
文章目录
一、重点内容:
1.数据库基本概念
2.列式存储
3.clickHouse存储设计
4.clickHouse典型应用场景
二、准备工作:
1、了解数据库基本概念
- 数据库
- DBMS:数据库管理系统
- OLTP 数据库 : OLTP(Online transactional processing)
- OLAP 数据库:OLAP (Online analytical processing)
- SQL (Structured Query Language)
- 词法分析
- 语法分析
- AST (Abstract syntax tree)
2、了解列式存储相关概念
- 行式存储
- 列式存储
- 数据压缩> a. LZ4> > b. Run-length encoding> > c. Delta encoding
- 延迟物化> a. 物化> > b. Cpu cache> > c. 内存带宽
- 向量化> a. SIMD (single instruction multiple data)> > b. SSE指令集> > c. AVX指令集
3、了解ClickHouse存储设计
- Shard key
- 索引> a. 哈希索引> > b. B-Tree> > c. B+Tree> > d. LSM-Tree
4、了解 ClickHouse典型应用场景
- Kafka
- Spark
- Hdfs
- Bitmap
- 字典编码
三、详细知识点介绍:
1、数据库相关概念
定义:
数据库是结构化信息或数据的有序集合,一般以电子形式存储在计算机系统中。
数据库的类型:
方式一:
关系数据库:
关系型数据库是把数据以表的形式进行储存,然后再各个表之间建立关系,通过这些表之间的关系来操作不同表之间的数据。
非关系数据库:
NoSQL或非关系数据库,支持存储和操作非结构化及半结构化数据。相比于关系型数据库,NoSQL没有固定的表结构,且数据之间不存在表与表之间的关系,数据之间可以是独立的。
方式二:
单机数据库:
在一台计算机上完成数据的存储和查询的数据库系统。
分布式数据库:
分布式数据库由位于不同站点的两个或多个文件组成。数据库可以存储在多台计算机上,位于同一个物理位置,或分散在不同的网络上。
方式三:
OLTP数据库:
OLTP ( Online transactional processing)数据库是―种高速分析数据库,专为多个用户执行大量事务而设计。
OLAP数据库:
OLAP (Online analytical processing) 数据库旨在同时分析多个数据维度,帮助团队更好地理解其数据中的复杂关系
OLAP数据库:
特性:
1、大量数据的读写,PB级别的存储。
2、多维分析,复杂的聚合函数。
3、窗口函数,自定义UDF(User DefineFucntion)
4、离线/实时分析
数据库架构:
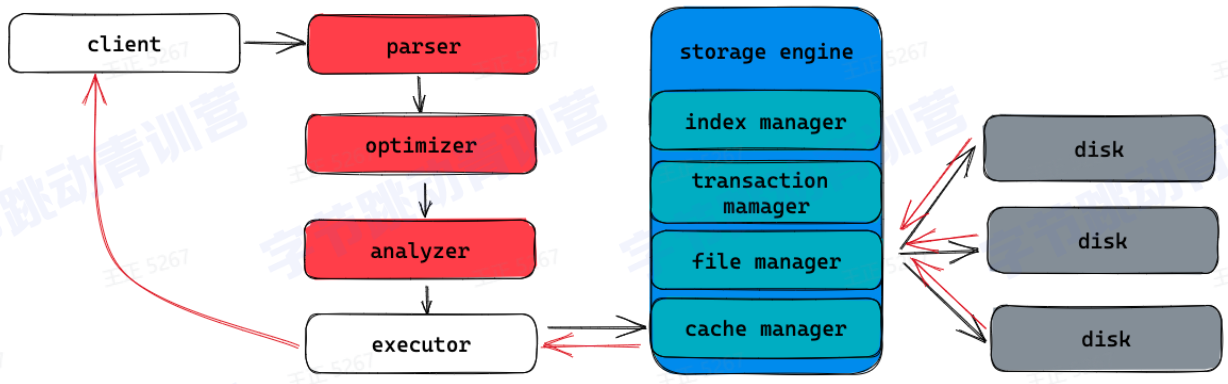
SQL的执行:
步骤:
1、Parser:词法分析,语法分析,生成AST树(Abstract syntax tree)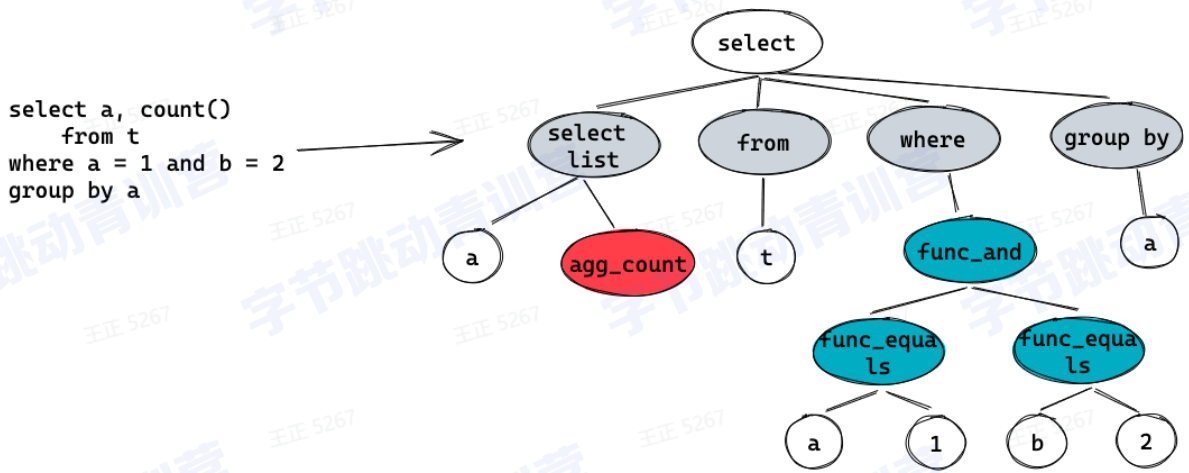
2、Analyzer:变量绑定、类型推导、语义检查、安全、权限检查、完整性检查等,为生成计划做准备
例如︰
判断a, b是不是类型正确。
a, b是不是来自表t。
group by字段是否合法,是否存在聚合函数。
3、Optimizer: 为查询生成性能最优的执行计划,进行代价评估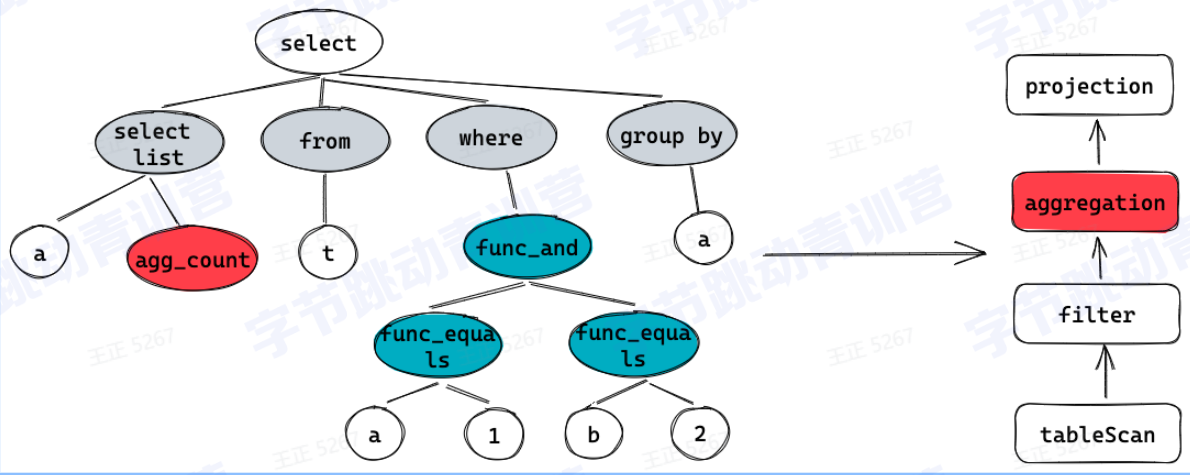
4、Executor: 将执行计划翻译成可执行的物理计划并驱动其执行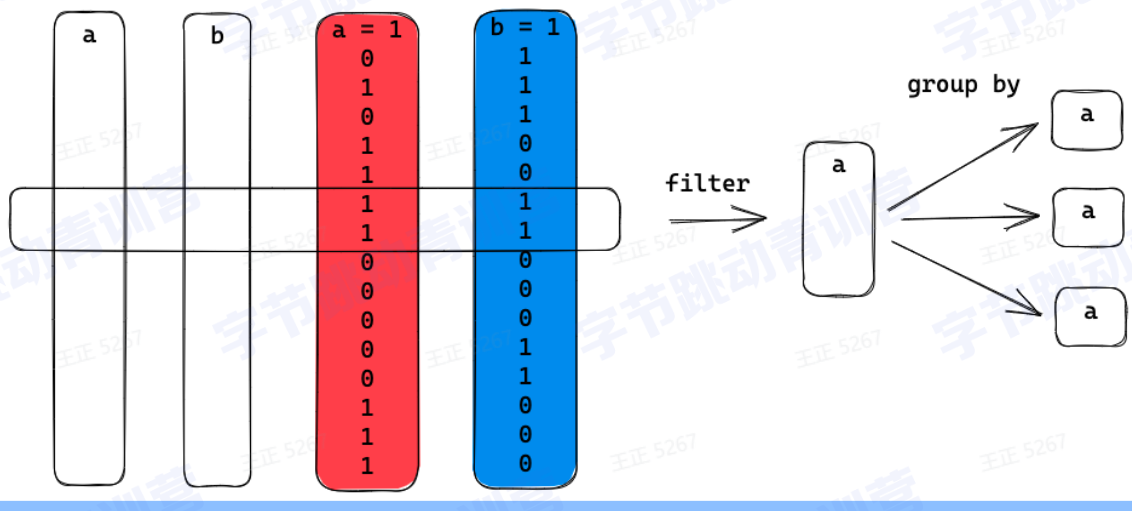
存储引擎作用:
1.管理内存数据结构
索引
内存数据
缓存:
Query cache
Data cache
lndex cache
2.管理磁盘数据
磁盘数据的文件格式磁盘数据的增删查改
3.读写算子
数据写入逻辑数据读取逻辑
2、列式存储
行式存储:
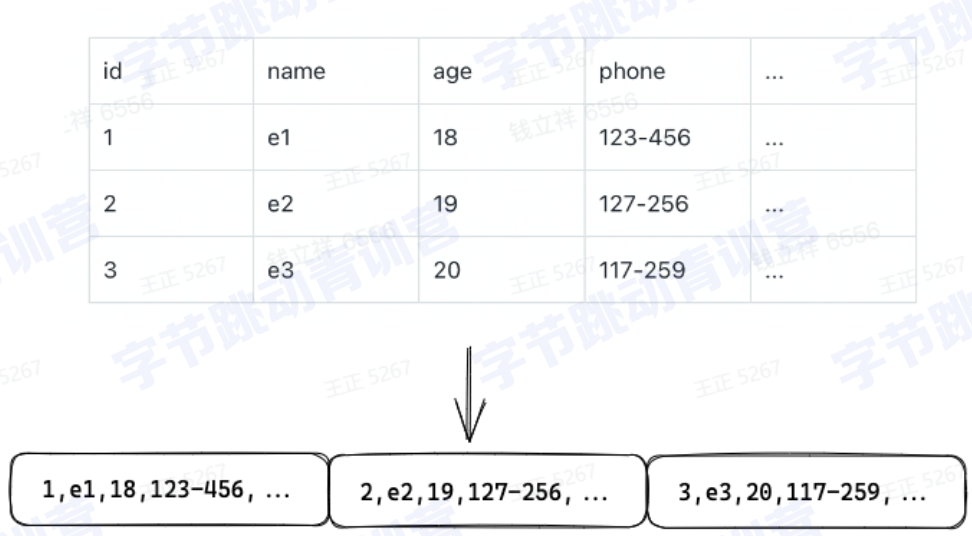
列式存储:

列式存储的优点:

数据压缩:
1、数据压缩可以使读的数据量更少.在IO密集型计算中获得更大的性能优势
2、相同类型压缩效率更高
3、排序之后压缩效率更高
4、可以针对不同类型使用不同的压缩算法
常见压缩算法:
1、LZ4:
(5,4)代表向前5个byte,匹配到的内容长度有4,即"bcde"是一个重复。
重复项越多或者越长,压缩率就会越高。

2、Run-length encoding:
压缩重复的数据
可以再压缩数据上直接计算

3、Delta encoding :
将数据存储为连续数据之间的差异,而不是直接存储数据本身
特定算子也能直接在压缩数据上计算

数据选择:
可以选择特定的列做计算而不是读所有列
对聚合计算友好
如图: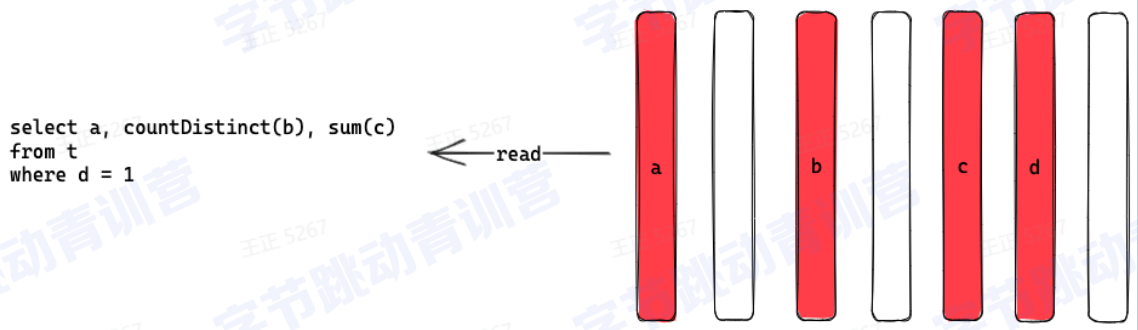
延迟物化:
物化:将列数据转换为可以被计算或者输出的行数据或者内存数据结果的过程,物化后的数据通常可以用来做数据过滤,聚合计算, Join。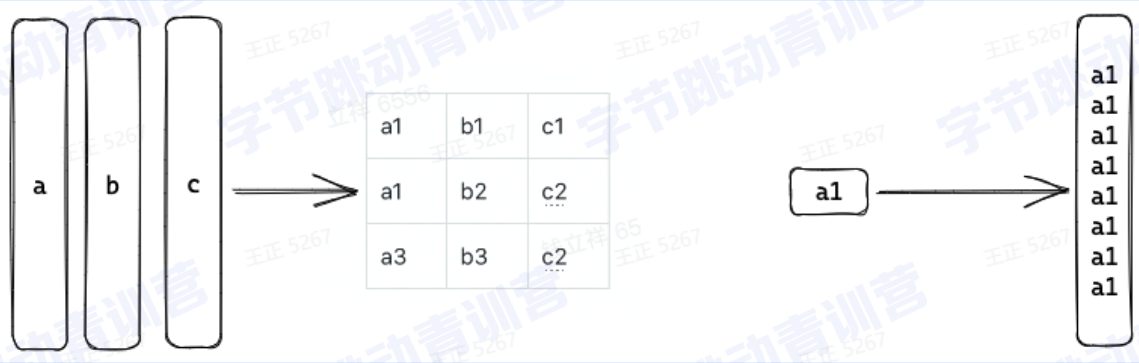
延迟物化:尽可能推迟物化操作的发生
3、ClickHouse存储设计
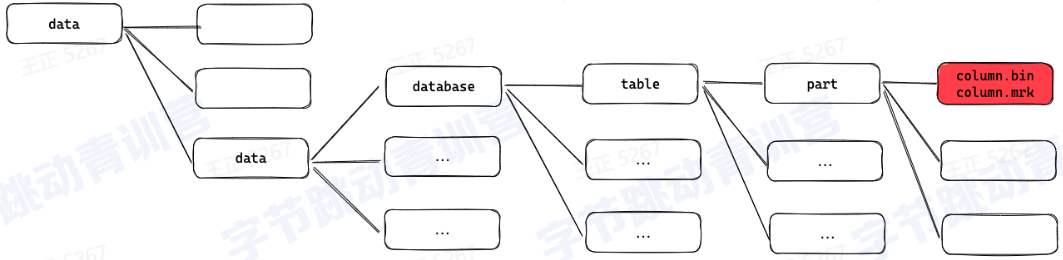
表定义和结构:

集群架构:
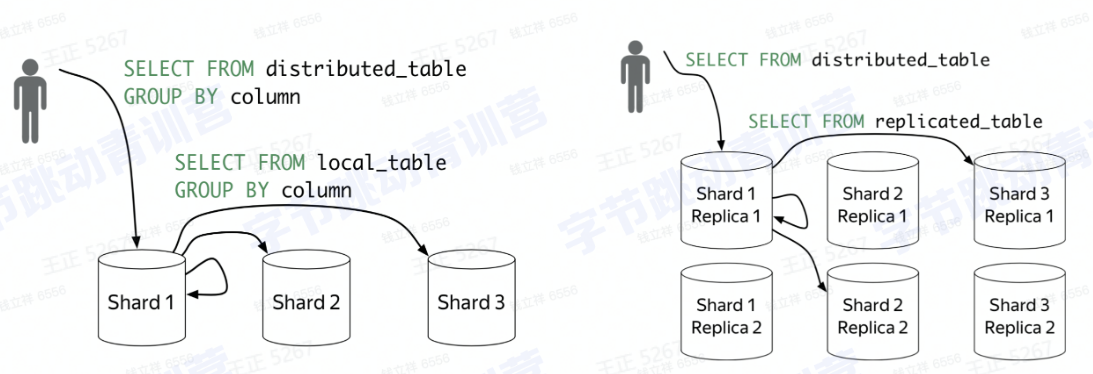
引擎架构:
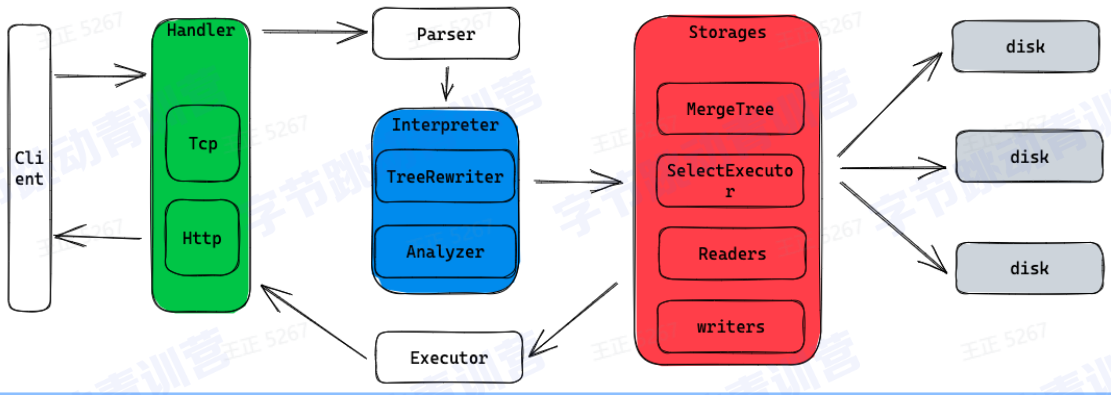
存储架构:
索引设计:
1、Hash lndex
1.将输入的key通过一个HashFunction映射到一组bucket上
2.每个bucket都包含一个指向一条记录的地址
3.哈希索引在查找的时候只适用于等值比较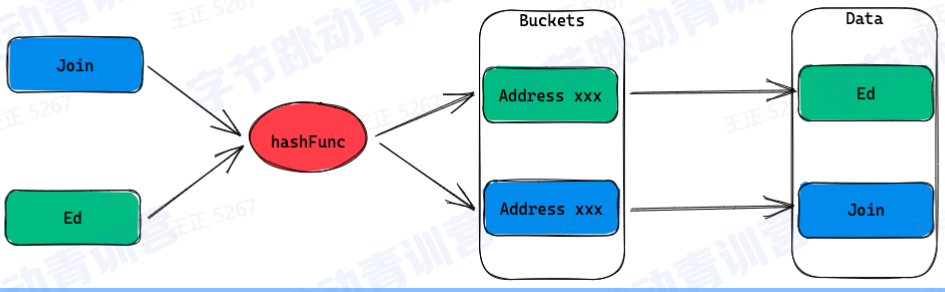
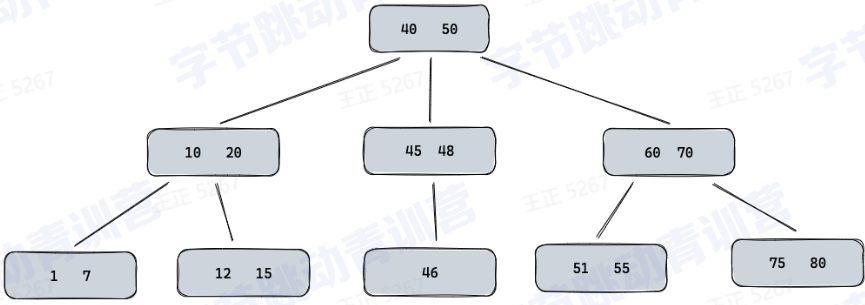
2、B-Tree
1.数据写入是有序的,支持增删查改
2.每个节点有多个孩子节点
3.每个节点都按照升序排列key值
4.每个key有两个指向左右孩子节点的引用
-左孩子节点保存的key都小于当前key
-右孩子节点的保存的key都大于当前key
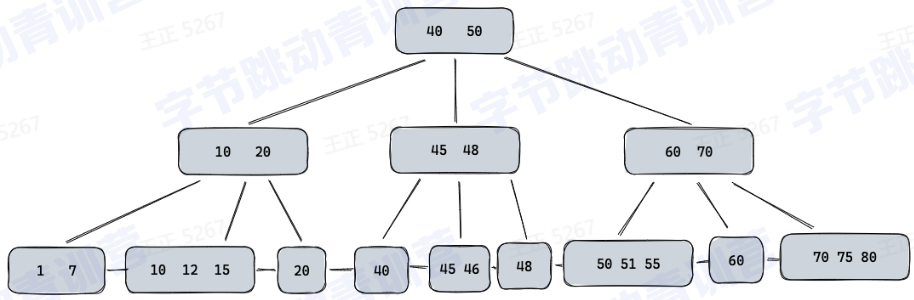
3、B+Tree
1.所有的数据都存储在叶子节点,非叶子节点只保存key值
2.叶子节点维护到相邻叶子节点的引用
3.可以通过key值做二分查找,也可以通过叶子节点做顺序访问
4、LSM-tree
Log-structured merge-tree (LSM tree)是一种为大吞吐写入场景而设计的数据结构
-着重优化顺序写入
-主要数据结构
1、SSTables
- Key按顺序存储到文件中,称为segment
- 包含多个segment
- 每个segment写入磁盘后都是不可更改的,新加的数据只能生成新的segment

2、Memtable
-在内存中的数据保存在memtable中,大多数实现都是―颗Binary search tree
-当memtable存储的数据到达一定的阈值的时候,就会按顺序写入到磁盘
LSM-tree的数据查询:
需要从最新的segment开始遍历每个key
也可以为每个segment建一个索引,例如下图: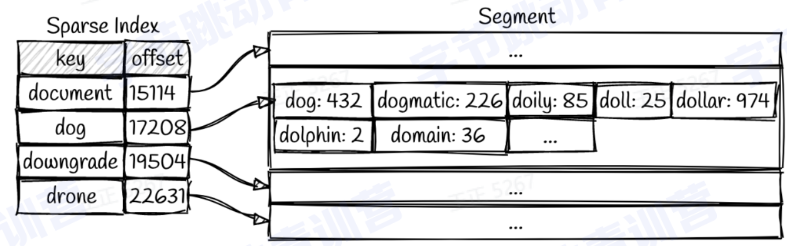
4、ClickHouse应用场景
1、大宽表存储和查询:
1.大宽表查询
-可以建非常多的列
-可以增加,删除,清空每—列的数据
-查询的时候引擎可以快速选择需要的列
-可以将列涉及到的过滤条件下推到存储层从而加速查询

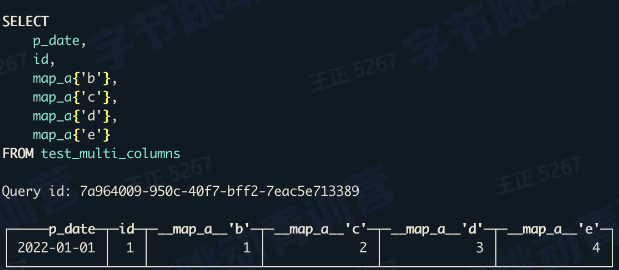
2、动态表结构
- map中的每个key都是一列
- map中的每一列都可以单独的查询
- 使用方式同普通列,可以做任何计算
2、离线数据分析
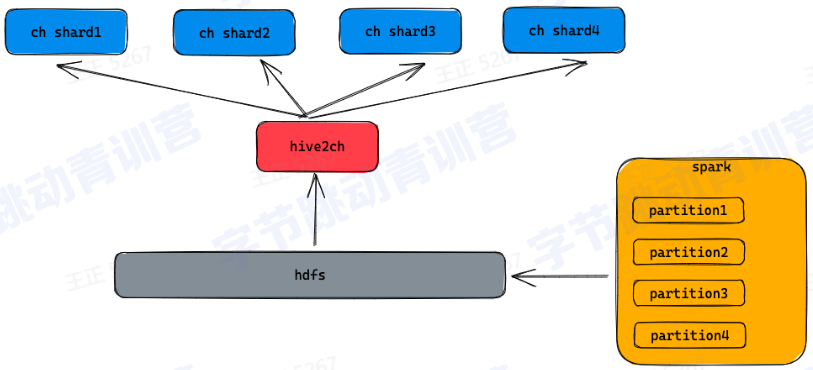
1.数据导入
-数据可以通过spark生成clickhouse格式的文件
-导入到hdfs上由hive2ch导入工具完成数据导入
-数据直接导入到各个物理节点
2.数据按列导入
保证查询可以及时访问已有数据
可以按需加载需要的列
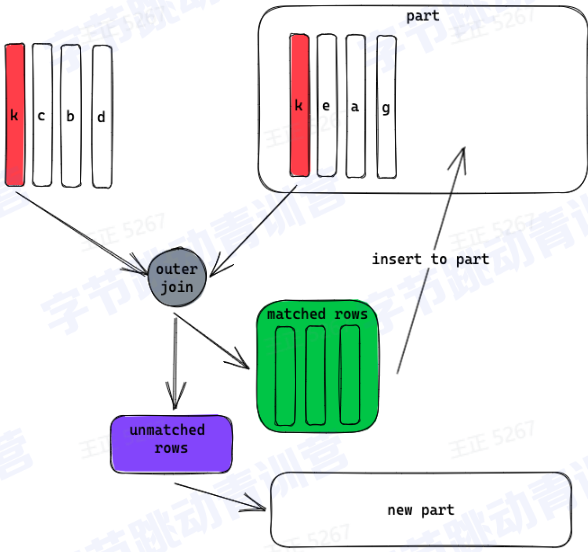
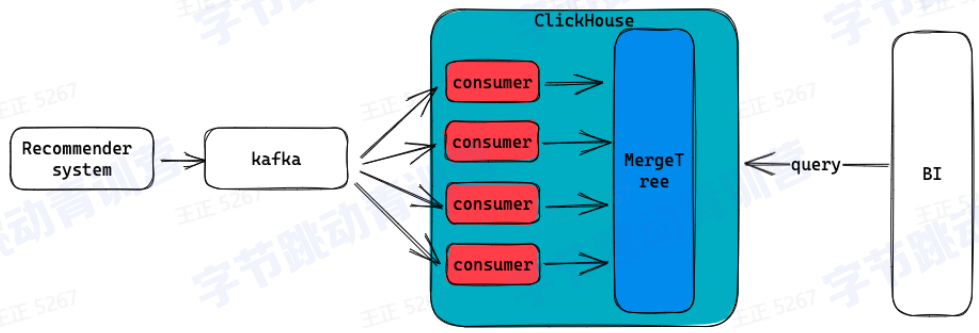
3、实时数据分析
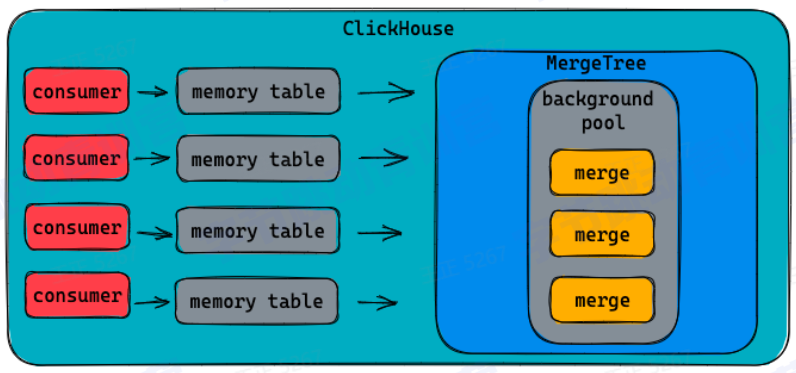
4、使用memory table减少parts数量
1.数据先缓存在内存中
2.到达—定阈值再写到磁盘
5、复杂类型查询:
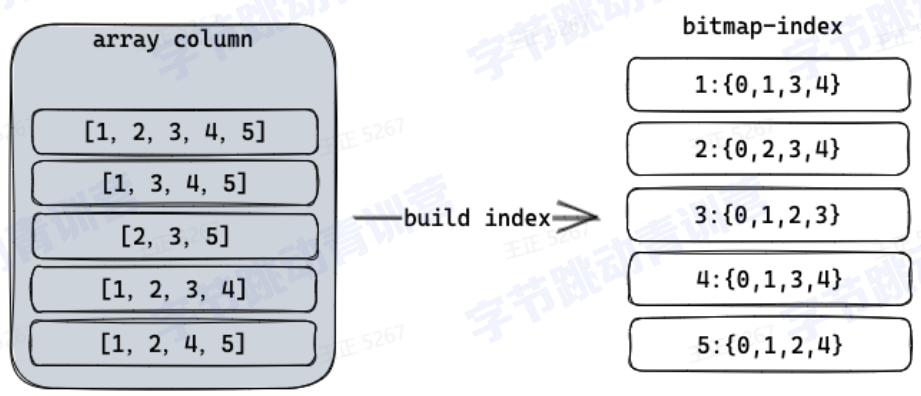
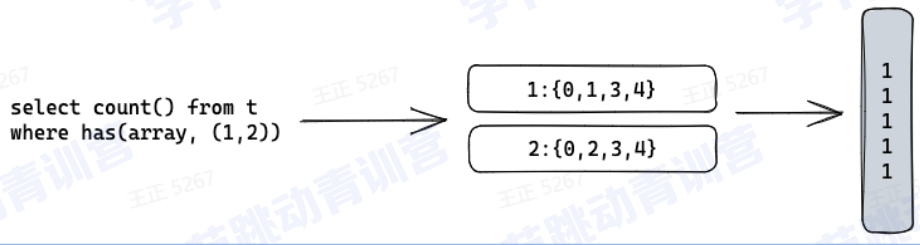
1、bitmap索引(构建)
2、bitmap索引(查询)
四、个人总结:
此次学习只要是借ClickHouse存储结构引出整个数据库的概念、原理、设计。终得到以下总结:ClickHouse是标准的列存结构;存储设计是LSM-Tree架构;使用稀疏索引加速查询;每个列都有丰富的压缩算法和索引结构;基于列存设计的高效的数据处理逻辑。
版权归原作者 爱打辅助的小可爱 所有, 如有侵权,请联系我们删除。