
xxx系列文章
xxxx系列(1)―
xxxx系列(2)―
xxxxx系列(3)―
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
在最近使用Kafka过程中,发现使用@KafkaListener指定分区消费时(指定了所有分区),如果服务是多节点,会出现重复消费的现象,即两个服务节点中的消费者均会消费到相同信息,这与消费者组中只有一个消费者可以消费到消息的规则不相符,于是花时间找了找原因
参考链接:
Consumer 机制
小龙虾你抓不到(上面博主的专栏)
KafkaConsumer assign VS subscribe
Kafka的assign和subscribe订阅模式
使用kafka-consumer-group.sh查看消息消费情况,CONSUMER-ID,HOST,CLIENT-ID不显示问题分析
kafka _ spring.kafka.listener.concurrency 的使用
kafka之Consumer消费者基本概念
kafka consumer属性
【spring-kafka】@KafkaListener详解与使用
【spring-kafka】属性concurrency的作用及如何配置(RoundRobinAssignor 、RangeAssignor)
石臻臻的杂货铺
Kafka消费者订阅指定主题(subscribe)或分区(assign)详解
Kafka 核心技术与实战学习笔记(二十五)消费者组重平衡
孔汤姆(上面博主的专栏)
@KafkaListener 详解及消息消费启停控制
kafka&logstash&flume&rabbitMq(上面博主的专栏)
一、问题描述
使用的代码如下,出现问题后使用kafka-consumer-groups.sh脚本查看,发现consumer-id,host,client-id均为空,这是很不正常的,于是搜索相关,在这篇博客找到了原因,(https://blog.csdn.net/z435128234/article/details/128320706)
@KafkaListener(topicPartitions = {@TopicPartition(topic = "arch",partitions = {"0"})})

二、问题解决
之所以出现上面的的问题,是因为使用了消费组的手动分区,也就是consumer.assign()方式,如果使用了手动分区,则分区的自动管理方式不会再起作用,而且如果消费组成员变更或主题的元数据等信息改变,将不会触发再平衡机制。
结论:
KafkaConsumer.subscribe() : 为consumer自动分配partition,有内部算法保证topic-partition以最优的方式均匀分配给同group下的不同consumer。
KafkaConsumer.assign() : 为consumer手动、显示的指定需要消费的topic-partitions,不受group.id限制,相当与指定的group无效(this method does not use the consumer’s group management)。
二、验证
两个服务节点,各自启动三个消费者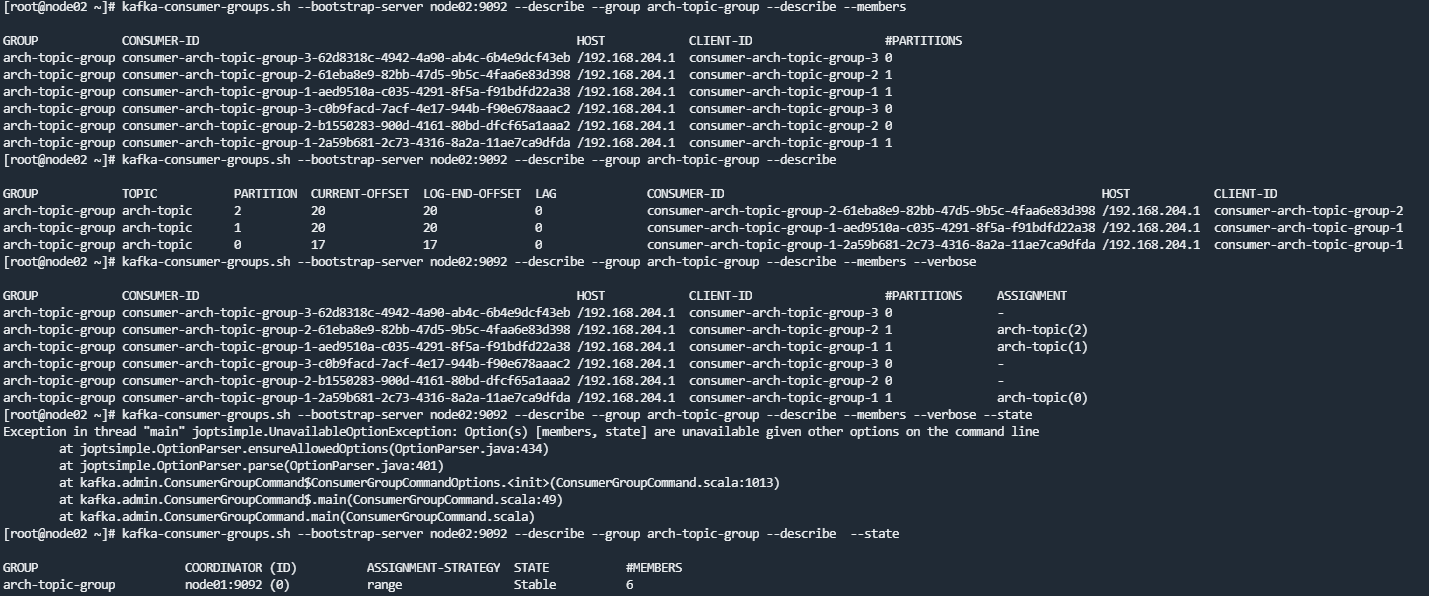
一个服务节点,启动三个消费者,concurrency设置为3,所以实际上是9个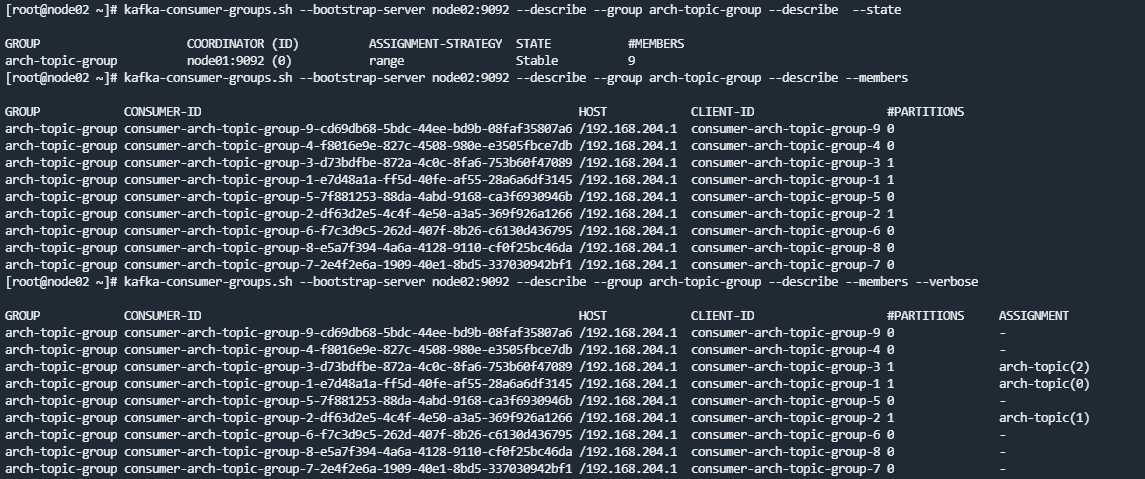
结论
client-id并不能唯一标识一个消费者,如果启动两个服务节点,就有重复的client-id出现,真正确定一个消费者的是consumer-id,由client-id+随机数生成
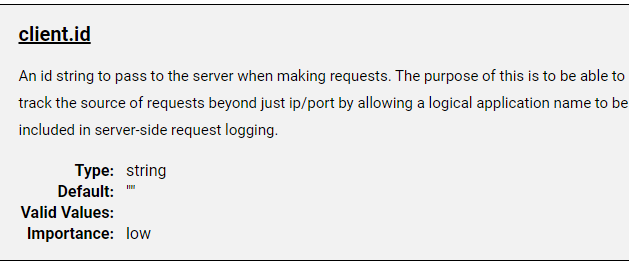
至于client-id的作用,官方给出的描述如下
An id string to pass to the server when making requests. The purpose of this is to be able to track the source of requests beyond just ip/port by allowing a logical application name to be included in server-side request logging.
发出请求时要传递给服务器的id字符串。这样做的目的是通过允许在服务器端请求日志中包含逻辑应用程序名称,能够跟踪不仅仅是ip/端口的请求源。
查看kafka的server.log文件发现确实是在日志中起到标识作用的实际上是consumer-id,而并不是client-id,而client-id相当于只是consumer-id的一部分,但是由于consumer-id对使用者来说是不可见的,用户能够配置的只是consumer-id的前缀,即client-id,所以官方的解释本质上来说并没有太大问题
但只有consumer-id才能确认唯一的一个消费者,client-id在多个spring-boot是会出现重复的,只有consumer-id(client-id+随机数)才能唯一确认一个消费者
 这里插入图片描述](https://img-blog.csdnimg.cn/895d84c9fa6d4caa86efb08b739a235a.png)
除此之外,在kafka协议相关也使用了client-id
抓包查看消费者相关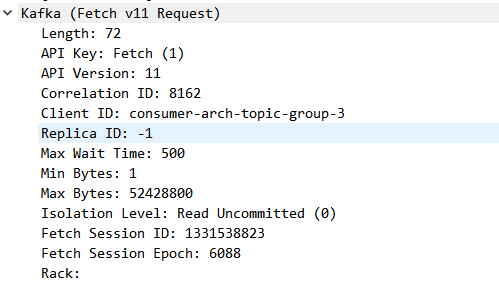
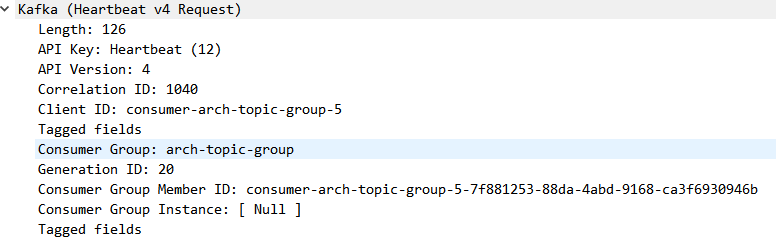
可以看到不仅有的client-id还有consumer-id,个人认为这个client只是个描述字段(非权威,勿喷),唯一确认请求的标志是correlation-id或是consumerid
欢迎关注我的公众号:映月空间
版权归原作者 TheFeasterfromAfar 所有, 如有侵权,请联系我们删除。