
一、主从复制原理
在企业应用中,成熟的业务通常数据量都比较大。单台MySQL在安全性、高可用性和高并发高并发方面都无法满足实际的需求。配置多台主从数据库服务器以实现读写分离。
mysql 的主从复制和mysql的读写分离两者有着紧密联系,首先要部署主从复制,
只有主从复制完成了,才能在此基础上进行数据的读写分离。
1、mysql 支持的复制类型
基于语句的复制(STATEMENT)。
在主服务器上执行的 SQL 语句,在从服务器上执行同样的语句。mysql 默认采用基于语句的复制,效率比较高。基于行的复制(ROW)。
把改变的内容复制过去,而不是把命令在从服务器上执行一遍。混合类型的复制(MIXED)。
默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
2、主从复制的原理 ☆
两日志
二进制日志: 记录数据库变动的信息(语句、变动记录)master
中继日志文件: 用于临时存放二进制文件内容。 slaves
三线程
master上: dump线程
slave上: i/o线程 sql线程
dump线程: ① 监听本地二进制日志 ② 记录I/O线程对应的slave位置
③同步二进制日志更新内容给I/O线程I/O线程: ①监听master的dump线程。②将slave信息发送给master 从服务器位置、日志的 position(记录位置), 超时时间 ③接受master的dump线程传递过来的更新信息
④写入relay-log中SQL线程:① 监听中继日志 ②将中继日志中的更新内容执行到自己的数据库中(保证从库与 主库执行相同操作)
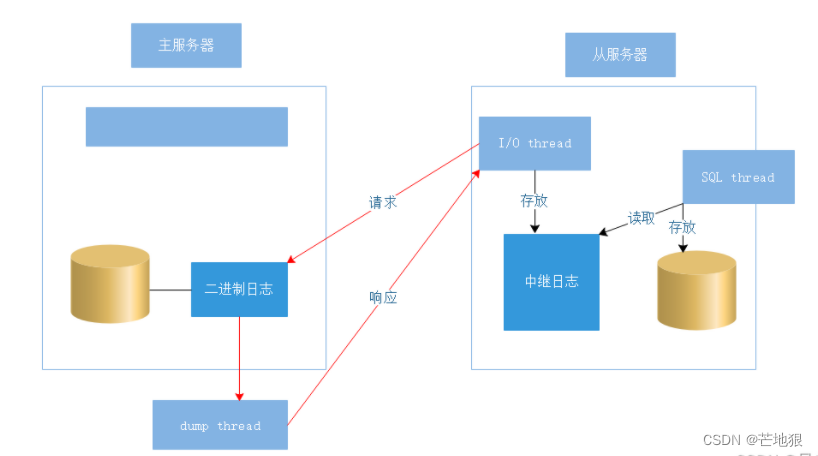
主MySQL 服务器做的增删改操作,都会写入自己的二进制日志(Binary log)
然后从MySQL 从服务器打开自己的 I/O线程 连接主服务器,进行读取主服务器的二进制日志
I/O 去监听二进制日志,一旦有新的数据,会发起请求连接
这时候会触发dump线程,dump thread响应请求,传送数据给I/O,通过tp的方式发送给I/O(dump线程要么处于等待,要么处于睡眠)
I/O 接收到数据之后存放在中继日志
SQL thread线程会读取中继日志里的数据,存放到自己的服务器中。
3、mysql主从复制方式
3.1、异步复制(Async Replication)
主库将更新写入Binlog日志文件后,不需要等待数据更新是否已经复制到从库中,就可以继续处理更多的请求。Master将事件写入binlog,但并不知道Slave是否或何时已经接收且已处理。在异步复制的机制的情况下,如果Master宕机,事务在Master上已提交,但很可能这些事务没有传到任何的Slave上。假设有Master->Salve故障转移的机制,此时Slave也可能会丢失事务。MySQL复制默认是异步复制,异步复制提供了最佳性能。
3.2、同步复制(Sync Replication)
主库将更新写入Binlog日志文件后,需要等待数据更新已经复制到从库中,并且已经在从库执行成功,然后才能返回继续处理其它的请求。同步复制提供了最佳安全性,保证数据安全,数据不会丢失,但对性能有一定的影响。
3.3、 半同步复制(Semi-Sync Replication)
写入一条数据请求到master,从服务器只要有一台接收到写入自己的中继日志,会给客户端返回一条接收成功的信息。
主库提交更新写入二进制日志文件后,等待数据更新写入了从服务器中继日志中,然后才能再继续处理其它请求。该功能确保至少有1个从库接收完主库传递过来的binlog内容已经写入到自己的relay log里面了,才会通知主库上面的等待线程,该操作完毕。
半同步复制,是最佳安全性与最佳性能之间的一个折中。
MySQL 5.5版本之后引入了半同步复制功能,主从服务器必须安装半同步复制插件,才能开启该复制功能。如果等待超时,超过rpl_semi_sync_master_timeout参数设置时间(默认值为10000,表示10秒),则关闭半同步复制,并自动转换为异步复制模式。当master dump线程发送完一个事务的所有事件之后,如果在rpl_semi_sync_master_timeout内,收到了从库的响应,则主从又重新恢复为增强半同步复制。
ACK (Acknowledge character)即是确认字符。
3.4、增强半同步复制(lossless Semi-Sync Replication、无损复制)
增强半同步是在MySQL 5.7引入,其实半同步可以看成是一个过渡功能,因为默认的配置就是增强半同步,所以,大家一般说的半同步复制其实就是增强的半同步复制,也就是无损复制。
增强半同步和半同步不同的是,等待ACK时间不同
rpl_semi_sync_master_wait_point = AFTER_SYNC(默认)
半同步的问题是因为等待ACK的点是Commit之后,此时Master已经完成数据变更,用户已经可以看到最新数据,当Binlog还未同步到Slave时,发生主从切换,那么此时从库是没有这个最新数据的,用户看到的是老数据。
增强半同步将等待ACK的点放在提交Commit之前,此时数据还未被提交,外界看不到数据变更,此时如果发送主从切换,新库依然还是老数据,不存在数据不一致的问题。
二、主从复制实验
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
1、Mysql主从服务器时间同步
1.1 主服务时间同步
yum -y install ntp 下载更新时间同步工具
ntpdate ntp1.aliyun.com 同步阿里云时间
systemctl start ntpd; 开启同步服务
或者设置本地时间源
vim /etc/ntp.conf 在末尾添加
server 127.127.0.0 #设置本地时钟源(网段与本机相同)
fudge 127.127.0.0 stratum 8 #设置时间层级为8(限制在15以为) 层级环设置本机的时间层级为8级,0级表示层级为0级,是向其他服务器时间同步源的意思,不要设置为0级
systemctl start ntpd; 开启同步服务


1.2 从服务器时间同步
yum -y install ntp 下载更新时间同步工具
ntpdate ntp1.aliyun.com 同步阿里云时间
systemctl start ntpd; 开启同步服务
或者同步指定的服务器
ntpdate 192.168.100.20 #指定同步NTP服务器
systemctl start ntpd; 开启同步服务
设置周期性计划同步主服务日志
crontab -e
- 1 * * 1 /usr/sbin/ntpdate 192.168.100.20



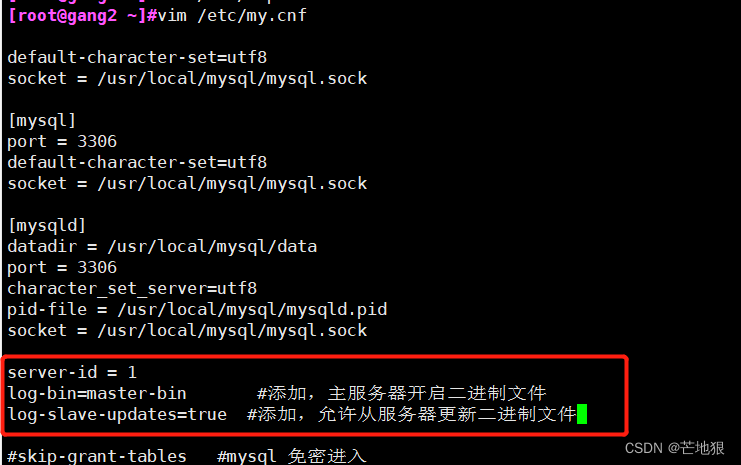
2、主服务器的mysql配置
vim /etc/my.cnf
[mysqld] 在这里插入
server-id = 1
log-bin=master-bin #添加,主服务器开启二进制日志
log-slave-updates=true #添加,允许从服务器更新二进制日志systemctl restart mysqld 重启
mysql -uroot -p #登录数据库
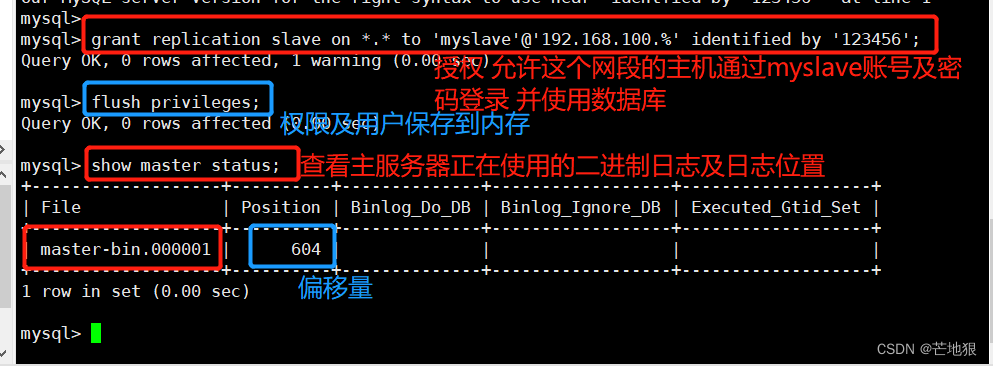
授权,允许192.18.100.0网段主机使用myslave账号及密码登录并使用数据库
grant replication slave on . to 'myslave'@'192.168.100.%' identified by '123456';
flush privileges; #将用户和权限配置保存在内存中
show master status; #查看master服务器当前正在执行的二进制日志位置,和列偏移量

注意:给从服务器授权时,可能会出现密码不符合当前策略要求
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
您的密码不符合当前策略要求
解决方法:
在数据库配置文件中添加一行,关闭密码策略vim /etc/my.cnf
[mysqld] 在这里插入
validate_password=off
配置好之后重启就好了
3、 slave从服务器的配置
vim /etc/my.cnf
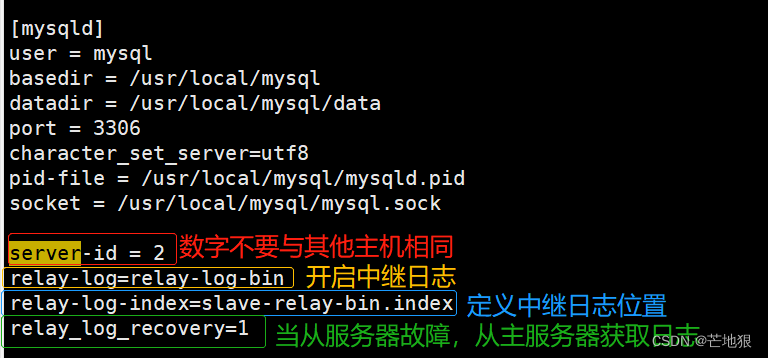
**server-id=2 ** #修改,id不能与master相同,两个slave也不能相同
relay-log=relay-log-bin #添加,开启中继日志,从服务器上同步master服务器日志文件到本地
relay-log-index=slave-relay-bin.index #添加,定义中继日志文件的位置和名称
**relay_log_recovery=1 **
#当 slave 从库宕机后,假如 relay-log 损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的 relay-log,并且重新从 master 上获取日志,这样就保证了relay-log 的完整性。默认情况下该功能是关闭的,将 relay_log_recovery 的值设置为 1 时, 可在 slave 从库上开启该功能,建议开启systemctl restart mysqld #启动mysqld服务器
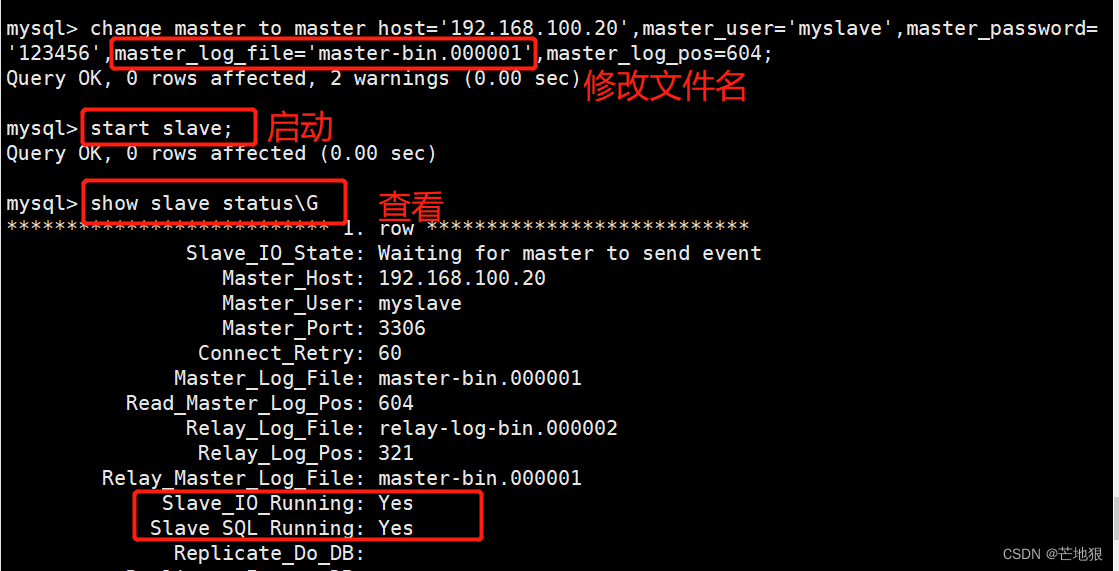
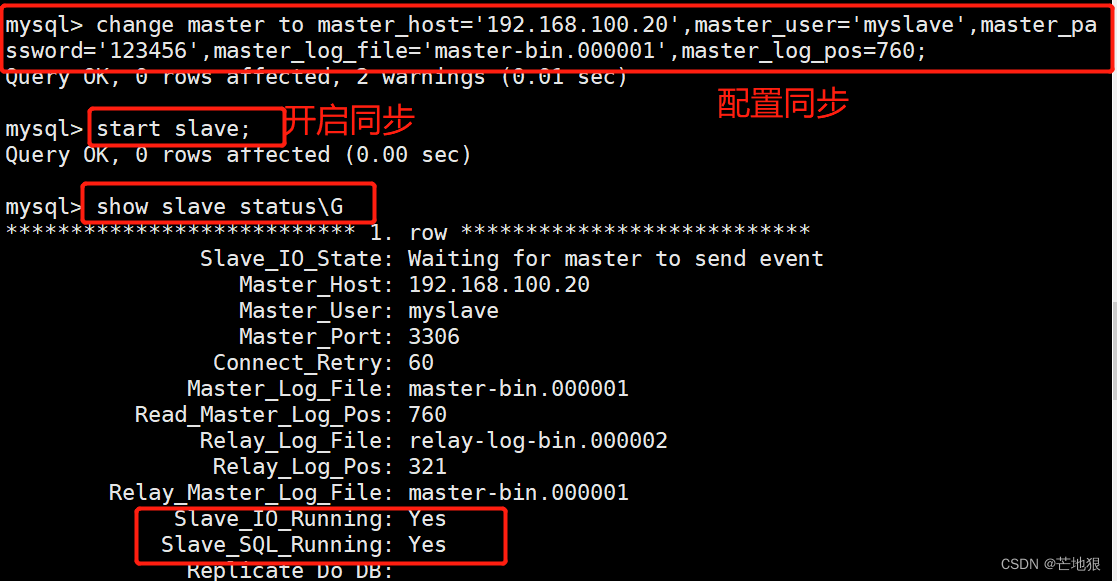
mysql -uroot -p123456 #登录数据库change master to master_host='192.168.100.20',
master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=604;
#配置同步,注意 master_log_file 和 master_log_pos 的值要与Master查询的一致,这里的是例子,每个人的都不一样start slave; #开启同步主从复制,如有报错执行 reset slave;
show slave status\G #查看 Slave 状态
//确保 IO 和 SQL 线程都是 Yes,代表同步正常。
Slave_IO_Running: Yes #负责与主机的io通信
Slave_SQL_Running: Yes #负责自己的slave mysql进程

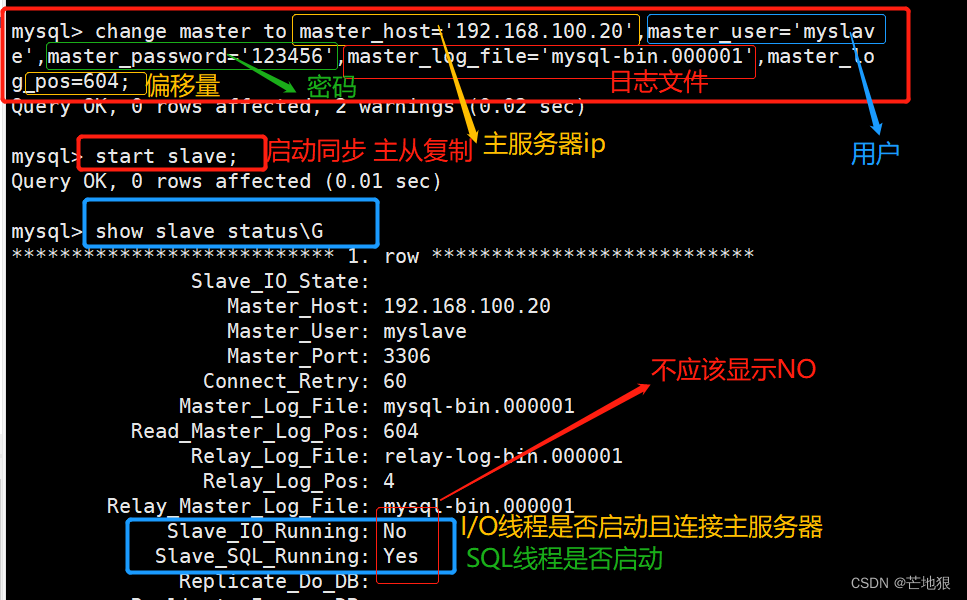
3.1 报错扩展 Slave_IO_Running: No的原因
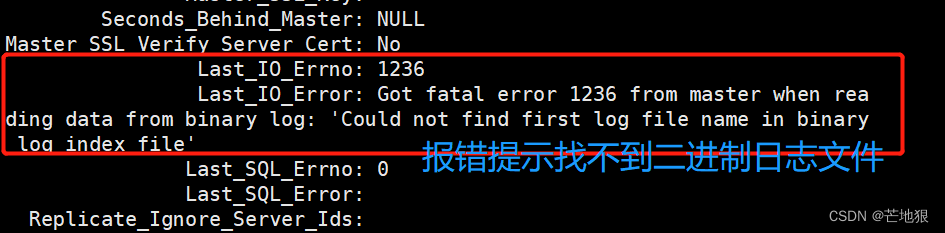
先总览看 : last_Error(报错数量) Last_Error(报错原因) 。
再看IO的报错: Last_IO_Errno: Last_IO_Error: 报错提示信息
一般 Slave_IO_Running: No 的可能性:
① 网络不通
② my.cnf配置有问题
③ 密码、file文件名、pos偏移量不对
④ 防火墙没有关闭
3.2 遇到Slave_SQL_Running:NO的情况
先总览看 : last_Error(报错数量) Last_Error(报错原因) 。
再看sql的报错: Last_SQL_Errno: 、Last_SQL_Error: 报错提示信息
#问题:slave_SQL_Running:NO 原因
1、程序可能在slave上进行了写操作
2、也可能是slave机器重起后,事务回滚造成的.
执行这个:set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
此处错误是二进制file 文件名出错
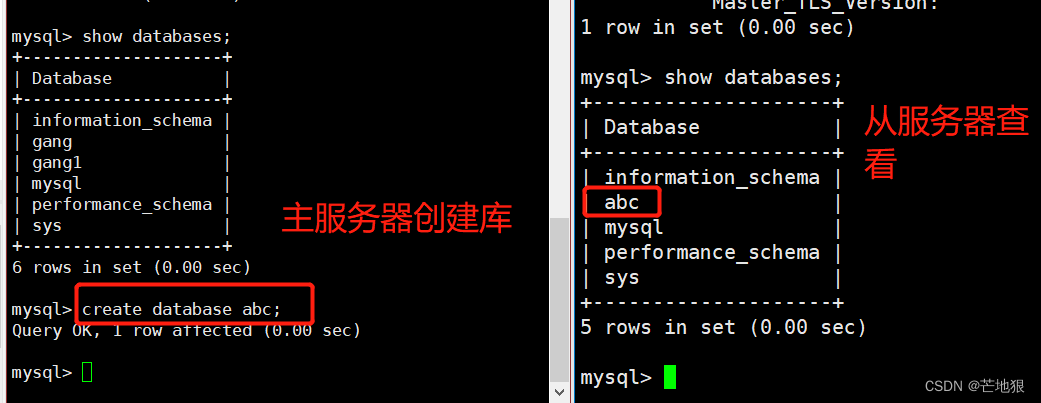
4、验证主从服务器效果
这里只配置一主一从
5、 在原有的主从服务器上在加一台从服务器slave2
5.1 时间同步
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
yum -y install ntp
ntpdate ntp1.aliyun.com 同步阿里云时间
systemctl start ntpd; 开启同步服务
或者同步指定的服务器
ntpdate 192.168.100.20 #指定同步NTP服务器
systemctl start ntpd; 开启同步服务
设置周期性计划同步主服务日志
crontab -e
- 1 * * 1 /usr/sbin/ntpdate 192.168.100.20



5.2 配置slave2的mysql配置文件
vim /etc/my.cnf
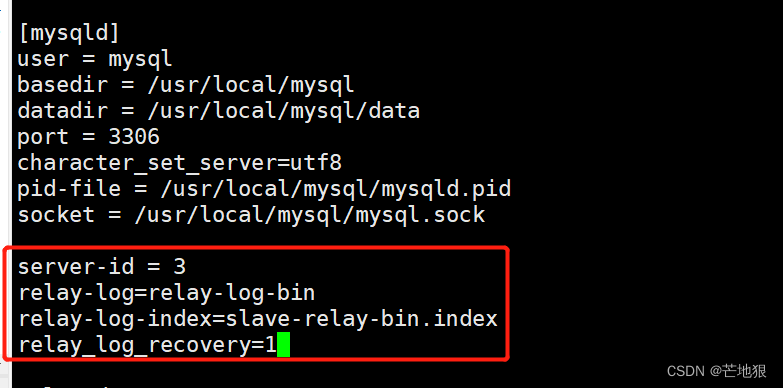
**server-id=3 ** #修改,id不能与master相同,两个slave也不能相同
relay-log=relay-log-bin #添加,开启中继日志,从服务器上同步master服务器日志文件到本地
relay-log-index=slave-relay-bin.index #添加,定义中继日志文件的位置和名称
**relay_log_recovery=1 **
#当 slave 从库宕机后,假如 relay-log 损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的 relay-log,并且重新从 master 上获取日志,这样就保证了relay-log 的完整性。默认情况下该功能是关闭的,将 relay_log_recovery 的值设置为 1 时, 可在 slave 从库上开启该功能,建议开启systemctl restart mysqld #启动mysqld服务器

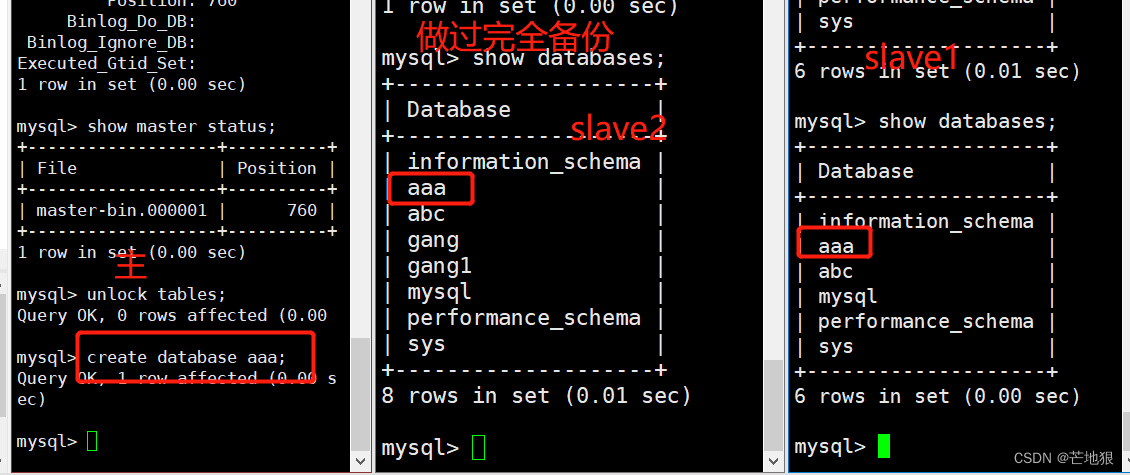
5.3 将主服务器数据导入到从服务器中
flush tables with read lock; //锁表防止后续数据写入,导致主从数据不一致
quit
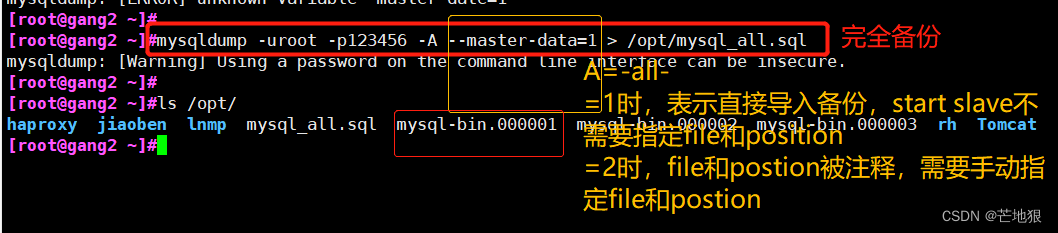
mysqldump -uroot -p123456 -A --master-data=1 > /opt/mysql_all.sql //完全备份
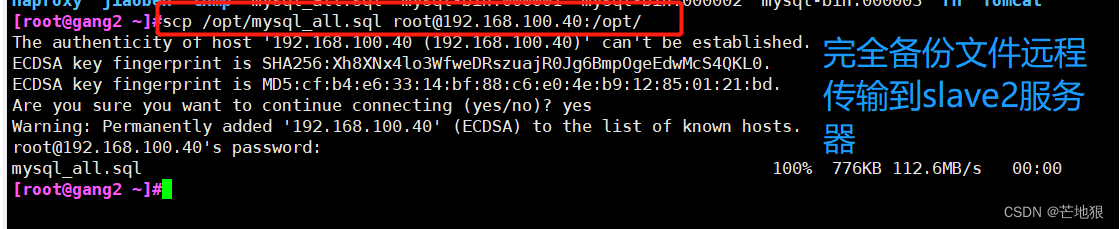
scp /opt/mysql_all.sql root@192.168.100.40:/opt //将完全备份文件发送到slave2
mysql -uroot -p123456 < /opt/mysql_all.sql //slave2同步master数据


5.4 在主服务器上查看当前偏移量
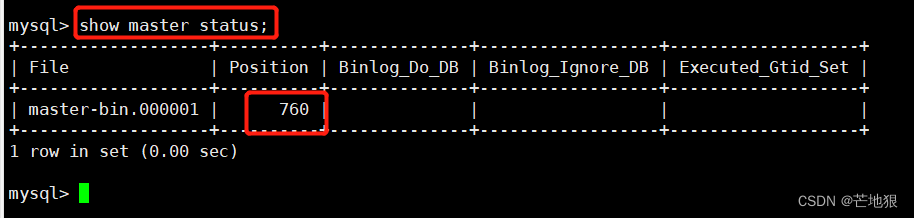
show master status; 查看偏移量及二进制日志文件
5.5 在从slave2服务器上配置与master服务器进行数据同步
mysql -uroot -p
change master to master_host='192.168.100.20' , master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=760;
#配置同步,在从服务器上指定主服务器 ,偏移量表示主服务器的二进制文件位置变量初始的位置。start slave; //开启主从复制同步
show slave status\G //查看主从复制
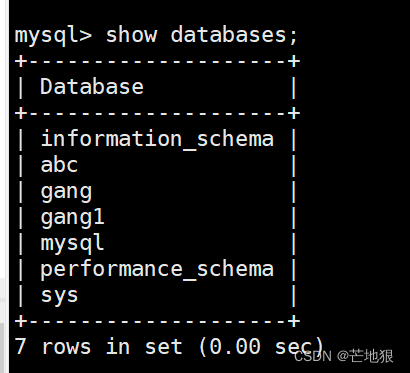
slave2从服务器查看完全备份数据
5.6 在主服务器上解锁表
解锁:UNLOCK TABLES ;

5.7 验证主从复制
在主服务器上创建库 在slave1与slave2上可以同时查看到
三、读写分离实验
做读写分离必须要做好主从复制的的环境,因为读写分离是基于主从复制的基础上去执行的架构。
1、前期环境
主机ip主服务器192.168.100.20从服务器1192.168.100.30从服务器2192.168.100.40Amoeba192.168.100.50客户端192.168.100.10
因为前面的主服务器和两台从服务器在前面主从复制的时候,已经部署好了,现在进行部署Amoeba代理服务器。
2、Amoeba服务搭建
systemctl stop firewalld
systemctl disable firewalld
setenforce 0

2.1 JDK环境安装
Amoeba服务时基于jdk1.5开发的,所有要使用jdk1.5或jdk1.6的版本,不建议使用高版本。
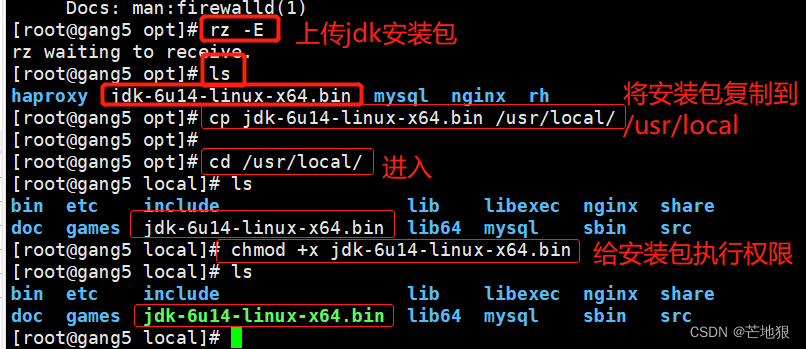
上传jdk-6u14-linux-x64.bin 到/opt
cp jdk-6u14-linux-x64.bin /usr/local #将jdk安装包复制到/usr/local目录下
cd /usr/local/ #进入local目录
chmod +x jdk-6u14-linux-x64.bin #给安装包执行文件
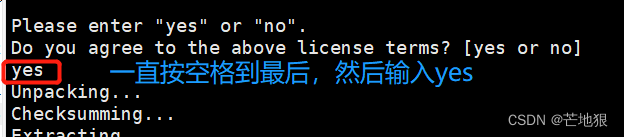
./jdk-6u14-linux-64.bin #安装jdk(按空格到最后一行,输入yes按回车)
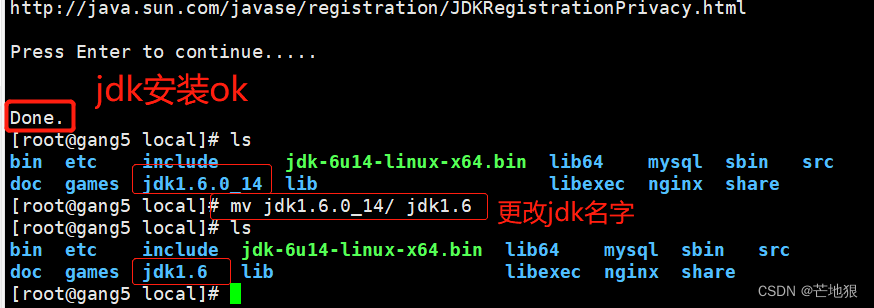
mv jdk1.6.0_14/ jdk1.6
#安装好之后在本地目录下生成jdk1.6.0_14目录,将其该名,方便后续操作vim /etc/profile #编辑全局配置文件
export JAVA_HOME=/usr/local/jdk1.6 #输出定义java的工作目录
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib #输出指定的java类文件
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin #将java加入工作环境
export AMOEBA_HOME=/usr/local/amoeba #输出定义的amoeba工作目录
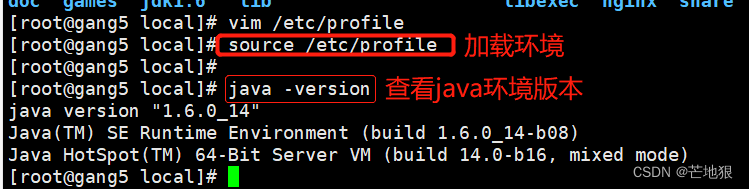
export PATH=$PATH:$AMOEBA_HOME/bin #加入路径环境变量source /etc/profile
#执行群居配置文件java -version
#查看java版本信息


2.2 Ameoba服务安装
mkdir /usr/local/amoeba
#创建amoeba的安装目录
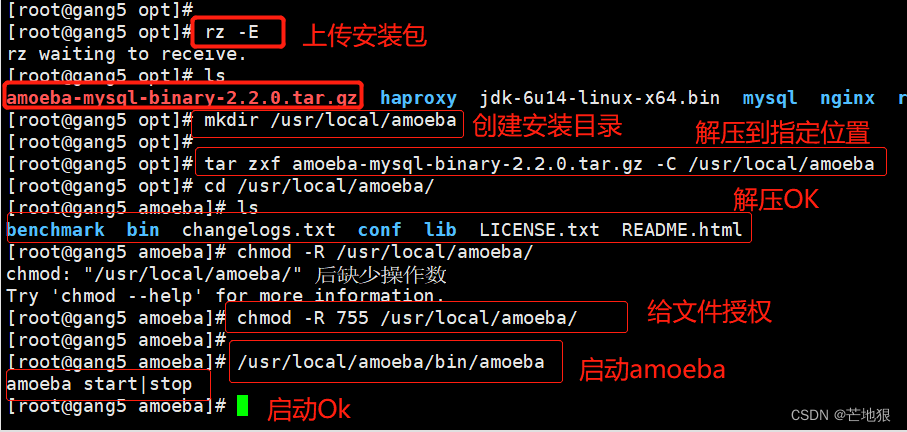
上传amoeba-mysql-binary-2.2.0.tar.gz安装包
tar zxvf /opt/amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba
#将amoeba的安装包解压到/usr/local/amoeba目录中chmod -R 775 /usr/local/amoeba
#给amoeba目录所有的权限/usr/local/amoeba/bin/amoeba
#开启amoeba(如果显示amoeba start |stop,则说明完成)
2.3 将三台mysql主从服务器设置权限
因为amoeba需要登录到三台mysql服务器进行读写,所以需要在三台服务器上进行授权。
grant all on . to 'amoeba'@'192.168.100.%' identified by '123456';



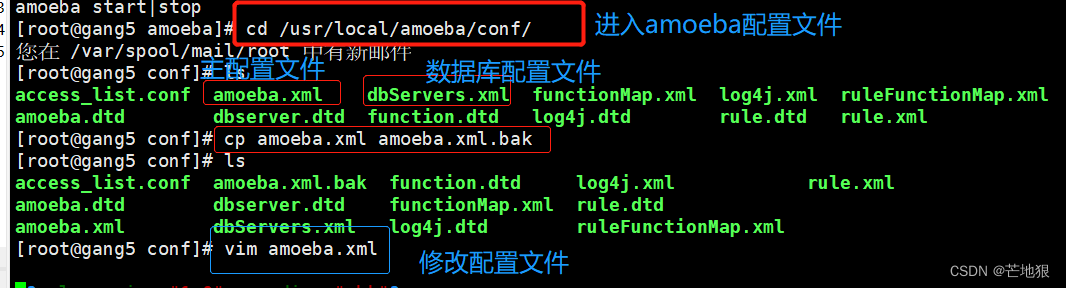
2.4 修改主配置文件 amoeba.xml
cd /usr/local/amoeba/conf
#进入配置文件cp amoeba.xml amoeba.xml.bak
#备份实现读写分离的文件vim amoeba.xml #进行修改配置(全局配置文件信息)
30行 <property name="user">amoeba</property>
#客户端访问amoeba使用的账号
32行 <property name="password">123456</property>
#这里是数据库访问amoeba服务器时使用账号时登录的密码
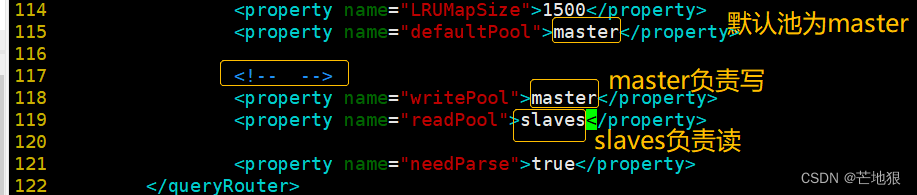
115行 <property name="defaultPool">master</property>
#修改默认池
118行 <property name="writePool">master</property>
#设置数据库写的池
119行 <property name="readPool">slaves</property>
#设置数据库读的池小结:amoeba.xml定义的是 用户通过amoeba访问数据库时“登录amoeba代理的账户,密码”。 定义amoeba代理的“读池”和“写池”的名称(读是:slaves,写是:master) #注意:这是第一个账户:定义的是client登录使用amoeba

2.5 修改数据库配置文件 dbServers.xml
cp dbServers.xml dbServer.xml.bak
#备份数据库配置文件vim dbServers.xml
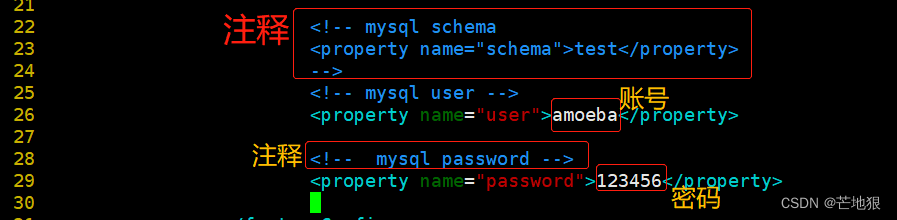
#23行 作用:注释!默认进入test库 以防mysql中没有test库时,会报错
****
#26修改 作用:访问mysql的账号
<property name="user">amoeba</property>#28-30去掉注释 作用:访问mysql的密码
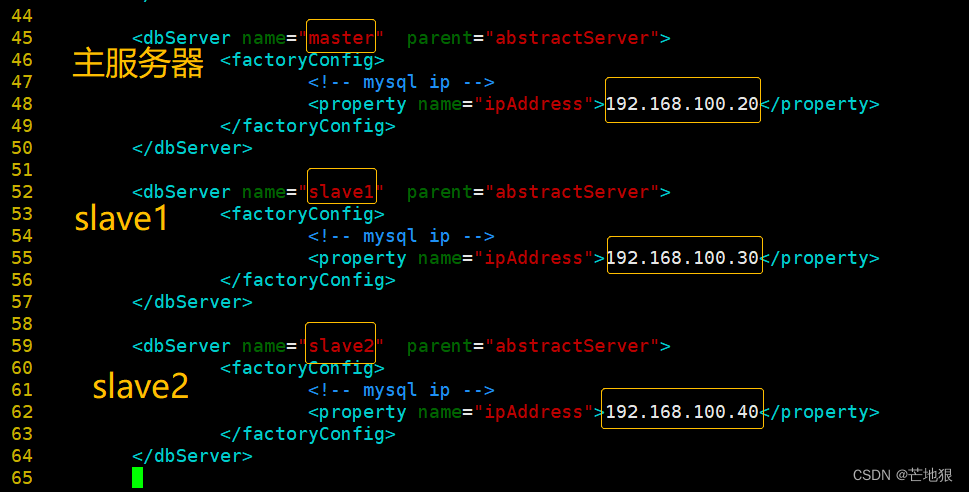
<property name="password">123456</property>#45修改,设置主服务器的名Master,作用:后端数据的一个节点名称
<dbServer name="**master**" parent="abstractServer">
#48修改,设置主服务器的地址
<property name="ipAddress">192.168.100.20</property>#52修改,设置从服务器1的名slave1
<dbServer name="**slave1**" parent="abstractServer">
#55修改,设置从服务器1的地址
<property name="ipAddress">192.168.100.30</property>#58 复制上面6行粘贴(52开始复制),设置从服务器2的名slave2和地址
<dbServer name="**slave2**" parent="abstractServer">
<property name="ipAddress">192.168.100.40</property>#65修改,作用:定义从服务器的池,因为有多个从服务器,主服务器不用,因为只有一个
<dbServer name="slaves" virtual="true">#71修改,作用:定义具体的从服务器的地址池的名称,跟52和58行要一致
<property name="poolNames">slave1,slave2</property>#67行 ,作用,定义了三种不同的分流模式,68行按序号选择模式
1、轮序模式,2、提权模式,3、高可用模式
#小结:dbServers.xml 主要定义了:
amoeba访问mysql数据库的用户和密码
定义了后端的mysql服务器具有的角色及其地址
定义了read poll读池有哪些。


2.6 启动amoeba服务
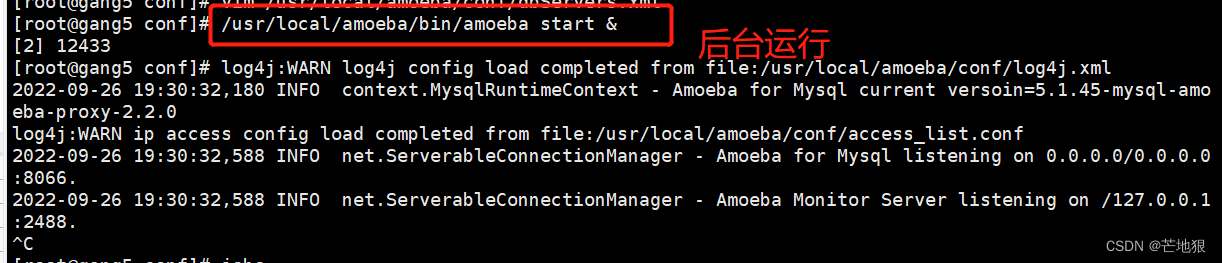
/usr/local/amoeba/bin/amoeba start & 防止后台启动amoeba
jobs 查看后台运行程序
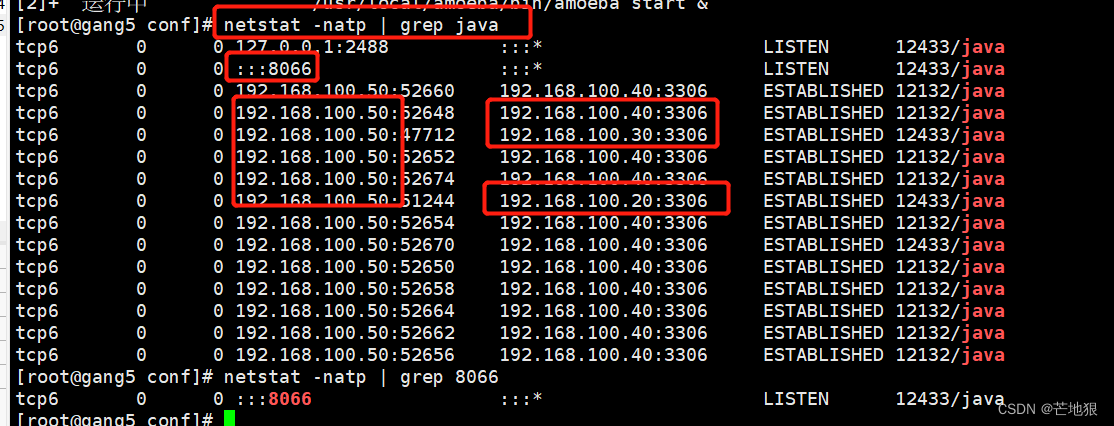
netstart -natp |grep java
netstart -natp |grep 8066

3、客户机测试验证
systemctl stop firewalld
setenforce 0yum -y install mariadb
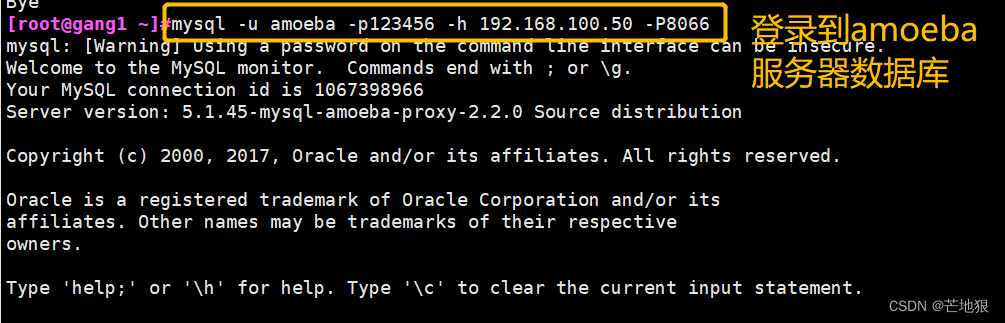
#下载数据库(centos7 默认的数据库)mysql -u amoeba -p123456 -h 192.168.100.50 -P8066
#登录到amoeba服务器,-h:指定ip,-P:指定端口
3.1 验证写入是否从master主机写入
#验证的目结果:主要为了验证从客户端登录可以进行可以写入数据到数据库中,而且是通过master服务器写入的。
在客户端登录到amoeba代理服务器上,进行创建一个表。
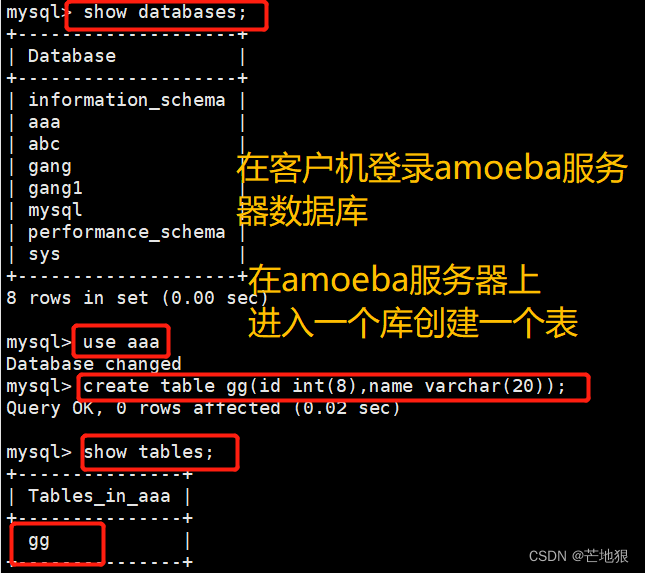
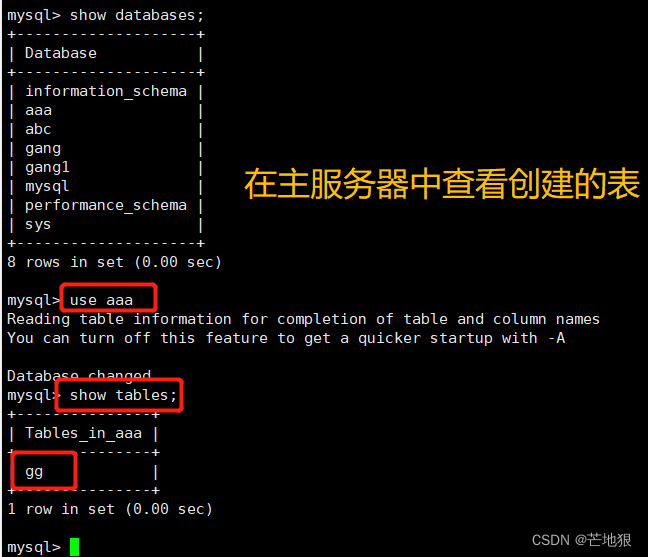
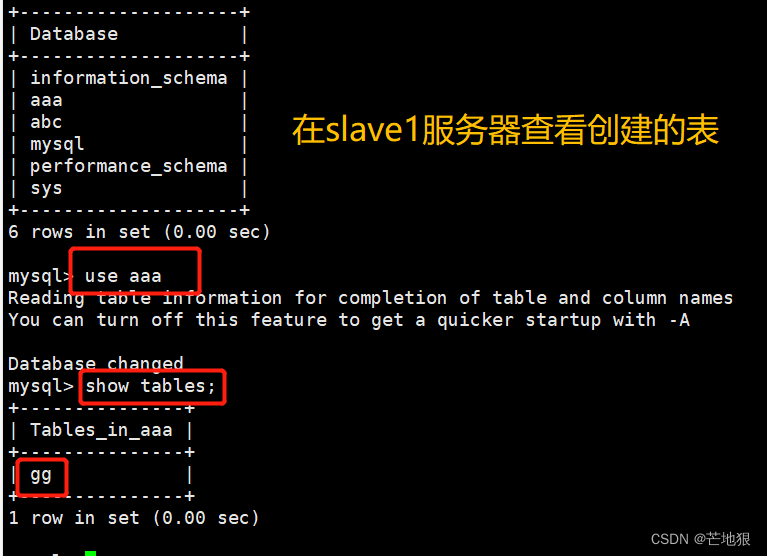
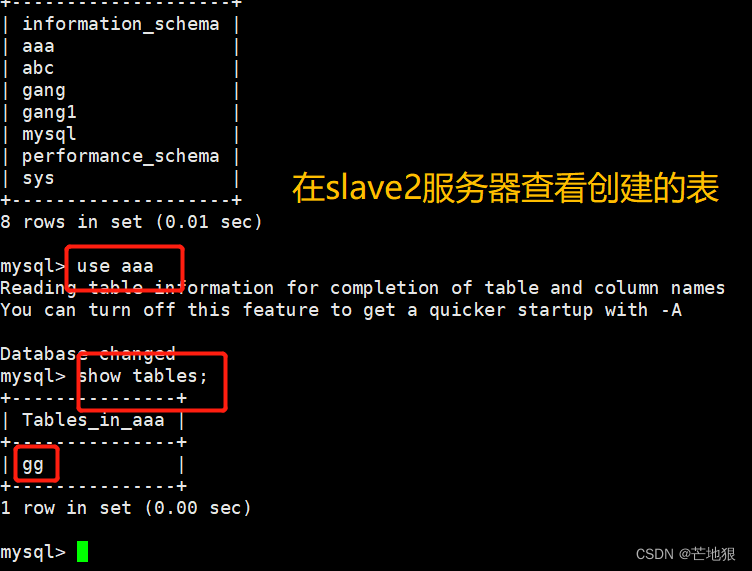
去master和两台slave上查看是否可以看到创建的表
3.2 测试是否读写分离
测试目的结果:主要验证写是靠matser写入数据,而读取数据时靠两台从服务器(slave)进行读取
先关闭两台slave的主从同步


在客户端上进行插入一条数据到的用户

去master主机上查看数据是否写入成功
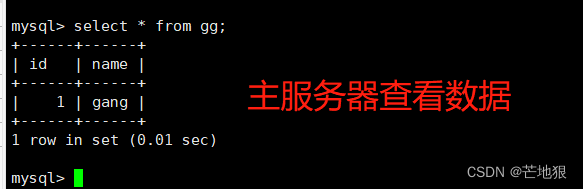
去两台slave从服务器查看数据,查看不到

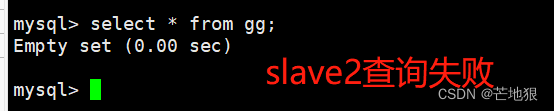
且在客户端上进行登录也查看不到数据

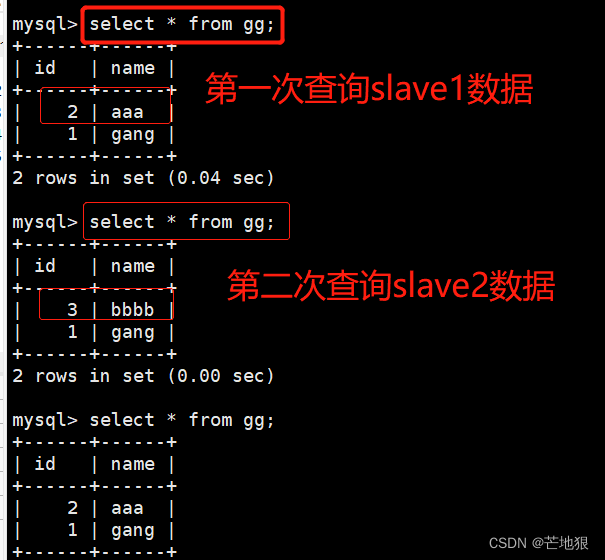
3.3 测试读的时候,是否是以轮询方法
验证目的结果:验证在读取数据库内容时,以轮询的方式读取数据库中的内容。
slave1,slave2各添加不同的数据,并开启主从同步
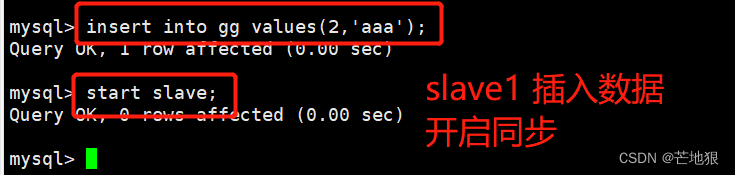
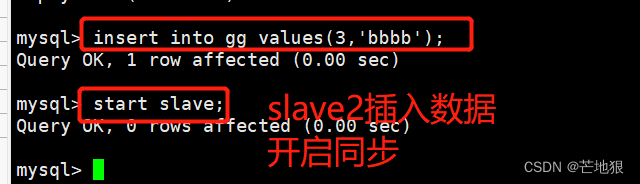
在客户端进行读写数据库中的内容
四、总结
1、主从复制
主从复制,简单理解就是2个日志文件,三个线程。
两日志
二进制文件: 记录数据库变动的信息(语句、变动记录)
中继日志文件: 用于临时存放二进制文件内容。
三线程
dump线程: ①监听I/O线程请求。②将二进制日志文件更新的数据发送给slave的I/O线程。
I/O线程: ①监听master主机的二进制文件。②向master的dump线程发出同步请求
SQL线程: 读取中继日志中的文件,更新到本机的数据库。
2、读写分离
读写分离,简单来说,就是基于主从复制来进行读和写的操作,但是读和写是分开来的,读是在slave服务器上,写是在master服务器上,这样做的 目的可以很好的缓解master的压力,而且在生产环境中,读的频率要搞,所以salva服务器可以设置多套服务器,使用轮询,权重、哈希的分流策略进行分摊压力。
版权归原作者 芒地狠 所有, 如有侵权,请联系我们删除。