
1、前言
阿里云 数据仓库这一系列断断续续也有很久没有更新了,新年新气象,赶紧追上开写。
2、基本概念
1、ODPS:
Open Data Processing Service, 简称ODPS;是由阿里云自主研发,提供针对TB/PB级数据、实时性要求不高的分布式处理能力,应用于数据分析、挖掘、商业智能等领域;阿里巴巴的离线数据业务都运行在ODPS上;
2、ODPS SQL:
与Hive SQL语法基本一致;适用于海量数据(TB级别),但实时性要求不高的场合,它的每个作业的准备,提交等阶段需要花费较长时间, 因此要求每秒处理几千至数万笔事务的业务是不能用ODPS SQL完成的;
ODPS SQL采用的是类似于SQL的语法,可以看作是标准SQL的子集,但不能因此简单的把ODPS SQL等价成一个数据库,它在很多方面并不具备数据库的特征;
3、 ODPS SQL
做数据分析与IT人员最熟悉使用SQL对数据进行分析统计了。ODPS也支持SQL查询操作,而且语法类似于Hive 的HQL。
SQL操作的主要对象是表,数据量可在T级到P级。
SQL中提供的功能有:
- DLL:表、列、分区、视图、生命周期等操作 ;
- DML:数据更新、多路输出以及动态分区输出 ;
- Join:多表关联分析,支持 inner , left , right full join 以及mapjoin;
- 窗口函数:支持常见的窗口函数如avg,count 也支持滑动窗口;
- UDF: 支持通过Java、Python编写UDF、UDAF和UDTF;
4、DataWorks数据开发增强了SQL编辑器功能
1、 实时语法检查,同时,支持MaxCompute 2.0语法,报错位置可以精确到行、列。
2、 在编辑器中显示具体的错误信息 。
3、自动补全 (关键字/project/表/字段) 在合适的地点出现关键字,project、表和字段;‘from’, ‘xxx join’,
‘drop table/view’, ‘alter table / view’ 提示表;’select’, ‘where’,
‘having’, ‘on’, ‘order by’, ‘partitioned by’, ‘distibute by’, ‘sort
by’, ‘desc’ 后 提示 相关表的字段;支持子查询的方式字段提示。4、多种语言的语法高亮如 SQL、python、shell
新版编辑器功能范围支持SQL、python、Shell两种语言的语法高亮,以彩色标识出某种编程语言的关键。5、快速定位问题,支持语法分析,为用户提示详细的报错信息。 实时语法检查,同时,支持MaxCompute2.0语法,报错位置可以精确到行、列。
6、代码折叠 在写大量代码时往往会因为代码过多无法快速准确的找到哪些代码是一个功能模块,哪些代码是成对的标签块,这时,代码缩进折叠功能就显得非常重要了;点击-号,完成代码折叠。
5、ODPS-SQL-----SQL开发优化
5.1、null
我们在进行=/<>/in/not in等判断时,null会不包含在这些判断条件中,所以在对null的处理时可以使用nvl或者coalesce函数对null进行默认转换。
5.2、select
在数据开发或者线上任务时,尽可能提前对列进行剪裁,即使是全表字段都需要,也要尽可能的把字段都写出来
(如果实在觉得麻烦,可以使用评台中 数据地图中表来生成select 功能)。
一、是减少了数据运算中不必要的数据读取,
二、是避免后期因为原表或者目标表字段增加,导致的任务报错。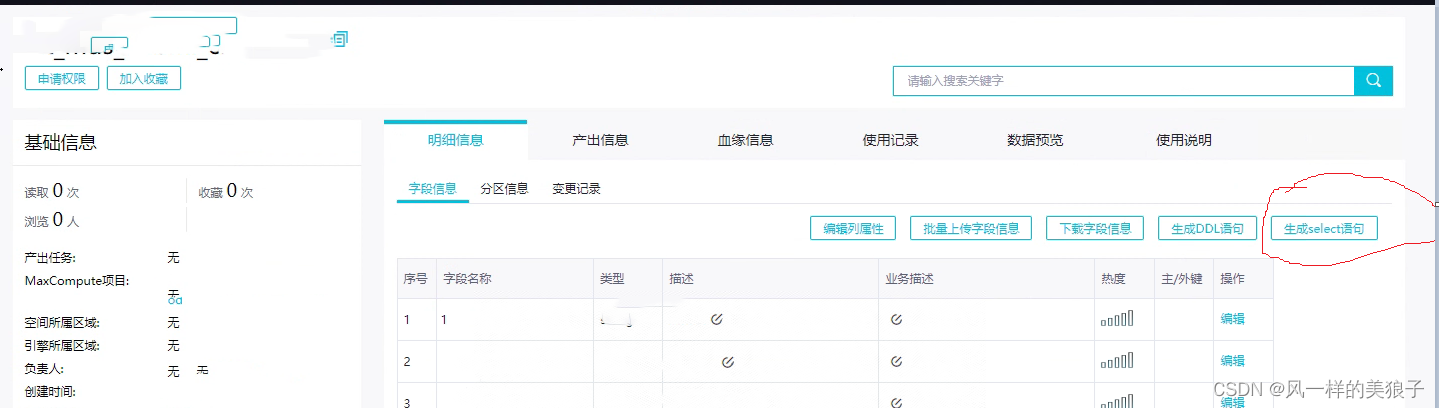
5.3、multi insert
读取同一张表,但是因为粒度不同,需要插入多张表时,可以考虑使用
from () tab insert overwrite A insert overwrite B 的方式,减少资源的浪费。
当然,有些团队的数仓开发规范中会规定一个任务不能有两个目标表,具体情况可以视情况尽可能复用公共数据,如通过临时表的方式临时存储这部分逻辑。
5.4、分区限定
ODPS表大部分都是分区表,分区表又会根据业务规则分为增量表、全量表、快照表等。所以在做简单查询,或者数据探查时,我们一定要养成习惯先限定分区ds。经常会在jobhistory中看到很多好资源的任务都是因为分区限定不合理或者没有限定分区导致的。
5.5、limit的使用
临时查询或者数据探查时,养成习惯加上limit,会快速的查询出你想要的数据,且消耗更少的资源。
5.6、UDF函数的使用
尽可能把UDF的使用下沉到第一层子查询中,效率会有很大的提升。
5.7、行转列、列转行
collect_set 、lateral view函数可以实现行转列或者列转行的功能,好多大佬也都写过类似的ATA,可以参考。
5.8、窗口函数的使用
可以通过 row_number()/rank() over(partition by order by )的方式实现数据按照某个字段分组的排序,也可以通过 max(struct())的方式实现。
5.9、表关联
我们大家都知道 左关联、内关联、右关联、left anti join 、left semi join等,可以实现不同情况下的多表关联。我们在使用 关联字段 时一定要确保字段类型的一致性。
5.10、笛卡尔积的应用
我们有时会存在把一行数据翻N倍的场景诉求,这时候我们可以考虑自己创建一个维表,通过笛卡尔积操作实现;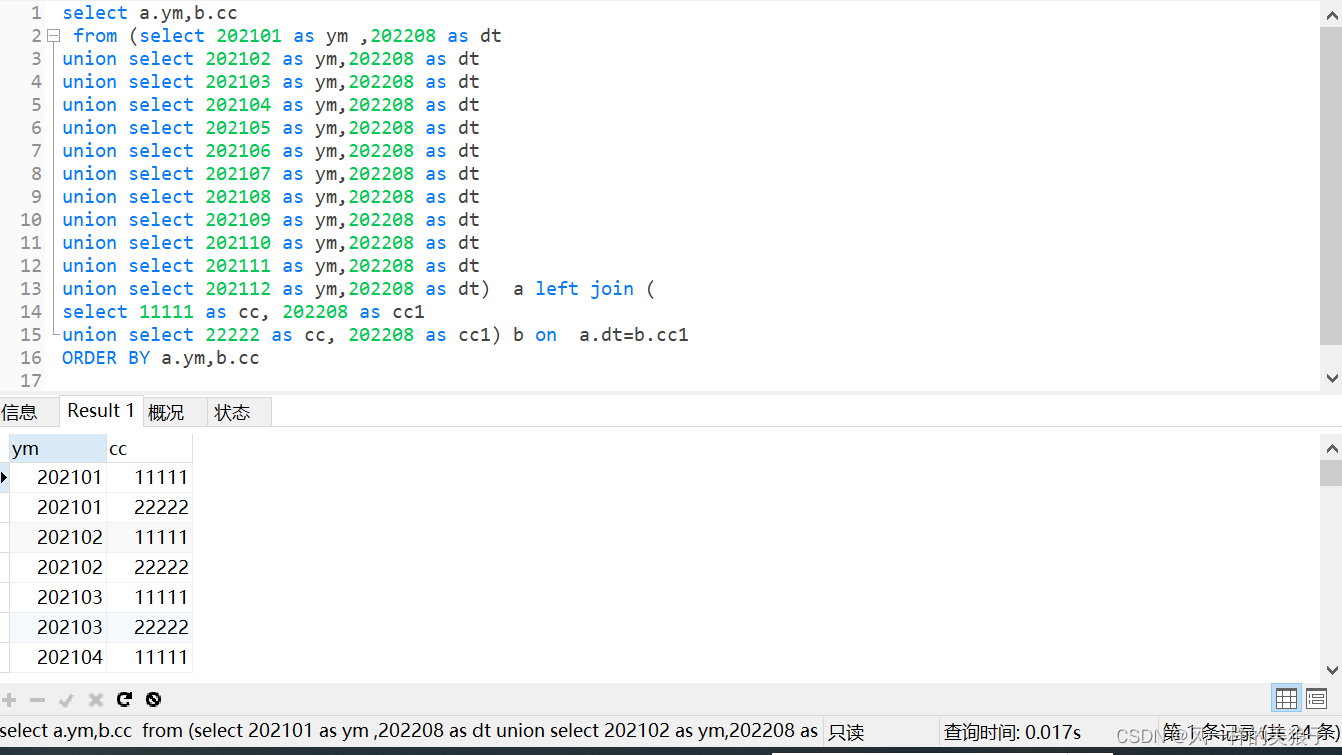
同时我们也可以通过LATERAL VIEW POSEXPLODE(split(REGEXP_REPLACE(space(end_num -start_num+1),’ ‘,‘1,’),’,')) t AS pos ,val的方式 来实现。
版权归原作者 风一样的美狼子 所有, 如有侵权,请联系我们删除。