
目标数据:爬取从2007年到2022年,各地级市中级法院历年关于“环境污染”的裁判文书数量。
由于裁判文书网需要登录,Selenium手动接管爬取可避免频繁登录造成的封号风险。
Selenium如何手动接管Edge浏览器:
1、打开终端,将命令 /Applications/Microsoft\ Edge.app/Contents/MacOS/Microsoft\ Edge --remote-debugging-port=9222 --user-data-dir="/Users/libraf/Documents/Edge"复制到终端里然后enter,其中:
/Applications/Microsoft\ Edge.app/Contents/MacOS/Microsoft\ Edge 表示Edge浏览器驱动路径(Edge浏览器驱动是selenium爬虫所必要的);
--remote-debugging-port=9222 表示一个空闲端口,通常照抄即可;
--user-data-dir="/Users/libraf/Documents/Edge" 表示浏览器配置文件存放路径,防止污染原本的Edge浏览器配置,"/Users/libraf/Documents/Edge" 为一个存在的任意路径即可。
2、打开裁判文书网(https://wenshu.court.gov.cn),登录完成并设定好相关筛选条件后,再用以下代码使selenium接管浏览器。
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Edge(executable_path='msedgedriver',options=options)
数据爬取:
如下图所示,选定关键词“环境污染”和法院层级“中级法院”,以2022年为例。图中左侧“地域及法院”为需要的数据。
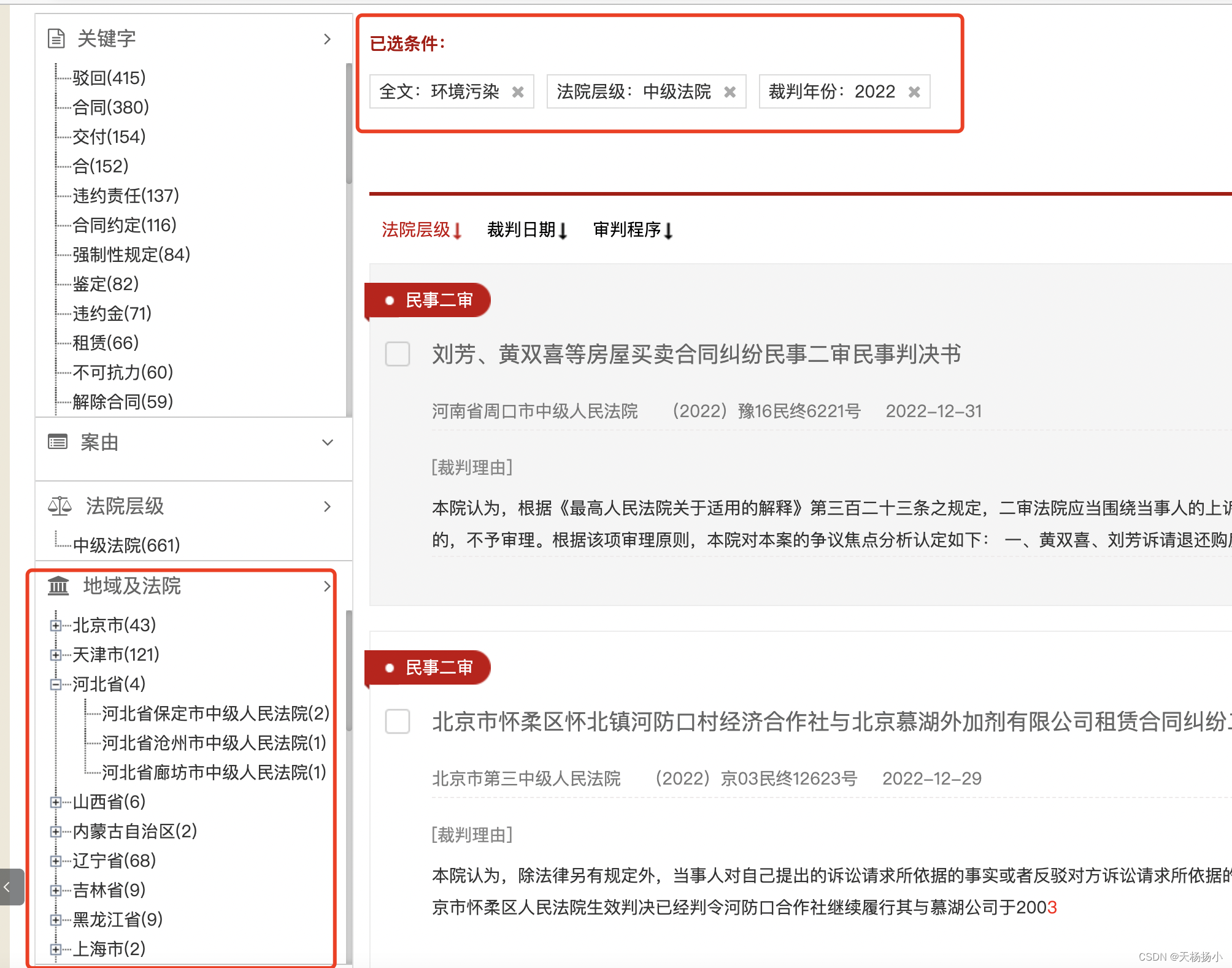
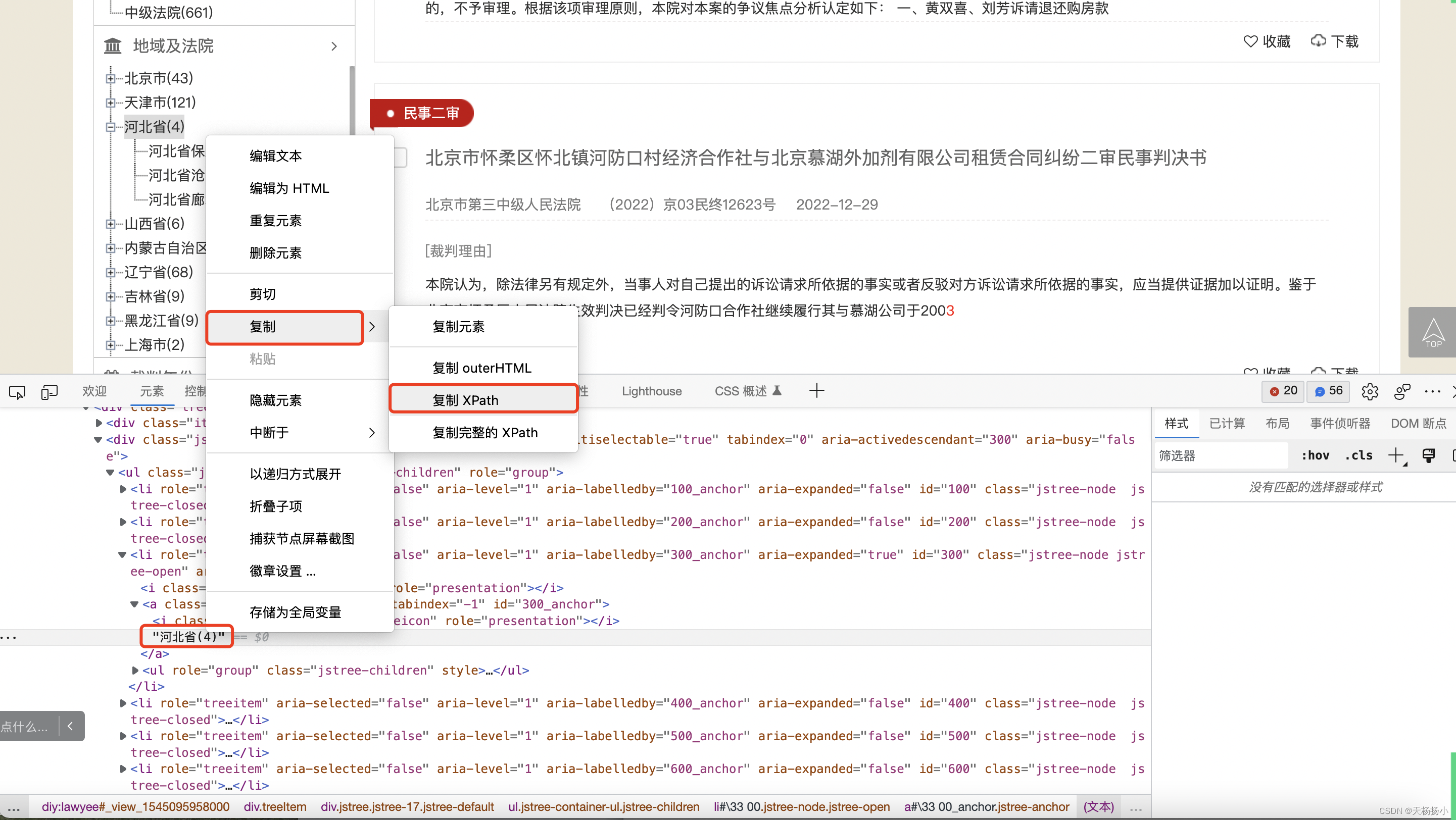
首先,按F12键打开开发者工具,分析省级数据的xpath位置,右键检查“河北省(4)”,复制“河北省(4)”的xpath路径://*[@id="300_anchor"]/text(),操作如下图:
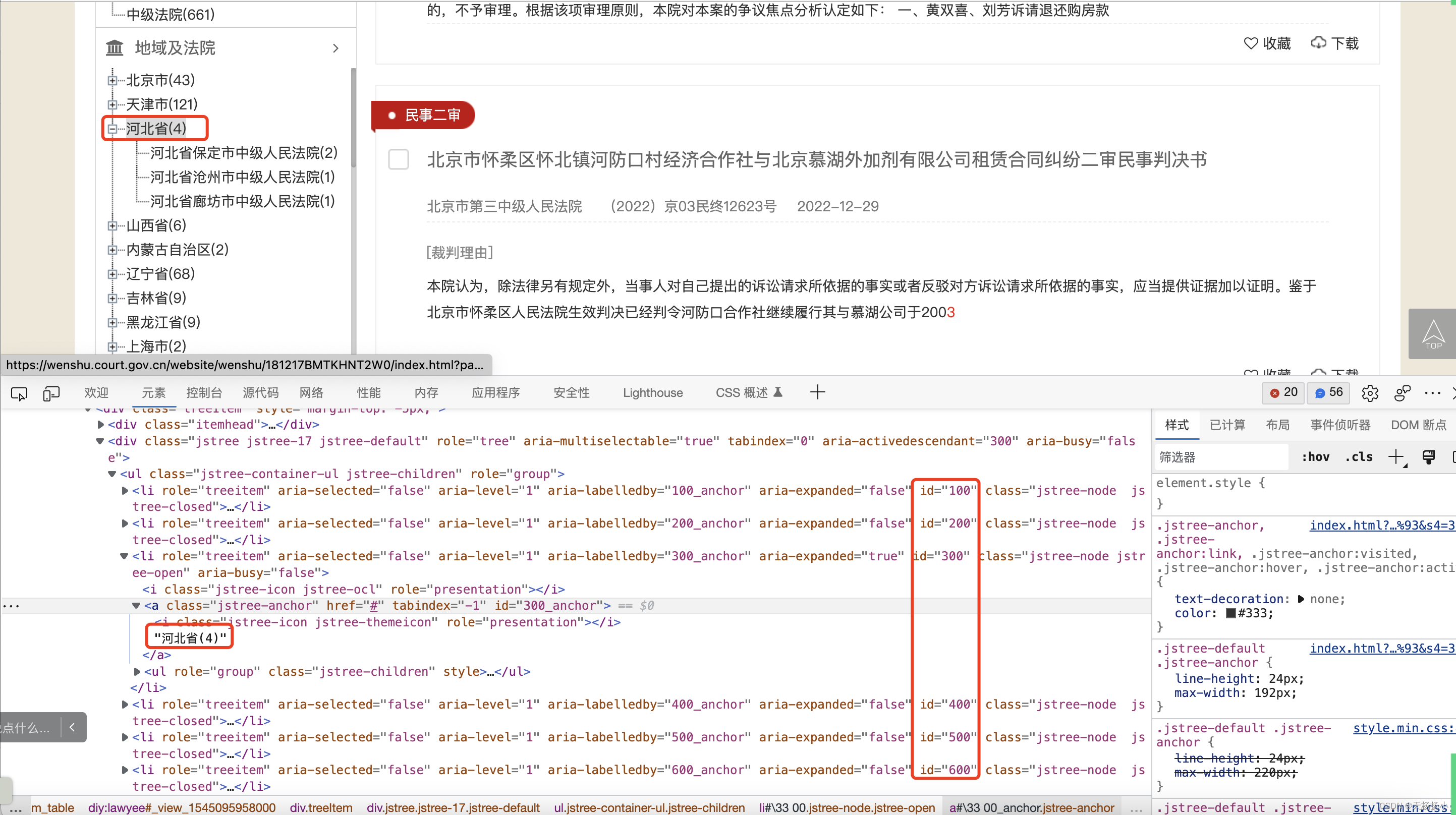
通过对其他省份的xpath路径对比发现,其关键在于id的不同,id的规律如下图所示:
因此自建列表,如下:
list0 = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'X']
接着,我们在断网状态下,点击图中左侧+字符号,发现无法展开地级市数据,说明该网页市级数据是动态加载的,需要展开后才能进行xpath定位,因此复制“河北省(4)”的+字符号的xpath路径://*[@id="300"]/i,发现同样可用id定位。
然后,复制“河北省保定市中级人民法院(2)”的xpath完整路径:/html/body/div/div[4]/div[1]/diy:lawyee[4]/div/div[2]/ul/li[3]/ul/li[1]/a/text(),操作如下图: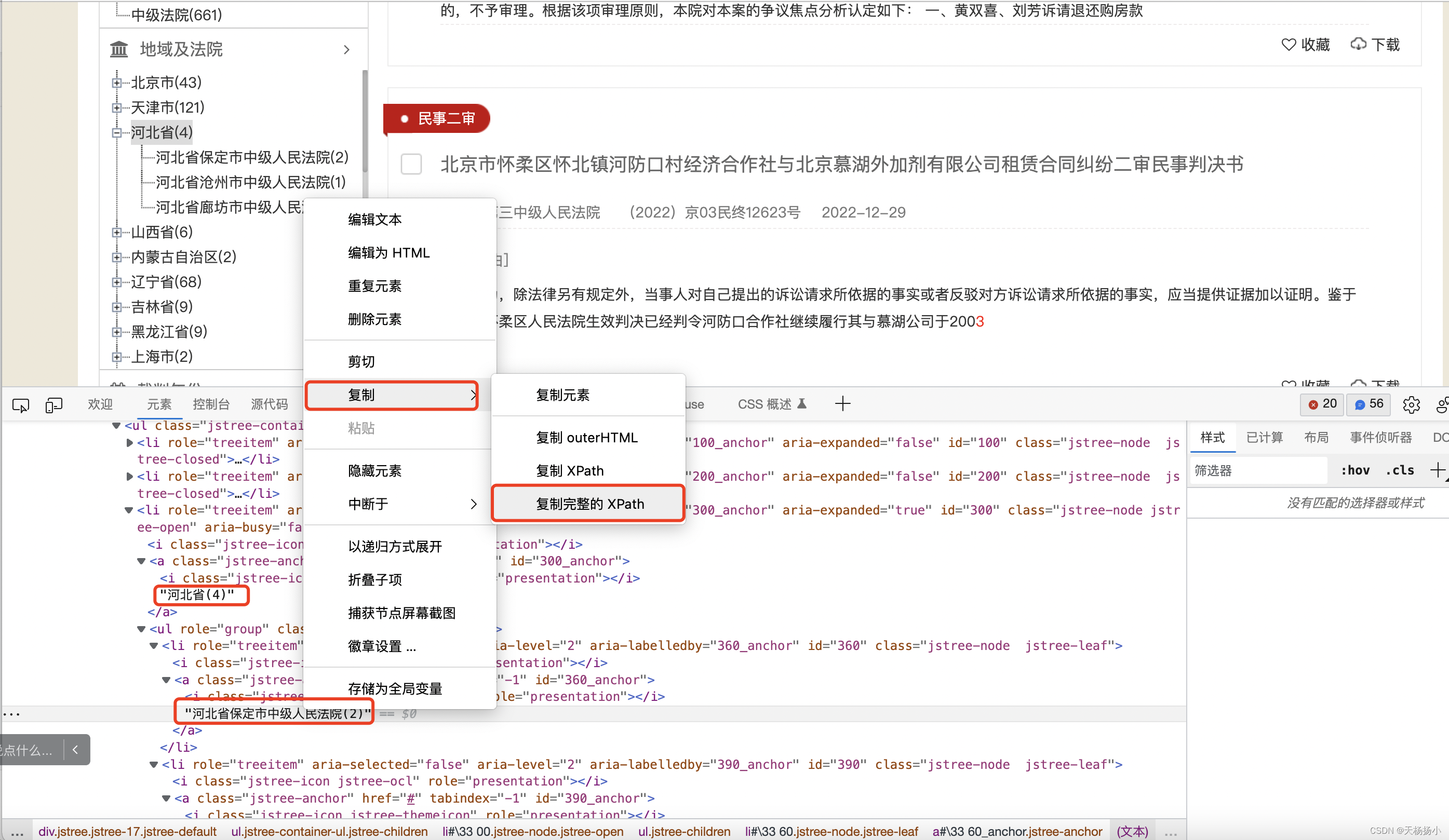
其中,
1、经反复调试发现:/html/body/div/div[4]/div[1]/diy:lawyee[4]/div/div[2]/ul/li[3]/ul/li[1]/a/text() 中的 diy:lawyee[4]要删掉,否则无法定位,原因不明;
2、经对比路径发现:/html/body/div/div[4]/div[1]/diy:lawyee[4]/div/div[2]/ul/li[3]/ul/li[1]/a/text() 中的第一个li表示第几个省份,第二个li表示该省的第几个地级市中级人民法院。
完整代码如下:
from selenium import webdriver
import time
from selenium.webdriver.edge.options import Options
import pandas as pd
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Edge(executable_path='msedgedriver',options=options)
list0 = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'X']
list1 = []
m = 0
for i in list0:
try:
province = browser.find_element_by_xpath('//*[@id="{}00_anchor"]'.format(i)).text
except:
continue
browser.find_element_by_xpath('//*[@id="{}00"]/i'.format(i)).click()
time.sleep(3)
m +=1
n = 0
while(1):
n+=1
try:
city = browser.find_element_by_xpath('/html/body/div/div[4]/div[1]//div/div[2]/ul/li[{}]/ul/li[{}]/a'.format(m, n)).text
print([province,city])
list1.append([province,city])
except:
break
browser.find_element_by_xpath('//*[@id="{}00"]/i'.format(i)).click()
time.sleep(1)
print(list1)
df = pd.DataFrame(list1)
df.to_excel('2022年中级法院.xlsx',index = False)
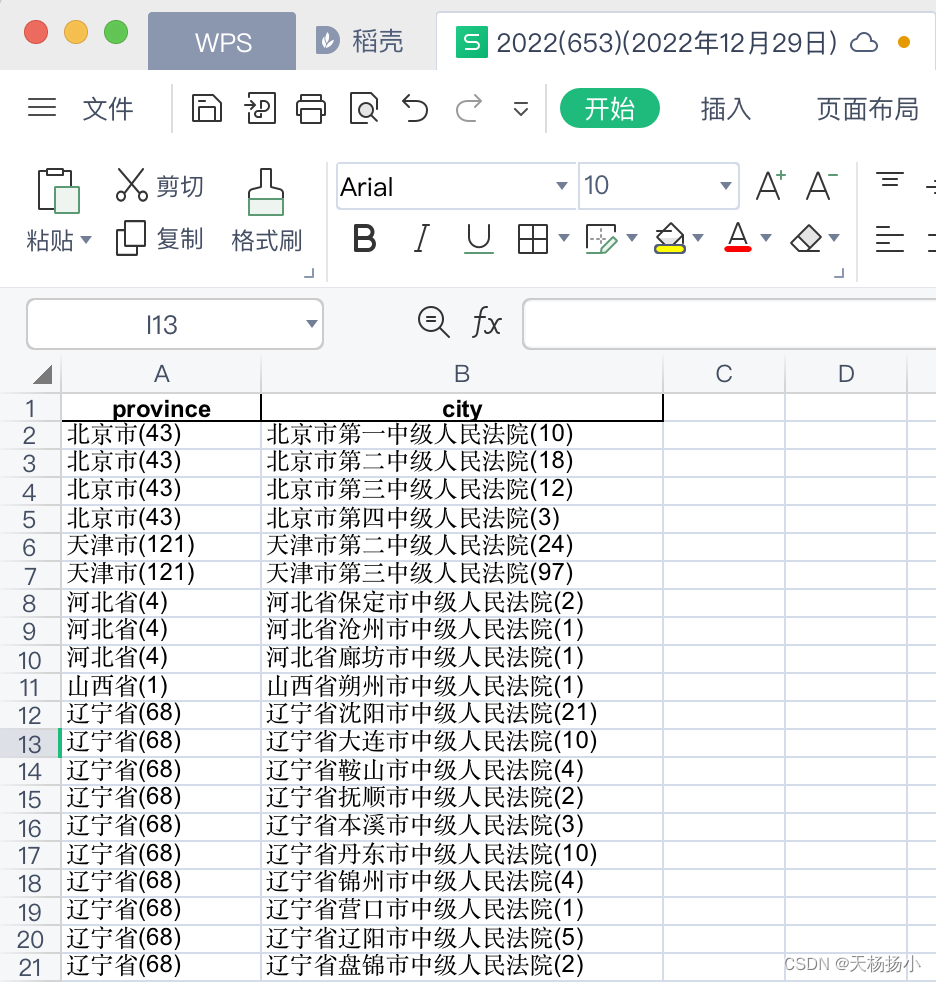
运行上述代码即可得到2022年的目标数据,重新手动设定网页裁判年份和代码中的保存文件名,再运行即可得到其他年份的目标数据。数据截图如下:
版权归原作者 天杨扬小 所有, 如有侵权,请联系我们删除。