
目录
循循渐进理解
wc.txt数据
hello java
spark hadoop flume kafka
hbase kafka flume hadoop
看下面代码会打印多少条-------------------------(RDD2)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Cache {defmain(args: Array[String]): Unit ={val sc =newSparkContext(newSparkConf().setMaster("local[4]").setAppName("test"))val rdd1: RDD[String]= sc.textFile("src/main/resources/wc.txt")val rdd2: RDD[String]= rdd1.flatMap(x =>{println("-------------------------")
x.split(" ")})val rdd3: RDD[(String, Int)]= rdd2.map(x =>(x,1))val rdd4: RDD[Int]= rdd2.map(x => x.size)
rdd3.collect()
rdd4.collect()
Thread.sleep(10000000)}}
正确答案是6条(**
解释一下wc.txt里面有三行数据,所以flatmap执行一次,会打印三条
**),因为执行了两个collect()行动算子(action)
大致流程就是这样,因为rdd2没有缓存,所以要执行两次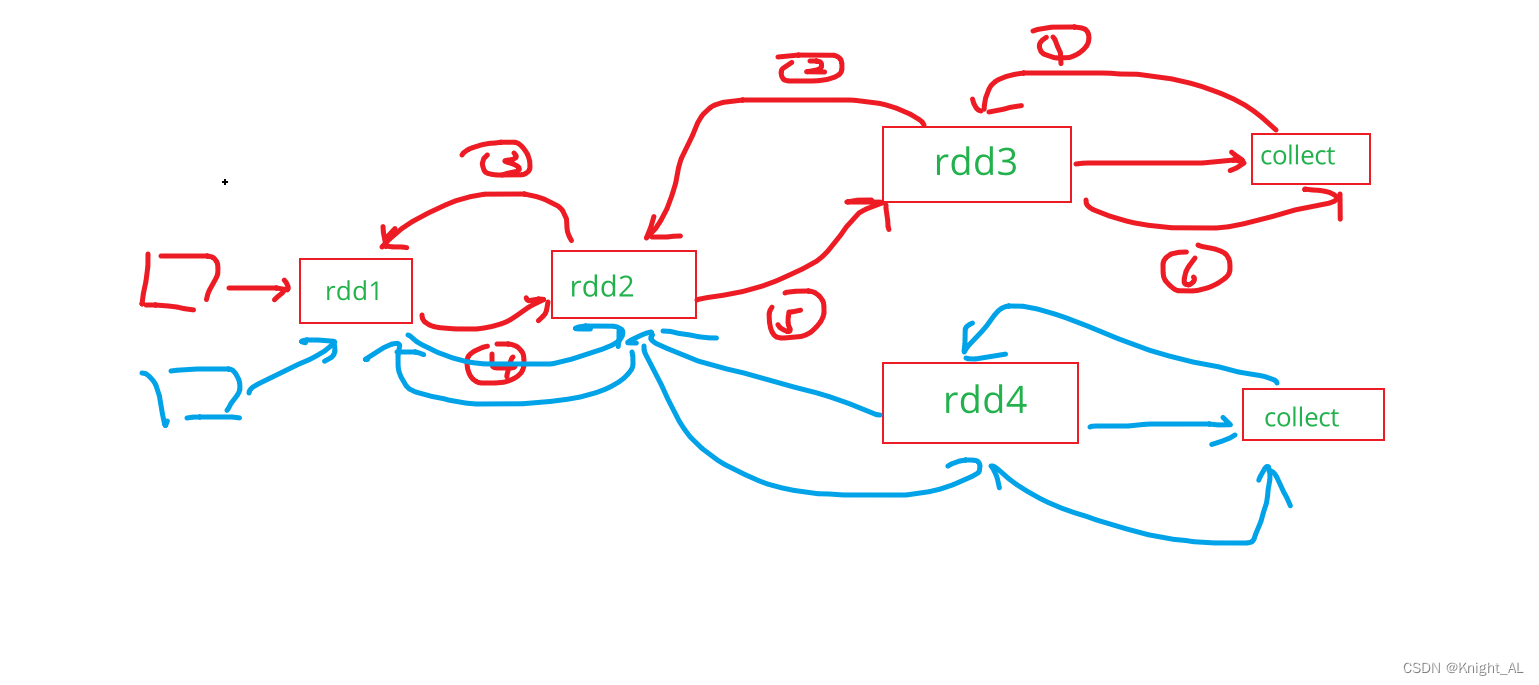
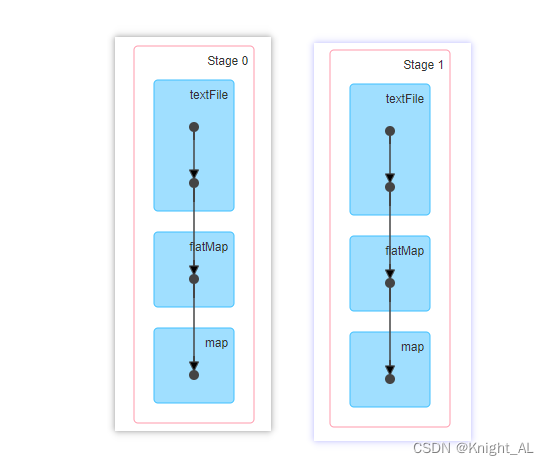
上述的问题
1.一个RDD在多个job中重复使用
- 问题:每个job执行的时候,该RDD之前处理布置也会宠物中
- 使用持久化的好处:可以将该RDD数据持久化后,后续job在执行在执行的时候可以直接获取数据计算,不用重读RDD之前数据处理
2.如果一个job依赖链条长
- 问题:依赖链条太长的时候,如果数据丢失需要重新计算浪费大量的空间
- 使用持久化的好处:可以直接持久化数据拿来计算,不用重头计算,节省时间
使用Cache或者Persist
看下面代码会打印多少条-------------------------(RDD2) 使用了Cache
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Cache {defmain(args: Array[String]): Unit ={val sc =newSparkContext(newSparkConf().setMaster("local[4]").setAppName("test"))val rdd1: RDD[String]= sc.textFile("src/main/resources/wc.txt")val rdd2: RDD[String]= rdd1.flatMap(x =>{println("-------------------------")
x.split(" ")})
rdd2.cache()val rdd3: RDD[(String, Int)]= rdd2.map(x =>(x,1))val rdd4: RDD[Int]= rdd2.map(x => x.size)
rdd3.collect()
rdd4.collect()
Thread.sleep(10000000)}}
正确答案是3条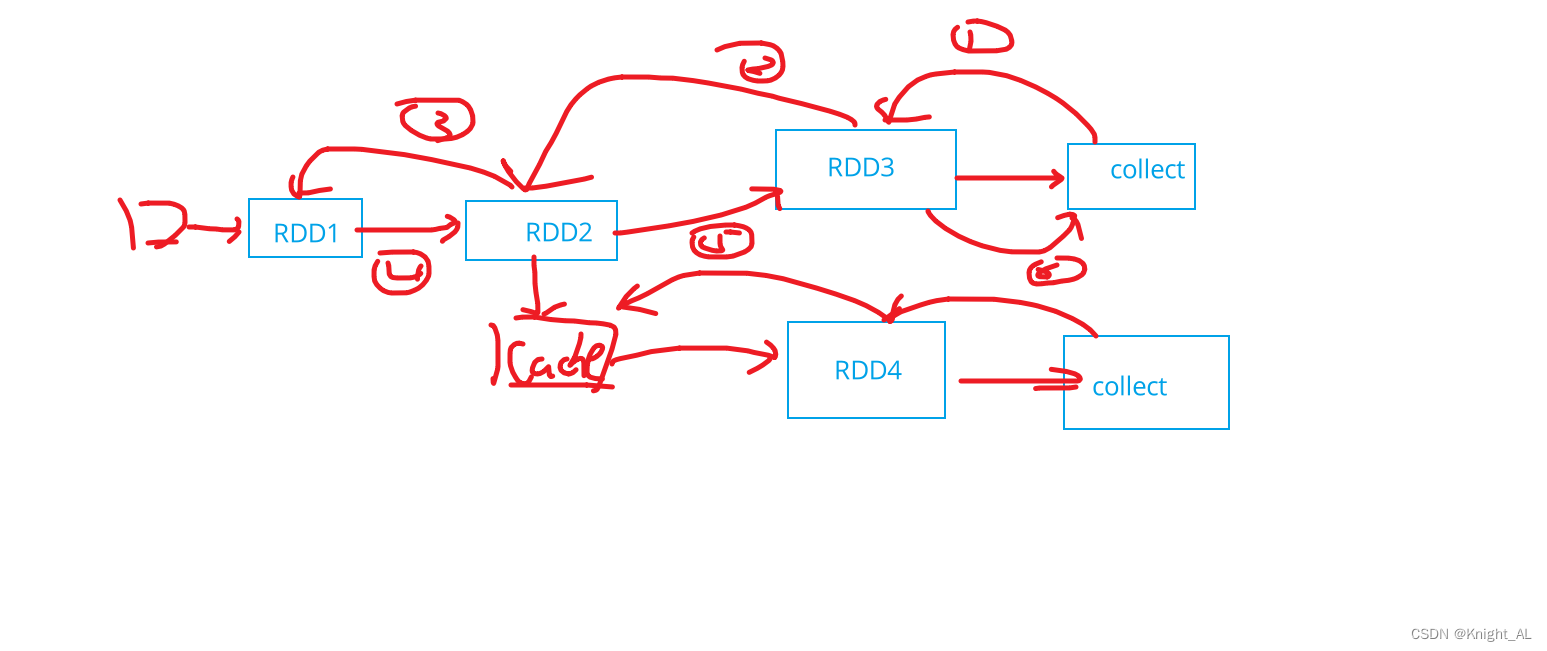
发现有个绿色点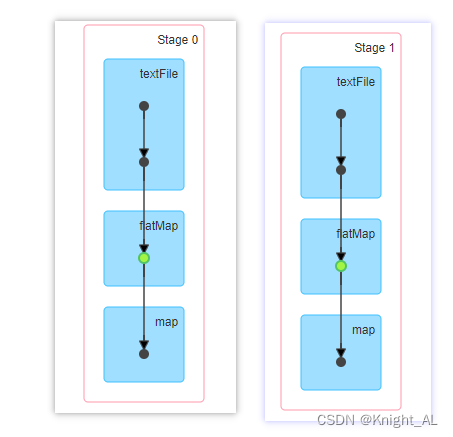
发现cache存到memory里面
RDD的持久化分为
缓存
- 数据保存位置: task所在主机内存/本地磁盘中
- 数据保存时机: 在缓存所在第一个Job执行过程中进行数据保存
- 使用: rdd.cache()/rdd.persist()/rdd.persist(StorageLevel.XXXX)
- cache与persist的区别- cache是只将数据保存在内存中(cache的底层就是persisit())
 - persist是可以指定将数据保存在内存/磁盘中
- persist是可以指定将数据保存在内存/磁盘中
- 常用的存储级别:- StorageLevel.MEMORY_ONLY:只将数据保存在内存中,一般用于小数据量场景- StorageLevel.MEMORY_AND_DISK:只将数据保存在内存+磁盘中,一般用于大数据量场景
CheckPoint
看下面代码会打印多少条-------------------------(RDD2) 使用了CheckPoint
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK
import org.apache.spark.{SparkConf, SparkContext}object Cache {defmain(args: Array[String]): Unit ={
System.setProperty("HADOOP_USER_NAME","root")val sc =newSparkContext(newSparkConf().setMaster("local[4]").setAppName("test"))
sc.setCheckpointDir("hdfs://hadoop102:8020/sparkss")val rdd1: RDD[String]= sc.textFile("src/main/resources/wc.txt")val rdd2: RDD[String]= rdd1.flatMap(x =>{println("-------------------------")
x.split(" ")})
rdd2.checkpoint()val rdd3: RDD[(String, Int)]= rdd2.map(x =>(x,1))val rdd4: RDD[Int]= rdd2.map(x => x.size)
rdd3.collect()
rdd4.collect()
rdd4.collect()
Thread.sleep(10000000)}}
正确答案是6条,无论你有多少个行动算子,他都是6条,因为在checkpoint rdd所在第一个job执行完成之后,**
会单独触发一个job计算得到rdd数据之后保存。
**
为什么要用CheckPoint的原因
缓存是将数据保存在主机磁盘/内存中,如果服务器宕机数据丢失,需要重新根据依赖关系计算得到数据,需要花费大量时间,所以需要将数据保存在可靠的存储介质HDFS中,避免后续数据丢失重新计算。
- 数据保存位置: HDFS
- 数据保存时机: 在checkpoint rdd所在第一个job执行完成之后,
会单独触发一个job计算得到rdd数据之后保存。 - 使用 - 1、设置保存数据的目录: sc.setCheckpointDir(path)- 2、保存数据: rdd.checkpoint
checkpoint会单独触发一个job执行得到数据之后保存,所以导致数据重复计算,此时可以搭配缓存使用: rdd.cache() + rdd.checkpoint(这样只会产生3条)
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK
import org.apache.spark.{SparkConf, SparkContext}object Cache {defmain(args: Array[String]): Unit ={
System.setProperty("HADOOP_USER_NAME","root")val sc =newSparkContext(newSparkConf().setMaster("local[4]").setAppName("test"))
sc.setCheckpointDir("hdfs://hadoop102:8020/sparkss")val rdd1: RDD[String]= sc.textFile("src/main/resources/wc.txt")val rdd2: RDD[String]= rdd1.flatMap(x =>{println("-------------------------")
x.split(" ")})
rdd2.cache()
rdd2.checkpoint()val rdd3: RDD[(String, Int)]= rdd2.map(x =>(x,1))val rdd4: RDD[Int]= rdd2.map(x => x.size)
rdd3.collect()
rdd4.collect()
rdd4.collect()
Thread.sleep(10000000)}}
缓存和CheckPoint的区别
1.数据保存位置不一样
- 缓存是将数据保存在task所在主机磁盘/内存中
- checkpoint是将数据保存到HDFS
2、数据保存时机不一样
- 缓存是rdd所在第一个Job执行过程中进行数据保存
- checkpoint是rdd所在第一个job执行完成之后保存
3、依赖关系是否保留不一样
- 缓存是将数据保存在task所在主机磁盘/内存中,所以服务器宕机数据丢失,需要根据依赖关系重新计算得到数据,所以rdd的依赖不能切除。
- checkpoint是将数据保存到HDFS,数据不会丢失,所以rdd的依赖后续就用不到了,会切除。
本文转载自: https://blog.csdn.net/qq_46548855/article/details/134436404
版权归原作者 Knight_AL 所有, 如有侵权,请联系我们删除。
版权归原作者 Knight_AL 所有, 如有侵权,请联系我们删除。