
作者:IT邦德
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
(Web\java\Python)工作,主要服务于生产制造
现拥有 Oracle 11g OCP/OCM、
Mysql、Oceanbase(OBCA)认证
分布式TBase\TDSQL数据库、国产达梦数据库以及红帽子认证
从业8年DBA工作,在数据库领域有丰富的经验
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
文章目录
前言
本文结合自己工作10年的积累,将Oracle的SQL性能的方法做了详细阐述
一、导读
正在参加博客之星活动,麻烦给个年度五星好评,谢谢!
https://bbs.csdn.net/topics/603955648
再次对您表示感谢,祝福新年快乐
一个好的运维团队,应该首先是一批好的开发工程师,当软件系统变得越来越复杂时
,主动承担起架构调整,系统调优,自动化等工作来帮助降低系统复杂度,优化系统
架构,提高系统可用性,下图为Oracle优化的进化论。

二、优化常识
2.1.显示执行计划方法
SYS@ORCL> SET AUTOTRACE TRACEONLY:只显示统计结果,不显示返回的结果集合
2.2.SQL执行计划
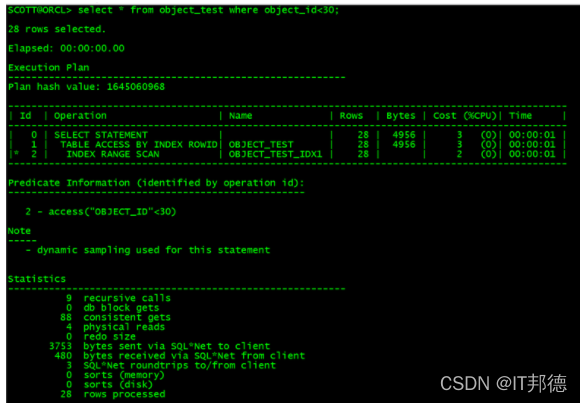
执行计划:一条查询语句在ORACLE中的执行过程或访问路径的描述。
即就是对一个查询任务,做出一份怎样去完成任务的详细方案。
如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,
看看SQL的每一步执行是否存在问题。
看懂执行计划也就成了SQL优化的先决条件。
通过执行计划定位性能问题,定位后就通过建立索引、修改sql等解决问题。
2.2.1 执行顺序的原则
执行顺序的原则是:由上至下,从右向左
由上至下:在执行计划中一般含有多个节点,
相同级别(或并列)的节点,靠上的优先执行,靠下的后执行
从右向左:在某个节点下还存在多个子节点,先从最靠右的子节点开始执行。
2.2.2 执行计划中字段解释
ID: 一个序号,但不是执行的先后顺序。执行的先后根据缩进来判断。
Operation: 当前操作的内容。
Rows: 当前操作的Cardinality,Oracle估计当前操作的返回结果集。
Cost(CPU):Oracle 计算出来的一个数值(代价),用于说明SQL执行的代价。
Time:Oracle 估计当前操作的时间。
在看执行计划的时候,除了看执行计划本身,
还需要看谓词和统计信息。 通过整体信息来判断SQL效率。
2.2.3 谓词说明
Access :
* 通过某种方式定位了需要的数据,然后读取出这些结果集,叫做Access。
* 表示这个谓词条件的值将会影响数据的访问路劲(表还是索引)。
Filter:
* 把所有的数据都访问了,然后过滤掉不需要的数据,这种方式叫做filter 。
* 表示谓词条件的值不会影响数据的访问路劲,只起过滤的作用。
在谓词中主要注意access,要考虑谓词的条件,使用的访问路径是否正确。
2.3 Statistics统计信息
CBO包含以下组件:查询转换器、评估器、计划生成器
recursive calls:产生的递归sql调用的条数。
Db block gets:从buffer cache中读取的block的数量
consistent gets:从buffer cache中读取的undo数据的block的数量
physical reads:从磁盘读取的block的数量
redo size:DML生成的redo的大小
bytes sent via SQL*Net to client:
数据库服务器通过SQL*Net向查询客户端发送的查询结果字节数
bytes received via SQL*Net from client:
通过SQL*Net接受的来自客户端的数据字节数
SQL*Net roundtrips to/from client:
服务器和客户端来回往返通信的Oracle Net messages条数
sorts (memory):在内存执行的排序量
sorts (disk):在磁盘上执行的排序量
rows processed:处理的数据的行数
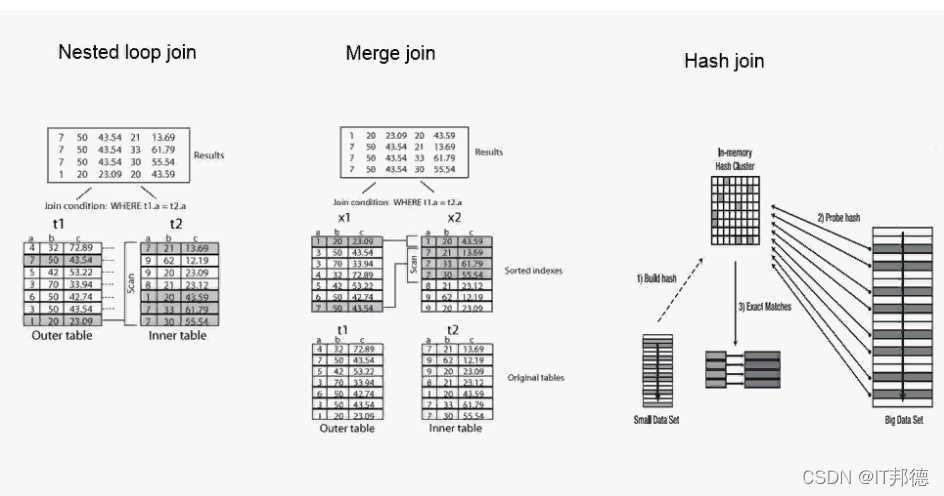
2.4 表连接方式
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式
多表之间的连接有三种方式:
Nested Loops,Hash Join 和 Sort Merge Join.
具体适用哪种类型的连接取决于:
* 当前的优化器模式 (ALL_ROWS 和 RULE)
* 取决于表大小
* 取决于连接列是否有索引
* 取决于连接列是否排序
2.4.1 hash join
使用情况:Hash join在两个表的数据量差别很大的时候.(小表一般会丢在内存中)
2.4.2 merge join
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,
到另一个排序表中做匹配。
适用情况:
1.RBO模式
2.不等价关联(>,<,>=,<=,<>)
3.HASH_JOIN_ENABLED=false
4. 用在没有索引,并且数据已经排序的情况.
2.4.3 nested loop
Nested loops 工作方式是循环从一张表中读取数据(驱动表outer table),
然后访问另一张表(被查找表 inner table,通常有索引)。
驱动表中的每一行与inner表中的相应记录JOIN。类似一个嵌套的循环。
适用情况:
适用于驱动表的记录集比较小(<10000)而且inner表需要有有效的访问方法(Index),
并且索引选择性较好的时候.
JOIN的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间是最快的。
2.4.执行计划的获取
2.4.1 dbms_xplan.display_cursor获取
select * from table( dbms_xplan.display_cursor('&sql_id') );
--该方法是从共享池得到,如果SQL已被age out出share pool,则查找不到
select * from table( dbms_xplan.display_awr('&sql_id') );
--该方法是从awr性能视图里面获取(直接在命令窗口执行,可对比执行计划,真实的计划)
2.4.2 Explain Plan(预估执行计划)
SYS@ORCL> explain plan for select * from scott.emp;
SYS@ORCL> select * from table(dbms_xplan.display);
注:Explain plan只生成执行计划,并不会真正执行SQL语句,
因此产生的执行计划有可能不准
三、优化案例展示
3.1 未走索引
创建测试表:
SQL> create table system.test_objects as select * from dba_objects;
SYS@ORCL> insert into system.test_objects select * from system.test_objects; --数据量达到1200多万即可
收集统计信息:
SQL> EXEC DBMS_STATS.gather_table_stats('SYSTEM','TEST_OBJECTS');
SQL> set autotrace on
SQL> set linesize 200
SYS@ORCL> set time on timing on
SQL> select count(*) from system.test_objects A where object_name='OBJ$';
COUNT(*)
----------
256
Elapsed: 00:00:03.08
Execution Plan
----------------------------------------------------------
Plan hash value: 3799704240
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 25 | 19506 (2)| 00:03:55 |
| 1 | SORT AGGREGATE | | 1 | 25 | | |
|* 2 | TABLE ACCESS FULL| TEST_OBJECTS | 226 | 5650 | 19506 (2)| 00:03:55 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OBJECT_NAME"='OBJ$')
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
176155 consistent gets
149912 physical reads
0 redo size
516 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SYS@ORCL> set autotrace off
SYS@ORCL> select count(*) from system.test_objects;
3.2 如何优化
如前所示,原SQL是要统计表system.test_objects中,object_name列中,
值为'OBJ$'的记录的行数。而表system.test_objects中共有记录600余万行。
该SQL共执行了3秒,进行了约17万个逻辑读(从内存中读取数据)
和几乎同样数量的物理读(从外部存储上读取数据,其处理速度比内存的处理速度慢千倍以上)。
但实际上,只有256行记录是满足检索条件的,其相对于600余万行的总记录数而言,是非常少的。
同时,也说明OBJECT_NAME列上选择性是比较好的。
综上,我们可以考虑在列OBJECT_NAME列上创建索引,这样,当进行同样的SQL时:
第一,我们可以通过该索引快速定位到满足条件的行,
从而避免了从头扫到尾的全表扫描的处理方式。
第二,由于是统计满足相关条件的记录数量,
所以,并不需要返回除检索条件列之外的其它列,只是计数罢了,
所以,仅仅访问相关的索引就足够了,而不需要再从索引回表,去获取其它列。
##优化效果
在列object_name创建索引后,执行时间为,由之前的03.08表降为0.01秒,
辑读和物理读分别为5和4
创建索引
SQL> create index ind_test_objects_object_name on system.TEST_OBJECTS(Object_Name);
SQL> select count(*) from system.test_objects A where object_name='OBJ$';
COUNT(*)
----------
256
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 251147837
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 25 | 6 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 25 | | |
|* 2 | INDEX RANGE SCAN| IND_TEST_OBJECTS_OBJECT_NAME | 226 | 5650 | 6 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_NAME"='OBJ$')
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
4 consistent gets
3 physical reads
0 redo size
516 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
大家点赞、收藏、关注、评论啦 、查看👇🏻👇🏻👇🏻微信公众号获取联系方式👇🏻👇🏻👇🏻
本文转载自: https://blog.csdn.net/weixin_41645135/article/details/122295678
版权归原作者 IT邦德 所有, 如有侵权,请联系我们删除。
版权归原作者 IT邦德 所有, 如有侵权,请联系我们删除。