

来自李兵老师的《浏览器工作原理与实践》,太赞了
垃圾回收
在我们说V8垃圾回收之前,先讲讲 数据是如何存储的?
我们都知道JavaScript是一种弱语言,动态的语言。那这些特点意味着什么呢?
弱语言,意味着你不需要告诉JavaScript引擎这个或那个变量是什么数据类型,JavaScript引擎在运行代码的时候会自己计算出来;
动态,意味着你可以使用同一个变量保存不同类型的数据。
那JavaScript是有多少种数据类型。其实JavaScript中的数据类型一共有8种,分别是:
其中这八种数据中又分了 原始类型和引用类型。除了Object是引用类型,其他的都是原始类型。那为什么会给这些数据划分不同的类型,是因为它们在内存中存放的位置不一样,到底是这么个不一样法,我们接下来看看。
内存空间
要理解JavaScript在运行过程中数据是如何存储的,你得要知道存储空间的种类。以下是JavaScript的内存模型:
从图中可以看出,JavaScript的执行过程中,主要有三种类型内存空间,分别是代码空间,栈空间和堆空间。其中代码空间,主要是存储可执行代码的,我们这里主要讲栈空间 和堆空间。
栈空间和堆空间
functionfoo(){var a ="极客时间"var b = a;var c ={name:"极客时间"}var d = c;}foo()
JavaScript拿到一段代码的时候,需要先编译,并且创建执行上下文,然后再按照顺序执行代码,我们看下这张调用栈的状态图: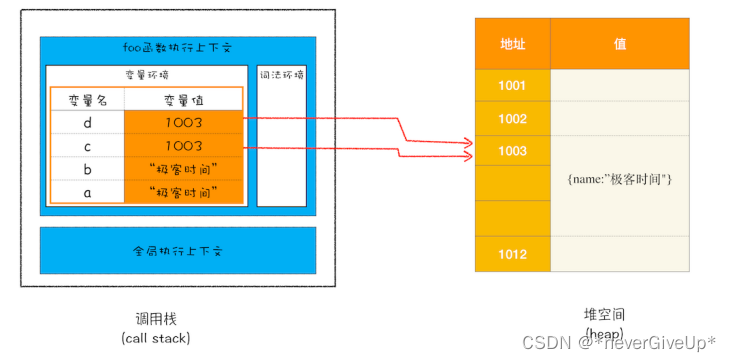
从上图我们可以看到 原始数据的值都是直接保存在“栈”中的,引用类型的值是存放在“堆”中的。那你可以还会好奇,为什么要分“堆”和“栈”两个存储空间呢?为什么直接把数据存放在“栈”中呢?
答案是不可以,这是因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。比如文中的 foo 函数执行结束了,JavaScript 引擎需要离开当前的执行上下文,只需要将指针下移到上个执行上下文的地址就可以了,foo 函数执行上下文栈区空间全部回收。
所以,在通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占空间都比较大,所以这类数据会被存放在堆中,堆空间很大,能存放很多大的数据。
回归文章正题,我们已经知道了JavaScript中的数据是如何存储的,不过有些数据被使用之后,可能就不再需要了,我们把这种数据叫做垃圾数据。如果这些垃圾数据一直保存在内存中,那么内存的垃圾会越来越多,所以我们需要对这些垃圾数据进行回收,以释放有限的内存空间。
不同语言的垃圾回收策略
通常情况下,垃圾数据回收分为手动回收和自动回收两种策略。
比如 C/C++ 就是使用手动回收策略,何时分配,何时销毁内存都是由代码控制的;JavaScript,Java,Python等语言,产生的垃圾数据是由垃圾回收器来释放的,并不需要手动通过代码来释放。对于JavaScript而言,也正是这个“自动”释放资源的特性,让很多人觉得可以不关心内存管理,这是一个很大的误解。
所以接下来我们就来分别介绍“栈中的垃圾数据” 和 “堆中的垃圾数据”是如何回收的。
调用栈中的数据是如何回收的
具体看代码:
functionfoo(){var a =1;var b ={name:"极客邦"};functionshowName(){var c ="极客时间";var d ={name:"极客时间"}}showName()}foo()
其调用栈和堆空间状态图如下: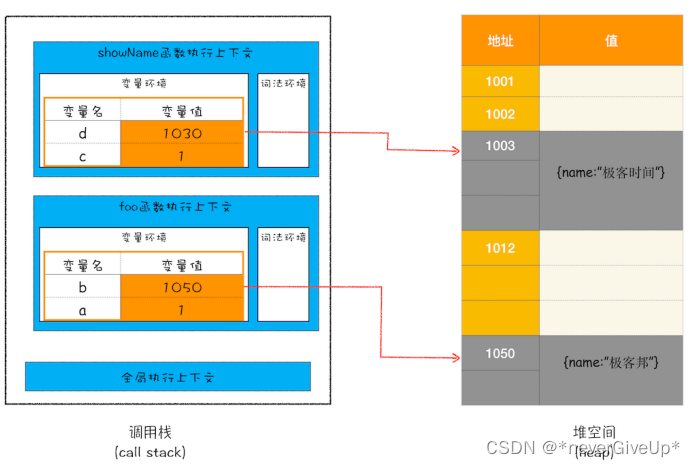
创建完执行上下文,接下来就是执行代码,当执行到showName函数时,与此同时,还有一个记录当前执行状态的指针(称为ESP),指向调用栈中showName函数的执行上下文,表示当前正在执行showName函数。
接着,当 showName 函数执行完成之后,函数执行流程就进入了 foo 函数,那这时就需要销毁 showName 函数的执行上下文了。ESP 这时候就帮上忙了,JavaScript 会将 ESP下移到 foo 函数的执行上下文,这个下移操作就是销毁 showName 函数执行上下文的过程。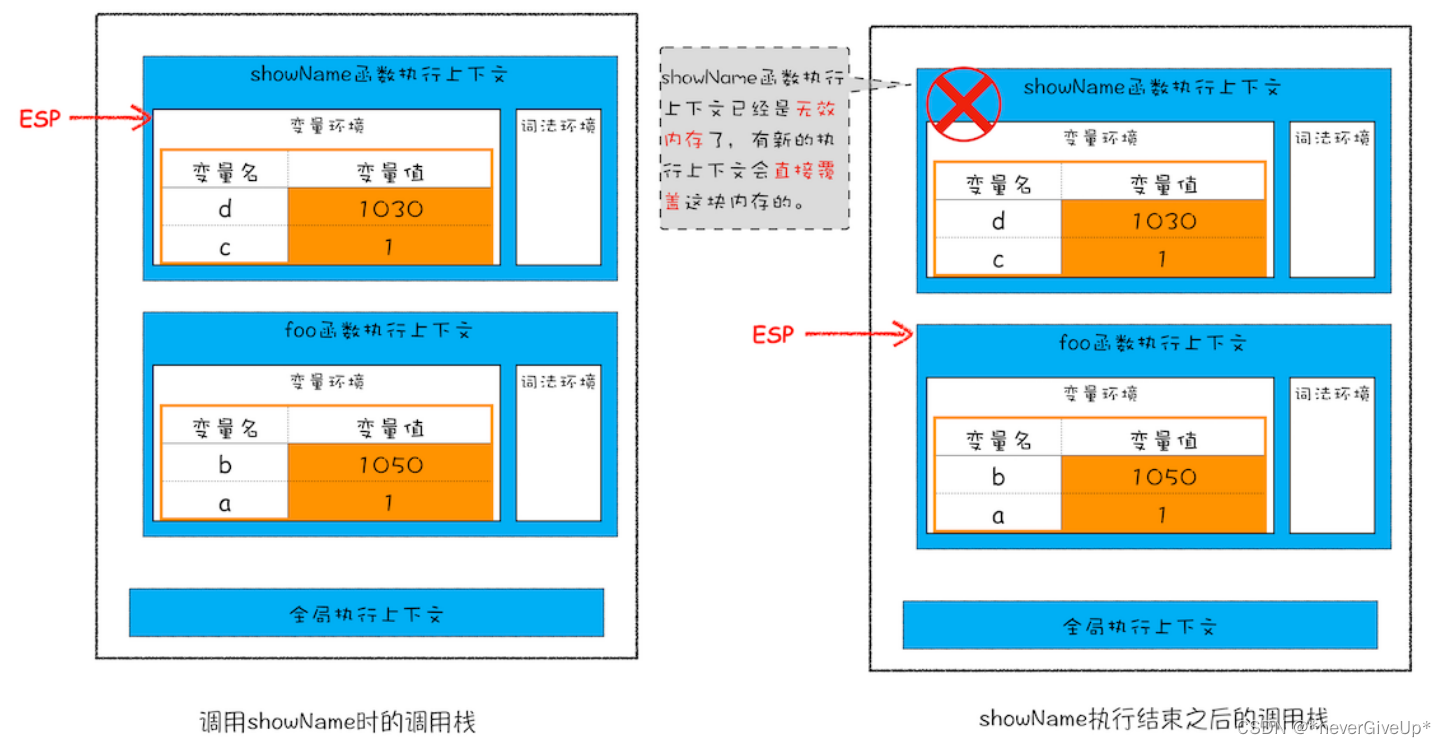
所以说,当一个函数执行结束后,JavaScript引擎会通过向下移动ESP来销毁函数保存在栈中的执行上下文。
堆中的数据是如何回收的
当上面那段代码foo函数执行结束之后,ESP应该是指向全局执行上下文,那这样的话showName 函数和 foo 函数的执行上下文就处于无效状态了,不过保存在堆中的两个对象依然占用着空间,如下图所示: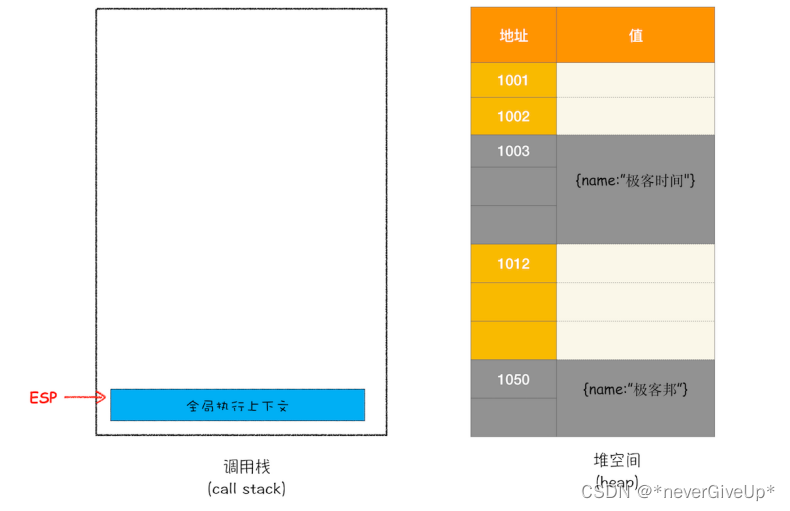
要回收堆中的垃圾数据,就需要用到JavaScript中的垃圾回收器了。所以接下来我们就通过Chrome的JavaScript引擎V8来分析下堆中的垃圾数据是如何回收的。
V8,谷歌收购并使用 C++开发并开源的 JavaScript & WebAssembly引擎,运用于 Chrome 浏览器 & Node.js,所以我们写的 JavaScript 应用,大多数都跑在 V8 上;它的作用就是,让我们所写的JavaScript代码能够让机器识别。
在V8中会把堆分为新生区和老生区两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。新生区通常只支持1~8M的容量,而老生区支持的容量就大很多了。对于这两块区域,V8分别使用两个不同的垃圾回收器,以便高效地实施垃圾回收。
副垃圾回收器,主要负责新生区的垃圾回收。
主垃圾回收器,主要负责老生区的垃圾回收。
副垃圾回收器
副垃圾回收器主要负责新生区的垃圾回收,通常情况下,大部分小的对象会被分到新生区,所以说这个区域虽然不大,但是垃圾回收的还是挺频繁的。
新生区中使用Scavenge算法来处理。所谓 Scavenge 算法,是把新生区空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如下图所示: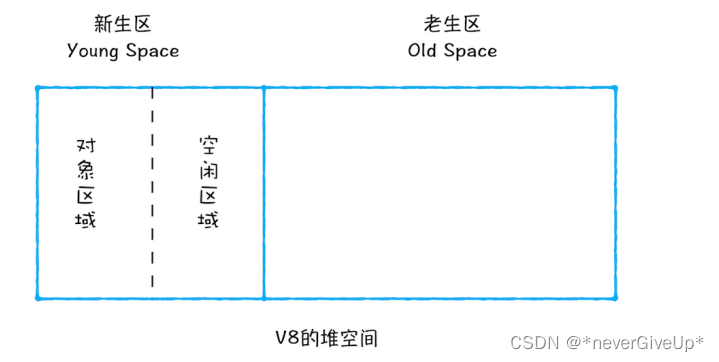
新加入的对象都会存到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作:
- 首先对对象区域中的垃圾做标记
- 垃圾清除阶段,副垃圾回收器会把这些存活的对象复制到空闲区域中,同时还会把这些对象有序地排列起来,所以这个过程也算是完成了内存整理操作,复制后空闲区域就没有内存碎片了。
- 完成复制之后,对象区域与空闲区域进行角色翻转也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。
这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生区中的这两块区域无限重复使用下去。
由于新生代中采用的Scavenge算法,所以每次执行清理操作,都需要将存活的对象从对象区域复制到空闲区域,但复制操作需要时间成本,如果新生区空间设置太大,那么每次清理的时间就会很久,所以为了执行效率,一般新生区的空间会被设置得比较小。
也正是因为新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过 两次垃圾 回收依然还存活的对象,会被移动到老生区中。
主垃圾回收器
主垃圾回收器主要负责老生区中的垃圾回收。除了新生区中晋升的对象,一些大的对象会直
接被分配到老生区。因此老生区中的对象有两个特点,一个是对象占用空间大,另一个是对
象存活时间长。
老生区采用Mark-Sweep(标记-清除)算法进行垃圾回收,以下是它的过程:
- 标记过程:递归遍历元素,在遍历得过程中,能够到达的元素称为活动对象,没有到达的元素称为垃圾数据,把垃圾数据做标记;
什么算是能够到达的元素,什么算是不能到达的元素?
比如前一个代码例子,当showName函数执行退出之后,这段调用栈和堆空间如下图所示: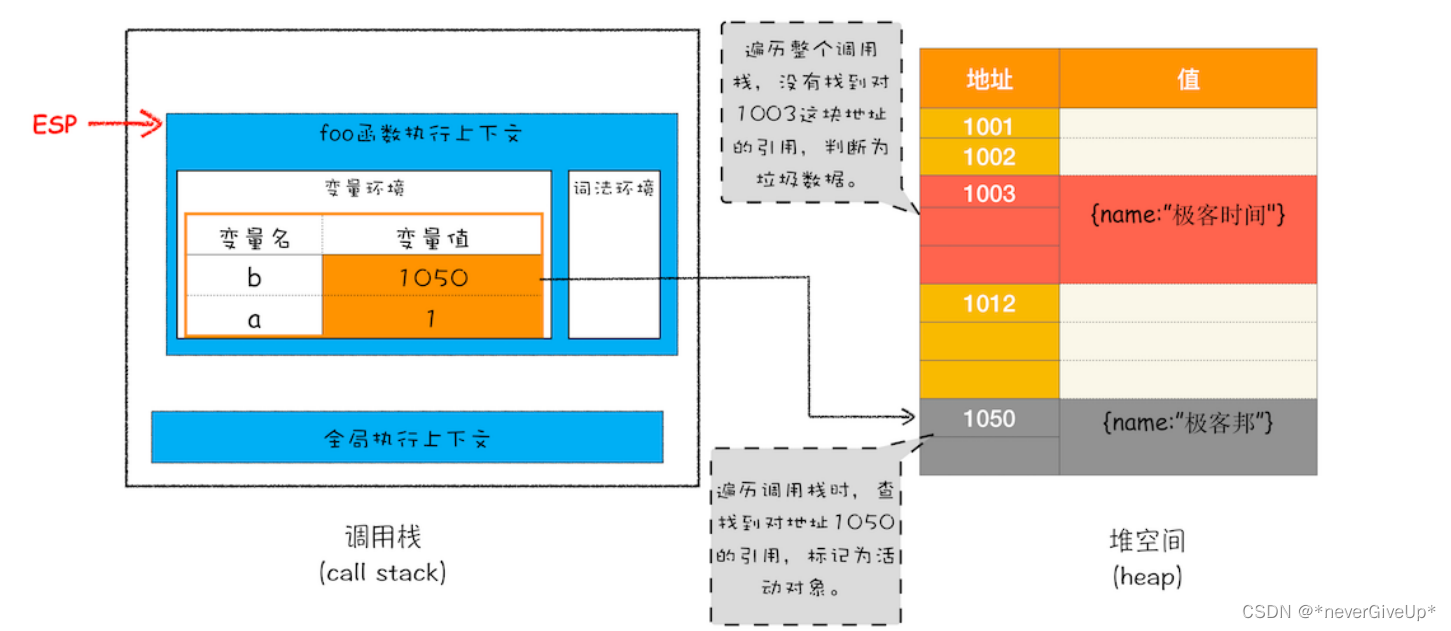
从上图你可以大致看到垃圾数据的标记过程,当 showName 函数执行结束之后,ESP 向下移动,指向了 foo 函数的执行上下文,这时候如果遍历调用栈,是不会找到引用 1003 地址的变量,也就意味着 1003 这块数据为垃圾数据,做个标记。由于 1050 这块数据被变量 b 引用了,所以这块数据为活动对象。这就是大致的标记过程。
- 垃圾的清除过程:把标记的垃圾数据清除
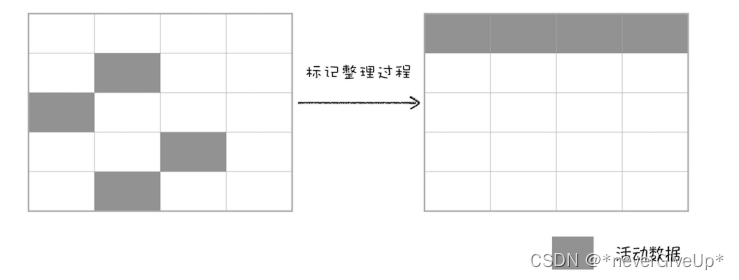
- 标记-整理算法,把垃圾数据清除后产生的大量不连续内存碎片进行整理,让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
 现在你知道了V8是使用副垃圾回收器和主垃圾回收器处理垃圾回收的,到这也差不多文章末尾了,最后我们来总结下。
现在你知道了V8是使用副垃圾回收器和主垃圾回收器处理垃圾回收的,到这也差不多文章末尾了,最后我们来总结下。
总结

版权归原作者 *neverGiveUp* 所有, 如有侵权,请联系我们删除。