
文中jdk与hadoop版本可能与博主不同 文中出现的所有jdk1.8.0_361和hadoop-2.7.7都要换成你所下载的jdk和hadoop版本,下方链接是我的jdk和hadoop压缩包自行提取。
链接:https://pan.baidu.com/s/132aoruf7SuUfqRisyR4TrQ?pwd=xu75
提取码:xu75
vim命令编辑器安装
书中是利用gedit进行文本编辑,利用xshell进行连接时不能使用gedit,而且有编辑状态下按上下左右键变成ABCD,所以个人喜欢使用vim命令编辑器。也可以跳过这一步,将文中vim命令全部换成gedit,vim安装命令如下:
sudo apt-get remove vim-common 卸载原先的vim-common组件。
sudo apt-get install vim 卸载完成后安装vim编辑器
SSH配置
sudo apt-get install ssh 安装ssh
ssh-keygen -t rsa 输入后一直回车即可

cd ~/.ssh/ 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa 会有提示,都按回车就可以
cat ~/.ssh/id_rsa.pub >> ~ /.ssh/authorized_keys # 加入授权
chmod 755 ~
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
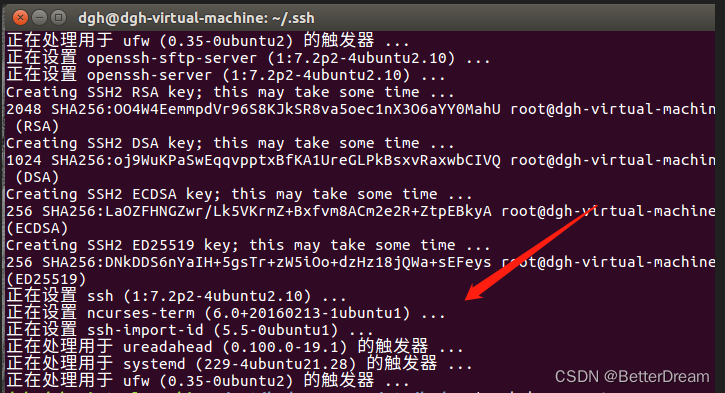
安装完成后出现以下界面
** **
ssh 主机名 登陆测试一下 使用hostname查看主机名
将jdk和hdoop移动到opt文件夹里(本人是放入了opt文件夹,可以根据自己喜好设置,记好这个位置 多次要用)
cd /opt 切换到放置jdk和hadoop的文件夹
tar -zxvf jdk压缩包 依次进行解压
tar -zxvf hadoop压缩包 可以在当前目录下使用table键进行补全
JDK配置
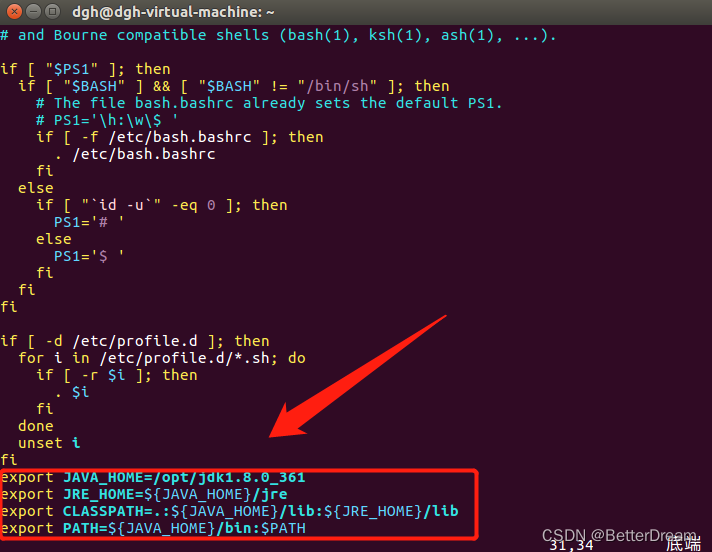
sudo vim /etc/profile 编辑profile文件
按i进入编辑模式
在末尾添加以下代码
export JAVA_HOME=/opt/jdk1.8.0_361
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
:wq 保存并退出
source /etc/profile 更新全局变量
java -version 查看jdk是否配置成功
** 出现以下界面即为JDK安装成功**
hadoop 配置
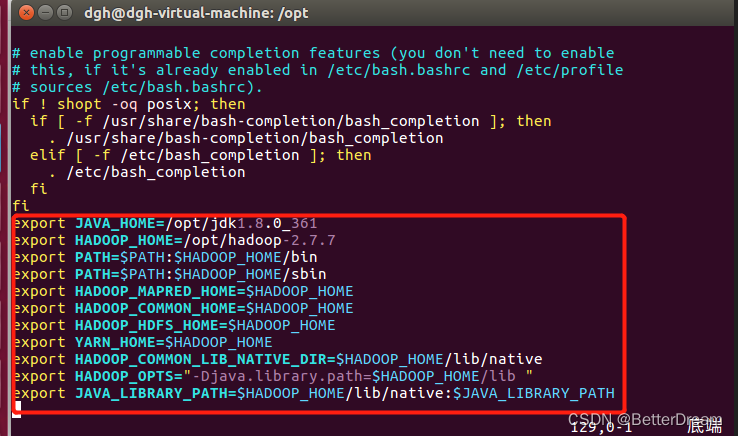
sudo vim ~/.bashrc 编辑bashrc文件
按i进入编辑模式
添加以下代码
export JAVA_HOME=/opt/jdk1.8.0_361
export HADOOP_HOME=/opt/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib "
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/
:wq 保存并退出
source ~/.bashrc 刷新环境变量
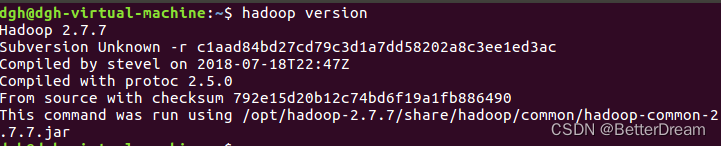
输入 hadoop version 查看是否安装成功
出现以下界面即为安装成功
hadoop 配置文件
**cd /opt/hadoop-2.7.7/etc/hadoop **进入hadoop目录下进行配置
sudo vim hadoop-env.sh 打开hadoop-env.sh进行编辑
按i进入编辑模式
添加 export JAVA_HOME=/opt/jdk1.8.0_361
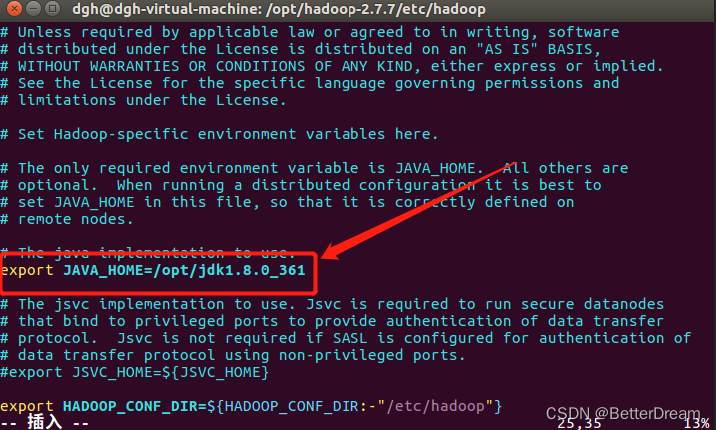
以下标红的字体都是根据本机ip地址和你jdk hadoop 所放置的文件夹自行更改
ifconfig #查看本机ip地址
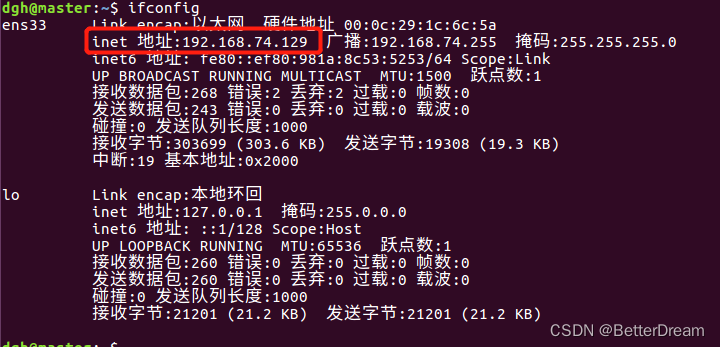
以下几个配置文件的代码都要放到箭头所指的地方
切记配置文件不要打错字 否则会出错
sudo vim yarn-site.xml 打开yarn-site.xml进行编辑
按i进入编辑模式
</property><property> <name>yarn.resourcemanager.hostname</name> <value>192.168.244.129</value></property><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value>**sudo vim hdfs-site.xml 打开hdfs-site.xml进行编辑 **
按i进入编辑模式
<property> <name>dfs.replication</name> <value>1</value> </property><property> <name>dfs.namenode.name.dir</name> <value>file:///opt/hadoop-2.7.7/hadoop_data/hdfs/namenode</value> </property><property> <name>dfs.datanode.data.dir</name> <value>file:///opt/hadoop-2.7.7/hadoop_data/hdfs/datanode</value> </property><property> <name>dfs.http-address</name> <value>192.168.244.129:50070</value> </property>sudo vim core-site.xml 打开core-site.xml进行编辑
按i进入编辑模式
</property><property> <name>fs.defaultFS</name> <value>hdfs://192.168.244.129:9000</value> </property> <!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop2.7.7/dataNode_1_dir</value>sudo vim mapred-site.xml 打开mapred-site.xml进行编辑
按i进入编辑模式
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>

最后修改
sudo vim /etc/profile ** #**打开/etc/profile进行编辑
按i进入编辑模式
在末尾添加
export PATH=${JAVA_HOME}/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME=./hadoop-2.7.7
:wq # 保存并退出
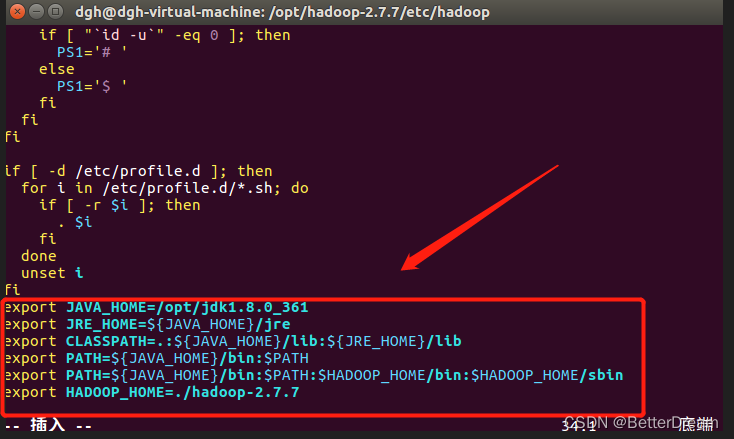
#创键并格式化文件系统
sudo mkdir -p ./hadoop-2.7.7/hadoop_data/hdfs/namenode
sudo mkdir -p ./hadoop-2.7.7/hadoop_data/hdfs/datanode
sudo mkdir -p ./hadoop-2.7.7/dataNode_1_dir/datanode
集群格式化及启动
hdfs namenode -format #将hdfs格式化
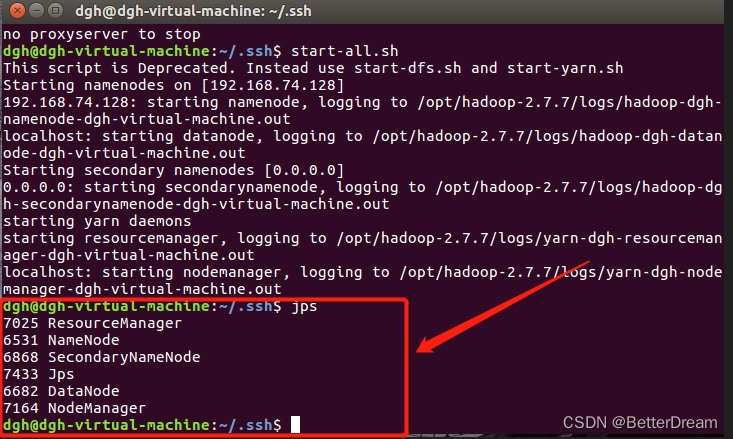
start-all.sh #启动集群
输入jps命令查看运行的节点
出现以下节点则证明伪分布安装成功
stop-all.sh #关闭集群
谢谢观看!!如果有错误请各位大佬及时提出,有问题也可以留言问我,欢迎补充!!!!
版权归原作者 BetterDream 所有, 如有侵权,请联系我们删除。