
目录
一、kafka基础概念了解
Kafka是一种高吞吐量、持久性、分布式的发布订阅的消息队列系统- kafka文档
- 为什么应该学习 Kafka
- Kafka 里面的信息是如何被消费的?
- 使用生成器把Kafka写入速度提高1000倍
- Kafka名词概念
producer:消息生产者,向 Kafka Broker 发消息的客户端broker: 一台 Kafka 机器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topictopic: 可以理解为一个队列,topic 将消息分类,生产者和消费者面向的是同一个 topicoffset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉,再重新恢复的时候,可以从消费位置继续消费partition: topic在物理上的分区,一个topic可以分为一个或多个分区,每个partition是一个有序的队列consumer: 消息消费者,从Kafka Broker 取消息的客户端consumer group: 消费者组(CG),消费者组内每个消费者,负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者Zookeeper: Kafka 集群能够正常工作,需要依赖于 zookeeper,zookeeper 帮助Kafka 存储和管理集群信息
二、下载安装Kafka
- 1、点击下载kafka,点击图中链接里面的下载链接
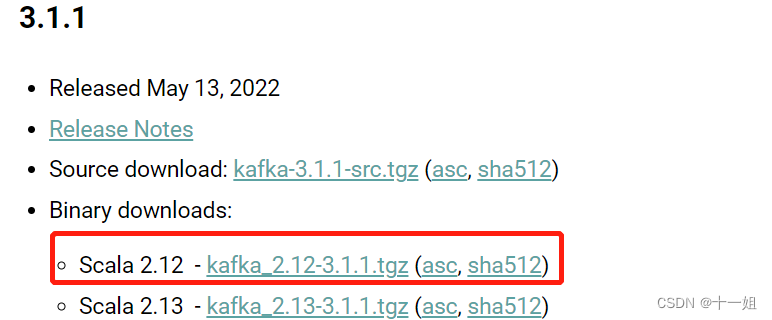
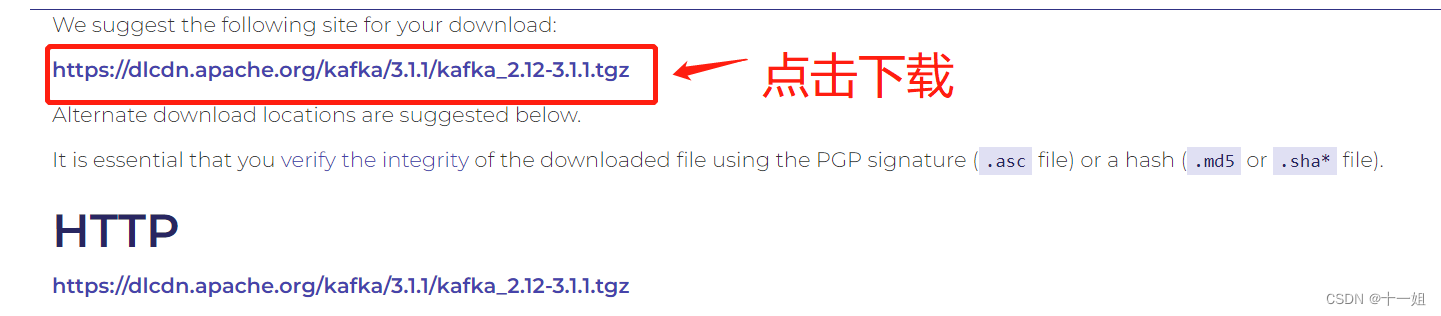
- 2、然后将压缩包解压即可,然后我们到
kafka_2.12-3.1.1\bin\windows目录下启动kafka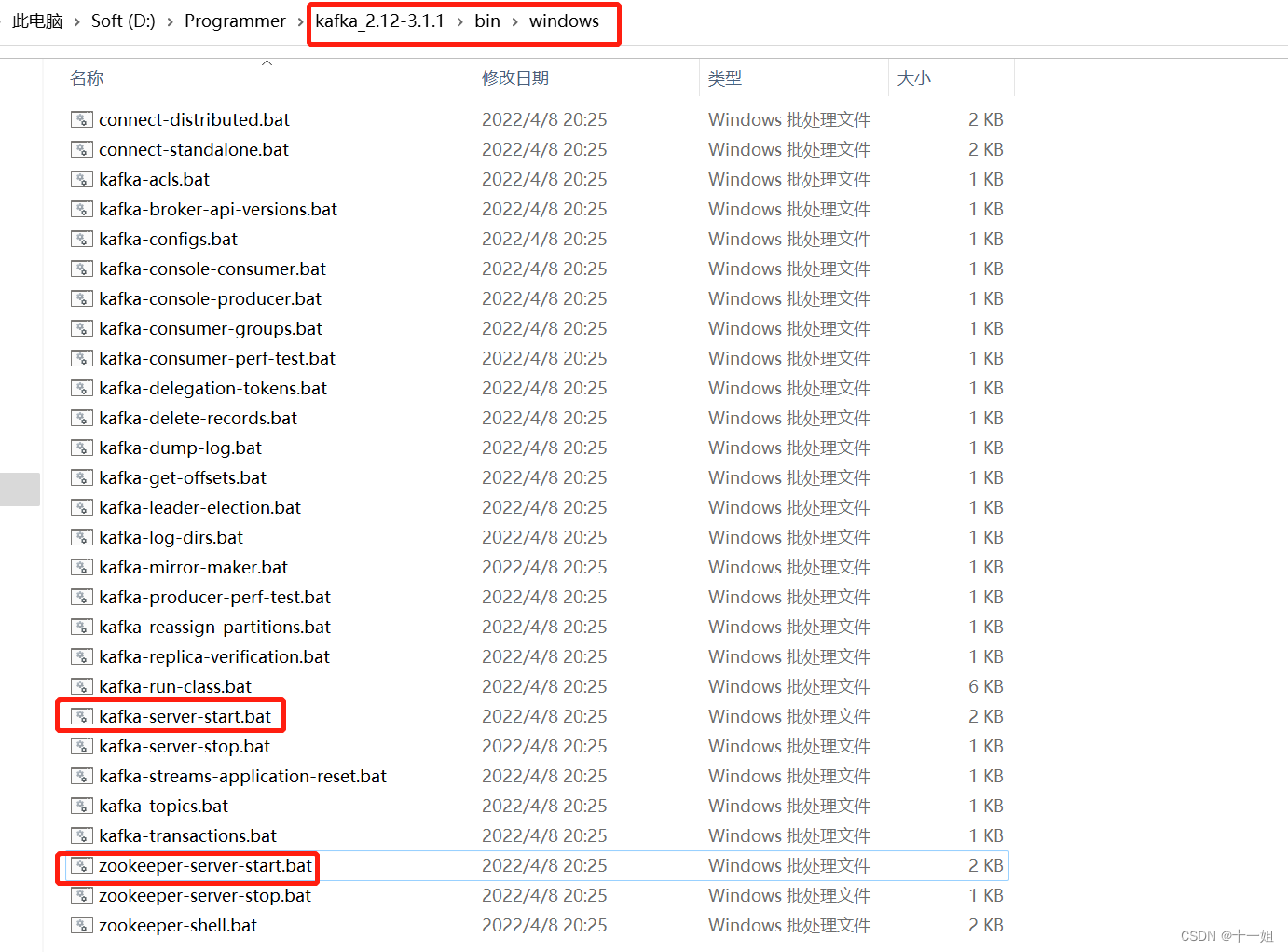
- 3、启动kafka前需要使用Zookeeper,如果没有安装Zookeeper,可以使用Kafka自带打包和配置好的Zookeeper。
先切换到kafka_2.12-3.1.1\bin\windows目录下,如下图打开两个cmd窗口,分别执行如下两个命令,注意这两个窗口不要关 -zookeeper-server-start.bat ..\..\config/zookeeper.properties -
- kafka-server-start.bat ..\..\config/server.properties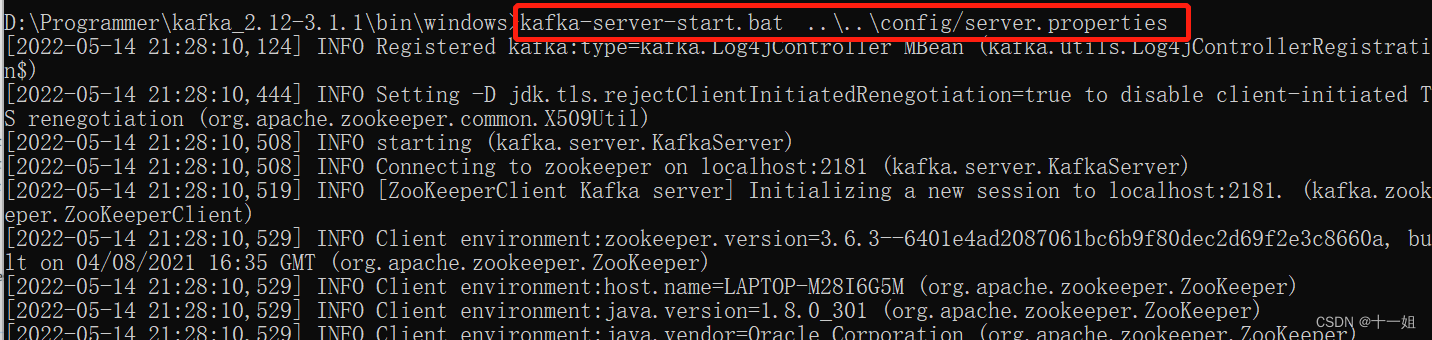
- 然后python就可以操作kafka了,注意这两个窗口不关
三、KafkaTool可视化工具
- KafkaTool下载,然后一路next即可,中间的安装路径可以自定义
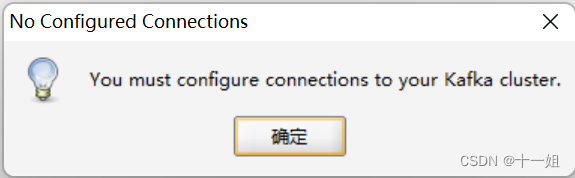
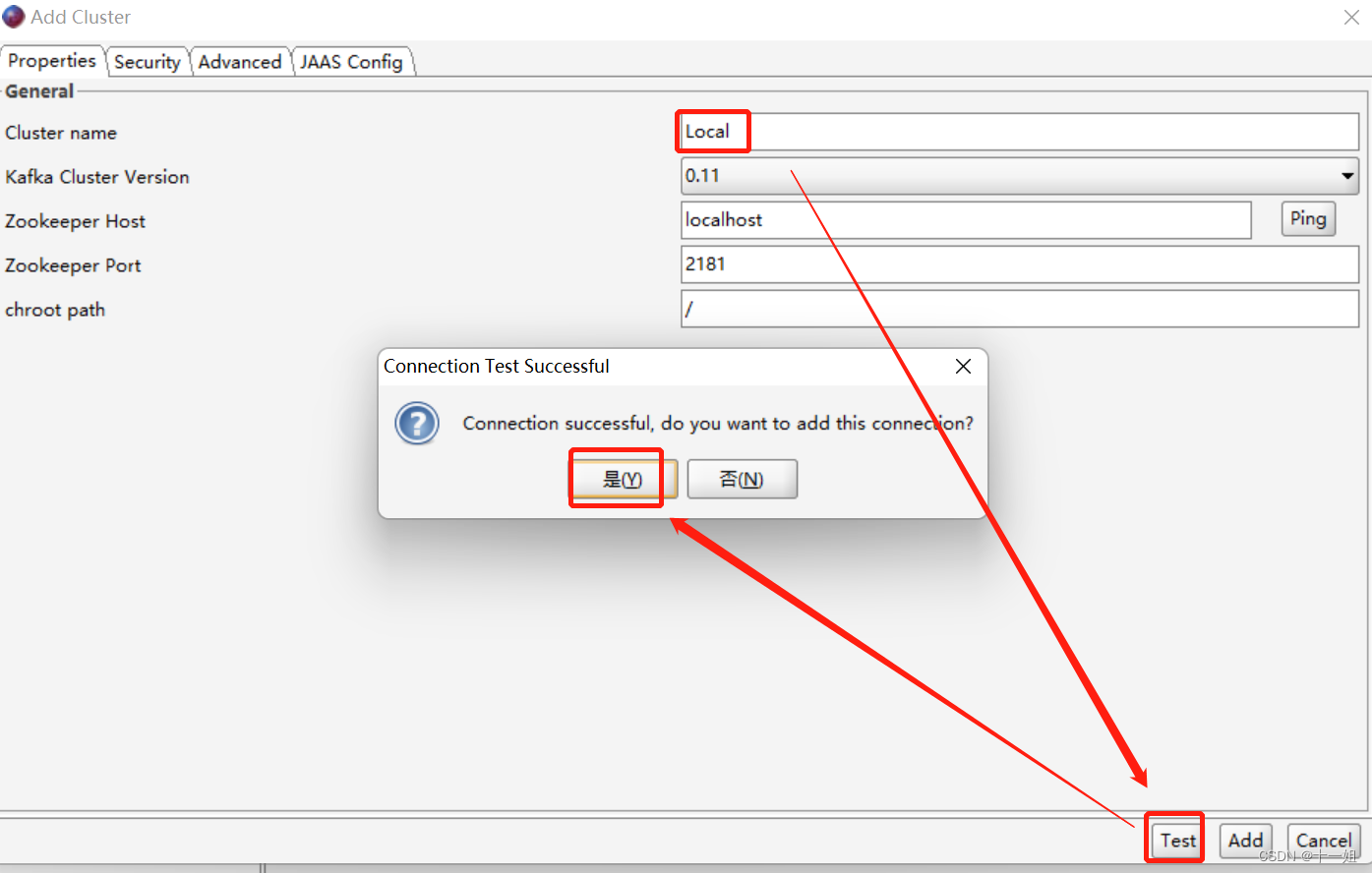
- 打开OffsetExploret,如图跳出提示,随意命名一个Cluster name即可连接
- 打开界面如下,可视化工具更详细的功能使用文档
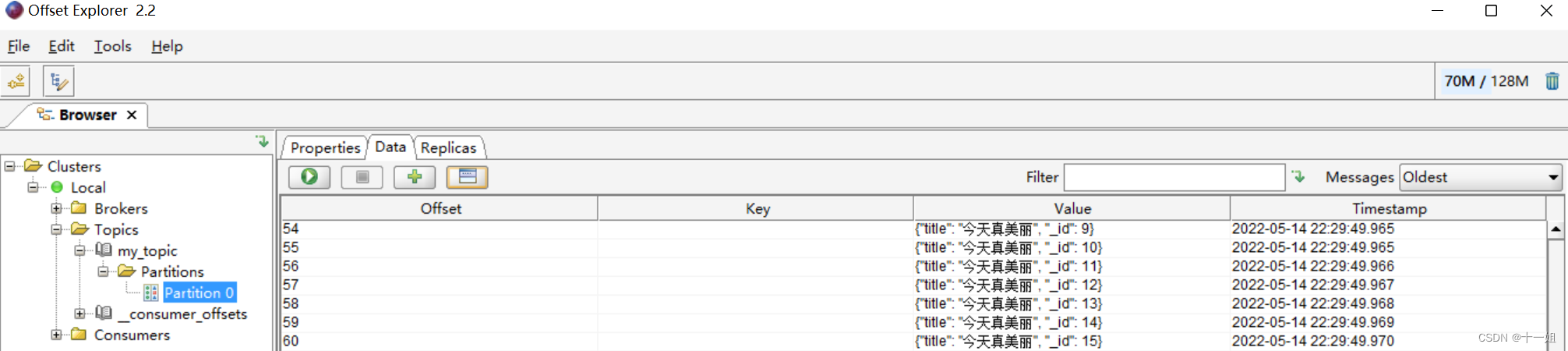
- 每个message默认是以
二进制形式展示的,可在如下Tools>Settings>Topics下设置为String的形式展示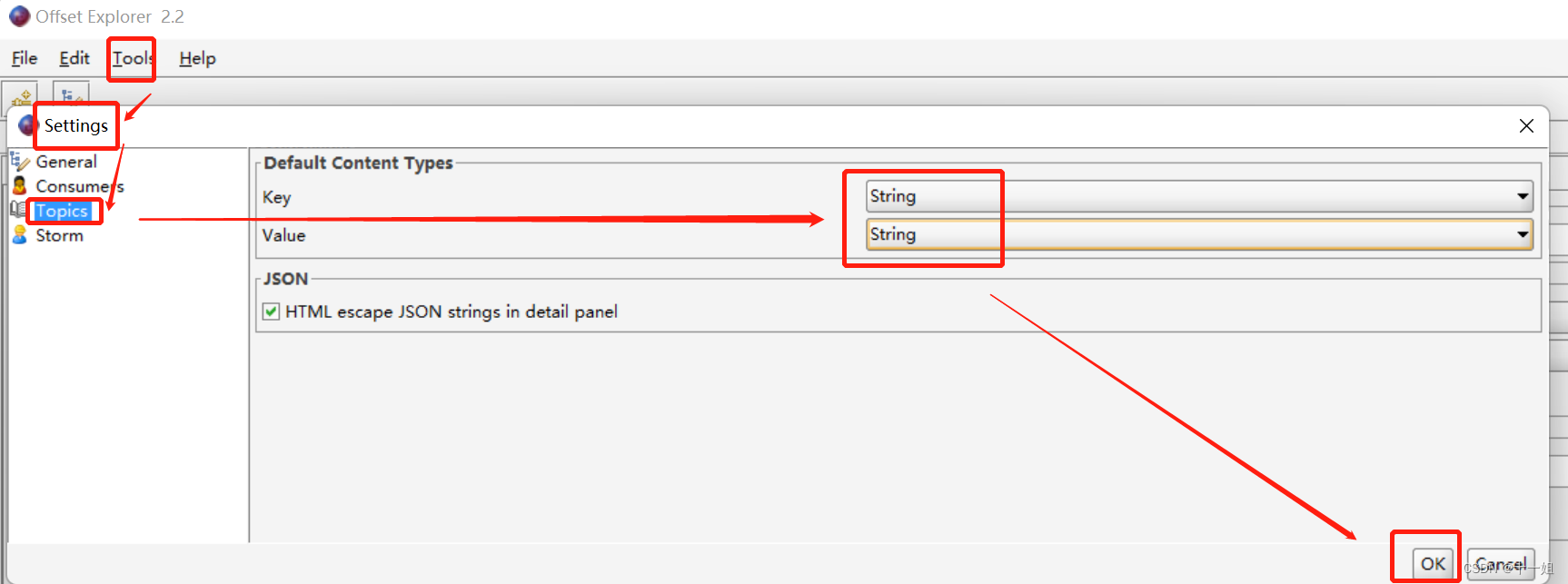
四、python操作kafka
pip install kafka-python- kafka-python基本使用
- 如何使用Python读写Kafka?
如果中断了重启,对于同一个group id消费者会继续上次的终止点继续消费,如果换了group id则从头开始消费- 因为Kafka的broker是无状态的,所以consumer必须使用partition offset来记录消费了多少数据。如果
一个consumer指定了一个topic的offset,意味着该consumer已经消费了该offset之前的所有数据;consumer可以通过指定offset,从topic的指定位置开始消费数据;consumer的offset存储在Zookeeper中,参考文档
- 新版kafka中,默认的partition是50
1、生产者代码
- 如图,第一个参数指定topic名称
from kafka import KafkaProducerproducer = KafkaProducer(bootstrap_servers=['localhost:9092'])record ={"title":"今天真美丽","url":"http://123123.jewr.com"}future = producer.send('my_topic', value=bytes(f'{record}', encoding='utf-8'), partition=0)result = future.get(timeout=10)print(result) - 参数
value_serializer用来指定序列化的方式,这里我使用 json 来序列化数据,从而实现我向 Kafka 传入一个字典,Kafka 自动把它转成 JSON 字符串的效果from kafka import KafkaProducerimport jsonproducer = KafkaProducer( bootstrap_servers=['localhost:9092'], max_block_ms=10000, max_request_size=10485760, send_buffer_bytes=10485760, value_serializer=lambda m: json.dumps(m, ensure_ascii=False).encode(), api_version=(0,10))for _id inrange(200,205): record ={"title":"今天真美丽","_id": _id} future = producer.send(topic='my_topic', value=record) result = future.get(timeout=10)print(result)
2、消费者代码
- 运行如下代码暂时没有显示,此时开另一个程序运行生产者代码,即会有输出显示;即监听生产者发布的消息,只要生产者新产生了一条消息,他就会print输出msg;
topic:topic的名称group_id:指定此消费者实例属于的组名,group_id这个参数后面的字符串可以任意填写;如果两个程序的Topic与group_id相同,那么他们读取的数据不会重复,两个程序的Topic相同,但是group_id不同,那么他们各自消费全部数据,互不影响bootstrap_servers: 指定kafka服务器auto_offset_rest这个参数有两个值,earliest和latest,如果省略这个参数,那么默认就是latest;参考如何使用Python读写Kafka:auto_offset_reset的作用,是在你的 group 第一次运行,还没有 offset 的时候,给你设定初始的 offset。而一旦你这个 group 已经有 offset 了,那么auto_offset_reset这个参数就不会再起作用了import timefrom kafka import KafkaConsumerconsumer = KafkaConsumer('my_topic', group_id='test_id', bootstrap_servers=['localhost:9092'], auto_offset_reset='earliest')for msg in consumer:print(msg)print(f"topic = {msg.topic}")# topic default is stringprint(f"partition = {msg.partition}")print(f"value = {msg.value.decode()}")# bytes to stringprint(f"timestamp = {msg.timestamp}")print("time = ", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(msg.timestamp /1000)))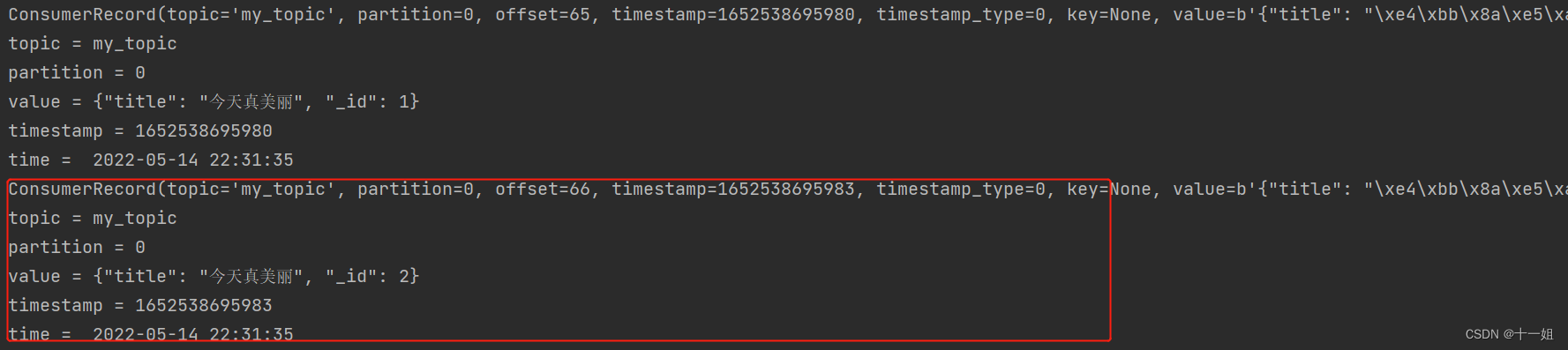
本文转载自: https://blog.csdn.net/weixin_43411585/article/details/124774360
版权归原作者 十一姐 所有, 如有侵权,请联系我们删除。
版权归原作者 十一姐 所有, 如有侵权,请联系我们删除。