
#所需安装包下载路径
(1)mysql
rpm包路径:https://downloads.mysql.com/archives/community/
connect路径:https://downloads.mysql.com/archives/c-j/
(2)hive
https://mirrors.huaweicloud.com/apache/hive/hive-3.1.3/
(3)spark
https://mirrors.huaweicloud.com/apache/spark/spark-2.3.0/
1.mysql安装部署
1.1安装包下载
1.1.1所需下载的rpm包
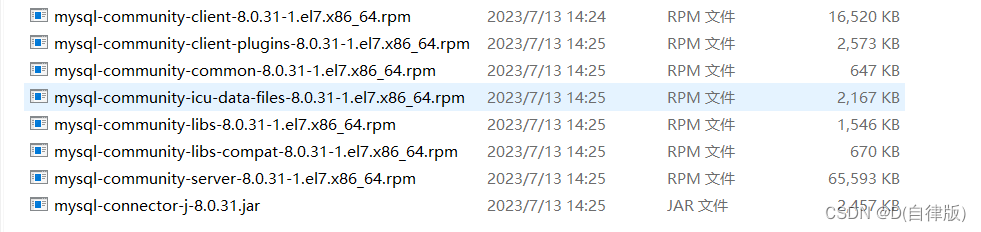
1.1.2所需驱动包下载
1.2上传到集群环境
(1)这里如果安装了lrzsz可以直接拖动过来,如果没有安装
命令行输入:sudo yum install -y lrzsz
(2)没有的话就用xftp
1.3卸载干扰依赖,安装所需依赖
1.3.1卸载干扰依赖
[student@hadoop102 mysql]# sudo yum remove mysql-libs
1.3.2安装所需的依赖
[student@hadoop102 mysql]# sudo yum install libaio
[student@hadoop102 mysql]# sudo yum -y install autoconf
1.4切换root用户执行安装脚本
1.4.1切换root用户
[student@hadoop102 mysql]$ su root
1.4.2执行脚本
[root@hadoop102 mysql]# sh install_mysql.sh
1.4.3脚本解析
#!/bin/bash
set -x
[ "$(whoami)" = "root" ] || exit 1
[ "$(ls *.rpm | wc -l)" = "7" ] || exit 1
test -f mysql-community-client-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-client-plugins-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-common-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-icu-data-files-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-libs-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-libs-compat-8.0.31-1.el7.x86_64.rpm && \
test -f mysql-community-server-8.0.31-1.el7.x86_64.rpm || exit 1
# 卸载MySQL
systemctl stop mysql mysqld 2>/dev/null
rpm -qa | grep -i 'mysql\|mariadb' | xargs -n1 rpm -e --nodeps 2>/dev/null
rm -rf /var/lib/mysql /var/log/mysqld.log /usr/lib64/mysql /etc/my.cnf /usr/my.cnf
set -e
# 安装并启动MySQL
yum install -y *.rpm >/dev/null 2>&1
systemctl start mysqld
#更改密码级别并重启MySQL
sed -i '/\[mysqld\]/avalidate_password.length=4\nvalidate_password.policy=0' /etc/my.cnf
systemctl restart mysqld
# 更改MySQL配置
tpass=$(cat /var/log/mysqld.log | grep "temporary password" | awk '{print $NF}')
cat << EOF | mysql -uroot -p"${tpass}" --connect-expired-password >/dev/null 2>&1
set password='000000';
update mysql.user set host='%' where user='root';
alter user 'root'@'%' identified with mysql_native_password by '000000';
flush privileges;
EOF
1.4.4退出root用户到student用户
[student@hadoop102 mysql]# exit
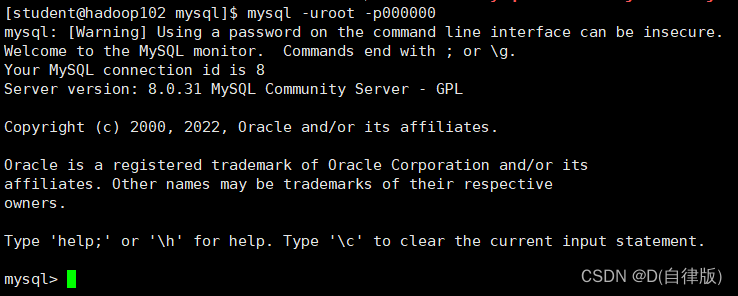
1.4.5登录测试
[student@hadoop102 mysql]$ mysql -uroot -p000000
2.hive安装部署
2.1安装hive
2.1.1把hive-3.1.3.tar.gz上传到linux的/opt/software目录下
2.1.2解压hive-3.1.3.tar.gz到/opt/module/目录下面
[student@hadoop102 software]$ tar -zxvf /opt/software/hive-3.1.3.tar.gz -C /opt/module/
2.1.3修改hive-3.1.3-bin.tar.gz的名称为hive
[student@hadoop102 software]$ mv /opt/module/apache-hive-3.1.3-bin/ /opt/module/hive
2.1.4*修改/etc/profile.d/my_env.sh,添加环境变量*
[student@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
#添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
#修改好后,刷新一下环境变量
[student@hadoop102 software]$ source /etc/profile.d/my_env.sh
2.1.5解决日志Jar包冲突,进入/opt/module/hive/lib****目录
[student@hadoop102 lib]$ mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak
2.1.6Hive元数据配置到MySQL
2.1.6.1拷贝驱动
#将MySQL的JDBC驱动拷贝到Hive的lib目录下。
[student@hadoop102 lib]$ cp /opt/software/mysql/mysql-connector-j-8.0.31.jar /opt/module/hive/lib/
2.1.6.2配置Metastore到MySQL
#在$HIVE_HOME/conf目录下新建hive-site.xml文件。
[student@hadoop102 conf]$ vim hive-site.xml
#添加如下内容。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--配置Hive保存元数据信息所需的 MySQL URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property>
<!--配置Hive连接MySQL的驱动全类名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--配置Hive连接MySQL的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置Hive连接MySQL的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
2.2启动Hive
2.2.1初始化元数据库
2.2.1.1登陆MySQL
[student@hadoop102 conf]$ mysql -uroot -p000000
2.2.1.2新建Hive元数据库
mysql> create database metastore;
2.2.1.3初始化Hive元数据库
[student@hadoop102 conf]$ schematool -initSchema -dbType mysql -verbose
2.2.1.4修改元数据库字符集
2.2.1.4.1添加字段注释
#Hive元数据库的字符集默认为Latin1,由于其不支持中文字符,所以建表语句中如果包含中文注释,会出现乱码现象。如需解决乱码问题,须做以下修改。
修改Hive元数据库中存储注释的字段的字符集为utf-8。
mysql> use metastore;
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
2.2.1.4.2添加表注释
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
2.2.2启动hive客户端
2.2.2.1启动Hive客户端
#先启动hadoop
[student@hadoop102 hive]$ hdp.sh start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------
[student@hadoop102 hive]$ hive
2.2.2.2查看一下数据库
hive (default)> show databases;
OK
database_name
default
Time taken: 0.966 seconds, Fetched: 1 row(s)
3.hive on spark配置
3.1兼容性问题hive3.1.3默认支持spark2.3.0,注意我们所下载的包

3.2 配置spark
3.2.1上传并解压解压spark-3.3.0-bin-without-hadoop.tgz
[student@hadoop102 software]$ tar -zxvf spark-2.3.0-bin-without-hadoop.tgz -C /opt/module/
[student@hadoop102 software]$ mv /opt/module/spark-2.3.0-bin-without-hadoop /opt/module/spark
3.2.2修改spark-env.sh配置文件
#修改文件名使其生效
[student@hadoop102 software]$ mv /opt/module/spark/conf/spark-env.sh.template /opt/module/spark/conf/spark-env.sh
#编辑文件
[student@hadoop102 software]$ vim /opt/module/spark/conf/spark-env.sh
#增加hadoop classpath
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
3.2.3配置SPARK_HOME环境变量
[student@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
#添加如下内容
#SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
#source刷新环境变量
[student@hadoop102 software]$ source /etc/profile.d/my_env.sh
3.2.4在hive中创建spark配置文件
[student@hadoop102 software]$ vim /opt/module/hive/conf/spark-defaults.conf
#添加如下内容
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
#在HDFS创建如下路径,用于存储历史日志。(必须)
[student@hadoop102 hadoop]$ hadoop fs -mkdir /spark-history
3.2.5向HDFS上传Spark纯净版jar包
#说明1:采用Spark纯净版jar包,不包含hadoop和hive相关依赖,能避免依赖冲突。
#说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
[student@hadoop102 hadoop]$ hadoop fs -mkdir /spark-jars
[student@hadoop102 hadoop]$ hadoop fs -put /opt/module/spark/jars/* /spark-jars
3.2.6修改hive-site.xml****文件
[student@hadoop102 ~]$ vim /opt/module/hive/conf/hive-site.xml
添加如下内容。
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
3.2.7Hive on Spark****测试
#启动hive客户端
[student@hadoop102 hive]$ hive
#创建一张测试表
hive (default)> create table student(id int, name string);
#通过insert测试效果
hive (default)> insert into table student values(1,'zhangsan');
#spark引擎每次重新启动执行时第一次跑的慢,往后就不会了,
下面两张图是第一次和第二次的执行结果
#如果你的执行结果也输出了一个进度条,说明你的hive on spark也已经成功部署了
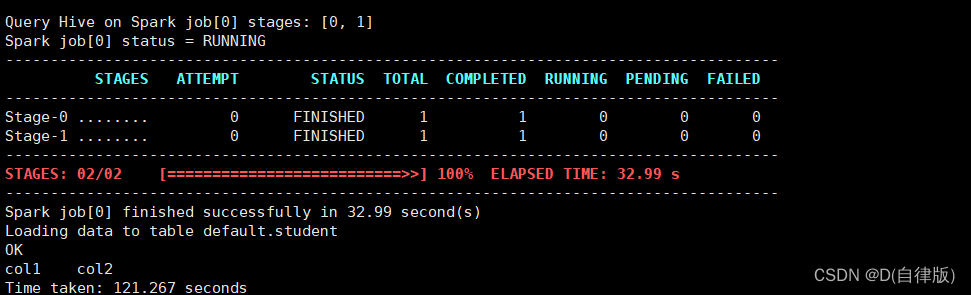
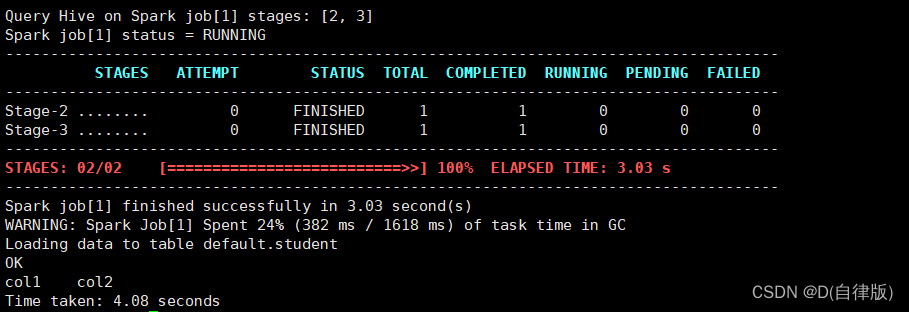
3.2.8增加ApplicationMaster资源比例
3.2.8.1分发capacity-scheduler.xml配置文
#说明:容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行,我们学习环境本来资源就不多,再不舍得给资源,不设置有时候提交任务会失败。
#在hadoop102的/opt/module/hadoop/etc/hadoop/capacity-scheduler.xml
文件中修改如下参数值
[student@hadoop102 hadoop]$ vim capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property
#分发capacity-scheduler.xml配置文件
[student@hadoop102 hadoop]$ xsync capacity-scheduler.xml
3.2.8.2重启yarn
关闭正在运行的任务,重新启动yarn集群
[student@hadoop103 hadoop]$ stop-yarn.sh
[student@hadoop103 hadoop]$ start-yarn.sh
本文转载自: https://blog.csdn.net/m0_64893323/article/details/134377516
版权归原作者 D(自律版) 所有, 如有侵权,请联系我们删除。
版权归原作者 D(自律版) 所有, 如有侵权,请联系我们删除。