


文章目录
Django模型学习总结
一、配置数据库
1.创建数据库
**
Windows
下进入
mysql
**
mysql -u root -p
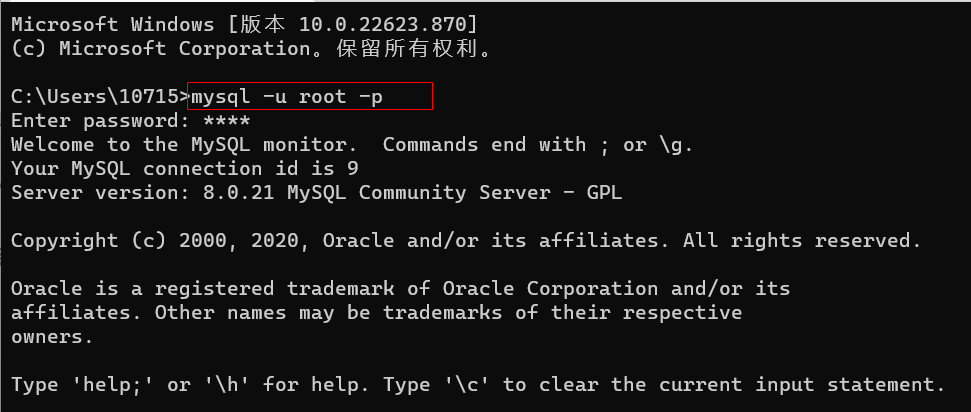
用户没有创建数据库的权限,要
root
用户登录,再去创建数据库,需要用户访问这个数据库的话,也要在
root
下面授予这个用户的这个数据库的权限。
1)创建数据库
create database filmdb charset=utf8;

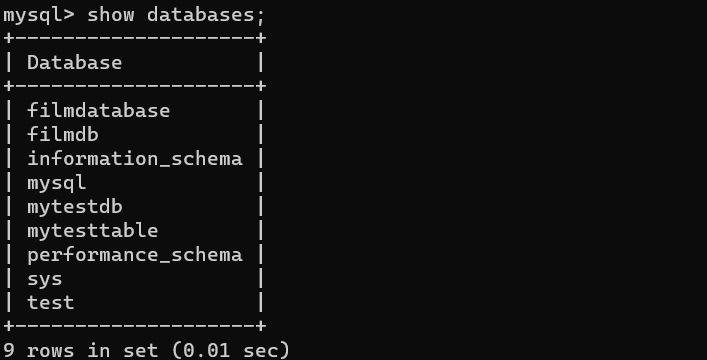
2)查看数据库
show databases;
3)授权
grant all on fildb.* to 'awei'@'%';

4)刷新权限
flush privileges;

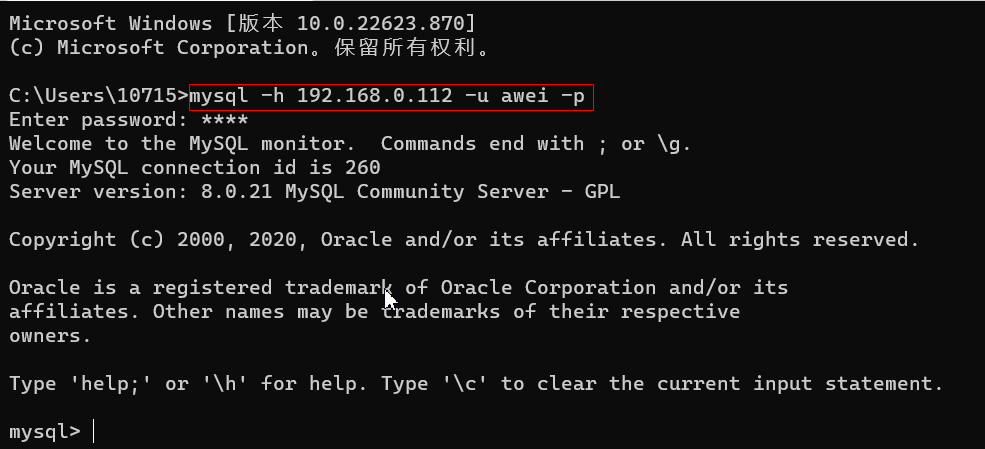
5.新用户连接
mysql -h localhost -u username -p
6)退出
mysql> quit;
查看用户
select host,user from mysql.user;
2.创建新用户
**
Windows
下进入
mysql
**
mysql -u root -p
1)创建新⽤户
CREATEUSER'username'@'host' IDENTIFIED BY'password';
例:
mysql>createuser'awei'@'%' identified by'123123';
mysql>createuser'awei'@'localhost' identified by'123123';
2)授权
# 语法GRANTprivilegesON databasename.tablename TO'username'@'host';# 授权所有的数据库GRANTALLON*.*TO'awei'@'%';# 授权testdb数据库GRANTALLON testdb.*TO'awei'@'%';
例:授权
filmdatabase
数据库给
awei
用户
grantallon filmdatabase.*to'awei'@'%';
3)刷新权限
flush privileges;
4)删除用户
DROPUSER'username'@'host';
3.修改数据库默认配置
在
settings.py
中保存了数据库的连接配置信息,
Django
默认初始配置使⽤
sqlite3
数据库。
# 在settings.py中保存了数据库的连接配置信息,Django默认初始配置使⽤sqlite3数据库。
DATABASES ={'default':{'ENGINE':'django.db.backends.sqlite3','NAME': os.path.join(BASE_DIR,'db.sqlite3'),}}
https://docs.djangoproject.com/en/2.2/ref/settings/#databases
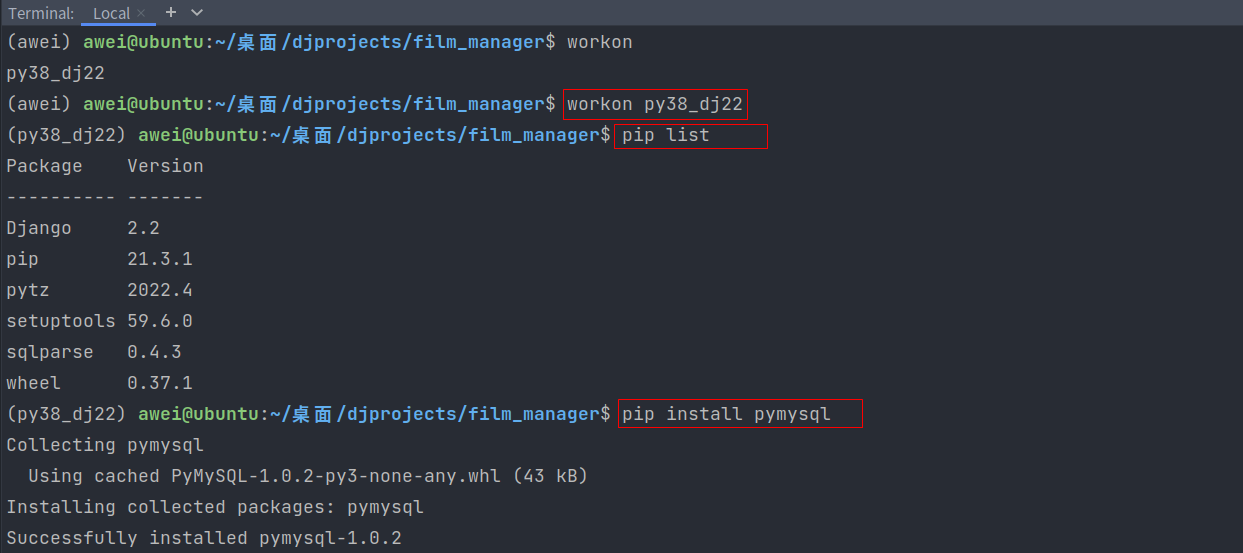
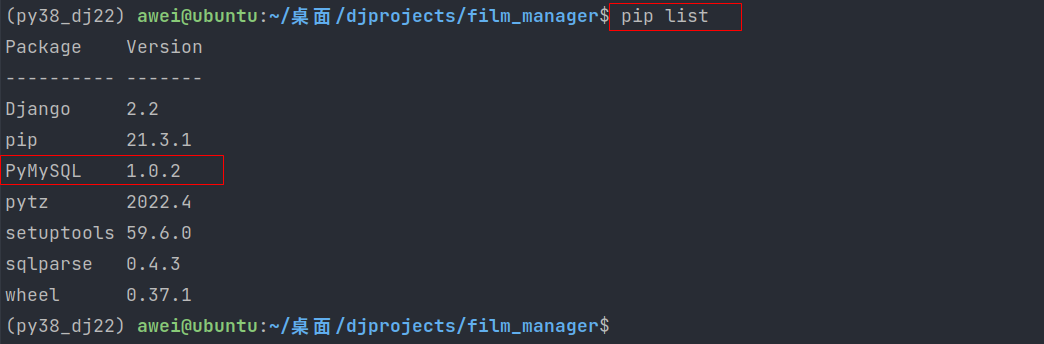
4.安装驱动程序
使⽤MySQL数据库⾸先需要安装驱动程序
# 查看虚拟环境
workon
# 进⼊当前虚拟环境
workon py38dj22
# 安装模块
pip install PyMySQL
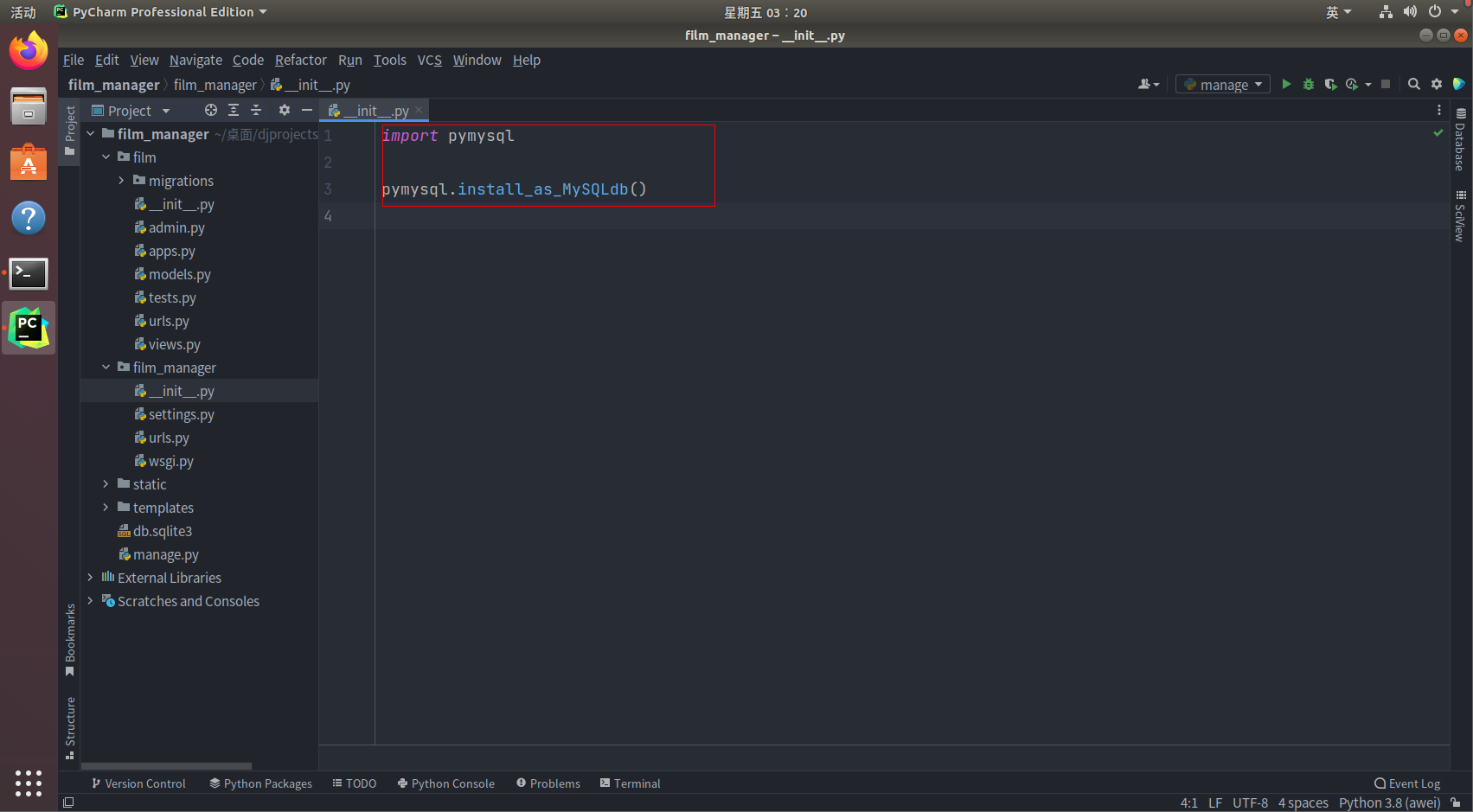
# 在Django的⼯程同名⼦⽬录的__init__.py⽂件中添加如下语句
import pymysql
# 作⽤是让Django的ORM能以mysqldb的⽅式来调⽤PyMySQL
pymysql.install_as_MySQLdb()
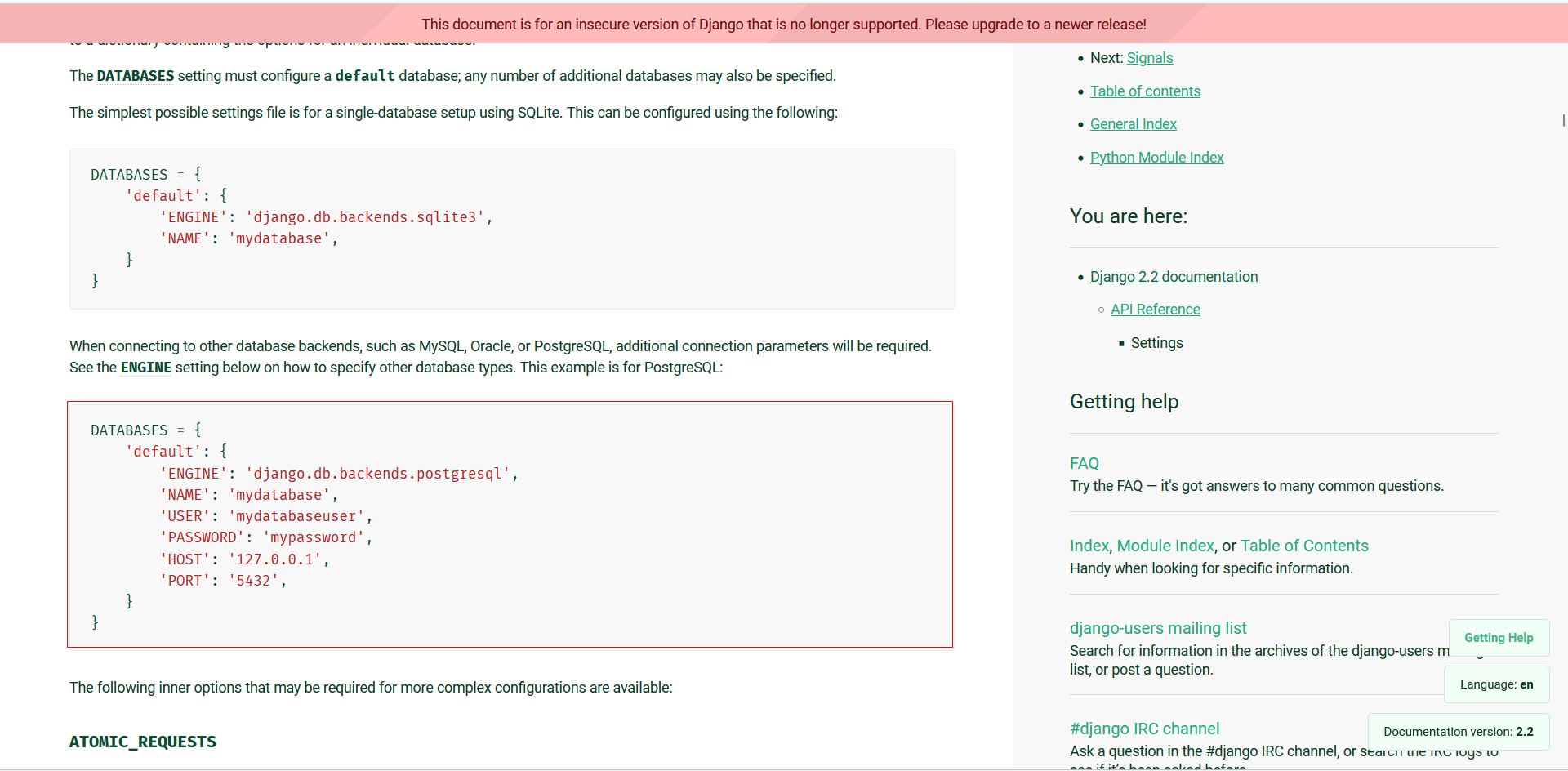
5.修改DATABASES配置信息
DATABASES ={'default':{'ENGINE':'django.db.backends.postgresql','NAME':'mydatabase','USER':'mydatabaseuser','PASSWORD':'mypassword','HOST':'127.0.0.1','PORT':'5432',}}
二、创建模型类
1.创建模型类
模型类被创建在"应⽤⽬录
/models.py
"⽂件中。 模型类必须继承⾃
Model
类,位于包
django.db.models
中。 接下来⾸先以"影⽚-⼈物"管理为例进⾏演示。
**1.定义 在
models.py
⽂件中定义模型类。**
from django.db import models
# Create your models here.# 定义模型类classDemo(moldes.Moldes):
did = models.AutiField(primary_key=True)
dname = models.CharField(max_length=20)
is_delete = models.BooleanField(default=False)classMeta:
db_table ='yingyong_demo'
verbose_name ='demo'def__str__(self):return self.dname
classTest(models.Models):
GENDER_CHOICES =((0,'男'),(1,'女')
)
tid = models.AutiField(primary_key=True)
tname = models.SmallIntegerField(max_length=20)
gender = models.CharField(choices=GENDER_CHOICES, default=0)
dj = models.ForeignKey(Demo,on_delete=models.CASCADE)
is_delete = models.BooleanField(default=False)classMeta:
db_table ='yingyong_test'
verbose_name ='test'def__str__(self):return self.tname
1)数据库表名
模型类如果未指明表名,
Django
默认以
⼩写应⽤名_⼩写模型类名
为数据库表名。
2)关于主键
django
会为表创建⾃动增⻓的主键列,每个模型只能有⼀个主键列,如果使⽤选项设置某属性为主键列后
django
不会再创建⾃动增⻓的主键列。
默认创建的主键列属性为
id
,可以使⽤
pk
代替,
pk
全拼为
primary key
。
3)属性命名限制
不能是
python
的保留关键字。 不允许使⽤连续的下划线,这是由
django
的查询⽅式决定的。 定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:
属性 = models.字段类型(选项)
2.字段类型说明
类型说明
AutoField
自动增长的
IntegetField
,主键自增
BooleanField
布尔字段,值为
True
或
False
NullBooleanField
支持
Null
,
True
,
Fals
CharField
字符串,参数
max_ length
表示最大字符个数
TextField
大文本字段,一般超过
4000
个字符时使用
IntegerField
整数
DecimalField
十进制浮点数,参数
max_ _digits
表示总位数,参数
decimal places
表示小数位数
DataField
日期,参数
auto_ _now
表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为
False
;参数
auto. _now_ _add
表示当对象第一次 被创建时自动设置当前时间,用于创建的时间戳,它总使用当前日期,默认为
False
;参数
auto_ _now_ _add
和
auto_ now
是相互排斥的, 组合将会发生错误.
TimeField
时间,参数同
DataField
DataTimeField
日期时间,参数同
DataFiel
d
FileFiels
上传文件字段
ImageField
继承
FileField
,对上传内容进行效验,确保是有效图片
3.字段选项说明
选项说明
null
如果为
True
,表示允许为空,默认值是
False
blank
如果为
True
,则该字段允许为空白,默认值是
False
db_column
字段的名称,如果未指定,则使用属性的名称
db_index
若值为
True
,则在表中会为此字段创建索引,默认值是
False
default
默认
primary_key
若为
True
,则该字段会成为模型的主键字段,默认值是
False
,-般作为
AutoField
的选项使用
unique
如果为
True
,这个字段在表中必须有唯- -值,默认值是
False
null
是数据库范畴的概念,
blank
是表单验证范畴的
4.外键
在设置外键时,需要通过
on_delete
选项指明主表删除数据时,对于外键引⽤表数据如何处理,在
django.db.models
中包含了可选常量:
CASCADE级联,删除主表数据时连通⼀起删除外键表中数据PROTECT保护,通过抛出ProtectedError异常,来阻⽌删除主表中被外键应⽤的数据SET_NULL设置为NULL,仅在该字段null=True允许为null时可⽤SET_DEFAULT设置为默认值,仅在该字段设置了默认值时可⽤SET()设置为特定值或者调⽤特定⽅法DO_NOTHING不做任何操作,如果数据库前置指明级联性,此选项会抛出IntegrityError异常
5. 迁移
将模型类同步到数据库中。
(1)⽣成迁移⽂件
python manage.py makemigrations 应用名
出现问题
1
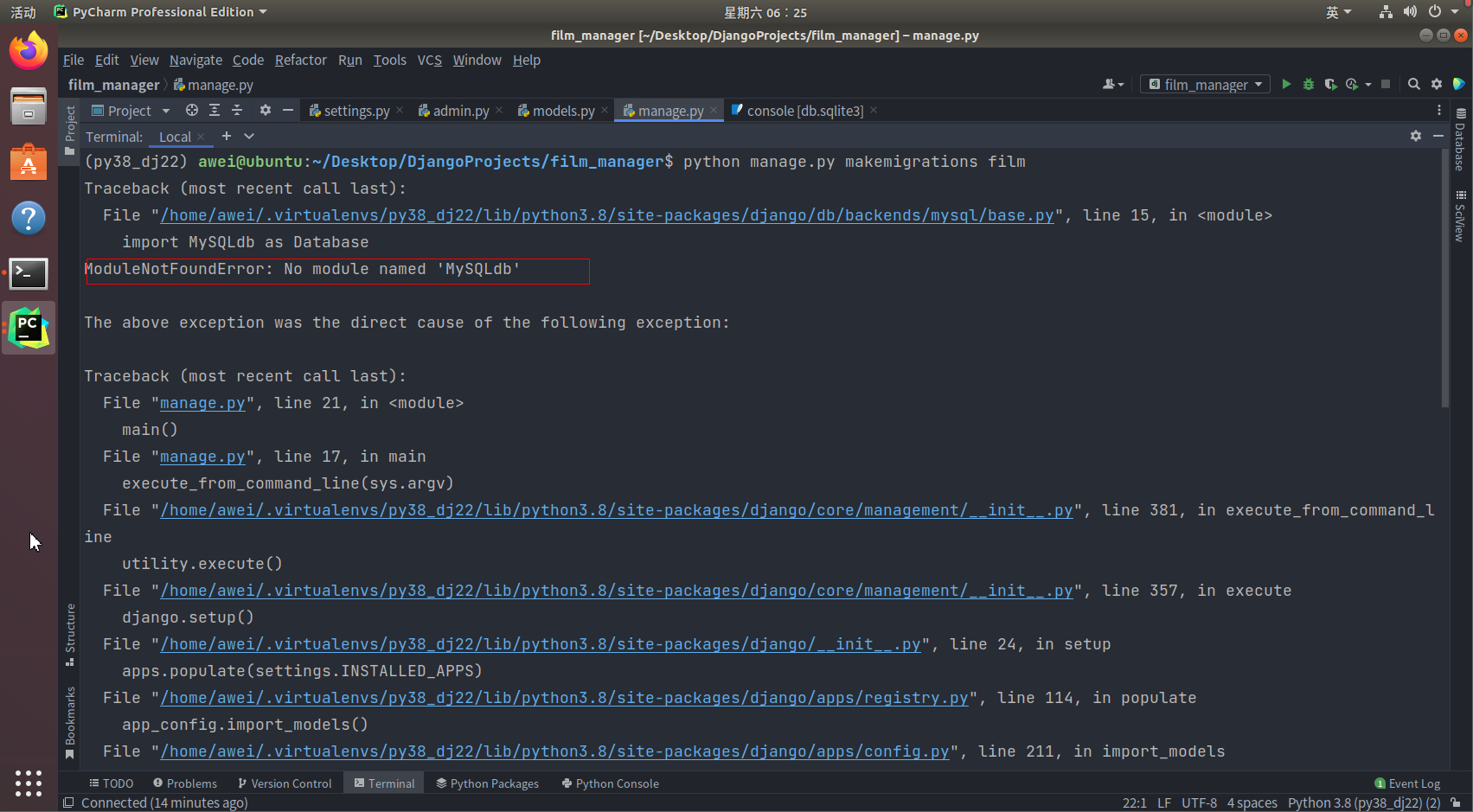
在项目(
settings.py
同级)目录中
__init__.py
中添加
import pymysql
pymysql.install_as_MySQLdb()
出现问题
2
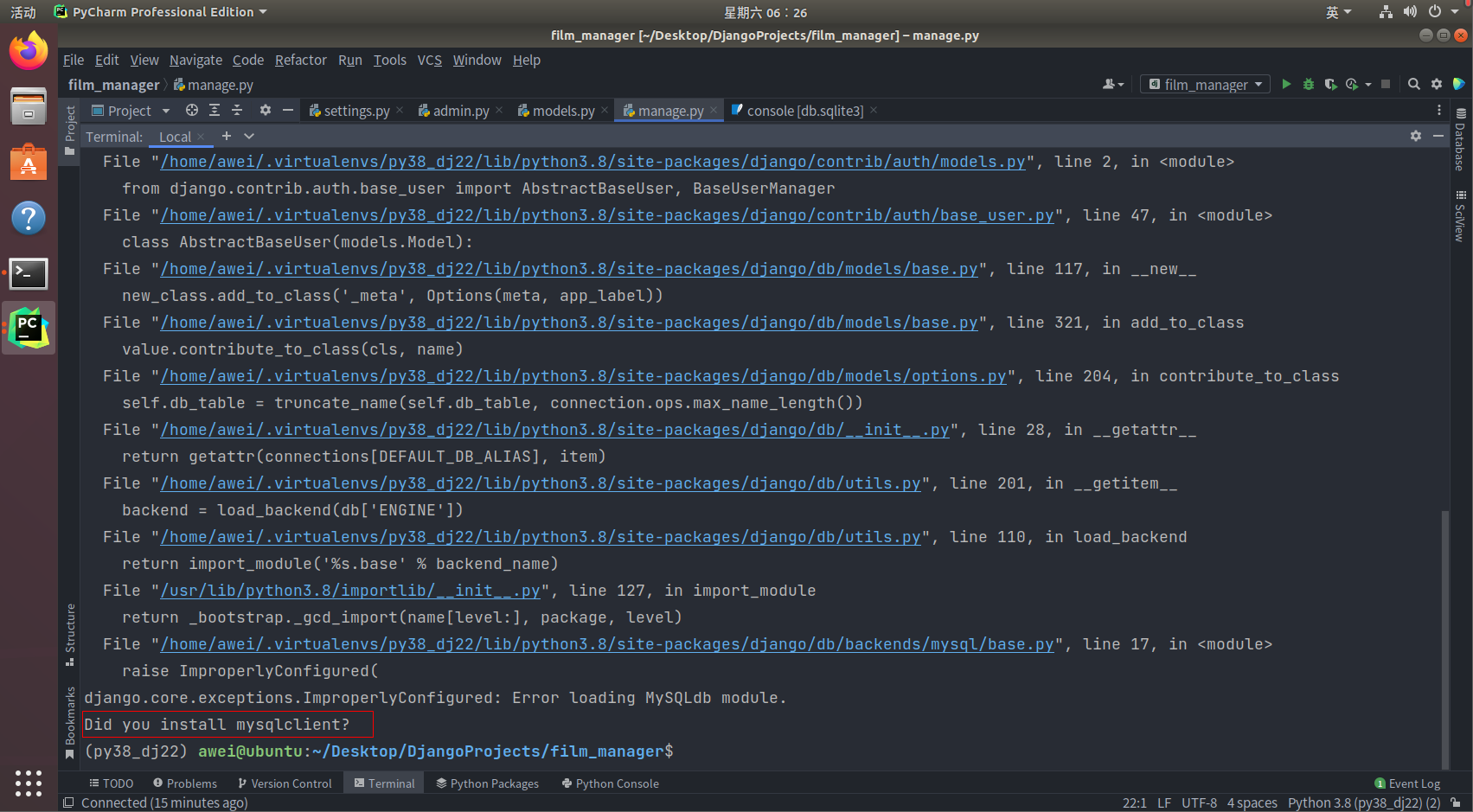
Django
使用
MySQL
数据库需要加载
MySQLdb
模块,需要安装
mysqlclient
,若已经安装请略过。 (
Django2.2
版本之前我们安装的是
pymysql
模块,不过现在使用的
mysqlclient
)
pip install mysqlclient
(2)同步到数据库中(
执行迁移文件
)
python manage.py migrate
6. 添加测试数据
mysq -h localhost -u username -p
show databases;
use filmdb;
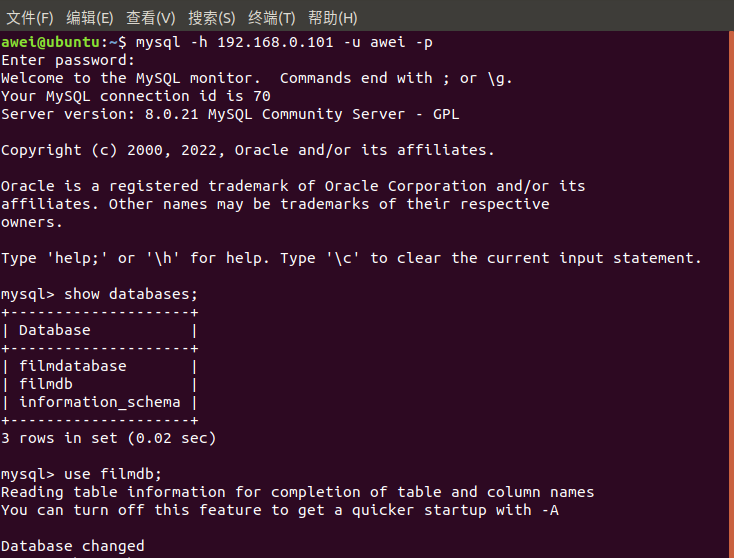
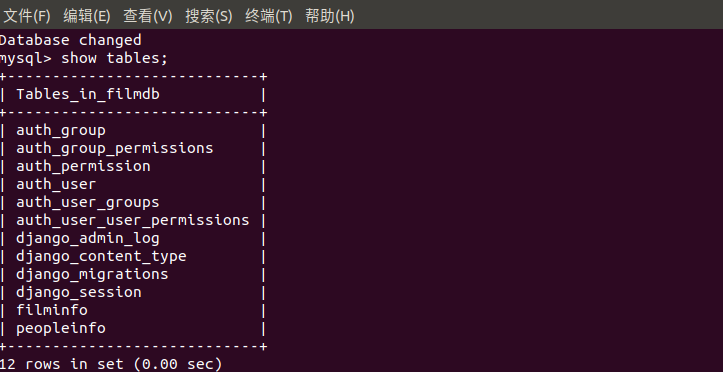
show tables;
三、shell工具
1.shell⼯具
Django
的
manage
⼯具提供了
shell
命令,帮助我们配置好当前⼯程的运⾏环境(如连接好数据库等),以便可以直接在终端中执⾏测试
python
语句。
# 通过如下命令进⼊shell
python manage.py shell

导⼊模型类,以便后续使⽤
from 应用.models import 模型类
2.
MySQL
数据库⽇志
查看mysql数据库⽇志可以查看对数据库的操作记录。
mysql
⽇志⽂件默认没有产⽣,需要做如下配置:
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
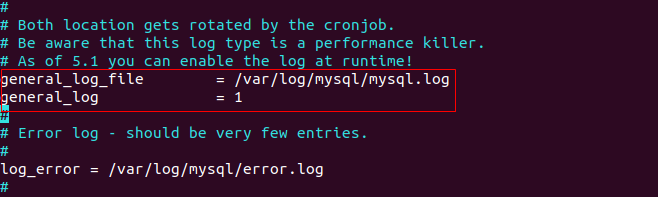
把
68、69
⾏前⾯的
#
去除,然后保存并使⽤如下命令重启
mysql
服务。
sudo service mysql restart
使⽤如下命令打开mysql⽇志⽂件。
# 可以实时查看数据库的⽇志内容
sudo tail -f /var/log/mysql/mysql.log

四、数据库操作增 删 改
1 增加
1)
save
通过创建模型类对象,执⾏对象的
save()
⽅法保存到数据库中。
$ python manage.py shell
>>> from 应用.models import 模型类
>>> f = 模型类()
>>> f.save()
>>> f
<FilmInfo: >
>>> 模型类.objects.all()
2)
create
通过模型类
.objects.create()
保存。
模型类.objects.create()
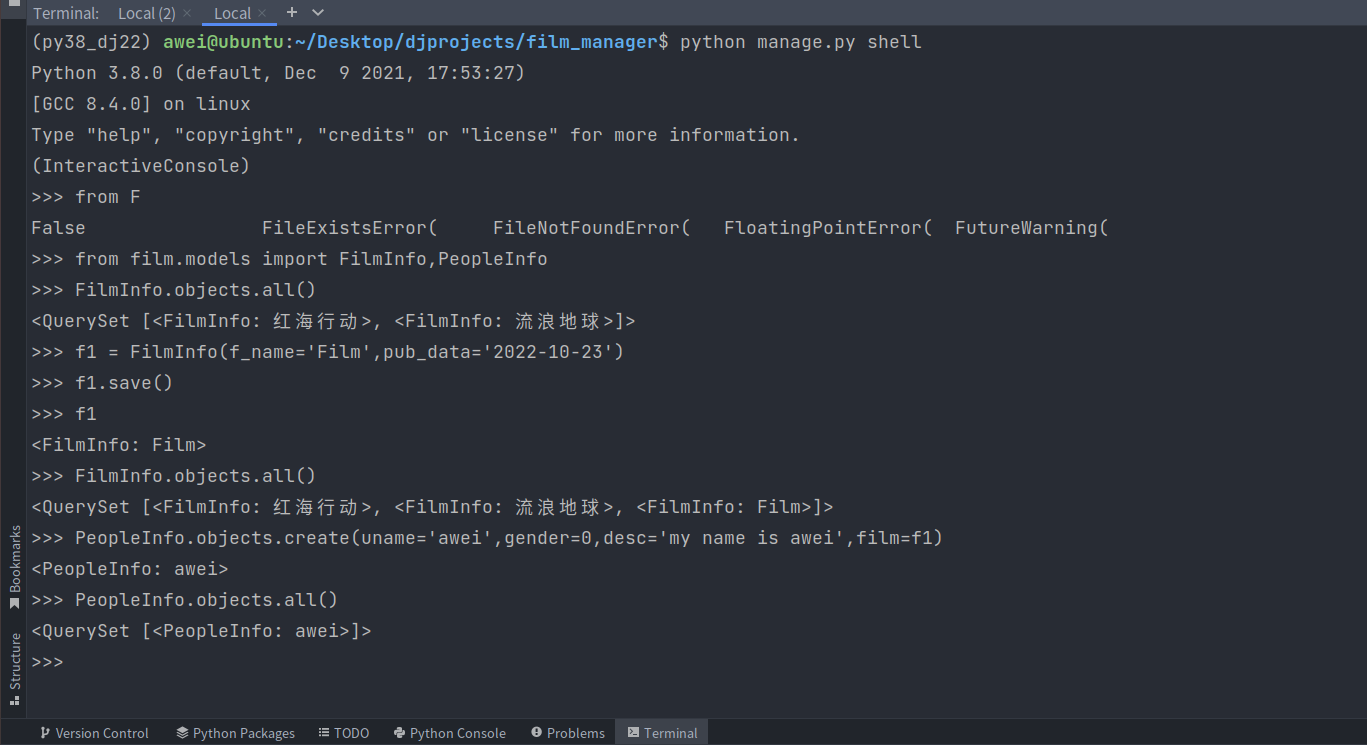
(py38_dj22) awei@ubuntu:~/Desktop/djprojects/film_manager$ python manage.py shell
Python 3.8.0 (default, Dec 9 2021, 17:53:27)[GCC 8.4.0] on linux
Type"help","copyright","credits" or "license"for more information.(InteractiveConsole)
>>> from F
False FileExistsError( FileNotFoundError( FloatingPointError( FutureWarning(
>>> from film.models import FilmInfo,PeopleInfo
>>> FilmInfo.objects.all()
<QuerySet [<FilmInfo: 红海行动>, <FilmInfo: 流浪地球>]>
>>> f1 = FilmInfo(f_name='Film',pub_data='2022-10-23')
>>> f1.save()
>>> f1
<FilmInfo: Film>
>>> FilmInfo.objects.all()
<QuerySet [<FilmInfo: 红海行动>, <FilmInfo: 流浪地球>, <FilmInfo: Film>]>
>>> PeopleInfo.objects.create(uname='awei',gender=0,desc='my name is awei',film=f1)
<PeopleInfo: awei>
>>> PeopleInfo.objects.all()
<QuerySet [<PeopleInfo: awei>]>
>>>
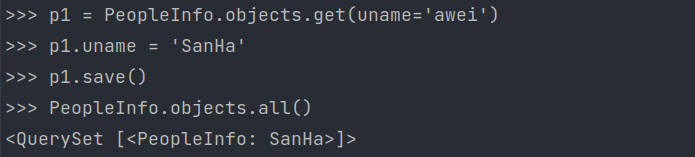
2. 修改
1)
save
修改模型类对象的属性,然后执⾏
save()
⽅法
>>> p1 = 模型类.objects.get(uname='旧名')>>> p1.uname ='新名'>>> p1.save()>>> 模型类.objects.all()<PeopleInfo: 新名>
2)
update
使⽤
模型类.objects.filter().update()
,会返回受影响的⾏数
>>> PeopleInfo.objects.filter(uname='SanHa').update(uname='SanHaHa')
1

3. 删除
1)模型类对象
delete
>>> p2 = PeopleInfo.objects.get(uname='haha')
>>> p2.delete()(1,{'film.PeopleInfo': 1})
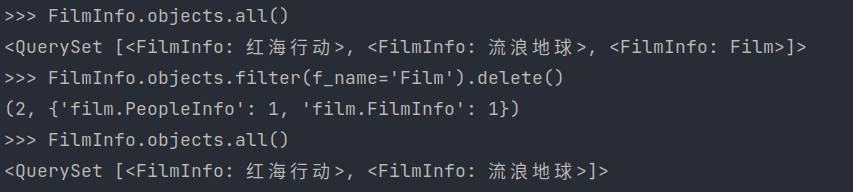
2)
模型类.objects.filter().delete()
>>> FilmInfo.objects.all()
<QuerySet [<FilmInfo: 红海行动>, <FilmInfo: 流浪地球>, <FilmInfo: Film>]>
>>> FilmInfo.objects.filter(f_name='Film').delete()(2,{'film.PeopleInfo': 1,'film.FilmInfo': 1})
>>> FilmInfo.objects.all()
<QuerySet [<FilmInfo: 红海行动>, <FilmInfo: 流浪地球>]>
五、基础条件查询
1.基本查询
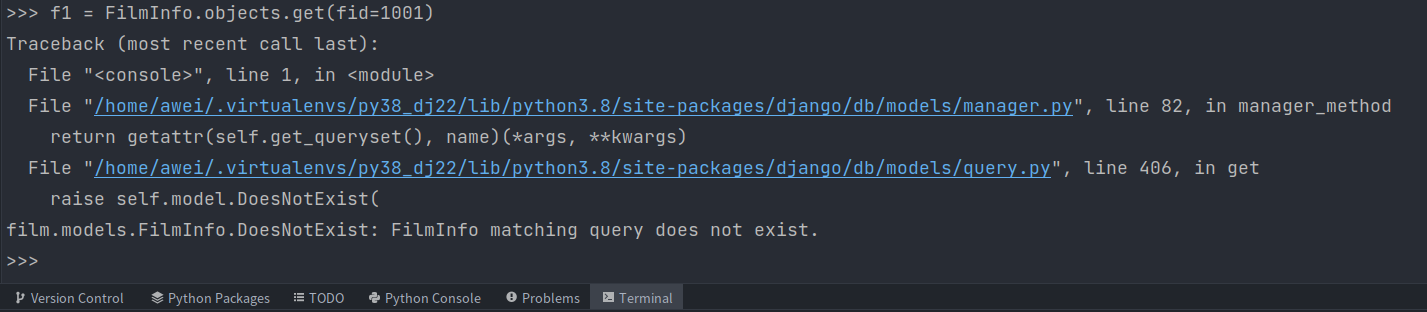
1)get查询单一结果
对象名 = 模型类.objects.get(条件)
get
查询单⼀结果,如果不存在会抛出
模型类.DoesNotExist
异常。
python manager.py shell
from 应用.models import 模块名
对象名 = 模型类.objects.get(条件)
2)all查询多个结果
all
查询多个结果。
模型类.objects.all()
>>> PeopleInfo.objects.all()
<QuerySet []>

3)count查询数量
count
查询结果数量。
模型类.objects.count()
>>> FilmInfo.objects.count()
2
2.过滤查询
实现
SQL
中的
where
功能,包括:
filter过滤出多个结果exclude排除掉符合条件剩下的结果get过滤单⼀结果
**以
filter
为例**
1)exact相等
exact
:表示判等。
例:查询编号为
01
的。
模块名.objects.filter(fid__exact=01)# 可简写为:
模块名.objects.filter(fid=01)
2)contains模糊查询
contains
:是否包含。
说明:如果要包含
%
⽆需转义,直接写即可。
例:查询书名包含
'人'
的影⽚。
模块名.objects.filter(fname__contains='人')
startswith、endswith
:以指定值开头或结尾。
例:查询以
'短'
结尾的
>>> 模块名.objects.filter(fname__endswith='短')
查名以
'短'
开始的
>>> 模块名.objects.filter(fname__startswith='短')
以上运算符都区分⼤⼩写,在这些运算符前加上
i
表示不区分⼤⼩写,如
iexact、icontains、istartswith、iendswith.
3)isnull空查询
isnull
:是否为
null
。
例:查询名为空的。
>>> 模块名.objects.filter(fname__isnull=True)
<QuerySet []>
4)in范围查询
in
:是否包含在范围内。
例:查询编号为
01
或
03
或
05
的
>>> 模块名.objects.filter(fid__in=[01,03,05])
5)⽐较查询
gt
⼤于 (
greater then
)
gte
⼤于等于 (
greater then equal
)
lt
⼩于 (
less then
)
lte
⼩于等于 (
less then equal
)
例:查询编号⼤于
10
的
模块名.objects.filter(fid__gt=1001)
不等于的运算符,使⽤
exclude()
过滤器。
6)日期查询
year、month、day、week_day、hour、minute、second
:对⽇期时间类型的属性进⾏运算。
例:查询
2020
年的。
>>> 模块名.objects.filter(pub_date__year=2020)
例:查询
2022
年
1
⽉
1
⽇后的。
>>> 模块名.objects.filter(pub_date__gt='2022-1-1')
六、F、Q对象
1.F对象
F
对象,获取某一个字段的原有值
语法:
F()
例:查询
counts
大于
count
的
>>> from django.db.models import F
>>> 模型类.objects.filter(counts__gt=F('count'))
可以在
F
对象上使⽤算数运算。
例:查询
counts
量⼤于
2
倍
count
的。
>>> 模型类.objects.filter(counts__gt=F('count')*2)
2.Q对象
语法:
Q(属性名__运算符=值)
多个过滤器逐个调⽤表示逻辑与关系,同
sql
语句中
where
部分的
and
关键字。
例:查询数量⼤于
20
的,改写为
Q
对象如下。
>>> from django.db.models import Q
>>> 模块名.objects.filter(Q(count__gt=20))
(1)Q对象可以使⽤
&、|
连接,
&
表示逻辑与,
|
表示逻辑或。
例:查询数量⼤于
20
,或编号⼩于
13
的,只能使⽤
Q
对象实现
>>> 模块名.objects.filter(Q(count__gt=20)|Q(fid__lt=13))
(2)
Q
对象前可以使⽤
~
操作符,表示⾮
not
。
例:查询编号不等于03的。
>>> 模块名.objects.filter(~Q(fid=03))
七、聚合、排序函数
1. 聚合函数
使⽤
aggregate()
过滤器调⽤聚合函数。聚合函数包括:
Avg
平均,
Count
数量,
Max
最⼤,
Min
最⼩,
Sum
求和,被定义在
django.db.models
中。
>>> from django.db.models import Sun,Count,Avg,Max,Min
例:查询总数量。
>>> from django.db.models import Sum
>>> 模型类.objects.aggregate(Sum('count'))
>{'count__sum': 30000}
注意:
aggregate
的返回值是⼀个字典类型,格式如下:
{'属性名__聚合类⼩写':值}
如:
{'count__sum': 30000}
使⽤
count
时⼀般不使⽤
aggregate()
过滤器。
例:查询
fid
总数。
模型类.objects.aggregate(Count('fid'))
注意
Count
函数的返回值是⼀个数字。
2. 排序函数
使⽤
order_by
对结果进⾏排序
# 默认升序
>>> 模型类.objects.all().order_by('count')
# 降序
>>> 模型类.objects.all().order_by('-count')
八、关联查询
1.关联查询
1)一到多
⼀对应的模型类对象.多对应的模型类名⼩写_set
例:查询编号为1001的所有信息
# 查询编号为1001的所有信息
>>> 模型类对象 = 模型类.objects.get(fid=1001)
>>> 模型类对象.小写模型类_set.all()
2)多到⼀
多对应的模型类对象.多对应的模型类中的关系类属性名
例:查询编号为1的信息
# 查询编号为1的信息
模型类对象 = 模型类.objects.get(uid=1)
模型类对象.模型类中的关系类属性名
3)⼀对应的模型类关联对象的id
多对应的模型类对象.关联类属性_id
例:
>>> 模型类对象 = 模型类.objects.get(uid=1)
>>> 模型类对象.关联属性_id
2.关联过滤查询
1)由多模型类条件查询⼀模型类数据
关联模型类名⼩写__属性名__条件运算符=值
注意:如果没有"
__运算符
"部分,表示等于。
例:查询影⽚信息,要求影⽚⼈物为"
周星驰
"
>>> Film = FilmInfo.objects.filter(peopleinfo__uname='周星驰')
>>> Film
查询影⽚信息,要求影⽚中⼈物的描述包含"
a
"
>>> Film = FilmInfo.objects.filter(peopleinfo__desc__contains='a')
>>> Film
2)由⼀模型类条件查询多模型类数据
⼀模型类关联属性名__⼀模型类属性名__条件运算符=值
注意:如果没有"
__运算符
"部分,表示等于。
例:查询影⽚名为“
战狼2
”的所有⼈物。
>>> people = PeopleInfo.objects.filter(film__fname='战狼2')
>>> people
查询影⽚播放量⼤于
1000
的所有⼈物
>>> people = PeopleInfo.objects.filter(film__playcount__gt=1000)
>>> people
九、查询集
1. 概念
Django
的
ORM
中存在 查询集 的概念。
查询集,也称查询结果集、
QuerySet
,表示从数据库中获取的对象集合。
当调⽤用如下过滤器器⽅方法时,
Django
会返回查询集(⽽而不不是简单的列列表):
all():返回所有数据。filter():返回满⾜足条件的数据。exclude():返回满⾜足条件之外的数据。order_by():对结果进⾏行行排序。
对查询集可以再次调⽤用过滤器器进⾏行行过滤,如
>>> films =FilmInfo.objects.filter(playcount__gt=30).order_by('pub_date')
>>> films
也就意味着查询集可以含有零个、一个或多个过滤器器。过滤器器基于所给的参数限制查询的结果。
从
SQL
的⻆角度讲,查询集与
select
语句句等价,过滤器器像
where、limit、order by
⼦子句句。
判断某⼀一个查询集中是否有数据:
exists()
:判断查询集中是否有数据,如果有则返回
True
,没有则返回
False
。
2. 两⼤大特性
1)**
惰性执⾏
**
当执⾏行行查询操作返回QuerySet时,默认查询前21条数据。
films = FilmInfo.objects.all()
查看映射SQL:select * from t_filminfo limit 21;
2)**
缓存
**
默认情况下,
QuerySet
会把结果存放在内置当缓存中。
QuerySet
提供了
_result_cache
的变量量专⻔门存储缓存。
films = FilmInfo.objects.all()#当执⾏行行完这条语句句后,films._result_cache
能够查看到结果。
3. 限制查询集
可以对查询集进⾏行行取下标或切⽚片操作,等同于
sql
中的
limit
和
offset
⼦子句句。
注意:不不⽀支持负数索引。
对查询集进⾏行行切⽚片后返回⼀一个新的查询集,不不会⽴立即执⾏行行查询。
如果获取⼀一个对象,直接使⽤用
[0]
,等同于
[0E1].get()
,但是如果没有数据,
[0]
引发
IndexError
异常,
[0E1].get()
如果没有数据引发
DoesNotExist
异常。
示例:获取第
1、2
项,运⾏行行查看。
>>> from film.models import FilmInfo
>>> films = FilmInfo.objects.all()[0:2]
>>> films
4. 分页
分页官方文档:https://docs.djangoproject.com/en/2.2/topics/pagination/
#查询数据
films = FilmInfo.objects.all()#导⼊入分⻚页类from django.core.paginator import Paginator
#创建分页实例
paginator=Paginator(films,2)#获取指定页码的数据
page_skus = paginator.page(1)#获取分页数据
total_page=paginator.num_pages
版权归原作者 北极的三哈 所有, 如有侵权,请联系我们删除。