
1、Apache Spark有哪些常见的稳定版本,Spark1.6.0的数字分别代表什么意思?
常见的大的稳定版本有Spark 1.3,Spark1.6, Spark 2.0 ,Spark1.6.0的数字含义
第一个数字:1
- major version : 代表大版本更新,一般都会有一些 api 的变化,以及大的优化或是一些结构的改变;
第二个数字:6
- minor version : 代表小版本更新,一般会新加 api,或者是对当前的 api 就行优化,或者是其他内容的更新,比如说 WEB UI 的更新等等;
第三个数字:0
- patch version , 代表修复当前小版本存在的一些 bug,基本不会有任何 api 的改变和功能更新;记得有一个大神曾经说过,如果要切换 spark 版本的话,最好选 patch version 非 0 的版本,因为一般类似于 1.2.0, … 1.6.0 这样的版本是属于大更新的,有可能会有一些隐藏的 bug 或是不稳定性存在,所以最好选择 1.2.1, … 1.6.1 这样的版本。
spark在1.6之前使用的是Akka进行通信,1.6及以后是基于netty。
现阶段的Flink是基于Akka+Netty
2、Spark技术栈有哪些组件,每个组件都有什么功能,适合什么应用场景?
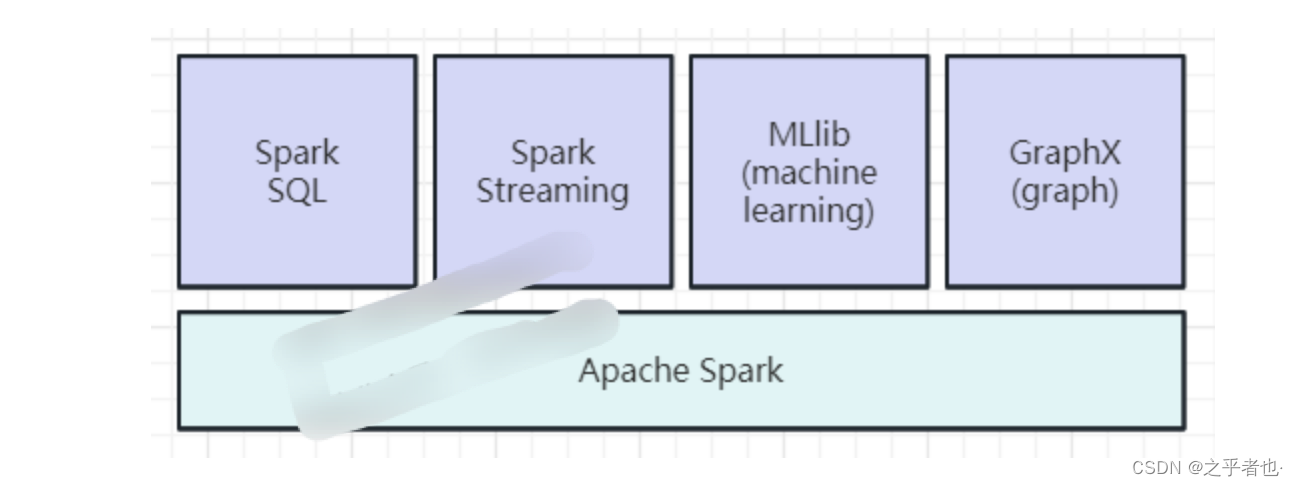
Spark 技术栈包含以下几个核心组件:
- Spark Core:Spark 的基础组件,提供了任务调度、内存管理和错误恢复等功能。它还定义了 RDD(Resilient Distributed Datasets)数据结构,用于在集群上进行分布式计算。
- Spark SQL:用于处理结构化数据的组件,支持使用 SQL 查询数据。它提供了 DataFrame 和 Dataset 两个 API,可以方便地进行数据处理和分析。适合处理大规模的结构化数据。
- Spark Streaming:用于实时数据处理的组件,可以将实时数据流划分为小批次进行处理。它支持各种数据源,如 Kafka、Flume 和 HDFS,并提供了窗口操作和状态管理等功能。适合实时数据分析和流式处理。
- Spark MLlib:用于机器学习的组件,提供了常见的机器学习算法和工具。它支持分类、回归、聚类和推荐等任务,并提供了特征提取、模型评估和模型调优等功能。适合大规模的机器学习任务。
- Spark GraphX:用于图计算的组件,提供了图结构的抽象和常见的图算法。它支持图的构建、遍历和计算,并提供了图分析和图挖掘等功能。适合社交网络分析和图计算任务。
- SparkR:用于在 R 语言中使用 Spark 的组件,提供了在 R 中进行分布式计算和数据处理的能力。它支持使用 R 语法进行数据操作,并提供了与 Spark SQL 和 MLlib 的集成。适合 R 语言用户进行大规模数据处理和分析。
这些组件可以根据具体的应用场景进行组合和使用,例如:
- 如果需要处理大规模的结构化数据,并进行复杂的数据分析和查询操作,可以使用 Spark SQL。
- 如果需要进行实时数据处理和流式计算,可以使用 Spark Streaming。
- 如果需要进行大规模的机器学习任务,可以使用 Spark MLlib。
- 如果需要进行图计算和图分析,可以使用 Spark GraphX。
- 如果需要在 R 语言中进行分布式计算和数据处理,可以使用 SparkR。
总的来说,Spark 技术栈提供了一套强大的工具和组件,可以满足不同场景下的大规模数据处理和分析需求。
3、Spark为什么比mapreduce快?为什么快呢? 快在哪里呢?
Spark计算比MapReduce快的根本原因在于DAG计算模型。一般而言,DAG相比Hadoop的MapReduce在大多数情况下可以减少shuffle次数
具体来说:
- Spark的DAGScheduler相当于一个改进版的MapReduce,如果计算不涉及与其他节点进行数据交换,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘IO的操作。但是,如果计算过程中涉及数据交换,Spark也是会把shuffle的数据写磁盘的!!!
- 有同学提到,Spark是基于内存的计算,所以快,这也不是主要原因,要对数据做计算,必然得加载到内存,Hadoop也是如此,只不过Spark支持将需要反复用到的数据给Cache到内存中,减少数据加载耗时,所以Spark跑机器学习算法比较在行(需要对数据进行反复迭代)。Spark基于磁盘的计算依然也是比Hadoop快。
- 刚刚提到了Spark的DAGScheduler是个改进版的MapReduce,所以Spark天生适合做批处理的任务。而不是某些同学说的:Hadoop更适合做批处理,Spark更适合做需要反复迭代的计算。
- Hadoop的MapReduce相比Spark真是没啥优势了。但是Hadoop的HDFS还是业界的大数据存储标准。
4、聊聊:Spark和MR的区别?
Spark vs MapReduce ≠ 内存 vs 磁盘
具体解答:
其实Spark和MapReduce的计算都发生在内存中,区别在于:
- MapReduce通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO。
- Spark则不需要将计算的中间结果写入磁盘,这得益于Spark的RDD(弹性分布式数据集,很强大)和DAG(有向无环图),其中DAG记录了job的stage以及在job执行过程中父RDD和子RDD之间的依赖关系。中间结果能够以RDD的形式存放在内存中,且能够从DAG中恢复,大大减少了磁盘IO。
5、Mapreduce和Spark的都是并行计算,那么他们有什么相同和区别
MapReduce和Spark都是用于并行计算的框架。
相同点:
- 并行计算:两者都支持将大规模的数据集划分为多个小任务,并在分布式环境中并行执行这些任务。
- 可扩展性:它们都可以在大规模集群上运行,通过添加更多的计算节点来扩展计算能力。
- 容错性:它们都具备故障恢复机制,能够处理计算节点的故障,并保证计算的正确性。
区别:
- 内存使用:MapReduce将中间数据写入磁盘,而Spark将中间数据存储在内存中,这使得Spark在某些情况下比MapReduce更快,尤其是对于迭代计算和交互式查询等需要多次读写数据的场景。
- 数据处理模型:MapReduce采用了经典的"map"和"reduce"操作模型,而Spark引入了更多的数据处理操作,如过滤、排序、连接等,使得编写数据处理逻辑更加灵活。
- 实时计算支持:Spark提供了实时流处理功能,可以对数据进行实时处理和分析,而MapReduce主要用于离线批处理。
- 编程接口:MapReduce使用Java编程接口,而Spark支持多种编程语言接口,包括Java、Scala、Python和R,使得开发者可以使用自己熟悉的语言进行开发。
总体而言,Spark相对于MapReduce来说更加灵活和高效,尤其适用于需要实时计算和复杂数据处理的场景。但对于一些传统的离线批处理任务,MapReduce仍然是一个可靠的选择。
6、Spark SQL为什么比hive快呢?
Spark SQL 相对于 Hive 具有以下几个方面的优势,使其在性能上更快:
- 内存计算:Spark SQL 使用内存计算作为其核心计算引擎,而 Hive 则是基于磁盘的计算模型。内存计算可以大大提高计算速度,因为内存的读写速度比磁盘快得多。
- 数据存储格式:Spark SQL 支持多种数据存储格式,如 Parquet、ORC 等,这些格式在压缩和列式存储方面具有优势。而 Hive 默认使用的存储格式是文本格式,对于大规模数据的查询和分析来说效率较低。
- 数据分区和索引:Spark SQL 具有更灵活的数据分区和索引机制,可以根据数据的特点进行自定义的分区和索引策略,从而提高查询性能。而 Hive 的分区和索引功能相对较为简单。
- 执行计划优化:Spark SQL 使用 Catalyst 优化器来生成更高效的执行计划,该优化器可以在查询执行之前对查询进行优化和重写。而 Hive 使用的是基于规则的优化器,优化能力相对较弱。
- 并行计算:Spark SQL 可以通过并行计算来加速查询和分析任务。Spark 的分布式计算框架可以将任务划分为多个并行的任务,在多个节点上同时执行,从而提高计算速度。而 Hive 的并行计算能力相对较弱。
需要注意的是,Spark SQL 适用于大规模数据分析和处理,特别是在需要实时计算和迭代计算的场景下表现出色。而 Hive 更适合于批处理和离线计算,特别是在大规模数据仓库中使用较多。
7、Spark为什么快,Spark SQL一定比Hive快吗
Spark为什么快? 主要答案:
- 消除了冗余的 HDFS 读写: Hadoop 每次 shuffle 操作后,必须写到磁盘,而 Spark 在 shuffle 后不一定落盘,可以 cache 到内存中,以便迭代时使用。如果操作复杂,很多的 shufle 操作,那么 Hadoop 的读写 IO 时间会大大增加,也是 Hive 更慢的主要原因了
- 消除了冗余的 MapReduce 阶段: Hadoop 的 shuffle 操作一定连着完整的 MapReduce 操作,冗余繁琐。而 Spark 基于 RDD 提供了丰富的算子操作,且 reduce 操作产生 shuffle 数据,可以缓存在内存中
- JVM 的优化: Hadoop 每次 MapReduce 操作,启动一个 Task 便会启动一次 JVM,基于进程的操作。而 Spark 每次 MapReduce 操作是基于线程的,只在启动 Executor 是启动一次 JVM,内存的 Task 操作是在线程复用的。每次启动 JVM 的时间可能就需要几秒甚至十几秒,那么当 Task 多了,这个时间 Hadoop 不知道比 Spark 慢了多少
极端反例:
Select month_id, sum(sales) from T group by month_id;
这个查询只有一次 shuffle 操作,此时,也许 Hive HQL 的运行时间也许比 Spark 还快,反正 shuffle 完了都会落一次盘,或者都不落盘
8、var、val、def三个关键字的区别?
- val:常量申明关键字
- var:变量声明关键字,类似于Java中的变量,变量值可更改,但是变量类型不能更改
- def:关键字,用于创建方法
var x = 3 // x是Int类型
x = 4 //
x = "error" // 类型变化,编译器报错'error: type mismatch'
val y = 3
y = 4 //常量值不可更改,报错 'error: reassignment to val'
def fun(name: String) = "Hey! My name is: " + name
fun("Scala") // "Hey! My name is: Scala"
//注意scala中函数式编程一切都是表达式
lazy val x = {
println("computing x")
3
}
val y = {
println("computing y")
10
}
x+x //
y+y // x 没有计算, 打印结果"computing y"
9、伴生类和伴生对象 有何区别?
伴生对象和伴生类:单例对象与类同名时,这个单例对象被称为这个类的伴生对象,而这个类被称之为这个单例对象的伴生类
伴生类和伴生对象要在同一个源文件中定义,伴生对象和伴生类可以互相访问其私有成员,不与伴生类同名的单例对象称之为孤立对象
1. 当在同一个文件中,有 class ScalaPerson 和 object ScalaPerson
2. class ScalaPerson 称为伴生类,将非静态的内容写到该类中
3. object ScalaPerson 称为伴生对象,将静态的内容写入到该对象(类)
10、case class是什么,与case object的区别是什么
case class:样例类,样例类用case关键字申明;样例类是为模式匹配而优化的类;
构造器中的每一个参数都成为val-除非被显式的申明为var;将自动生成toString、equals、hashCode 和 copy 方法11、描述一下你对RDD的理解
- 一组分片(Partition):数据集的基本组成单位,对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,若没有指定,则会采用默认值,即程序所分配到的CPU Core数
- 一个计算每个分区的函数:Spark中RDD的计算是以分片为单位的,每个RDD都会实现compite函数以达到这个目的。cpmpute函数会对迭代器进行复合,不需要保存每次计算的结果
- RDD之间的依赖关系:RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算
- 一个Partitioner:即RDD的分片函数。当前Apark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个时基于范围的RangePatititon。只有对于是key-value 的 RDD,才会有 Partitioner,非 key-value 的 RDD 的 Parititioner 的值是 None。Partitioner 函数不但决定了 RDD 本身的分片数量,也决定了 parent RDD Shuffle 输出时的分片数量
- 一个列表:存储存取每个 Partition 的优先位置(preferred location)。对于一个 HDFS 文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照“移动数据不如移动计算”的理念,Spark 在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置
11、描述以下算子的区别与联系:
一、groupByKey、reduceByKey、aggreageByKey
reduceByKey:可以在每个分区移动数据之前将输出数据与一个共用的
key
结合,适用于大数据集计算
groupByKey:所有的键值对(key-value pair) 都会被移动,在网络上传输这些数据非常没必要,因此避免使用 groupByKey
aggreageByKey:
二、cache、presist
都用于将RDD进行缓存
cache:只有一个默认的缓存级别MEMORY_ONLY
presist:persist有一个 StorageLevel 类型的参数,总共有12种缓存级别
三、repartition、coalesce
都是RDD的分区进行重新划分
repartition:repartition只是coalesce接口中shuffle为true的实现
coalesce:如果shuff为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的
四、map、flatMap
map:将函数用于RDD中的每个元素,将返回值构成新的RDD
flatMap:将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD
12、简述Spark中的缓存机制与checkpoint机制,说明两者的区别与联系
两者都是做RDD持久化的
RDD的缓存机制
RDD通过cache方法或者persist方法可以将前面的计算结果缓存,但并不是立即缓存,而是在接下来调用Action类的算子的时候,该RDD将会被缓存在计算节点的内存中,并供后面使用。它既不是transformation也不是action类的算子。
注意:缓存结束后,不会产生新的RDD
缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
使用缓存的条件:(或者说什么时候进行缓存)
- 要求的计算速度快,对效率要求高的时候
- 集群的资源要足够大,能容得下要被缓存的数据
- 被缓存的数据会多次的触发Action(多次调用Action类的算子)
- 先进行过滤,然后将缩小范围后的数据缓存到内存中
在使用完数据之后,要释放缓存,否则会一直在内存中占用资源
CheckPoint机制(容错机制)
RDD的缓存容错机制能保证数据丢失也能正常的运行,是因为在每一个RDD中,都存有上一个RDD的信息,当RDD丢失以后,可以追溯到元数据,再进行计算
检查点(本质是通过将RDD写入高可用的地方(例如 hdfs)做检查点)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销
设置checkpoint的目录,可以是本地的文件夹、也可以是HDFS。一般是在具有容错能力,高可靠的文件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据
在设置检查点之后,该RDD之前的有依赖关系的父RDD都会被销毁,下次调用的时候直接从检查点开始计算。 checkPoint和cache一样,都是通过调用一个Action类的算子才能运行
checkPoint减少运行时间的原因:第一次调用检查点的时候,会产生两个executor,两个进程分别是从hdfs读文件和计算(调用的Action类的算子),在第二次调用的时候会发现,运行的时间大大减少,是由于第二次调用算子的时候,不会再从hdfs读文件,而读取的是缓存到的数据,同样是从hdfs上读取
13、说说RDD、DataFrame、DataSet三者的区别与联系
一、RDD
RDD叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表了一个弹性的、不可变的、可分区、里面的元素可进行计算的集合
RDD封装了计算逻辑,并不保存数据;RDD是一个抽象类,需要子类具体实现;RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑;可分区、并行计算
二、DataFrame
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格
三、RDD与DataFrame的区别
两者均为懒执行
- DataFrame- 带有schema元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型,便于Spark SQL的操作- 支持嵌套数据类型(struct、array和Map),从易用性来说,DataFrame提供的是一套高层的关系操作,比函数式的RDD API更加友好- 因为优化的查询执行计划,导致DataFrame执行效率优于RDD
- RDD- 无法得到所存数据元素的具体结构,SparkCore只能在Stage层面进行简单、通用的流水线优化- 操作门槛高
四、DataSet
DataSet是分布式数据集,是DataFrame的一个扩展。提供了RDD的优势(强类型)以及Spark SQL优化执行引擎的优点
DataFrame是DataSet的特例:
DataFrame=DataSet[Row]
,
14、介绍Spark核心组件及功能
Spark是一个快速、通用的大数据处理框架,它提供了丰富的核心组件和功能,用于处理和分析大规模数据集。下面是Spark的核心组件及其功能的详细介绍:
- Spark Core:Spark的核心组件,提供了分布式任务调度、内存管理和错误恢复等基本功能。它还定义了RDD(弹性分布式数据集)的概念,RDD是Spark中的基本数据结构,用于表示可并行处理的数据集。
- Spark SQL:用于处理结构化数据的模块,支持SQL查询和DataFrame API。它可以将数据从多种数据源(如Hive、Avro、Parquet等)加载到Spark中,并提供了强大的查询优化和执行功能。
- Spark Streaming:用于实时数据流处理的模块,支持高吞吐量的数据流处理和复杂事件处理。它可以将实时数据流分成小批次,并在每个批次上应用批处理操作。
- MLlib:Spark的机器学习库,提供了常见的机器学习算法和工具,如分类、回归、聚类、推荐等。它支持分布式训练和推理,并提供了丰富的特征提取、转换和选择功能。
- GraphX:用于图计算的模块,支持图的创建、操作和分析。它提供了一组高级图算法和操作符,可以用于社交网络分析、推荐系统等领域。
- SparkR:用于在R语言中使用Spark的接口。它提供了与Spark Core和Spark SQL的集成,可以在R中使用Spark的分布式计算和数据处理功能。
除了以上核心组件,Spark还提供了一些其他功能和工具,如:
- Spark Streaming可以与Kafka、Flume等数据源集成,实现实时数据流处理。
- Spark可以与Hadoop、Hive、HBase等大数据生态系统中的其他工具和框架无缝集成。
- Spark提供了交互式Shell(spark-shell)和Web界面(Spark UI)等开发和监控工具。
- Spark支持在本地模式、独立模式和集群模式下运行,可以根据需求进行灵活部署和扩展。
总之,Spark的核心组件和功能使其成为处理和分析大规模数据的强大工具,可以满足各种数据处理和机器学习任务的需求。
15、说说Spark Yarn任务提交流程
一、Yarn Client模式
Client模式一般用于测试
- Driver在任务提交的本地机器上运行
- Driver启动后会向ResourceManager通讯申请启动ApplicationMaster
- ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,负责向ResourceManager申请Executor内存
- ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上驱动Executor进程
- Executor进程启动后会向Driver反向注册,Executor全部注册完成之后,Driver开始执行Main函数
- 之后执行到Action算子,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行
二、Yarn Cluster模式
- 任务提交后,Client会先和ResourceManager通讯,申请启动ApplicationMaster
- ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver
- Driver启动后会向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程
- Executor进程启动后会向Driver反向注册,Executor全部注册完成之后,Driver开始执行Main函数
- 之后执行到Action算子,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行
16、什么是迭代计算,迭代与循环的区别是什么?
迭代计算的基本思想是逐次逼近,先取一个粗糙的近似值,然后用同一个递推公式,反复校正此初值,直至达到预定精度要求为止;也可以说是将输出作为输入,再次进行处理。如KMeans对中心点的计算就是迭代
循环:是最基础的概念,凡是重复执行一段代码,都可以称之为循环
迭代:一定是循环,但循环不一定是迭代
17、MapReduce和Spark多是并行计算,区别是什么
两者都是使用 MapReduce 模型来进行并行计算的。
- Hadoop的一个作业称为job,job里面包含Map task和Reduce task(也有Map-Only的Task),每个task都在自己的进程中运行,当task结束时,进程也会结束
- Spark用户提交的任务称为Application,一个Application对应一个SparkContext。Application中可能存在多个job,一个Action操作产生一个job。这些job串行执行,每个job包含一个或多个Stage,Stage是DAGScheduler 通过RDD之间的依赖关系划分而来的。每个Stage里面有多个Task,这些Task被TaskScheduler 分发到 Executor 中执行,Executor的生命周期与Application是一样的,即使没有job运行也是存在的,Task可以快速启动读取数据进行计算
- Hadoop的job只有map和reduce操作,表达能力比较欠缺;而且job之间会重复的读写HDFS,造成大量的IO操作,多个job需要自己管理它们之间的关系
- Spark API提供了丰富的RDD操作,如join、groupBy等,并通过DAG图实现良好的容错
18、Spark算子可分为那两类,这两类算子的区别是什么,分别距离6个这两类算子,举例6个会产生Shuffle的算子
Spark的算子可以分为两类:Transformation、Action
- Transformation:从现有的数据集创建一个新的数据集,返回一个新的 RDD 操作。Transformation都是惰性的,它们并不会立刻执行,只是记住了这些应用到 RDD 上的转换动作
- Action:触发在 RDD 上的计算,这些计算可以是向应用程序返回结果,也可以是向存储系统保存数据
Transformation 最重要的特点:延迟执行、返回 RDD
Action最重要的特点:触发 Job ,返回的结果一定不是 RDD
- 常见的 Transformation 包括:map、mapVaules、filter、flatMap、mapPartitions、uoin、join、distinct、xxxByKey
- 常见的 Action 包括:count、collect、collectAsMap、first、reduce、fold、aggregate、saveAsTextFile有Shuffle的 Transformation 包括:
- 一堆的 xxxByKey(sortBykey、groupByKey、reduceByKey、foldByKey、aggrea geByKey、combineByKey)。备注:不包括countByKey
- join相关(join、leftOuterJoin、rightOuterJoin、fullOuterJoin、cogroup)
- distinct、intersection、subtract、partionBy、repartition
19、简述Spark中共享变量(广播变量和累加器)的基本原理和用途
通常情况下,一个传递给 RDD 操作(如map、reduceByKey)的 func 是在远程节点上执行的。函数 func 在多个节点执行过程中使用的变量,是Driver上同一个变量的多个副本。这些变量以副本的方式拷贝到每个task中,并且各task中变量的更新并不会返回 Driver
为了解决以上问题,Spark 提供了两种特定类型的共享变量 : 广播变量 和 累加器。广播变量主要用于高效分发较大的数据对象,累加器主要用于对信息进行聚合
广播变量的好处,不需要每个task带上一份变量副本,而是变成每个节点的executor才一份副本。这样的话, 就可以让变量产生的副本大大减少。而且 Spark 使用高效广播算法(BT协议)分发广播变量以降低通信成本
累加器是 Spark 中提供的一种分布式的变量机制,在Driver端进行初始化,task中对变量进行累加操作
广播变量典型的使用案例是Map Side Join;累加器经典的应用场景是用来在 Spark 应用中记录某些事件/信息的数量
20、说说Spark提交作业参数
提交作业时的重要参数:
- executor_cores 缺省值:1 in YARN mode, all the available cores on the worker in standalone and Mesos coarse-grained modes 生产环境中不宜设置为1!否则 work 进程中线程数过少,一般 2~5 为宜
- executor_memory 缺省值:1g 该参数与executor分配的core有关,分配的core越多 executor_memory 值就应该越大; core与memory的比值一般在 1:2 到 1:4 之间,即每个core可分配2~4G内存。如 executor_cores 为4,那么executor_memory 可以分配 8G ~ 16G; 单个Executor内存大小一般在 20G 左右(经验值),单个JVM内存太高易导致GC代价过高,或资源浪费
- executor_cores * num_executors 表示的是能够并行执行Task的数目。不宜太小或太大!理想情况下,一般给每个core分配 2-3 个task,由此可反推 num_executors 的个数
- driver-memorydriver 不做任何计算和存储,只是下发任务与yarn资源管理器和task交互,一般设为 1-2G 即可;增加每个executor的内存量,增加了内存量以后,对性能的提升,有三点:
- 如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘。减少了磁盘IO
- 对于shuffle操作,reduce端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。如果给executor分配更多内存,会减少磁盘的写入操作,进而提升性能
- task的执行,可能会创建很多对象。如果内存比较小,可能会频繁导致JVM堆内存满了,然后频繁GC,垃圾回收,minor GC和full GC。内存加大以后,带来更少的GC,垃圾回收,避免了速度变慢,性能提升;
21、Spark的宽窄依赖,以及Spark如何划分Stage,如何确定每个Stage中Task个数
RDD之间的依赖关系分为窄依赖(narrow dependency)和宽依赖(Wide Depencency,也称为Shuffle Depencency)
- 窄依赖:指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
- 宽依赖:是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)相比于依赖,窄依赖对优化很有利,主要基于以下几点:
- 宽依赖往往对应着Shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换
- 当RDD分区丢失时(某个节点故障),Spark会对数据进行重算
- 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的
- 对于宽依赖,重算的父RDD分区对应多个子RDD分区的,这样实际上父RDD中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其他未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,所有的父RDD分区都要进行重新计算
Stage:根据RDD之间的依赖关系将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
Task:Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task
22、如何理解Spark中Lineage
首先要明确一下 Spark 中 RDD 的容错机制。每一个 RDD 都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系( lineage ),所以只要输入数据是可容错的,那么任意一个 RDD 的分区( Partition )出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。如果一个分区出错了:
- 对于窄依赖,则只要把丢失的父 RDD 分区重算即可,不依赖于其他分区
- 对于宽依赖,则父 RDD 的所有分区都需要重算,代价昂贵
所以在长“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点
23、Scala类型系统中 Null、Nothing、Nil、None、Unit 的区别
在Scala类型系统中,Null、Nothing、Nil、None和Unit是不同的概念。
- Null:Null是一个特殊的类型,它只有一个值null。它是所有引用类型的子类型,表示一个空引用或缺失的值。Null主要用于与Java代码的互操作性。
- Nothing:Nothing是Scala类型系统中的底类型,它是所有类型的子类型。Nothing表示不可能的类型,它没有任何实例。在函数返回类型推断中,如果函数永远不会返回结果(比如抛出异常),那么可以将其返回类型标记为Nothing。
- Nil:Nil是一个空列表(List)的表示,它是
List[Nothing]的实例。在Scala中,List是一个不可变的链表,而Nil表示一个空的链表。 - None:None是Option类型的一个实例,它表示一个不存在的值或空值。Option是Scala中用于处理可能为空的值的容器类型,它可以包含一个值Some(x),或者不包含任何值None。当一个值可能为空时,可以使用Option来避免空指针异常。
- Unit:Unit表示没有返回值的函数或表达式的类型。类似于Java中的void类型,但在Scala中,Unit是一个真正的类型,它只有一个实例值(),表示没有意义的值或副作用。
总结一下:
- Null表示空引用或缺失的值。
- Nothing表示不可能的类型,用于表示不会有返回结果的函数。
- Nil表示空列表。
- None表示一个不存在的值或空值,常用于处理可能为空的值。
- Unit表示没有返回值的函数或表达式的类型。
24、说说你对Spark分区器的理解
Spark分区器是用于将数据集划分为多个分区的组件。分区器决定了数据在集群中的分布方式,对于数据处理和计算的效率具有重要影响。
Spark提供了多种分区器,其中常见的有哈希分区器(HashPartitioner)和范围分区器(RangePartitioner)。
哈希分区器根据键的哈希值将数据均匀地分布到不同的分区中。它适用于键的分布相对均匀的情况,可以保证相同键的数据被分配到同一个分区,从而方便后续的聚合操作。
范围分区器根据键的大小范围将数据划分到不同的分区中。它适用于键的分布有序的情况,可以保证相邻键的数据被划分到相邻的分区,从而提高了数据的局部性,有利于后续的数据处理操作。
除了这两种常见的分区器,Spark还提供了自定义分区器的接口,用户可以根据自己的需求实现自己的分区策略。
分区器的选择对于Spark作业的性能至关重要。一个合适的分区策略可以使得数据在集群中的负载均衡,减少数据的传输和重组开销,提高作业的并行度和执行效率。因此,在使用Spark时,需要根据数据的特点和作业的需求选择合适的分区器来优化作业的性能。
25、Spark Streaming 中有哪些消费Kafka数据的方式,它们之间的区别是什么
在Spark Streaming中,有两种主要的方式可以消费Kafka数据:直接方式(Direct Approach)和接收器方式(Receiver Approach)。
- 直接方式(Direct Approach):- 使用
createDirectStream方法从Kafka直接读取数据。- Spark Streaming会直接连接到Kafka的分区,每个Spark分区都会对应一个Kafka分区。- 消费者的偏移量由应用程序自己管理,通常与外部存储(如ZooKeeper)结合使用。- 可以实现端到端的一次性语义(Exactly-once semantics)。 - 接收器方式(Receiver Approach):- 使用
createStream方法创建一个接收器(Receiver)来接收Kafka数据。- 接收器是一个独立的线程,负责从Kafka主题中接收数据。- 接收到的数据会存储在Spark的内存中,并由Spark Streaming进行处理。- 消费者的偏移量由接收器自动管理,并定期保存到检查点(checkpoint)中。- 无法实现端到端的一次性语义,可能会有数据丢失或重复。
两种方式之间的区别主要在于数据的接收和处理方式,以及语义保证的能力。
直接方式具有更低的延迟和更高的吞吐量,因为它直接连接到Kafka分区,避免了接收器线程的开销。同时,直接方式可以实现端到端的一次性语义,确保数据的精确处理。
接收器方式相对简单,适用于较低的数据吞吐量和较高的延迟容忍度。它使用接收器线程将数据存储在Spark的内存中,并由Spark Streaming进行处理。但是,由于接收器的存在,可能会引入一些额外的延迟,并且无法提供端到端的一次性语义。
根据具体的需求和应用场景,可以选择适合的方式来消费Kafka数据。如果对延迟和一次性语义有较高的要求,直接方式是更好的选择;如果对延迟和一次性语义要求较低,接收器方式可能更简单方便。
26、说明yarn-cluster模式作业提交流程,yarn-cluster与yarn-client的区别
在Spark中,YARN是一种用于集群资源管理的框架,可以将Spark应用程序提交到YARN集群上进行执行。YARN提供了两种模式供Spark应用程序提交:yarn-cluster和yarn-client。
一、yarn-cluster模式作业提交流程:
- 当你在使用
spark-submit命令提交Spark应用程序时,指定了--deploy-mode cluster参数,即使用yarn-cluster模式。 - 提交命令发送给YARN的ResourceManager,ResourceManager会为应用程序分配一个ApplicationMaster。
- ApplicationMaster是一个专门负责管理应用程序执行的组件,它会向ResourceManager请求资源。
- ResourceManager会为ApplicationMaster分配一定数量的资源,这些资源将用于启动Executor。
- ApplicationMaster会与各个NodeManager通信,启动Executor,并将应用程序的代码和依赖文件分发到各个Executor所在的节点上。
- Executor会根据指定的任务分配策略执行具体的任务,任务的执行结果会返回给ApplicationMaster。
- ApplicationMaster会将任务的执行结果返回给Driver程序,Driver程序可以根据需要进行后续处理。
二、yarn-cluster与yarn-client的区别:
- yarn-cluster模式下,Driver程序运行在集群中的一个Executor上,并且Driver程序与ApplicationMaster是独立的进程。这意味着Driver程序的执行不会受到本地环境的限制,可以充分利用集群资源。
- yarn-client模式下,Driver程序运行在提交Spark应用程序的本地机器上,而不是集群中的一个Executor上。Driver程序与ApplicationMaster是同一个进程。这意味着Driver程序的执行受到本地环境的限制,例如可用的内存和CPU资源。
- 在yarn-cluster模式下,提交的应用程序可以在集群中长时间运行,即使与提交应用程序的客户端断开连接,应用程序仍然可以继续执行。而在yarn-client模式下,如果与客户端断开连接,应用程序会被终止。
- yarn-cluster模式适用于长时间运行的应用程序,例如批处理作业。yarn-client模式适用于交互式应用程序,例如Spark Shell。
总结:yarn-cluster模式下,Driver程序运行在集群中的一个Executor上,与ApplicationMaster是独立的进程;yarn-client模式下,Driver程序运行在本地机器上,与ApplicationMaster是同一个进程。
27、介绍一下Spark SQL解析过程
Spark SQL是Apache Spark中的一个模块,用于处理结构化数据。它提供了一个用于查询数据的统一编程接口,并支持SQL查询和DataFrame API。Spark SQL的解析过程包括以下几个步骤:
- 输入SQL查询或DataFrame操作:用户可以使用SQL语句或DataFrame操作来描述他们想要执行的查询或转换操作。
- 解析器(Parser):Spark SQL首先使用解析器将输入的SQL查询或DataFrame操作转换为逻辑计划。解析器负责将输入的查询语句或操作转换为一个抽象语法树(AST)表示。
- 语义分析器(Semantic Analyzer):在解析完成后,Spark SQL使用语义分析器对AST进行处理。语义分析器负责验证查询语句的语法和语义的正确性,包括检查表和列的存在性、解析函数和表达式,并进行类型检查等。
- 逻辑优化器(Logical Optimizer):在语义分析完成后,Spark SQL使用逻辑优化器对逻辑计划进行优化。逻辑优化器通过应用一系列的规则和转换来优化查询计划,以提高查询性能。例如,它可以进行谓词下推、投影消除、常量折叠等优化操作。
- 物理优化器(Physical Optimizer):在逻辑优化完成后,Spark SQL使用物理优化器对逻辑计划进行进一步的优化。物理优化器负责将逻辑计划转换为物理执行计划,选择最优的物理算子和执行策略。它考虑了数据的分布、数据大小、可用的计算资源等因素来选择最佳的执行计划。
- 代码生成器(Code Generator):在物理优化完成后,Spark SQL使用代码生成器将优化后的物理执行计划转换为可执行的Java字节码。代码生成器负责生成高效的执行代码,以提高查询的执行速度。
- 执行器(Executor):最后,Spark SQL将生成的Java字节码交给执行器执行。执行器负责将查询计划分解为一系列的任务,并在集群上执行这些任务。执行器还负责处理数据的读取、计算和输出等操作,以完成整个查询过程。
总结起来,Spark SQL的解析过程包括解析、语义分析、逻辑优化、物理优化、代码生成和执行等阶段。这些阶段的目标是将用户输入的查询或操作转换为高效的执行计划,并在集群上执行这些计划来处理结构化数据。
28、说说Spark的动态资源分配
对于Spark应用来说,资源是影响Spark应用执行效率的一个重要因素。当一个长期运行的服务,若分配给它多个Executor,可是却没有任何任务分配给它,而此时有其他的应用却资源紧张,这就造成了很大的资源浪费和资源不合理的调度。
一、Spark的资源分配
Spark的资源分配主要包括以下几个方面:
- 初始分配:当一个应用程序提交到Spark集群时,Spark会根据应用程序的配置和集群的可用资源进行初始资源分配。初始分配可以根据应用程序的需求来分配一定数量的Executor和内存资源。
- 动态分配:在应用程序运行过程中,Spark可以根据应用程序的负载情况动态分配资源。它可以根据任务的需求来增加或减少Executor的数量,并可以根据任务的内存需求来调整每个Executor的内存分配。
- 任务调度:Spark的任务调度器负责将任务分配给可用的Executor。在动态资源分配的情况下,任务调度器可以根据Executor的可用性和负载情况来选择最合适的Executor执行任务。它可以将任务分配给负载较轻的Executor,以提高任务的执行效率。
- 资源回收:当应用程序运行结束或者资源不再需要时,Spark会回收已经分配的资源。它会释放Executor和内存资源,并将它们返回给集群的资源池,以供其他应用程序使用。
- 动态调整策略:Spark提供了多种动态资源调整策略,可以根据应用程序的需求选择合适的策略。例如,可以基于任务的等待时间、任务的执行时间、内存的使用情况等来进行资源的调整。
动态资源调度就是根据当前应用任务的负载情况,实时的增减Executor个数,从而实现动态分配资源,使整个Spark系统更加健康。
在应用程序运行过程中,Spark可以根据应用程序的负载情况动态分配资源。它可以根据任务的需求来增加或减少Executor的数量,并可以根据任务的内存需求来调整每个Executor的内存分配
通过动态资源分配,Spark可以根据应用程序的需求来灵活分配和管理集群资源,以提高集群的利用率和应用程序的性能。它可以自动适应应用程序的负载变化,并根据需要增加或减少资源的分配,从而更好地满足应用程序的需求。
二、动态资源策略
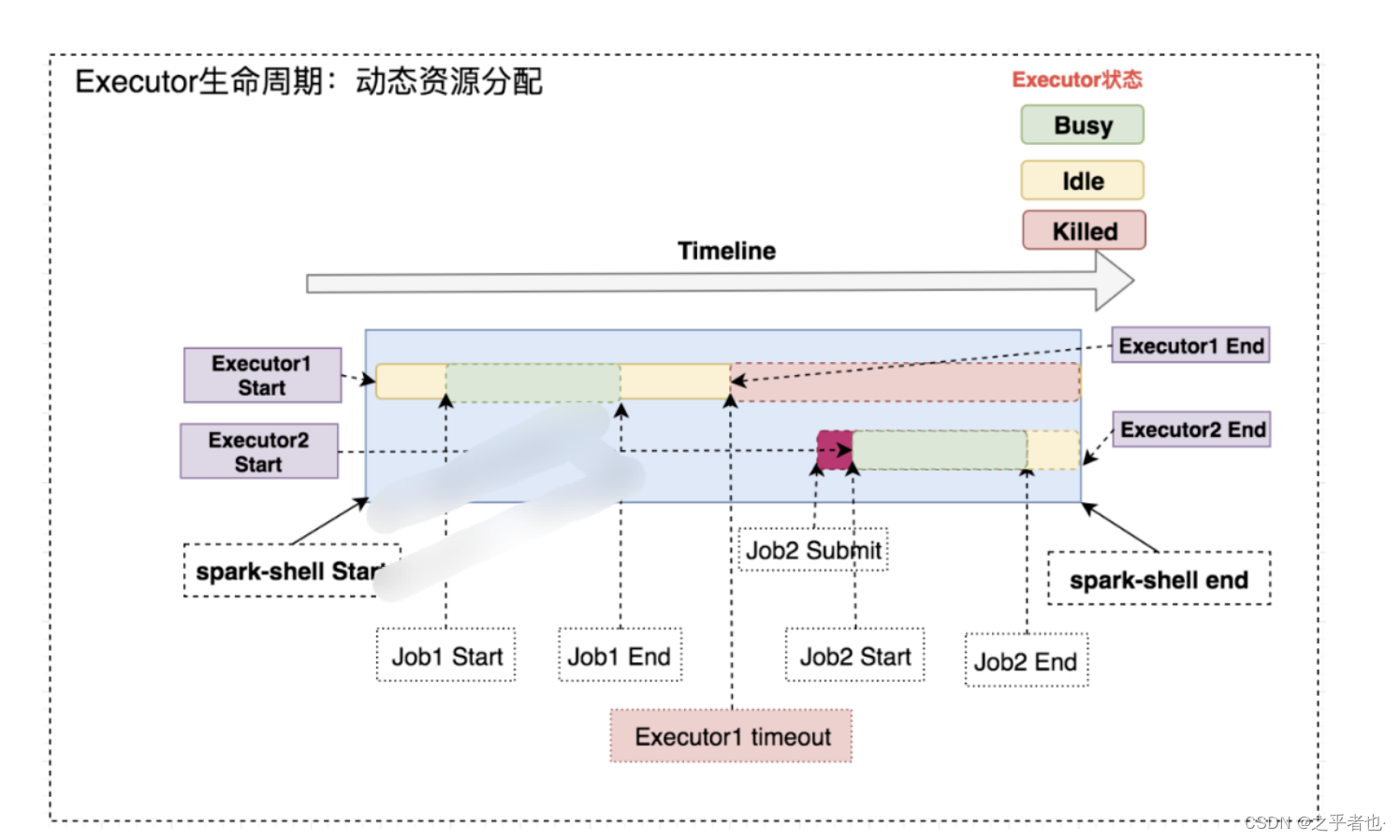
1.资源分配策略
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待
spark.dynamicAllocation.schedulerBacklogTimeout
(默认1s)时间的时候,会开始动态资源分配;之后会每隔
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout
(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。 之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
2.资源回收策略
当application的executor空闲时间超过
spark.dynamicAllocation.executorIdleTimeout(默认60s)
后,就会被回收。
三、动态资源操作步骤
1.yarn的配置
首先需要对YARN进行配置,使其支持Spark的Shuffle Service。
修改每台集群上的yarn-site.xml:
- 修改
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
- 增加
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
将
$SPARKHOME/lib/spark-X.X.X-yarn-shuffle.jar
拷贝到每台NodeManager的
${HADOOPHOME}/share/hadoop/yarn/lib/
下, 重启所有修改配置的节点。
2.Spark的配置
配置
$SPARK_HOME/conf/spark-defaults.conf
,增加以下参数:
spark.shuffle.service.enabled true //启用External shuffle Service服务
spark.shuffle.service.port 7337 //Shuffle Service默认服务端口,必须和yarn-site中的一致
spark.dynamicAllocation.enabled true //开启动态资源分配
spark.dynamicAllocation.minExecutors 1 //每个Application最小分配的executor数
spark.dynamicAllocation.maxExecutors 30 //每个Application最大并发分配的executor数
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
四、动态分配资源启动
使用spark-sql On Yarn执行SQL,动态分配资源。
以yarn-client模式启动ThriftServer:
cd $SPARK_HOME/sbin/
./start-thriftserver.sh \
--master yarn-client \
--conf spark.driver.memory=10G \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.minExecutors=1 \
--conf spark.dynamicAllocation.maxExecutors=300 \
--conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
启动后,ThriftServer会在Yarn上作为一个长服务来运行。
29、简要介绍下Spark的内存管理
与数据频繁落盘的
Mapreduce
引擎不同,Spark是基于
内存
的分布式计算引擎,其内置强大的内存管理机制,保证数据
优先内存
处理,并支持数据磁盘存储。Spark的内存管理是其高效执行任务的关键之一。
Spark通过将内存分为不同的区域来管理内存,包括堆内存、堆外内存和执行内存。
- 堆内存(Heap Memory):Spark使用堆内存来存储对象实例和执行引擎的元数据。堆内存的大小可以通过配置参数
spark.executor.memory来设置。堆内存主要用于存储RDD分区数据、Shuffle数据、用户代码和其他元数据。 - 堆外内存(Off-Heap Memory):堆外内存是指分配在JVM堆之外的内存空间。Spark使用堆外内存来存储较大的数据结构,如广播变量和缓存的RDD分区。通过使用堆外内存,Spark可以减少垃圾回收的开销,并提高内存利用率。
- 执行内存(Execution Memory):执行内存是Spark用于执行任务的内存池。它主要用于存储任务执行期间的数据和计算结果。执行内存的大小可以通过配置参数
spark.executor.memoryOverhead来设置。执行内存被划分为两个部分:用于存储数据的存储内存和用于计算的堆外内存。
在任务执行期间,Spark将数据存储在执行内存中进行计算。当执行内存不足时,Spark会根据一定的策略将数据溢出到磁盘上的临时文件中,以释放内存空间。这个过程称为内存溢出(spill)。溢出的数据可以在需要时重新加载到内存中进行计算。
Spark还提供了一种动态内存管理机制,称为动态分配(Dynamic Allocation)。动态分配允许Spark根据任务的需求自动调整执行内存的大小。它可以根据当前任务的资源需求动态分配和回收执行内存,以提高集群资源的利用率。
总的来说,Spark的内存管理通过合理划分不同的内存区域,并提供动态分配机制,以最大化内存的利用和任务执行的效率。这使得Spark能够处理大规模的数据集并进行高效的计算。
一、Spark内存概述
首先简单的介绍一下Spark运行的基本流程。
- 用户在
Driver端提交任务,初始化运行环境(SparkContext等) - Driver根据配置向
ResoureManager申请资源(executors及内存资源) - ResoureManager资源管理器选择合适的
worker节点创建executor进程 Executor向Driver注册,并等待其分配task任务- Driver端完成
SparkContext初始化,创建DAG,分配taskset到Executor上执行。 - Executor启动线程执行task任务,返回结果。
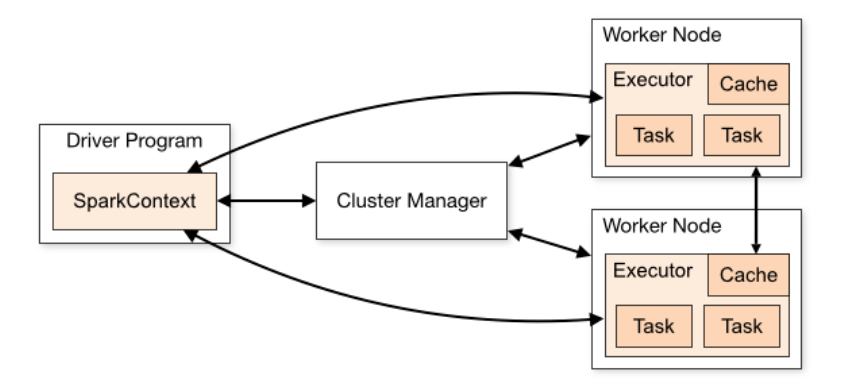
img
Spark在任务运行过程中,会启动
Driver
和
Executor
两个进程。其中Driver进程除了作为Spark提交任务的执行节点外,还负责申请Executor资源、注册Executor和提交Task等,完成整个任务的协调调度工作。而Executor进程负责在工作节点上执行具体的
task
任务,并与Driver保持通信,返回结果。
由上可见,Spark的数据计算主要在
Executor
进程内完成,而Executor对于RDD的
持久化
存储以及
Shuffle
运行过程,均在Spark内存管理机制下统一进行,其内运行的task任务也
共享
Executor内存,因此本文主要围绕Executor的内存管理进行展开描述。
Spark内存分为
堆内内存
(On-heap Memory)和
堆外内存
(Off-heap Memory)。其中堆内内存基于
JVM内存
模型,而堆外内存则通过调用底层
JDK Unsafe API
。两种内存类型统一由Spark内存管理模块接口实现。
def acquireStorageMemory(...): Boolean //申请存储内存
def acquireExecutionMemory(...): Long //申请执行内存
def releaseStorageMemory(...): Unit //释放执行内存
def releaseStorageMemory(...): Unit //释放存储内存
1.1 Spark的堆内内存
Executo作为一个
JVM
进程,其内部基于JVM的内存管理模型。
Spark在其之上封装了统一的内存管理接口
MemoryManager
,通过对JVM堆空间进行合理的规划(逻辑上),完成对象实例内存空间的
申请
和
释放
。保证满足Spark运行机制的前提下,最大化利用内存空间。
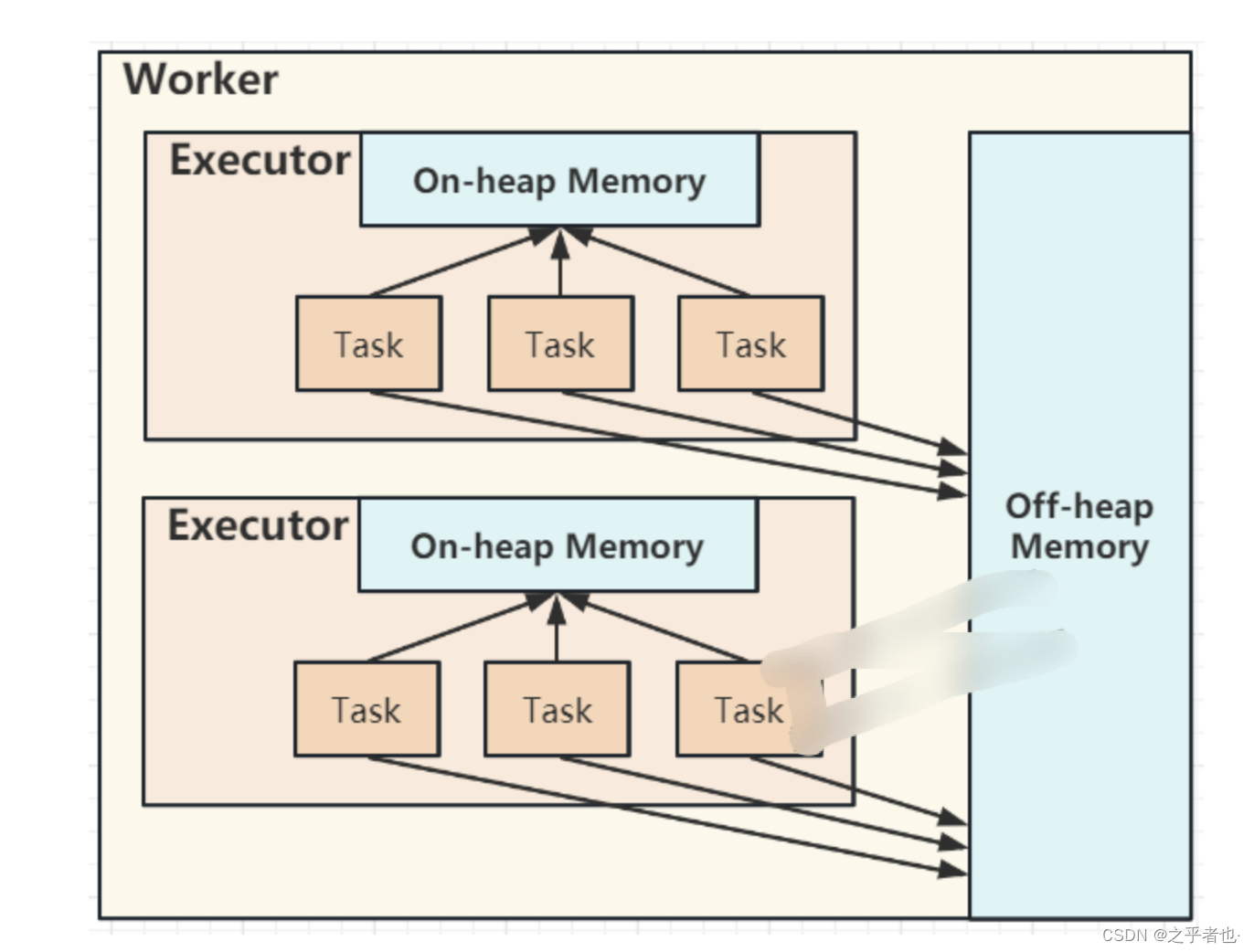
这里涉及到的
JVM堆空间概念,简单描述就是在程序中,关于对象实例|数组的
创建、
使用和
释放的内存,都会在JVM中的一块被称作为"JVM堆"内存区域内进行管理分配。
Spark程序在创建对象后,JVM会在堆内内存中
分配一定大小的空间,创建
Class对象并返回对象引用,Spark保存对象引用,同时记录占用的内存信息。
Spark中堆内内存参数有:
-executor-memory
或
-spark-executor-memory
。通常是任务提交时在参数中进行定义,且与
-executor-cores
等相关配置一起被提交至ResourceManager中进行Executor的资源申请。
在Worker节点创建一定数目的Executor,每个Executor被分配
-executor-memory大小的堆内内存。Executor的堆内内存被所有的Task线程任务共享,多线程在内存中进行数据交换。
Spark堆内内存主要分为
Storage
(存储内存)、
Execution
(执行内存)和
Other
(其他) 几部分。
- Storage用于缓存RDD数据和broadcast广播变量的内存使用
- Execution仅提供shuffle过程的内存使用
- Other提供Spark内部对象、用户自定义对象的内存空间
Spark支持多种内存管理模式,在不同的管理模式下,以上堆内内存划分区域的占比会有所不同,具体详情会在第2章节进行描述。
1.2 Spark的堆外内存
Spark
1.6
在堆内内存的基础上引入了堆外内存,进一步优化了Spark内存的使用率。
其实如果你有过Java相关编程经历的话,相信对堆外内存的使用并不陌生。其底层调用
基于C的JDK Unsafe类方法,通过
指针直接进行内存的操作,包括内存空间的申请、使用、删除释放等。
Spark在2.x之后,摒弃了之前版本的
Tachyon
,采用Java中常见的基于
JDK Unsafe API
来对堆外内存进行管理。此模式不在JVM中申请内存,而是直接操作系统内存,减少了JVM中内存
空间切换
的开销,降低了
GC回收
占用的消耗,实现对内存的精确管控。
堆外内存默认情况下是不开启的,需要在配置中将
spark.memory.offHeap.enabled
设为True,同时配置
spark.memory.offHeap.size
参数设置堆大小。
对于堆外内存的划分,仅包含Execution(执行内存)和Storage(存储内存)两块区域,且被所有task线程任务共享。
二、Spark内存管理机制
前文说到,不同模式下的Spark堆内、堆外内存区域划分占比是不同的。
在Spark1.6之前,Spark采用的是
静态管理
(Static Memory Manager)模式,Execution内存和Storage内存的分配占比全部是
静态
的,其值为系统预先设置的默认参数。
在Spark1.6后,为了考虑内存管理的动态灵活性,Spark的内存管理改为
统一管理
(Unified Memory Manager)模式,支持Storage和Execution内存
动态占用
。至于静态管理方式任然被保留,可通过
spark.memory.useLegacyMode
参数启用。
2.1 静态内存管理(Static Memory Manager)
Spark最原始的内存管理模式,默认通过系统固定的内存配置参数,分配相应的Storage、Execution等内存空间,支持用户自定义修改配置。
1) 堆内内存分配
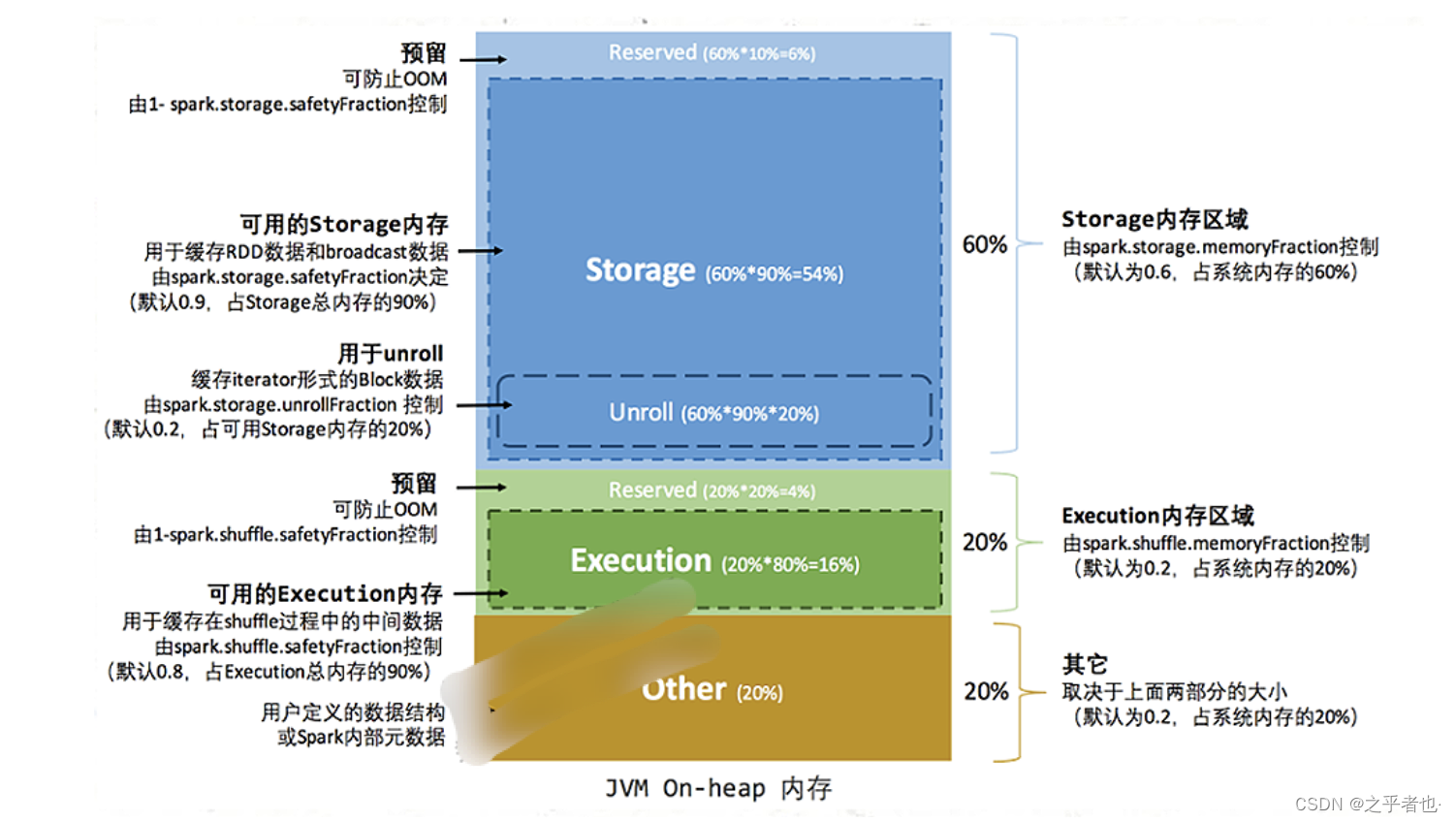
堆内内存空间整体被分为
Storage
(存储内存)、
Execution
(执行内存)、
Other
(其他内存)三部分,默认按照
6:2:2
的比率划分。其中Storage内存区域参数:
spark.storage.memoryFraction
(默认为0.6),Execution内存区域参数:
spark.shuffle.memoryFraction
(默认为0.2)。Other内存区域主要用来存储用户定义的数据结构、Spark内部元数据,占系统内存的20%。
在Storage内存区域中,10%的大小被用作
Reserved
预留空间,防止内存溢出情况,由参数:
spark.shuffle.safetyFraction
(默认0.1)控制。90%的空间当作可用的Storage内存,这里是Executor进行RDD数据缓存和broadcast数据的内存区域,参数和Reserved一致。还有一部分
Unroll
区域,这一块主要存储Unroll过程的数据,占用20%的可用Storage空间。
Unroll过程: RDD在缓存到内存之前,
partition中record对象实例在堆内other内存区域中的
不连续空间中存储。RDD的缓存过程中, 不连续存储空间内的partition被转换为
连续存储空间的Block对象,并在Storage内存区域存储,此过程被称作为Unroll(展开)。
Execution内存区域中,20%的大小被用作Reserved预留空间,防止OOM和其他内存不够的情况,由参数:
spark.shuffle.safetyFraction
(默认0.2)控制。80%的空间当作可用的Execution内存,缓存shuffle过程的中间数据,参数:
spark.shuffle.safetyFraction
(默认0.8)。
计算公式
可用的存储内存 =
systemMaxMemory
* spark.storage.memoryFraction
* spark.storage.safetyFraction
可用的执行内存 =
systemMaxMemory
* spark.shuffle.memoryFraction
* spark.shuffle.safetyFraction
2) 堆外内存
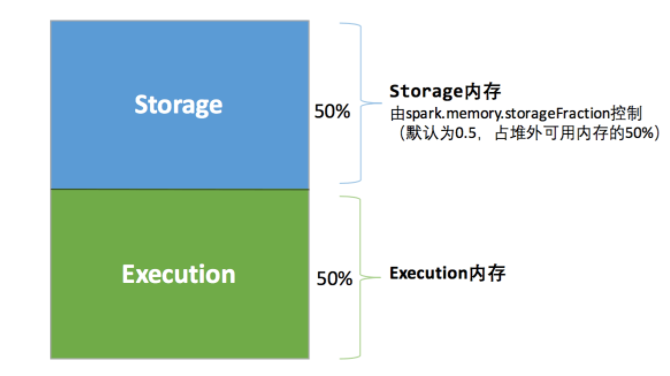
相较于堆内内存,堆外内存的分配较为简单。堆外内存默认为
384M
,由系统参数
spark.yarn.executor.memoryOverhead
设定。整体内存分为Storage和Execution两部分,此部分分配和堆内内存一致,由参数:
spark.memory.storageFaction
决定。堆外内存一般存储序列化后的二进制数据(字节流),在存储空间中是一段连续的内存区域,其大小可精确计算,故此时无需设置预留空间。
3) 总结
- 实现机制简单,易理解
- 容易出现内存失衡的问题,即Storage、Execution一方内存过剩,一方内容不足
- 需要开发人员充分了解存储机制,调优不便
更多细节讨论,欢迎添加我的个人微信:
youlong525
2.2 统一内存管理(Unified Memory Manager)
为了解决(Static Memory Manager)静态内存管理的
内存失衡
等问题,Spark在1.6之后使用了一种新的内存管理模式—Unified Memory Manager(统一内存管理)。在新模式下,移除了旧模式下的Executor内存静态占比分配,启用了
内存动态占比机制
,并将Storage和Execution划分为统一共享内存区域。
1) 堆内内存

堆内内存整体划分为
Usable Memory
(可用内存)和
Reversed Memory
(预留内存)两大部分。其中预留内存作为OOM等异常情况的内存使用区域,默认被分配300M的空间。可用内存可进一步分为(Unified Memory)统一内存和Other内存其他两部分,默认占比为6:4。
统一内存中的Storage(存储内存)和Execution(执行内存)以及Other内存,其参数及使用范围均与静态内存模式一致,不再重复赘述。只是此时的Storage、Execution之间启用了
动态内存占用
机制。
动态内存占用机制
- 设置内存的初始值,即Execution和Storage均需设定各自的内存区域范围(默认参数0.5)
- 若存在一方内存不足,另一方内存空余时,可占用对方内存空间
- 双方内存均不足时,需落盘处理
- Execution内存被占用时,Storage需将此部分转存硬盘并归还空间
- Storage内存被占用时,Execution无需归还
2) 堆外内存
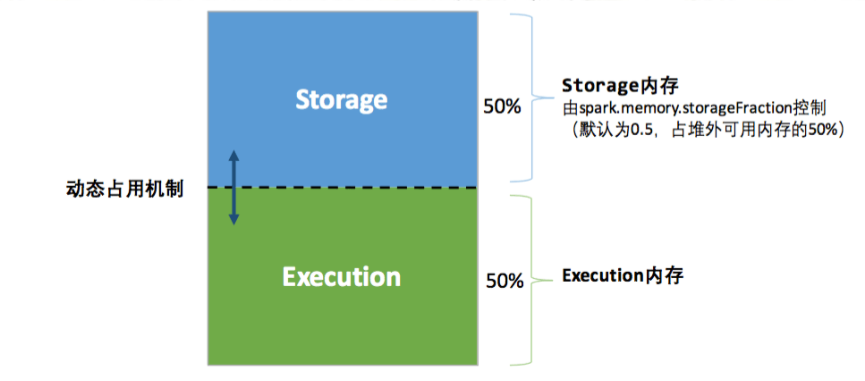
和静态管理模式分配一致,堆外内存默认值为384M。整体分为Storage和Execution两部分,且启用
动态内存占用
机制,其中默认的初始化占比值均为0.5。
计算公式
可用的存储&执行内存 =
(systemMaxMemory -ReservedMemory)
* spark.memoryFraction
* spark.storage.storageFraction
(启用内存动态分配机制,己方内存不足时可占用对方)
3) 总结
- 动态内存占比,提升内存的合理利用率
- 统一管理Storage和Execution内存,便于调优和维护
- 由于Execution占用Storage内存可不规划,存在Storage内存不够频繁GC的情况
三、Spark On Yarn模式的内存分配
由于Spark内存管理机制的健全,Executor能够高效的处理节点中RDD的内存运算和数据流转。而作为分配Executor内存的资源管理器Yarn,如何在过程中保证内存的最合理化分配,也是一个值得关注的问题。
首先看下Spark On Yarn的基本流程:
- Spark
Driver端提交程序,并向Yarn申请Application - Yarn接受请求响应,在NodeManager节点上创建AppMaster
- AppMaster`向Yarn ResourceManager申请资源(Container)
- 选择合适的节点创建
Container(Executor进程) - 后续的Driver启动调度,运行任务
Yarn Client、Yarn Cluster模式在某些环节会有差异,但是基本流程类似。其中在整个过程中的涉及到的内存配置如下(源码默认配置):
var executorMemory = 1024
val MEMORY_OVERHEAD_FACTOR = 0.10
val MEMORY_OVERHEAD_MIN = 384
// Executo堆外内存
val executorMemoryOverhead =
sparkConf.getInt("spark.yarn.executor
.memoryOverhead",
math.max((MEMORY_OVERHEAD_FACTOR
* executorMemory).toInt
, MEMORY_OVERHEAD_MIN))
// Executor总分配内存
val executorMem= args.executorMemory
+ executorMemoryOverhead
因此假设当我们提交一个spark程序时,如果设置
-executor-memory
=5g。
spark-submit
--master yarn-cluster
--name test
--executor-memory 5g
--driver-memory 5g
根据源码中的计算公式可得:
memoryMem= args.executorMemory(5120) + executorMemoryOverhead(512) = 5632M
然而事实上查看
Yarn UI
上的内存却不是这个数值?这是因为Yarn默认开启了
资源规整化
。
1) Yarn的资源规整化
Yarn会根据最小可申请资源数、最大可申请资源数和规整化因子综合判断当前申请的资源数,从而合理规整化应用程序资源。
- 定义
程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值
公式: ceil(a/b)*b
(a是程序申请资源,b为规整化因子)
- 相关配置
yarn.scheduler.minimum-allocation-mb:
最小可申请内存量,默认是1024
yarn.scheduler.minimum-allocation-vcores:
最小可申请CPU数,默认是1
yarn.scheduler.maximum-allocation-mb:
最大可申请内存量,默认是8096
yarn.scheduler.maximum-allocation-vcores:
最大可申请CPU数,默认是4
回到前面的内存计算:由于memoryMem计算完的值为
5632
,不是规整因子(1024)的整数倍,因此需要重新计算:
memoryMem = ceil(5632/1024) * 1024=6144M
2) Yarn模式的Driver内存分配差异
Yarn Client 和 Cluster 两种方式提交,Executor和Driver的内存分配情况也是不同的。Yarn中的ApplicationMaster都启用一个
Container
来运行;
Client模式下的Container默认有
1G
内存,1个cpu核,Cluster模式的配置则由
driver-memory
和
driver-cpu
来指定,也就是说Client模式下的driver是默认的内存值;Cluster模式下的dirver则是自定义的配置。
- cluster模式(driver-memory:5g): ceil(a/b)*b可得driver内存为6144M
- client模式(driver-memory:5g): ceil(a/b)*b可得driver内存为5120M
3) 总结
Apache Yarn作为分布式资源管理器,有自己内存管理优化机制。当在Yarn部署Spark程序时,需要同时考虑两者的内存处理机制,这是生产应用中最容易忽视的一个知识点。
30、说说对Spark Shuffle的理解
Spark中的Shuffle是指在数据重分区(Data Redistribution)的过程中,将数据从一个或多个输入分区重新分布到新的输出分区的操作。Shuffle是Spark中一种非常重要的操作,它在许多转换操作(如groupByKey、reduceByKey和join等)中都会被使用到。
Shuffle的原理可以分为三个主要步骤:Map阶段、Shuffle阶段和Reduce阶段。
- Map阶段:- 在Map阶段,Spark将输入数据按照指定的键(key)进行分组,形成多个(key, value)对。每个(key, value)对被称为一个记录(record)。- 每个记录被分配到对应的分区(Partition),分区的数量可以通过配置参数
spark.sql.shuffle.partitions进行设置,默认为200个分区。分区的数量决定了并行度和任务的负载均衡。 - Shuffle阶段:- 在Shuffle阶段,Spark会将每个分区的数据按照键(key)进行排序,并将相同键的记录聚合在一起,形成多个(key, list of values)对。这个过程称为排序和聚合(Sort and Aggregation)。- 排序和聚合的目的是将相同键的记录放在同一个分区中,以便后续的Reduce阶段可以更高效地进行计算。
- Reduce阶段:- 在Reduce阶段,Spark将每个(key, list of values)对分发给不同的Executor节点上的Reduce任务进行处理。- Reduce任务会对每个键(key)对应的值列表进行迭代,并对值进行合并、计算或聚合等操作,生成最终的结果。
Shuffle过程中的数据传输是通过网络进行的,因此Shuffle的性能对Spark的性能影响很大。为了提高Shuffle的性能,Spark引入了多种优化技术,包括:
- 压缩:可以使用压缩算法对Shuffle数据进行压缩,减少网络传输的数据量。
- 聚合缓冲区(Aggregation Buffer):在Shuffle阶段,可以使用聚合缓冲区对相同键的记录进行缓存,减少网络传输和磁盘读写的次数。
- 基于Sort的Merge:在Reduce阶段,可以使用基于Sort的Merge算法对具有相同键的记录进行合并,减少计算的次数。
通过合理配置Shuffle相关的参数,使用适当的优化技术,可以提高Shuffle的性能,从而提升Spark应用程序的整体性能和可扩展性。
一、Shuffle图解
Shuffle 就是对数据进行重组,是把一组无规则的数据尽量转换成一组具有一定规则的数 据。由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂。
在 MapReduce 框架,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Map 阶段通过 shuffle 读取 数据并输出到对应的 Reduce。而 Reduce 阶段负责从 Map 端拉取数据并进行计算。在整个 shuffle 过程中,往往伴随着大量的磁盘和网络 I/O。所以 shuffle 性能的高低也直接决定 了整个程序的性能高低。下图为 Hadoop Shuffle 过程。

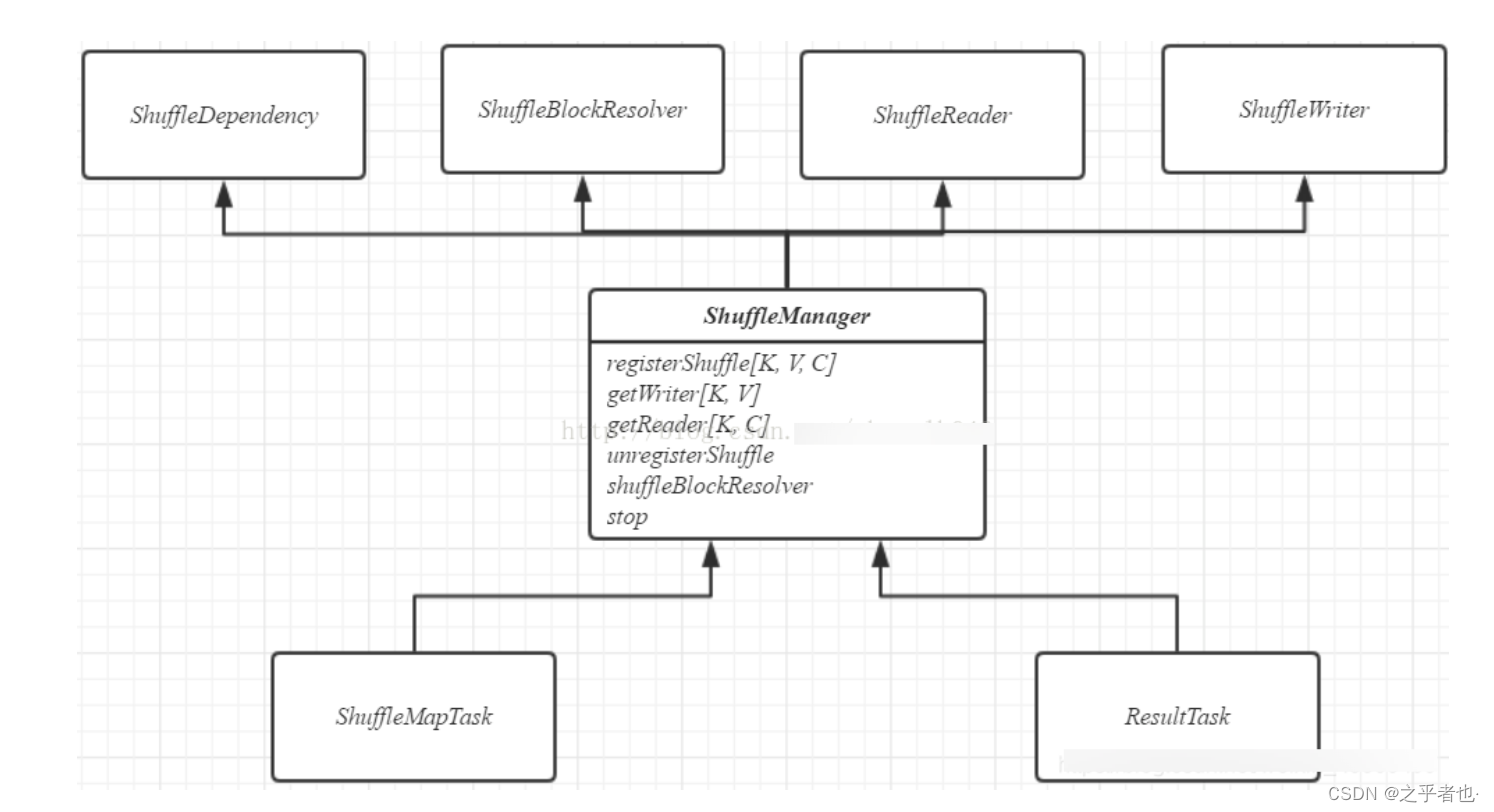
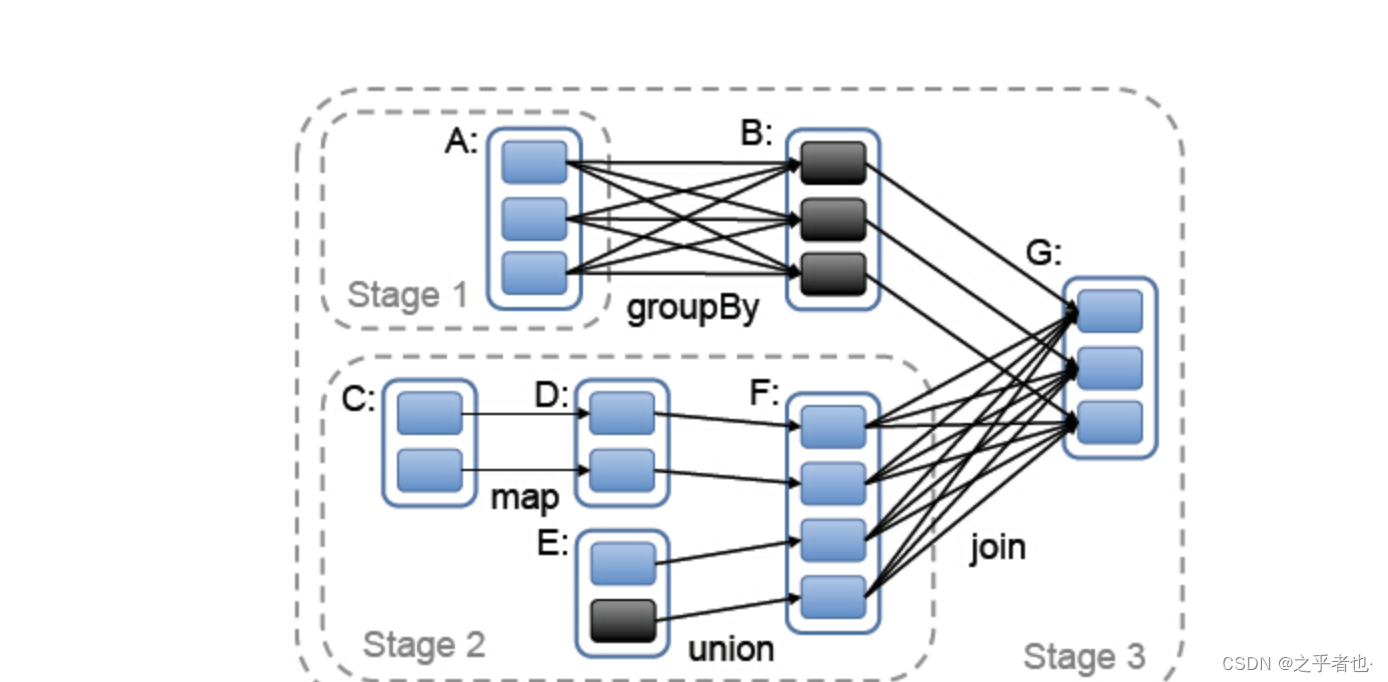
Spark 也有自己的 shuffle 实现过程。在 DAG 调度的过程中,Stage 阶段的划分是根据是否 有 shuffle 过程,也就是存在 ShuffleDependency 宽依赖的时候,需要进行 shuffle。 并且在划分 Stage 并构建 ShuffleDependency 的时候进 行 shuffle 注册,获取后续数据读取所需要的 ShuffleHandle, 最终每一个 job 提交后都会 生成一个 ResultStage 和若干个 ShuffleMapStage,其中 ResultStage 表示生成作业的最终 结果所在的 Stage。ResultStage 与 ShuffleMapStage 中的 task 分别对应着 ResultTask 与 ShuffleMapTask。一个作业,除了最终的 ResultStage 外,其他若干 ShuffleMapStage 中各 个 ShuffleMapTask 都需要将最终的数据根据相应的 Partitioner 对数据进行分组,然后持 久化分区的数据。
二、Hash Shuffle 图解
2.1)Hash Shuffle概述
在 spark-1.6 版本之前,一直使用 HashShuffle,在 spark-1.6 版本之后使用 Sort Shuffle,因为 HashShuffle 存在的不足所以就替换了 HashShuffle。
我们知道,Spark 的运行主要分为 2 部分:一部分是驱动程序,其核心是 SparkContext。另 一部分是 Worker 节点上 Task,它是运行实际任务的。程序运行的时候,Driver 和 Executor 进程相互交互,Driver 会分配 Task 到 Executor,也就是 Driver 跟 Executor 会进行网络 传输。另外,当前 Task 要抓取其他上游的 Task 的数据结果,所以这个过程中就不断的产 生网络结果。其中下一个 Stage 向上一个 Stage 要数据这个过程,我们就称之为 Shuffle。
2.2)没有优化之前的Hash Shuffle机制
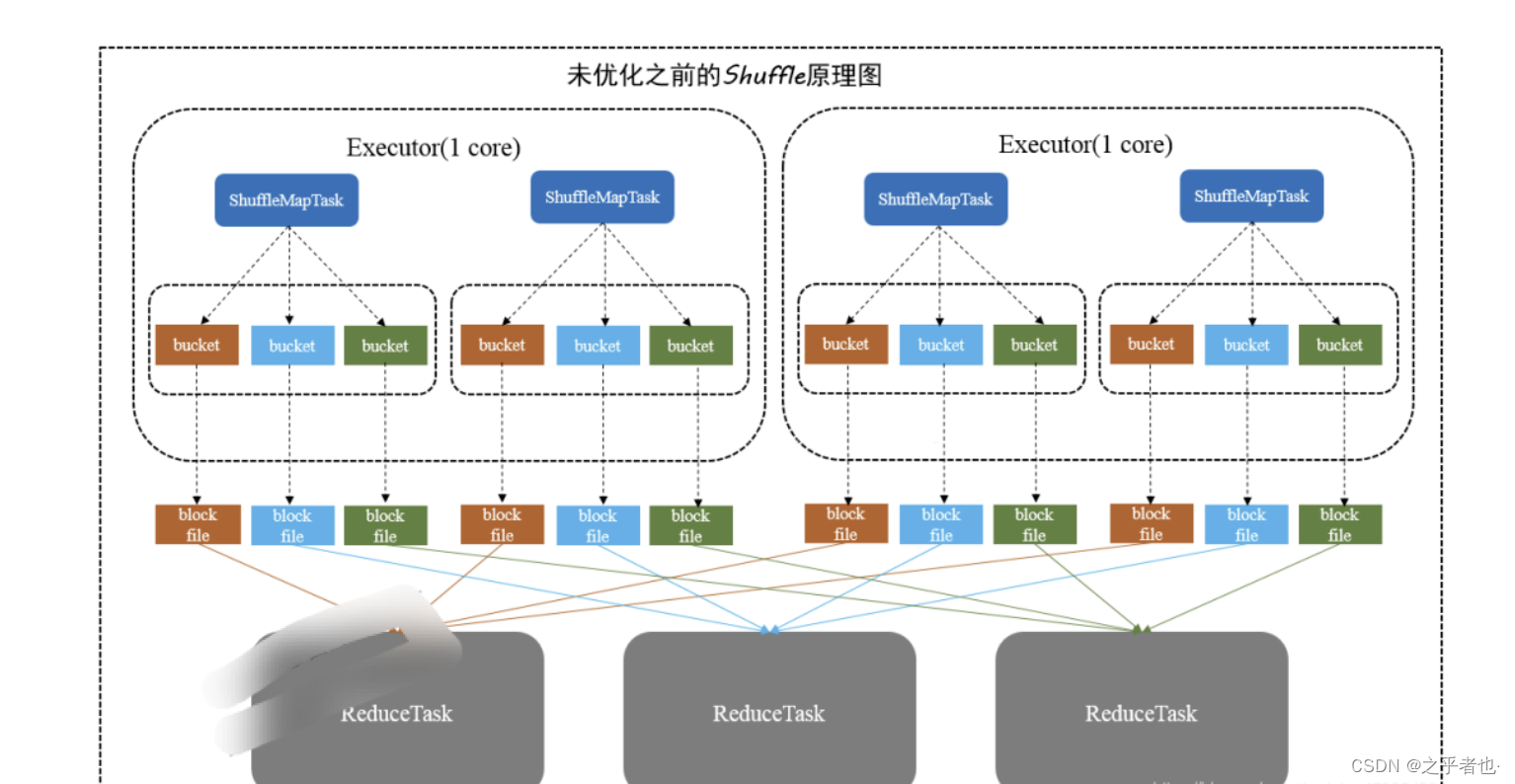
HashShuffle没有优化之前的细节过程:
在 HashShuffle 没有优化之前,每一个 ShufflleMapTask 会为每一个 ReduceTask 创建一个bucket 缓存,并且会为每一个 bucket 创建一个文件。这个 bucket 存放的数据就是经过 Partitioner 操作(默认是 HashPartitioner)之后找到对应的 bucket 然后放进去,最后将数 据刷新 bucket 缓存的数据到磁盘上,即对应的 block file。
然 后 ShuffleMapTask 将 输 出 作 为 MapStatus 发 送 到 DAGScheduler 的 MapOutputTrackerMaster,每一个 MapStatus 包含了每一个 ResultTask 要拉取的数据的位 置和大小。
接下来 ResultTask 去利用 BlockStoreShuffleFetcher 向 MapOutputTrackerMaster 获取 MapStatus,看哪一份数据是属于自己的,然后底层通过 BlockManager 将数据拉取过来。
拉取过来的数据会组成一个内部的 ShuffleRDD,优先放入内存,内存不够用则放入磁盘, 然后 ResulTask 开始进行聚合,最后生成我们希望获取的那个 MapPartitionRDD。
自己的话总结:
每一个上游ShufflleMapTask 根据下游 ReduceTask数量,产生对应多个的bucket内存,这个bucket存放的数据是经过Partition操作(默认是Hashpartition)之后找到对应的 bucket 然后放进去,bucket内存大小默认是32k,最后将bucket缓存的数据溢写到磁盘,即为对应的block file。接下来Reduce Task底层通过 BlockManager 将数据拉取过来。拉取过来的数据会组成一个内部的 ShuffleRDD,优先放入内存,内存不够用则放入磁盘。
没有优化的Hash Shuffle的缺点
如上图所示:在这里有 1 个 worker, 2 个 executor, 每一个 executor 运行 2 个 ShuffleMapTask, 有三个 ReduceTask, 计算方式为:executor 数量 * 每个 executor 的 ShuffleMapTask 数量 * ReduceTask 数量。所以总共就有 2 * 2 * 3=12 个 bucket 以及对应 12 个 block file(分区文件)。
- 如果数据量较大,将会生成 M * R 个小文件,比如 ShuffleMapTask 有 100 个,ResultTask 有 100 个,这就会产生 100 * 100=10000 个小文件
- bucket 缓存很重要,需要将 ShuffleMapTask 所有数据都写入 bucket,然后再刷到磁盘。 那么如果 Map 端数据过多,这就很容易造成内存溢出。尽管后面有优化,bucket 写入的数 据达到刷新到磁盘的阀值之后,就会将数据一点一点的刷新到磁盘,但是这样磁盘 I/O 就多 了。
2.3)优化后的Hash Shuffle机制
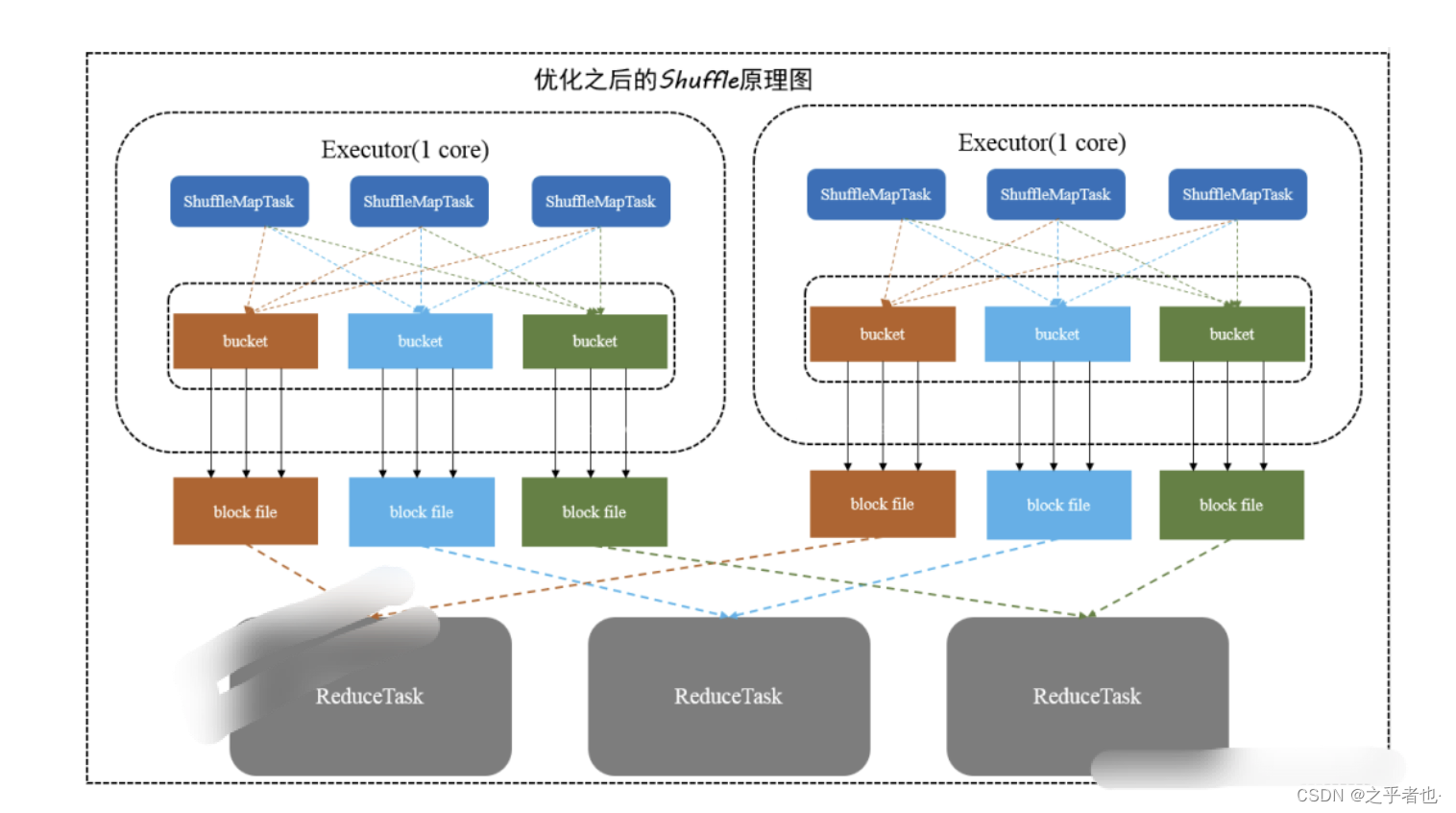
HashShuffle优化之后的细节过程:每一个 Executor 进程根据核数,决定 Task 的并发数量,比如 executor 核数是 2,那就可 以并发运行两个 task,如果是一个则只能运行一个 task。
假设 executor 核数是 1,ShuffleMapTask 数量是 M,那么它依然会根据 ResultTask 的数量 R, 创建 R 个 bucket 缓存,然后对 key 进行 hash,数据进入不同的 bucket 中,每一个 bucket 对应着一个 block file,用于刷新 bucket 缓存里的数据。
然后下一个 task 运行的时候,就不会再创建新的 bucket 和 block file,而是复用之前的 task 已经创建好的 bucket 和 block file。即所谓同一个 Executor 进程里所有 Task 都会把 相同的 key 放入相同的 bucket 缓冲区中。
这样的话, 生成文件的数量就是(本地 worker 的所有 executor 对应的 cores 的总数
*ResultTask
数量)如上图所示,即 2 * 3 = 6 个文件,每一个 Executor 的 shuffleMapTask 数量 100,ReduceTask 数量即为 100。
接下来举例比较一下,未优化的 HashShuffle 的文件数是 2 * 100 * 100 =20000,优化之后的 数量是 2 * 100 = 200 文件,相当于少了 100 倍。
自己的话总结:
每一个 Executor 进程根据核数,决定 Task 的并发数量,如果executor 核数是1,则只能运行一个task。ShuffleMapTask 会根据 ResultTask 的数量,产生对应多个的bucket内存,然后对 key 进行 hash分区,数据进入不同的 bucket 中,每一个 bucket 对应着一个 block file,用于刷新 bucket缓存里的数据。然后下一个 task 运行的时候,就不会再创建新的 bucket 和 block file,而是复用之前的 task 已经创建好的 bucket 和 block file。即所谓同一个 Executor 进程里所有 Task 都会把 相同的 key放入相同的 bucket 缓冲区中。
优化过的Hash Shuffle的缺点如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧 过大,也会产生很多小文件。
三、Sort Shuffle 图解
为了缓解 Shuffle 过程产生文件数过多和 Writer 缓存开销过大的问题,spark 引入了类似 于 hadoop Map-Reduce 的 shuffle 机制。该机制每一个 ShuffleMapTask 不会为后续的任务 创建单独的文件,而是会将所有的 Task 结果写入同一个文件,并且对应生成一个索引文件。 以前的数据是放在内存缓存中,等到缓存读取完数据后再刷到磁盘,现在为了减少内存的使 用,在内存不够用的时候,可以将输出溢写到磁盘。结束的时候,再将这些不同的文件联合 内存(缓存)的数据一起进行归并,从而减少内存的使用量。一方面文件数量显著减少,另 一方面减少 Writer 缓存所占用的内存大小,而且同时避免 GC 的风险和频率。
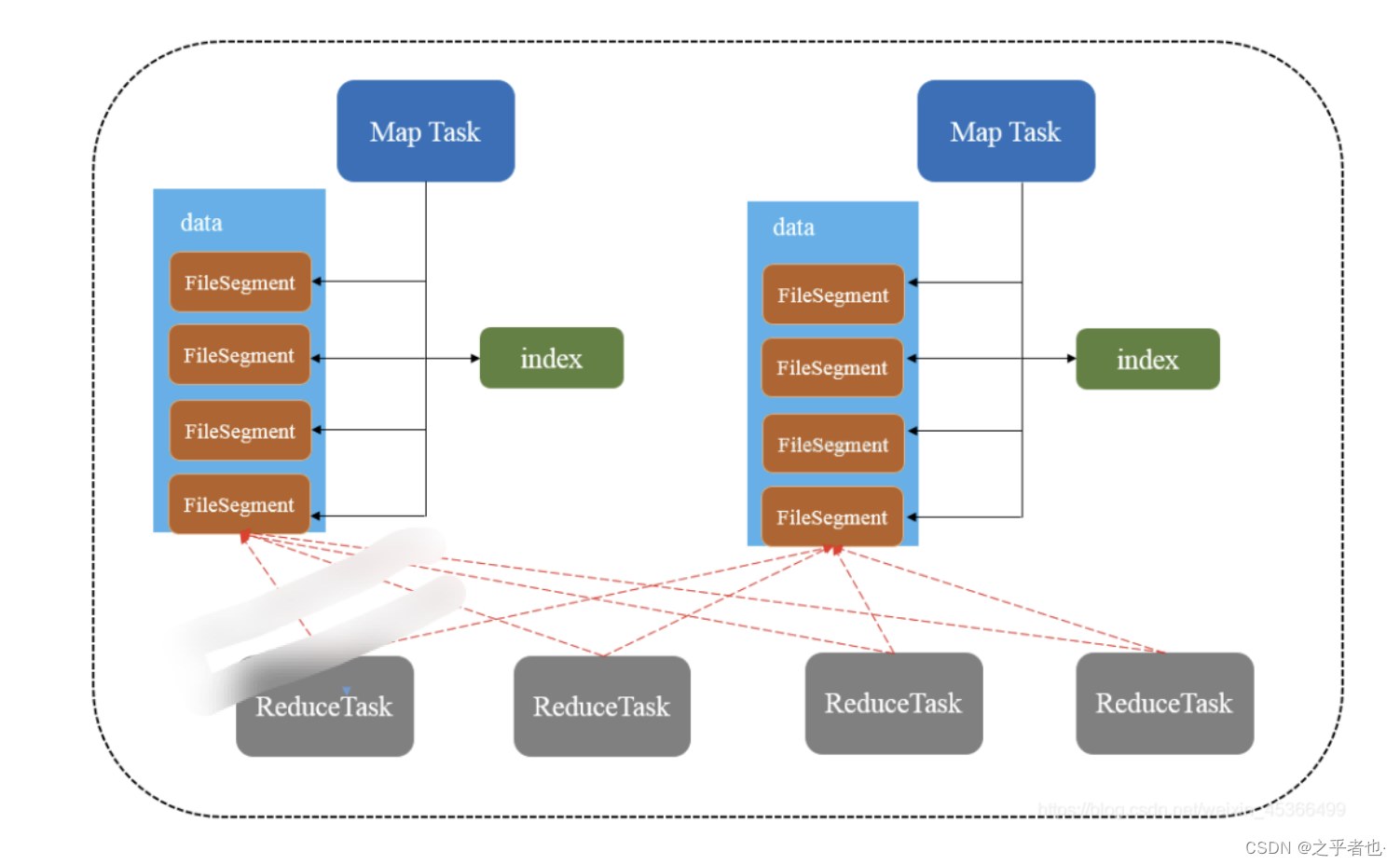
Sort Shuffle原理: 普通的SortShuffle

在普通模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可以选用不同的数据结构。如果是由聚合操作的shuffle算子,就是用map的数据结构(边聚合边写入内存),如果是join的算子,就使用array的数据结构(直接写入内存)。接着,每写一条数据进入内存数据结构之后,就会判断是否达到了某个临界值,如果达到了临界值的话,就会尝试的将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序,排序之后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批次1万条数据的形式分批写入磁盘文件,写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
此时task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写,会产生多个临时文件,最后会将之前所有的临时文件都进行合并,最后会合并成为一个大文件。最终只剩下两个文件,一个是合并之后的数据文件,一个是索引文件(标识了下游各个task的数据在文件中的start offset与end offset)。最终再由下游的task根据索引文件读取相应的数据文件。
Sort Shuffle原理: bypass运行机制

此时上游stage的task会为每个下游stage的task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
bypass机制与普通SortShuffleManager运行机制的不同在于:
a、磁盘写机制不同; b、不会进行排序。
也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
自己的话总结:****普通的SortShuffle机制
在普通模式下,数据会先写入一个内存数据结构中,如果是由聚合操作的shuffle算子用map数据结构,如果是join算子就用Array数据结构。在写入的过程中如果达到了临界值,就会将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。在溢写磁盘之前,会先根据key对内存数据结构中的数据进行排序,排序好的数据,会以每批次1万条数据的形式分批写入磁盘文件。在task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写,会产生多个临时文件,最后会将之前所有的临时文件都进行合并,最后会合并成为一个大文件。最终只剩下两个文件,一个是合并之后的数据文件,一个是索引文件,最终再由下游的task根据索引文件读取相应的数据文件。
bypass运行机制
bypass的就是不排序,还是用hash去为key分磁盘文件,分完之后再合并,形成一个索引文件和一个合并后的key hash文件。省掉了排序的性能。
Sort Shuffle 有几种不同的策略:
- BypassMergeSortShuffleWriter(Bypass 机制)
- SortShuffleWriter(普通机制)
- UnsafeShuffleWriter
对于 BypassMergeSortShuffleWriter,使用这个模式的特点为:
- 主要用于处理不需要排序和聚合的 Shuffle 操作,所以数据是直接写入文件,数据量较大 的时候,网络 I/O 和内存负担较重。
- 主要适合处理 Reducer 任务数量比较少的情况。
- 将每一个分区写入一个单独的文件,最后将这些文件合并,减少文件数量。但是这种方式 需要并发打开多个文件,对内存消耗比较大。
因为 BypassMergeSortShuffleWriter 这种方式比 SortShuffleWriter 更快,所以如果在 Reducer 数 量 不 大 , 又 不 需 要 在 map 端 聚 合 和 排 序 , 而 且 Reducer 的 数 目 小 于 spark.shuffle.sort.bypassMergeThreshold 指定的阀值(默认 200)时,就是用的是这种 方式(即启用条件)。
对于 SortShuffleWriter(普通机制),使用这个模式的特点为:
- 比较适合数据量很大的场景或者集群规模很大。
- 引入了外部排序器,可以支持在 Map 端进行本地聚合或者不聚合。
- 如果外部排序器 enable 了 spill 功能,如果内存不够,可以先将输出溢写到本地磁盘, 最后将内存结果和本地磁盘的溢写文件进行合并。
另外,这个 Sort-Based Shuffle 跟 Executor 核数没有关系,即跟并发度没有关系,它是每 一个 ShuffleMapTask 都会产生一个 data 文件和 index 文件, 所谓合并也只是将该 ShuffleMapTask 的各个 partition 对应的分区文件合并到 data 文件而已。所以这个就需要 和 Hash-BasedShuffle 的 consolidation 机制区别开来。
四、Spark Shuffle调优
- 调节map端缓冲区大小- map端缓冲的默认配置是32KB-
val conf = new SparkConf().set("spark.shuffle.file.buffer", "64") - 调节reduce端拉取数据缓冲区大小- 如果内存资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能- reduce端数据拉取缓冲区大小默认48MB-
val conf = new SparkConf().set("spark.reducer.maxSizeInFlight", "96") - 调节reduce端拉取数据重试次数- reduce端拉取数据重试次数默认为3-
val conf = new SparkConf().set("spark.shuffle.io.maxRetries", "6") - 调节reduce端拉取数据等待间隔- reduce端拉取数据等待间隔默认为5s-
val conf = new SparkConf().set("spark.shuffle.io.retryWait", "60s") - 调节SortShuffle排序操作阈值- SortShuffleManager排序操作阈值默认为200-
val conf = new SparkConf().set("spark.shuffle.sort.bypassMergeThreshold", "400")
31、谈一谈Spark中的容错机制
Spark是一个分布式计算框架,具备强大的容错机制,以确保在集群中发生故障时能够保持计算的正确性和可靠性。下面是Spark中的几个主要容错机制:
- 数据容错:Spark通过将数据划分为一系列弹性分布式数据集(RDD)来实现数据容错。RDD是不可变的、可分区的数据集合,它可以在集群中的多个节点上进行并行计算。当节点发生故障时,Spark可以使用RDD的血统(lineage)信息重新计算丢失的数据分区,从而实现数据的容错。
- 任务容错:Spark将计算任务划分为一系列的阶段(stage),每个阶段包含一组可以并行执行的任务。每个任务都会在执行过程中生成一系列的输出数据,这些输出数据会被持久化到稳定存储中。如果任务失败,Spark可以通过重新执行该任务来实现任务的容错。
- 节点容错:Spark通过使用主从架构来实现节点容错。在集群中,有一个主节点(Driver)负责协调任务的执行和结果的收集,以及监控集群中的节点状态。如果主节点发生故障,Spark可以通过重新启动一个新的主节点来实现节点的容错。
- 任务调度容错:Spark使用任务调度器来管理任务的执行顺序和资源分配。如果某个任务在执行过程中发生错误,任务调度器可以重新调度该任务,并将其分配给其他可用的节点进行执行。
- 数据丢失容错:Spark在执行过程中会将数据缓存在内存中,以提高计算性能。为了防止数据丢失,Spark提供了可配置的数据持久化选项,可以将数据持久化到磁盘或其他外部存储系统中。这样即使发生节点故障,数据也可以从持久化存储中恢复。
总的来说,Spark的容错机制主要依赖于RDD的血统信息、任务调度器、主从架构和数据持久化等技术手段,通过这些手段可以实现数据、任务、节点和数据丢失的容错处理,保证计算的正确性和可靠性。
32、说说Spark数据倾斜
Spark数据倾斜是指在数据处理过程中,某些数据分区的负载远远超过其他分区,导致计算资源不均衡,从而影响整体性能。数据倾斜可能导致任务执行时间延长,资源浪费,甚至导致任务失败。下面是一些常见的数据倾斜情况和解决方法:
- Key数据倾斜:当使用某个字段作为数据集的Key时,如果该字段的分布不均匀,就会导致Key数据倾斜。解决方法包括:- 增加分区:通过增加数据集的分区数,可以将数据均匀地分布到更多的分区中,减少数据倾斜的可能性。- 使用哈希分区:使用哈希函数将Key映射到不同的分区,确保数据均匀分布。- 聚合合并:将具有相同Key的数据进行聚合操作,减少数据量,降低倾斜程度。
- 数据倾斜的Join操作:在进行Join操作时,如果连接字段的分布不均匀,就会导致数据倾斜。解决方法包括:- 使用Broadcast Join:对于小表和大表进行Join操作时,可以将小表广播到每个节点上,避免数据倾斜。- 使用随机前缀:对于连接字段分布不均匀的情况,可以在连接字段上添加随机前缀,使连接字段的值更均匀分布。
- 数据倾斜的聚合操作:在进行聚合操作时,如果某些分组的数据量远远超过其他分组,就会导致数据倾斜。解决方法包括:- 使用预聚合:对于可能导致数据倾斜的字段进行预聚合操作,将数据量较大的分组合并为一个分组,减少数据倾斜。- 使用多级聚合:将聚合操作拆分为多个阶段,逐步聚合,减少单个阶段的数据量。
- 数据倾斜的排序操作:在进行排序操作时,如果数据分布不均匀,就会导致数据倾斜。解决方法包括:- 使用随机前缀:对于排序字段分布不均匀的情况,可以在排序字段上添加随机前缀,使排序字段的值更均匀分布。- 使用二次排序:对于多个字段进行排序时,可以使用二次排序算法,先按照一个字段排序,再按照另一个字段排序,减少数据倾斜。
除了上述方法,还可以通过动态资源分配、任务重试、数据重分区等方式来应对数据倾斜问题。数据倾斜是Spark中常见的性能瓶颈之一,需要根据具体情况选择合适的解决方法。
33、说说Spark的优化
Spark是一个基于内存的分布式计算框架,为了提高计算性能和资源利用率,它采用了多种优化技术。下面是Spark的一些优化策略:
- 延迟执行(Lazy Evaluation):Spark采用了延迟执行的策略,也就是说,它在遇到转换操作时不会立即执行,而是将这些操作记录下来,直到遇到行动操作时才执行。这样可以将多个转换操作合并为一个任务,减少数据的读写和中间结果的存储。
- 数据分区(Data Partitioning):Spark将数据划分为多个分区,每个分区可以在集群中的不同节点上并行处理。通过合理的数据分区策略,可以减少数据的传输和网络开销,提高计算效率。
- 内存管理(Memory Management):Spark使用了内存管理技术来加速数据的处理。它将数据存储在内存中,减少了磁盘IO的开销。同时,Spark还使用了内存缓存和数据序列化等技术来提高内存利用率和数据传输效率。
- 任务调度(Task Scheduling):Spark使用了任务调度器来将任务分配给集群中的不同节点进行执行。它可以根据节点的负载情况和数据位置等因素来决定任务的调度顺序,以提高资源利用率和数据本地性。
- 数据本地性优化(Data Locality Optimization):Spark会尽量将任务调度到与数据所在位置相近的节点上执行,以减少数据的网络传输。它可以通过数据划分和任务调度策略来实现数据本地性的优化。
- 广播变量(Broadcast Variable):当需要在集群中的所有节点上共享一个较小的只读变量时,Spark可以使用广播变量来减少数据的传输和复制开销。广播变量会将变量的副本缓存在每个节点上,以便任务可以直接访问,而不需要从驱动程序传输。
- 部分聚合(Partial Aggregation):在进行聚合操作时,Spark可以在每个分区上进行部分聚合,然后再将结果合并起来。这样可以减少数据的传输和聚合的计算量,提高聚合操作的性能。
- 动态资源分配(Dynamic Resource Allocation):Spark可以根据任务的需求动态分配集群资源。它可以根据任务的执行情况来调整资源的分配,以提高资源的利用率和整体性能。
这些优化策略使得Spark能够高效地处理大规模数据,并提供快速的计算和查询能力。同时,Spark还提供了丰富的配置选项和调优参数,可以根据应用的需求进行定制化的优化。
34、说说Spark工作机制
Spark是一个开源的分布式计算框架,它提供了高效的数据处理和分析能力。Spark的工作机制可以分为以下几个关键步骤:
- 应用程序启动:用户编写Spark应用程序,并通过SparkContext对象与Spark集群进行通信。SparkContext负责与集群管理器通信,获取资源并分配任务。
- 任务划分:Spark将应用程序划分为一系列任务,每个任务处理数据的一部分。任务的划分是根据数据分区和用户定义的转换操作来完成的。
- 数据分区:Spark将输入数据划分为多个分区,每个分区包含数据的一个子集。分区可以是文件、HDFS块或其他数据源。
- 任务调度:Spark将任务分发到集群中的执行器节点上执行。任务调度器负责将任务分配给可用的执行器节点,并考虑数据本地性以提高性能。
- 任务执行:每个执行器节点接收到任务后,会在本地执行相应的任务操作。执行器会将数据加载到内存中,并执行用户定义的转换和操作。
- 数据流动:Spark的核心概念是弹性分布式数据集(Resilient Distributed Dataset,简称RDD)。RDD是一个可并行操作的对象集合,可以在集群中的多个节点上进行转换和操作。数据在RDD之间流动,允许在不同的转换操作之间进行缓存和重用。
- 任务完成与结果返回:一旦任务执行完成,执行器将结果返回给驱动程序。驱动程序可以将结果保存到内存、磁盘或其他外部存储中,也可以将结果返回给应用程序。
- 容错和恢复:Spark具有容错机制,可以在节点故障时自动恢复。如果某个节点失败,Spark可以重新调度任务并在其他节点上执行。
总的来说,Spark的工作机制包括任务划分、任务调度、任务执行和数据流动等过程。通过这些步骤,Spark能够高效地处理大规模数据,并提供快速的分布式计算能力。
35、说说Spark Job执行流程?spark的执行流程?简要描述Spark写数据的流程?
Spark Job的执行流程可以简要描述为以下几个步骤:
- 创建SparkContext:在执行Spark应用程序之前,首先需要创建一个SparkContext对象。SparkContext是与集群通信的入口点,它负责与集群管理器进行通信,分配资源,并将任务分发给集群中的执行器。
- 创建RDD:在Spark中,数据被组织成弹性分布式数据集(RDD)。RDD可以从外部存储系统(如HDFS)中读取数据,也可以通过对已有RDD进行转换操作来创建。
- 转换操作:Spark提供了一系列的转换操作,如map、filter、reduce等。这些操作可以对RDD进行转换,生成一个新的RDD。转换操作是惰性求值的,即不会立即执行,而是在遇到一个行动操作时才会触发执行。
- 行动操作:行动操作是对RDD进行实际计算并返回结果的操作,例如collect、count、reduce等。当执行行动操作时,Spark将根据依赖关系图(DAG)将转换操作和行动操作组织成一个有向无环图(DAG),并将其划分为一系列的阶段。
- 任务调度:Spark将每个阶段划分为一组任务,并将这些任务分发给集群中的执行器进行执行。任务调度是根据数据的分区进行的,每个任务处理一个或多个分区的数据。
- 任务执行:每个执行器接收到任务后,会在其分配的资源上执行任务。执行器将数据从内存或磁盘中读取到内存中,并执行相应的转换和行动操作。执行结果可以保存在内存中或写入外部存储系统。
Spark写数据的流程可以简要描述为以下几个步骤:
- 创建DataFrame或RDD:首先,需要创建一个包含要写入的数据的DataFrame或RDD对象。DataFrame是一种结构化的数据集,RDD是弹性分布式数据集。
- 指定写入选项:根据要写入的数据的格式和目标存储系统,可以指定相应的写入选项,如文件格式、文件路径、分区方式等。
- 执行写入操作:调用DataFrame或RDD的写入方法,如
write或save,并传入写入选项。Spark会将数据按照指定的格式和方式写入到目标存储系统中。 - 等待写入完成:写入操作是异步的,Spark会在后台执行写入任务。可以使用
awaitTermination等方法等待写入任务完成。
需要注意的是,Spark的写入操作是幂等的,即可以多次执行相同的写入操作而不会导致数据重复写入。
36、说说Spark的运行模式,简单描述WC
Spark有两种运行模式:本地模式和集群模式。
- 本地模式(Local Mode):在本地模式下,Spark运行在单个计算机上,使用单个进程进行任务的执行。这种模式适用于开发和测试阶段,可以快速验证代码的正确性。
- 集群模式(Cluster Mode):在集群模式下,Spark将任务分发给多个计算节点进行并行处理。集群模式适用于大规模数据处理和生产环境。集群模式有两种部署方式:- Standalone模式:在Standalone模式下,Spark自带了一个集群管理器,可以通过启动和配置Master和Worker节点来管理集群资源和任务调度。- YARN模式:YARN是Hadoop的资源管理系统,Spark可以通过YARN来管理集群资源。Spark作为YARN的一个应用程序提交到集群中,YARN负责资源的分配和任务的调度。
WC(WordCount)是一个经典的示例程序,用于统计文本中每个单词的出现次数。在Spark中,可以使用以下步骤实现WordCount:
- 创建SparkContext:首先,需要创建一个SparkContext对象,作为与Spark集群通信的入口点。
- 加载文本数据:使用SparkContext的
textFile方法加载文本文件,并将其转换为RDD(弹性分布式数据集)。 - 数据转换:对RDD进行一系列转换操作,例如使用
flatMap方法将每行文本拆分为单词,使用map方法将每个单词映射为(key, value)对,其中key是单词,value是1。 - 数据聚合:使用
reduceByKey方法对(key, value)对进行聚合操作,将相同key的value相加。 - 结果输出:使用
collect方法将聚合结果收集到Driver程序,并输出结果。
这就是Spark中简单的WordCount示例程序。通过并行处理和分布式计算,Spark能够高效地处理大规模数据集。
37、Spark应用程序的执行过程是什么?spark的执行流程
Spark应用程序的执行过程可以分为以下几个步骤:
- 创建SparkContext:应用程序首先需要创建一个SparkContext对象,它是与Spark集群通信的入口点。SparkContext负责与集群管理器通信,并为应用程序分配资源。
- 创建RDD:应用程序需要将数据加载到弹性分布式数据集(RDD)中。RDD是Spark的核心数据结构,它代表了分布在集群中的数据集合。RDD可以通过读取文件、从内存中的数据集创建、从其他RDD转换等方式来创建。
- 转换操作:一旦RDD被创建,应用程序可以对RDD进行一系列的转换操作,例如map、filter、reduce等。这些转换操作会生成新的RDD,而不会立即执行计算。
- 行动操作:当应用程序需要获取转换操作的结果时,需要执行行动操作。行动操作会触发Spark执行计划的生成和执行。常见的行动操作包括collect、count、save等,它们会返回计算结果给应用程序。
- 作业划分:Spark将应用程序的行动操作划分为一系列的作业(jobs),每个作业由一组相关的转换操作组成。作业划分是为了提高并行度和数据本地性,以便更好地利用集群资源。
- 任务划分:每个作业被划分为一系列的任务(tasks),每个任务处理数据的一部分。任务的划分是根据数据分区和可用资源来完成的。
- 任务调度和执行:Spark将任务分发到集群中的执行器节点上执行。任务调度器负责将任务分配给可用的执行器节点,并考虑数据本地性以提高性能。执行器节点会加载数据到内存中,并执行任务操作。
- 结果返回:一旦任务执行完成,执行器将结果返回给驱动程序。驱动程序可以将结果保存到内存、磁盘或其他外部存储中,也可以将结果返回给应用程序。
- 容错和恢复:Spark具有容错机制,可以在节点故障时自动恢复。如果某个节点失败,Spark可以重新调度任务并在其他节点上执行。
总的来说,Spark应用程序的执行过程包括创建SparkContext、创建RDD、转换操作、行动操作、作业划分、任务划分、任务调度和执行、结果返回以及容错和恢复等步骤。通过这些步骤,Spark能够以高效、可靠的方式处理大规模数据和复杂计算任务。
38、如何理解Standalone模式下,Spark资源分配是粗粒度的?
在Standalone模式下,Spark的资源分配是粗粒度的,这意味着资源的分配单位是整个应用程序,而不是每个任务或每个操作。在Standalone模式下,Spark应用程序被划分为一个或多个独立的执行器(Executors),每个执行器运行在独立的JVM进程中,并且可以分配一定数量的CPU核心和内存资源。
当一个Spark应用程序提交到Standalone集群时,用户需要指定应用程序需要的总体资源需求,例如CPU核心数和内存大小。然后,Spark的资源管理器将根据这些需求来分配执行器,并将应用程序的任务分配给这些执行器。每个执行器被分配的资源是固定的,直到应用程序完成或释放资源。
由于资源分配是以整个应用程序为单位进行的,因此在Standalone模式下,无法根据任务的实际需求进行细粒度的资源分配。这可能导致资源的浪费或不足,影响应用程序的性能。为了更好地利用资源,可以考虑使用其他资源管理器,如YARN或Mesos,它们支持更细粒度的资源分配和共享,可以根据任务的需求进行动态的资源分配。
39、Spark on Mesos中,什么是粗粒度分配,什么是细粒度分配,各自的优点和缺点是什么?
在Spark on Mesos中,粗粒度分配和细粒度分配是两种不同的资源分配策略。
一、粗粒度分配:
- 粗粒度分配是指将整个应用程序的资源需求作为一个整体进行分配。当应用程序启动时,Mesos将为其分配一定数量的CPU核心和内存资源,并将其分配给一个或多个Spark执行器。
- 优点:粗粒度分配简单且高效,减少了资源管理的开销,并且适用于资源需求相对稳定的应用程序。
- 缺点:由于资源分配是静态的,无法根据任务的实际需求进行动态调整,可能导致资源的浪费或不足,影响应用程序的性能。
二、细粒度分配:
- 细粒度分配是指根据任务的实际需求进行动态的资源分配。Mesos会根据任务的需求分配适当数量的CPU核心和内存资源,并在任务执行完成后回收这些资源。
- 优点:细粒度分配可以更好地利用集群资源,根据任务的需求进行动态调整,提高资源利用率和应用程序的性能。
- 缺点:细粒度分配需要更复杂的资源管理和调度机制,增加了系统的开销和复杂性。
选择粗粒度分配还是细粒度分配取决于应用程序的特点和需求。如果应用程序的资源需求相对稳定,粗粒度分配可以提供简单高效的资源管理。如果应用程序的资源需求变化较大或需要更高的资源利用率,细粒度分配可以更好地满足需求。在实际应用中,可以根据具体情况选择适合的资源分配策略。
40、Spark中standalone模式特点,有哪些优点和缺点?
在Spark的standalone模式中,以下是其主要特点、优点和缺点:
特点:
- 独立性:Spark standalone模式是Spark自带的资源管理器,可以独立于其他资源管理系统运行,如Hadoop YARN或Mesos。
- 简单易用:相对于其他资源管理系统,Spark standalone模式配置和使用相对简单,适合初学者或小规模集群。
- 高可用性:Spark standalone模式支持主备模式,即可以配置一个或多个备用的主节点,以提高系统的可用性。
优点:
- 效率高:Spark standalone模式的资源分配是粗粒度的,以整个应用程序为单位进行分配,减少了资源管理的开销,提高了任务的执行效率。
- 简化部署:使用Spark standalone模式,无需依赖其他资源管理系统,可以快速部署和运行Spark应用程序。
- 灵活性:Spark standalone模式支持动态资源分配,可以根据应用程序的需求在运行时调整资源的分配情况。
缺点:
- 资源浪费:由于资源分配是以整个应用程序为单位进行的,可能导致资源的浪费。如果应用程序中某些任务的资源需求较小,但被分配了较多的资源,会导致资源的浪费。
- 资源不足:如果应用程序的资源需求超过了集群的可用资源,可能会导致资源不足,影响任务的执行。
- 缺乏细粒度调整:由于资源分配是粗粒度的,无法对每个任务进行细粒度的资源调整,可能导致资源的利用率不高。
综上所述,Spark standalone模式在简单易用和高效性方面具有优势,但在资源利用和灵活性方面存在一些限制。选择使用该模式还需根据具体应用程序的特点和需求进行考虑。
41、Spark的优化怎么做?Spark做过哪些优化,(优化说完会问你为什么?原理是什么?)
Spark的优化可以从多个方面进行,包括数据存储和压缩、数据分区和分桶、Shuffle操作的优化、内存管理和缓存、并行度和资源配置等。以下是一些常见的Spark优化技术和原理:
- 数据存储和压缩:使用列式存储格式(如Parquet、ORC)可以减少磁盘IO和内存占用,提高查询性能。同时,使用压缩算法(如Snappy、Gzip)可以减小数据的存储空间,减少磁盘IO和网络传输开销。
- 数据分区和分桶:合理的数据分区和分桶可以提高数据的局部性,减少Shuffle操作的数据传输量。通过将相同键的数据分配到同一个分区或桶中,可以减少数据的移动和网络传输。
- Shuffle操作的优化:Shuffle是Spark中性能开销较大的操作,可以通过以下方式进行优化:- 调整分区数:合理设置分区数,避免数据倾斜和资源浪费。- 使用本地化Shuffle:尽可能将Shuffle数据放置在与计算节点相同的节点上,减少网络传输开销。- 使用累加器和广播变量:避免将大量数据通过Shuffle传输,而是通过累加器和广播变量在节点间共享数据。
- 内存管理和缓存:Spark使用内存来加速数据处理,可以通过以下方式进行优化:- 合理设置内存分配比例,如Executor内存和Storage内存的比例。- 使用内存序列化:将数据以序列化的方式存储在内存中,减少内存占用和GC开销。- 合理使用缓存:将频繁使用的数据缓存到内存中,避免重复计算和IO开销。
- 并行度和资源配置:合理设置并行度和资源配置可以充分利用集群资源,提高作业的执行效率。可以根据数据量、计算复杂度和集群规模等因素来调整并行度和资源分配。
Spark做出这些优化的目的是为了提高作业的执行效率和性能,减少资源的浪费和开销。这些优化的原理主要是通过减少磁盘IO、网络传输和计算开销,提高数据的局部性和并行度,充分利用内存和缓存等方式来优化Spark的执行过程,从而提高作业的整体性能。
42、Spark性能优化主要有哪些手段?
Spark性能优化可以从多个方面入手,以下是一些常见的手段:
- 数据存储和压缩:选择合适的数据存储格式,如Parquet或ORC,可以减少磁盘IO和内存消耗。同时,使用数据压缩技术可以减小数据的存储空间,提高IO效率。
- 数据分区和分桶:根据数据的特点和查询需求,将数据进行适当的分区和分桶,可以减少数据倾斜和提高查询性能。
- Shuffle操作的优化:Shuffle是Spark中常见的开销较大的操作,可以通过使用合适的Shuffle操作算子、调整分区数、合理设置缓存等手段来优化Shuffle的性能。
- 内存管理和缓存:合理配置Spark的内存分配和缓存策略,可以充分利用内存资源,减少磁盘IO,提高查询速度。
- 并行度和资源配置:根据集群的资源情况和作业的需求,合理设置并行度和资源配置,可以提高作业的执行效率。
- 使用合适的算子和函数:选择合适的Spark算子和函数,避免使用性能较差的操作,如全量数据的操作和大量的shuffle操作。
- 使用缓存和持久化:对于经常被重复使用的数据集,可以使用缓存或持久化技术将其保存在内存或磁盘中,避免重复计算,提高性能。
- 使用广播变量:对于小规模的数据集,可以将其广播到每个Executor上,减少数据传输开销。
- 资源预测和动态资源分配:通过资源预测和动态资源分配技术,根据作业的实际需求和集群的资源情况,动态调整资源的分配,提高资源的利用率。
以上是一些常见的Spark性能优化手段,具体的优化策略需要根据具体的应用场景和需求进行选择和调整。
43、简要描述Spark分布式集群搭建的步骤?
搭建Spark分布式集群的步骤如下:
- 准备环境:确保每台机器上都安装了Java和Spark的依赖库,并且网络连接正常。
- 配置主节点:选择一台机器作为主节点,编辑Spark的配置文件(spark-defaults.conf和spark-env.sh),设置主节点的IP地址、端口号、内存分配等参数。
- 配置工作节点:编辑Spark的配置文件,设置工作节点的IP地址、端口号、内存分配等参数。
- 配置集群管理器:如果使用集群管理器(如Standalone、YARN或Mesos),需要配置相关的参数,如集群管理器的地址、端口号等。
- 分发Spark安装包:将Spark安装包分发到所有的机器上,确保每台机器上都可以访问到Spark的安装目录。
- 启动集群:在主节点上执行启动命令,启动集群管理器和工作节点。具体命令可以是
./sbin/start-master.sh启动集群管理器,./sbin/start-worker.sh <master-url>启动工作节点。 - 验证集群:通过访问Spark的Web界面(通常是
http://<master-ip>:8080)来验证集群是否正常运行。在Web界面上可以查看集群的状态、任务的执行情况等信息。 - 提交任务:使用Spark提供的命令行工具或编写Spark应用程序,将任务提交到集群中执行。具体命令可以是
./bin/spark-submit --class <main-class> --master <master-url> <application-jar>。
以上是Spark分布式集群搭建的一般步骤,具体的步骤和命令可能会因为使用的集群管理器和环境的不同而有所差异。在实际搭建过程中,还需要根据具体的需求和环境进行相应的配置和调整。
44、spark-submit的时候如何引入外部jar包
在使用
spark-submit
提交Spark应用程序时,可以通过
--jars
选项来引入外部的JAR包。具体的命令格式如下:
spark-submit --class <main-class> --master <master-url> --jars <comma-separated-jars> <application-jar> [application-arguments]
其中,
<main-class>
是你的应用程序的主类名,
<master-url>
是Spark集群的URL,
<comma-separated-jars>
是用逗号分隔的外部JAR包的路径列表,
<application-jar>
是你的应用程序的JAR包路径,
[application-arguments]
是传递给应用程序的参数(可选)。
例如,如果你有一个名为
myapp.jar
的应用程序JAR包,并且想要引入一个名为
external.jar
的外部JAR包,你可以使用以下命令:
spark-submit --class com.example.MyApp --master spark://localhost:7077 --jars /path/to/external.jar /path/to/myapp.jar
这样,
external.jar
就会被提交的Spark应用程序所引用。在应用程序中,你可以使用
SparkContext
的
addJar()
方法来加载这个外部JAR包:
val sc = new SparkContext(...)
sc.addJar("/path/to/external.jar")
这样,你就可以在应用程序中使用外部JAR包中的类和方法了。
45、Spark提交你的jar包时所用的命令是什么?
当你使用
spark-submit
命令提交Spark应用程序时,你需要提供一些参数来指定应用程序的配置和运行方式。下面是一个详细的命令示例:
spark-submit --class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--executor-memory <executor-memory> \
--total-executor-cores <total-executor-cores> \
--jars <comma-separated-jars> \
--conf <key>=<value> \
<application-jar> [application-arguments]
下面是各个参数的解释:
<main-class>: 你的应用程序的主类名。<master-url>: Spark集群的URL,可以是local、yarn、mesos、standalone等。<deploy-mode>: 应用程序的部署模式,可以是client或cluster。client模式表示驱动程序运行在提交命令所在的节点上,cluster模式表示驱动程序运行在集群中的某个节点上。<executor-memory>: 每个Executor的内存大小,例如2g、4g等。<total-executor-cores>: 所有Executor的总核数。<comma-separated-jars>: 用逗号分隔的外部JAR包的路径列表,可以通过--jars选项引入外部JAR包。<key>=<value>: 额外的配置项,可以通过--conf选项指定,例如--conf spark.executor.extraJavaOptions="-XX:+PrintGCDetails"。<application-jar>: 你的应用程序的JAR包路径。[application-arguments]: 传递给应用程序的参数,可选。
例如,假设你有一个名为
myapp.jar
的应用程序JAR包,主类为
com.example.MyApp
,并且你想要在本地模式下运行应用程序,你可以使用以下命令:
spark-submit --class com.example.MyApp \
--master local[*] \
--deploy-mode client \
--executor-memory 2g \
--total-executor-cores 4 \
--jars /path/to/external.jar \
/path/to/myapp.jar arg1 arg2
这样,你就可以提交你的Spark应用程序并运行它了。请根据你的实际情况修改命令中的参数值。
46、你如何从Kafka中获取数据?
要从Kafka中获取数据,你可以使用Apache Spark来实现。下面是详细的步骤:
- 配置Spark和Kafka依赖:在你的Spark项目中,需要添加Kafka相关的依赖。可以在
build.sbt文件中添加以下依赖:
libraryDependencies += "org.apache.spark" %% "spark-sql-kafka-0-10" % "版本号"
- 创建SparkSession:在你的Spark应用程序中,首先需要创建一个SparkSession对象。SparkSession是与Spark集群通信的主要入口点。你可以使用以下代码创建一个SparkSession对象:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("KafkaConsumer")
.master("local[*]") // 这里的master可以根据你的需求进行修改
.getOrCreate()
- 读取Kafka数据:使用SparkSession的
readStream方法来读取Kafka中的数据。你需要指定Kafka的服务器地址、主题和其他必要的配置。例如:
val kafkaDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "Kafka服务器地址")
.option("subscribe", "Kafka主题")
.load()
- 解析Kafka数据:Kafka中的数据以二进制格式存储,你需要将其解析为可读的格式。可以使用Spark的内置函数或自定义函数来解析数据。例如,如果数据是以JSON格式存储的,你可以使用
from_json函数将其解析为DataFrame的列。示例代码如下:
import org.apache.spark.sql.functions._
val parsedDF = kafkaDF.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.select(from_json(col("value"), yourSchema).as("data"))
.select("data.*")
这里的
yourSchema
是你定义的JSON模式。
- 处理Kafka数据:一旦你将Kafka数据解析为DataFrame,你可以使用Spark的各种操作和转换来处理数据。例如,你可以进行过滤、聚合、筛选等操作。
- 启动流式处理:使用
writeStream方法将处理后的数据写入到目标位置,如文件系统、数据库等。你需要指定输出的格式和位置。例如,将数据写入到控制台:
val query = parsedDF.writeStream
.format("console")
.start()
query.awaitTermination()
在实际生产环境中,你可以将数据写入到Kafka、HDFS、数据库等。
这样,你就可以使用Spark从Kafka中获取数据并进行处理了。记得根据你的实际情况修改代码中的参数和配置。
47、Spark Streaming对接Kafka两种整合方式的区别
Spark Streaming(简称SS)对接Kafka的两种整合方式的区别。在Spark 2.0版本之后,Spark Streaming已经被整合到了Structured Streaming中,因此可以使用Structured Streaming对接Kafka。
一、Direct方式:
- Direct方式是Spark Streaming的推荐方式,也是Structured Streaming对接Kafka的推荐方式。
- Direct方式通过直接连接到Kafka的每个分区来读取数据,并行地从多个分区读取数据。
- 它使用Kafka的高级消费者API来维护消费者偏移量,并支持Exactly-once语义。
- Direct方式具有更好的性能和可靠性,因为它可以从Kafka中直接读取数据,而不需要中间人(例如Receiver)。
- 使用Direct方式时,可以通过设置参数来控制读取数据的位置(例如从最早的偏移量开始读取或从最新的偏移量开始读取)。
二、Receiver方式(已被官方废弃,不推荐使用):
- Receiver方式是Spark Streaming早期版本中对接Kafka的方式,但自Spark 2.0版本起已经被官方废弃,不再推荐使用。
- Receiver方式通过在Spark集群中的接收器(Receiver)进程中接收Kafka数据,并将数据存储在Spark的Executor进程中进行处理。
- Receiver方式使用Kafka的低级消费者API来维护消费者偏移量,并支持At-least-once语义。
- Receiver方式会引入一定的延迟,因为数据需要通过Receiver进程进行传输和处理。
- Receiver方式在处理高吞吐量和低延迟要求的场景下可能会出现性能问题。
总结起来,Direct方式是Spark Streaming和Structured Streaming对接Kafka的推荐方式,具有更好的性能和可靠性。而Receiver方式已经被官方废弃,不再推荐使用。
48、Spark Streaming中如何实现精准一次消费
在Spark Streaming中,实现精确一次消费(exactly-once semantics)是通过以下步骤来实现的:
- 使用Kafka作为数据源:首先,将Kafka作为Spark Streaming的数据源。Kafka是一个分布式流处理平台,具有高吞吐量和容错性。
- 使用Kafka的Direct方式消费数据:Spark Streaming提供了两种方式来消费Kafka数据,即Direct方式和Receiver方式。为了实现精确一次消费,我们使用Direct方式。Direct方式通过直接从Kafka分区中读取数据来消费,而不是通过Kafka Receiver。
- 将偏移量保存到ZooKeeper或Kafka:在Direct方式中,Spark Streaming会周期性地将消费的偏移量(offset)保存到外部存储系统,比如ZooKeeper或Kafka的特殊主题。这样,在发生故障或重启时,Spark Streaming可以从上一次保存的偏移量继续消费数据,从而实现精确一次消费。
- 定期提交偏移量:Spark Streaming会定期提交已经处理的偏移量,以确保即使在处理过程中发生故障,也不会重复处理已经处理过的数据。
- 容错机制:Spark Streaming具有容错机制,即使在处理过程中发生故障,也可以恢复并继续处理数据。当发生故障时,Spark Streaming会使用保存的偏移量来重新启动,并从上一次保存的偏移量处继续消费数据,确保数据不会丢失或重复处理。
通过以上步骤,Spark Streaming能够实现精确一次消费,确保每条数据只被处理一次,从而保证数据处理的准确性和一致性。
49、Spark中Master 实现HA有哪些方式 ?
在Spark中,实现Master的高可用性(HA)可以采用以下几种方式:
- Standalone模式下的HA:在Spark的Standalone模式中,可以通过启动多个Master节点来实现HA。这些Master节点将组成一个高可用性的集群,其中一个节点将被选举为活动Master,而其他节点则处于备用状态。当活动Master节点发生故障时,备用节点将自动接管并成为新的活动Master节点。
- YARN模式下的HA:在Spark的YARN模式中,可以利用YARN的HA机制来实现Master的高可用性。YARN提供了ResourceManager的HA配置,可以使用ZooKeeper来进行故障检测和自动故障转移。当活动的ResourceManager节点发生故障时,ZooKeeper将自动选举一个备用节点作为新的活动节点。
- Mesos模式下的HA:在Spark的Mesos模式中,可以通过启动多个Mesos Master节点来实现HA。这些Master节点将组成一个高可用性的集群,其中一个节点将被选举为活动Master,而其他节点则处于备用状态。当活动Master节点发生故障时,备用节点将自动接管并成为新的活动Master节点。
需要注意的是,无论是哪种模式下的HA,都需要使用外部组件(如ZooKeeper)来进行故障检测和自动故障转移。这些组件负责监控Master节点的状态,并在需要时进行故障转移。同时,还需要配置Spark的相关参数,以便Spark能够与这些外部组件进行通信和协调。
总结起来,Spark中实现Master的HA可以通过在Standalone、YARN或Mesos模式下配置多个Master节点,并结合外部组件(如ZooKeeper)进行故障检测和自动故障转移来实现。
50、Spark master使用zookeeper进行HA,有哪些元数据保存在Zookeeper?
在Spark中,使用ZooKeeper进行Master的高可用性(HA)时,以下元数据将保存在ZooKeeper中:
- Master的主节点选举信息:ZooKeeper用于协调多个Master节点之间的主节点选举过程。每个Master节点都会在ZooKeeper上创建一个临时顺序节点,称为"master_election"。当一个Master节点启动时,它会尝试创建这个节点。如果创建成功,它将成为主节点,并且其他Master节点将成为备用节点。如果创建失败,它将监听前一个节点的删除事件,一旦前一个节点被删除,它将尝试再次创建节点并成为主节点。
- Master的元数据信息:每个Master节点都会在ZooKeeper上创建一个持久节点,称为"master"。这个节点中保存了Master节点的元数据信息,包括Master节点的主机名、端口号、Web UI地址等。其他Spark组件(如Worker节点和Driver程序)可以通过查询这个节点获取Master节点的信息,以便与Master节点进行通信。
- Worker节点的注册信息:每个Worker节点都会在ZooKeeper上创建一个临时顺序节点,称为"workers"。这个节点中保存了Worker节点的注册信息,包括Worker节点的主机名、端口号、状态等。Master节点可以通过监听这个节点的变化来实时获取Worker节点的注册和注销信息,并进行资源调度和任务分配。
- Application的注册信息:每个运行的Spark应用程序都会在ZooKeeper上创建一个临时顺序节点,称为"applications"。这个节点中保存了应用程序的注册信息,包括应用程序的ID、驱动程序的主机名、端口号等。Master节点可以通过监听这个节点的变化来实时获取应用程序的注册和注销信息,并进行任务调度和资源管理。
通过将这些元数据保存在ZooKeeper中,Spark的Master节点可以实现高可用性和故障转移。当一个Master节点发生故障时,其他备用节点可以通过监听ZooKeeper上的节点变化来感知到故障,并自动选举新的主节点。同时,其他Spark组件也可以通过查询ZooKeeper上的节点来获取Master节点和Worker节点的信息,从而实现与它们的通信和协调。
51、Spark master HA 主从切换过程不会影响集群已有的作业运行,为什么?
Spark的Master节点高可用性(HA)切换过程不会影响集群中已有的作业运行,这是因为Spark的Master节点只负责作业的调度和资源管理,并不直接参与作业的执行过程。下面是详细的说明:
- Master节点的故障转移:当当前的Master节点发生故障时,通过使用ZooKeeper等外部的协调服务来实现Master节点的故障转移。ZooKeeper会监视Master节点的状态,并在Master节点故障时自动选举出新的Master节点。在选举过程中,已有的作业不会受到影响,因为它们已经在Worker节点上运行,并由Worker节点自主地管理。
- Worker节点的自治性:Spark的Worker节点是独立的执行引擎,它们负责运行作业的任务。一旦作业被分配到Worker节点上,它们就会独立地运行,不依赖于Master节点的状态。即使Master节点发生故障,Worker节点仍然可以继续执行已经接收到的任务,因为它们已经获取了执行任务所需的资源和数据。
- 作业的元数据和状态信息:Spark的作业元数据和状态信息通常存储在外部的持久化存储中,如HDFS或数据库中。这些信息包括作业的执行计划、任务的状态、作业的进度等。即使Master节点发生故障,这些信息仍然可以被保留,并且可以在新的Master节点上进行恢复和管理。
综上所述,Spark的Master节点的故障转移过程不会影响已有的作业运行,因为作业的执行是由Worker节点独立完成的,并且作业的元数据和状态信息可以在故障转移后进行恢复和管理。这种设计使得Spark集群具有高可用性和容错性,能够保证作业的稳定运行。
52、Spark master如何通过Zookeeper做HA?
Spark的Master节点可以通过ZooKeeper来实现高可用性(HA)。下面是Spark Master节点通过ZooKeeper实现HA的详细过程:
- ZooKeeper的安装和配置:首先,需要在Spark集群中安装和配置ZooKeeper。ZooKeeper是一个分布式协调服务,用于管理集群中的各个节点和数据。
- Master节点的注册:当Spark的Master节点启动时,它会向ZooKeeper注册自己的信息,包括主机名、端口号和其他必要的元数据。这样,ZooKeeper就知道了Master节点的存在。
- 主节点选举:在ZooKeeper中,可以设置一个临时的有序节点(EPHEMERAL_SEQUENTIAL),用于表示Master节点的候选人。所有的Master节点都会尝试创建这个临时节点,并在节点上记录自己的ID。ZooKeeper会根据节点的创建顺序和ID来选举出一个主节点。
- 主节点的选举过程:当Master节点启动并注册到ZooKeeper后,它会检查是否已经存在一个主节点。如果不存在,则它会尝试创建一个临时节点,并成为主节点。如果已经存在主节点,则当前的Master节点会成为备用节点,并监听主节点的状态。
- 备用节点的监听和故障转移:备用节点会监听主节点的状态变化。如果主节点发生故障,ZooKeeper会自动将备用节点提升为新的主节点。此时,备用节点将接管Master节点的角色,并继续管理作业的调度和资源分配。
- 元数据的保存和监听:除了主节点的选举外,Spark还会将其他重要的元数据信息保存在ZooKeeper中,如Worker节点的注册信息、Application的注册信息等。这些信息的保存和监听可以实现Master节点的故障转移和其他组件与Master节点的通信和协调。
通过以上步骤,Spark的Master节点可以利用ZooKeeper来实现高可用性。当当前的Master节点发生故障时,ZooKeeper会自动选举出新的Master节点,并且已有的作业不会受到影响。这种方式可以确保Spark集群的稳定运行和容错性。
53、如何配置Spark master的HA?
要配置Spark Master的高可用性(HA),可以使用ZooKeeper来实现。以下是配置Spark Master HA的步骤:
- 安装和配置ZooKeeper:首先,需要安装和配置ZooKeeper集群。确保ZooKeeper集群正常运行,并且可以通过客户端连接到集群。
- 配置Spark Master:在Spark Master节点上,编辑
spark-env.sh文件,设置以下参数:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=<ZooKeeper连接地址>"
其中,
<ZooKeeper连接地址>
是ZooKeeper集群的连接地址,例如
zk1:2181,zk2:2181,zk3:2181
。
- 启动Spark Master:启动Spark Master节点,Spark Master将会自动连接到ZooKeeper集群,并在ZooKeeper中注册自己的信息。
- 配置Spark Worker:在每个Spark Worker节点上,编辑
spark-env.sh文件,设置以下参数:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=<ZooKeeper连接地址>"
同样,
<ZooKeeper连接地址>
是ZooKeeper集群的连接地址。
- 启动Spark Worker:启动每个Spark Worker节点,它们将自动连接到ZooKeeper集群,并在ZooKeeper中注册自己的信息。
- 启动Spark Application:在提交Spark应用程序时,确保使用
--master参数指定Spark Master的URL,例如:
spark-submit --master spark://<Spark Master地址>:<Spark Master端口> ...
其中,
<Spark Master地址>
是Spark Master节点的地址,
<Spark Master端口>
是Spark Master节点的端口。
通过上述步骤,配置了Spark Master的高可用性。当Spark Master节点发生故障时,ZooKeeper将会感知到并触发故障转移,将Master角色转移到另一个可用的节点上。这样可以确保Spark应用程序的持续运行和高可用性。
54、对于Spark中的数据倾斜问题你有什么好的方案?
在Spark中,数据倾斜是指在数据处理过程中,某些分区的数据量远远超过其他分区,导致任务执行时间延长或者任务失败。解决数据倾斜问题可以采取以下几种方案:
- 随机前缀:对于可能导致数据倾斜的键进行随机前缀处理,将原本可能集中在某个分区的数据均匀分散到多个分区中。这种方法可以通过在键前添加随机字符串或者随机数来实现。
- 扩容分区:对于数据倾斜的分区,可以考虑将其拆分成多个小分区,以增加并行度。可以使用repartition或者coalesce方法来重新分区。
- 聚合优化:对于需要进行聚合操作的场景,可以先对数据进行预聚合,将数据量减少到一个可接受的范围,然后再进行全局聚合。
- 广播变量:如果数据倾斜是由于某个较小的数据集引起的,可以将该数据集使用广播变量的方式分发到所有的Executor上,避免数据重复加载。
- 分桶和排序:对于连接操作或者聚合操作中的数据倾斜问题,可以通过对数据进行分桶和排序来解决。将数据按照某个特定的列进行分桶,然后在连接或者聚合时,只对相同桶中的数据进行操作。
- 动态调整资源:如果在任务执行过程中发现某个分区的数据量过大,可以动态调整资源,增加该分区的处理能力,以加快任务的执行速度。
以上是一些常见的解决数据倾斜问题的方法,具体应该根据实际情况选择合适的方案。在实际应用中,可能需要结合多种方法来解决复杂的数据倾斜问题。
55、Spark使用parquet文件存储格式能带来哪些好处?
Spark使用Parquet文件存储格式可以带来以下几个好处:
- 高效的压缩和编码:Parquet文件采用了列式存储的方式,将同一列的数据存储在一起,可以更好地利用压缩算法和编码方式。这样可以大大减小数据的存储空间,降低磁盘IO和网络传输的开销。
- 列式存储和投影扫描:Parquet文件的列式存储方式使得Spark可以只读取需要的列,而不必读取整个数据集。这种投影扫描的方式可以大大减少IO和内存的开销,提高查询性能。
- 谓词下推和统计信息:Parquet文件存储了每个列的统计信息,包括最小值、最大值、空值数量等。Spark可以利用这些统计信息进行谓词下推,即在读取数据时根据查询条件过滤掉不符合条件的数据,减少数据的读取量和处理量。
- 列式压缩和编码:Parquet文件支持多种压缩算法和编码方式,例如Snappy、Gzip、LZO等。Spark可以根据需求选择适合的压缩算法和编码方式,以平衡存储空间和查询性能。
- 数据模式和架构演化:Parquet文件存储了数据的模式信息,包括列名、数据类型、架构等。这使得Spark可以在读取数据时自动推断数据的模式,而不需要提前定义模式。同时,Parquet文件还支持架构演化,即在数据更新时可以增加、删除或修改列,而不需要重新创建整个数据集。
综上所述,Spark使用Parquet文件存储格式可以提供高效的压缩和编码、列式存储和投影扫描、谓词下推和统计信息、列式压缩和编码,以及数据模式和架构演化等好处,从而提高数据存储和查询的性能。
56、Spark累加器有哪些特点?
Spark累加器是一种用于在分布式计算中进行累加操作的特殊变量。以下是Spark累加器的几个特点:
- 分布式计算:Spark累加器可以在分布式环境中进行并行计算。它可以在集群中的多个节点上并行更新和累加值。
- 只写:累加器的值只能增加,不能减少或修改。它们用于收集和聚合分布式计算中的统计信息。
- 容错性:Spark累加器具有容错性,即使在节点故障的情况下也可以保持正确的计算结果。如果节点失败,Spark可以自动重新计算丢失的部分。
- 分布式共享变量:累加器是一种分布式共享变量,可以在分布式任务之间共享和传递。这使得可以在不同的任务中更新和使用累加器的值。
- 惰性计算:Spark累加器是惰性计算的,只有在执行动作操作时才会真正计算累加器的值。这样可以减少不必要的计算开销。
总之,Spark累加器是一种在分布式环境中进行累加操作的特殊变量,具有分布式计算、容错性和惰性计算等特点。它们在统计和聚合分布式计算中非常有用。
57、在一个不确定的数据规模的范围内进行排序可以采用以下几种方法:
- 内存排序:如果数据规模较小,可以将所有数据加载到内存中进行排序。这种方法简单快速,适用于能够一次性加载到内存的数据集。
- 外部排序:当数据规模较大,无法一次性加载到内存时,可以采用外部排序算法。外部排序将数据划分为多个较小的块,并在磁盘上进行排序和合并操作。外部排序的优点是可以处理大规模数据,但需要额外的磁盘空间和IO操作。- 首先,将数据分割成适当大小的块,并将每个块加载到内存中进行排序。- 然后,使用归并排序等算法将排序好的块逐一合并,直到得到完整排序的结果。
- 分布式排序:对于超大规模的数据,可以采用分布式排序算法。分布式排序将数据分布在多台计算机上进行并行排序和合并。分布式排序可以充分利用集群的计算资源,高效地处理大规模数据。- 首先,将数据划分为多个分区,并将每个分区分配给不同的计算节点。- 每个节点独立对自己负责的数据分区进行排序。- 最后,使用归并排序等算法将各个节点的排序结果合并成最终的全局排序结果。
无论使用哪种方法,在不确定数据规模的情况下,都需要考虑内存和磁盘的限制,选择适当的算法和数据分割策略,以实现高效的排序操作。
58、Spark如何自定义partitioner分区器?
在Spark中,可以通过自定义分区器(Partitioner)来控制数据在RDD或DataFrame中的分布方式。分区器决定了数据如何在集群中的不同节点上进行分片和分发。
要自定义分区器,需要创建一个继承自
org.apache.spark.Partitioner
类的新类,并实现其中的方法。下面是一个简单的示例:
import org.apache.spark.Partitioner
class CustomPartitioner(numPartitions: Int) extends Partitioner {
override def numPartitions: Int = numPartitions
override def getPartition(key: Any): Int = {
// 自定义分区逻辑
// 返回一个整数,表示分区的索引
}
override def equals(other: Any): Boolean = other match {
case customPartitioner: CustomPartitioner =>
customPartitioner.numPartitions == numPartitions
case _ =>
false
}
override def hashCode(): Int = numPartitions
}
在上面的示例中,
CustomPartitioner
类接受一个
numPartitions
参数,用于指定分区的数量。然后,需要实现
numPartitions
方法,返回分区的数量;
getPartition
方法,根据数据的键(key)返回分区的索引;
equals
方法和
hashCode
方法,用于比较分区器的相等性。
自定义分区器的使用方式取决于你正在使用的Spark组件。例如,如果你使用的是RDD,可以在调用
partitionBy
方法时指定自定义分区器,如下所示:
val rdd = ...
val customPartitioner = new CustomPartitioner(10)
val partitionedRDD = rdd.partitionBy(customPartitioner)
如果你使用的是DataFrame或Dataset,可以在调用
repartition
或
coalesce
方法时指定自定义分区器,如下所示:
val df = ...
val customPartitioner = new CustomPartitioner(10)
val partitionedDF = df.repartition(customPartitioner)
通过自定义分区器,你可以根据自己的需求控制数据的分布,以便更好地利用集群资源并提高计算性能。
59、说说spark hashParitioner的弊端是什么?
Spark的
HashPartitioner
是一种常用的分区器,它根据键的哈希值将数据分布到不同的分区中。虽然
HashPartitioner
在许多情况下都能提供良好的性能,但它也存在一些弊端,具体如下:
- 数据倾斜:
HashPartitioner使用键的哈希值来确定分区索引,如果数据中的某些键的哈希值分布不均匀,就会导致数据倾斜问题。这意味着一些分区可能会比其他分区更大,从而导致负载不平衡和计算性能下降。 - 无法保证有序性:
HashPartitioner将数据根据哈希值分散到不同的分区中,这意味着相同键的数据可能会分散到不同的分区中,无法保证数据的有序性。在某些场景下,需要保持数据的有序性,这就需要使用其他类型的分区器。 - 分区数量固定:
HashPartitioner在创建时需要指定分区的数量,这意味着分区数量是固定的。在某些情况下,数据规模可能会发生变化,需要动态调整分区数量来更好地利用集群资源,但HashPartitioner无法满足这种需求。
总的来说,
HashPartitioner
在一些常见场景下表现良好,但在数据倾斜、有序性和动态调整分区数量等方面存在一些限制。在这些情况下,可能需要考虑使用其他类型的自定义分区器来解决这些问题。
60、Spark读取数据,是几个Partition呢?
在Spark中,数据的分区数量取决于数据源和集群的配置。当使用Spark读取数据时,可以通过以下几个因素来确定数据的分区数量:
- 数据源的分区情况:不同的数据源在读取数据时会有不同的分区策略。例如,当从Hadoop分布式文件系统(HDFS)读取数据时,Spark会根据HDFS块的大小来确定分区数量。每个HDFS块通常对应一个分区。而当从数据库或其他数据源读取数据时,分区策略可能会有所不同。
- 数据源的切片数:Spark将数据源切分为多个切片,每个切片对应一个分区。切片的数量由Spark的
spark.sql.files.maxPartitionBytes和spark.sql.files.openCostInBytes等配置参数控制。这些参数可以调整以控制分区数量。 - 数据规模和集群资源:数据的大小和集群的资源配置也会影响数据的分区数量。如果数据较小,Spark可能会使用较少的分区。而如果数据较大,Spark可能会使用更多的分区来更好地利用集群资源。
需要注意的是,Spark并不保证每个数据分区都具有相同数量的数据。这取决于数据的分布情况和分区策略。有时候,数据可能会出现倾斜,导致某些分区比其他分区更大。
可以通过以下方式来查看数据的分区数量:
- 对于RDD:可以使用
getNumPartitions()方法获取RDD的分区数量。 - 对于DataFrame或Dataset:可以使用
rdd.getNumPartitions()方法获取底层RDD的分区数量。
需要注意的是,分区数量在读取数据时是动态确定的,并且可以根据数据源、配置和集群资源的不同而变化。因此,实际的分区数量可能会有所不同。
61、RangePartitioner分区的原理?
RangePartitioner是Spark中的一种分区器,用于将数据按照一定的范围进行分区。它的原理是根据数据的键值范围将数据划分到不同的分区中。
RangePartitioner的工作流程如下:
- 首先,RangePartitioner会对数据进行采样,以获取数据的键值范围。采样过程可以通过调用
RDD.sample方法来实现。 - 接下来,RangePartitioner会根据指定的分区数量,将键值范围划分为相应数量的区间。
- 然后,RangePartitioner会将数据按照键值范围划分到对应的分区中。具体的划分方式是根据数据的键值与区间的比较来确定数据所属的分区。
- 最后,RangePartitioner会返回一个分区器对象,可以将其应用到RDD或DataFrame中。在使用RDD时,可以通过调用
RDD.partitionBy方法,并传入RangePartitioner来进行分区;在使用DataFrame时,可以通过调用DataFrame.repartition方法,并传入RangePartitioner来进行分区。
RangePartitioner的优点是可以根据数据的键值范围进行分区,可以保证相同范围内的数据被划分到同一个分区中,从而提高数据的局部性。这对于一些需要按照键值范围进行聚合或排序的操作非常有用。
然而,RangePartitioner也存在一些限制。首先,它要求数据的键值范围是已知的,这对于一些动态生成的数据集可能不适用。其次,如果数据的分布不均匀,可能会导致某些分区的数据量过大或过小,从而影响计算性能。因此,在实际使用中,需要根据数据的特点选择合适的分区策略。
62、RangePartioner分区器特点?
RangePartitioner分区器具有以下特点:
- 基于范围划分:RangePartitioner根据数据的键值范围将数据划分到不同的分区中。它将键值范围划分为若干个区间,并将数据按照键值与区间的比较进行划分。
- 数据局部性:RangePartitioner会将相同范围内的数据划分到同一个分区中,从而提高数据的局部性。这对于一些需要按照键值范围进行聚合或排序的操作非常有用。
- 适用于有序数据:RangePartitioner适用于有序数据的分区。它可以保证相同范围内的数据被划分到同一个分区中,从而保持数据的有序性。
- 分区数量可控:RangePartitioner可以通过指定分区数量来控制数据的分区个数。这对于优化计算性能和资源利用非常重要。
- 采样获取范围:为了确定数据的键值范围,RangePartitioner会对数据进行采样。采样过程可以通过调用
RDD.sample方法来实现。 - 需要键值范围已知:RangePartitioner要求数据的键值范围是已知的,这对于一些动态生成的数据集可能不适用。
- 可应用于RDD和DataFrame:RangePartitioner可以应用于RDD和DataFrame。在使用RDD时,可以通过调用
RDD.partitionBy方法,并传入RangePartitioner来进行分区;在使用DataFrame时,可以通过调用DataFrame.repartition方法,并传入RangePartitioner来进行分区。
需要注意的是,RangePartitioner也存在一些限制。如果数据的分布不均匀,可能会导致某些分区的数据量过大或过小,从而影响计算性能。因此,在使用RangePartitioner时,需要根据数据的特点选择合适的分区策略。
63、介绍parition和block有什么关联关系?
在Spark中,Partition(分区)和Block(块)是两个不同的概念,但它们之间存在一定的关联关系。
Partition(分区)是将数据集拆分为较小、可并行处理的数据块的过程。在Spark中,数据集被划分为多个分区,每个分区包含数据的一个子集。每个分区都可以在集群中的不同节点上进行并行处理。
而Block(块)是Spark中数据存储和传输的基本单位。在Spark中,数据被划分为多个块,每个块的大小通常为128MB。每个块都会被存储在集群中的不同节点上,并且可以在节点之间进行传输和共享。
Partition和Block之间的关联关系在数据处理过程中体现出来。当Spark执行任务时,每个分区的数据会被加载到对应节点的内存中,并以块的形式进行存储。这样可以提高数据的读取和处理效率,因为每个节点只需要加载和处理自己负责的分区数据块。
此外,Spark还使用Partition和Block之间的关联关系来进行数据的本地性调度。Spark会尽量将任务调度到与数据所在的分区块相同的节点上执行,以减少数据传输的开销,并提高任务的执行效率。
总结起来,Partition和Block之间的关联关系可以简单描述为:Partition是数据集的逻辑划分,而Block是数据的物理存储和传输单位,二者配合使用可以提高数据处理的效率和性能。
64、什么是二次排序,你是如何用spark实现二次排序的?(互联网公司常面)
二次排序(Secondary Sorting)是指在对数据进行排序时,除了主排序键(Primary Key)外,还需要对次要排序键(Secondary Key)进行排序。在Spark中,可以使用自定义排序函数和自定义分区器来实现二次排序。
要实现二次排序,首先需要定义一个包含主排序键和次要排序键的元组作为数据的键。然后,可以使用
sortByKey()
函数对键值对进行排序。在排序时,可以通过自定义的排序函数来指定主排序键和次要排序键的排序规则。
下面是一个使用Spark实现二次排序的示例代码:
# 创建一个包含主排序键和次要排序键的键值对RDD
data = [(1, 4), (2, 2), (1, 2), (2, 1), (1, 3)]
rdd = sc.parallelize(data)
# 自定义排序函数,按照主排序键升序、次要排序键降序排序
def custom_sort(key):
primary_key, secondary_key = key
return (primary_key, -secondary_key)
# 使用sortByKey函数进行二次排序
sorted_rdd = rdd.sortByKey(keyfunc=custom_sort)
# 输出排序结果
sorted_data = sorted_rdd.collect()
for key, value in sorted_data:
print(key, value)
在上述代码中,我们创建了一个包含主排序键和次要排序键的键值对RDD。然后,定义了一个自定义排序函数
custom_sort
,该函数按照主排序键升序、次要排序键降序的规则进行排序。最后,使用
sortByKey()
函数对RDD进行排序,并输出排序结果。
通过自定义排序函数,我们可以实现对数据的二次排序,根据需要对主排序键和次要排序键进行灵活的排序规则定义。
65、如何使用Spark解决TopN问题?(互联网公司常面)
在Spark中,解决TopN问题通常涉及以下几个步骤:
- 加载数据:首先,你需要加载数据到Spark中。你可以使用
textFile方法加载文本文件,或者使用其他适合你数据格式的方法加载数据。 - 数据预处理:根据你的需求,对数据进行必要的预处理。这可能包括数据清洗、转换和过滤等操作。
- 数据转换:将数据转换为键值对的形式,其中键是你要进行TopN操作的字段,值是与该字段相关的其他数据。你可以使用
map或者flatMap方法来实现这个步骤。 - 按键分组:使用
groupByKey方法将数据按键进行分组。这将把具有相同键的数据分组到一起。 - 计算TopN:对每个键的数据进行处理,以获取TopN结果。你可以使用
mapValues方法结合排序操作来实现这一步骤。例如,你可以使用takeOrdered方法获取每个键的前N个元素。 - 合并结果:如果你需要获得全局的TopN结果,你需要将每个分区的TopN结果进行合并。你可以使用
reduceByKey方法来合并分区结果。
下面是一个示例代码,演示了如何使用Spark解决TopN问题:
# 导入必要的模块
from pyspark import SparkContext
# 创建SparkContext
sc = SparkContext("local", "TopN Example")
# 加载数据
data = sc.textFile("data.txt")
# 数据预处理和转换
key_value_pairs = data.map(lambda line: (line.split(",")[0], line.split(",")[1]))
# 按键分组
grouped_data = key_value_pairs.groupByKey()
# 计算TopN
topN_results = grouped_data.mapValues(lambda values: sorted(values, reverse=True)[:N])
# 合并结果
global_topN_results = topN_results.reduceByKey(lambda x, y: x + y)
# 打印结果
print(global_topN_results.collect())
# 停止SparkContext
sc.stop()
在上面的示例代码中,我们假设数据文件
data.txt
的每一行都是以逗号分隔的键值对。首先,我们加载数据并进行预处理和转换,然后按键分组。接下来,我们对每个键的数据进行排序,并使用
takeOrdered
方法获取前N个元素。最后,我们使用
reduceByKey
方法将每个分区的结果进行合并,得到全局的TopN结果。
请根据你的具体需求调整代码,并根据你的数据格式和数据处理逻辑进行相应的修改。
66、如何使用Spark解决分组排序问题?(互联网公司常面)
要使用Spark解决分组排序问题,可以按照以下步骤进行操作:
一、创建SparkSession:
首先,需要创建一个SparkSession对象,作为与Spark交互的入口点。可以使用以下代码创建SparkSession:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("GroupBy and Sort") \
.getOrCreate()
二、加载数据:
接下来,需要加载包含要排序的数据的DataFrame。可以使用
spark.read
方法从不同的数据源(例如CSV、JSON、数据库等)加载数据。以下是一个加载CSV文件的示例:
df = spark.read.csv("path/to/data.csv", header=True, inferSchema=True)
三、执行分组排序:
使用Spark的DataFrame API,可以使用
groupBy
和
orderBy
方法来实现分组排序。首先,使用
groupBy
方法按照要分组的列进行分组,然后使用
orderBy
方法按照要排序的列进行排序。以下是一个示例:
from pyspark.sql.functions import desc
sorted_df = df.groupBy("group_column").orderBy(desc("sort_column"))
在上面的示例中,假设要按照"group_column"列进行分组,并按照"sort_column"列进行降序排序。
四、显示结果:
最后,可以使用
show
方法来显示排序后的结果。以下是一个示例:
sorted_df.show()
这将在控制台上显示排序后的结果。
注意事项:
- 如果要对多个列进行排序,可以在
orderBy方法中传递多个列名。 - 如果要按照升序排序而不是降序排序,可以使用
asc方法代替desc方法。 - 在执行分组排序之前,确保DataFrame中包含正确的列名和数据类型。
这是使用Spark解决分组排序问题的一般步骤。根据具体的需求,可以根据需要进行进一步的数据转换和操作。
67、Hadoop中,Mapreduce操作的mapper和reducer阶段相当于spark中的哪几个算子?
在Hadoop中,MapReduce操作的Mapper和Reducer阶段可以与Spark中的多个算子进行对应。下面是对应关系的详细解释:
一、Mapper阶段:
- 在Hadoop中,Mapper阶段负责对输入数据进行切分和映射操作。它将输入数据分割成小的数据块,并为每个数据块生成键值对。
- 在Spark中,可以使用
map算子来实现类似的功能。map算子会对输入RDD中的每个元素应用一个函数,生成一个新的RDD。
二、Reducer阶段:
- 在Hadoop中,Reducer阶段负责对Mapper阶段输出的键值对进行合并和归约操作,生成最终的输出结果。
- 在Spark中,可以使用
reduceByKey或groupByKey算子来实现类似的功能。reduceByKey算子会将具有相同键的值进行合并,而groupByKey算子会将具有相同键的值进行分组。
需要注意的是,Spark的数据处理模型与Hadoop的MapReduce模型不同。Spark的数据处理模型是基于弹性分布式数据集(RDD)的,而不是基于键值对的。因此,在Spark中,可以使用更多的算子来进行数据转换和操作,例如
filter
、
flatMap
、
join
等。
总结起来,Mapper阶段可以使用Spark的
map
算子,而Reducer阶段可以使用Spark的
reduceByKey
或
groupByKey
算子。但是,需要注意的是,Spark中的算子更加灵活,可以进行更多种类的数据操作和转换。
68、Spark shell启动时会启动derby?
在Spark中,Derby是一个内置的关系型数据库,用于支持Spark的元数据存储和管理。当你启动Spark Shell时,它会自动启动Derby数据库作为元数据存储的后端。
Derby数据库是一个轻量级的Java数据库,它可以在本地模式下运行,不需要额外的配置或安装。Spark使用Derby数据库来存储关于Spark应用程序的元数据信息,包括表结构、数据源连接信息、执行计划等。
当你启动Spark Shell时,它会在本地启动一个Derby数据库实例,并将元数据存储在该实例中。这个Derby实例是与Spark Shell进程绑定的,当你退出Spark Shell时,Derby数据库也会随之关闭。
通过Derby数据库,Spark可以方便地管理和查询元数据信息,例如可以使用Spark的SQL语法来查询表结构、执行计划等。此外,Derby还支持事务处理和并发控制,确保对元数据的修改是安全和一致的。
总之,Spark Shell启动时会自动启动Derby数据库作为元数据存储的后端,这使得Spark能够方便地管理和查询应用程序的元数据信息。
69、介绍一下你对Unified Memory Management内存管理模型的理解?
Unified Memory Management(统一内存管理)是一种内存管理模型,它在计算机系统中统一了CPU和GPU之间的内存管理。传统上,CPU和GPU拥有各自独立的内存空间,数据需要在它们之间进行显式的复制。而在Unified Memory Management模型中,CPU和GPU共享同一块内存,数据可以在CPU和GPU之间自动进行迁移,无需显式的复制操作。
在Unified Memory Management模型中,程序员可以将内存分配给CPU和GPU使用,并通过简单的标记来指示数据在CPU和GPU之间的访问模式。当CPU或GPU需要访问数据时,系统会自动将数据从一个设备迁移到另一个设备。这种自动的数据迁移使得程序员可以更方便地编写跨设备的并行代码,而无需手动管理数据的复制和迁移。
使用Unified Memory Management模型可以简化并行编程,并提高代码的可移植性和性能。程序员可以更容易地利用GPU的并行计算能力,而无需关注数据的复制和迁移。同时,系统可以根据数据的访问模式进行智能的数据迁移,以提高访问数据的效率。
总之,Unified Memory Management模型通过统一CPU和GPU之间的内存管理,简化了并行编程,并提高了代码的可移植性和性能。
70、HBase预分区个数和Spark过程中的reduce个数相同么
HBase的预分区个数和Spark过程中的reduce个数不一定相同。它们是两个不同的概念,分别用于不同的目的。
- HBase的预分区个数:HBase是一个分布式的NoSQL数据库,它使用行键(Row Key)来进行数据的存储和索引。为了实现数据的负载均衡和高效查询,HBase会将数据分散存储在不同的Region中。在创建HBase表时,可以指定表的预分区个数,也称为Region个数。预分区个数决定了HBase表在集群中的分布情况,可以根据数据的特点和负载要求进行调整。
- Spark过程中的reduce个数:在Spark中,reduce是指对数据进行聚合操作的阶段,通常是在MapReduce模型中的reduce阶段。在Spark中,reduce的个数由数据的分区数决定,每个分区都会有一个reduce任务。分区数可以通过调整RDD的分区策略或使用
repartition、coalesce等操作来进行控制。reduce的个数影响了并行计算的程度,可以根据数据量和计算资源进行调整。
虽然HBase的预分区个数和Spark过程中的reduce个数可以相互关联,但它们并不是一一对应的关系。HBase的预分区个数主要用于数据的存储和负载均衡,而Spark的reduce个数主要用于计算的并行度控制。在实际应用中,可以根据数据的特点和计算需求来调整它们的个数,以达到最佳的性能和效果。
版权归原作者 之乎者也· 所有, 如有侵权,请联系我们删除。