
一、数据为什么会乱序?
在了解为什么会乱序之前我们先来看一下在Flink中的时间语序。
1.1 Flink Time 时间语义
- Event Time:事件产生的时间,它通常由事件中的时间戳描述。
- Ingestion Time:事件进入Flink的时间。
- Processing Time:事件被处理时当前系统的时间。
这三种时间的对应关系如下图所示:

1.2 数据乱序的产生
在使用EventTime处理Stream数据的时候就会遇到数据乱序的问题。流处理从Event(事件)产生,流经Source,再到Operator,这中间需要一定的时间。虽然大部分情况下,传输到Operator的数据都是按照Event Time顺序来的,但是也不排除因为网络延迟等原因导致乱序的产生。特别是使用kafka的时候,多个分区间无法保证数据的有序性。
那么Flink针对乱序数据是如何处理的呢?
二、Flink是如何处理乱序数据的?
故事时间到~
学校准备春游,春游是大家小时候最爱的活动了。
小明班计划的发车时间是09:00~09:10。
但是老师怕有同学迟到,赶不上一年一次的春游,所以让司机大叔把他自己的表的时间调慢了五分钟。(这样实际发车时间是09:05~09:15)
果然早上的时候学校附近有条路突然开始维修,导致部分同学在规定时间内无法到达,不过还好老师有先见之明,让司机大叔将表调慢了五分钟,九点十五前陆陆续续到了一部分。
不过还是有小部分同学没能在五分钟内赶到,也不能一直等着,所以老师便和司机大叔说先走但是前三分钟开慢点,让那些小部分已经快赶到的同学打车追过来,这样就也能上车了。
但总有一些家贼远,或者路上堵住了等各种问题,导致又过了三分钟还是没追上,可是也不能不让人家参加春游,毕竟一年一次,所以学校安排了备用车,送这些晚到很久的同学。最后,同学们都愉快的玩耍了起来。
总结:
故事中的班车:同一个班级上同一辆班车,对应的就是流式计算的窗口。
2.1 Flink为什么需要窗口计算?
我们知道在Flink的世界观中一切都是由流组成的,离线的数据是有界流,实时的数据是无界流。我们需要的是通过计算数据汇总产生结果。就算是有界流也不可能一直等数据,所以无论是有界流还是无界流就都需要规划一个范围来进行计算,这就是所谓的窗口。
窗口就是将无界流或者大的有界流切割成小的有界流的一种方式,它会将数据分发到有限大小的桶中进行分析。
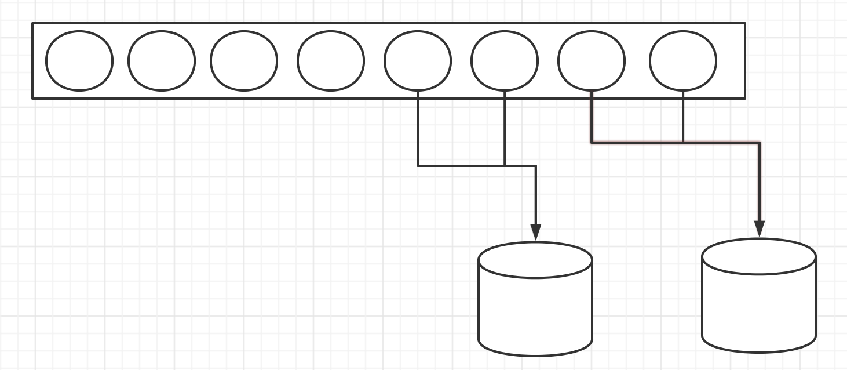
2.2 Flink中的窗口
- 时间窗口(Time Window)
- 滚动时间窗口
- 滑动时间窗口
- 会话窗口
- 计数窗口 (Count Window)
- 滚动计数窗口
- 滑动计数窗口
2.2.1 滚动窗口

- 将数据依据固定的窗口长度进行切分;
- 时间对齐,窗口长度固定,没有重叠。
2.2.2 滑动窗口
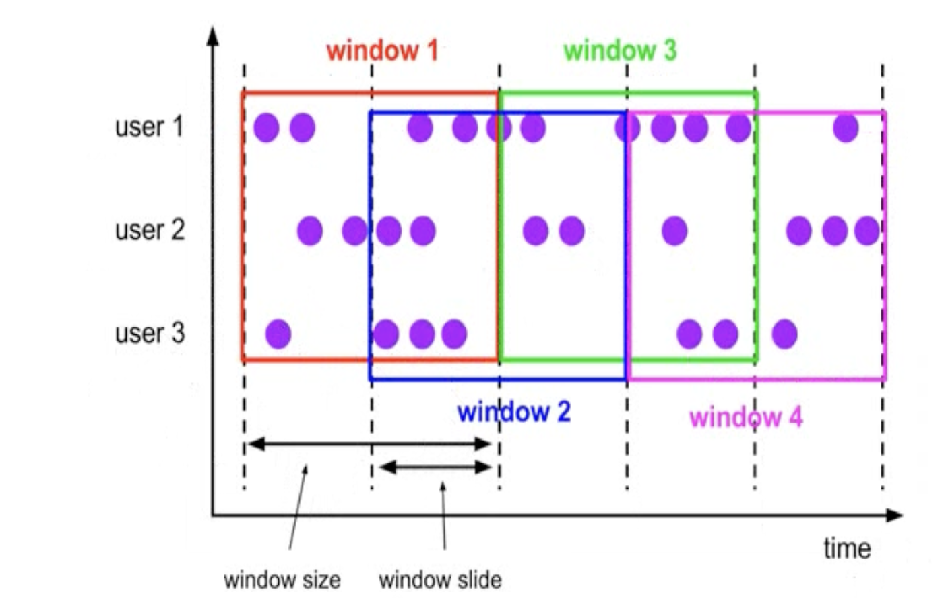
- 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成;
- 窗口长度固定,可以有间隔。
2.2.3 会话窗口

- 由一系列事件组合一个特定时间长度的timeout间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口;
- 时间无对齐。
2.3 如何进行窗口计算?
进行窗口计算,我们至少需要知道两个条件:
- 数据的产生时间即 EventTime
- 在窗口内的数据,何时触发计算?
第一点很好解决,只需要在数据产生的时候将时间戳带过来就可以了。那么第二点,Flink是如何判断何时触发窗口计算的呢?并且第一个窗口是什么时候生成的呢?
在回答这个问题之前,让我们先来看一下以下三点:
2.3.1 有序事件

理想情况下,数据都是严格有序的,那么这个时候流式计算引擎选定窗口时间后,是可以正确的将窗口内的数据计算出来的。然而理想很丰满,现实很骨感,现实中的数据往往都存在乱序的情况。
2.3.2 无序事件

刚刚已经知道了数据必然存在乱序的可能,因此Flink需要有一种机制能让迟到的数据放在对应的窗口中进行计算。
还记得故事中,老师让司机大叔将自己的表调慢五分钟吗?对应的就是这种机制 Watermark -- 水位线。
2.3.3 Watermark -- 水位线
特点:
- Watermark 是一个特殊的数据,本质上就是一个时间戳;
- Watermark 必须单调递增,以确保任务的事件时间时钟一直在往前推进;
- Watermark 与数据的时间戳有关。
为什么Watermark 能解决问题?
- Watermark是一种告诉Flink一个消息延迟多少的方式,它定义了从什么时候开始可以不再等待更早的数据;
- 可以把Watermarks理解为一个水位线,这个Watermarks在不断地变化。Watermark实际上作为数据流的一部分随数据流流动;
- 当Flink中的运算符接收到Watermarks时,它明白早于该时间的消息已经完全抵达计算引擎,即假设不会再有时间小于水位线的事件到达;
- 这个假设是触发窗口计算的基础,只有水位线越过窗口对应的结束时间,才会触发窗口计算操作。
下图详解了watermark的工作流程:

如何防止数据丢失?
如果说故事中司机大叔故意将表调慢五分钟,对应的Flink设置水位线是防止数据短时间内错乱是第一道保险的话,那么老师让司机大叔开车后的前三分钟开慢点让后面的同学可以坐出租车追上,对应的就是Flink可以设置延迟时间,在延迟时间内(也就是数据的watermark时间)乱序数据可以再次进入对应的窗口进行计算便是Flink防止数据乱序的第二道保险。


** 如果还有更晚到的数据呢?**
对于实时数据,我们不好肯定可容错的水位线以及延迟时间可以防止所有晚到的数据进入窗口计算。
从性能,从实时性考虑我们都不能将水位线或者延迟时间拉得太长。
水位线与延迟时间的设置只能是开发人员基于业务,数据量,乱序的范围等综合考虑,是在不过多影响性能,实时性的前提下设计的。
那么更晚到的数据怎么办呢?
就如同刚刚的故事中,学校让更晚到的同学坐另一辆车去目的地一样,Flink对于更晚到的乱序数据的处理就是,将他们统一放入侧输出流中让开发人员自行处理。

三、总结
- 通过 assignTimestampsAndWatermarks 来设置水位线时间,让短时间内大量迟到的数据可以进入对应的窗口,当水位线时间漫过窗口时间,开始触发窗口操作。
- 通过 allowedLateness 来设置延迟时间,让在延迟时间内迟到的数据可以进入窗口计算。
- 通过 sideOutputLateData 来设置侧输出流进行兜底,让更晚到的数据进入侧输出流中。
Flink最终就是用这一套组合拳来处理乱序数据的。
Flink不同操作是可以分区的,那么在分区时watermark是如何传递的呢?大家可以结合实践好好思考下~
本期内容就到这里了,如果喜欢就点个关注吧,微信公众号搜索“数 新 网 络 科 技 号”可查看更多精彩内容~
版权归原作者 数新网络 所有, 如有侵权,请联系我们删除。