
DataBend介绍

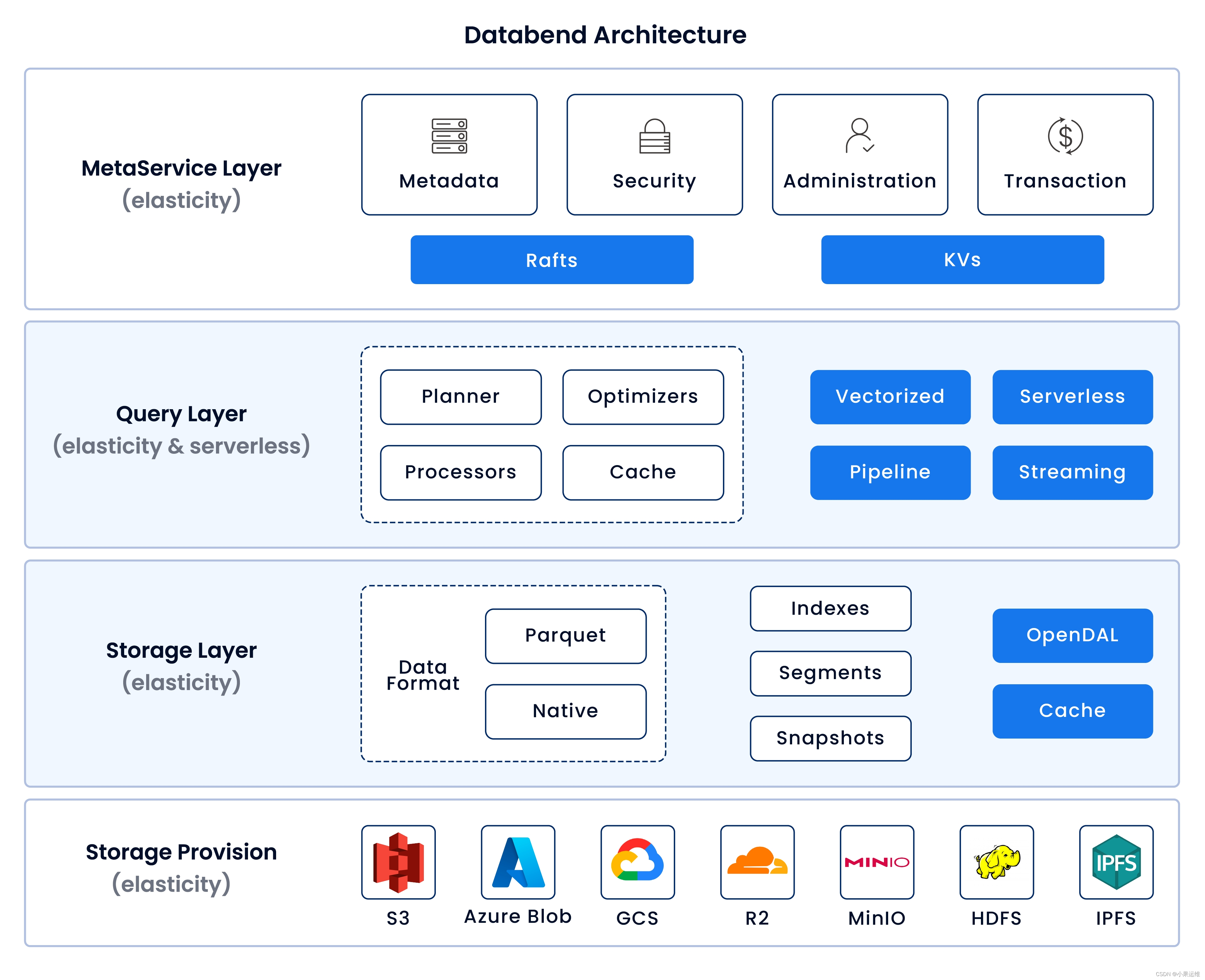
Databend 是一个开源、云原生且实时分析型的现代数据仓库,旨在提供高效的数据存储和处理能力。它采用 Rust 语言开发,并支持 Apache Arrow 格式以实现高性能列式存储与查询处理。
主要特点:
- 云原生设计:Databend 构建在 Kubernetes 之上,具备弹性伸缩、水平扩展的能力,可轻松部署在公有云或私有云环境中。
- SQL 支持:Databend 具备完善的 SQL 查询功能,兼容 MySQL 协议,使得用户可以利用熟悉的 SQL 语法进行数据查询和处理。
- 性能优化:通过矢量化查询执行引擎和列式存储技术,Databend 可实现对大规模数据集的快速读取和分析。
- 对象存储集成:Databend 能够将数据存储在各种对象存储服务上,如 AWS S3、Azure Blob 存储、Google Cloud Storage 等,实现成本低廉的大规模存储。
- 实时分析:Databend 支持实时数据摄取和即时查询响应,适合于 BI 分析、日志分析、实时报表等应用场景。
- 社区驱动:作为开源项目,Databend 由活跃的开发者社区共同维护和贡献,持续迭代更新,增加新功能并改进现有特性。
使用场景示例:
- 数据分析师可以使用 Databend 进行复杂的数据查询和数据分析。
- 开发者可以构建实时数据管道,将流式数据写入 Databend 并立即进行查询和分析。
- 数据科学家可以结合 Databend 和其他工具(如 Python 或 R)进行机器学习模型训练前的数据预处理工作。
部署与使用步骤:
- 下载或克隆 Databend 的源代码或二进制包。
- 根据官方文档配置所需的环境变量和服务参数,例如数据库 URL、连接凭据以及对象存储的访问信息。
- 启动 Databend 服务,通常可以通过命令行工具完成启动、停止和管理操作。
- 使用 MySQL 客户端或支持 MySQL 协议的应用程序连接到 Databend 数据库,并开始创建表、插入数据以及执行 SQL 查询。
Databend Cloud - Open Source Cloud Data Warehouse Alternative to Snowflake | Databend Cloud
Databend的安装
以下是一个简化的 Databend 安装和配置步骤,具体细节可能根据实际情况有所调整,请参照最新的官方文档进行操作。
1. 环境准备
确保你的机器上已安装 Rust 工具链(Rustup)以及 Docker。如果尚未安装,请参考以下链接进行安装:
- Rustup: rustup.rs - The Rust toolchain installer
- Docker: Install Docker Engine | Docker Docs
2. 安装 Databend
使用 Rust 工具链编译并安装 Databend:
# 克隆 Databend 仓库
git clone https://github.com/datafuselabs/databend.git
cd databend
# 使用 nightly 版本的 Rust 编译器构建 Databend
rustup default nightly
cargo build --release
# 创建 Databend 的数据存储目录(例如 /var/lib/databend)
sudo mkdir -p /var/lib/databend
sudo chown $(id -u):$(id -g) /var/lib/databend
3. 配置与运行 Databend
Databend 提供了单机模式和分布式模式的部署方式。这里我们先介绍单机模式下的配置与启动:
# 运行一个单节点的 Databend 服务
./target/release/databend-server --config-path=config.toml.example
# 或者如果你想在后台运行(daemon mode),可以加上 `--log-file` 参数指定日志文件
./target/release/databend-server --config-path=config.toml.example --log-file=/var/log/databend/server.log &
上述命令中,
config.toml.example
是一个示例配置文件,你需要根据实际需求修改它。例如设置监听地址、端口、数据目录等信息。
4. 配置数据库连接
默认情况下,Databend 启动后会在本地监听
3307
端口作为 SQL 查询接口。你可以通过任何支持 MySQL 协议的客户端连接到 Databend。
mysql -h localhost -P 3307 -u root
5. 配置持久化存储 (可选)
如果你希望将数据持久化存储在某个位置(比如 S3 或 MinIO),则需要在配置文件中添加对应的存储后端,并提供相应的访问凭证。
6. 分布式部署
对于生产环境或大规模测试,你可能需要部署多节点集群。请参考 Databend 的 Kubernetes Helm Chart 或 Docker Compose 文件来搭建分布式集群。
注意事项:
- 在正式环境中,请确保正确配置安全性相关的选项,如密码加密、访问控制等。
- 对于持久化存储支持,Databend 可以配置为使用各种对象存储服务,包括但不限于 AWS S3、MinIO、Google Cloud Storage 等。
请查阅最新版的 Databend 文档获取详细指导和最佳实践:Databend - The Future of Cloud Data Analytics. | Databend
基于Docker安装和配置使用
atabend 提供了 Docker 镜像,使得用户可以通过 Docker 容器快速部署和运行 Databend 数据库。以下是一个使用 Docker 安装 Databend 的详细配置步骤:
1. 拉取 Databend Docker 镜像
首先,确保已安装 Docker,并在终端中执行以下命令以拉取最新的 Databend Docker 镜像。请注意,实际镜像名可能会随着版本更新而变化,请参考官方文档获取最新版本。
docker pull databend-docker:databend-query # 查询引擎(databend-query)
docker pull databend-docker:databend-meta # 元数据服务(databend-meta)
2. 创建用于持久化存储的目录(可选)
为了在容器重启后仍能保留数据,可以创建本地主机上的目录用于持久化存储元数据和服务数据:
mkdir -p /path/to/databend/meta-data
mkdir -p /path/to/databend/query-data
3. 运行 Databend Meta 服务
docker run -d --name databend-meta \
-v /path/to/databend/meta-data:/var/lib/databend-meta \
-e "DATABEND_QUERY_HTTP_PORT=8001" \
databend-docker:databend-meta
这里,
-v
参数将主机上的目录映射到容器内的
/var/lib/databend-meta
目录。
4. 运行 Databend Query 引擎
docker run -d --name databend-query \
--link databend-meta:databend-meta \
-v /path/to/databend/query-data:/var/lib/databend-query \
-p 8080:8080 \
databend-docker:databend-query
这里的
--link
参数用于连接查询引擎与元数据服务容器,使查询引擎能够访问元数据服务。同时
-p
参数用于映射查询引擎的 HTTP 端口到宿主机上。
5. 配置环境变量(可选)
根据需要,可以设置其他环境变量来配置数据库的行为,例如日志级别、监听地址等。请查阅 Databend 文档了解可用的环境变量列表。
6. 访问和测试 Databend
启动容器后,可以通过如下方式访问 Databend 查询引擎:
- HTTP API: 在浏览器或 Postman 中访问
http://localhost:8080/(如果映射的是本机端口)。 - SQL Client:通过 MySQL 客户端工具如 MySQL Workbench 或者命令行工具连接至 Databend,端口通常为
3307,用户名和密码可能需要查看具体文档或环境变量配置。
请始终参照最新的官方文档进行操作,因为具体的参数和配置可能会随时间发生变化。以上示例是基于假设的默认配置给出的。
Centos 9下安装和使用
在CentOS 9系统上安装Databend的大致步骤(以最新的官方文档为准):
1. 确保环境准备就绪
- CentOS 9系统已经安装了必要的开发工具和依赖库。
- Rust编程语言环境已安装。
# 更新系统并安装必要软件包
sudo dnf update -y
sudo dnf install -y curl git make gcc-c++ zlib-devel openssl-devel
# 安装Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env
2. 安装Databend
- 使用Rust的Cargo来构建和安装Databend的服务器部分(metasrv和databend-query)。
# 克隆Databend源代码
git clone https://github.com/datafuselabs/databend.git
cd databend
# 构建并安装
cargo build --release --bin metasrv
cargo build --release --bin databend-query
# 创建用于存放运行时数据的目录
mkdir -p /var/lib/databend/meta /var/lib/databend/data
3. 配置与启动服务
- 配置Databend的元数据存储、日志路径等参数,并启动服务。
# 编写配置文件(这里仅提供示例配置)
cat << EOF > /etc/databend/config.toml
[meta_service]
listen = "127.0.0.1:9191"
data_dir = "/var/lib/databend/meta"
[databend_query]
http_server_address = "0.0.0.0:8000"
query_pool_size = 4
local_data_path = "/var/lib/databend/data"
EOF
# 启动metasrv服务
./target/release/metasrv --config /etc/databend/config.toml &
# 启动databend-query服务
./target/release/databend-query --config /etc/databend/config.toml &
4. 验证安装
- 在本地或通过网络连接到Databend Query API端口进行验证。
# 如果是在本地机器上安装,可以尝试执行一个简单的查询
curl -G "http://localhost:8000/v1/query" --data-urlencode 'sql=SELECT version()'
# 应该返回类似如下信息:
{"results":[{"meta":{"columns":[{"name":"version","type":5}],"rows":[["nightly"]]},"stats":{"elapsed_time":...}}]}
注意事项:
- 实际部署中,您可能需要为Databend设置持久化存储,比如挂载适当的磁盘分区或使用云存储服务。
- 生产环境中,请确保使用稳定的版本而非nightly版,并根据官方推荐的最佳实践进行配置和管理。
- Databend还支持通过Docker容器方式部署,对于生产部署而言,采用Docker Compose或者Kubernetes等方式更加便捷且易于维护。
请始终查阅最新版的Databend官方文档获取详细的安装指导:https://docs.databend.rs/
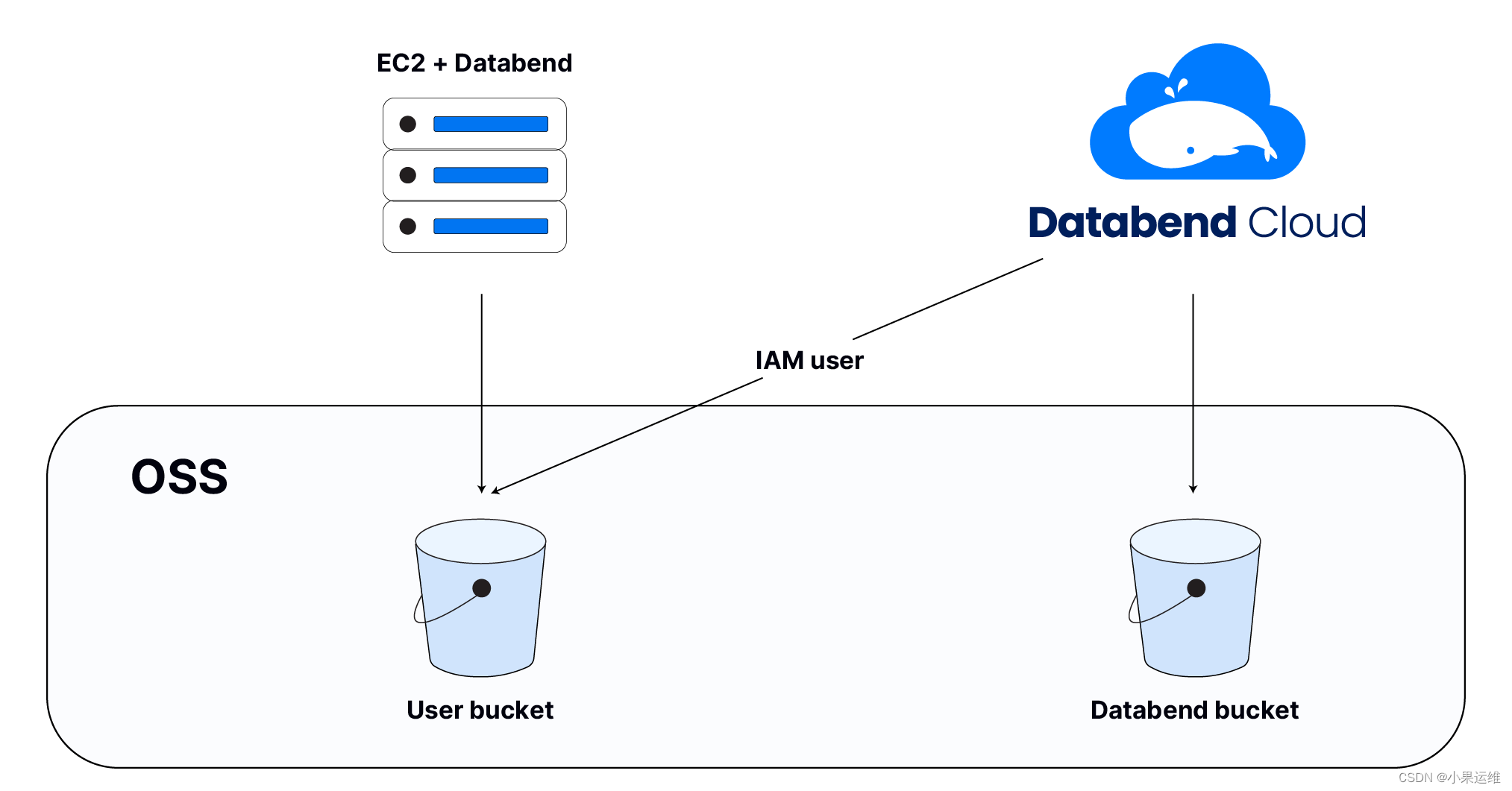
Databend、lakeFS 和 MinIO三者结合
高性能、可扩展、分布式对象存储系统MinIO的介绍、部署步骤以及代码示例-CSDN博客
Databend、lakeFS 和 MinIO 的功能介绍:
- Databend:- Databend 是一个开源的实时分析型数据仓库,它构建在 Rust 之上,并兼容 Apache Arrow 格式。- 提供了类似 Snowflake 的云原生架构,支持高并发查询和近实时的数据插入与更新。- 支持 SQL 查询语言,可以处理 PB 级别的数据并提供亚秒级延迟的交互式分析体验。- 集成了多种数据源,并且可以通过 JDBC/ODBC 连接各种 BI 工具进行数据分析。
- lakeFS:- lakeFS 是一种基于 Git-like 分支模型的对象存储管理工具,适用于 AWS S3 或其他 S3 兼容存储服务(如 MinIO)。- 它为数据湖提供了版本控制功能,允许用户对存储在对象存储中的数据集创建分支、合并、回滚等操作。- 用户可以在不同的分支上进行数据开发、测试和生产流程,增强了数据资产管理能力,简化了数据流水线的治理和审计工作。
- MinIO:- MinIO 是一款高性能、分布式的对象存储系统,完全兼容 Amazon S3 API。- 可以部署在本地或云端,用于大规模非结构化数据存储,包括大数据分析所需的原始数据、备份和归档数据等。- 提供高可用性、可扩展性和安全性,适合用作企业内部或者混合云环境下的对象存储解决方案。
三者结合使用的方式及示例:
假设您希望将 MinIO 作为底层存储,通过 lakeFS 对其上的数据进行版本管理和分支操作,并使用 Databend 对这些数据进行查询分析。以下是大致的配置步骤和使用方法:
配置步骤:
- 部署 MinIO:- 在服务器集群或单台机器上安装并启动 MinIO,确保其网络可达并已配置好适当的访问密钥和私有密钥。
- 配置 lakeFS-
lakectl init <lakefs-server-url> my-repo s3://<minio-bucket-name> - 上传数据到 lakeFS-
lakectl cp local-data.csv lakefs://my-repo/main/data.csvlakectl branch create my-repo/dev --parent mainlakectl cp local-data-dev.csv lakefs://my-repo/dev/data.csv - 配置 Databend 数据源:- 在 Databend 中设置一个 S3 数据源,指向 lakeFS 的其中一个分支(例如 main 分支),这样 Databend 就能读取该分支下的数据进行分析。- 更新 Databend 的 catalog 配置文件,添加 S3 存储连接信息,并指定 bucket 名称(这里会是 lakeFS 虚拟出来的 bucket)以及正确的 endpoint URL(lakeFS 服务器地址)。
- 在 Databend 中执行查询-
SELECT * FROM "s3://my-repo/main/data.csv" (format CSV);
示例场景:
- 数据开发阶段:- 开发团队成员在 lakeFS 上的 dev 分支上进行数据清洗、转换等操作,完成后提交更改。
- 代码审核和合并:- 通过 lakeFS 的 merge 功能将 dev 分支的更改合并到 main 分支。
- 数据验证与分析:- 数据分析师在 Databend 中选择 main 分支作为数据源,运行 SQL 查询验证数据质量和分析结果。
- 问题排查与回滚:- 如果发现主分支数据出现问题,可以通过 lakeFS 回滚到特定版本,并在修复后再合并到主分支;Databend 自动获取最新版本数据进行查询分析。
请注意,实际集成时需要根据各自的官方文档详细配置参数,并且可能需要额外的适配层或中间件来确保各组件之间的无缝对接。由于不同项目之间接口可能会有所变化,请查阅最新的文档和指南。
版权归原作者 小果运维 所有, 如有侵权,请联系我们删除。