
目录
一、系统高可用(High Availability)
(1) 啥是 “高可用” ?
🍀 通俗一点说,高可用的意思是:在高并发的情况下,系统仍然是可用的
🍀 高可用的目的:保障业务的连续性(实现在用户眼里,业务永远是正常对外提供服务的)
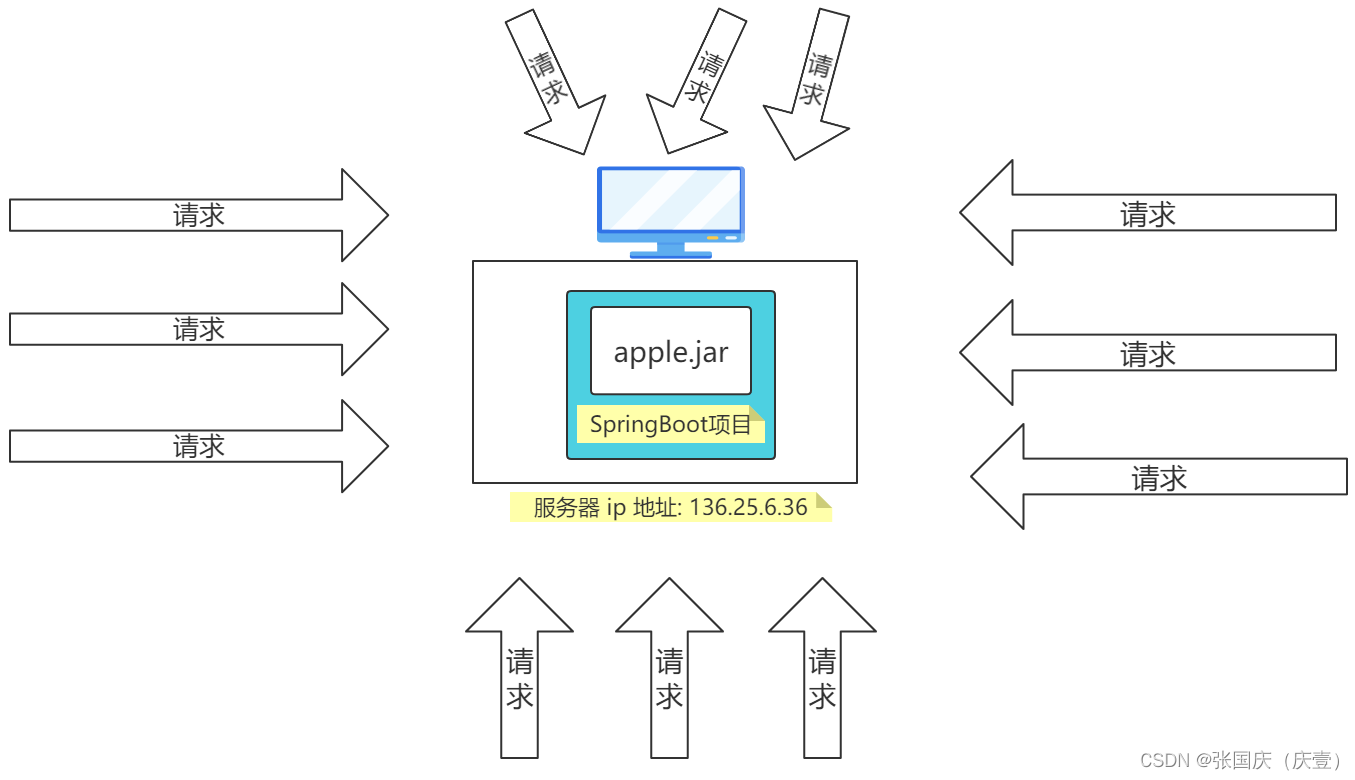
🍀 🍬 【上图】一个 SpringBoot 项目(apple.jar)被部署到服务器上运行,可向其发送网络请求对数据库执行增删改查操作
🍀 🍬 随着请求数量逐渐增多,服务器宕机(死机、挂掉)的可能性也越来越高
🍀 🍬 若服务器宕机会导致服务器上的程序无法运行、会导致服务器上的项目无法启动,则该服务器上的项目不是高可用的项目,很容易产生单点故障
🍀 🍬 单点故障:服务器与项目共生(服务器生,项目活;服务器挂,项目死)
🍀 高可用希望实现两个目标🍬:
① 系统的健壮性,不允许出现单点故障
② 提高系统的处理能力,保证系统的运行效率
(2) 集群是啥意思?
服务器就是计算机🖥️,计算机🖥️就是服务器。
❓ 如何实现高可用( 在高并发的情况下,系统仍然可用 )❓
🤔 思想上:可以把项目部署在多台服务器上( 某台服务器挂了,可以有其他服务器顶上 )
🍀 集群(cluster):一组 相互独立的、通过高速网络互联的计算机🖥️的集合
- 多台计算机🖥️构成一个组( 一个集群 ),这些计算机💻被一种 单一系统的模式 加以管理
✏️单一系统的模式:虽然是多个计算机的集合,但管理和使用的时候与操纵一台计算机无异( 感觉就像是一个单一的系统,而不是多个计算机的集合 )
- 集群模式:多台计算机的组合方式
📚 集群模式有三种:
✏️① 主备模式
✏️② 主从模式
✏️③ 高可用模式
① 主备模式
🖊️ 多台服务器的结合构成集群, 其中有一台是主服务器🖥️
🖊️ 正常情况下,只有主服务器🖥️提供服务(主服务器处于 active 状态)
🖊️ 除主服务器之外的都是备用服务器【备用服务器💻平时不提供服务,处于 standby( 待命 )状态】
🖊️ 若主服务器💻宕机,挑选众多备用服务器🖥️中的一台作为新的主服务器💻,继续提供服务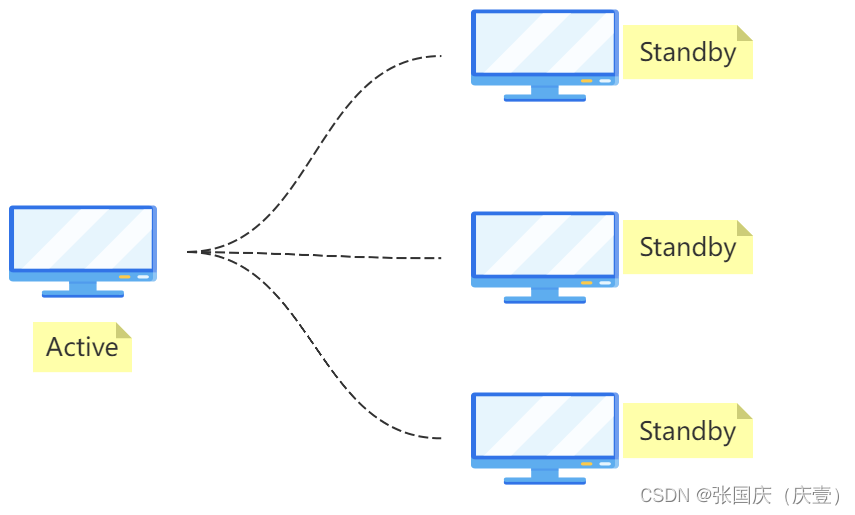
② 主从模式
- ✏️ 多台服务器构成集群,每台服务器都提供服务( 只是不同的服务器提供的功能不同 )
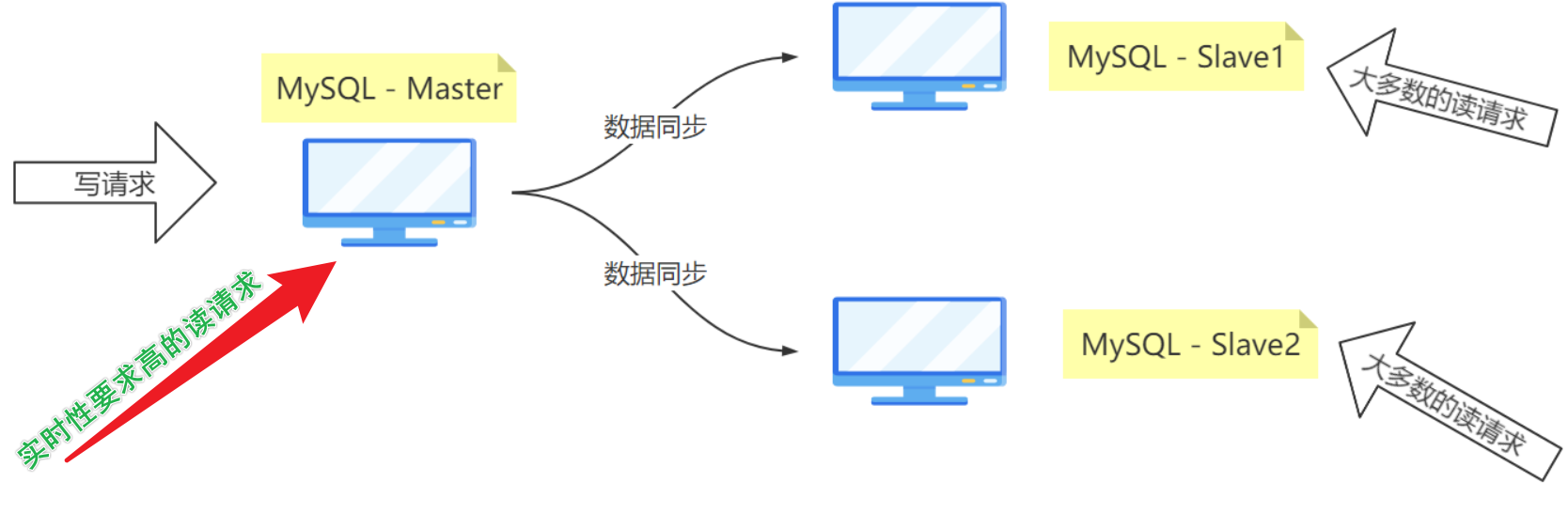
- ✏️ 【上图】① 主服务器接收写请求和实时性要求高的读请求;② 从服务器接收大多数的读请求;③ 减少服务器宕机的可能
③ 高可用模式
🍀 Queries-per-second:单个进程每秒请求服务器的成功次数( 每秒查询率 )
- ✏️ 多台服务器的组合构成集群,每台服务器的角色和功能都一样
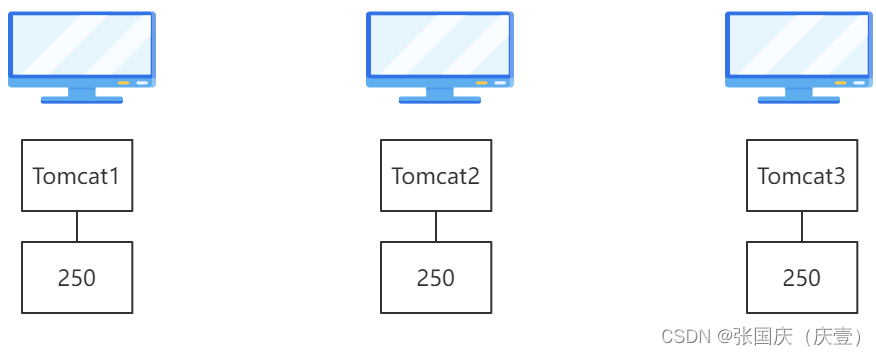
✏️ 【上图】若一台服务器的 Tomcat 每秒支持 250 个并发请求,则三台服务器的集合构成的集群服务器每秒可支持750个并发请求
④ 总结
📝 主备集群:避免单点故障
📝 主从集群:避免单点故障;提高并发度和吞吐量
📝 高可用集群:避免单点故障;提高并发度和吞吐量
(3) 分布式(Distribution)
- 📝 分布式是一种系统部署方式
① 单机部署
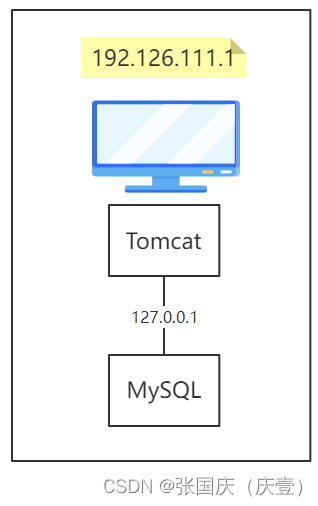
📝【上图】部署应用的方式是单机部署
- ✏️ 应用服务( Tomcat )和数据库服务( MySQL )部署在同一台服务器上,这种部署方式叫做单机部署
- ✏️ 好处:Tomcat 和 MySQL 沟通的网络开销很小
- ✏️ 坏处:Tomcat 和 MySQL 共享服务器的内存空间
② 分布式部署
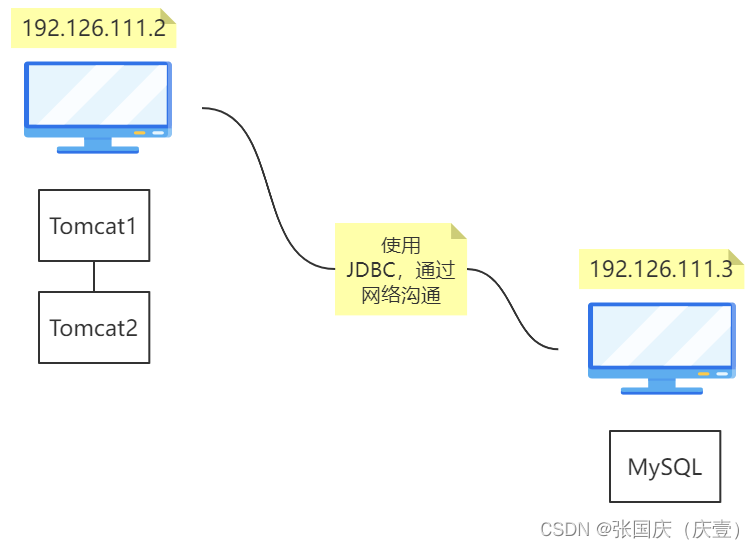
📝【上图】部署应用的方式是分布式部署
✏️ 【上图】应用服务( Tomcat )部署在 192.126.111.2 服务器;数据库服务(MySQL)部署在 192.126.111.3 服务器【Tomcat 服务和 MySQL 服务之间通过网络沟通】
- ✏️ 缺点:两个服务器之间通过网络沟通(存在网络开销)
- ✏️ 优点:Tomcat 服务和 MySQL 服务独享自己所在服务器的内存空间
(4) 微服务
- 📝 微服务是系统的一种架构设计方式
- 📝 微服务一定是分布式
- 📝 但分布式不一定是微服务
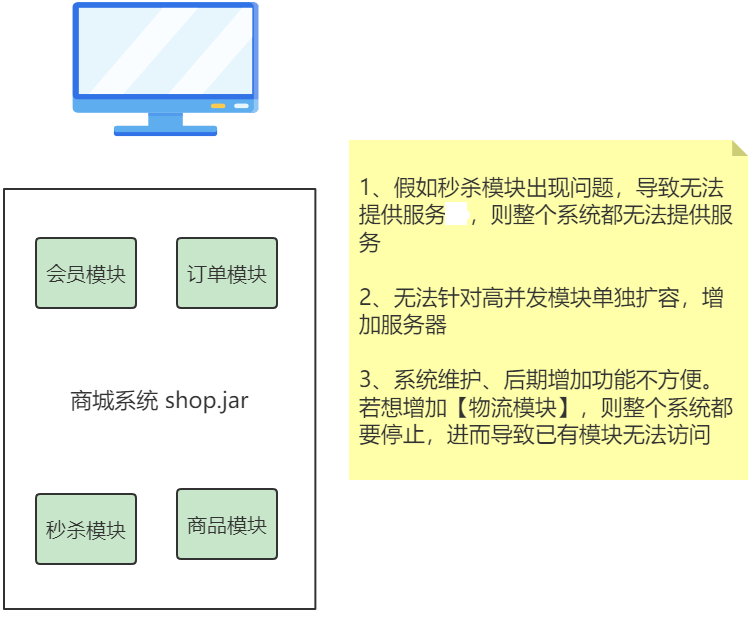
✏️ 上图把一个应用全部的功能置于同一个项目、同一个应用、同一个 jar 包中,这是单体应用
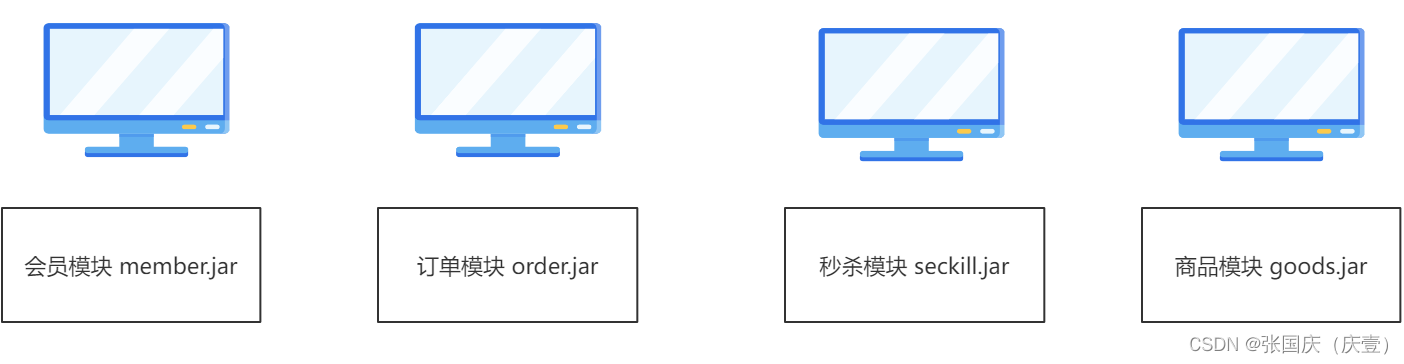
✏️ 上图根据模块进行划分,每个模块部署在不同的服务器中。服务之间通过网络请求进行访问和沟通,这是微服务架构
(5) 分布式和微服务的对比
✒️① 单体架构所有模块全都耦合在同一个项目中(代码量大,维护困难)
- 微服务每个模块就相当于一个单独的项目(代码量明显减少,遇到问题也好针对解决)
✒️② 单体架构的所有模块共用一个数据库,存储方式比较单一
- 微服务架构各个模块可以使用不同的存储方式(如有的用 redis,有的用 MySQL),单个模块( 独立的模块 )对应自己独立的数据库
✒️③ 单体架构所有模块开发所使用的技术一样
- 微服务每个模块可以使用不同的开发技术,开发模式更加灵活
二、分布式应用
🀄 大数据时代,将会面临三个重大问题:
① 海量数据如何存储 ❓
② 如何对海量数据进行运算 ❓
③ 高并发请求如何处理 ❓
🀄 这些问题都可通过【分布式】进行解决
📝 ① 分布式存储解决海量数据的存储问题
📝 ② 分布式计算处理海量数据的运算
📝 ③ 分布式系统处理高并发的请求
(1) 分布式存储

🍀 使用 MySQL 数据库可存储数据,但其存储的数据是有限的。假如 MySQL 可存储的数据是 1T,则固定只能存储 1T 的数据,若数据容量超过 1T 就无法存储了
HBase:Hadoop Database 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。利用 HBase 技术可在廉价 PC Server 上搭建起大规模的结构化的存储集群【百度百科】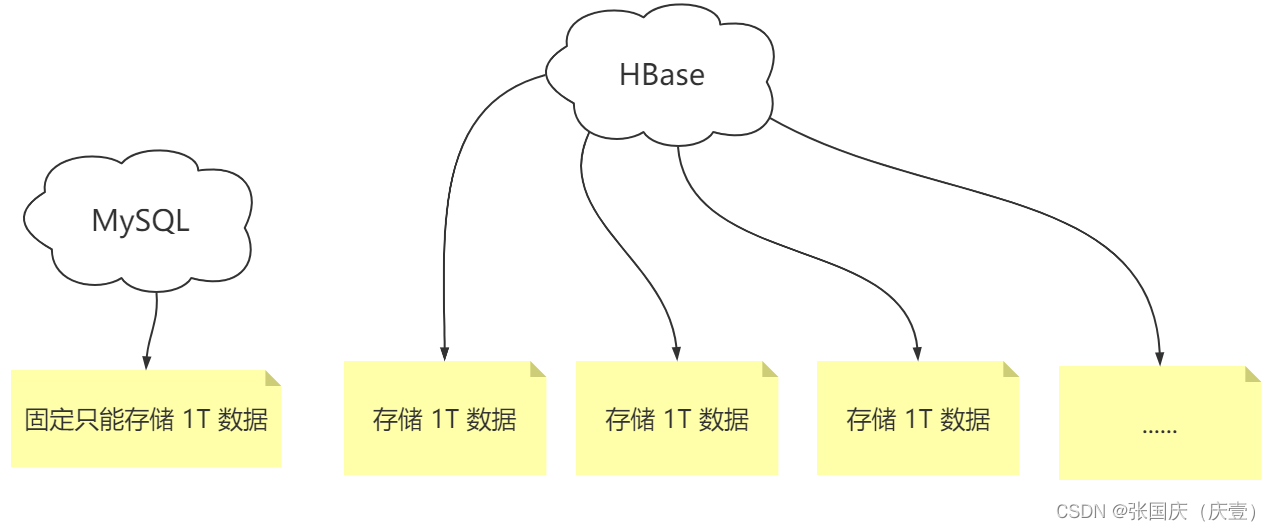
(2) 分布式计算
🎄 分布式计算:分而算之,把一个大的计算任务分解为多个小的计算任务进行计算操作
🎄 通过汇总小的计算任务的计算结果,进而得到大的计算任务的结果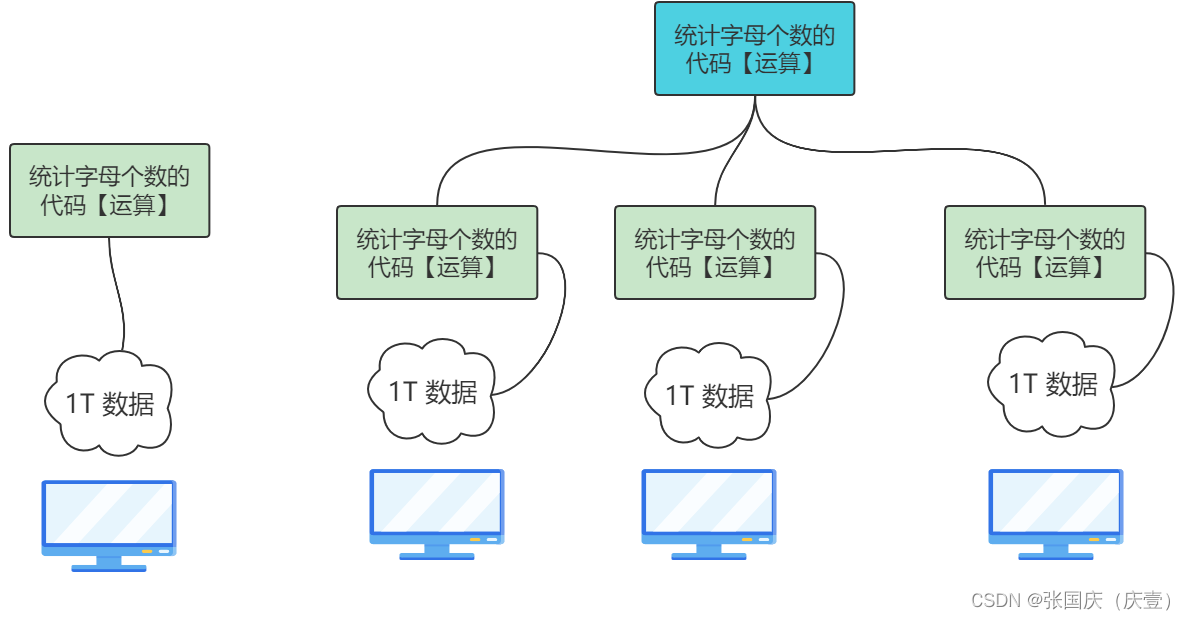
🍬【上图】有一个 计算海量数据中字母个数 的任务。不同的数据被存放在不同的服务器中,计算字母个数的代码放在 A 服务器。把每个服务器的数据都移动到 A 服务器,再进行计算(非常耗费时间、性能低)
🍬 最好的做法是: 把计算字母个数的代码移动到不同的服务器,在数据所在的服务器中统计完字母个数后,再把计算结果进行汇总【不耗时:移动运算代码所花费的时间肯定低于移动数据所花费的时间⏰】
🍬 一份 计算字母个数的代码 可能最多100M,而不同服务器上的一份数据肯定是远大于100M的,移动代码(运算)比移动数据划算
分布式计算强调:移动运算,而不是移动数据
(3) 分布式系统
🎄 把应用服务(Tomcat)和数据库服务(MySQL)部署在不同的服务器上,Tomcat 和 MySQL 之间通过网络进行沟通
三、分布式协调服务(以 ZooKeeper 为例)
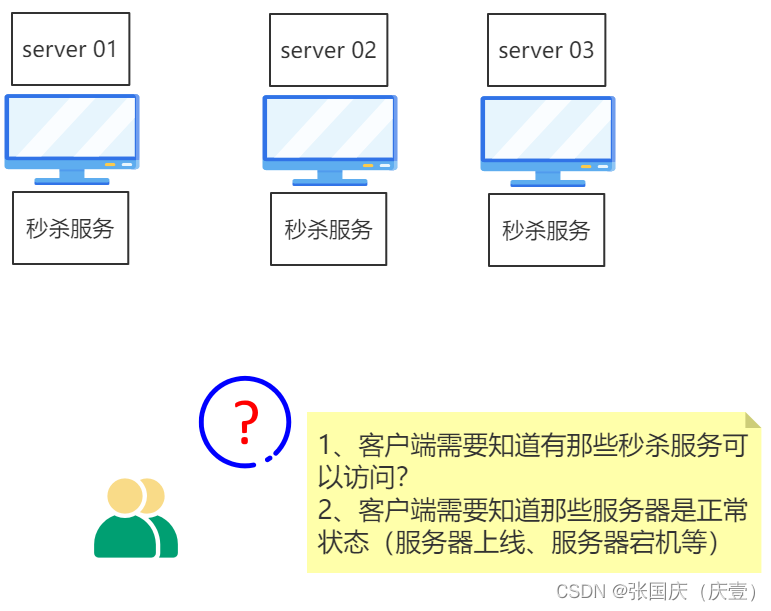
🍀 【上图】客户端若想访问秒杀服务,理论上, 需要知道有哪些秒杀服务器可以访问 ❓
🍀 理论上, 需要知道秒杀服务的动态变化(哪些服务器已宕机,哪些服务器上线了)
🍀 但实际上,客户端并没有必要知道服务器的状态
🍀 客户端只需要发送请求就可以了,实际上是那个服务器处理请求❓客户端没有必要知道
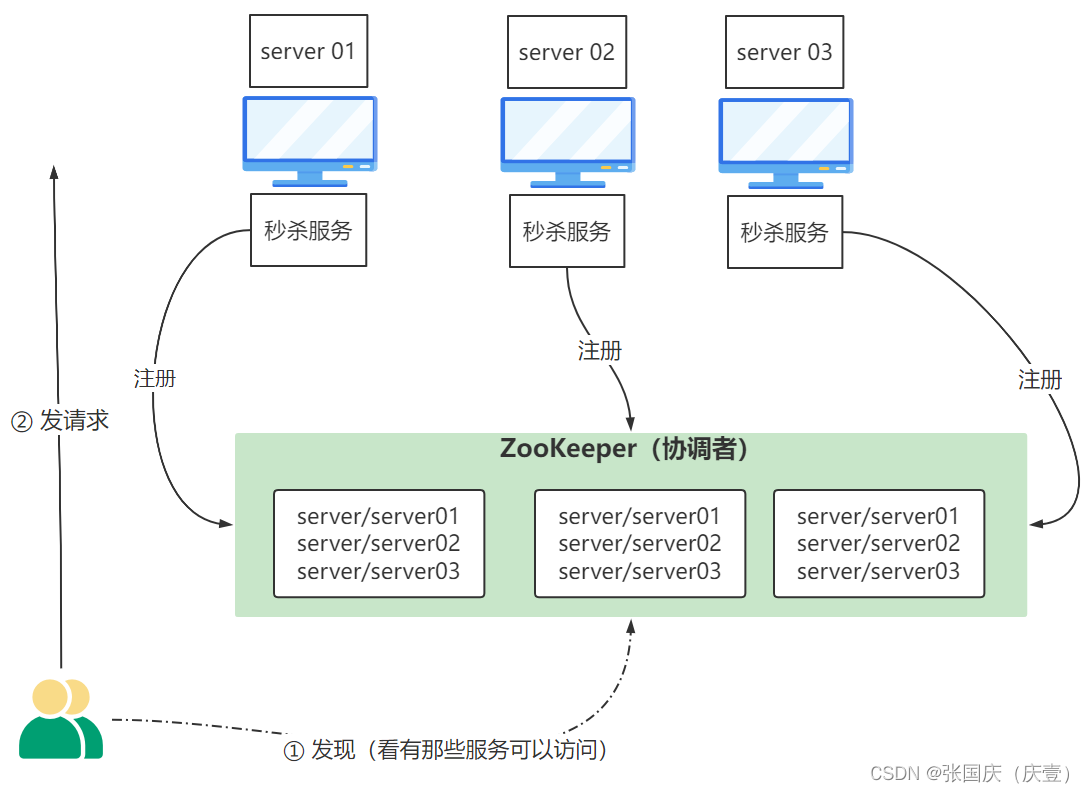
🎄 ZooKeeper 在分布式系统中充当协调者的角色,帮助客户端和分布式服务之间进行沟通,保证系统的正常运行。
版权归原作者 JavaLearnerZGQ 所有, 如有侵权,请联系我们删除。