

文章目录
每篇前言
- 🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答);进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
一、JSON基础概述
1、JSON是什么?
JSON(全名:JavaScript Object Notation 对象表示法)是一种轻量级的文本数据交换格式,JSON的数据格式其实就是python里面的字典格式,里面可以包含方括号括起来的数组,也就是python里面的列表。
- JSON独立于语言
- JSON具有自我描述性,更易理解
- JSON 比 XML 更小、更快,更易解析
- 爬虫经常经常会获取接口数据,接口数据就是JSON格式
2、JSON长什么样?
语法格式:
{key1:value1, key2:value2,}
键值对形式(用冒号分开),对间用逗号连接
简单案例:JSON 对象
{"name":"小明","age":18}
复杂案例:JSON 数组
{"student":[{"name":"小明","age":11},{"name":"小红","age":10}],"classroom":{"class1":"room1","class2":"room2"}}
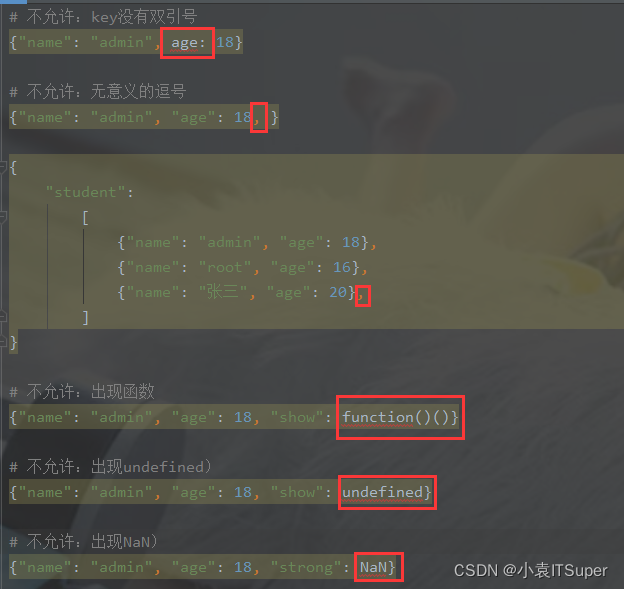
3、注意事项
1、json的键值对的键部分,必须用双引号
"
包裹,单引号都不行(所以如果在键中出现了关键字,也被字符化了),而js中对象没有强制要求(所以在键中不允许出现关键字)。
2、json的键值对的值部分,不允许出现函数function,undefined,NaN,但是可以有null,js中对象的值中可以出现。
3、json数据结束后,不允许出现没有意义的逗号,如:
{"name":"admin","age":18,}
,注意看数据结尾部分18的后面的逗号,不允许出现。
4、json格式总结
正确的json格式如下:
# 格式1:JSON 对象{"name":"admin","age":18}# 格式2:JSON 数组{"student":[{"name":"小明","age":18},{"name":"小红","age":16},{"name":"小黑","age":20}]}
错误的json格式如下:
二、json 模块
1、作用
1、使用jsON字符串生成python对象(load)
2、由python对象格式化成为ison字符串(dump)
2、数据类型转换
将数据从
Python转换到json
格式,在数据类型上会有变化,如下表所示:
PythonJSONdictobjectlist, tuplearraystrstringint, float, int- & float-derived EnumsnumberTruetrueFalsefalseNonenull
反过来,将json格式转化为python内置类型,如下表所示:
JSONPythonobjectdictarrayliststringstrnumber(int)intnumber(real)floattrueTruefalseFalsenullNone
3、使用方法
json模块的使用其实很简单,对于绝大多数场合下,我们只需要使用下面四个方法就可以了:
方法功能
json.dumps(obj)
将python数据类型转换为json格式的字符串。
json.dump(obj, fp)
将python数据类型转换并保存到son格式的文件内。
json.loads(s)
将json格式的字符串转换为python的类型。
json.load(fp)
从json格式的文件中读取数据并转换为python的类型。
4、 json.dumps()
将python数据类型转换为json格式的字符串。
语法格式:
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
>>>import json
# Python字典>>> person ={"name":"小明","age":30,"tel":["888888","1351111111"],"isonly":True}>>>print(person){'name':'小明','age':30,'tel':['888888','1351111111'],'isonly':True}>>>type(person)<class'dict'# Python字典转换为json字符串>>> jsonStr = json.dumps(person)>>>print(jsonStr ){"name":"\u5c0f\u660e","age":30,"tel":["888888","1351111111"],"isonly": true}>>>type(jsonStr)<class'str'>
从上可以看出json格式和Python格式的区别在于:python格式打印输出是单引号,类型为
dict
。而json格式打印输出是双引号,类型为:
str
。
True
的开头大小写区别。
使用参数能让JSON字串格式化输出:
>>>print(json.dumps(person, sort_keys=True, indent=4, separators=(',',': '))){"age":30,"isonly": true,"name":"\u5c0f\u660e","tel":["888888","1351111111"]}
参数解读:
sort_keys:是否排序indent:定义缩进距离separators:是一个元组,定义分隔符的类型skipkeys:是否允许JSON字串编码字典对象时,字典的key不是字符串类型(默认是不允许)
修改分割符类型:
>>>print(json.dumps(person, sort_keys=True, indent=4, separators=('!','-'))){"age"-30!
"isonly"-true!
"name"-"\u5c0f\u660e"!
"tel"-["888888"!
"1351111111"]}
文件操作:
import json
person ={"name":"小明","age":30,"tel":["888888","1351111111"],"isonly":True}
jsonStr = json.dumps(person)withopen('test.json','w', encoding='utf-8')as f:# 打开文件
f.write(jsonStr)# 在文件里写入转成的json串
查看生成的新文件:
5、json.dump()
将python数据类型转换并保存到son格式的文件内。
语法格式:
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
import json
person ={"name":"小明","age":30,"tel":["888888","1351111111"],"isonly":True}
json.dump(person,open('data.json','w'))
查看生成的新文件:
使用参数能让JSON字串格式化输出:
import json
person ={"name":"小明","age":30,"tel":["888888","1351111111"],"isonly":True}
json.dump(person,open('data.json','w'), sort_keys=True, indent=4, separators=(',',': '))
再次查看文件: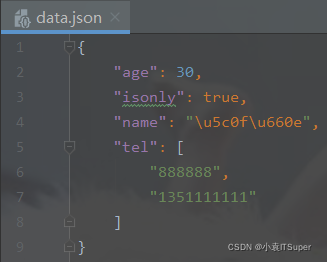
json.dumps
和
json.dump
写入文件的区别:
- dump() 不需要使用
.write()方法,只需要写那个字典,那个文件即可;而 dumps() 需要使用.write()方法写入。 - 如果把字典写到文件里面的时候,dump()好用;但是如果不需要操作文件,或需要把内容存储到数据库何excel,则需要使用dumps()先把字典转换成字符串,再写入
6、json.loads()
将json格式的字符串转换为python的类型。
语法格式:
json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
>>>import json
# Python字典>>> person ={"name":"小明","age":30,"tel":["888888","1351111111"],"isonly":True}>>>print(person){'name':'小明','age':30,'tel':['888888','1351111111'],'isonly':True}>>>type(person)<class'dict'# Python字典转换为json字符串>>> jsonStr = json.dumps(person)>>>print(jsonStr ){"name":"\u5c0f\u660e","age":30,"tel":["888888","1351111111"],"isonly": true}>>>type(jsonStr)<class'str'># json字符串再转换为Python字典>>> python_obj = json.loads(jsonStr)>>>print(python_obj){'name':'小明','age':30,'tel':['888888','1351111111'],'isonly':True}>>>print(type(python_obj))<class'dict'># 打印字典的所有key>>>print(python_obj.keys())
dict_keys(['name','age','tel','isonly'])# 打印字典的所有values>>>print(python_obj.values())
dict_values(['小明',30,['888888','1351111111'],True])
文件操作:
import json
f =open('data.json', encoding='utf-8')
content = f.read()# 使用loads()方法需要先读文件
python_obj = json.loads(content)print(python_obj)
输出结果:
7、json.load()
从json格式的文件中读取数据并转换为python的类型。
语法格式:
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
文件操作:
import json
python_obj = json.load(open('data.json','r'))print(python_obj)print(type(python_obj))
输出结果:
json.load()
和
json.loads()
区别:
- loads() 传的是json字符串,而 load() 传的是文件对象
- 使用 loads() 时需要先读取文件在使用,而 load() 则不用
8、总结
不管是dump还是load,带s的都是和字符串相关的,不带s的都是和文件相关的
三、XML文件和JSON文件互转
记录工作中常用的一个小技巧
cmd控制台安装第三方模块:
pip install xmltodict
1、XML文件转为JSON文件
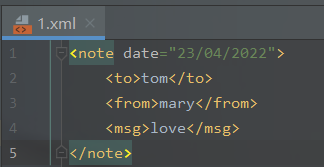
新建一个
1.xml
文件:
<note date="23/04/2022"><to>tom</to><from>mary</from><msg>love</msg></note>
转换代码实现:
import json
import xmltodict
defxml_to_json(xml_str):"""parse是的xml解析器,参数需要
:param xml_str: xml字符串
:return: json字符串
"""
xml_parse = xmltodict.parse(xml_str)# json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。# dumps()方法的ident=1,格式化json
json_str = json.dumps(xml_parse, indent=1)return json_str
XML_PATH ='./1.xml'# xml文件的路径withopen(XML_PATH,'r')as f:
xmlfile = f.read()withopen(XML_PATH[:-3]+'json','w')as newfile:
newfile.write(xml_to_json(xmlfile))
输出结果(生成json文件):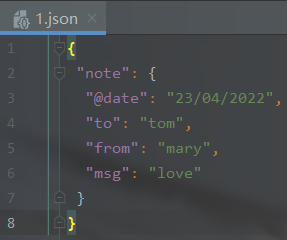
2、JSON文件转换为XML文件
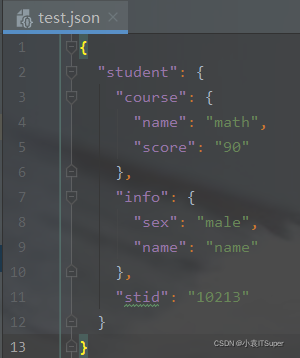
新建
test.json
文件:
{"student":{"course":{"name":"math","score":"90"},"info":{"sex":"male","name":"name"},"stid":"10213"}}
转换代码实现:
import xmltodict
import json
defjson_to_xml(python_dict):"""xmltodict库的unparse()json转xml
:param python_dict: python的字典对象
:return: xml字符串
"""
xml_str = xmltodict.unparse(python_dict)return xml_str
JSON_PATH ='./test.json'# json文件的路径withopen(JSON_PATH,'r')as f:
jsonfile = f.read()
python_dict = json.loads(jsonfile)# 将json字符串转换为python字典对象withopen(JSON_PATH[:-4]+'xml','w')as newfile:
newfile.write(json_to_xml(python_dict))
输出结果(生成xml文件):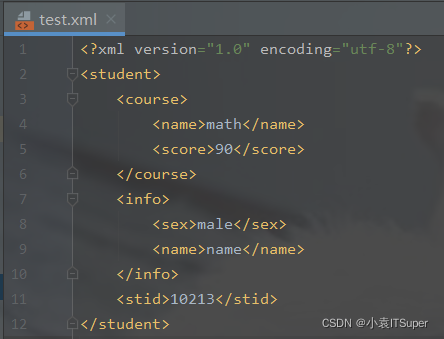
🎉三、参与抽粉丝送书啦
以后每周新文评论区抽两个粉丝送书,大家持续关注此专栏:《每周免费送书活动》专栏
书籍展示:《 自然语言处理NLP从入门到项目实战(Python语言实现)》
【抽奖方式】:
关注博主、点赞收藏文章后,评论区留言:人生苦短,我用Python!!!博主会用爬虫代码随机抽取两人送书!【开奖时间】:截止到周日晚8点,博主会用爬虫代码随机抽取两人送书!
【书籍内容简介】
- 本书分为12章,主要包括学习人工智能原理、自然语言处理技术、掌握深度学习模型、NLP开源技术实战、Python神经网络计算实战、AI语音合成有声小说实战、玩转词向量、近义词查询系统实战、机器翻译系统实战、文本情感分析系统实战、电话销售语义分析系统实战人工智能辅助写作系统(独家专利技术解密)。
- 本书内容通俗易懂,案例丰富,实用性强,特别适合使用Python语言人工智能自然语言处理的入门和进阶的读者阅读,也适合产品经理、人工智能研究者等对人工智能自然语言处理感兴趣的读者阅读。另外,本书也适合作为相关培训机构的教材使用。
也有不想靠抽的小伙伴可以参考下面:
版权归原作者 小袁ITSuper 所有, 如有侵权,请联系我们删除。