
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,Java领域新星创作者。
- 📝个人公众号:爱敲代码的小黄(回复 “技术书籍” 可获千本电子书籍)
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人
文章目录
一、消费者组
1. 简述
消费者组,既 Consumer Group。Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制。
一个消费者组有多个消费者,他们共享一个公共的 ID,这个 ID 被称为 Group ID。组内的所有消费者协调在一起来消费订阅主题下的所有分区。
我们之前讲过 点对点模型和发布/订阅模型,点对点模型的缺点在于,当我我们消费完一批数据之后,消息队列会将该笔数据进行删除,这种模型的 伸缩性 很差。而反观我们的发布/订阅模型,虽然数据允许多个消费者消费,但是他的伸缩性也不高,因为每个订阅者都要订阅主题的所有分区。
我们有没有一种方法可以同时兼容这两种情况的?
那就是我们的消费者组,当我们的 Consumer Group 订阅了多个主题后,组内的每个实例只会消费一部分分区的消息。消费者组之间彼此独立,互不影响,能够订阅相同的一组主题而互不干涉。
Kafka 通过使用消费者组这一机制,实现了传统消息引擎的两大模型
如果所有实例都属于同一个 Group,那么它实现的就是消息队列模型;如果所有实例分别属于不同的 Group,那么它实现的就是发布 / 订阅模型。
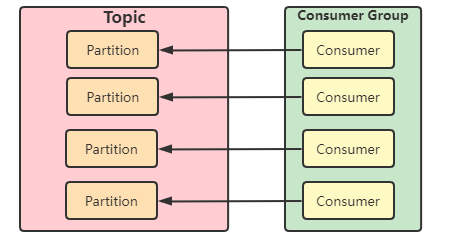
理想情况下,Consumer 实例的数量应该等于该 Group 订阅主题的分区总数,相当于一个消费者实例对应一个分区。
- Consumer 实例的数量 等于 该 Group 订阅主题的分区总数
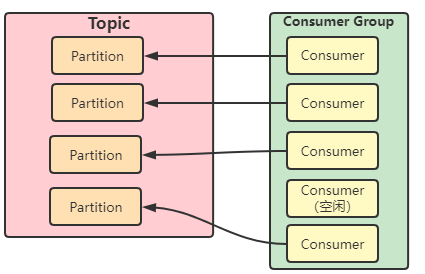
- Consumer 实例的数量 小于 该 Group 订阅主题的分区总数

- Consumer 实例的数量 大于 该 Group 订阅主题的分区总数
针对我们的消费者组,我们的 offset 是怎么进行管理的呢?
对于我们的消费组而言,使用 KV 对来进行表示,Key 是分区,Value 对应该分区的位移。使用我们的 Java 大概是这种:
Map<TopicPartition, Long>
这里简单提一个概念,Kafka 之间的版本将 offset 放在我们的 Zookeeper 中,但后来发现,Zookeeper 这种框架不适合大量的写更新,会拖慢我们 Zookeeper 的性能,最终 Kafka 社区将 offset 放入到我们 Kafka 内部主题。也就是 _consumer_offset
2. 重平衡
2.1 简介
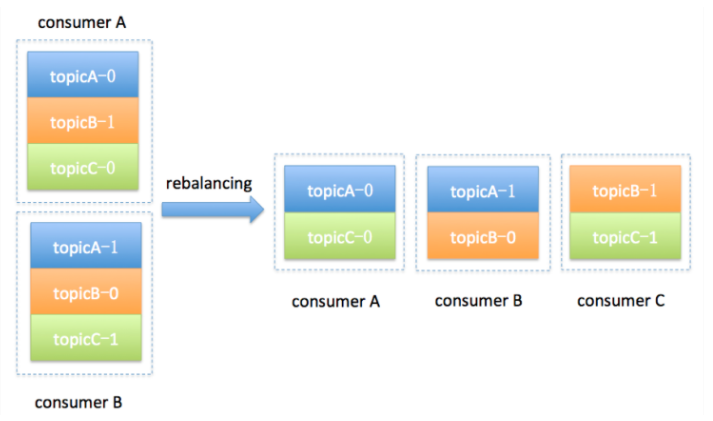
重平衡(Rebalance)本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致,来分配订阅 Topic 的每个分区。
简单来说,比如我们某个 Group 有 20 个Consumer 实例,订阅了一个 100 分区的 Topic。正常情况下,Kafka 会为每个 Consumer 分配 5 个分区,这就叫 重平衡。
重平衡触发的条件:
- 组成员发生变更:Consumer 实例加入或离开消费组
- 订阅主题数发生变更:新增符合条件的主题
- 订阅主题分区数发生变更:新增一个主题的分区数
当重平衡发生时,消费组的所有 Consumer 都会协调在一起共同参与。
Kafka 提供 3 种分配策略,每一种都有优势和劣势,每一种具体的策略以后再进行解读,我们目前记住,社区提供保证最公平的策略,不会出现:**有的实例会“闲死”,而有的实例则会“忙死” **这种情况的发生。
2.2 重平衡的缺点
- 重平衡对消费组的消费有重大的影响。在重平衡期间,所有 Consumer 都会停止消费,等待重平衡的完成。
- 重平衡让所有的分区重新分配,比如我 A 本来消费分区1、2、3,如果重平衡后还继续消费分区1、2、3就会节省大量的时间。如果我们重新换分区的话,还需要重新连接 Broker,重新创建 TCP 连接,无法达到 TCP 连接复用的状态。
- 重平衡的速度及其缓慢。
版权归原作者 爱敲代码的小黄 所有, 如有侵权,请联系我们删除。