
前言:
在搭建spark和Scala前提下,必需安装好hive和java,和 Hadoop的伪分布式 哦
一、下载spark和Scala
1、安装与配置Scale
(1)去官网下载Scala
官网地址:The Scala Programming Language (scala-lang.org)https://www.scala-lang.org/
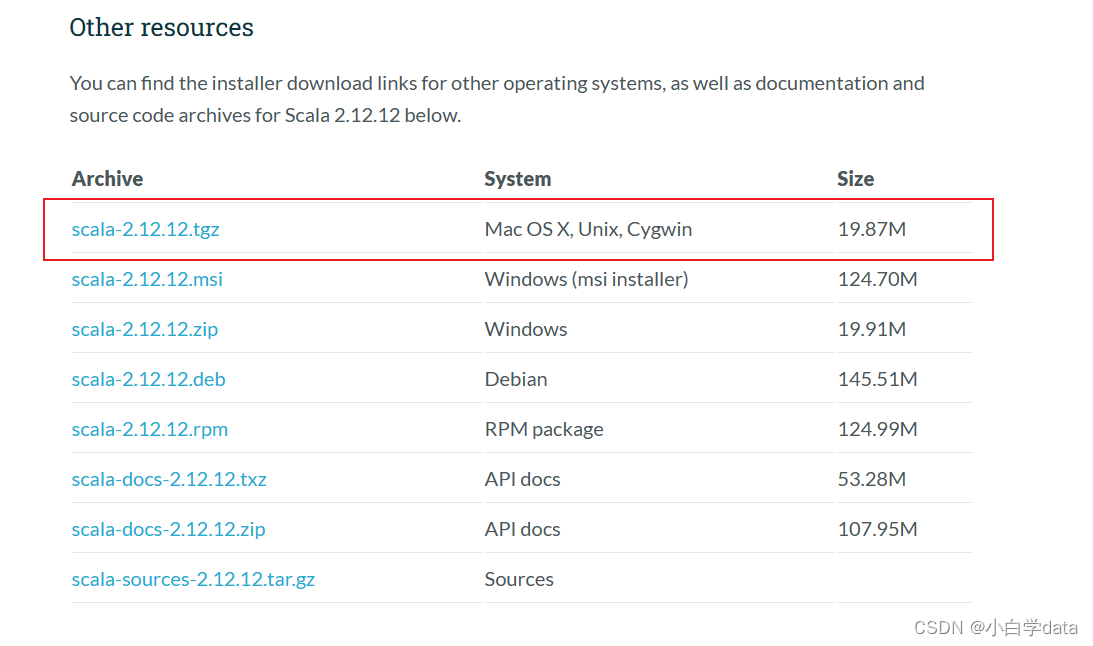
这里我要的是scala-2.2.12.12.tgz
然后我们点击 all releases

点进去之后往下找


然后找我们需要的tgz文件(注意:在Linux版本中我们需要用到 .tgz后缀)
(2)、安装Scala
这里我使用是xshell进行的操作,需要的可以自行下载,这里就不多做解释了(xshell)
打开xshell,连接虚拟机,找到xftp进行文件传输
然后进行文件的托拽到(/opt/software)目录下,也可以复制哦
这里是拖拽完后的出效果

然后我们用xshell进入到此目录下
代码为:
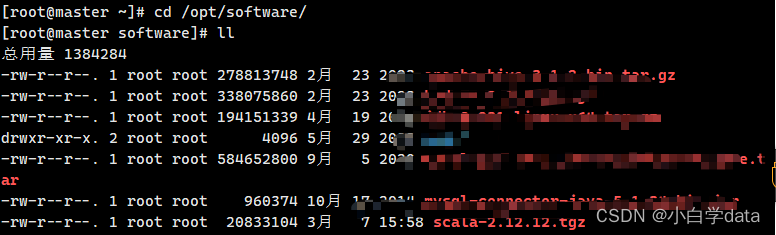
cd /opt/software/

进去之后可以看到我们的安装包
然后用tar命令解压文件,解压到/opt/module目录下
代码为:
tar -zxvf /opt/software/scala-2.12.12.tgz -C /opt/module/
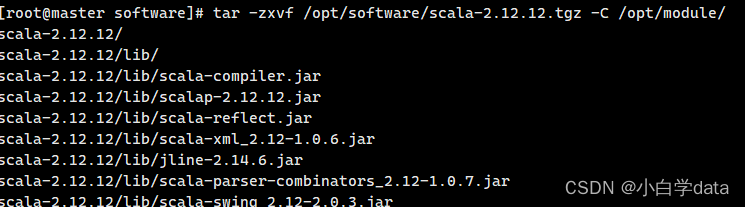
之后就进入/opt/module目录
cd /opt/module/
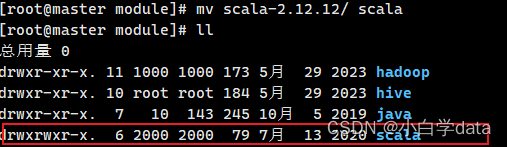
进行改名字
mv scala-2.12.12/ scala
查看,可以看到scala
(3)、配置scala的环境变量
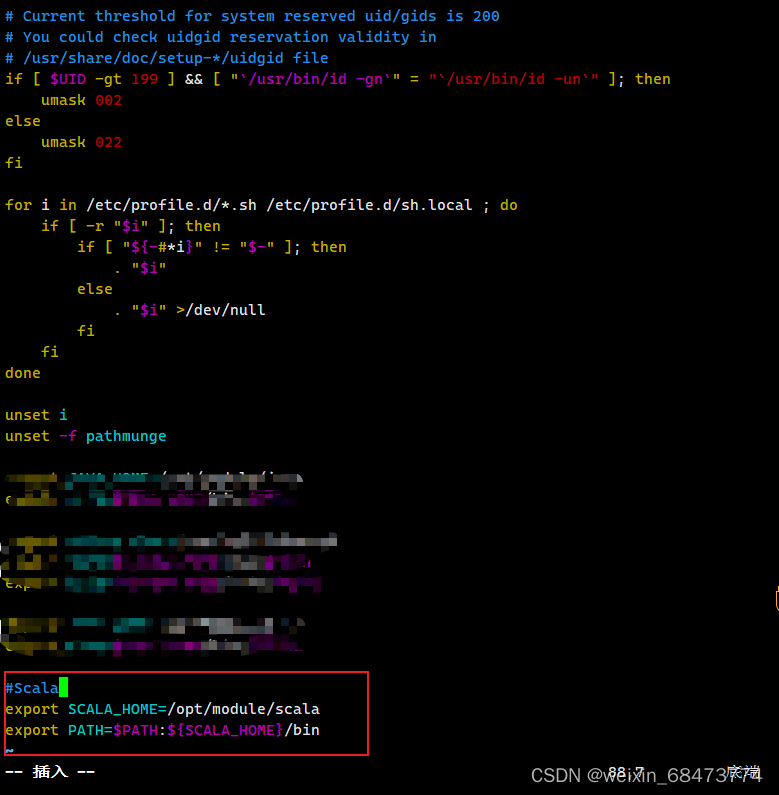
vim进入 /etc/profile目录
vim /etc/profile
键盘输入“a”,进行插入

插入俩行配置文件
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:${SCALA_HOME}/bin
这要注意路径问题,如果自己的路径与我不一样就需要改成你放Scala的目录下,还有空格的书写
然后退出保存,输入 :wq!
:wq!
然后用source重启环境文件
source /etc/profile

(4)、Scala的查看
用version查看
scala -version

输入scala后,看出现一下就说明搭建成功

二、spark部署与安装
(1)spark的下载
去官网下载sparkIndex of /sparkhttps://dlcdn.apache.org/spark/**点到里面去**

选择我们需要的版本
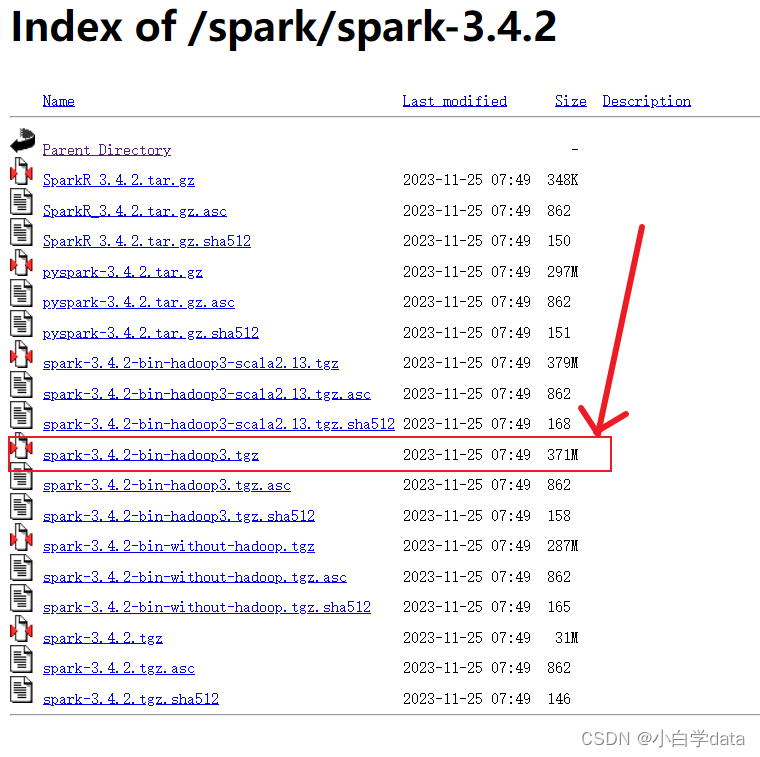
下载好后我们使用同样的办法把他放入到 /opt/software 目录下

我们进入到**/opt/software **目录下查看
cd /opt/software/
ll
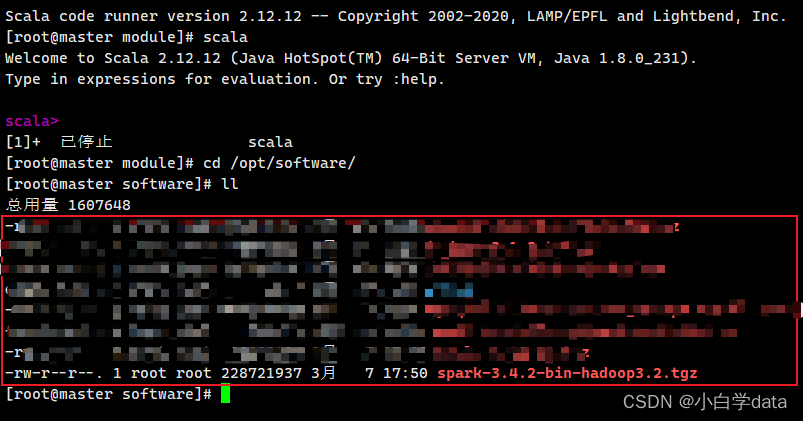
解压文件到 opt/module/ 目录下
代码
tar -zxvf spark-3.4.2-bin-hadoop3.2.tgz -C /opt/module/

把文件名改为spark
mv spark-3.1.1-bin-hadoop3.2 spark

(2)、配置spark的环境变量
用vim修改/etc/profile文件
vim /etc/profile

输入环境变量
代码
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
输入完后保存并退出
:wq!

保存好后就(重启)source一下配置文件
代码
source /etc/profile

(3)、修改配置文件
先备份文件cp spark-env.sh.template文件
进入到/conf目录下
cd /opt/module/spark/conf/
备份
cp spark-env.sh.template spark-env.sh

进行配置spark配置文件
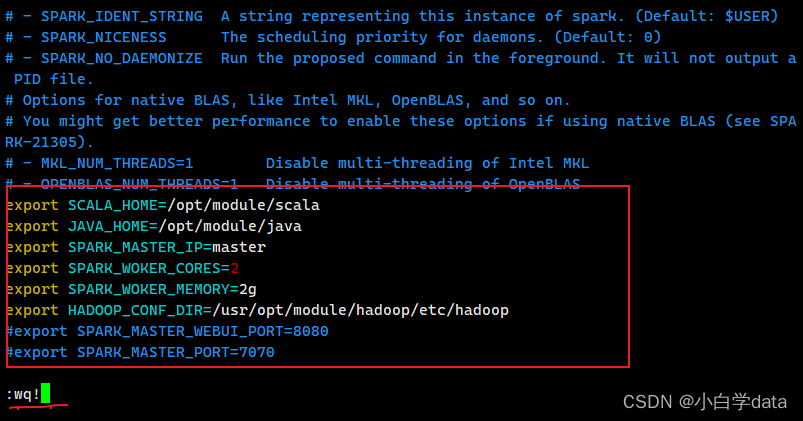
修改spark- env.sh文件,加以下内容:
vim spark-env.sh
内容:
export SCALA_HOME=/opt/module/scala
export JAVA_HOME=/opt/module/java
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/opt/module/hadoop/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
(4)进入spark/sbin 启动spark ./start-all.sh
cd /opt/module/spark/sbin
./start-all.sh

(5)查看spark
spark-submit --version
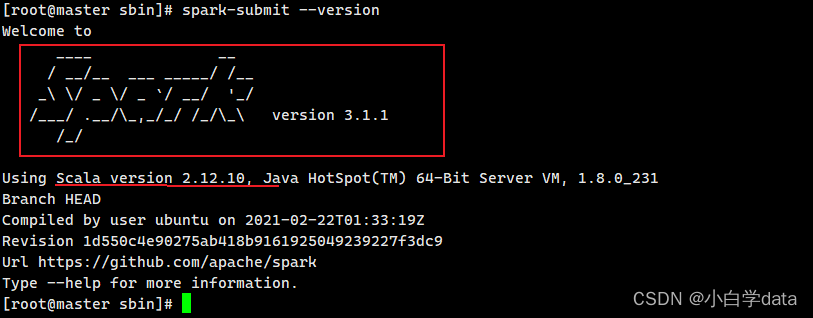

出现上面的情况,说明你的伪分布式的spark安装成功!!!
版权归原作者 小白学data 所有, 如有侵权,请联系我们删除。