

🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
🍁🪁🍁 🪁🍁🪁🍁感谢点赞和关注 ,每天进步一点点!加油!🍁🪁🍁 🪁🍁🪁🍁
一、FileSystem文件抽象类
为了提供对不同数据访问的一致接口,Hadoop借鉴了Linux虚拟文件系统的概念,为此Hadopo提供了一个抽象的文件系统模型FileSystem,HDFS 是其中的一个实现。
FileSystem是Hadoop中所有文件系统的抽象父类,它定义了文件系统所具有的基本特征和基本操作。
1.1文件读取API
HadoopFileSystem操作
Java操作
Linux操作
描述
URL.openStream
FileSystem.open
FileSystem.create
FileSystem.append
URL.openStream
open
打开一个文件
FSDataInputStream.read
InputStream.read
read
读取文件中的数据
FSDataInputStream.write
OutputStream.write
write
向文件中写入数据
FSDataInputStream.close
FSDataOutputStream.close
InputStream.close
OutputStream.close
close
关闭一个文件
FSDataInputStream.seek
RandomAccessFile.seek
lseek
改变文件读写位置
FileSystem.getContentSummary
du/wc
获取文件存储信息
1.2文件操作API
HadoopFileSystem操作
Java操作
Linux操作
描述
FileSystem.getFileStatus
FileSystem.get*
File.get*
stat
获取文件/目录的属性
FileSystem.set*
File.set*
chomd
修改文件属性
FileSystem.createNewFile
File.createNewFile
create
创建一个文件
FileSystem.delete
File.delete
remove
删除一个文件
FileSystem.rename
File.renameTo
rename
移动或先修改文件/目录名
FileSystem.mkdirs
File.mkdir
mkdir
创建目录
FileSystem.delete
File.delete
rmdir
从一个目录下删除一个子目录
FileSystem.listStatus
File.list
readdir
读取一个目录下的项目
FileSystem.setWorkingDirectory
getcwd/getwd
返回当前工作目录
FileSystem.setWorkingDirectory
chdir
更改当前的工作目录
1.3抽象FileSystem类的具体实现子类

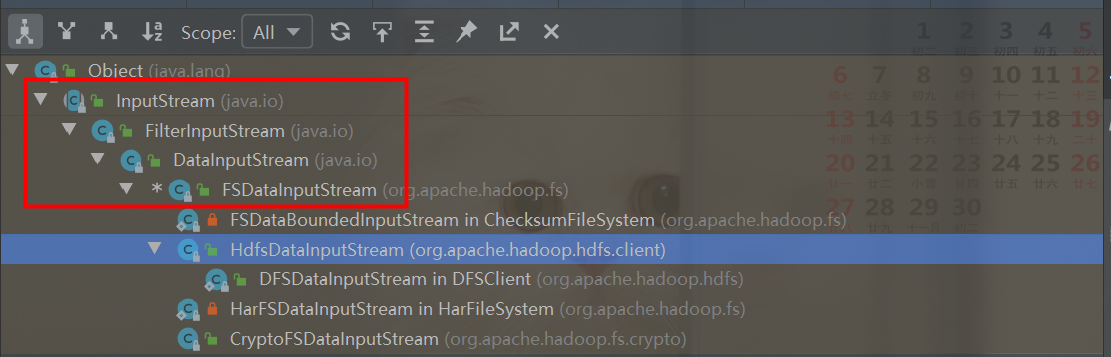
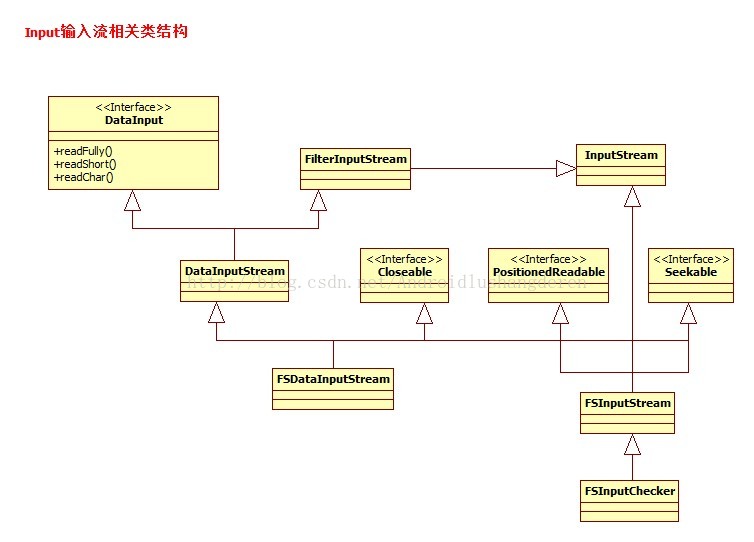
1.4FileSystem IO输入系统相关类
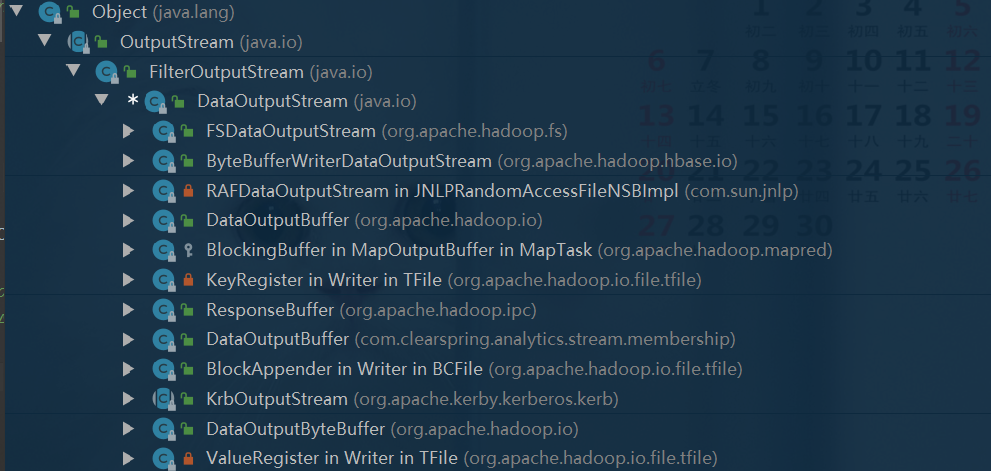
1.5FileSystem IO输出系统相关类

二、HDFS的API操作
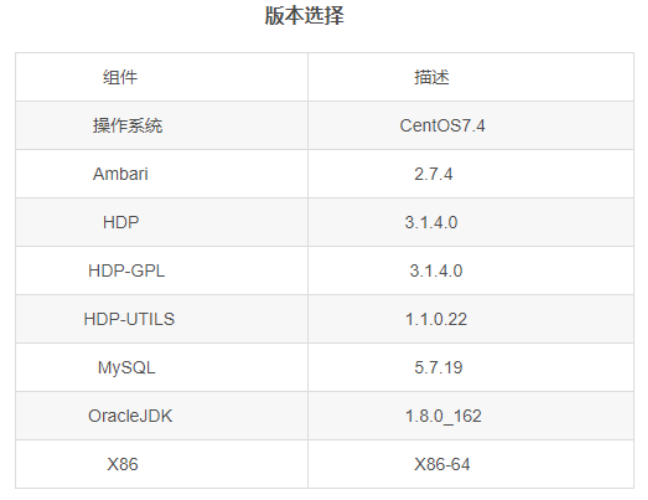
2.1测试集群版本信息
2.2文件上传下载和移动
/**
* 本地文件上传到 HDFS
*
* @param srcPath 本地路径 + 文件名
* @param dstPath Hadoop路径
* @param fileName 文件名
*/
def copyToHDFS(srcPath: String, dstPath: String, fileName: String): Boolean = {
var path = new Path(dstPath)
val fileSystem: FileSystem = path.getFileSystem(conf)
val isFile = new File(srcPath).isFile
// 判断路径是否存在
val existDstPath: Boolean = fileSystem.exists(path)
if (!existDstPath) {
fileSystem.mkdirs(path)
}
// 本地文件存在
if (isFile) {
// HDFS 采用 路径+ 文件名
path = new Path(dstPath + File.separator + fileName)
// false: 是否删除 目标文件,false: 不覆盖
fileSystem.copyFromLocalFile(false, false, new Path(srcPath), path)
return true
}
false
}
/**
* Hadoop文件下载到本地
*
* @param srcPath hadoop 源文件
* @param dstPath 目标文件
* @param fs 文件访问对象
*/
def downLoadFromHDFS(srcPath: String, dstPath: String, fs: FileSystem): Unit = {
val srcPathHDFS = new Path(srcPath)
val dstPathLocal = new Path(dstPath)
// false: 不删除源文件
fs.copyToLocalFile(false, srcPathHDFS, dstPathLocal)
}
/**
* 检查Hadoop文件是否存在并删除
*
* @param path HDFS文件
*/
def checkFileAndDelete(path: String, fs: FileSystem) = {
val dstPath: Path = new Path(path)
if (fs.exists(dstPath)) {
// false: 是否递归删除,否
fs.delete(dstPath, false)
}
}
/**
* 获取指定目录下,正则匹配后的文件列表
*
* @param dirPath hdfs路径
* @param regexRule 正则表达式 ,如:"^(?!.*[.]tmp$).*$" ,匹配非 .tmp结尾的文件
*/
def listStatusHDFS(dirPath: String, regexRule: String, fs: FileSystem): util.ArrayList[Path] = {
val path = new Path(dirPath)
val pattern: Pattern = Pattern.compile(regexRule)
// 匹配的文件
val fileList = new util.ArrayList[Path]()
val fileStatusArray: Array[FileStatus] = fs.listStatus(path)
for (fileStatus <- fileStatusArray) {
// 文件 全路径
val filePath: Path = fileStatus.getPath()
val fileName: String = filePath.getName.toLowerCase
if (regexRule.equals("")) {
// 如果匹配规则为空 则获取目录下的全部文件
fileList.add(filePath)
log.info("match file : " + fileName)
} else {
// 正则匹配文件
if (pattern.matcher(fileName).matches()) {
fileList.add(filePath)
log.info("match file : " + fileName)
}
}
}
fileList
}
/**
* 文件移动或重命名到指定目录, 如:文件00000 重命名为00001
*
* @param srcPath 源文件路径
* @param dstPath 源文件路径
* @param fs 文件操作对象
*/
def renameToHDFS(srcPath: String, dstPath: String, fs: FileSystem): Boolean = {
var renameFlag = false
val targetPath = new Path(dstPath)
// 目标文件存在先删除
if (fs.exists(targetPath)) {
fs.delete(targetPath, false)
}
renameFlag = fs.rename(new Path(srcPath), targetPath)
if (renameFlag) {
log.info("renamed file " + srcPath + " to " + targetPath + " success!")
} else {
log.info("renamed file " + srcPath + " to " + targetPath + " failed!")
}
renameFlag
}
2.3文件读写操作
Hadoop抽象文件系统也是使用流机制进行文件的读写。Hadoop抽象文件系统中,用于读文件数据的流是FSDataInputStream,对应地,写文件通过抽象类FSDataOutputStream实现。
/**
* 读取HDFS文件
*
* @param inPutFilePath 源文件路径
* @param fs 文件操作对象
*/
def readFromHDFS(inPutFilePath: String, OutputFilePath: String, fs: FileSystem) = {
var fSDataInputStream: FSDataInputStream = null
var bufferedReader: BufferedReader = null
val srcPath = new Path(inPutFilePath)
if (fs.exists(srcPath)) {
val fileStatuses: Array[FileStatus] = fs.listStatus(srcPath)
for (fileStatus <- fileStatuses) {
val filePath: Path = fileStatus.getPath
// 判断文件大小
if (fs.getContentSummary(filePath).getLength > 0) {
fSDataInputStream = fs.open(filePath)
bufferedReader = new BufferedReader(new InputStreamReader(fSDataInputStream))
var line = bufferedReader.readLine()
while (line != null) {
print(line + "\n") // 打印
line = bufferedReader.readLine()
}
}
}
}
fSDataInputStream.close()
bufferedReader.close()
}
/**
* 读取HDFS文件, 处理完成 重新写入
*
* @param inPutFilePath 源文件路径
* @param OutputFilePath 输出文件到新路径
* @param fs 文件操作对象
*/
def writeToHDFS(inPutFilePath: String, OutputFilePath: String, fs: FileSystem) = {
var fSDataInputStream: FSDataInputStream = null
var fSDataOutputStream: FSDataOutputStream = null
var bufferedReader: BufferedReader = null
var bufferedWriter: BufferedWriter = null
val srcPath = new Path(inPutFilePath)
var count = 0
if (fs.exists(srcPath)) {
val fileStatuses: Array[FileStatus] = fs.listStatus(srcPath)
for (fileStatus <- fileStatuses) {
val filePath: Path = fileStatus.getPath
// 判断文件大小
if (fs.getContentSummary(filePath).getLength > 0) {
fSDataInputStream = fs.open(filePath)
bufferedReader = new BufferedReader(new InputStreamReader(fSDataInputStream))
val outputFilePath = new Path(OutputFilePath + count)
fSDataOutputStream = fs.create(outputFilePath)
bufferedWriter = new BufferedWriter(new OutputStreamWriter(fSDataOutputStream, "UTF-8"))
var line = bufferedReader.readLine()
while (line != null) {
val bytes: Array[Byte] = line.getBytes("UTF-8")
bufferedWriter.write(new String(bytes) + "\n")
line = bufferedReader.readLine()
}
bufferedWriter.flush()
count += 1
}
}
}
fSDataInputStream.close()
bufferedReader.close()
bufferedWriter.close()
}
测试结果如下:
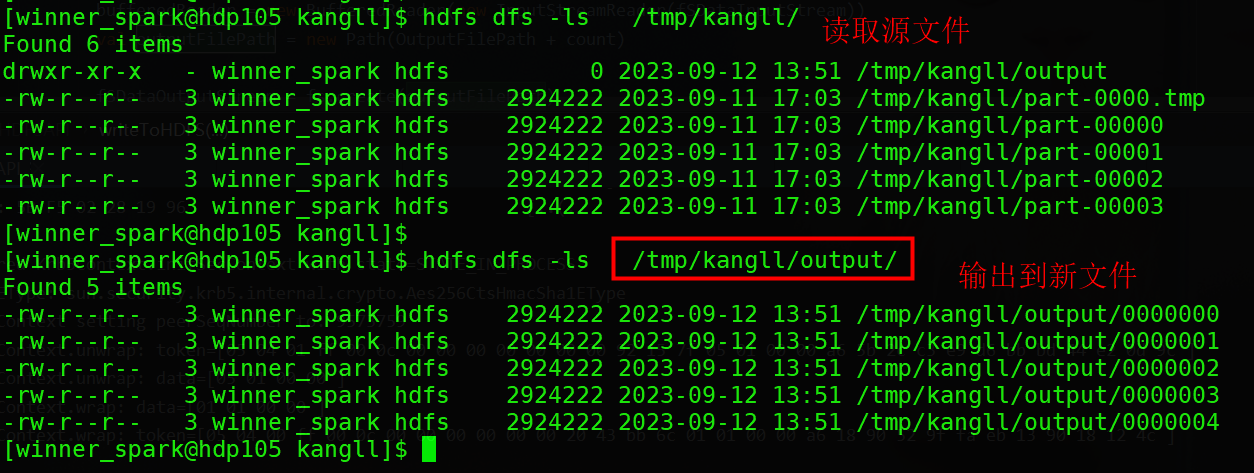
2.4文件状态信息获取
FileSystem. getContentSummary()提供了类似Linux命令du、df提供的功能。du表示"disk usage",它会报告特定的文件和每个子目录所使用的磁盘空间大小;命令df则是"diskfree"的缩写,用于显示文件系统上已用的和可用的磁盘空间的大小。du、df是Linux中查看磁盘和文件系统状态的重要工具。
getContentSummary()方法的输入是一个文件或目录的路径,输出是该文件或目录的一些存储空间信息,这些信息定义在ContentSummary,包括文件大小、文件数、目录数、文件配额,已使用空间和已使用文件配额等。
/**
* HDFS路径下文件信息统计
*
* @param dirPath hdfs路径
**/
def listHDFSStatus(dirPath: String, fs: FileSystem) = {
val path = new Path(dirPath)
// 匹配的文件
val contentSummary: ContentSummary = fs.getContentSummary(path)
println("/tmp/kangll 目录下子目录个数: ", contentSummary.getDirectoryCount)
println("/tmp/kangll 目录下文件个数: ", contentSummary.getFileCount)
println("/tmp/kangll 目录下文件大小: ", contentSummary.getLength)
println("/tmp/kangll 目录下文件和子目录个数: ", contentSummary.getFileAndDirectoryCount)
}
/tmp/kangll目录信息获取结果:
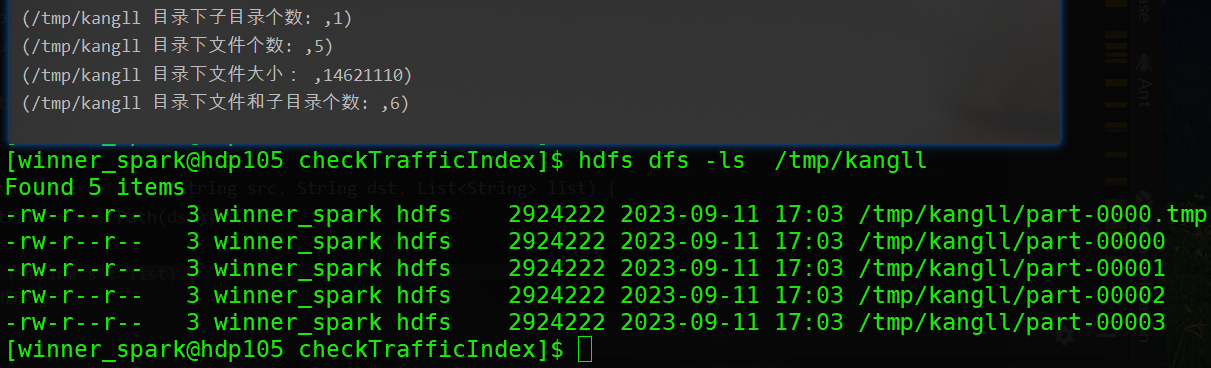
2.5实战案例
案例说明: HDFS 文件清理, 根据文件大小、个数、程序休眠时间控制 匀速 批量删除 HDFS 文件,当文件越大 ,需要配置 删除个数更少,休眠时间更长,防止 NameNode 负载过大,减轻DataNode磁盘读写压力,从而不影响线上业务情况下清理过期数据。
package com.kangll.common.utils
import java.text.SimpleDateFormat
import java.util.concurrent.TimeUnit
import java.util.{Calendar, Date, Properties}
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{ContentSummary, FileStatus, FileSystem, Path}
import org.apache.log4j.Logger
import scala.collection.mutable.ListBuffer
/** ***************************************************************************************
*
* @auther kangll
* @date 2023/09/12 12:10
* @desc HDFS 文件清理, 根据文件大小、个数、程序休眠时间控制 匀速 批量删除
* HDFS 文件,当文件越大 ,需要配置 删除个数更少,休眠时间更长,防止
* NameNode 负载过大,减轻DataNode磁盘读写压力,从而不影响线上业务下删除
*
*
* 1.遍历文件夹下的文件个数据, 当遍历的文件夹下的文件个数到达阈值时 将
* 文件所述的 父路径直接删除
*
* ****************************************************************************************/
object CleanHDFSFileUtil {
// 删除文件总数统计
var HDFS_FILE_SUM = 0
// 批次删除文件个数显示
var HDFS_FILE_BATCH_DEL_NUM = 0
val start = System.currentTimeMillis()
/**
*
* @param fs 文件操作对象
* @param pathName 文件根路径
* @param fileList 批次清理的 buffer
* @param saveDay 根据文件属性 获取文件创建时间 选择文件保留最近的天数
* @param sleepTime 休眠时间,防止一次性删除太多文件 导致 datanode 文件负载太大
* @param fileBatchCount 批次删除文件的个数, 相当于是 上报到 namenode 文件清理队列的大小,参数越大 队列越大,datanode 磁盘负载相对来说就高
* @return
*/
def listPath(fs: FileSystem, pathName: String, fileList: ListBuffer[String], saveDay: Int, sleepTime: Long, fileBatchCount: Int): ListBuffer[String] = {
val fm = new SimpleDateFormat("yyyy-MM-dd")
// 获取当前时间
val currentDay = fm.format(new Date())
val dnow = fm.parse(currentDay)
val call = Calendar.getInstance()
call.setTime(dnow)
call.add(Calendar.DATE, -saveDay)
// 获取保留天前的时期
val saveDayDate = call.getTime
// 遍历文件
val fileStatuses = fs.listStatus(new Path(pathName))
for (status <- fileStatuses) {
// 获取到文件名
val filePath = status.getPath
if (status.isFile) {
// 获取到文件修改时间
val time: Long = status.getModificationTime
val hdfsFileDate = fm.parse(fm.format(new Date(time)))
if (saveDayDate.after(hdfsFileDate)) {
fileList += filePath.toString
// 获取文件个数
val cs: ContentSummary = fs.getContentSummary(filePath)
HDFS_FILE_SUM += cs.getFileCount.toInt
HDFS_FILE_BATCH_DEL_NUM += cs.getFileCount.toInt
if (HDFS_FILE_BATCH_DEL_NUM >= fileBatchCount) {
val end = System.currentTimeMillis()
println("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
println("++++++++++++++++ 遍历文件数量达到 " + HDFS_FILE_BATCH_DEL_NUM + " 个,删除HDFS文件 ++++++++++++++++")
println("++++++++++++++++++++++++++++ 休眠 " + sleepTime + " S ++++++++++++++++++++++++++++")
println("++++++++++++++++++++++++ 删除文件总数:" + HDFS_FILE_SUM + " ++++++++++++++++++++++++++")
println("++++++++++++++++++++++++ 程序运行时间:" + (end - start) / 1000 + " s ++++++++++++++++++++++++")
println("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
HDFS_FILE_BATCH_DEL_NUM = 0
TimeUnit.MILLISECONDS.sleep(sleepTime)
}
// 文件删除根据绝对路径删除
println("+++++ 删除文件: " + filePath + "+++++")
// 递归删除
fs.delete(filePath, true)
}
} else {
// 递归文件夹
listPath(fs, filePath.toString, fileList, saveDay, sleepTime, fileBatchCount)
}
}
println("+++++++++++++++++++++++++ 删除文件总数:" + HDFS_FILE_SUM + " +++++++++++++++++++++++++")
fileList
}
/**
* 删除空文件夹
*
* @param fs 文件操作对象
* @param pathName 路径
* @param pathSplitLength 文件按照"/"拆分后的长度
*/
def delEmptyDirectory(fs: FileSystem, pathName: String, pathSplitLength: Int) = {
// 遍历文件
val fileStatuses = fs.listStatus(new Path(pathName))
for (status <- fileStatuses) {
if (status.isDirectory) {
val path: Path = status.getPath
// /kangll/winhadoop/temp/wmall_batch_inout/day/1660878372 = 7
val delPathSplitLength = path.toString.substring(6, path.toString.length).split("/").length
// filePath /kangll/winhadoop/temp/wmall_batch_inout/day 子时间戳文件夹两个
// val hdfsPathListCount = fileStatuses.length
val hdfsPathListCount = fs.listStatus(path).length
if (delPathSplitLength == pathSplitLength && hdfsPathListCount == 0) {
println("+++++++++++++++++ 删除空文件夹 : " + path + " +++++++++++++++++++")
fs.delete(path, true)
}
}
}
}
def main(args: Array[String]): Unit = {
val logger = Logger.getLogger("CleanHDFSFileUtil")
val conf = new Configuration()
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem")
conf.set("fs.file.impl", "org.apache.hadoop.fs.LocalFileSystem")
val fs = FileSystem.get(conf)
val fileList = new ListBuffer[String]
val hdfsDir = if (args.size > 0) args(0).toString else System.exit(0).toString
val saveDay = if (args.size > 1) args(1).toInt else 2
val sleepTime = if (args.size > 2) args(2).toLong else 10
val fileBatchCount = if (args.size > 3) args(3).toInt else 5
/*
默认不启用文件夹删除,参数为 文件夹绝对路径Split后的数组长度
如 路径 /winhadoop/temp/wmall_batch_inout/thirty" 配置为 7
*/
val pathSplitLength = if (args.size > 4) args(4).toInt else 20
// 删除文件
listPath(fs, hdfsDir, fileList, saveDay, sleepTime, fileBatchCount)
// 删除空文件夹
delEmptyDirectory(fs, hdfsDir, pathSplitLength)
fs.close()
}
}
调用脚本
#
# 脚本功能: 过期文件清理
# 作 者: kangll
# 创建时间: 2023-09-14
# 修改内容: 控制删除文件的批次个数,程序休眠时间传入
# 当前版本: 1.0v
# 调度周期: 一天一次
# 脚本参数: 删除文件夹、文件保留天数、程序休眠时间、批次删除个数
# 1.文件根路径,子文件夹递归遍历
# 2.文件保留天数
# 3.程序休眠时间 防止 DataNode 删除文件负载过大,单位 秒
# 4.批次删除文件个数 ,如配置 100,当满足文件个数100时, 整批执行 delete,紧接着程序休眠
# 5.默认不启用文件夹删除,也就是不传参,参数为 文件夹绝对路径Split后的数组长度
# /winhadoop/temp/wmall_batch_inout/thirty/时间戳/ Split后 长度为7,默认删除时间戳文件夹
#
### 对应的新删除程序
jarPath=/hadoop/project/del_spark2-1.0-SNAPSHOT.jar
### 集群日志
java -classpath $jarPath com.kangll.common.utils.CleanHDFSFileUtil /spark2-history 3 10 100

参考 :
hadoop抽象文件系统filesystem框架介绍_org.apache.hadoop.fs.filesystem_souy_c的博客-CSDN博客
Hadoop FileSystem文件系统的概要学习 - 回眸,境界 - 博客园
hadoop抽象文件系统filesystem框架介绍_org.apache.hadoop.fs.filesystem_souy_c的博客-CSDN博客
版权归原作者 开着拖拉机回家 所有, 如有侵权,请联系我们删除。