
前言
如题这是一个我个人的学习记录,学习目标就是Hadoop的伪分布模式的部署,所以在Hadoop,JDK等等背景不做过多介绍,直接开始部署吧.
一.JDK的下载安装配置
1.JDK 下载
下载地址:Java Archive Downloads - Java SE 8u211 and later
页面下滑找到对应自己电脑系统和版本的 JDK 源文件,我下载的是Windows系统64位版本
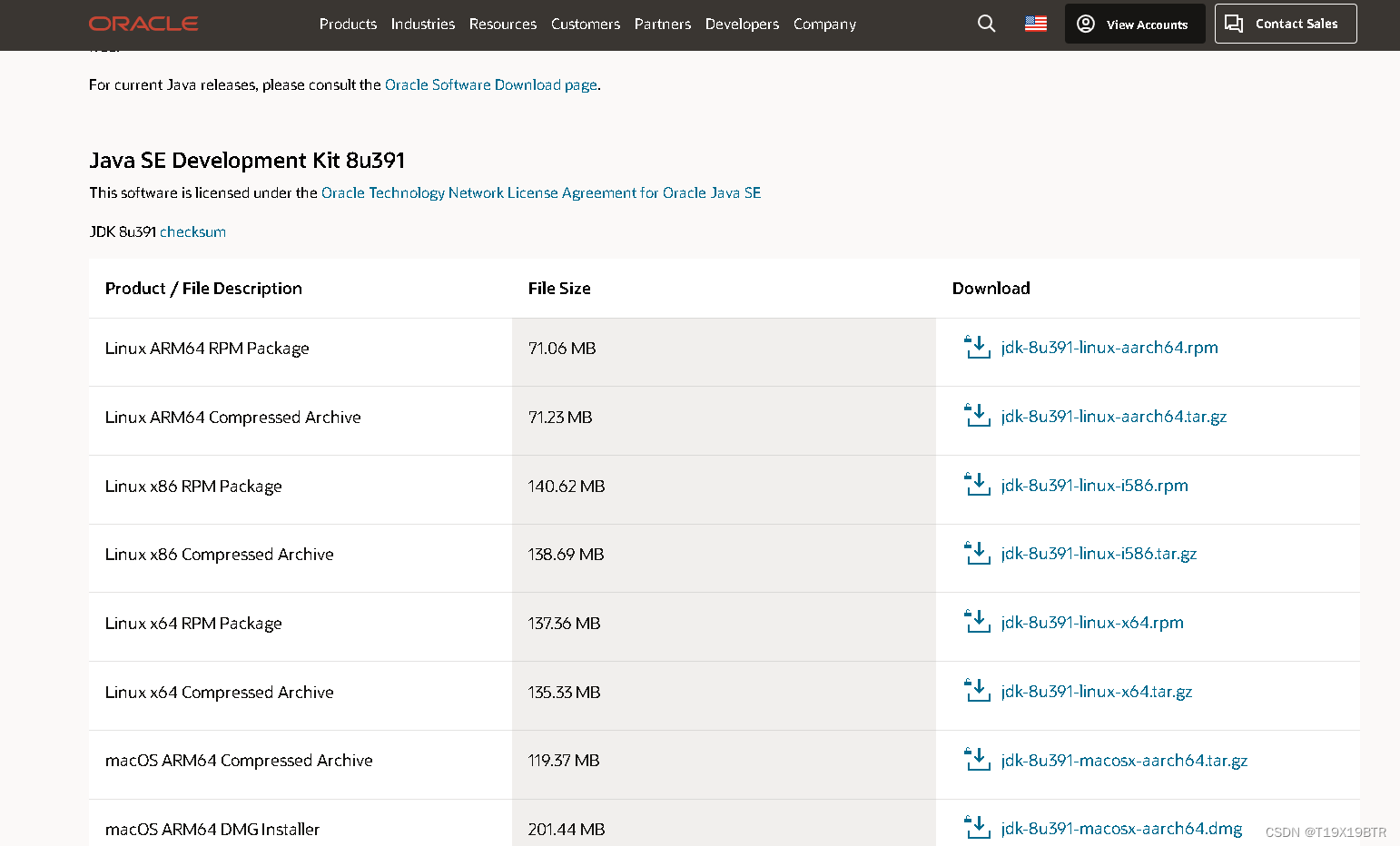

2.JDK 安装
小tips: 像这样开发环境还有python杂七杂八的环境,能就尽可能放在自定义目录当中,易于管理(但这里我的话就选择直接默认安装了,毕竟不怎么用管啥哈哈哈)
直接双击打开就行:
"欢迎仪式",点击下一步:
再下一步:
"状态"满了之后会回空静止,会弹出一个新的窗口:

这个是安装 JAVA 的路径,刚才安装的是 JDK 同样有需要可以更改路径,确认好路径就可以下一步了::
很快啊,啪的一下就完成了:

同时这个也会成功
可以去安装路径看一眼good(路径待会得用到可以留着窗口复制)
3.JDK 环境变量配置
我个人会使用Win+R 输入,感觉比较方便
sysdm.cpl
点击高级就可以看到环境变量了
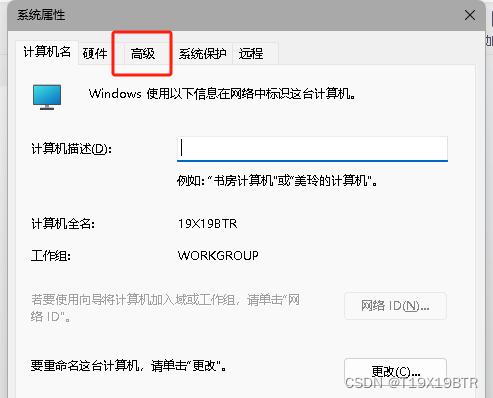
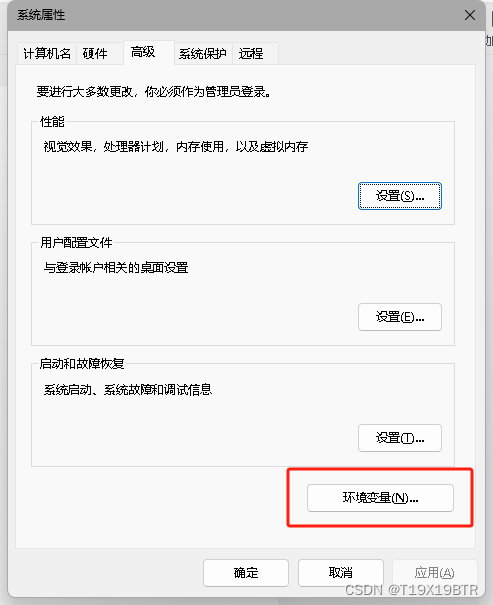
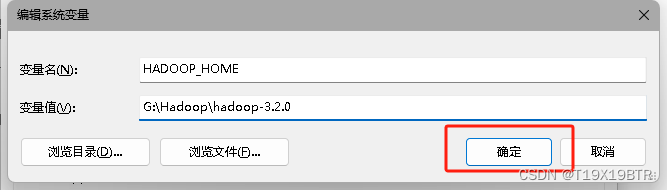
在系统变量中新建:

新建一个变量名位 JAVA_HOME ,变量值为刚才安装 jdk的安装路径,如果路径跟我一样也可以直接复制:
C:\Program Files\Java\jdk-1.8
设置完点击确认:

找到系统变量里的Path点进去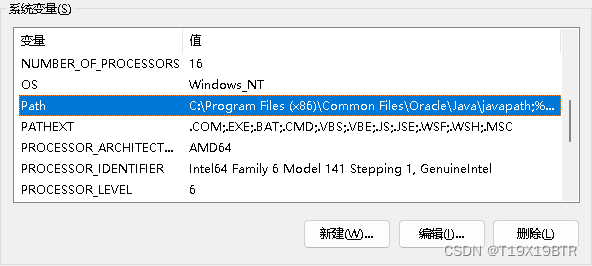
新建两个环境变量,因为学习过程中发现网络上很多出现因为只设置" \bin "路径导致的某些错误,我索性就直接两个都设置了
%JAVA_HOME%\jre\bin
%JAVA_HOME%\bin
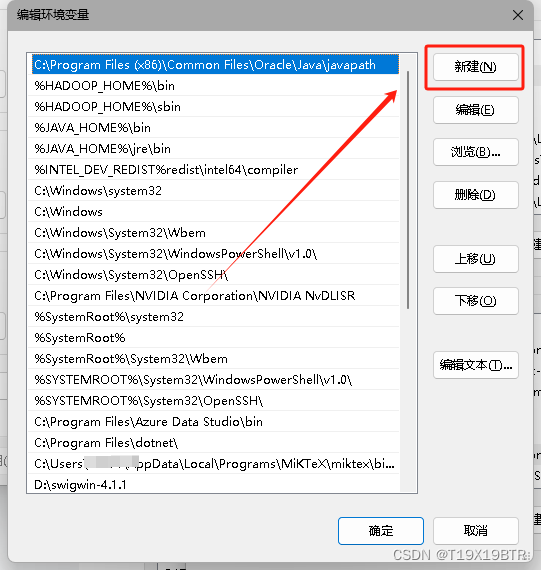

也可以绝对路径配置环境变量像这样
4.验证JDK安装是否成功
最简单的验证方法,尝试获取版本:
Win + R --> cmd 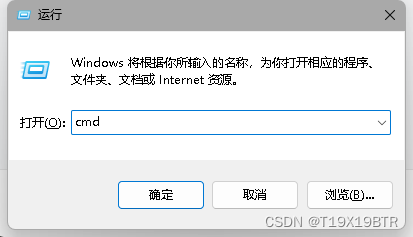
输入:
java -version
如果如图显示了你所下载版本的版本号,说明JDK安装成功!
5.重点?
!!!一定要确定环境变量路径正确,这是在这个环节我目前能总结的唯一问题!!!
二.Hadoop部署以及工具集winutils
1.下载Hadoop解压/下载winutils以及"安装"
下载Hadoop和winutils
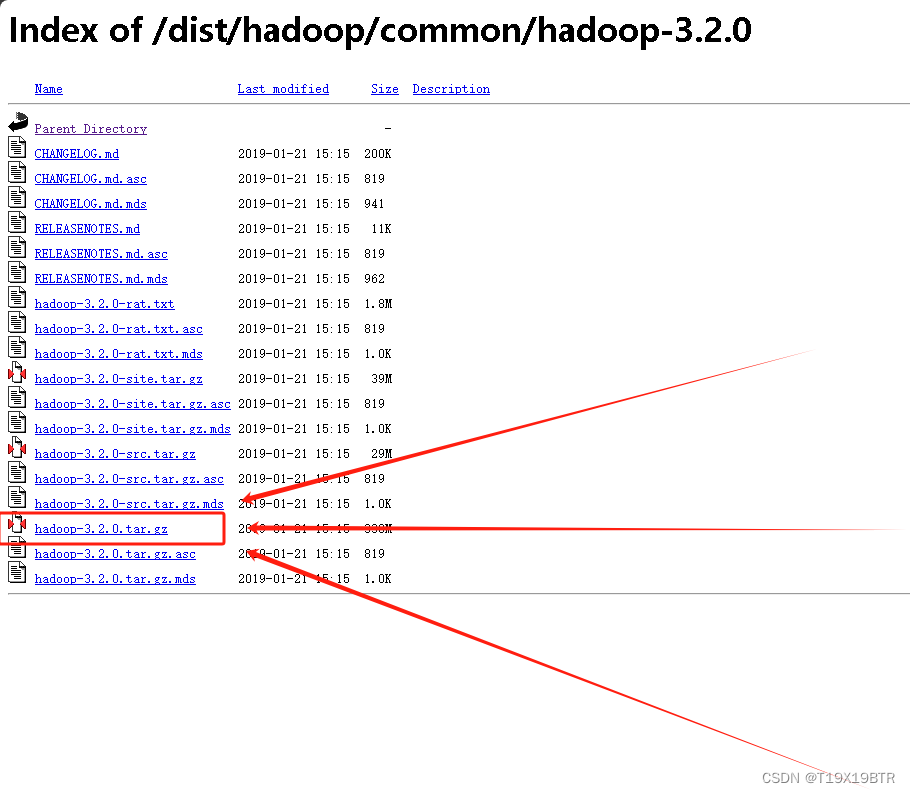
Hadoop下载地址:Index of /dist/hadoop/common/hadoop-3.2.0 (apache.org)
winutils 下载地址:cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows (github.com)
可以根据你需要的版本进行下载我这里选择的是3.2.0版本
!!!Hadoop版本和winutils版本一定要相同!!!
Hadoop下载" hadoop-3.2.0.tar.gz "
下载winutils,点击" code" -->download zip(下载压缩包),为什么不之下3.2.0的winutils,原因是......我不知道怎么在GitHub上单独下载一个文件夹,乐.(但是winutils所有版本加起来也没多大,问题不大)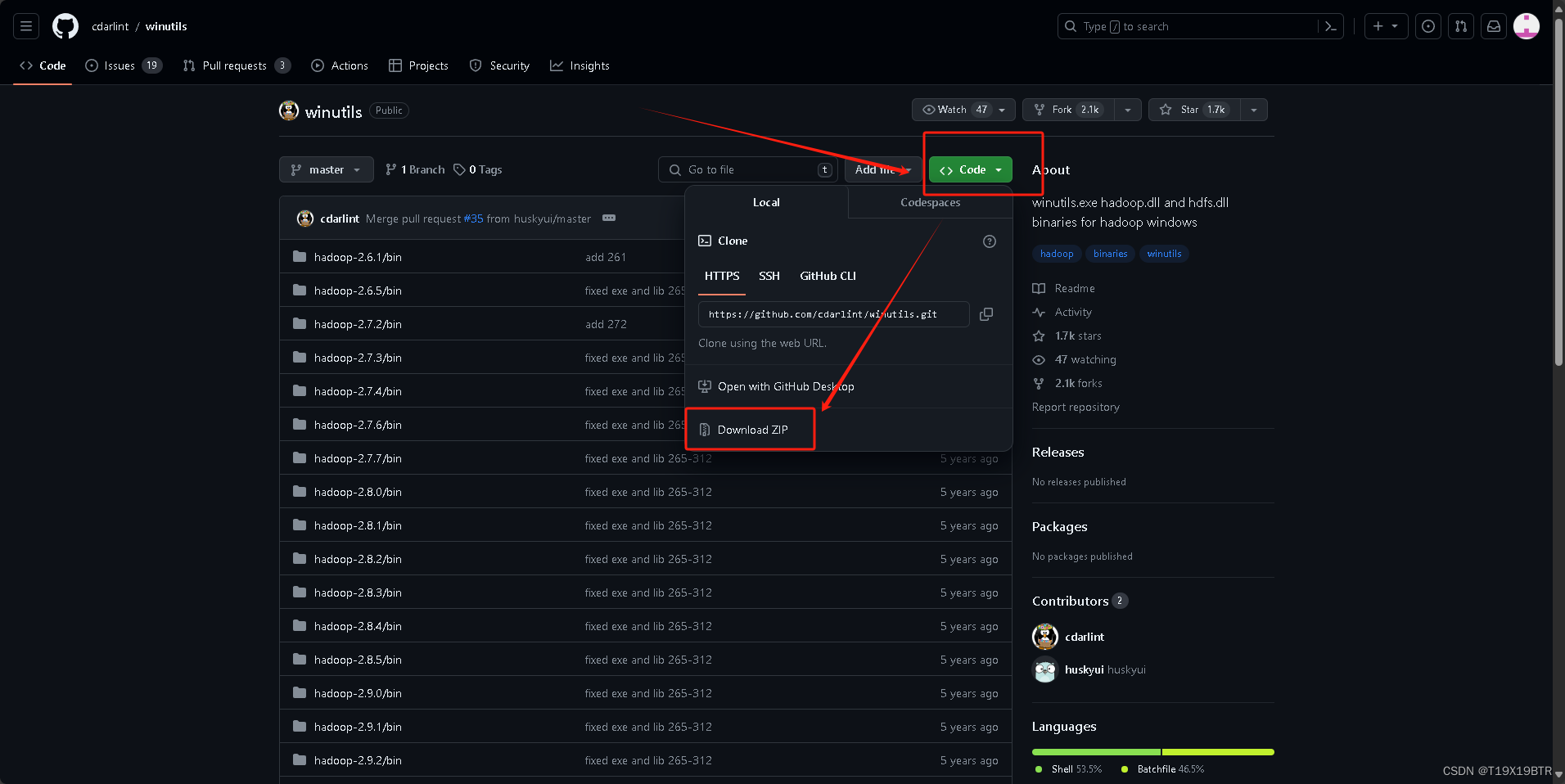
下载完成:

我有360压缩可行所以我就直接用360解压了
也可以无需任何软件解压:
Win + R --> cmd --> 输入" G: " 再输入你的Hadoop压缩包的位置 (注意是你自己电脑的压缩包位置),如图划线部位,说明你已经进入了压缩包的位置,再输入
# tar -zxvf 你下载的版本的压缩包全称包括后缀名,如果你的位置只有这个压缩包 Tab键可以直接补全
tar -zxvf hadoop-3.2.0.tar.gz
等待解压:
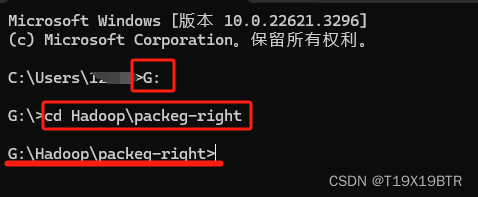
解压出hadoop-3.2.0文件夹如下图:
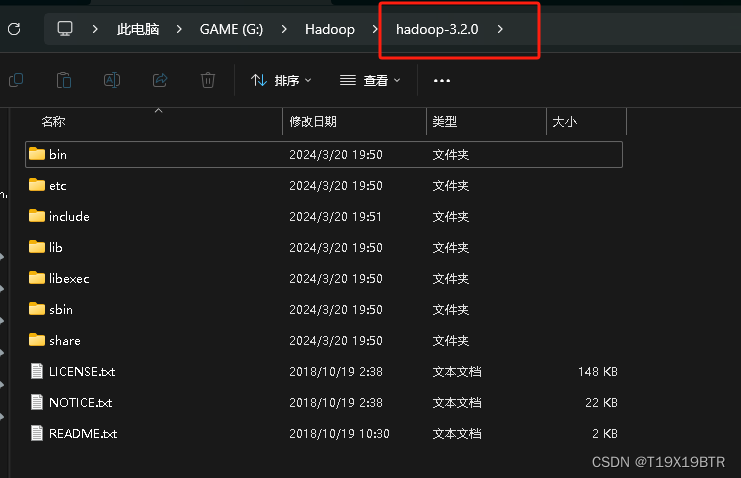
"安装"winutils
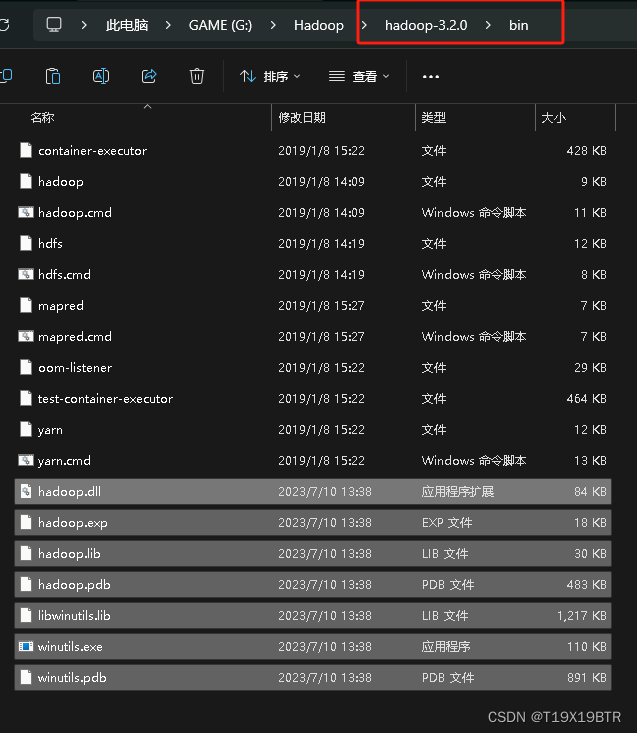
打开压缩包找到对应版本bin全部放到hadoop\bin里建议先将winutils压缩包里的bin解压出来再复制粘贴,因为我发现从360解压拖到Hadoop的bin无法全部成功替换,如第二张替换解说图

先解压出来再复制粘贴到 hadoop-3.2.0文件夹下的 bin

这样就算是" 安装"好了.
2.配置Hadoop环境变量/配置Hadoop文件
Hadoop配置环境变量
如JAVA_HOME一样,不做赘述

hadoop-env.cmd
还有一个重要的点,进入 hadoop-3.2.0 的 etc再进入hadoop 文件夹 找到hadoop-env.cmd,右键在记事本中编辑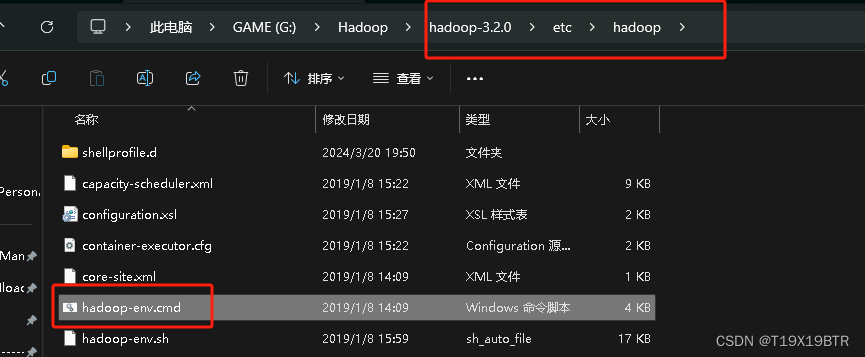

将%JAVA_HOME%更改为JDK 的绝对路径 (路径中不能存在空格) 我的路径在" C:\Program Files\Java\jdk-1.8 "所以更改为如下," PROGRA~1 " 和 " Program Files "是一样的等价替换的.
C:\PROGRA~1\Java\jdk-1.8

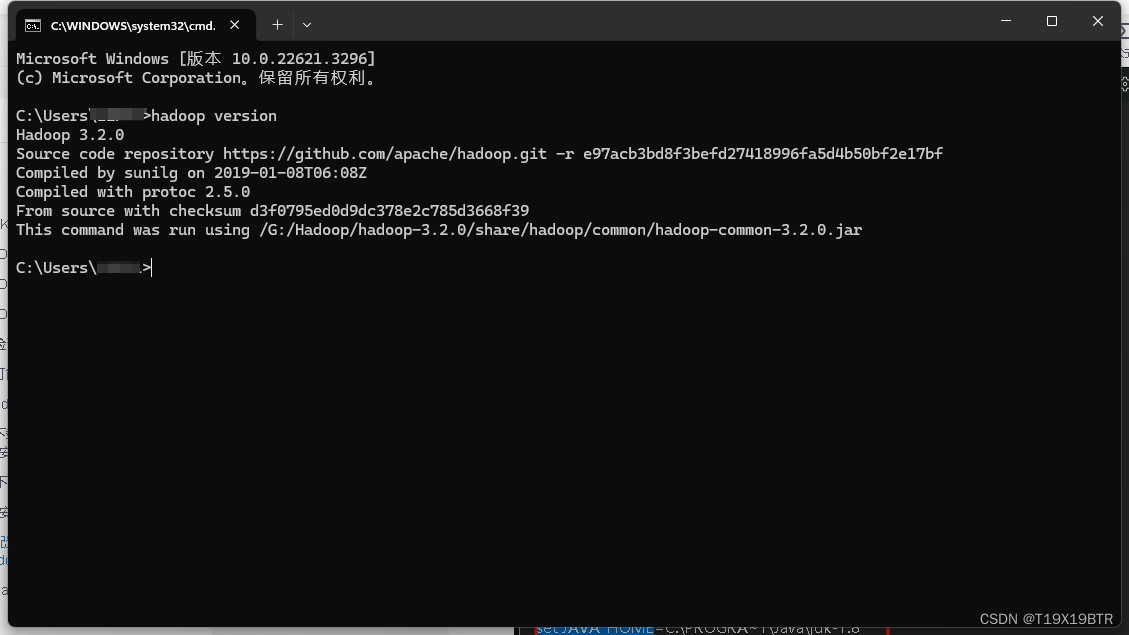
修改完这个路径以及环境变量后,尝试获取版本号.
hadoop version
接下来还需要配置核心文件 **core-site.xml **和** hdfs-site.xml**
core-site.xml

同样以右键笔记本中编辑,配置内容可以直接覆盖使用
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

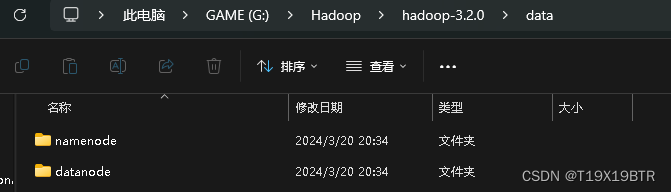
创建data文件夹以及datanode和namenode
在hadoop-3.2.0目录下新建data文件夹,然后在data目录下再新建datanode和namenode文件夹

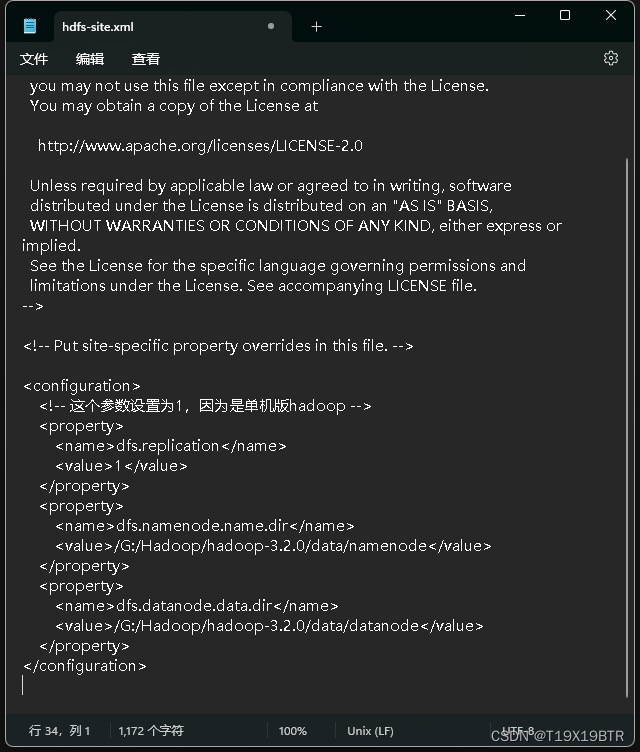
hdfs-site.xml

这里的路径一定要和你自己namenode和datanode路径相同且在盘路径前也需要'/'
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/G:/Hadoop/hadoop-3.2.0/data/namenode</value>这里的路径
一定要和你自己namenode路径相同且在盘路径前也需要'/'
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/G:/Hadoop/hadoop-3.2.0/data/datanode</value>这里的路径
一定要和你自己datanode路径相同且在盘路径前也需要'/'
</property>
</configuration>
初始化namenode
先打开hadoop-3.2.0/bin文件夹在路径栏直接输入cmd,也可以直接在当前目录打开命令提示符(cmd)
输入:
hdfs namenode -format
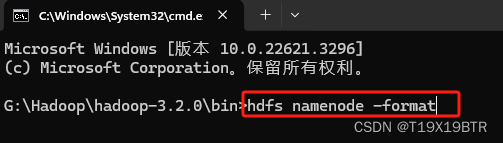
显示了如图信息说明初始化成功:

启动hadopp
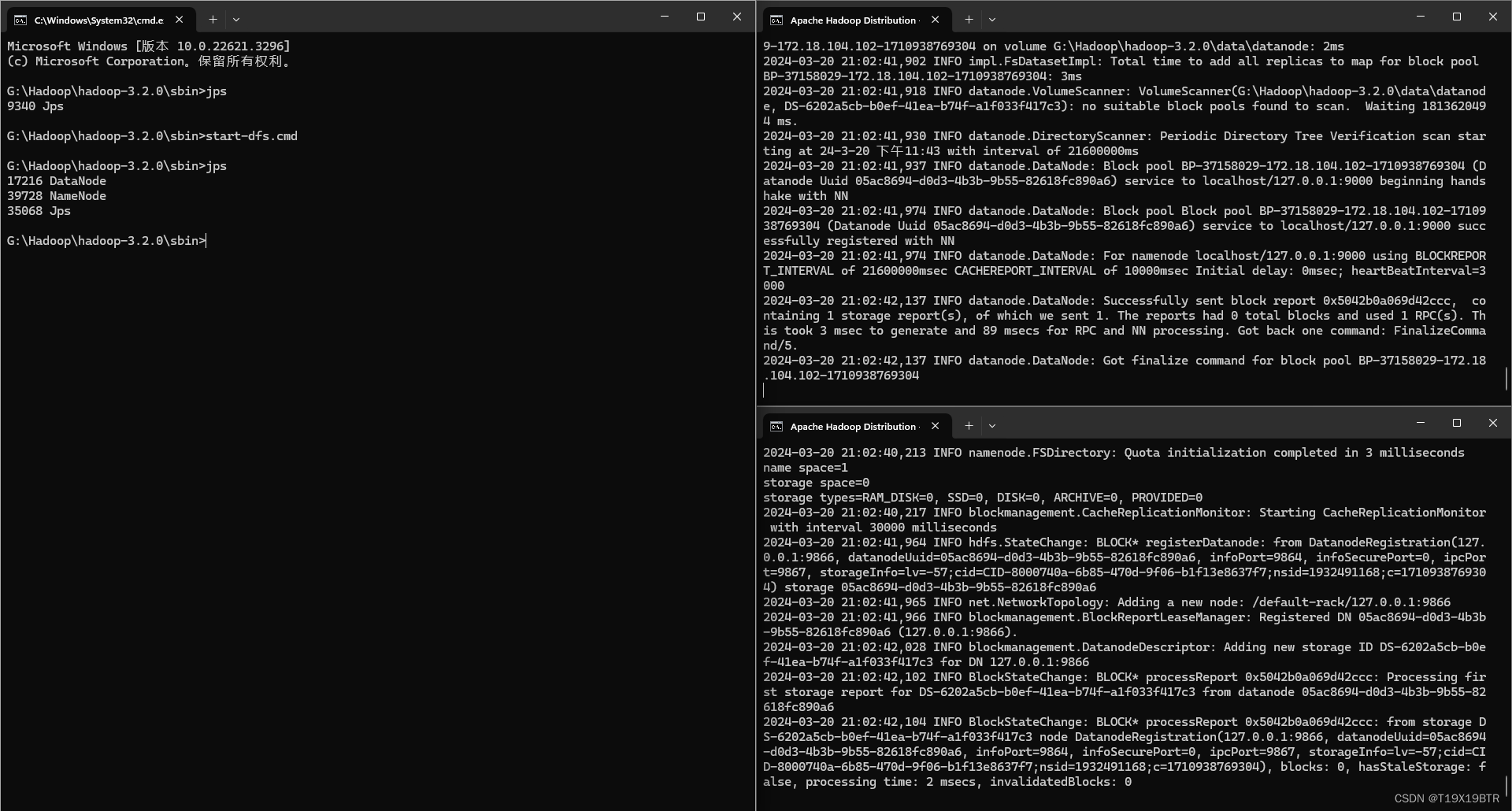
命令提示符(cmd)窗口进入hadoop-3.2.0目录下的 sbin (记得是sbin文件夹一开始我傻子以为教程写错了进了bin......) 也可以直接在sbin目录的路径栏cmd在当前位置打开cmd


输入并回车启动服务:
start-dfs.cmd
这时会弹出两个命令提示符窗口,千万不要关闭,且就我的经验来说,如果两个弹出窗口都没有回到可输入状态,如图,说明服务已经启动成功!
不要管这两个窗口在最开始输入start-dfs.cmd的窗口输入" jps " 检查启动的服务
输入jps 如果出现以下进程说明Hadoop启动成功
打开WEB管理页面
成功后可以打开WEB管理页面查看Hadoop的状态以及操作,启动服务后不要关闭命令提示符窗口,在浏览器中打开如下网址即是Hadoop的网页管理界面
http://localhost:9870
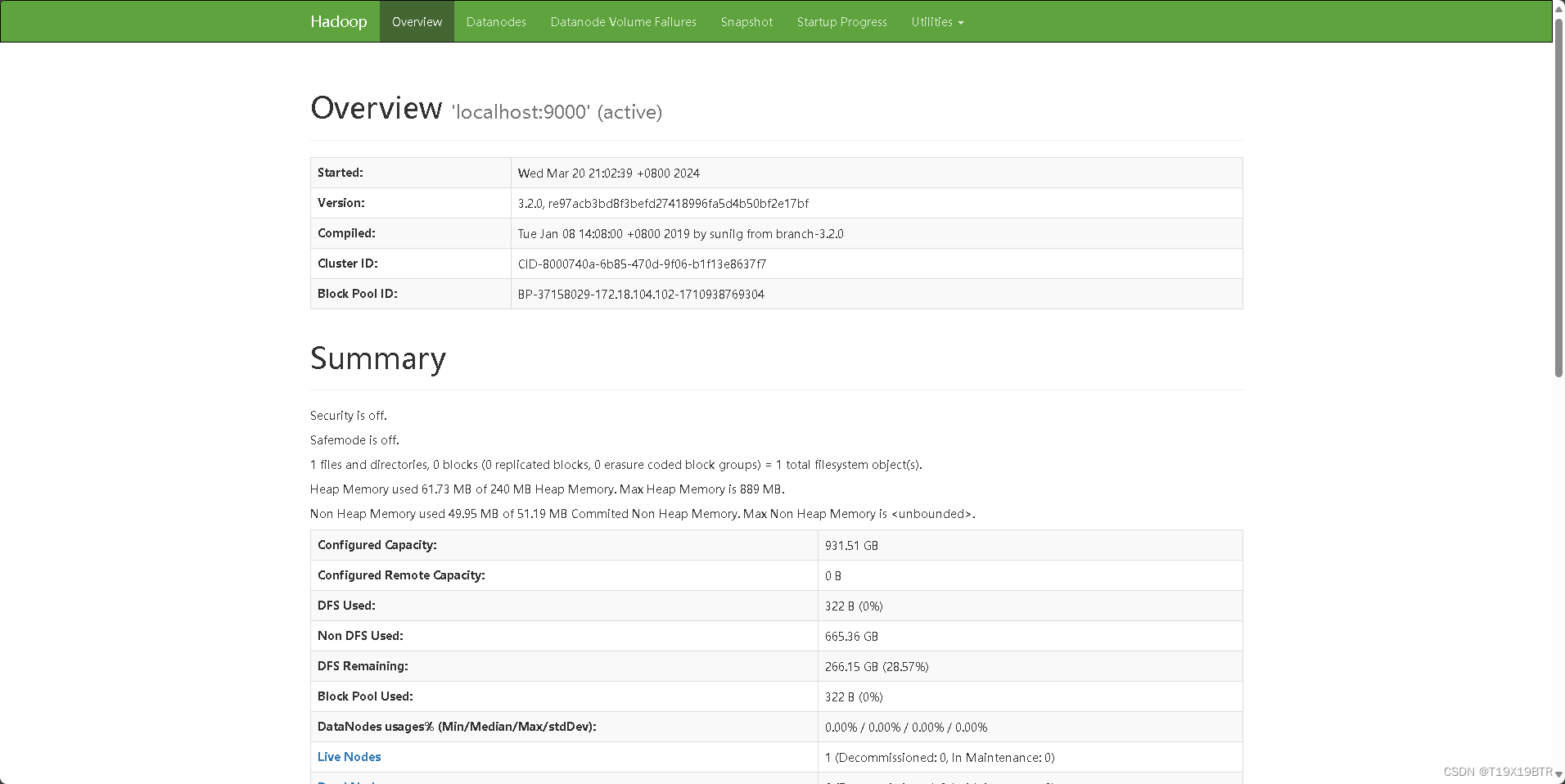
在这里可以进行文件的相关操作了 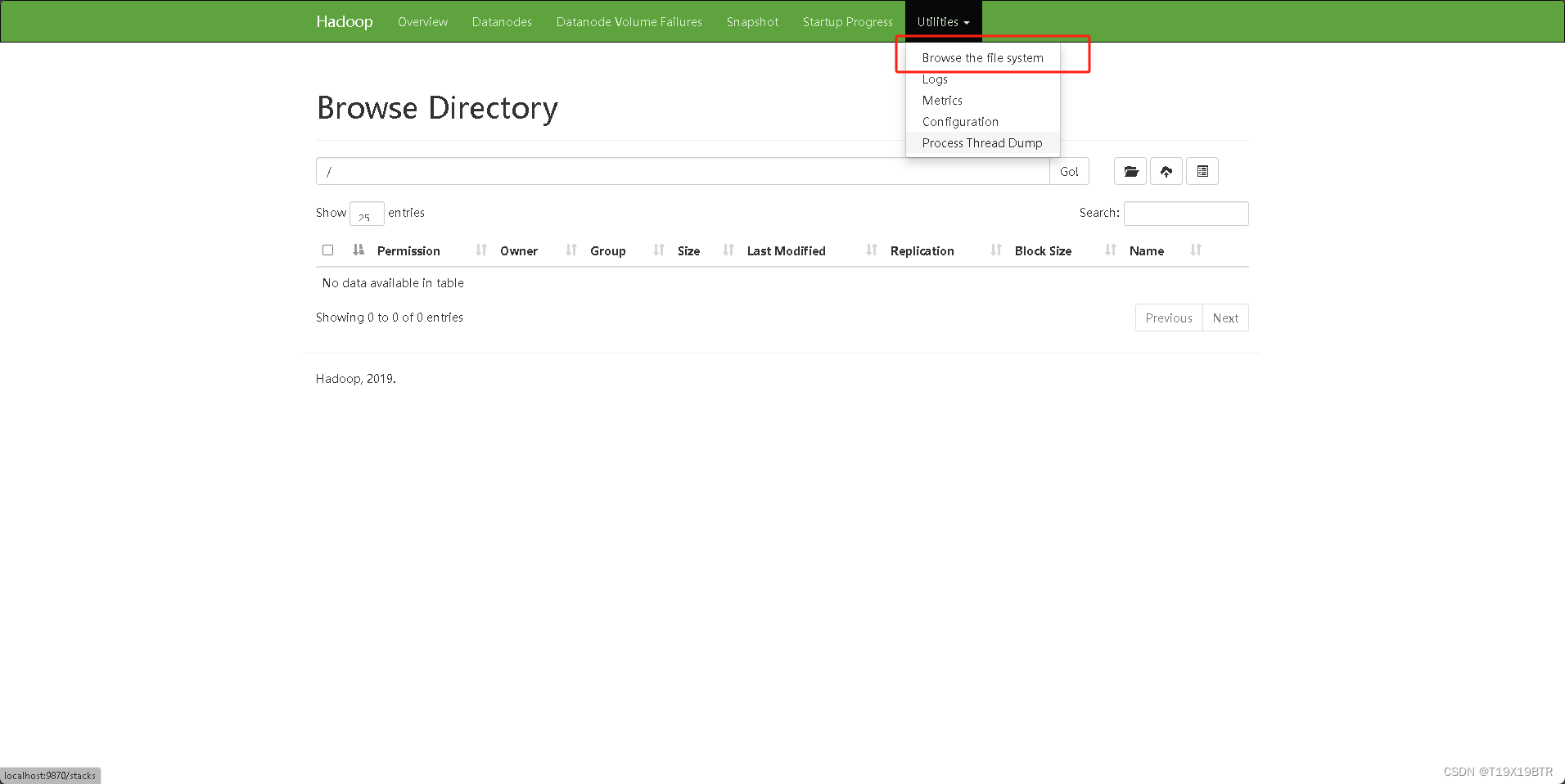
3.Hadoop部署过程的重点?
确保操作中的路径正确
winutils版本要和Hadoop匹配
Java环境变量配置正确
总结
以上就是我一次又一次配置失败,一次又一次不甘心,一次次尝试最后成功的学习笔记,回想起来有些操作失误真的挺傻的,真可恶啊,有些教程讲的不明白导致我没看明白(好吧是我基础不够没能理解),我现在作为傻瓜来设计了这么一个直达式教程希望对你有用.goodgood,接下来要尝试创建虚拟机来部署Hadoop,要是可以的话还会再出.See U
版权归原作者 T19X19BTR 所有, 如有侵权,请联系我们删除。