
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。
数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其中的规律。因此数据进入数据仓库后,它便稳定且不会改变。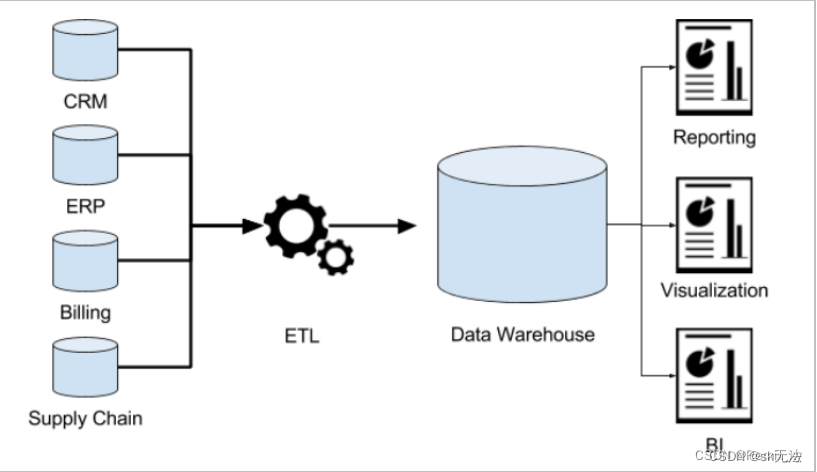
一、BI平台分为事实表、维表,然后两种表聚合成一个宽表。(注意这里取的BI平台是Davinci:https://edp963.github.io/davinci/)
其维表、事实表的关系图如下:
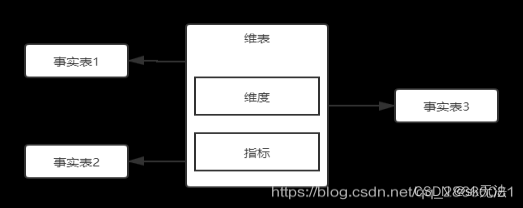
一个维表会对应多个事实表,而维表和事实表所有关联起来就形成一个宽表,其关系如同mysql中的外键索引,如A表中有B_id,A作为维表,B作为事实表,A(维表)可通过B_id来关联B(事实表),然后关联汇总生成的SQL就是宽表。
BI系统中可根据事实表和维度表的关系,应遵循如下两种模型的规范:星型模型和雪花型模型。
星型表:反范式,数据冗余,查询效率高。
雪花型:数据不冗余,但引用层级深,维护复杂,查询效率较低。
下面举一个星型模型(体验课上课预约记录)的例子来说明如下: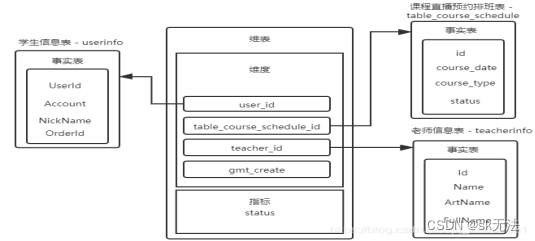
上图以user_table_course_schedule的部分字段(user_id、table_course_schedule_id、teacher_id、gmt_create)来作为维度,并分别关联到了userinfo、tablec_course_schedule、teacherinfo这三张事实表,然后形成一张宽表。
以上面星型模型的例子,对其进行修改,举一个雪花模型例子来说明如下:
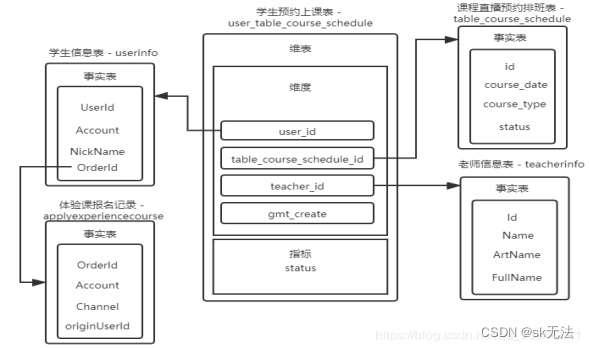
上面雪花模型中,学生信息事实表的orderId还继续关联了下一个层级体验课记录表,体验课报名记录表还可能会继续往下关联,对于复杂的系统而言,一般会采用雪花模型,关键层级会较多,而星型模型的关联过于单一,层级不够深,无法支持这种操作。
理解了上面两种模型的设计,接下来需要确定维度和指标的用法:
维度与指标的规范:
维度:维度用于关联事实表,也可用于做冗余显示(如gmt_create),用于数据检索,所以对于维度设计时,可将其进行分类(看业务扩展需要):
时间维:将时间进行维度细分,如gmt_create划分为年维度、月维度、日维度。
地域维:将地域划分为省维度、市维度、区维度。反例:把省市区 只作为一个维度,而没有拆分,后面进行筛选就不方便。
其他维度按业务进行扩招
指标:用于统计(如总和、平均数、最大值、最小值)、排序等。
可见之前做的那个daac的查询sql就是在利用不同的维度表dim和事实表fact进行雪花模型的关联,然后查出需要的事实表,查询的sql就是宽表。
宽表从字面意义上讲就是字段比较多的数据库表。通常是指业务主题相关的指标、维度、属性关联在一起的一张数据库表。需要维度和指标!而不是机械得认为把维度拆多了,就叫宽表!这个说法才是对的。
二、数据仓库分层
数据仓库架构分层设计包括STG(数据缓冲层)、ODS(数据操作层)、DWD(数据明细层)、DWS(主题汇总层)和ADM(数据应用层)。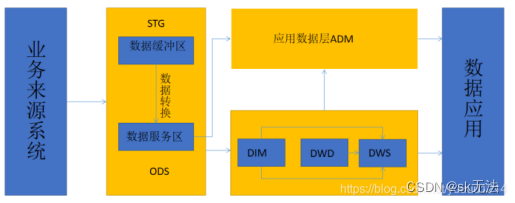
1、STG层
主要完成业务系统结构化数据引入到数据中台,保留业务系统原始数据,缓冲层设计主要保持和数据源的一致性,不做任何类型转换和数据加工处理,为ODS层提供基础数据服务。
2、ODS层
对STG层数据进行类型转换或增量合并处理,得到的全量明细数据,为DWD、DWS和ADM层提供数据服务。
3、DWD层
明细宽表层,用于存放完整详细历史数据。面向业务过程建模,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和与业务过程有关的度量。其设计目标是为后续的Data Warehouse Model提供灵活性和扩展性的基础,同时可以在DW层无法支持需求时直接为应用层提供数据。DWD层由于与业务系统耦合程度较高,其稳定性会受到业务系统的影响。
4、DWS层
存放详细历史数据的公共汇总数据层,面向分析主题建模。DWS是核心数据层,是为应用层提供足够的灵活性和扩展性的基础。
5、ADM层
提供直接面向业务或应用的数据,主要对个性化指标数据进行架构处理,如无公用性或复杂性(如指数型、比值型、排名型等指标数据)的指标数据加工。同时为方便实现数据应用、数据消费的诉求,进行面向应用逻辑的数据组装(如打宽表集市、横表转纵表、趋势指标串等)。
6、DIM维度层:主要存储公共的属性数据,比如产品类别、地理位置、时间详情等信息。综上所述,数据仓库建设的主要工作,就是对原始业务数据进行汇聚,进行分层次的数据处理,生成业务需要的数据,提供给前端业务使用。
三 、 具体的看一下数据仓库的各个层级
①STG层是为了从各个数据源接收数据,并保持和源数据的一致。
1、首先是从不同地方收集数据,一般就是客户的数据库,网页和手机端的API, 用户自己手动上传的excel。
SAP的核心产品是ERP系统,是目前世界排名第一的ERP软件,同时也有其他如供应链管理、财务、CRM、支出、人力资源管理等多个企业管理平台。致力于帮助企业高效处理整个企业范围内的数据,实现无缝的信息流。世界500强中有超过80%的公司使用SAP。中国的大型国营、民营企业 90%使用SAP。2003年9月份,SAP公司特意推出SAP Business One中文版ERP软件,专门为中国中小型企业服务。
EPR: ERP系统是企业资源计划(Enterprise Resource Planning )的简称,是指建立在信息技术基础上,集信息技术与先进管理思想于一身,以系统化的管理思想,为企业员工及决策层提供决策手段的管理平台。
CRM: 客户关系管理 ,CRM库是企业集成管理各种客户数据、整理客户行为数据及一切客户相关数据的中心,为市场分析提供依据。
OMS :订单管理系统
WMS和TMS:都是Web地图服务协议。
②进入一些数据清洗,比如类型转换,数据合并之类的存入ODS层
也就是我们常说的ETL过程:抽取,转换,加载
③ 进入cdm层
按照阿里巴巴的数据体系,ods是数据引入层,将非结构化的数据结构化,而cdm层中包含了dim(维度表),dws(公共汇总表),dwd(明细事实表)。简单理解,dim是将需要观察的角度写出来(维度表),dws是将ods的数据汇总(事实表),dwd则是在dim和dws的基础上写出部分指标(明细宽表);
④进入ads层,展示给用户看的报表之类的
接着到ADS层,进行面向应用逻辑的数据组装(如打宽表集市、横表转纵表、趋势指标串等),生成一些直接给业务用的表。(我这里接触的一般是用于生成power bi报表和tableau报表)
四 数据工厂
一般情况下,我们数据ETL过程是通过编写本地的sql存储过程或者sparksql进行代码处理的
,然后部署到服务器上自动定时运行。
或者我们也可以将这些ETL的过程放在云上运行,称作数据工厂。
这里我们看看azure微软云的架构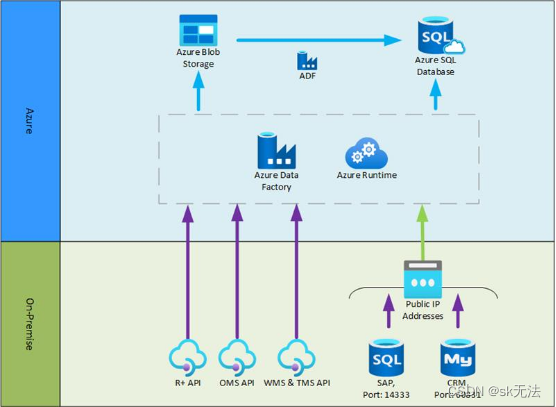
Infrastructure Architecture
The solution will use following key Azure native products:
*Azure Blob Storage: exist as landing zone for API outputs and outbound zone for exports
*Azure Data Factory: ETL tool to connect to source systems via database direct connection or API call. Load raw data into data warehouse. Schedule job and Monitor
Azure SQL DB:
*data warehouse physical carrier that contains
*staging tables with raw data,
*meta tables with meta control data,
*target tables with cleansed/transformed data,
*export tables, etc
我们可以看到,这里azure并不是直接把数据存入了stg层,而是先放入了azure data factory,再从数据工厂通过缓存blog或者直接的存入azure sql DB。
那什么是数据工厂呢,数据工厂起什么作用呢?
在大数据环境中,原始、散乱的数据通常存储在关系、非关系和其他存储系统中。 但是,就其本身而言,原始数据没有适当的上下文或含义来为分析师、数据科学家或业务决策人提供有意义的见解。
大数据需要可以启用协调和操作过程以将这些巨大的原始数据存储优化为可操作的业务见解的服务。 Azure 数据工厂是为这些复杂的混合提取-转换-加载 (ETL)、提取-加载-转换 (ELT) 和数据集成项目而构建的托管云服务。
版权归原作者 sk无法 所有, 如有侵权,请联系我们删除。