
1)Spark工作原理:
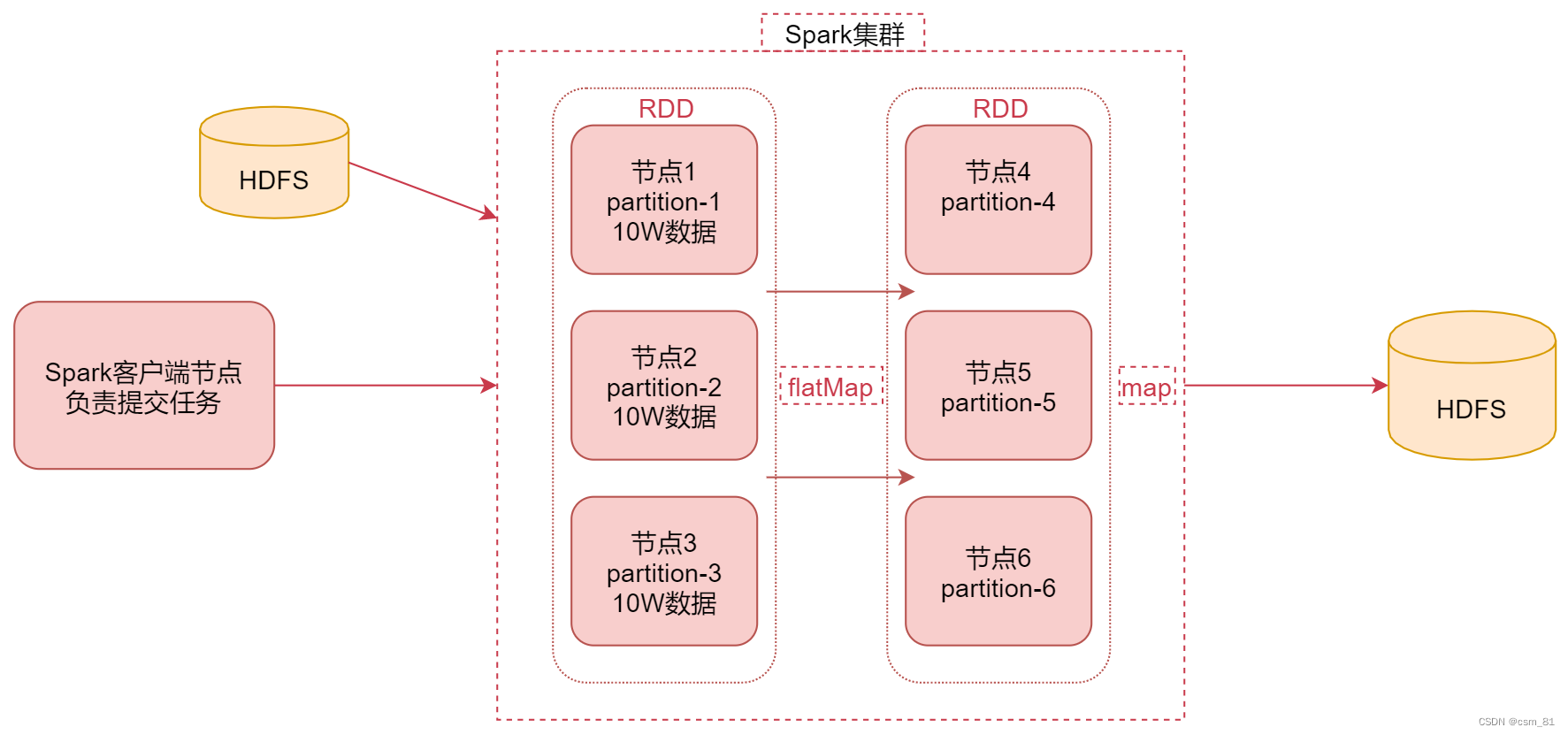
首先看中间是一个Spark集群,**可以理解为是Spark的 standalone集群,集群中有6个节点**
左边是Spark的客户端节点,这个节点主要负责向Spark集群提交任务,假设在这里我们向Spark集群提交了一个任务
那这个Spark任务肯定会有一个数据源,数据源在这我们使用HDFS,就是让Spark计算HDFS中的数据。
当Spark任务把HDFS中的数据读取出来之后,它会把HDFS中的数据转化为RDD,RDD其实是一个弹性分布式数据集,它其实是一个逻辑概念,在这你先把它理解为是一个数据集合就可以了,后面我们会详细分析这个RDD
在这里这个RDD你就可以认为是包含了我们读取的HDFS上的数据
其中这个RDD是有分区这个特性的,也就是一整份数据会被分成多份,
假设我们现在从HDFS中读取的这份数据被转化为RDD之后,在RDD中分成了3份,那这3份数据可能会分布在3个不同的节点上面,对应这里面的节点1、节点2、节点3
这个RDD的3个分区的数据对应的是partiton-1、partition-2、partition-3
这样的好处是可以并行处理了,后期每个节点就可以计算当前节点上的这一个分区的数据。
注意:这个RDD的数据是在内存中的。
假设现在这个RDD中每个分区中的数据有10w条,那接下来我们就想对这个RDD中的数据进行计算了,可以使用一些高阶函数进行计算,例如:flatMap、map之类的。那在这我们先使用flatMap对数据进行处理,把每一行数据转成多行数据,此时flatMap这个函数就会在节点1、节点2和节点3上并行执行了。计算之后的结果还是一个带有分区的RDD,那这个RDD我们假设存在节点4、节点5和节点6上面。此时每个节点上面会有一个分区的数据,我们给这些分区数据起名叫partition-4、partition-5、partition-6。
正常情况下,前面节点1上的数据处理之后会发送到节点4上面,另外两个节点也是一样的。此时经过flatmap计算之后,前面RDD的数据传输到后面节点上面这个过程是不需要经过shuffle的。后面可能还会通过map、或者其它的一些高阶函数对数据进行处理,当处理到最后一步的时候是需要把
数据存储起来的,在这我们选择把数据存储到hdfs上面,其实在实际工作中,针对这种离线计算,大部分的结果数据都是存储在hdfs上面的,当然了也可以存储到其它的存储介质中。
梳理一下:
** 1)**首先通过Spark客户端提交任务到Spark集群,2)然后Spark任务在执行的时候会读取数据源HDFS中的数据,将数据加载到内存中,转化为RDD,3)然后针对RDD调用一些高阶函数对数据进行处理,中间可以调用多个高阶函数,最终把计算出来的结果数据写到HDFS中。
什么是RDD
1)RDD通常通过Hadoop上的文件,即HDFS文件进行创建,也可以通过程序中的集合来创建
2)RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集
RDD的特点
弹性:RDD数据默认情况下存放在内存中,但是在内存资源不足时,Spark也会自动将RDD数据写入
磁盘
分布式:RDD在抽象上来说是一种元素数据的集合,它是被分区的,每个分区分布在集群中的不同节
点上,从而让RDD中的数据可以被并行操作
容错性:RDD最重要的特性就是提供了容错性,可以自动从节点失败中恢复过来
Spark相关进程:
1)Driver
我们编写的Spark程序就在Driver(进程)上,由Driver进程负责执行
Driver进程所在的节点可以是Spark集群的某一个节点或者就是我们提交Spark程序的客户端节点
具体Driver进程在哪个节点上启动是由我们提交任务时指定的参数决定的
2)master
集群的主节点中启动的进程
主要负责集群资源的管理和分配,还有集群的监控等
3)Worker
集群的从节点中启动的进程
主要负责启动其它进程来执行具体数据的处理和计算任务
4)Executor
此进程由Worker负责启动,主要为了执行数据处理和计算
5)Task
是一个线程
由Executor负责启动,它是真正干活的
二)spark架构原理分析图
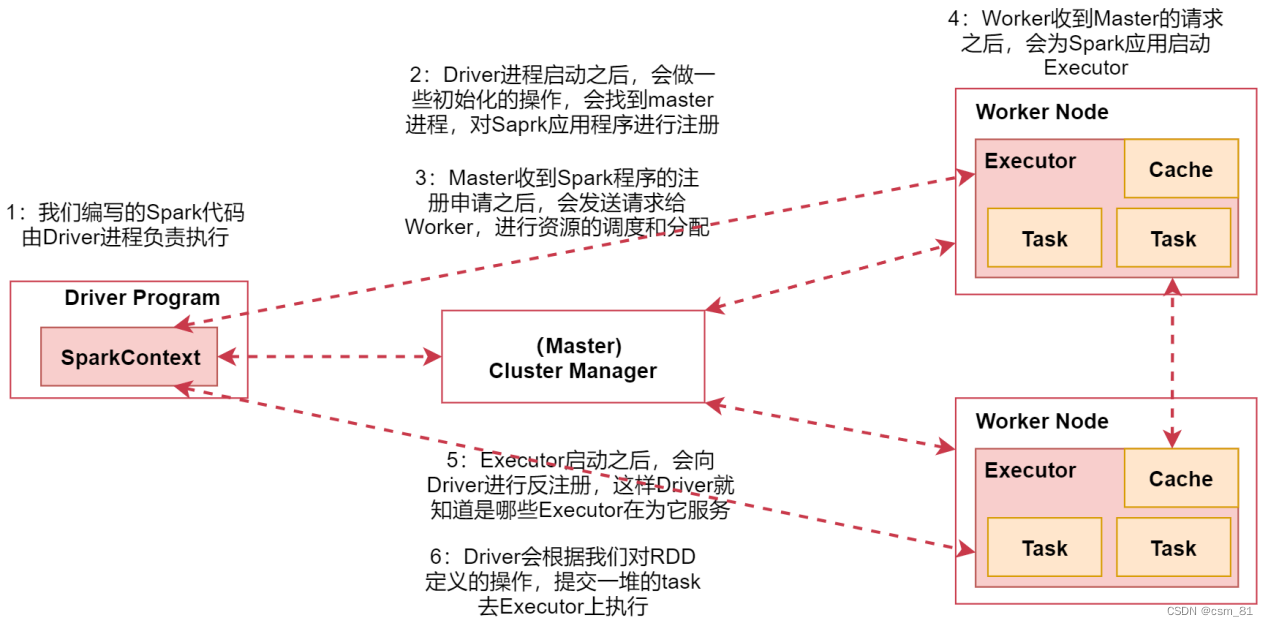
- 首先我们在spark的客户端机器上通过driver进程执行我们的Spark代码
当我们通过spark-submit脚本提交Spark任务的时候Driver进程就启动了。 - Driver进程启动之后,会做一些初始化的操作,会找到集群master进程,对Spark应用程序进行注册
- 当Master收到Spark程序的注册申请之后,会发送请求给Worker,进行资源的调度和分配
- Worker收到Master的请求之后,会为Spark应用启动Executor进程
会启动一个或者多个Executor,具体启动多少个,会根据你的配置来启动 - Executor启动之后,会向Driver进行反注册,这样Driver就知道哪些Executor在为它服务了
- Driver会根据我们对RDD定义的操作,提交一堆的task去Executor上执行
task里面执行的其实就是具体的map、flatMap这些操作。
版权归原作者 小崔的技术博客 所有, 如有侵权,请联系我们删除。