
1.题目要求
针对全球重大地震数据进行分析,采用Python为编程语言,采用Hadoop存储数据,采用Spark对数据进行处理分析,并对结果进行数据可视化。
2.需求分析
本项目将使用大数据分析引擎Spark对美国国家地震中心收集的历史地震数据进行分析处理,为了保证研究的可行性,本文选取了1965年—2016年的全球重大地震数据。该数据集记录了该时间段全世界所有震级5.5以上地震的发生时间、场景等详细信息。
数据处理:
对美国国家地震中心1965-2016全球重大地震数据集进行必要的数据处理,使用python语言编写代码,实现根据数据集发生地点的经纬度获取地震的发生地理位置信息。
数据分析:
- 使用大数据引擎Spark对处理后的数据进行分析,统计以年、月、日为单位的地震发生次数。
- 使用大数据引擎Spark对处理后的数据进行分析,统计中国境内每个省份(海域)发生重大地震的次数。
- 使用大数据引擎Spark对处理后的数据进行分析,统计中国境内和世界范围内的不同地震类型的数量。
- 使用大数据引擎Spark对处理后的数据进行分析,统计震级前500的地震次数。
- 使用大数据引擎Spark对处理后的数据进行分析,统计震源深度前500的地震次数。
- 使用大数据引擎Spark对处理后的数据进行分析,震级与震源深度的关系。
- 将分析后的数据上传到Hadoop。
数据可视化:
1.将所有分析后的数据绘制到带有坐标的地图上,并保存为html格式。 2.对分析后的数据集分别选取合适的图表进行可视化(包括散点图、热力图、柱状图、词云等等),并保存为html格式文件方便查看。
流程图:

3.实验环境
官网给出的实验环境,虚拟机为hadoop单节点伪分布式:

本实验采用的虚拟机为厦门大学林子雨老师创建的虚拟机镜像,里面有配置好的实验环境,可以直接使用VMware创建此镜像的虚拟机,安装简单,步骤如下。
下载镜像:
可以访问林子雨老师的公开百度云盘百度网盘 请输入提取码 (baidu.com)(提取码:jysh)进行下载,此镜像大小是7.18G,下载时间较长,下载完成后保存到本地。
如有需要可以访问林子雨老师官方网站进行查看步骤:
大数据Linux实验环境虚拟机镜像文件_厦大数据库实验室博客 (xmu.edu.cn)
安装虚拟机:
详细步骤可以查看此篇教程:VMware导入ova/ovf虚拟机文件_vmware ova-CSDN博客
按图片步骤进行安装:
在VMware里选择打开虚拟机文件:
选择虚拟机文件
设置名称和安装路径:
安装完成后打开虚拟机,进入hadoop用户,默认密码为hadoop,升级root用户密码也是hadoop。
内部环境:
我使用的python版本为3.7版本,在进行环境配置时发现,该版本与spark 1.8和spark 2.1是不兼容的,而此虚拟机的spark是1.6版本,于是对spark进行升级,以下是各版本兼容表。
Linux
Hadoop
Spark
Python
是否兼容
Ubuntu 16.4
Hadoop 2.7
Spark 1.8
Python 3.7(anaconda)
不兼容
Ubuntu 16.4
Hadoop 2.7
Spark 2.1
Python 3.7(anaconda)
不兼容
Ubuntu 16.4
Hadoop 2.7
Spark 2.4
Python 3.7(anaconda)
兼容
最终采取的配置如下:
Ubuntu 16.4 + Hadoop 2.7 + Spark 2.4 + Python 3.7 (Ananconda)

安装plotly用于绘制地图,安装wordcloud用于绘制词云图。
conda install plotly
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple wordcloud
4.数据预处理
下载数据:
earthquake.csv有
23412条地震数据,下载百度网盘地址为:百度网盘 请输入提取码 提取码: 2hza
上传数据:
可以直接拖动已下载的csv文件到ubuntu内,也可以通过xftp进行远程连接上传。
创建jupyter notebook:
使用以下命令新建一个jupyter开发环境并设置密码:
jupyter notebook --generate -config
jupyter notebook password # 按提示,输入密码,确认密码
然后在终端输入jupyter notebook,后台启动lupyter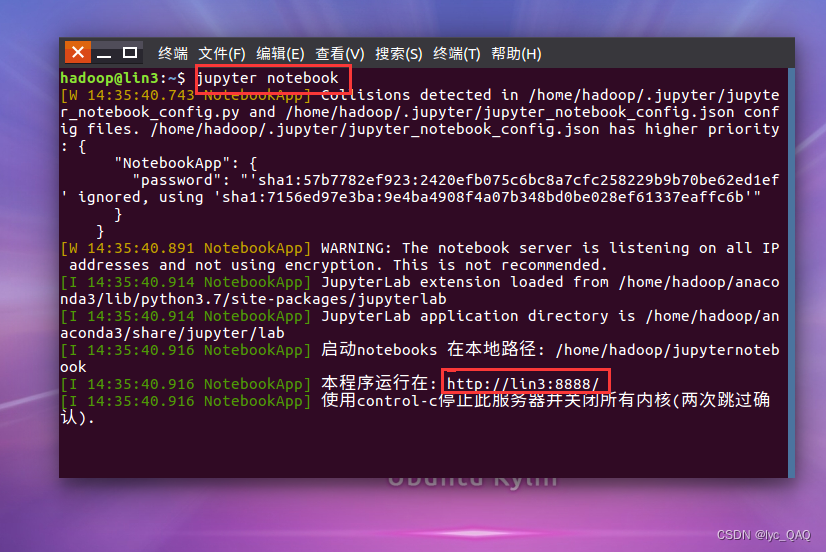
在浏览器中输入程序运行的网址进入jupyter,并输入之前设置的密码。

读取数据:
import pandas as pd
import numpy as np
data = pd.read_csv('~/jupyternotebook/bigdataProject/earthquake.csv')
data.head(10)
清洗数据:
查看全数据信息
data.describe()
查看有无重复值
data.duplicated().sum()
查看各列的基础信息
data.info()
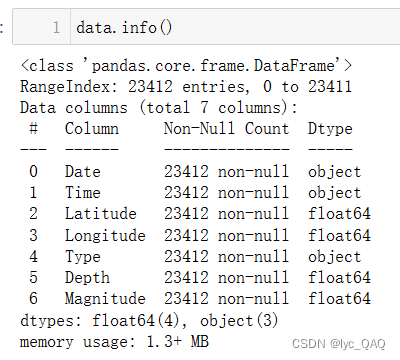
其中‘Date’、‘Time’属性均为object,故数据清洗分为两部分:‘Date’属性清洗和‘Time’属性清洗。
‘Date’列:
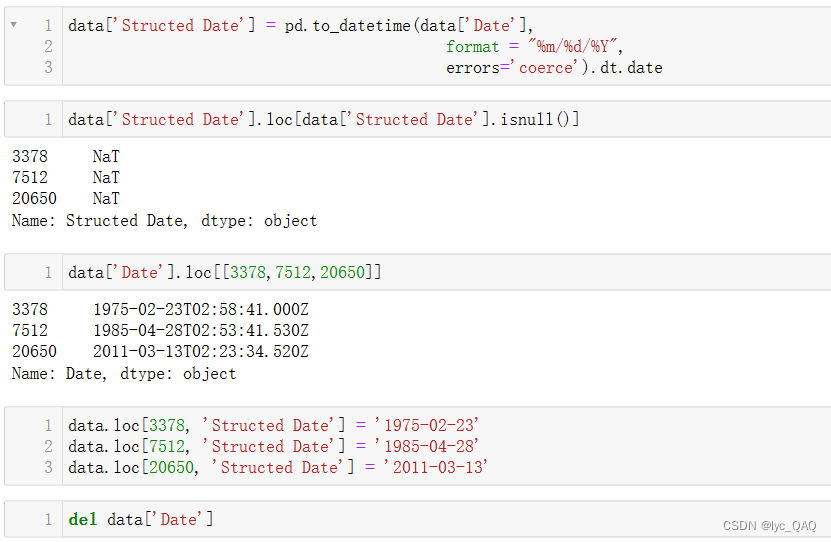
首先,我们使用pandas内置函数to_datetime () 来对原‘Date’列进行格式的转换。其中format用于将年、月、日分别映射到原数据的年、月、日;errors用来设置错误情况,‘coerce’参数意味着当出现格式无法进行转换的时候,会将其值记为‘NaT’。我们创建了一个‘Structed Date’属性来存放转换后的‘Date’值。然后通过isnull () 函数来查看转换后的数据,可以发现有3行转换出现错误,分别是378、7512、20650行。为了修正这三行,我们需要用loc () 函数手动定位到这三行,然后进行数据的修改。最后,将原本的‘Date’列删除。
‘Time’列:
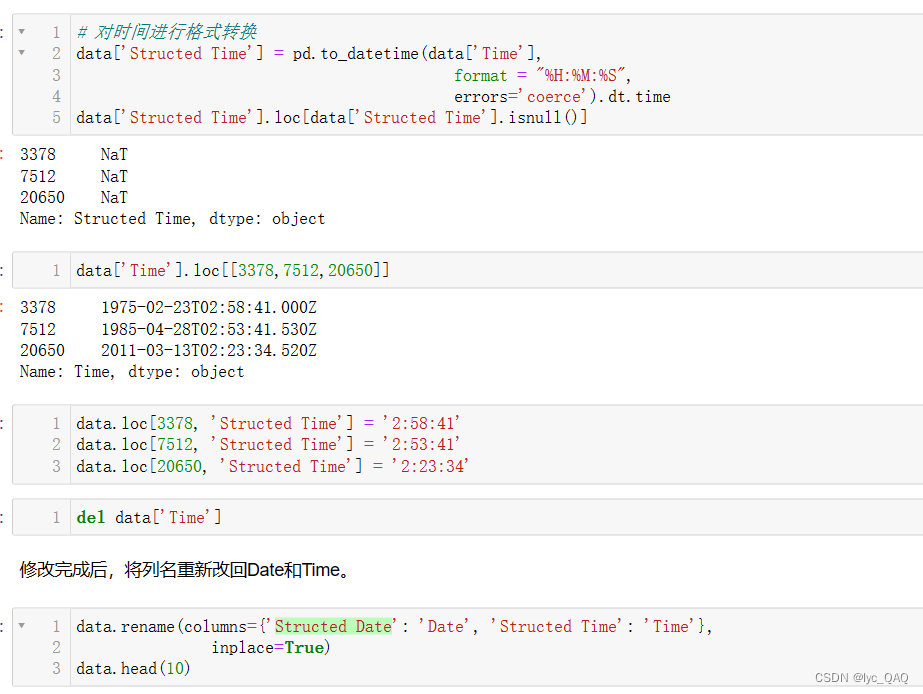
首先,我们使用pandas内置函数to_datetime () 来对原‘Time’列进行格式的转换。其中format用于将时、分、秒分别映射到原数据的时、分、秒;errors用来设置错误情况,‘coerce’参数意味着当出现格式无法进行转换的时候,会将其值记为‘NaT’。‘Structed Time’属性来存放转换后的‘Time’值。然后通过isnull () 来查看转换后的数据,可以发现有3行转换出现错误,分别是378、7512、20650行。使用loc () 手动定位到这三行,然后进行数据的修改。最后,将原本的‘Time’列删除。
5.根据经纬度获取地名
我们首先调用高德的逆地址解析API,根据地震发生的经纬度进行确定在哪个区域发生的地震。
高德API服务:
(1) 首先注册成为开发者
(2) 创建API的key用于调用逆地址解析

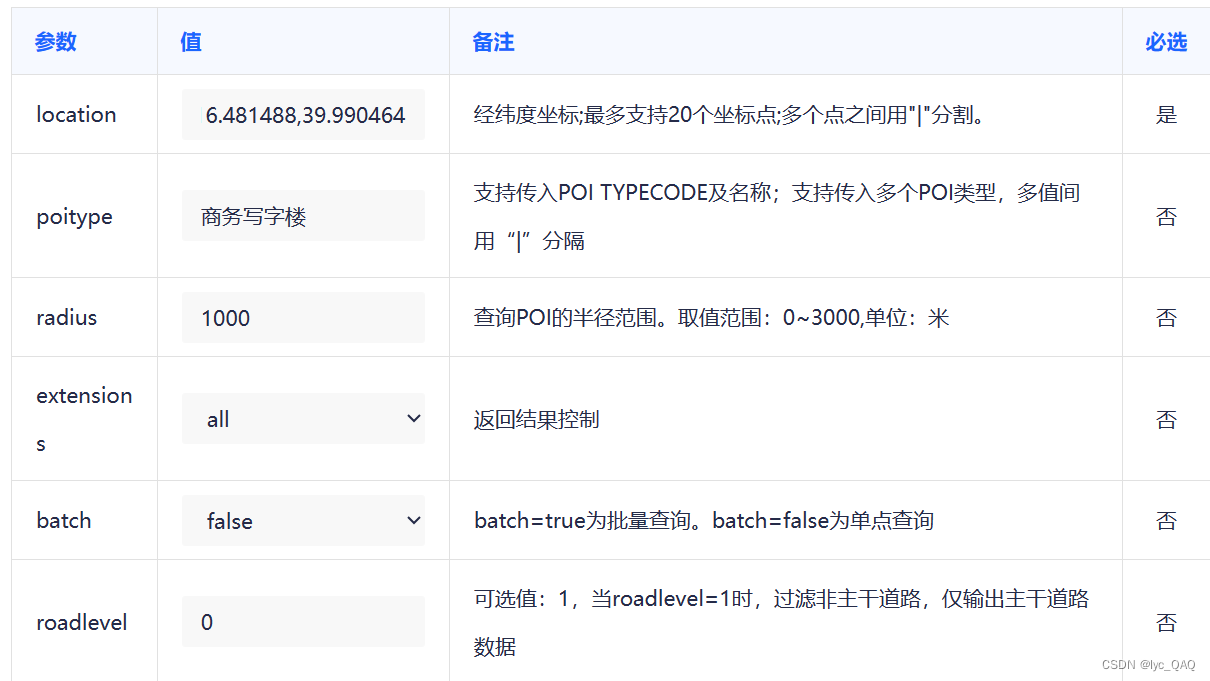
 (3) 传入参数解读
(3) 传入参数解读
(4) 根据已创建的key,利用request请求进行调用API,传入所有地震发生的经纬度获取区域名称并提取。根据自定义的函数getProvince () 为每个经纬度坐标获取位置信息,大概需要花费十分钟左右的时间。

结果如上图,使用unique () 函数对结果查看。可以发现这个API对于中国境内海域和境外的坐标不能准确地返回结果。坐标在中国境内海域时,返回的结果是‘中人民共和国’;坐标在中国境外时,就返回一个空值。
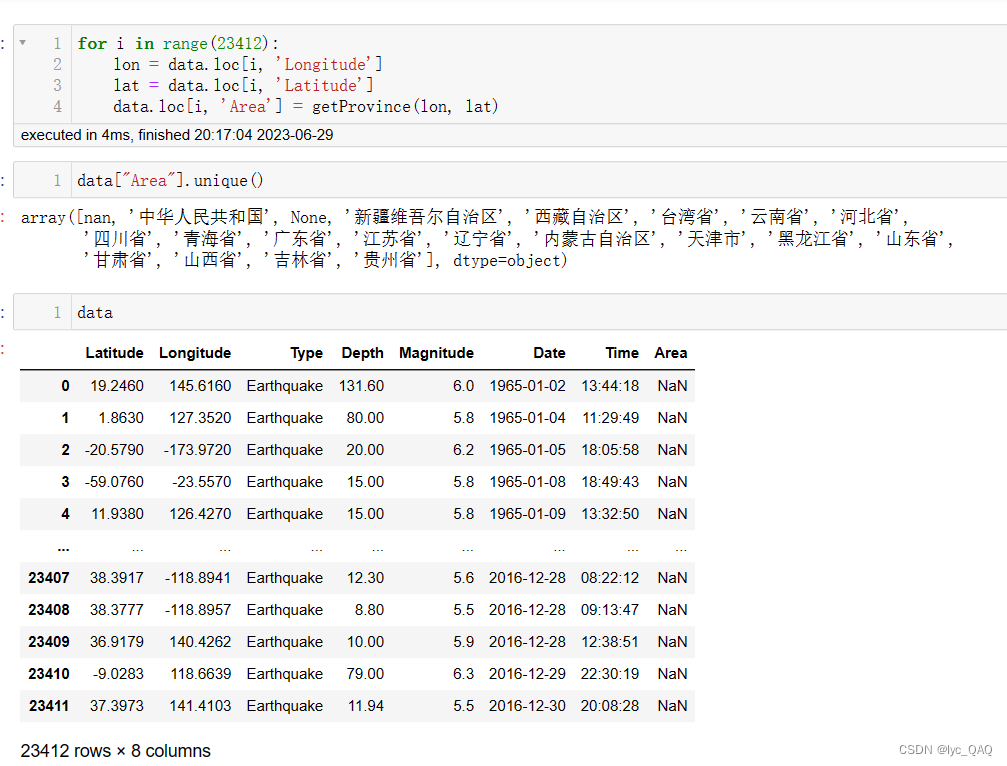
查看data数据,可以看到很多境外的坐标调用结果都是NaN。对于提取有误的结果,我们换腾讯API服务网站进行结果调用。
腾讯API服务:
(1) 对国内地震区域名称进行提取
首先将request的查询结果转换为json类型(以北京为例)。

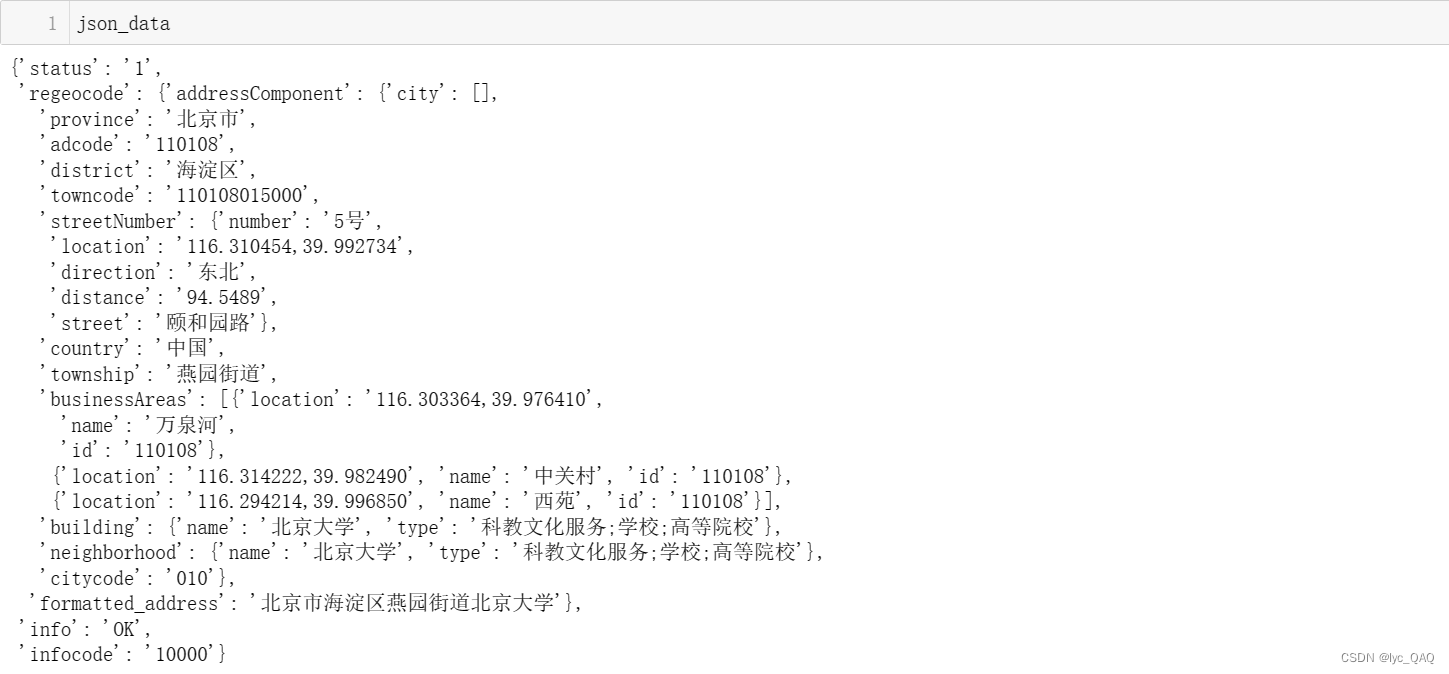
可以看出我想要的区域省份名称在’regeocode’下的’addressComponent’里的’province’,所以我们对查询结果进行一级一级的提取,最终得到地震发生的区域名称。

(2) 对中国地震区域名称提取
高德地图的定位会过于笼统,有些中国区域内的偏僻地区省份以及海域的经纬度识别不出来,并且会发生数据丢失的情况,我们用腾讯API对中国地震区域名称进行提取,腾讯的逆地址API的调用与高德一致,都是通过一个key来调用查询。
对比分析(同一经纬度35.206,115.213):
1)调用高德查询
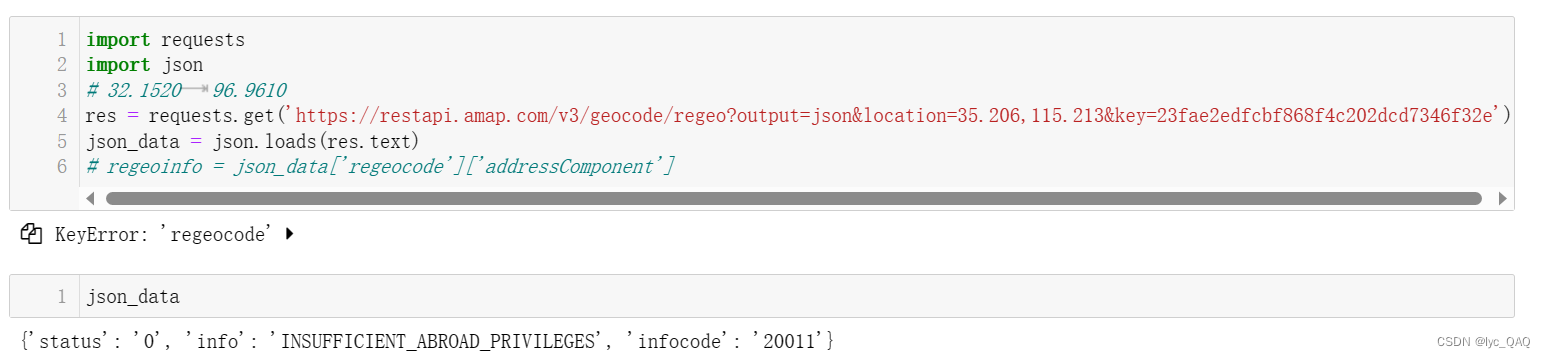
解析以上的报错原因

2)调用腾讯查询
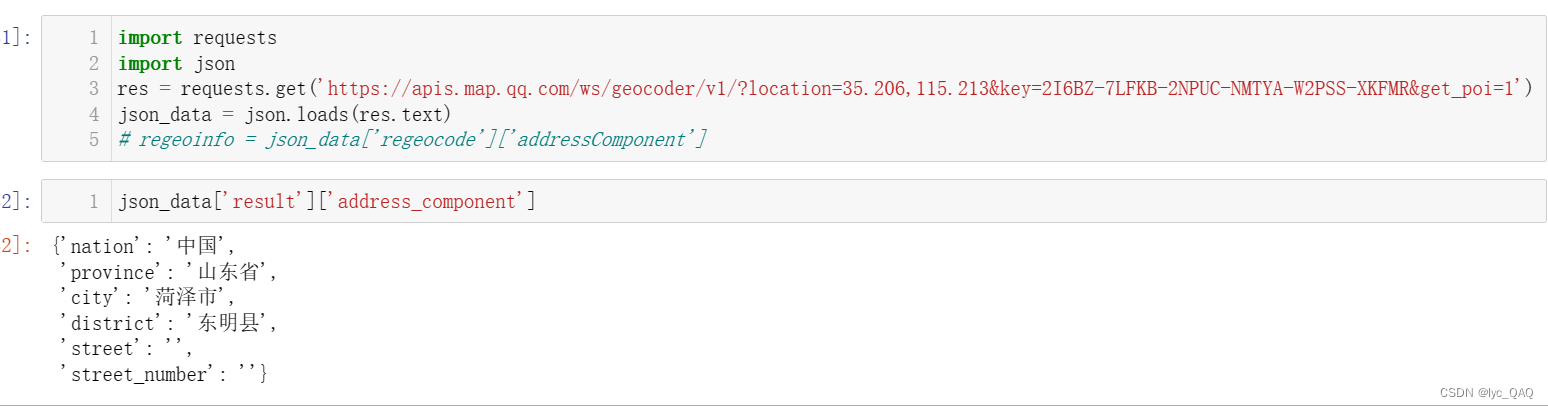
可见同样的经纬度,在调用腾讯API时可以识别出准确省份,而高德API识别不出。
下面对于调用高德API没有识别出的海洋区域,利用腾讯API进行提取。对海洋区域查询结果进行测试:
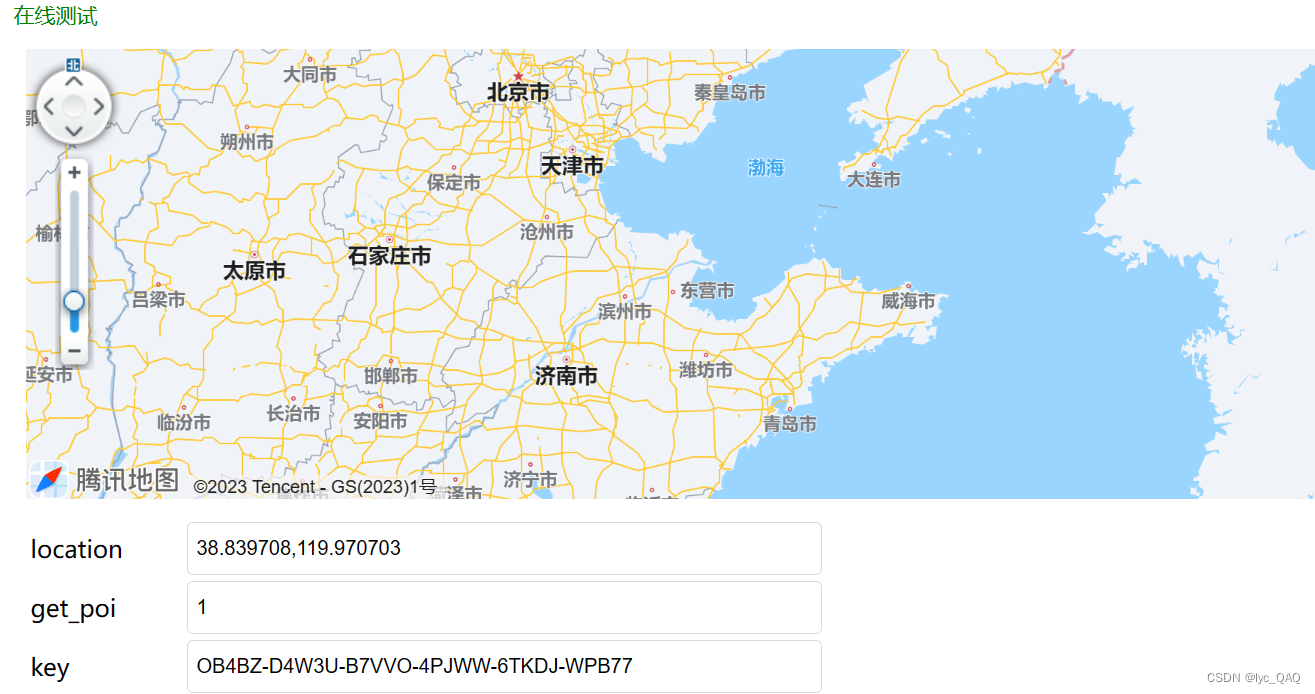
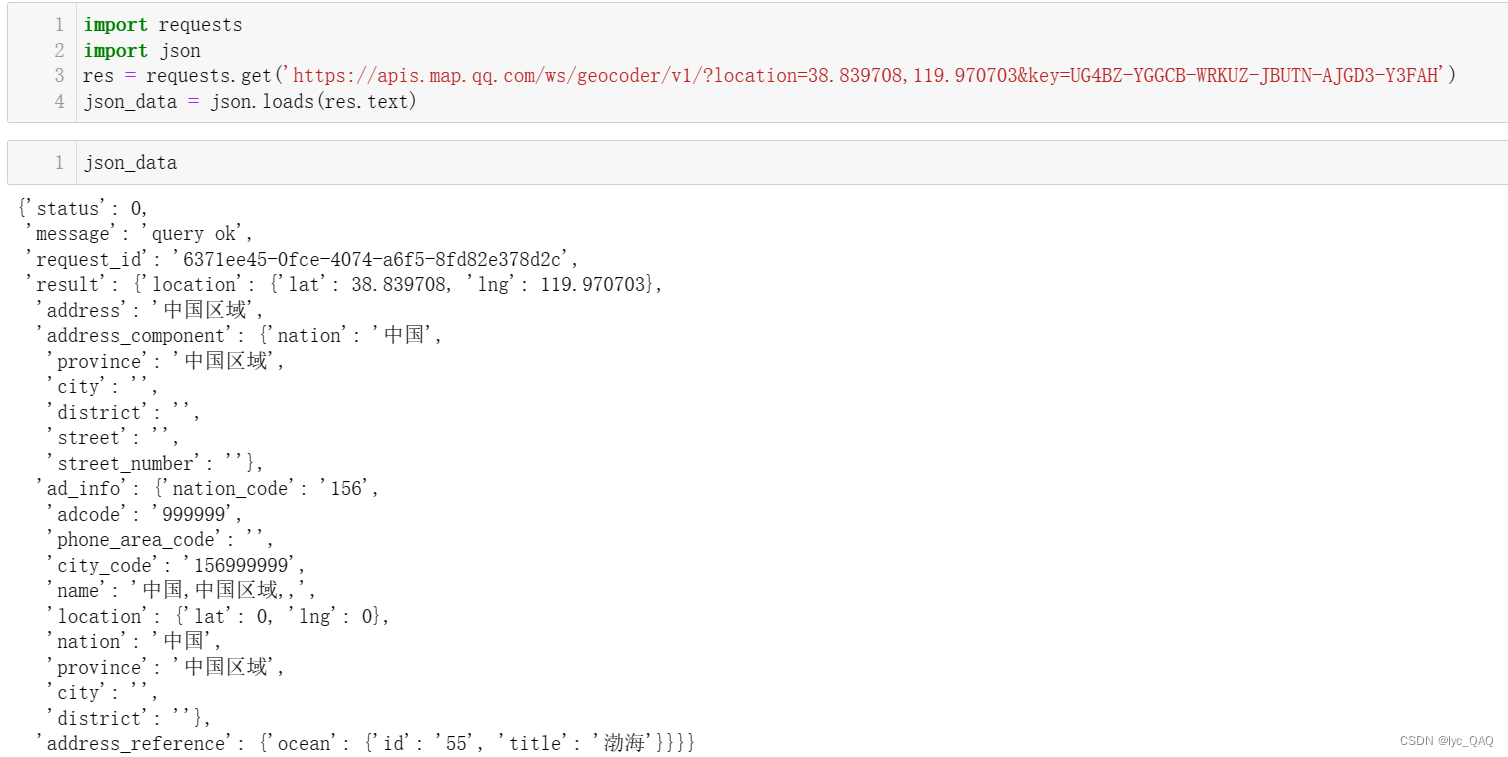
可以看出海域名称在 ’result’ 下的 ’address_reference’ 下的 ’ocean’ 下的 ’title’ 里,对中国地震海域名称进行提取:


将提取的海域数据与原数据合并:

最终得到了中国境内的地震区域名称:

(3) 提取世界范围以国家为单位的发生地震区域名称
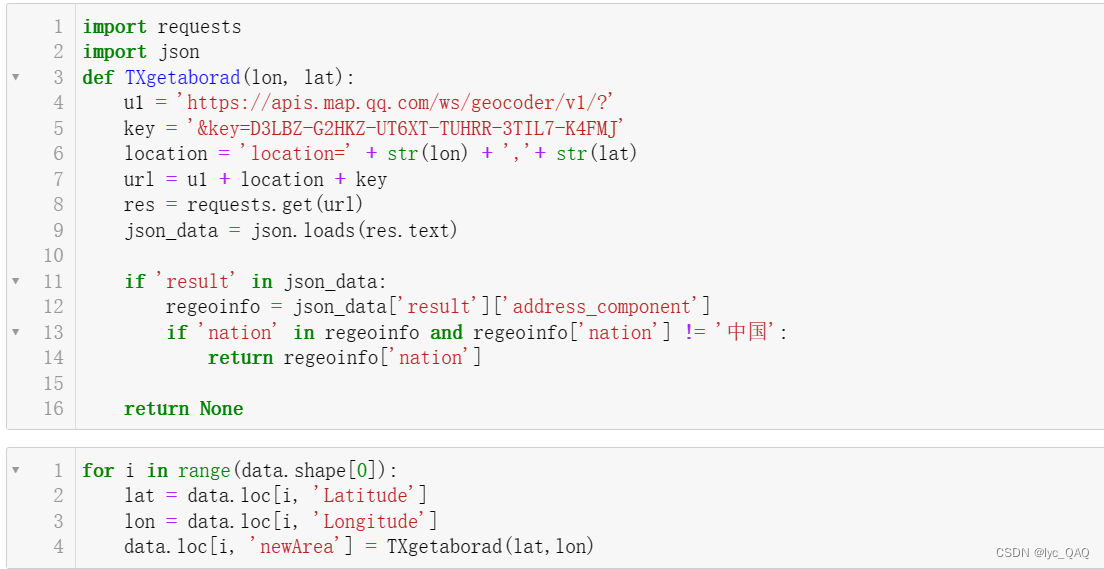

getProvince () 函数来根据调用API服务网站实现该功能。
部分参数的定义ul:API服务网站(这里我们使用了高德API和腾讯API两种服务进行对比);key:API服务网站的密码(由网站定义);location:自定义的位置信息字符串。
然后通过requests的函数get () 调用那个网页获取位置信息,并将结果转化为json格式。由于网站给出的信息内容很多,我们只需要其中省份这一部分,所以对查询结果先判断是否为中国区域,如果是则进行下一步具体省份提取,最终返回所需要的信息。
import requests
import json
def getProvince(lon, lat):
u1 = 'http://restapi.amap.com/v3/geocode/regeo?output=json&'
key = '&key=23fae2edfcbf868f4c202dcd7346f32e'
location = 'location=' + str(lon) + ','+ str(lat)
url = u1 + location + key
res = requests.get(url)
json_data = json.loads(res.text)
regeoinfo = json_data['regeocode']['addressComponent']
if 'country' in regeoinfo and regeoinfo['country'] == '中国':
if 'province' in regeoinfo and regeoinfo['province']:
return regeoinfo['province']
elif 'seaArea' in regeoinfo and regeoinfo['seaArea']:
return regeoinfo['seaArea']
return None
6.上传数据
数据清洗工作完成之后,还需要对数据上传到Hadoop。通过to_csv () 函数将数据保存到文件earthquake_cleaned.csv中,编码设为utf-8,防止spark读取的时候出现中文乱码。
rawData.to_csv("earthquake_clean.csv",
encoding='utf-8',
index=False)
(1) 启动Hadoop
查看各组件状态
** (2) 上传到HDFS**


7.Spark数据分析
(1) 读取数据
从HDFS中读取处理后的文件:
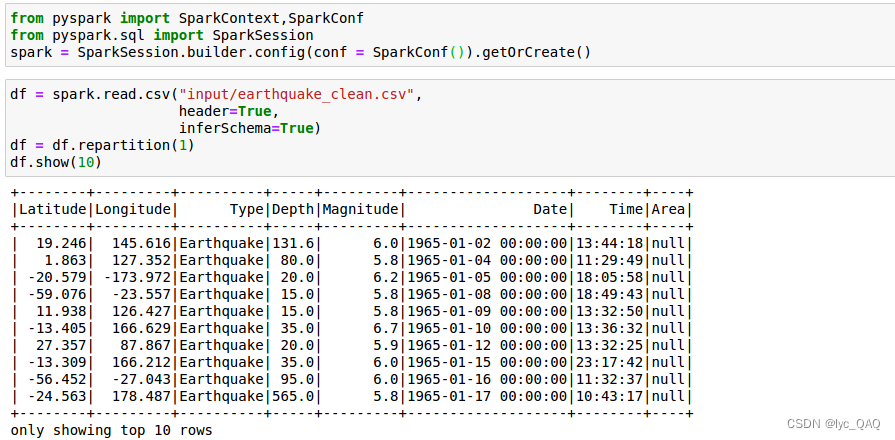
显示数据部分行后发现Spark读取csv文件时将Date列读取成了‘1965-01-02 00:00:00’的格式,因此还需要进一步对数据进行处理。对‘Date’属性进行拆分,丢掉后面00:00:00的部分。使用split () 函数根据空格对‘Date’属性进行拆分,我们只需要第一部分的数据,故对其使用索引值切片获得所需的部分。withColumn () 是 spark 中常用的 API,可以用于添加新字段 / 字段重命名 / 修改字段类型,这里我们用来添加新字段。withColumnRenamed () 用来对字段进行重命名。
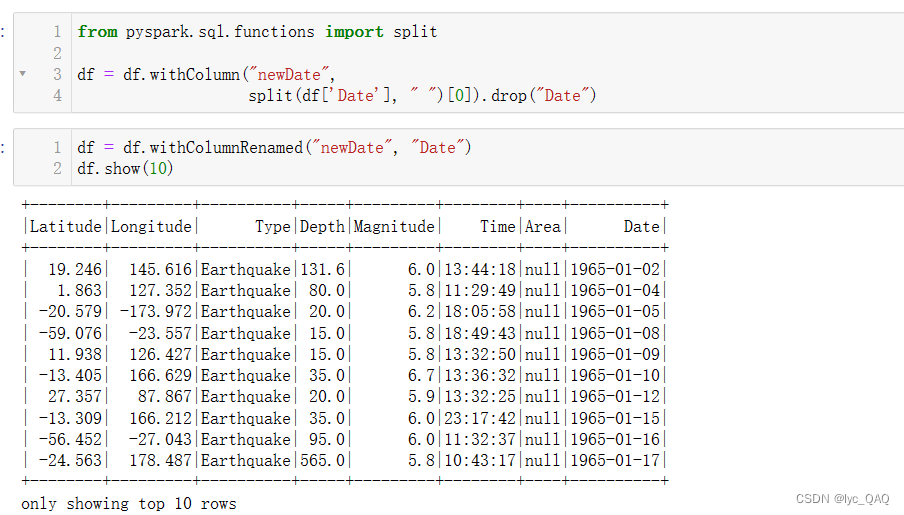 ** (2) 添加年、月、日列**
** (2) 添加年、月、日列**
为了分别以年、月、日为时间粒度统计全球地震数据,我们将‘Date’属性分为‘Year'、‘Month’、
‘Day’,三个属性,并添加到数据表中
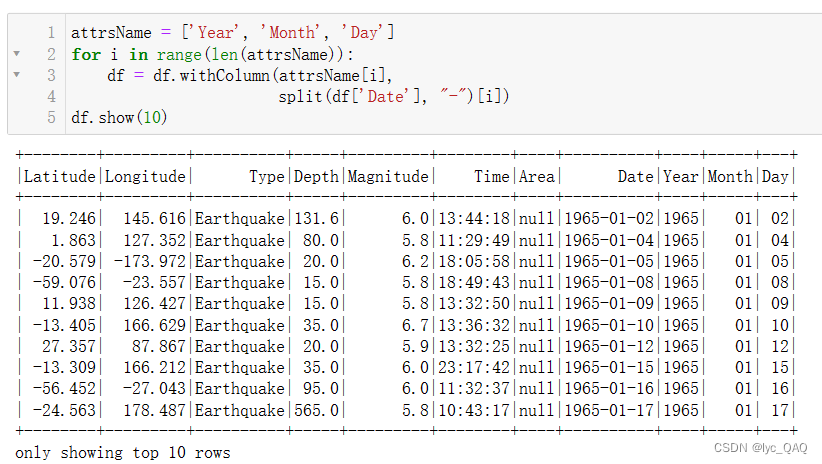
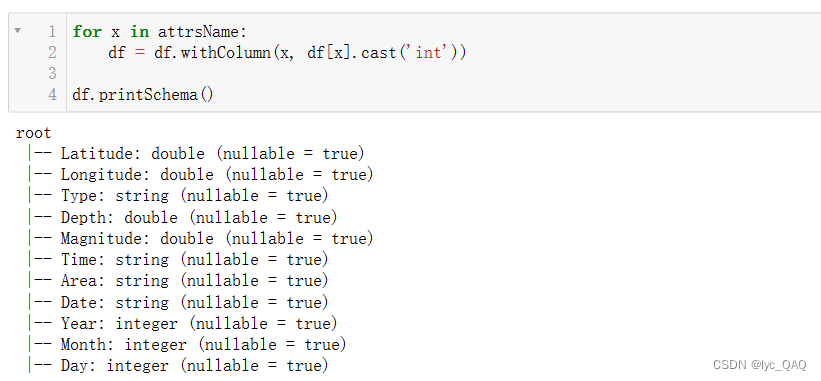
由于切分后的数据类型为字符串型,我们需要将其进行格式转换。通过 for 循环遍历 attrsName 列表中的每个属性名,将 DataFrame 中对应的列通过Spark的withColumn () 函数重新赋值,并使用cast () 将其转换为整数类型。
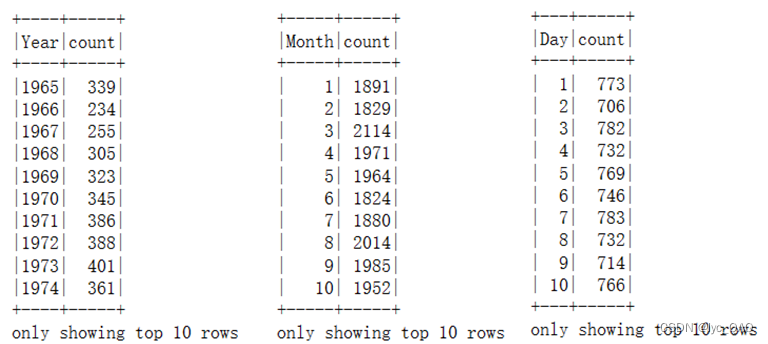
** (3) 统计各年、月、日重大地震的次数**
转换格式后,我们对数据分别以年、月、日地震数据进行统计。如下图,通过常见函数groupBy () 对数据的‘year’属性进行分组,并通过count () 函数分别对每个组进行统计,最后用orderBy () 函数对统计结果进行排序。统计完成之后,将数据存入countByYear.csv”文件。年、月、日的统计过程一致。将结果保存到文件中,方便之后进行可视化。由于使用Spark自带的函数将DataFrame保存为csv文件时,文件会保存为文件夹,在本地读取时比较麻烦。因此使用toPandas()方法将Spark的DataFrame转换成pandas的DataFrame,再保存为csv文件,方便可视化时读取。这里展示了以年为例的代码部分。

** (4) 统计中国各省份(海域)发生重大地震的次数**
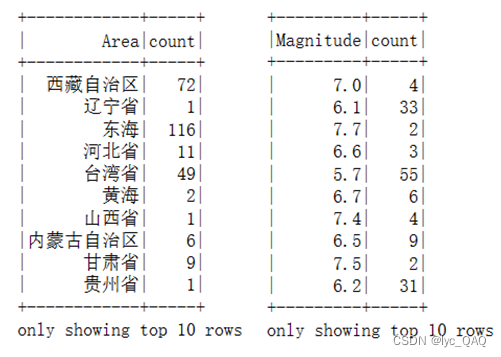
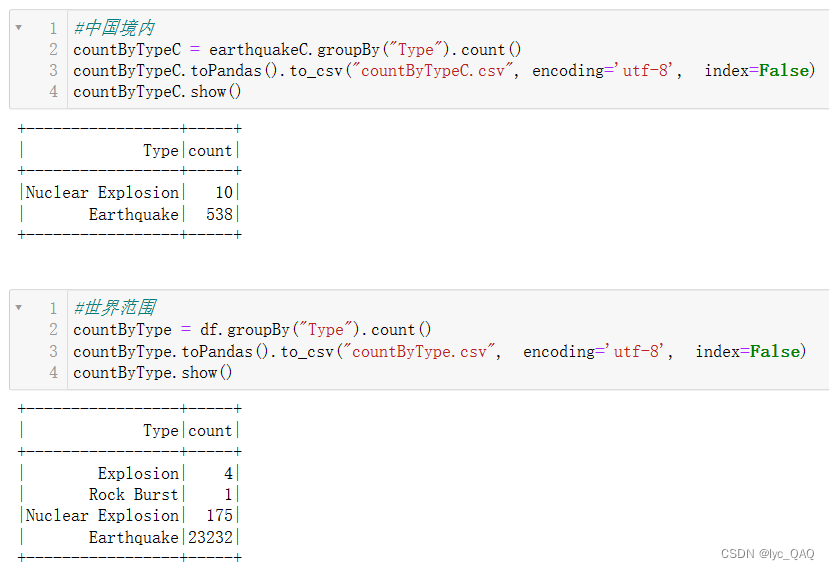
(5) 统计不同类型地震的数量
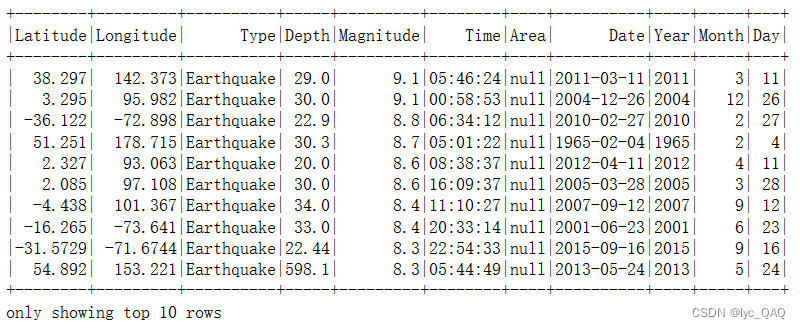
(6) 统计震级前500的地震
(7) 统计****震源深度前500的地震
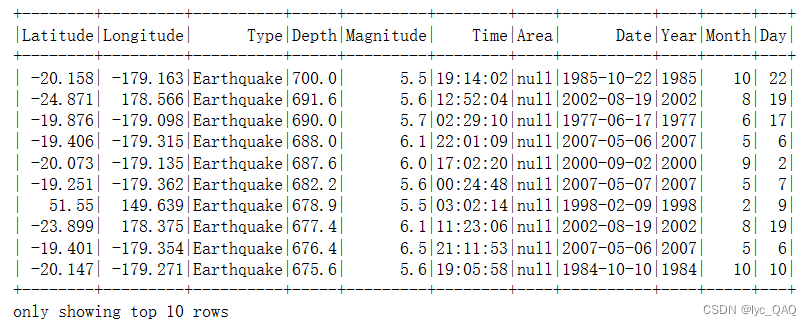
(8) 统计震级与震源深度的关系

上述是我针对中国境内数据进行的统计,还有针对全世界的数据进行统计,这里不再给出。以下是我统计得到的所有文件,根据这些文件进行数据可视化

8.数据可视化
我从中国境内、世界范围、全球总体三个方面进行数据分析与可视化。,用到的可视化库有plotly和pyecharts。
(1) 中国境内地震数据可视化

中国区域总体地震分布地图
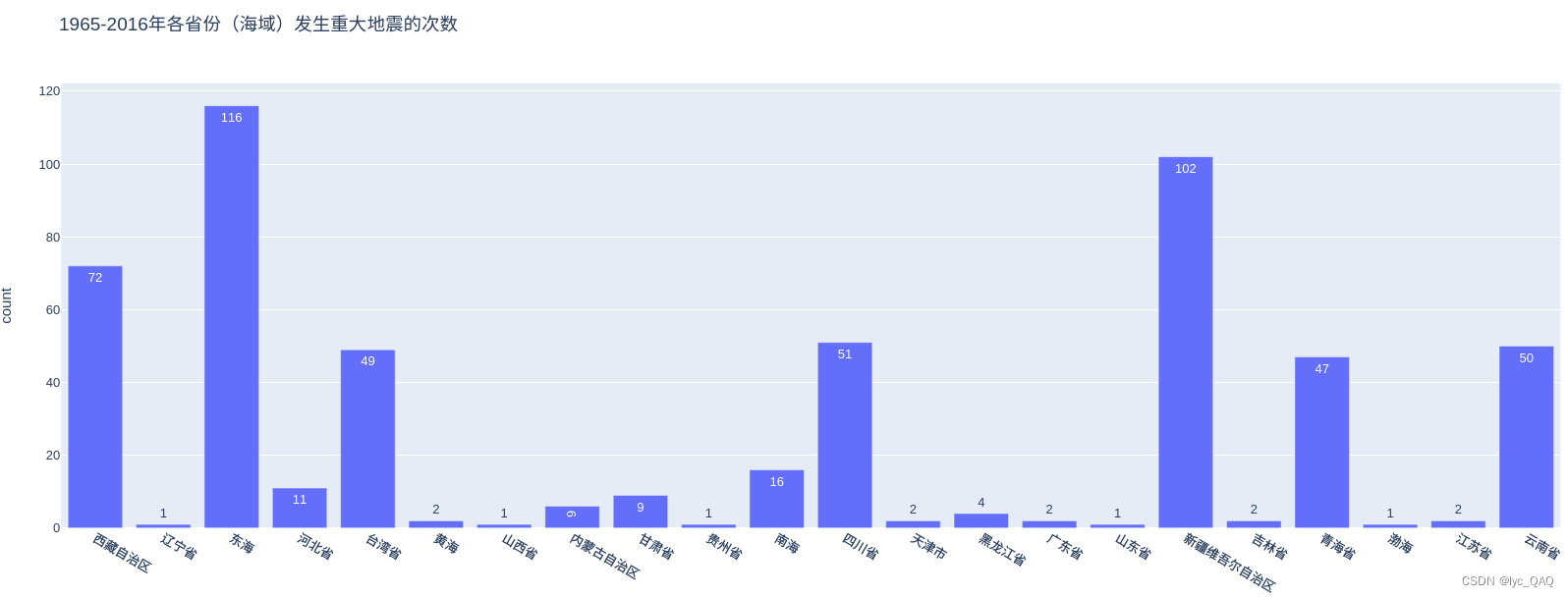
中国各省份(海域)发生重大地震的次数

中国区域内各省份地震次数分布(省级地图)

中国区域内各省份地震次数分布(词云图)
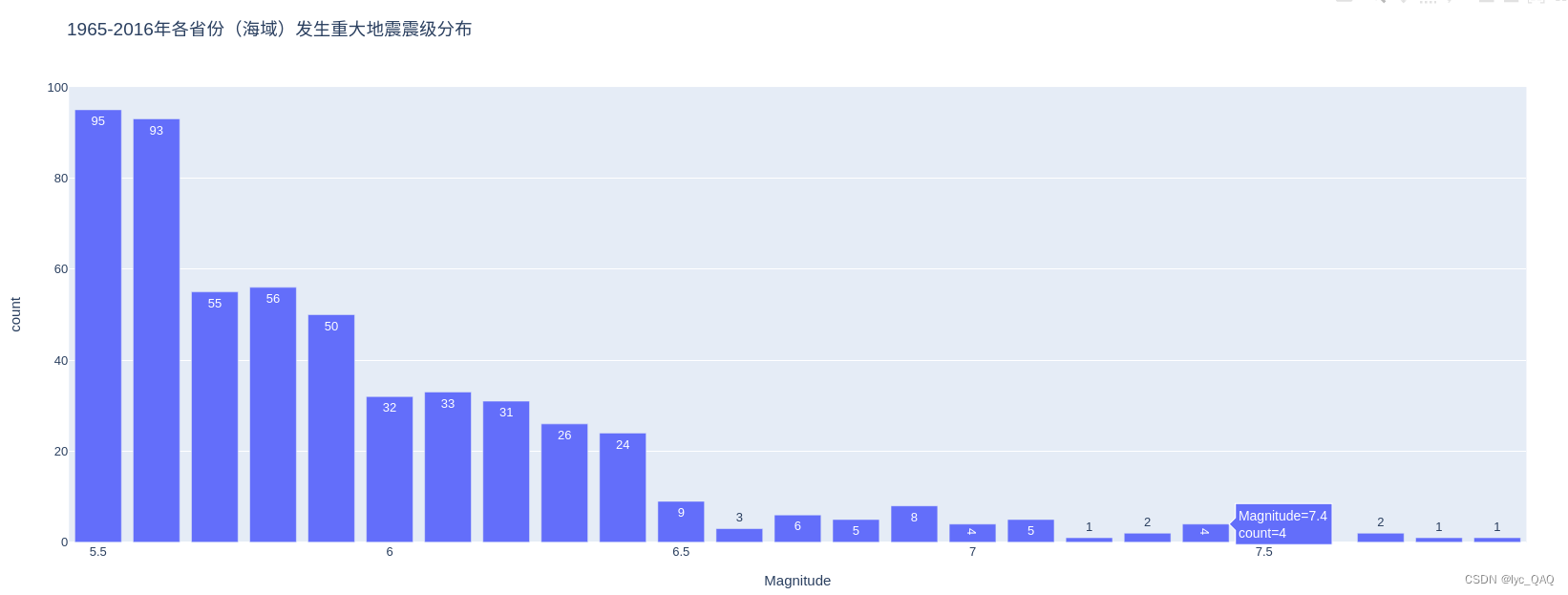
中国各省份(海域)发生重大地震的震级分布柱状图

中国区域内各省份地震类型分布占比图
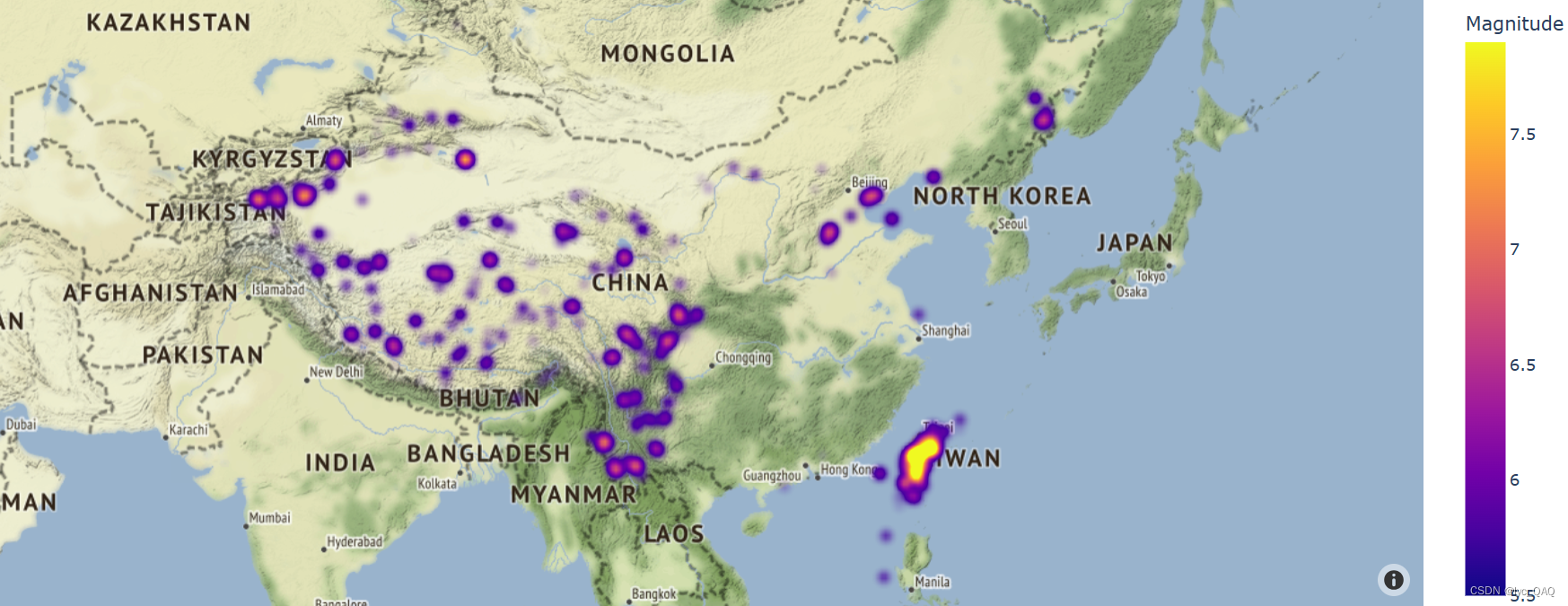
中国区域内地震震源热力图(符合地震带分布)
将我绘制的热力图与中国强震及地震带分布图对比:
 (2) 世界范围地震数据可视化
(2) 世界范围地震数据可视化
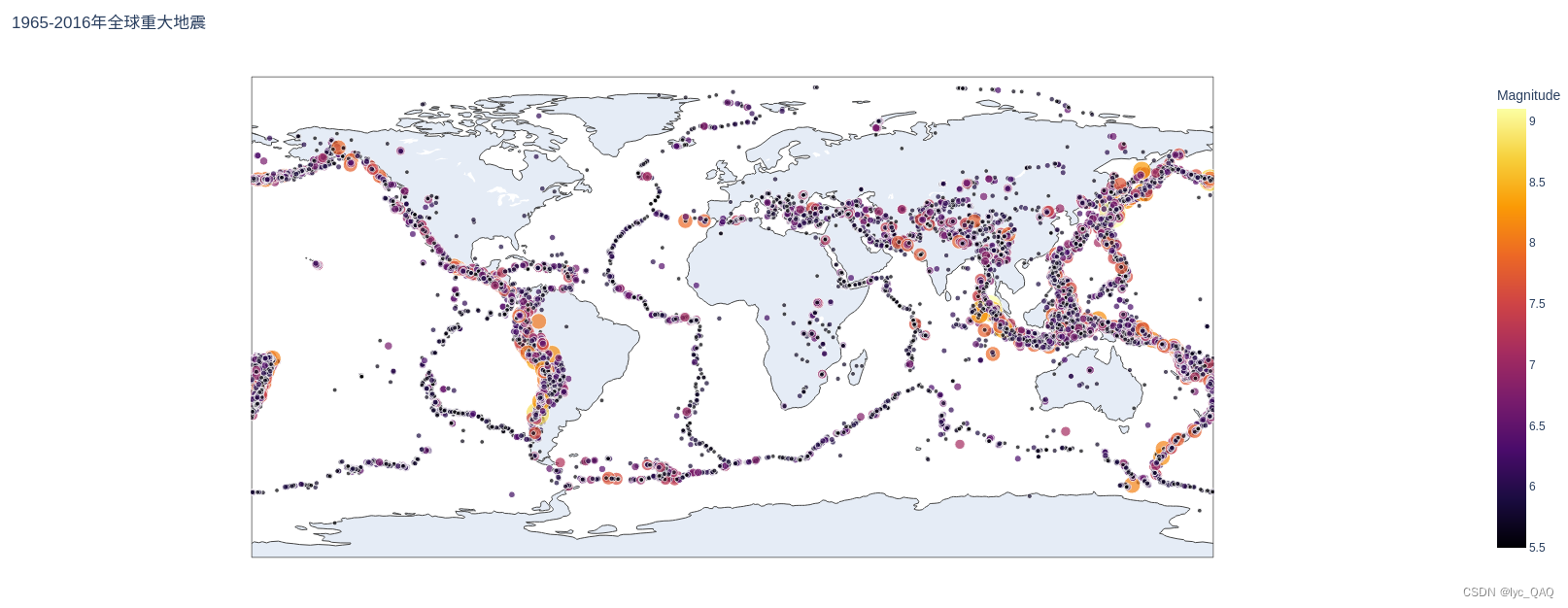
世界区域内总体地震分布图

世界区域内各国家地震次数分布柱状图

世界区域内各国家地震次数分布词云图

世界区域内各国家地震类型分布占比图

世界区域震源热力图
将我绘制的热力图与全球地震带分布图对比:
(3) 全球总体地震数据可视化
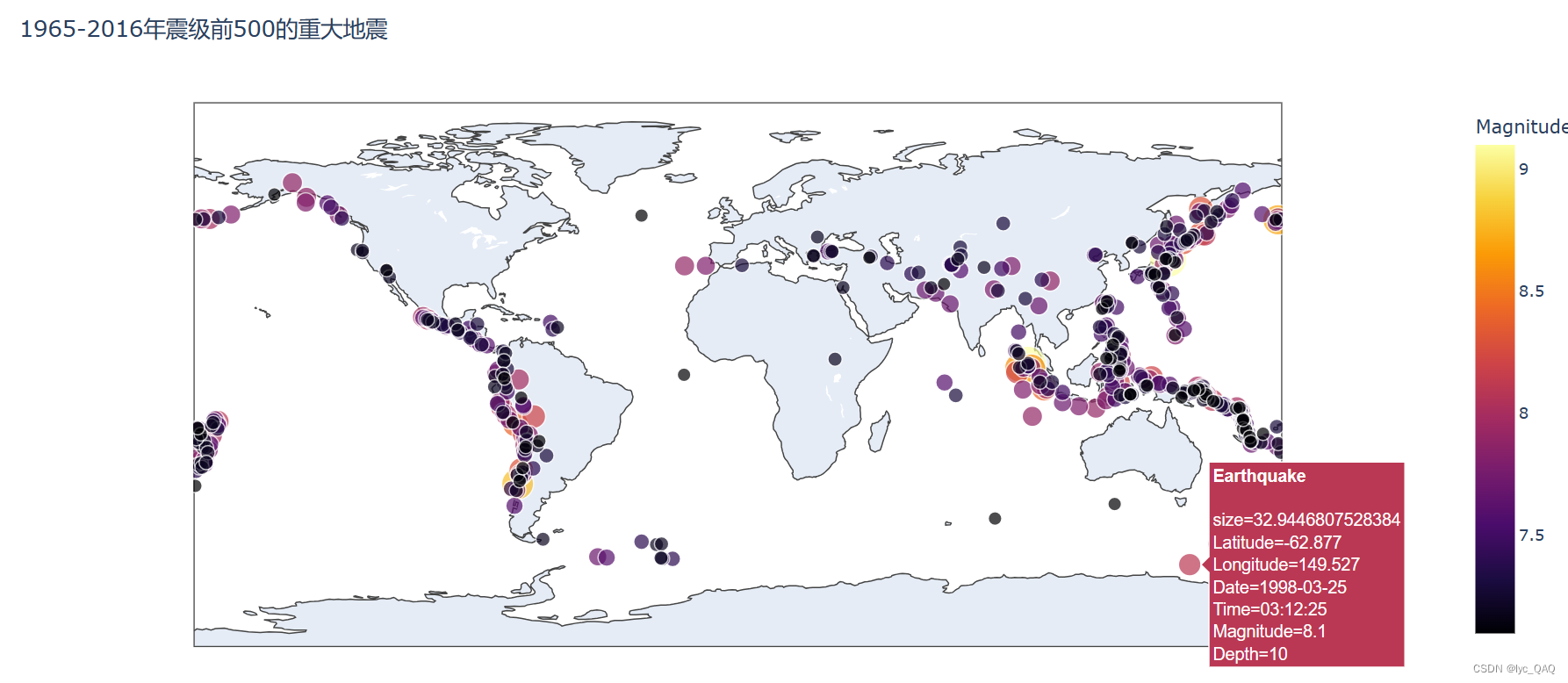
震级前500重大地震世界区域分布

震源深度前500重大地震世界区域分布
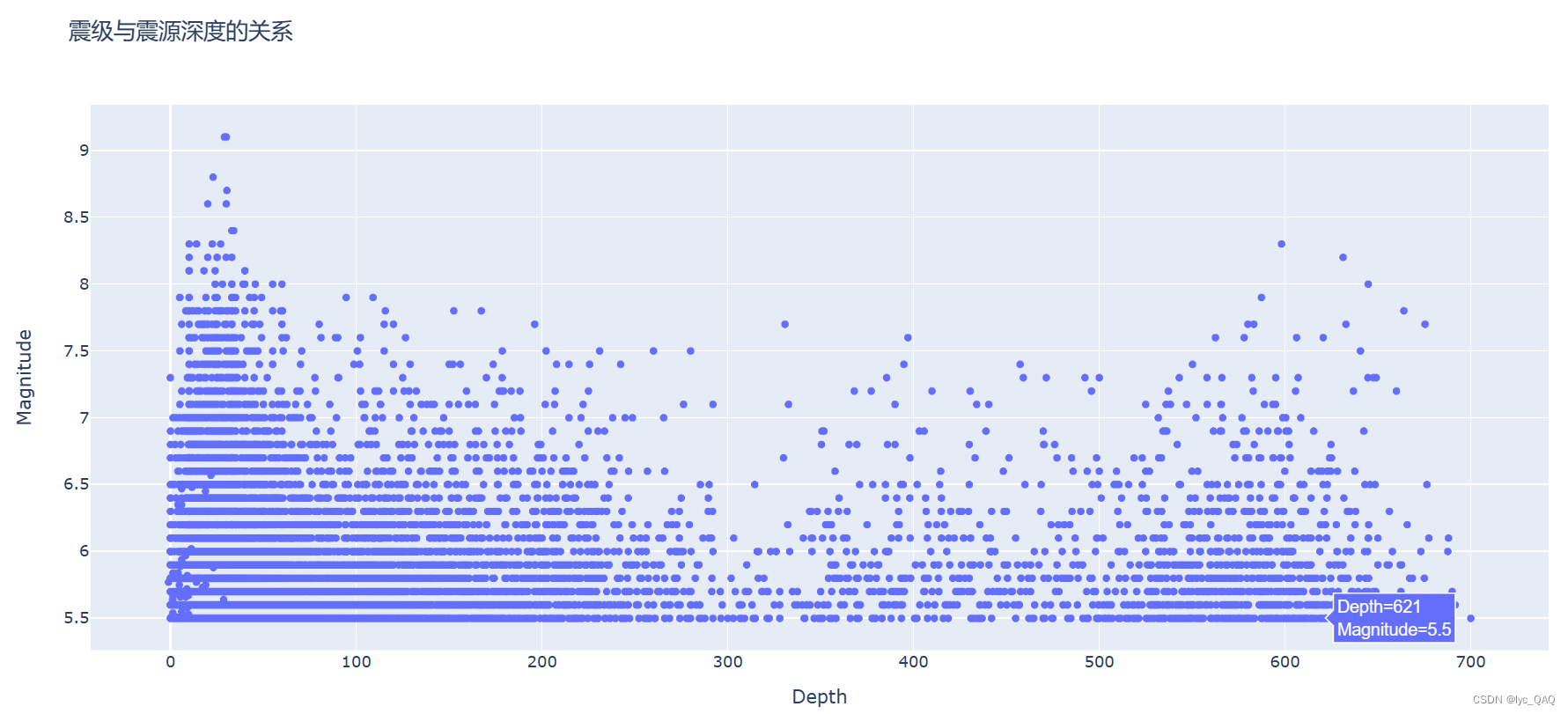
震级与震源深度关系散点图

世界范围内重大地震次数年变化柱状图
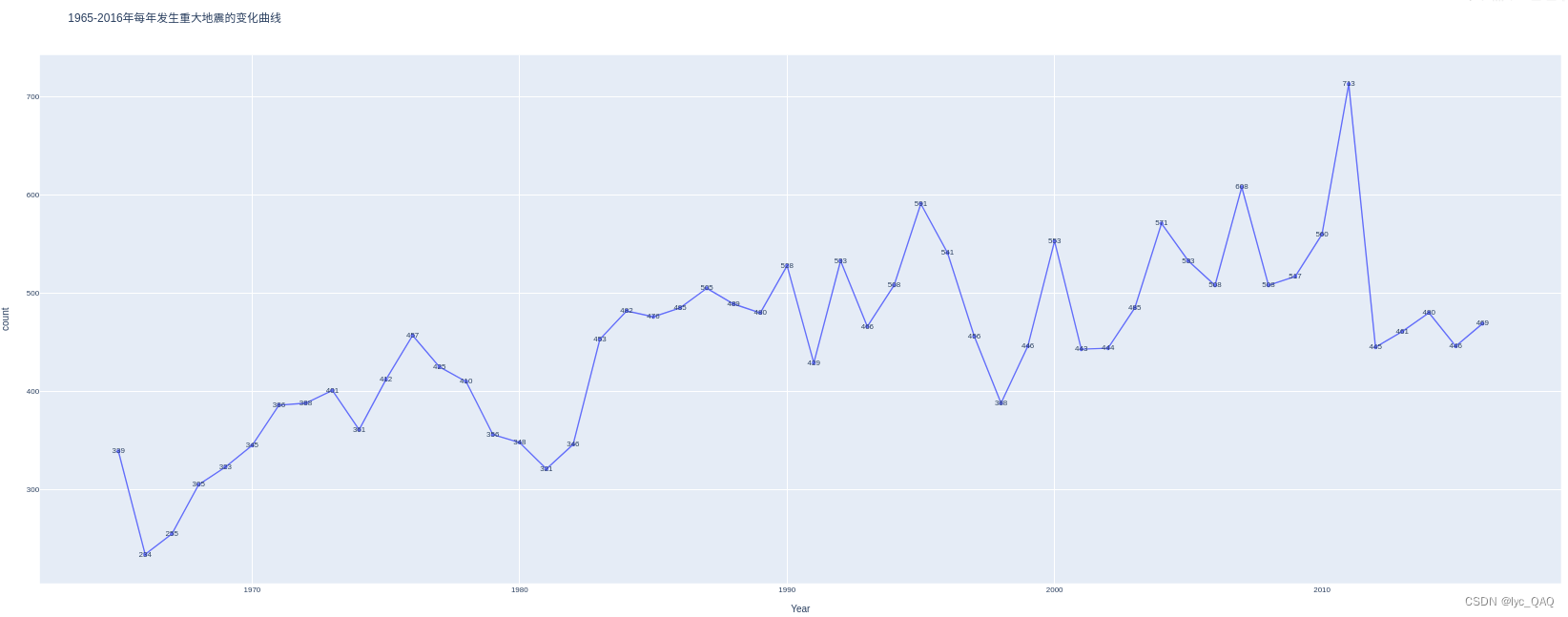
世界范围内重大地震次数年变化折线图
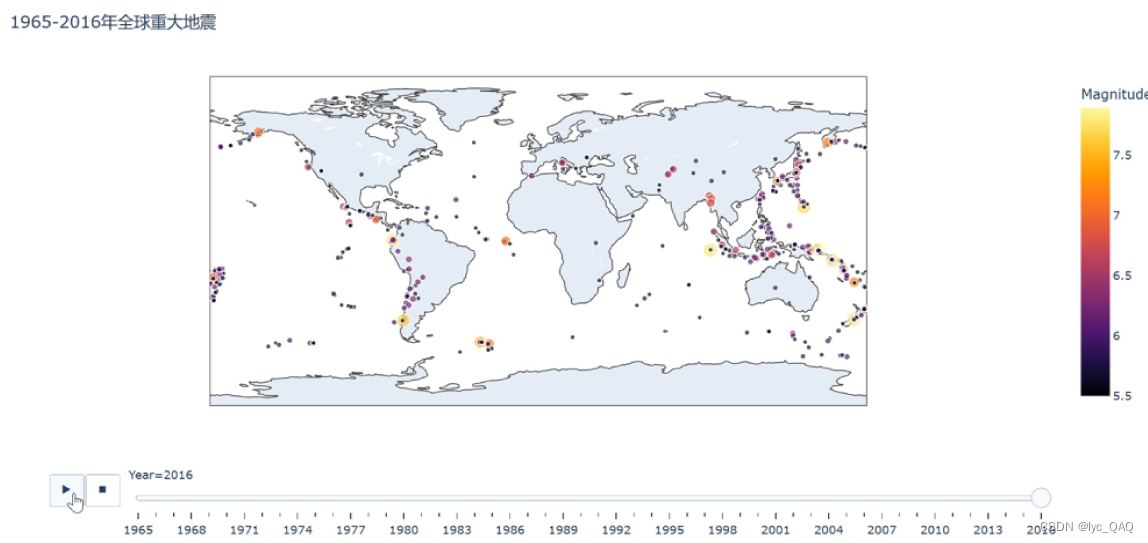
世界范围内重大地震次数年变化地图(动态效果)
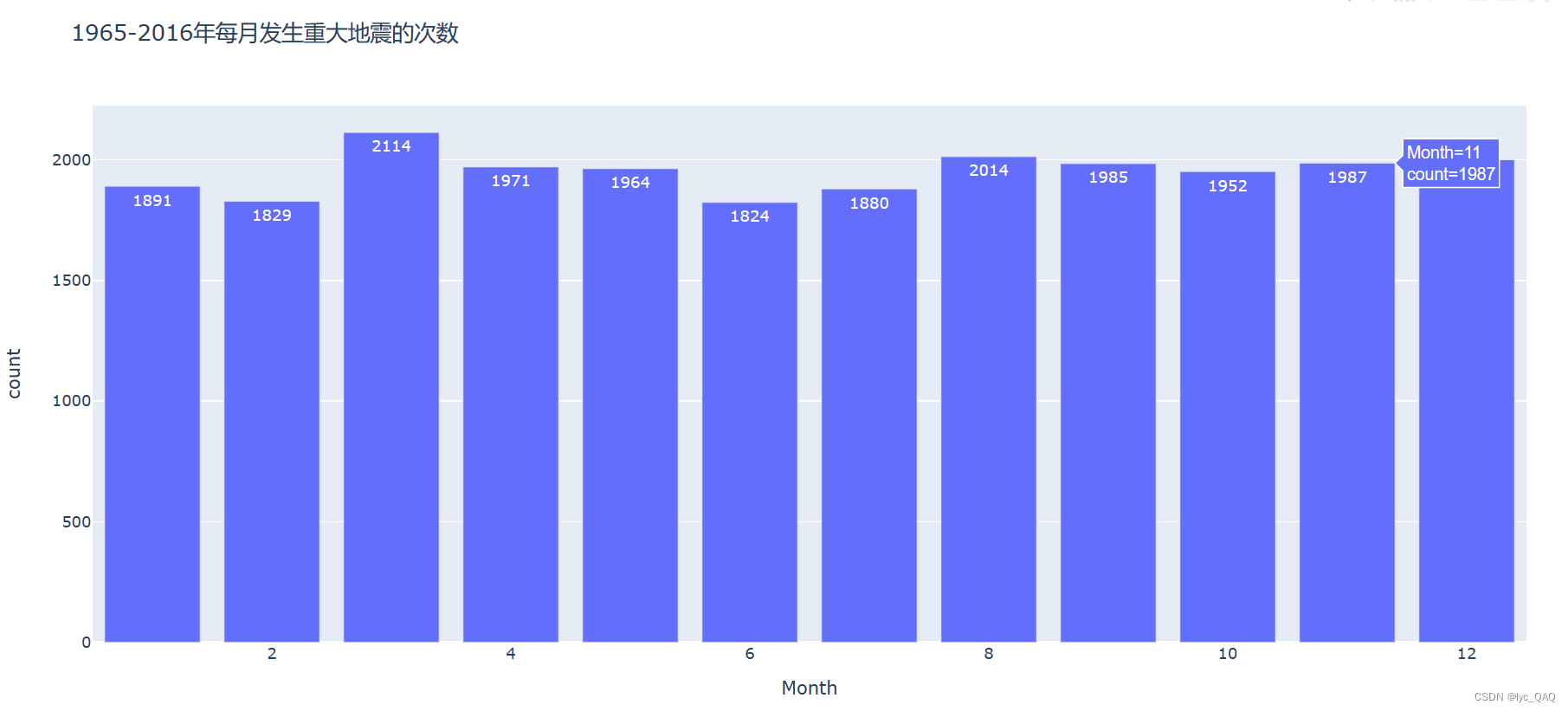
世界范围内重大地震次数月变化柱状图
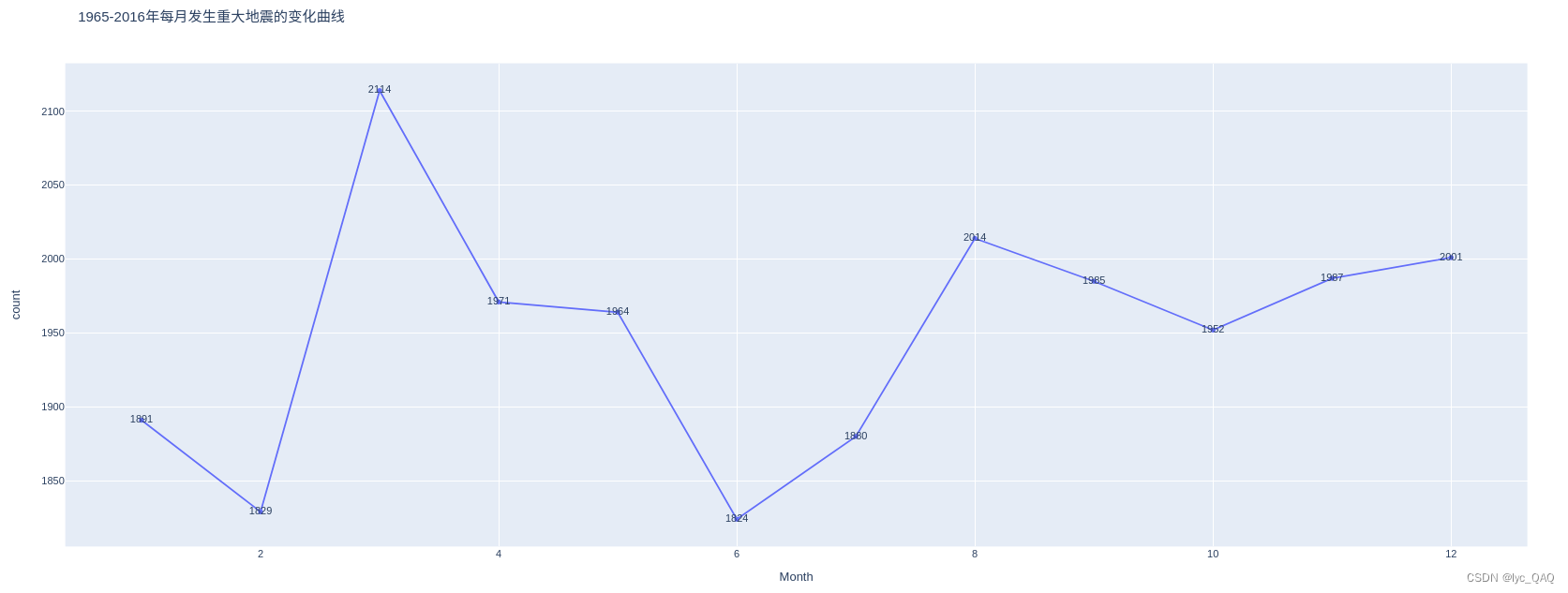
世界范围内重大地震次数月变化折线图
版权归原作者 lyc_QAQ 所有, 如有侵权,请联系我们删除。