供了简单的两个演示页面。
软件依赖:nodejs
项目依赖库:koa、log4js、koa-router
编写 Dockerfile
FROM node:11
MAINTAINER easydoc.net
# 复制代码
ADD . /app
# 设置容器启动后的默认运行目录
WORKDIR /app
# 运行命令,安装依赖
# RUN 命令可以有多个,但是可以用 && 连接多个命令来减少层级。
# 例如 RUN npm install && cd /app && mkdir logs
RUN npm install --registry=https://registry.npm.taobao.org
# CMD 指令只能一个,是容器启动后执行的命令,算是程序的入口。
# 如果还需要运行其他命令可以用 && 连接,也可以写成一个shell脚本去执行。
# 例如 CMD cd /app && ./start.sh
CMD node app.js
Dockerfile文档
实用技巧:
如果你写 Dockerfile 时经常遇到一些运行错误,依赖错误等,你可以直接运行一个依赖的底,然后进入终端进行配置环境,成功后再把做过的步骤命令写道 Dockerfile 文件中,这样编写调试会快很多。
例如上面的底是node:11,我们可以运行
docker run -it -d node:11 bash,跑起来后进入容器终端配置依赖的软件,然后尝试跑起来自己的软件,最后把所有做过的步骤写入到 Dockerfile 就好了。
掌握好这个技巧,你的 Dockerfile 文件编写起来就非常的得心应手了。
Build 为镜像(安装包)和运行
编译
docker build -t test:v1 .
-t设置镜像名字和版本号
命令参考:https://docs.docker.com/engine/reference/commandline/build/
运行
docker run -p 8080:8080 --name test-hello test:v1
挂载演示
bind mount` 方式用绝对路径 `-v D:/code:/app
volume` 方式,只需要一个名字 `-v db-data:/app
示例:
docker run -p 8080:8080 --name test-hello -v D:/code:/app -d test:v1
多容器通信
要想多容器之间互通,从 Web 容器访问 Redis 容器,我们只需要把他们放到同个网络中就可以了。
文档参考:https://docs.docker.com/engine/reference/commandline/network/
创建一个名为
test-net
的网络:
docker network create test-net
运行 Redis 在
test-net
网络中,别名
redis
docker run -d --name redis --network test-net --network-alias redis redis:latest
修改代码中访问
redis
的地址为网络别名

运行 Web 项目,使用同个网络
docker run -p 8080:8080 --name test -v D:/test:/app --network test-net -d test:v1
查看数据
http://localhost:8080/redis
容器终端查看数据是否一致
redis-cli
get count
docker-compose 创建容器
要把项目依赖的多个服务集合到一起,我们需要编写一个
docker-compose.yml
文件,描述依赖哪些服务
参考文档:https://docs.docker.com/compose/
创建
docker-compose.yml
文件,在文件目录打开终端,输入
docker-cmpose up
创建并运行容器。
version: "3.7"
services:
app:
build: ./
ports:
- 80:8080
volumes:
- ./:/app
environment:
- TZ=Asia/Shanghai
redis:
image: redis:5.0.13
volumes:
- redis:/data
environment:
- TZ=Asia/Shanghai
volumes:
redis:
容器默认时间不是北京时间,增加 TZ=Asia/Shanghai 可以改为北京时间
在后台运行只需要加一个 -d 参数 docker-compose up -d
查看运行状态:docker-compose ps
停止运行:docker-compose stop
重启:docker-compose restart
重启单个服务:docker-compose restart service-name
进入容器命令行:docker-compose exec service-name sh
查看容器运行log:docker-compose logs [service-name]
发布和部署
上传自己的镜像
- 首先你要先 注册一个账号
- 创建一个镜像库
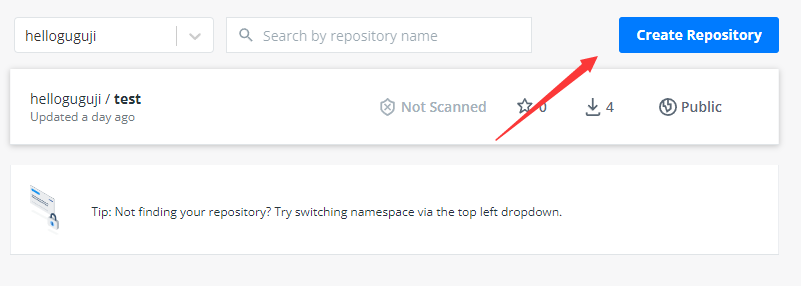
- 命令行登录账号:
docker login -u username - 新建一个tag,名字必须跟你注册账号一样
docker tag test:v1 username/test:v1 - 推上去
docker push username/test:v1 - 部署试下
docker run -dp 8080:8080 username/test:v1
docker-compose 中也可以直接用这个镜像了
version: "3.7"
services:
app:
# build: ./
image: helloguguji/test:v1
ports:
- 80:8080
volumes:
- ./:/app
environment:
- TZ=Asia/Shanghai
redis:
image: redis:5.0.13
volumes:
- redis:/data
environment:
- TZ=Asia/Shanghai
volumes:
redis:
备份和迁移数据
迁移方式介绍
容器中的数据,如果没有用挂载目录,删除容器后就会丢失数据。
前面我们已经讲解了如何 挂载目录
如果你是用
bind mount
直接把宿主机的目录挂进去容器,那迁移数据很方便,直接复制目录就好了
如果你是用
volume
方式挂载的,由于数据是由容器创建和管理的,需要用特殊的方式把数据弄出来。
备份和导入 Volume 的流程
备份:
- 运行一个 ubuntu 的容器,挂载需要备份的 volume 到容器,并且挂载宿主机目录到容器里的备份目录。
- 运行 tar 命令把数据压缩为一个文件
- 把备份文件复制到需要导入的机器
导入:
- 运行 ubuntu 容器,挂载容器的 volume,并且挂载宿主机备份文件所在目录到容器里
- 运行 tar 命令解压备份文件到指定目录
备份 MongoDB 数据演示
- 运行一个 mongodb,创建一个名叫
mongo-data的 volume 指向容器的 /data 目录docker run -p 27018:27017 --name mongo -v mongo-data:/data -d mongo:4.4 - 运行一个 Ubuntu 的容器,挂载
mongo容器的所有 volume,映射宿主机的 backup 目录到容器里面的 /backup 目录,然后运行 tar 命令把数据压缩打包docker run --rm --volumes-from mongo -v d:/backup:/backup ubuntu tar cvf /backup/backup.tar /data/
最后你就可以拿着这个 backup.tar 文件去其他地方导入了。
恢复 Volume 数据演示
- 运行一个 ubuntu 容器,挂载 mongo 容器的所有 volumes,然后读取 /backup 目录中的备份文件,解压到 /data/ 目录
docker run --rm --volumes-from mongo -v d:/backup:/backup ubuntu bash -c "cd /data/ && tar xvf /backup/backup.tar --strip 1"
注意,volumes-from 指定的是容器名字
strip 1 表示解压时去掉前面1层目录,因为压缩时包含了绝对路径
conductor介绍
一 简介
netflix conductor是基于JAVA语言编写的开源流程引擎,用于架构基于微服务的流程。它具备如下特性:
- 允许创建复杂的业务流程,流程中每个独立的任务都是由一个微服务所实现。
- 基于JSON DSL 创建工作流,对任务的执行进行编排。
- 工作流在执行的过程中可见、可追溯。
- 提供暂停、恢复、重启等多种控制模型。
- 提供一种简单的方式来最大限度重用微服务。
- 拥有扩展到百万流程并发运行的服务能力。
- 通过队列服务实现客户端与服务端的分离。
- 支持 HTTP 或其他RPC协议进行数据传送
二 基本概念
1 Task
Task是最小执行单元,承载了一段执行逻辑,如发送HTTP请求等。
- System Task:被conductor服务执行,这些任务的执行与引擎在同一个JVM中。
- Worker Task:被worker服务执行,执行与引擎隔离开,worker通过队列获取任务后,执行并更新结果状态到引擎。Worker的实现是跨语言的,其使用Http协议与Server通信。
conductor提供了若干内置SystemTask:
- 功能性Task: - HTTP:发送http请求- JSON_JQ_TRANSFORM:jq命令执行,一般用户json的转换,具体可见jq官方文档- KAFKA_PUBLISH: 发布kafka消息
- 流程控制Task: - SWITCH(原Decision):条件判断分支,类似于代码中的switch case- FORK:启动并行分支,用于调度并行任务- JOIN:汇总并行分支,用于汇总并行任务- DO_WHILE:循环,类似于代码中的do while- WAIT:一直在运行中,直到外部时间触发更新节点状态,可用于等待外部操作- SUB_WORKFLOW:子流程,执行其他的流程- TERMINATE:结束流程,以指定输出提前结束流程,可以与SWITCH节点配合使用,类似代码中的提前return语句
- 自定义Task: - 对于System Task,Conductor提供了WorkflowSystemTask 抽象类,可以自定义扩展实现。- 对于Worker Task,可以实现conductor的client Worker接口实现执行逻辑。
2 Workflow
- Workflow由一系列需要执行的Task组成,conductor采用json来描述Task的流转关系。
- 除基本的顺序流程外,借助内置的SWITCH、FORK、JOIN、DO_WIHLE、TERMINATE任务,还能实现分支、并行、循环、提前结束等流程控制。
3 Input&Output
Task的输入是一种映射,其作为工作流实例化的一部分或某些其他Task的输出。允许将来自工作流或其他Task的输入/输出作为随后执行的Task的输入。
- Task有自己的输入和输出,输入输出都是jsonobject类型。
- Task可以引用其他Task的输入输出,使用{taskxxx.output}的方式引用。引用语法为json-path,除最基础的${taskxxx.output}的值解析方式外,还支持其他复杂操作,如过滤等,具体见json-path语法。
- 启动Workflow时可以传入流程的输入数据,Task可以通过${workflow.input}的方式引用。
Task实现原子操作的处理以及流程控制操作,Workflow定义描述Task的流转关系,Task引用Workflow或者其它Task的输入输出。通过这些机制,conductor实现了JSON DSL对流程的描述。
三 整体架构

主要分为几个部分:
- Orchestrator: 负责流程的流转调度工作;
- Management/Execution Service: 提供流程、任务的管理更新等操作;
- TaskQueues: 任务队列,Orchestrator解析出来的待执行Task会放到队列中;
- Worker: 任务执行worker,从TaskQueues中获取任务,通过Execution Service更新任务状态与结果数据;
- Database: 元数据&运行时数据库,用于保存运行时的Workflow、Task等状态信息,以及流程任务定义的等原信息;
- Index: 索引数据库,用于存储执行历史;
版权归原作者 urnotlanxi 所有, 如有侵权,请联系我们删除。