
【人工智能概论】 用Pandas读写excel
文章目录
Pandas读取excel用的是它的read_excel方法
- 只读取一个sheet时,返回的是DataFrame类型的数据;
- 同时读取多个sheet时,返回的是字典类型的数据,结构为{name:DataFrame} 。
- 注1:DataFrame是一种表格数据类型,其能展现数据的表格型结构。
- 注2:同时读取多个sheet后续操作不方便,建议一次只读取一个sheet。
一.用read_excel读取excel文件
1.read_excel的基本参数
1.1 io
- 指定excel文件的路径,可以是路径,文件对象。
- 有时因为文件路径包含中文字符串,pandas可能会解析失败,可以使用文件对象来解决。
file='xxxx.xlsx'
f =open(file,'rb')
df = pd.read_excel(f, sheet_name='Sheet1')
f.close()# 切记要手动释放文件。# ------------- with模式 -------------------withopen(file,'rb')as f:
df = pd.read_excel(f, sheet_name='Sheet1')
1.2 sheet_name=0:
- 指定要访问的excel工作表,可以是str、int、list、None类型,默认值是0。
- str类型:指定工作表名称,例,sheet_name=‘Test1’ ;
- int类型:指定从0开始的工作表的索引,例,sheet_name=0 ;
- list类型:指定多个工作表,例,sheet_name=[0, 2, ‘Test3’] ;
- None类型:访问所有的工作表 。
1.3 header=0:
- header是标题行,指定某行作为数据的标题行,即数据的列名,默认首行数据(0-index)作为标题行。
- 若表头不只有一行,可以通过传入列表来指定多个标题行,如header=[0,1]。
- 没有标题行使用header=None。
注:指定标题行后,read_excel将从最后一个标题行的下一行开始读取数据。
1.4 names=None
- 多用于文件数据不具有标题行(表头)的情况,可以用names指定列名,传入的是列表类型,此时要显式的指出header=None,否则会造成首行数据丢失。
1.5 index_col=None
- 指定列索引,传入数据的类型为int或元素都是int的列表,将某列的数据作为DataFrame的行标签,如果传递了一个列表,这些列将被组合成一个多索引。
实际应用中,它更多的是被用于剔除不想要的列。
1.6 skiprows=0
- 跳过指定行数的数据,传入数据类型int类型或元素都是int的列表,分别对应文件开头要跳过的行数(int)或要跳过的行号(0索引列表)。
- 输入是int类型数据n时,跳过前n行开始读取。
- 输入是元素都为int类型的列表时,是将列表内对应编号(从0开始编号)的行跳过。例,skiprows=[0,1,3,5]是把第1,2,4,6行跳过不读取。
1.7 skipfooter=0
- 指定从尾部跳过的行数,即最后几行不读取,输入数据为int型,默认为0,自下向上。
1.8 dtype=None
- 指定某列的数据类型,传入一个对应列名与类型的字典即可,例 {‘A’: np.int64, ‘B’: str}。
1.9 其他参数
- usecols=None: 指定要使用的列,如果没有默认解析所有的列。
- squeeze=False, 布尔值,默认False。 如果解析的数据只有一列,返回一个Series。
- nrows=None: int类型,默认None。 只解析指定行数的数据。
2.数据的数值获取——values
read_excel读取的数据类型是DataFrame类型,不能直接用于运算,因此需要values来获取数值。
- df.values,获取全部数据,返回类型为ndarray(二维);
- df.index.values,获取行索引的向量,返回类型为ndarray(一维);
- df.columns.values,获取列索引的向量(对有表头的方式,是表头标签向量),返回类型为ndarray(一维)。
3.数据切片访问——loc,iloc
- 所用数据
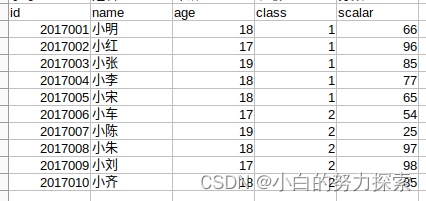
- loc方法是通过行、列的名称或者索引标签来寻找需要的值,是闭区间。
- 与一般的切片操作很相似,只不过是可以用索引标签访问罢了。
data.loc[1]# 索引第二行,返回的数据类型为'pandas.core.series.Series'
data.loc[1].values # 索引第二行,返回的数据类型是'numpy.ndarray'的列表
data.loc[1,'id':'name']# 索引第二行中从列标签为‘id’到‘name’的项,返回的数据类型为'pandas.core.series.Series'
data.loc[1,'id':'name'].values # 索引第二行中从列标签为‘id’到‘name’的项,返回的数据类型为'numpy.ndarray'的列表
- 也可根据条件进行筛选
# 根据'scalar'列中大于60的值筛选
data5 = data.loc[ data.scalar >60]# 也可进行切片操作,选择id,name,scalar三列区域内,scalar列大于60的值
data1 = data.loc[ data.scalar >60,["id","name","scalar"]]
- iloc方法是通过索引行、列的索引位置[index, columns]来寻找值,是前闭后开区间。
- 几乎等于切片操作,但是不能用索引标签来访问。
小结:这两个方法的区别是,loc将参数当作标签处理,iloc将参数当作索引号处理。
- 在有表头的方式中,当列索引使用str标签时,只可用loc,当列索引使用int索引号时,只可用iloc;
- 在无表头的方式中,索引向量也是标签向量,loc和iloc均可使用;在切片中,loc是闭区间,iloc是半开区间。
二.将数据写入excel文件
有两种方法可以进行写入,可以使用to_excel方法或ExcelWriter()类。
1.to_excel方法
- 它可以往一个sheet内写入数据,注意写入时把excel文件关掉。
# 用字典指定数据
data ={'名字':['张三','李四'],'分数':[100,100]}# 将数据转化成DataFrame格式以便于传入excel
df= pandas.DataFrame(data)# 写入数据到指定文件中
df.to_excel('1.xlsx', sheet_name='Sheet1',index=False)# index = False表示不写入索引
2.ExcelWriter()
- 它可以一次性向同一个excel的不同sheet中写入对应的表格数据。
- 下面代码为在1.xlsx中写入sheet1,sheet2两个表
df1 = pandas.DataFrame({'名字':['张三','王四'],'分数':[100,100]})
df2 = pandas.DataFrame({'年龄':['18','19'],'性别':['男','女']})with pandas.ExcelWriter('1.xlsx')as writer:
df1.to_excel(writer, sheet_name='Sheet1', index=False)
df2.to_excel(writer, sheet_name='Sheet2', index=False)
- 新增表单
- 可以通过在ExcelWriter中添加mode参数,新增一个sheet。
- 该参数默认为w,修改为a的话,可以在已存在sheet的excel中添加sheet表。
df3 = pandas.DataFrame({'新增表':['1','2']})with pandas.ExcelWriter('1.xlsx', mode='a')as writer:
df3.to_excel(writer, sheet_name='Sheet3', index=False)
- 覆盖excel中已有sheet
- 如果需要重新写入excel中某个sheet,直接往excel写入同名sheet是不可以的,命令会覆盖原本的所有数据,因此需采用以下方法。
df4 = pandas.DataFrame({'test':['2017002038','2017003024']})with pandas.ExcelWriter('1.xlsx',mode='a',engine='openpyxl')as writer:
wb = writer.book # openpyxl.workbook.workbook.Workbook 获取所有sheet
wb.remove(wb['Sheet3'])#删除需要覆盖的sheet
df4.to_excel(writer, sheet_name='Sheet3',index=False)#sheet3的内容更新成df4值
- 已有sheet中追加数据
- 实现excel的追加,可以将原有的数据先读出来,然后与需要存入的数据一并添加即可。
import pandas as pd
# 待追加的数据
df5 ={'名字':['李五','赵六','孙七'],'分数':[90,60,68]}
df5 = pd.DataFrame(df5)# 读取相应sheet中原本的数据
original_data = pd.read_excel('1.xlsx',sheet_name='Sheet1')# 将新数据与旧数据合并起来
save_data = pd.concat([original_data, df5], axis=0)# 覆盖掉原有的sheetwith pd.ExcelWriter('1.xlsx',mode='a',engine='openpyxl')as writer:
wb = writer.book # openpyxl.workbook.workbook.Workbook 获取所有sheet
wb.remove(wb['Sheet1'])#删除需要覆盖的sheet
save_data.to_excel(writer, sheet_name='Sheet1',index=False)#sheet1的内容更新成save_data值
本文转载自: https://blog.csdn.net/qq_44928822/article/details/129002504
版权归原作者 小白的努力探索 所有, 如有侵权,请联系我们删除。
版权归原作者 小白的努力探索 所有, 如有侵权,请联系我们删除。