
有两种方法可以实际调用百度的ENRIE模型:
第一种,是在本地安装百度文心的ENRIE Bot Sdk,直接调用本地的SDK API。
第二种,是调用百度千帆大模型平台提供的ENRIE服务API:可以远程RPC调用或者本地SDK调用
一、ENRIE Bot Sdk调用
ERNIE Bot SDK是文心&飞桨官方提供的Python软件开发工具包,简称EB SDK。
EB SDK提供便捷易用的Python接口,可调用文心一言大模型能力,完成包含文本创作、通用对话、语义向量、AI作图在内的多项任务。
1. SDK基础
1.1 安装EB SDK
使用pip可以快速安装EB SDK,这里安装0.4.0版本。
!pip install erniebot==0.4.0
1.2 认证鉴权
调用文心一言大模型功能是收费服务,所以使用EB SDK需要认证鉴权。
EB SDK认证鉴权主要是设置后端和access token,分别通过
api_type
和
access_token
参数来指定。
此处,我们使用
aistudio
后端。在AI Studio个人中心的访问令牌页面,大家可以获取
aistudio
后端的access token,然后填入下面代码中(替换
{YOUR-ACCESS-TOKEN}
)。
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = '{YOUR-ACCESS-TOKEN}'
请注意:
- 不同后端的access token获取方式不同,特定后端获取的access token无法用于其他后端的认证鉴权。
- access token是私密信息,切记不要对外公开。
aistudio后端的access token对应大家的个人账户,目前每个账户有100万token的免费额度,可以用于EB SDK调用文心一言大模型。
1.3 EB SDK Hello-World
作为开始,让我们用EB SDK开发一个hello-world程序:
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': "请对我说“你好,世界!”"}],
)
print(response.get_result())
你好,世界!我很高兴能够与你进行对话。如果你有任何问题或需要帮助,请随时告诉我。
以上代码调用
erniebot.ChatCompletion.create
API,发起对话补全请求,并打印模型的响应结果。
我们通过
model
参数指定使用ernie-bot模型,通过
messages
参数指定给大模型的输入消息。
在以上代码中,我们只进行单轮对话,因此
messages
列表中只包含一个元素。
messages
中的每一项都是一个字典,其中的
'role': 'user'
表示发出当前消息的角色是“用户”(也就是我们),
'content'
则对应消息的具体内容。
1.4 多轮对话
下面让我们尝试一个复杂一些的例子——多轮对话。
文心一言大模型具备强大的上下文理解能力,在我们发送新的消息时,模型能够联系历史消息进行回复。
首先,对hello-world的例子做一点修改:
model = 'ernie-bot'
messages = [{'role': 'user', 'content': "请问你能以《你好,世界》为题,写一首现代诗吗?"}]
first_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
print(first_response.get_result())
当然可以,以下是我创作的《你好,世界》:
你好,世界
在无尽的星辰下,我向世界问好,
在时间的怀抱中,寻找存在的意义。
我是一颗小小的尘埃,漂浮在浩瀚的宇宙,
我是一片轻轻的叶子,摇曳在生命的枝头。
你好,世界,我向你致敬,
在微妙的呼吸中,感受生命的韵律。
我在清晨的阳光里,欢快地歌唱,
我在傍晚的微风中,静静地沉思。
你好,世界,我向你学习,
在万物的交融中,发现无尽的可能。
我在春花秋月中,领略岁月的流转,
我在悲欢离合中,体验人生的百味。
你好,世界,我向你告别,
在永恒的时光里,感悟生命的短暂。
我在璀璨的星空中,寻找未来的方向,
我在寂静的夜色中,安放内心的情感。
你好,世界,你是我的家,
在你的怀抱中,我找到了自我。
在你的辽阔中,我理解了生命的意义,
在你的浩瀚中,我找到了存在的价值。
你好,世界,再次向你问好,
在星辰的闪烁中,我找到了答案。
你好,世界,你是我的舞台,
在你的辽阔中,我找到了自我。
上述代码相比hello-world的例只是修改了
messages
参数的取值,并分别用两个变量
model
和
messages
记录模型名称与消息列表。
接下来,让我们发送第二条消息:
messages.append(first_response.to_message())
messages.append({'role': 'user', 'content': "谢谢你!请问你能把这首诗改写成七言绝句吗?"})
second_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
print(second_response.get_result())
当然可以,以下是我将《你好,世界》改写为七言绝句:
问好世界心欢畅,时间寻义意悠长。
星尘微妙呼吸中,敬畏生命韵律扬。
在上述代码中,我们首先将模型在第一轮对话里做出的回答加入到
messages
中(调用
to_message
方法将响应转换为消息)。
接着,将我们在第二轮对话中想要发送的消息加入到
messages
中。这里我们特意设置了一个模型需要联系上下文才能理解的问题,来测试模型是否真的“记得”对话历史。
最后,将
messages
传入
erniebot.ChatCompletion.create
API,获取第二轮响应。此时的
messages
中包含了全部的历史消息,因此模型能够根据上下文做出回答。
1.5 语义向量
语义向量功能将文本转化为用数值表示的向量形式,从而以紧凑高效的方式编码文本,而这些向量可进一步用于文本检索、信息推荐、知识挖掘等场景。
EB SDK提供
erniebot.Embedding.create
API生成输入文本的语义向量。一个例子如下:
import numpy as np
response = erniebot.Embedding.create(
model='ernie-text-embedding',
input=[
"我是百度公司开发的人工智能语言模型,我的中文名是文心一言,英文名是ERNIE-Bot。",
"2018年深圳市各区GDP"
])
for embedding in response.get_result():
embedding = np.array(embedding)
print(embedding)
1.6 文生图
ERNIE Bot SDK提供具备文生图能力的ernie-vilg-v2大模型。
该模型具备丰富的风格与强大的中文理解能力,支持生成多种尺寸的图片。
import erniebot
erniebot.api_type = 'yinian'
erniebot.access_token = '<access-token-for-yinian>'
response = erniebot.Image.create(
model='ernie-vilg-v2',
prompt="雨后的桃花,8k,辛烷值渲染",
width=512,
height=512
)
print(response.get_result())

2. SDK进阶 - 对话补全(Chat Completion)
本节介绍对话补全功能的几种进阶用法,在实际应用中有助于提升效率以及完成更复杂的任务。
2.1 通过参数调节响应结果多样性
EB SDK支持设定
top_p
和
temperature
参数,影响模型在采样过程中的行为,进而控制模型响应结果的多样性。通常来说,
top_p
和
temperature
参数只需要设置其中一个即可。
设置
top_p
参数可以使生成的token从概率和恰好达到或超过
top_p
的token集合中采样得到。设置
top_p
参数时需注意以下几点:
top_p影响生成文本的多样性,取值越大,生成文本的多样性越强;top_p的默认取值为0.8,取值范围为[0, 1.0]。
temperature
参数也用于控制采样的随机性。设置
temperature
参数需要注意如下几点:
- 较高的
temperature会使生成结果更加随机,而较低的数值会使结果更加集中和确定; temperature的默认取值为0.95,取值范围为(0, 1.0],不能为0。
设置
top_p
和
temperature
的例子如下:
In [ ]
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': "请帮我制定一份深圳一日游计划”"}],
top_p=0.2,
)
print(response.get_result())
In [ ]
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': "请帮我制定一份深圳一日游计划”"}],
temperature=0.7,
)
print(response.get_result())
2.2 流式传输
在实际应用中,模型可能给出很长的回答,而这会导致很长的响应时间。在下面的例子中,我们尝试让模型写一篇200字的文案:
In [ ]
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': "请写一篇200字的文案,介绍文心一言"}],
)
print(response.get_result())
由于生成200字的文案耗时较久,在获取到模型的响应前能够感觉到明显的卡顿。
为了减少用户的等待时间,EB SDK支持流式传输数据。具体而言,为
erniebot.ChatCompletion.create
API传入参数
stream=True
,则API将返回一个生成器。这个生成器对应一个响应序列,我们通过迭代操作即可获取全部响应。一个例子如下:
In [ ]
response_stream = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': "请写一篇200字的文案,介绍文心一言"}],
stream=True,
)
for response in response_stream:
print(response.get_result(), end='', flush=True)
print("")
执行上述代码,我们能够“实时”地获取模型响应,而不需要等待全部内容生成完毕。
2.3 设定模型行为
erniebot.ChatCompletion.create
API的另一个有用的参数是
system
,该参数可用于设定模型的行为,例如给予模型人设或是要求模型以特定格式回答问题。一个例子如下:
In [33]
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': "你好呀,和我打个招呼吧"}],
system="你是一个爱笑的智能助手,请在每个回答之后添加“哈哈哈”",
)
print(response.get_result())
你好呀!我是爱笑的智能助手,很高兴认识你!哈哈哈
3. SDK进阶 - 函数调用(Function Calling)
本节介绍EB SDK的函数调用功能。“函数调用”指的是由大模型根据对话上下文确定何时以及如何调用函数。借由函数调用,用户可以从大模型获取结构化数据,进而利用编程手段将大模型与已有的内外部API结合以构建应用。
3.1 简单示例
函数调用功能的典型使用流程如下:
- 用户提供对一组函数的名称、功能、请求参数(输入参数)和响应参数(返回值)的描述;
- 模型根据用户需求以及函数描述信息,智能确定是否应该调用函数、调用哪一个函数、以及在调用该函数时需要如何设置输入参数;
- 用户根据模型的提示调用函数,并将函数的响应传递给模型;
- 模型综合对话上下文信息,以自然语言形式给出满足用户需求的回答。
下面我们按照上述步骤给出一个完整的例子。
在开始正式步骤前,我们先定义一个用于获取城市气温的函数:
In [ ]
def get_current_temperature(location, unit):
return {"temperature": 25, "unit": "摄氏度"}
作为演示,以上代码所定义的
get_current_temperature
是一个硬编码的dummy函数,在实际应用中可将其替换为真正具备相应功能的API。
流程的第一步要求我们对函数的基本信息进行描述。使用JSON Schema格式描述函数的请求参数与响应参数:
In [ ]
functions = [
{
'name': 'get_current_temperature',
'description': "获取指定城市的气温",
'parameters': {
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': "城市名称",
},
'unit': {
'type': 'string',
'enum': [
'摄氏度',
'华氏度',
],
},
},
'required': [
'location',
'unit',
],
},
'responses': {
'type': 'object',
'properties': {
'temperature': {
'type': 'integer',
'description': "城市气温",
},
'unit': {
'type': 'string',
'enum': [
'摄氏度',
'华氏度',
],
},
},
},
},
]
上述代码中定义了一个列表
functions
,其中包含对函数
get_current_temperature
的名称、请求参数等信息的描述。
接着,将以上信息与对需要完成的任务的自然语言描述一同传给
erniebot.ChatCompletion
API。需要注意的是,目前只有ernie-bot模型支持函数调用功能。
In [62]
messages = [
{
'role': 'user',
'content': "深圳市今天气温如何?",
},
]
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=messages,
functions=functions,
)
assert response.is_function_response
function_call = response.get_result()
print(function_call)
{'name': 'get_current_temperature', 'thoughts': '我需要调用get_current_temperature来解决这个问题。', 'arguments': '{"location":"深圳市","unit":"摄氏度"}'}
以上代码中的断言语句用于确保
response
中包含函数调用信息。在实际应用中通常还需要考虑
response
中不包含函数调用信息的情况,这意味着模型选择不调用任何函数。当
response
中包含函数调用信息时,
response.get_result
返回函数调用信息;否则,
response.get_result
返回模型回复的文本。
function_call
是一个字典,其中包含的键
name
、
thoughts
分别对应大模型选择调用的函数名称以及模型的思考过程。
function_call['arguments']
是一个JSON格式的字符串,其中包含了调用函数时需要用到的参数。
然后,根据模型的提示调用相应函数得到结果:
In [63]
import json
name2function = {'get_current_temperature': get_current_temperature}
func = name2function[function_call['name']]
args = json.loads(function_call['arguments'])
res = func(location=args['location'], unit=args['unit'])
print(res)
{'temperature': 25, 'unit': '摄氏度'}
以上代码从
function_call
中获取模型选择调用的函数名称(
function_call['name']
),通过该名称找到对应的函数,并从
function_call['arguments']
中解析需要传入函数的参数,最终完成对函数的调用。
最后,将模型上一轮的响应以及函数的响应加入到对话上下文信息中,再次传递给模型。回传给模型的函数响应内容应当是JSON格式的字符串(如
'{"temperature": 25, "unit": "摄氏度"}'
),在本示例中,函数的响应是一个字典,因此需要先调用
json.dumps
函数对其进行编码。
In [ ]
#保存第一轮对话
messages.append(response.to_message())
print(messages)
--------------------------------------------------------------------
打印结果:
[{'role': 'user', 'content': '上海市今天气温如何?'}, {'role': 'assistant', 'content': None, 'function_call': {'name': 'get_current_temperature', 'thoughts': '用户想要知道上海市今天的天气情况,我可以使用get_current_temperature工具来获取这个信息。', 'arguments': '{"location":"上海市","unit":"摄氏度"}'}}]
#加入第二轮对话内容
messages.append(
{
'role': 'function',
'name': function_call['name'],
'content': json.dumps(res, ensure_ascii=False),
}
)
print(messages)
--------------------------------------------------------------------
打印结果:
[{'role': 'user', 'content': '上海市今天气温如何?'}, {'role': 'assistant', 'content': None, 'function_call': {'name': 'get_current_temperature', 'thoughts': '用户想要知道上海市今天的天气情况,我可以使用get_current_temperature工具来获取这个信息。', 'arguments': '{"location":"上海市","unit":"摄氏度"}'}}, {'role': 'function', 'name': 'get_current_temperature', 'content': '{"temperature": 25, "unit": "摄氏度"}'}]
In [66]
#基于第一轮和第二轮对话内容,获取第三轮对话响应
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=messages,
)
print(response.get_result())
------------------------------------------------------------------
打印结果:
根据您提供的数据,上海市今天的温度为25摄氏度。如果您需要更多关于上海天气的信息,可以查询当地的天气预报网站或手机应用程序。
通过执行上述代码,我们期望从模型侧得到的响应是自然语言形式的、对我们最初问题的解答,而不希望模型继续建议调用函数。但需要注意的是,模型可能判断需要在第二轮、乃至后续轮次的对话中连续调用函数。因此,在实际应用中,我们需要根据模型的响应类型执行相应的操作。此外,大模型的“幻觉”现象在函数调用中依然存在,也就是说,模型返回的函数名称与参数有可能是不准确的,这就需要用户适当通过参数合法性校验等手段处理这些情况。
3.2 基于函数调用开发智能社交助理
接下来,让我们通过一个更加复杂、但与实际应用更为贴近的例子,进一步体会函数调用功能的使用。在这个例子中,我们将开发一个智能社交助理,用户可以使用自然语言与智能助理交流,并指挥它完成邮箱地址更新以及邮件发送等任务。
首先定义一个查询好友信息的函数:
In [ ]
info_dict = {
'李小明': {
'age': 31,
'email': '[email protected]',
'mbti': 'ESFJ',
'hobbies': ['健身', '篮球', '游泳', '烹饪'],
},
'王刚': {
'age': 28,
'email': '[email protected]',
'mbti': 'INTP',
'hobbies': ['游戏', '音乐', '电影', '旅游'],
},
'张一一': {
'age': 26,
'email': '[email protected]',
'mbti': 'ENTP',
'hobbies': ['摄影', '美食', '桌游', '编程'],
},
}
def get_friend_info(name, field=None):
info = info_dict[name]
if field is not None:
return {'name': name, field: info[field]}
else:
return {'name': name, ** info}
get_friend_info_desc = {
'name': 'get_friend_info',
'description': "获取好友的个人信息",
'parameters': {
'type': 'object',
'properties': {
'name': {
'type': 'string',
'description': "好友姓名",
},
'field': {
'type': 'string',
'description': "想要获取的字段名称,如果不指定则返回所有字段",
'enum': [
'age',
'email',
'mbti',
'hobbies',
],
},
},
'required': ['name', ],
},
'responses': {
'type': 'object',
'properties': {
'name': {
'type': 'string',
'description': "姓名",
},
'age': {
'type': 'integer',
'description': "年龄",
'minimum': 0,
},
'email': {
'type': 'string',
'description': "电子邮箱地址",
'format': 'email',
},
'mbti': {
'type': 'string',
'description': "好友的MBTI人格类型",
},
'hobbies': {
'type': 'array',
'description': "兴趣爱好列表",
'items': {
'type': 'string',
},
},
},
'required': ['name', ],
},
}
get_friend_info
函数用于获取好友的个人信息,
name
和
field
参数分别用于指定好友的姓名以及想要获取的字段名称。我们将好友信息存储在全局字典
info_dict
中,便于其他函数对这些信息进行修改。与之前的例子一样,
get_friend_info
仍然是一个本地函数。不过,在实际中,这个函数可以有更复杂的实现细节——例如向本地SQL数据库或是远程服务器发送请求,查询并返回信息。
第二个函数允许我们对好友的邮箱地址进行修改:
In [ ]
def update_email_address(name, email):
try:
info = info_dict[name]
info['email'] = email
except Exception as e:
return {'status': False, 'error_message': f"{type(e)}: {str(e)}"}
else:
return {'status': True}
update_email_address_desc = {
'name': 'update_email_address',
'description': "更新好友的电子邮箱地址",
'parameters': {
'type': 'object',
'properties': {
'name': {
'type': 'string',
'description': "好友姓名",
},
'email': {
'type': 'string',
'description': "新的邮箱地址",
},
},
'required': ['name', 'email', ],
},
'responses': {
'type': 'object',
'properties': {
'status': {
'type': 'boolean',
'description': "更新操作是否成功,true表示成功,false表示失败",
},
'error_message': {
'type': 'string',
'description': "更新操作失败原因",
},
},
'required': ['status', ],
},
}
最后,我们再定义一个dummy函数,用于模拟发送邮件:
In [ ]
def send_email(to, content):
return {'status': True}
send_email_desc = {
'name': 'send_email',
'description': "向好友发送邮件",
'parameters': {
'type': 'object',
'properties': {
'to': {
'type': 'string',
'description': "收件人姓名",
},
'content': {
'type': 'string',
'description': "邮件内容",
}
},
'required': ['to', 'content', ]
},
'responses': {
'type': 'object',
'properties': {
'status': {
'type': 'boolean',
'description': "邮件发送状态,true表示成功到达对方服务器,false表示发送失败",
},
},
},
}
在实际中,我们可以将函数的具体实现替换为真实的发送邮件逻辑。作为示例,上述三个函数没有覆盖“增删改查”中的“增”和“删”,但相信在理解这个例子之后,大家可以轻松地为我们的智能助理追加更多的功能。
完成函数定义后,我们对模型响应的处理逻辑稍作封装,便于复用:
In [ ]
import json
name2function = {
'get_friend_info': get_friend_info,
'update_email_address': update_email_address,
'send_email': send_email,
}
functions = [
get_friend_info_desc,
update_email_address_desc,
send_email_desc,
]
messages = []
def to_pretty_json(obj):
return json.dumps(obj, ensure_ascii=False, indent=2)
def chat(message, system=None, use_functions=True, auto_func_call=True, _max_recur_depth=3):
# 当`auto_func_call`参数为True时,根据模型响应自动调用函数,并将调用结果回传给模型
if isinstance(message, str):
message = {'role': 'user', 'content': message}
messages.append(message)
create_kwargs = {
'model': 'ernie-bot',
'messages': messages,
}
if system:
create_kwargs['system'] = system
if use_functions:
create_kwargs['functions'] = functions
response = erniebot.ChatCompletion.create(**create_kwargs)
if response.is_function_response:
# 模型建议调用函数
function_call = response.get_result()
messages.append(response.to_message())
if auto_func_call:
# 从模型响应中解析函数名称和请求参数
func_name = function_call['name']
try:
func = name2function[func_name]
except KeyError as e:
raise KeyError(f"函数`{func_name}`不存在") from e
func_args = function_call['arguments']
try:
func_args = json.loads(func_args)
except json.JSONDecodeError as e:
raise ValueError(f"无法从{repr(func_args)}解析参数") from e
# 调用函数
if not isinstance(func_args, dict):
raise TypeError(f"{repr(func_args)}不是字典")
print(f"【函数调用】函数名称:{func_name},请求参数:{to_pretty_json(func_args)}")
func_res = func(**func_args)
print(f"【函数调用】响应参数:{to_pretty_json(func_res)}")
# 将函数响应回传给模型
message = {
'role': 'function',
'name': func_name,
'content': json.dumps(func_res, ensure_ascii=False),
}
# 根据允许的最大递归层级判断是否应该设置`use_functions`和`auto_func_call`为`False`
# 这样做主要是为了限制调用函数的次数,防止无限递归
return chat(
message,
use_functions=(use_functions and _max_recur_depth > 1),
auto_func_call=(auto_func_call and _max_recur_depth > 1),
_max_recur_depth=_max_recur_depth-1,
)
else:
return function_call
else:
# 模型返回普通的文本消息
result = response.get_result()
messages.append(response.to_message())
return result
由于大模型生成内容具有不确定性,本教程无法预测模型针对用户提问会做出什么样的回答。大家可以运行下方的cell,尝试输入不同的内容,与智能助理进行交互。如果对输入内容没有什么头绪的话,不妨试试这些例子:
请问李小明今年几岁?
张一一和我说她的邮箱地址换成了[email protected],请你帮我更新一下。
国庆节快到了,帮我发封邮件,问问王刚有没有出行计划。对了,我一般称呼他“刚哥”。
我是INTJ,我想知道王刚的MBTI和我是否契合,和他相处需要注意什么。
我想送李小明一份生日礼物,希望他能喜欢。根据你对小明的兴趣爱好的了解,你觉得我应该送什么好?
张一一过段时间要到深圳来找我玩,你能根据她的兴趣爱好帮我们制定一份旅游计划吗?
In [ ]
messages = []
# 为了使模型能够得到更充足的提示,我们借助`system`参数对模型说明它需要扮演的角色以及一些注意事项
system = """
你是一个智能社交助理,能够帮助我查询好友信息、更新好友邮箱地址、发送电子邮件以及给出社交建议。
在我们的对话中,我提到的所有人名都是好友的名称。请尽可能使用我提供的函数解决问题。
"""
# 默认进行单轮对话,修改传给`range`的数字可进行多轮对话
for _ in range(1):
result = chat(input("请输入:"), system=system)
print(result)
3.3 函数调用效果调优技巧
作为一个较为复杂的功能,函数调用的效果好坏取决于诸多因素,如描述信息的准确性和完备性、以及用户对任务需求表述的清晰程度等。为了帮助大家在实际应用中更好地使用函数调用功能,本教程将分享一系列函数调用效果的调优技巧。
3.3.1 函数描述的编写技巧
使描述尽可能准确和详细
在编写函数描述时,EB SDK要求必须为每个函数提供
name
、
description
和
parameters
。虽然
responses
是可选的,但如果函数具有返回值,建议也提供
responses
。
对于
parameters
中的每个参数,建议至少都填写
type
和
description
。如果某些参数是必须传入的,使用JSON Schema的
required
关键字指定这些参数为必选;如果某个参数的取值只能在几个固定值中选取,使用JSON Schema的
enum
关键字指定可能的取值。需要说明的是,尽管JSON Schema语法允许在指定了
enum
关键字时不指定
type
,但为了使模型获得更充足的提示,建议在使用
enum
的情况下仍同时指定
type
。大家可以在上文智能社交助理的例子中找到使用
enum
和
required
的例子。
在编写函数以及参数的
description
时,需要注意用词的精确,避免模糊、有歧义的语言。例如,上文智能社交助理的例子中的
send_email
函数用于向好友发送邮件,其中的
to
参数指的是收件人的姓名而非邮箱地址,因此其
description
为
收件人姓名
。倘若
description
被设置为
收件人
,则存在歧义,可能导致模型误解该参数可以传入收件人的邮箱地址,从而出现错误。此外,如果有可能的话,可以在
description
中添加简短的示例,例如
省,市名。如:广东,深圳。
比
省,市名
更准确,更易于模型理解。
注意函数名称与参数名称
尽管
description
提供了对函数和参数的自然语言描述,函数名称和参数名称本身仍会在一定程度上影响模型的判断。因此,请大家尽可能使用常用的、易于理解的函数和参数名称,最好能做到“见名知意”。
例如,将用于查询天气的函数命名为
getWhether
(拼写错误)、
getTianQi
(混用汉语拼音和英语单词)、
getWX
(使用不常见的缩写)可能令模型难以理解;
get_info
、
weather
这样的命名则过于宽泛,光看名字很难知道函数的用途。对于这个例子来说,推荐的命名是
get_weather
或稍微有些冗余的
GetWeatherInfo
。在函数和参数名称表达的意思足够清晰的情况下,命名风格通常不是问题,文心一言模型可以理解符合驼峰命名法、蛇形命名法等常见命名规范的名称。
提升编写JSON Schema的效率
函数描述中的
parameters
和
responses
都需要按照JSON Schema语法编写。尽管JSON Schema的功能强大,但编写起来并不复杂,大家可以多多参考JSON Schema官方文档或者网上的中文教程。
在这里给出两个小工具,用于提升编写JSON Schema的效率。首先是如下定义的
describe_function
函数:
In [ ]
def describe_function(func):
import inspect
sig = inspect.signature(func)
func_desc = {
'name': func.__name__,
'description': "",
'parameters': {
'type': 'object',
'properties': {},
},
}
params_desc = func_desc['parameters']
for param in sig.parameters.values():
name = param.name
param_desc = {}
if param.kind in (param.POSITIONAL_ONLY, param.VAR_POSITIONAL,
param.VAR_KEYWORD):
raise ValueError(
"不支持函数中包含positional-only、var-positional或var-keyword参数")
if param.default is not param.empty:
param_desc['default'] = param.default
if param.kind == param.POSITIONAL_OR_KEYWORD and param.default is param.empty:
if 'required' not in params_desc:
params_desc['required'] = []
params_desc['required'].append(name)
params_desc['properties'][name] = param_desc
return func_desc
该函数接受一个Python函数
func
作为输入,可用于从
func
的函数签名自动提取各参数的JSON Schema格式的描述信息,进而生成初始版本的函数描述。如下展示了一个使用例子:
In [ ]
def my_function(a, b=1):
return a + b
print(describe_function(my_function))
可以看出,
describe_function
自动识别到
my_function
的输入参数
a
、
b
,并将其添加到函数描述中,其中
b
的默认值被记录,而
a
作为必选参数也被记录到
required
中。
另外一个推荐的工具是在线JSON Schema校验工具。大家可以使用这个工具快速检查自己编写的JSON Schema是否存在格式问题,或者检验编写的JSON Schema的功能是否符合预期。
3.3.2 提供函数调用示例
erniebot.ChatCompletion.create
的
functions
参数还支持一个
examples
参数,通过该参数可以传递给模型一个函数调用示例,从而使模型获得更加充分的提示。
一个例子如下:
In [ ]
examples = [
{
'role': 'user',
'content': "深圳的天气怎么样?",
},
{
'role': 'assistant',
'content': None,
'function_call': {
'name': 'get_current_weather',
'arguments': '{"location":"深圳"}',
},
},
{
'role': 'function',
'name': 'get_current_weather',
'content': '{"temperature":25,"unit":"摄氏度","description":"多云"}',
},
]
可以看出,
examples
中的项和
messages
中的项具有完全相同的格式。上述
examples
以对话的形式提供了
get_current_weather
函数的一个调用示例,包括用户发起提问、模型返回
function_call
、用户将函数调用结果回传给模型等。
3.3.3 为函数响应参数增加prompt
当函数的响应参数为JSON object时,EB SDK允许在其中加入一个
prompt
键值对,用于针对如何从函数的响应参数构造输出给模型更多提示。
如下是使用
prompt
的一个例子:
In [ ]
messages = [
{
'role': 'user',
'content': "深圳的天气怎么样?",
},
{
'role': 'assistant',
'content': None,
'function_call': {
'name': 'get_current_weather',
'arguments': '{"location":"深圳"}',
},
},
{
'role': 'function',
'name': 'get_current_weather',
'content': '{"temperature":25,"unit":"摄氏度","description":"多云","prompt":"请根据函数返回的气温与天气描述,以“你好,这是天气信息:”开头输出回答"}',
},
]
response = erniebot.ChatCompletion.create(
model='ernie-bot-3.5',
messages=messages,
)
print(response.get_result())
二、千帆大模型服务调用
百度的ENRIE Bot服务已经集成到了千帆大模型平台,我们可以通过RPC API的方式请求千帆大模型上面的ENRIE Bot服务。
1. 千帆大模型平台介绍
百度推出的千帆大模型平台集成了众多的大模型, 千帆不仅提供了包括文心一言底层模型(ERNIE-Bot)和第三方开源大模型,还提供了各种AI开发工具和整套开发环境,方便客户轻松使用和开发大模型应用。
千帆平台预置的大模型(查看与管理预置模型 - 千帆大模型平台 | 百度智能云文档)如下:
模型名称模型类型模型描述ERNIE-Bot大语言模型百度⾃⾏研发的⼤语⾔模型,覆盖海量中⽂数据,具有更强的对话问答、内容创作⽣成等能⼒。ERNIE-Bot-turbo大语言模型百度自行研发的高效语言模型,基于海量高质数据训练,具有更强的文本理解、内容创作、对话问答等能力。BLOOMZ-7B「体验」大语言模型业内知名的⼤语⾔模型,由BigScience研发并开源,能够以46种语⾔和13种编程语⾔输出⽂本。Stable-Diffusion-XL「体验」文生图大模型业内知名的跨模态大模型,由Stability AI研发并开源,有着业内领先的图像生成能力。Mistral-7B「体验」大语言模型由Mistral AI研发并开源的7B参数大语言模型,具备强大的推理性能和效果,对硬件需求更少、在各项评测基准中超越同规模模型。Llama-2-7B「体验」大语言模型由Meta AI研发并开源的7B参数大语言模型,在编码、推理及知识应用等场景表现优秀。Llama-2-13B「体验」大语言模型由Meta AI研发并开源的13B参数大语言模型,在编码、推理及知识应用等场景表现优秀。Llama-2-70B「体验」大语言模型由Meta AI研发并开源的70B参数大语言模型,在编码、推理及知识应用等场景表现优秀。RWKV-4-world「体验」大语言模型由香港大学物理系校友彭博研发并开源,结合了Transformer与RNN的优点,具备优秀的推理性能与效果。ChatGLM2-6B「体验」大语言模型智谱AI与清华KEG实验室发布的中英双语对话模型,具备强大的推理性能、效果、较低的部署门槛及更长的上下文,在MMLU、CEval等数据集上相比初代有大幅的性能提升。SQLCoder-7B「体验」大语言模型由Defog研发、基于Mistral-7B微调的语言模型,用于将自然语言问题转换为SQL语句,具备优秀的生成效果。OpenLLaMA-7B「体验」大语言模型在Meta AI研发的Llama模型基础上,OpenBuddy进行调优,涵盖了更广泛的词汇、通用字符与token嵌入,具备与Llama相当的性能与推理效果。Falcon-7B「体验」大语言模型由TII研发、在精选语料库增强的1500B tokens上进行训练。由OpenBuddy调优并开源,提升了处理复杂对话任务的能力与表现。Dolly-12B「体验」大语言模型由Databricks训练的指令遵循大语言模型。基于pythia-12b,由InstructGPT论文的能力域中生成的约15k指令/响应微调记录训练。MPT-7B「体验」大语言模型MPT-7B-Instruct是一种短格式指令遵循模型,由MosaicML研发,基于MPT-7B模型在Databricks Dolly-15k、HH-RLHF数据集上调优的版本,采用经过修改的仅使用解码器的transformer架构。RWKV-14B「体验」大语言模型由香港大学物理系校友彭博研发并开源的14B参数模型,结合了Transformer与RNN的优点,具备优秀的推理性能与效果。Aquila-7B「体验」大语言模型由智源研究院研发的中英双语语言模型,继承了GPT-3和LLaMA的架构优点,基于中英文高质量语料训练,实现了高效训练,获得了比其他开源模型更优的性能,并符合国内数据合规需要。Falcon-40B「体验」大语言模型由TII研发的仅使用解码器的模型,并在Baize的混合数据集上进行微调,具备优异的推理效果。MPT-30B「体验」大语言模型MPT-30M-Instruct是一种短格式指令遵循模型,由MosaicML研发,基于MPT-7B模型在更为丰富的数据集上调优的版本,采用经过修改的仅使用解码器的transformer架构。Cerebras-GPT-13B「体验」大语言模型由Cerebras研发并开源,使用 Chinchilla 公式进行训练的13B参数GPT模型,可为给定的计算预算提供最高的准确性,具备更低的训练成本与功耗。Pythia-12B「体验」大语言模型由EleutherAI研发并开源,在Pile数据集上训练的12B参数transformer语言模型。GPT-J-6B「体验」大语言模型EleutherAI开发的6B参数transformer模型,基于Mesh Transformer JAX训练。GPT-NeoX-20B「体验」大语言模型由EleutherAI开发,使用GPT-NeoX库,基于Pile训练的200亿参数自回归语言模型,模型结构与GPT-3、GPT-J-6B类似。StarCoder「体验」大语言模型由BigCode研发的15.5B参数模型,基于The Stack (v1.2)的80+编程语言训练,训练语料来自Github。StableLM-Alpha-7B「体验」大语言模型Stability AI开发的7B参数的NeoX transformer架构语言模型,支持4k上下文。
2. 远程RPC调用方式
2.1 调用方法
可以通过RPC远程调用的方式实现,比如调用ENRIE-bot的chat功能,可以通过以下地址访问:
https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions
在调用之前先要获取access token,通过以下方式获得:
其中,API_KEY和SECRET_KEY参数可以在千帆网站上通过创建应用后获取:百度智能云千帆大模型平台
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
2.2 调用实例
下面以调用千帆的ENRIE-bot-4服务的实操代码为例:
import requests
#链接百度文心大模型,声明百度ERNIE类,指向ERNIE-bot-4模型
class BaiduErnie:
host: str = "https://aip.baidubce.com"
client_id: str = ""
client_secret: str = ""
access_token: str = ""
def __init__(self, client_id: str, client_secret: str):
self.client_id = client_id
self.client_secret = client_secret
self.get_access_token()
#获取access token
def get_access_token(self) -> str:
url = f"{self.host}/oauth/2.0/token?grant_type=client_credentials&client_id={self.client_id}&client_secret={self.client_secret}"
response = requests.get(url)
if response.status_code == 200:
self.access_token = response.json()["access_token"]
print(self.access_token)
return self.access_token
else:
raise Exception("获取access_token失败")
#调用bot的对话接口
def chat(self, messages: list, user_id: str) -> tuple:
if not self.access_token:
self.get_access_token()
#ERNIE-Bot-turbo:
#url = f"{self.host}/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token={self.access_token}"
#ERNIE-Bot-4:
url = f"{self.host}/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions_pro?access_token={self.access_token}"
data = {"messages": messages, "user_id": user_id}
response = requests.post(url, json=data)
if response.status_code == 200:
resp = response.json()
#return response.text
return resp["result"], resp
else:
raise Exception("请求失败")
#填入文心大模型后台你自己的API信息
user_id = ""
#API Key
client_id = "你的API KEY"
#Secret Key
client_secret = "你的SECRET KEY"
#实例化ERNIE类
baidu_ernie = BaiduErnie(client_id, client_secret)
prompt = "中国的首都在哪?"
def chat(prompt):
messages = []
messages.append({"role": "user", "content": prompt}) # 用户输入
result, response = baidu_ernie.chat(messages, user_id) # 调用接口
#result = baidu_ernie.chat(messages, user_id) # 调用接口
return result
res = chat(prompt)
print("prompt: ", prompt)
print("answer: ", res)
3. 本地千帆SDK调用方式
3.1 安装千帆SDK
使用千帆SDK可以进行基础的大模型能力调用:
- Chat 对话
- Completion 续写
- Embedding 向量化
- Plugin 插件调用
- Text2Image 文生图
目前千帆 SDK 已发布到 PyPI ,用户可使用 pip 命令进行安装。安装千帆 SDK 需要 3.7.0 或更高的 Python 版本
pip install qianfan -U
在安装完成后,用户即可在代码内引入千帆 SDK 并使用
import qianfan
3.1 平台鉴权
千帆SDK基于文心千帆大模型平台对用户提供能力,因此在使用前需要用户使用平台指定的鉴权方式进行初始化。
如何获取AK/SK
用户需要在千帆平台上创建应用,以获得 API Key (AK) 和 Secret Key (SK)。AK 与 SK 是用户在调用千帆 SDK 时所需要的凭证。具体获取流程参见平台的应用接入使用说明文档。
获取到 AK 和 SK 后,用户还需要传递它们来初始化千帆 SDK。 千帆 SDK 支持如下两种传递方式,按优先级从低到高排序:
通过环境变量传递(作用于全局,优先级最低)
import os
os.environ["QIANFAN_AK"]="..."
os.environ["QIANFAN_SK"]="..."
或者构造时传递(仅作用于该对象,优先级最高)
import qianfan
chat_comp=qianfan.ChatCompletion(ak="...", sk="...")
3.2 Chat 对话
用户只需要提供预期使用的模型名称和对话内容,即可调用千帆大模型平台支持的,包括 ERNIE-Bot 在内的所有预置模型,如下所示:
import qianfan
chat_comp = qianfan.ChatCompletion(ak="...", sk="...")
# 调用默认模型,即 ERNIE-Bot-turbo
resp = chat_comp.do(messages=[{
"role": "user",
"content": "你好"
}])
print(resp['body']['result'])
# 输入:你好
# 输出:你好!有什么我可以帮助你的吗?
# 指定特定模型
resp = chat_comp.do(model="ERNIE-Bot", messages=[{
"role": "user",
"content": "你好"
}])
也可以利用内置 Messages 简化多轮对话,下面是一个简单的用户对话案例,实现了对话内容的记录
msgs = qianfan.Messages()
while True:
msgs.append(input()) # 增加用户输入
resp = chat_comp.do(messages=msgs)
print(resp) # 打印输出
msgs.append(resp) # 增加模型输出
除此之外也支持使用异步编程 以及 流式输出
resp=await chat_comp.ado(model="ERNIE-Bot-turbo", messages=[{
"role": "user",
"content": "你好"
}], stream=True)
3.3 Completion 续写
对于不需要对话,仅需要根据 prompt 进行补全的场景来说,用户可以使用
qianfan.Completion
来完成这一任务。
import qianfan
comp=qianfan.Completion(ak="...", sk="...")
resp=comp.do(model="ERNIE-Bot", prompt="你好")
# 输出:你好!有什么我可以帮助你的吗
3.4 Embedding 向量化
千帆 SDK 同样支持调用千帆大模型平台中的模型,将输入文本转化为用浮点数表示的向量形式。转化得到的语义向量可应用于文本检索、信息推荐、知识挖掘等场景。
Embedding 基础功能
import qianfan
# 替换下列示例中参数,应用API Key替换your_ak,Secret Key替换your_sk
emb = qianfan.Embedding(ak="your_ak", sk="your_sk")
resp = emb.do(texts=[ # 省略 model 时则调用默认模型 Embedding-V1
"世界上最高的山"
])
对于向量化任务,目前千帆大模型平台预置的模型有:
- Embedding-V1(默认)
- bge-large-en
- bge-large-zh
3.5 模型配置和接入
以上几种大模型都使用了预置的模型服务,通过model参数来进行设置;除此之外为了支持自行发布的模型服务(例如ChatGLM等开源模型服务部署),千帆SDK当前ChatCompletion,Completion,Embedding,Plugin都支持了endpoint字段;在此基础上,用户可以通过直接传入自行发布模型的endpoint来接入模型服务。以下以plugin为例子进行说明。
3.6 Plugin 插件
千帆大模型平台支持使用平台插件并进行编排,以帮助用户快速构建 LLM 应用或将 LLM 应用到自建程序中。在使用这一功能前需要先创建应用、设定服务地址、将服务地址作为参数传入千帆 SDK。
# 以下以使用智慧图问插件为例:
plugin = qianfan.Plugin(endpoint="your_endpoint")
resp = p.do(plugins=["uuid-chatocr"], prompt="这上面的牛是什么颜色的", verbose=True, fileurl="https://qianfan-doc.bj.bcebos.com/imageai/cow.jpeg")
3.7 文生图
除了语言类的AIGC能力,我们也基于开源的文生图模型提供了多模态的能力,以下是使用stableDiffusion-XL进行文生图的示例:
import os
os.environ["QIANFAN_AK"]="your_ak"
os.environ["QIANFAN_SK"]="your_sk"
import qianfan
from PIL import Image
import io
t2i = qianfan.Text2Image()
resp = t2i.do(prompt="A Ragdoll cat with a bowtie.", with_decode="base64")
img_data = resp["body"]["data"][0]["image"]
img = Image.open(io.BytesIO(img_data))
display(img)
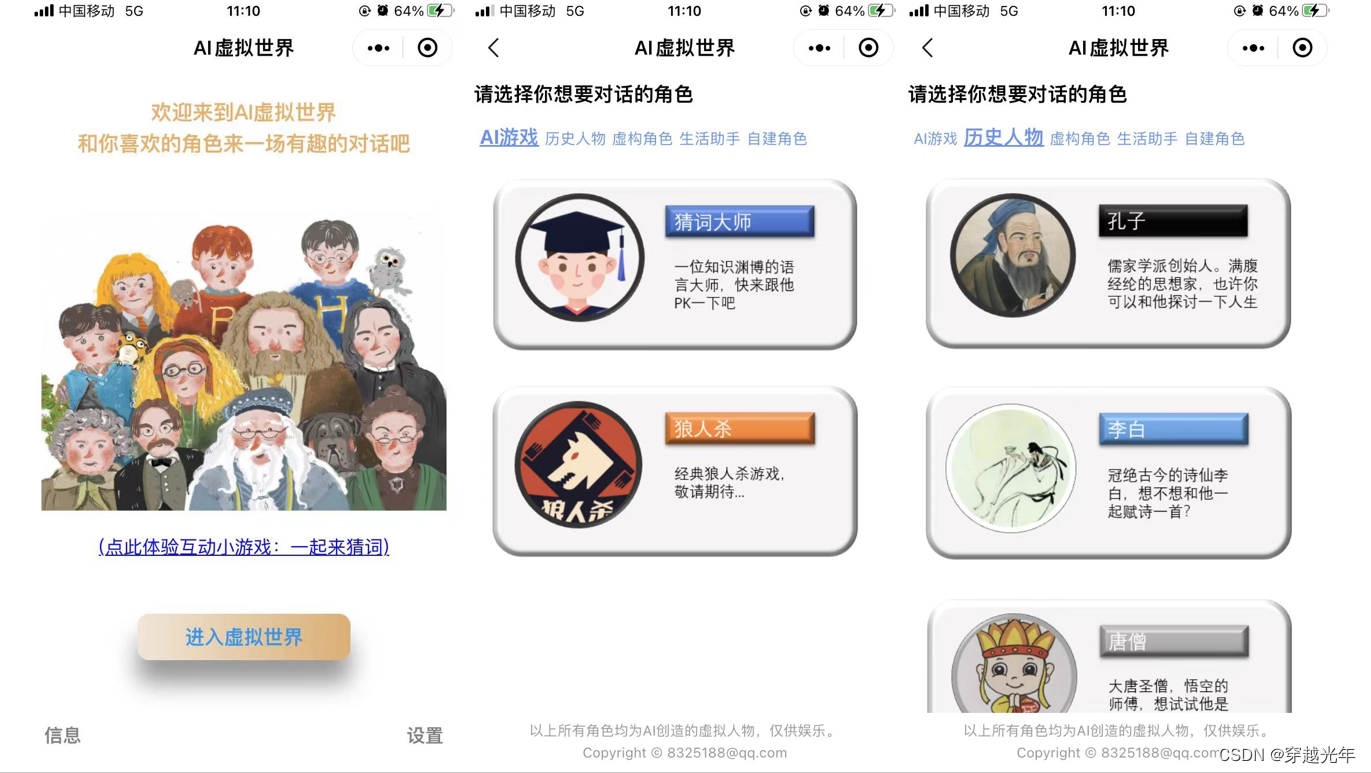
三、基于百度文心大模型实现AI虚拟角色应用
基于大模型的API,我们可以很容易的创建出各种AI虚拟角色,只需要给不同的角色设定不同的系统prompt,就可以让AI扮演对应的角色。基于这个想法,尝试做了一个AI虚拟世界的微信小程序,这里面有AI扮演的孔子,李白,唐僧,林黛玉,哈利波特,哆啦A梦,心里专家,旅行家,等等虚拟角色。用户可以和这些角色进行有趣的对话。截图如下。感兴趣具体实现过程的可参考这个:
人工智能学习与实训笔记(六):基于百度文心大模型实现的A-CSDN博客
小程序码可直达体验:

版权归原作者 穿越光年 所有, 如有侵权,请联系我们删除。