
创作初衷:由于在这上面翻过太多的烂文章(博主自己都没搞懂就“写作抄袭”),才写下此文(已从重装系统做过3次测试,没有问题才下笔),文章属于保姆级别。
~~~~~~~~~~~~~~~~~~~~~~~~~创作不易,转载请说明~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
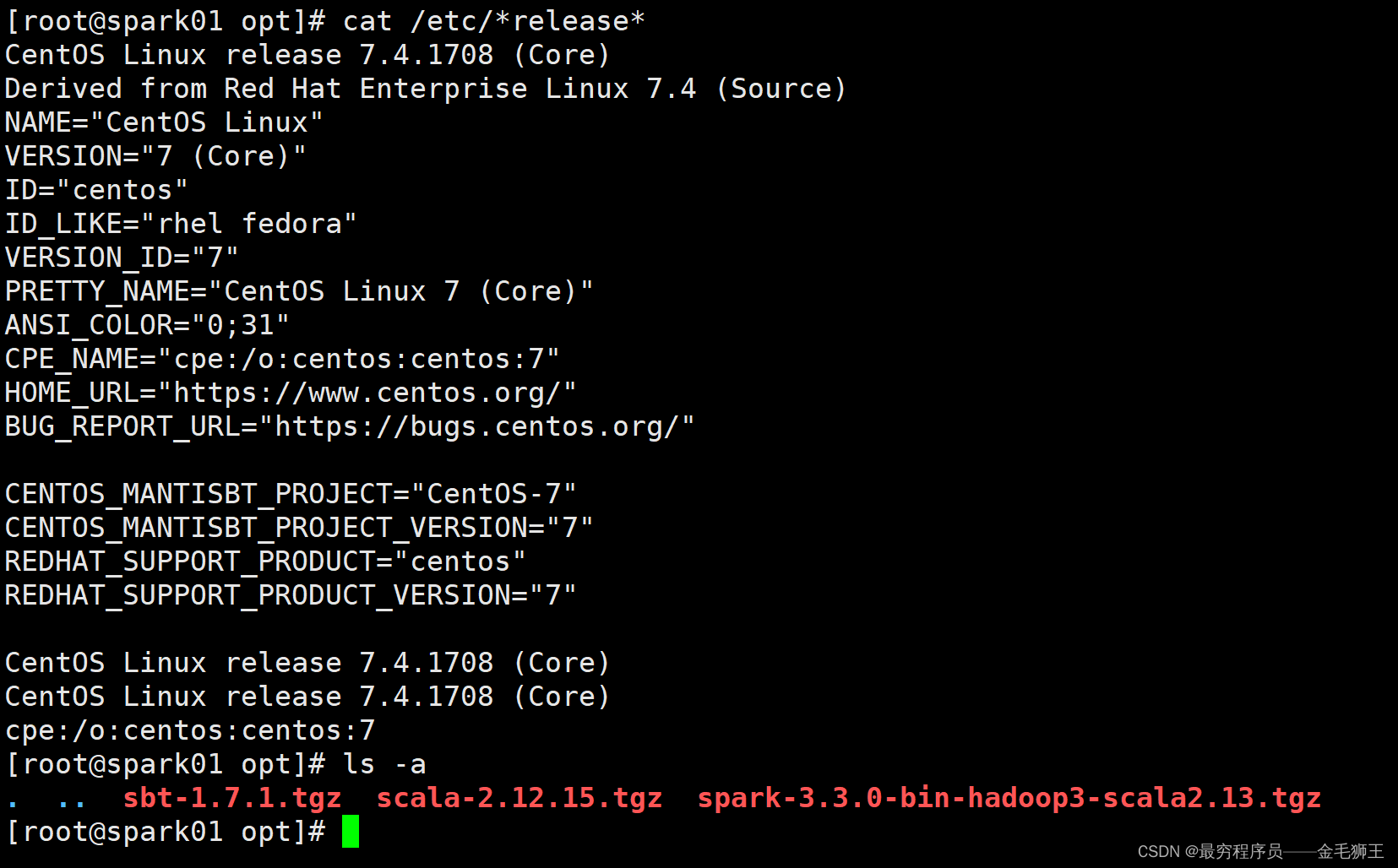
本文相关的版本信息(没部署Hadoop,本文环境基于Linux的,且文件和程序全是root用户组)
操作系统:Centos 7.4
sbt 打包插件:1.7.1 官链:sbt - The interactive build tool
spark版本:3.3.0 官链:Index of /dist/spark
JDK版本:1.8 略
scala版本: 2.12.15 官链:All Available Versions | The Scala Programming Language
先把包传/opt上去:
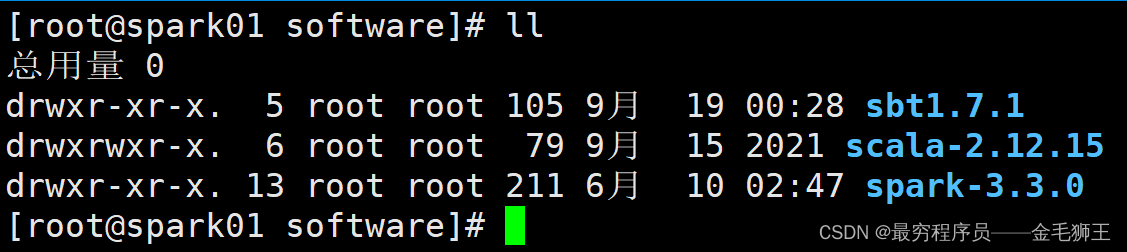
一、spark和scala基础安装与环境配置
a、scala安装
解压scala包到software,授权给root用户组,配置环境变量
[root@spark01 opt]# tar -zxvf scala-2.12.15.tgz -C /software/
[root@spark01 opt]# cd /software/
[root@spark01 software]# ll
总用量 0
drwxrwxr-x. 6 2000 2000 79 9月 15 2021 scala-2.12.15
[root@spark01 software]# chown -R root.root /software/[root@spark01 software]# vim /etc/profile # 把scala安装路径加进去
SCALA_HOME=/software/scala-2.12.15
PATH=$PATH:$SCALA_HOME/bin[root@spark01 software]# source /etc/profile
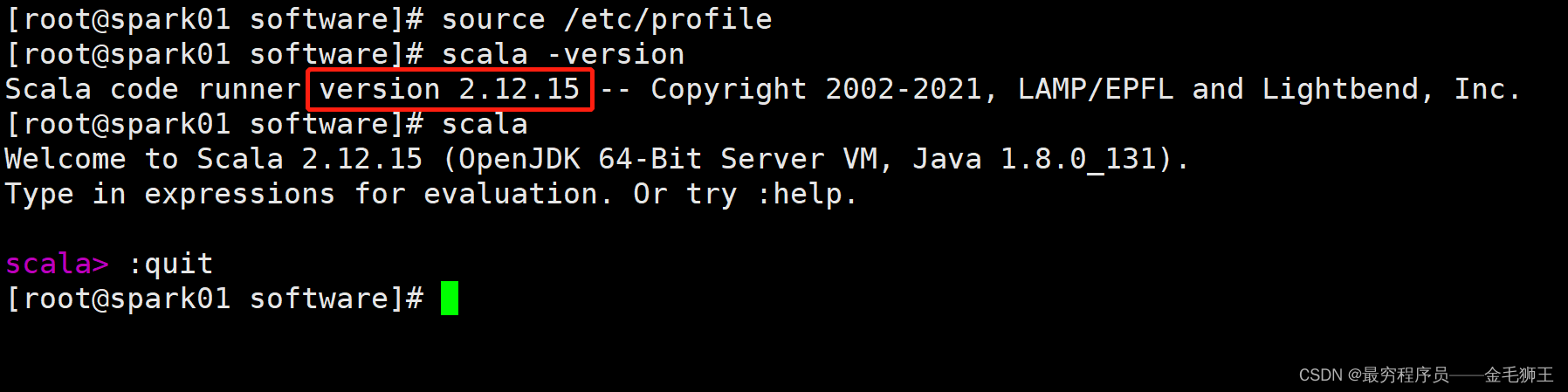
[root@spark01 software]# scala -version
Scala code runner version 2.12.15 -- Copyright 2002-2021, LAMP/EPFL and Lightbend, Inc.
[root@spark01 software]# scala
Welcome to Scala 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_131).
Type in expressions for evaluation. Or try :help.scala> :quit
b、spark安装
本处提出一个疑问,spark的scala版本问题,我翻了很多篇文章,发现有的配置了spark的env文件,配置的是他自己安装的scala版本,但是spark-shell启动还是用的默认版本,该处没整明白,所有本处暂不做spark详细配置。
解压spark包到software,授权给root用户组,改名spark-3.3.0,配置环境变量
[root@spark01 opt]# tar -xvf spark-3.3.0-bin-hadoop3-scala2.13.tgz -C /software/
[root@spark01 software]# chown -R root.root /software/[root@spark01 software]# mv spark-3.3.0-bin-hadoop3-scala2.13/ spark-3.3.0
[root@spark01 software]# vim /etc/profile # 把spark的安装目录加进去
SPARK_HOME=/software/spark-3.3.0
PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin[root@spark01 software]# source /etc/profile
环境配置没有问题的话,可任何路径启动spark
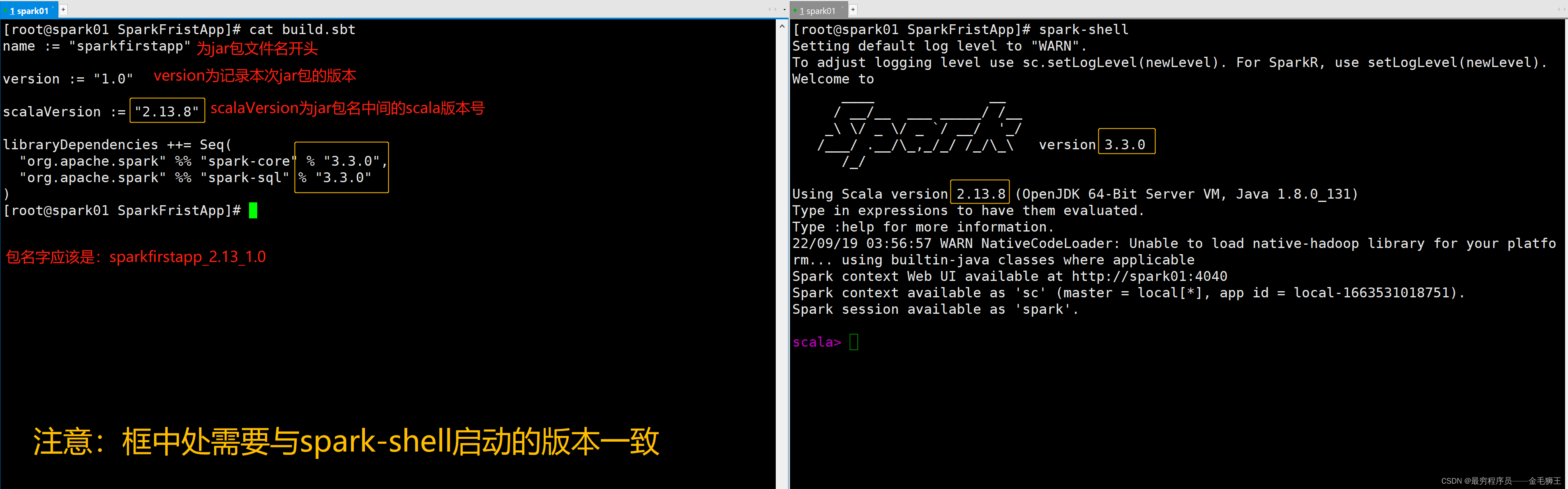
[root@spark01 software]# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ / ___ _/ /
\ / _ / _ `/ _/ '/
/_/ .__/_,// //_\ version 3.3.0
/_/Using Scala version 2.13.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
22/09/19 00:56:10 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://spark01:4040
Spark context available as 'sc' (master = local[*], app id = local-1663520171943).
Spark session available as 'spark'.scala>
二、SBT安装与环境配置
把包下载上传到opt之后解压到software并改名sbt1.7.1,本文所有执行程序权限是root用户
[root@spark01 opt]# mkdir /software ; tar -xf sbt-1.7.1.tgz -C /software ; mv /software/sbt/ /software/sbt1.7.1
[root@spark01 opt]# cd /software/
[root@spark01 software]# chown -R root.root sbt1.7.1/
[root@spark01 software]# ll
总用量 0
drwxr-xr-x. 4 root root 58 7月 12 11:49 sbt1.7.1复制sbt1.7.1/bin目录下的sbt-launch.jar到上级目录,然后vim一个sbt脚本加载基础依赖(./sbt sbtVersion 笔者这里执行费时大约5分钟,首次需耐心等待)。并授予执行权限
[root@spark01 software]# cd sbt1.7.1/
[root@spark01 sbt1.7.1]# cp bin/sbt-launch.jar ./
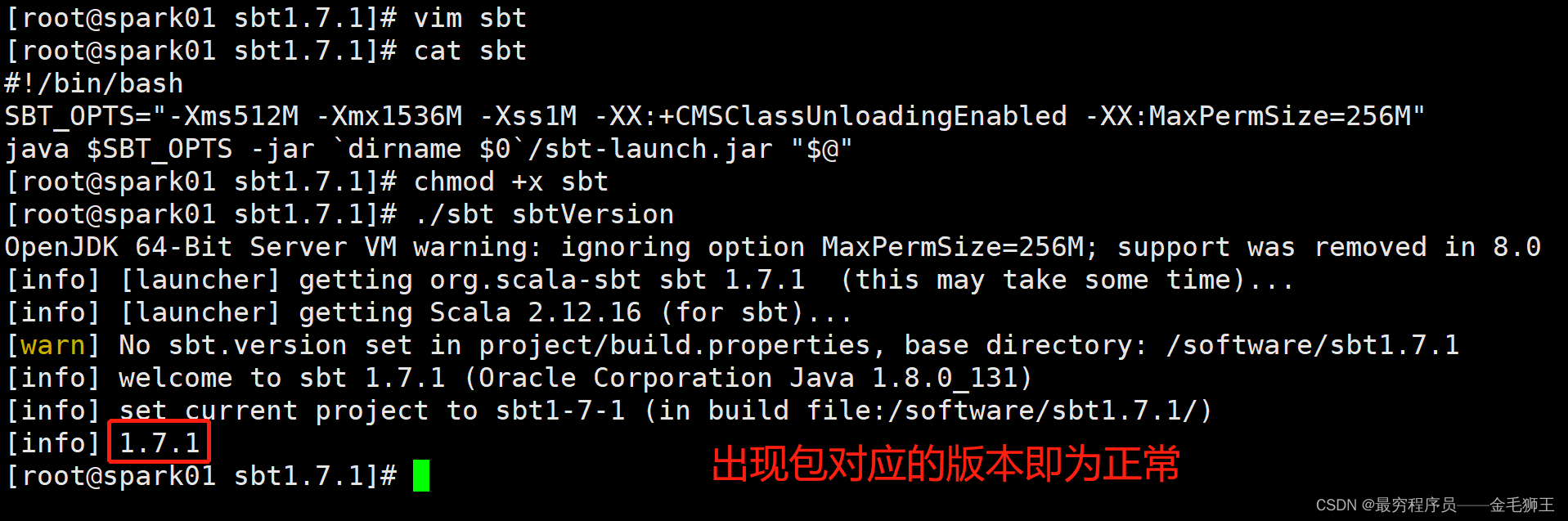
[root@spark01 sbt1.7.1]# vim sbt
[root@spark01 sbt1.7.1]# cat sbt
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jardirname $0/sbt-launch.jar "$@"
[root@spark01 sbt1.7.1]# chmod +x sbt
[root@spark01 sbt1.7.1]# ./sbt sbtVersion
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] [launcher] getting org.scala-sbt sbt 1.7.1 (this may take some time)...
[info] [launcher] getting Scala 2.12.16 (for sbt)...
[warn] No sbt.version set in project/build.properties, base directory: /software/sbt1.7.1
[info] welcome to sbt 1.7.1 (Oracle Corporation Java 1.8.0_131)
[info] set current project to sbt1-7-1 (in build file:/software/sbt1.7.1/)
[info] 1.7.1
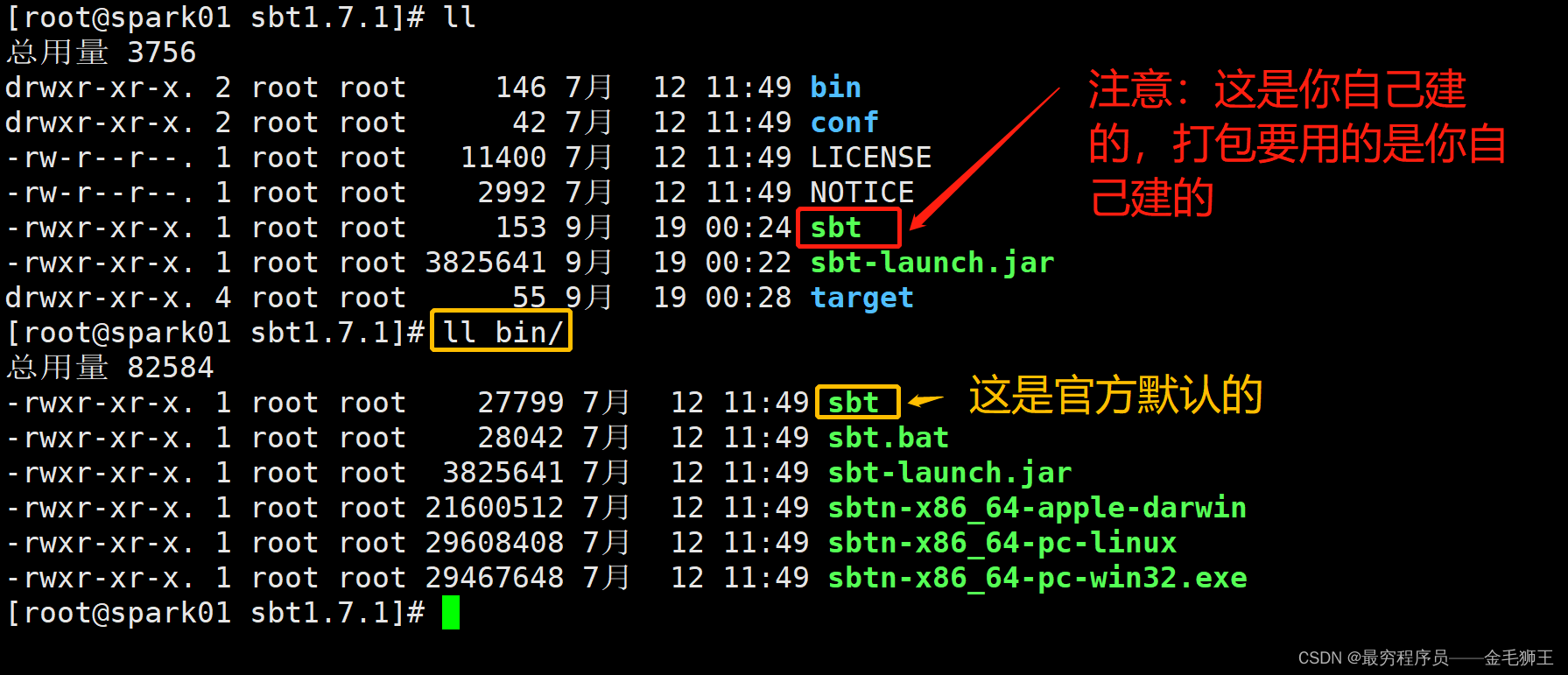
配置sbt的环境变量,因为你创建的sbt在/software/sbt1.7.1 ,/software/sbt1.7.1/bin这个下面的是官方的
[root@spark01 sbt1.7.1]# vim /etc/profile
SBT_HOME=/software/
PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin:$SBT_HOME/sbt1.7.1[root@spark01 sbt1.7.1]# source /etc/profile
[root@spark01 sbt1.7.1]# sbt
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[warn] No sbt.version set in project/build.properties, base directory: /software/sbt1.7.1
[info] welcome to sbt 1.7.1 (Oracle Corporation Java 1.8.0_131)
[info] set current project to sbt1-7-1 (in build file:/software/sbt1.7.1/)
[info] sbt server started at local:///root/.sbt/1.0/server/ffba2d1aa13a1e5b3cdb/sock
[info] started sbt server
sbt:sbt1-7-1>
[info] shutting down sbt server安装完成之后的software目录,文件和权限应如下所示,父目录及子目录全为root
三、经典案例——HelloWorld
我这里的路径是/demo,demo下面放spark应用程序
[root@spark01 /]# mkdir /demo
[root@spark01 demo]# mkdir SparkFristApp
[root@spark01 demo]# cd SparkFristApp/
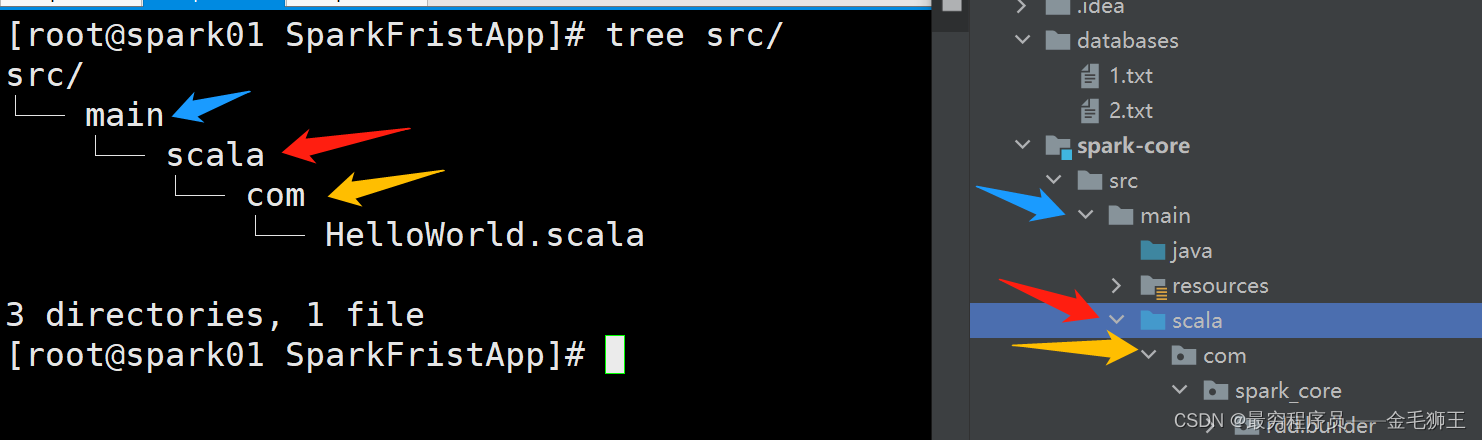
[root@spark01 SparkFristApp]# mkdir -p src/main/scala/com
[root@spark01 SparkFristApp]# cd src/main/scala/com/[root@spark01 com]# vim HelloWorld.scala
[root@spark01 com]# cat HelloWorld.scala
package main.scala.comobject HelloWorld {
def main(args:Array[String]) :Unit = {
println("HelloWorld !!!")
}
}
上述路径图解:对应idea的maven
基础代码已经写好了,现在编写build.sbt打包,注意这个地方需要到你的应用程序根目录下,也就是你的SparkFristApp,然后需要编写你这个应用需要的依赖库,这个简单输出HelloWorld,是看不出问题的,后续有案例详解
注意:这个是Linux环境,build.sbt文件不要CV,不要CV,不要CV,老老实实手敲。
[root@spark01 com]# cd /demo/SparkFristApp/
[root@spark01 SparkFristApp]# vim build.sbt
[root@spark01 SparkFristApp]# cat build.sbt
name := "sparkfirstapp"version := "1.0"
scalaVersion := "2.13.8"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.3.0",
"org.apache.spark" %% "spark-sql" % "3.3.0"
)build.sbt文件图解
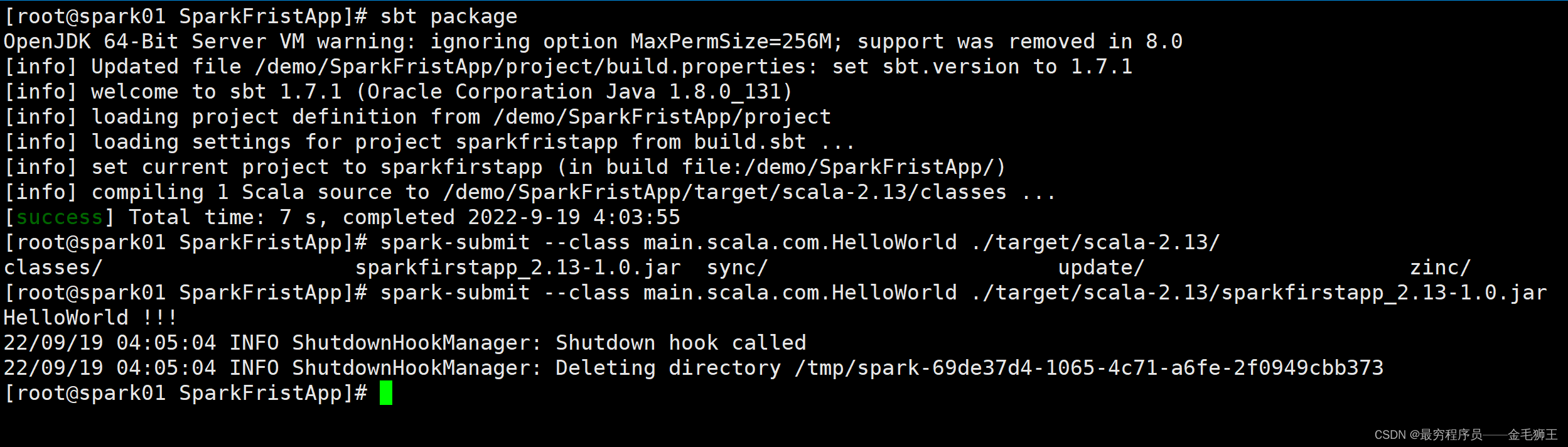
开始打包,注意文件子目录应如下,打包需在SparkFristApp,这里没加载依赖,所有打包很快,花费了7 S ,还有一个原因:不确定是不是sbt1.7.1版本优化了这个问题不。
[root@spark01 SparkFristApp]# tree src/
src/
└── main
└── scala
└── com
└── HelloWorld.scala3 directories, 1 file
[root@spark01 SparkFristApp]# sbt package
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] Updated file /demo/SparkFristApp/project/build.properties: set sbt.version to 1.7.1
[info] welcome to sbt 1.7.1 (Oracle Corporation Java 1.8.0_131)
[info] loading project definition from /demo/SparkFristApp/project
[info] loading settings for project sparkfristapp from build.sbt ...
[info] set current project to sparkfirstapp (in build file:/demo/SparkFristApp/)
[info] compiling 1 Scala source to /demo/SparkFristApp/target/scala-2.13/classes ...
[success] Total time: 7 s, completed 2022-9-19 4:03:55打包完成之后,就可丢spark里跑jar包了
[root@spark01 SparkFristApp]# spark-submit --class main.scala.com.HelloWorld ./target/scala-2.13/sparkfirstapp_2.13-1.0.jar
HelloWorld !!!
22/09/19 04:05:04 INFO ShutdownHookManager: Shutdown hook called
22/09/19 04:05:04 INFO ShutdownHookManager: Deleting directory /tmp/spark-69de37d4-1065-4c71-a6fe-2f0949cbb373
四、官方spark3.3.0独立应用程序
helloworld已经跑完了,现在来试试官方的简单案例吧,该案例的意思就是计算含有a和b的行数
官链地址:Quick Start - Spark 3.3.0 Documentation
开始建vim scala代码,把官方的案例CV加一下包路径,还有你环境README.md文件路径
[root@spark01 SparkFristApp]# cd src/main/scala/com/
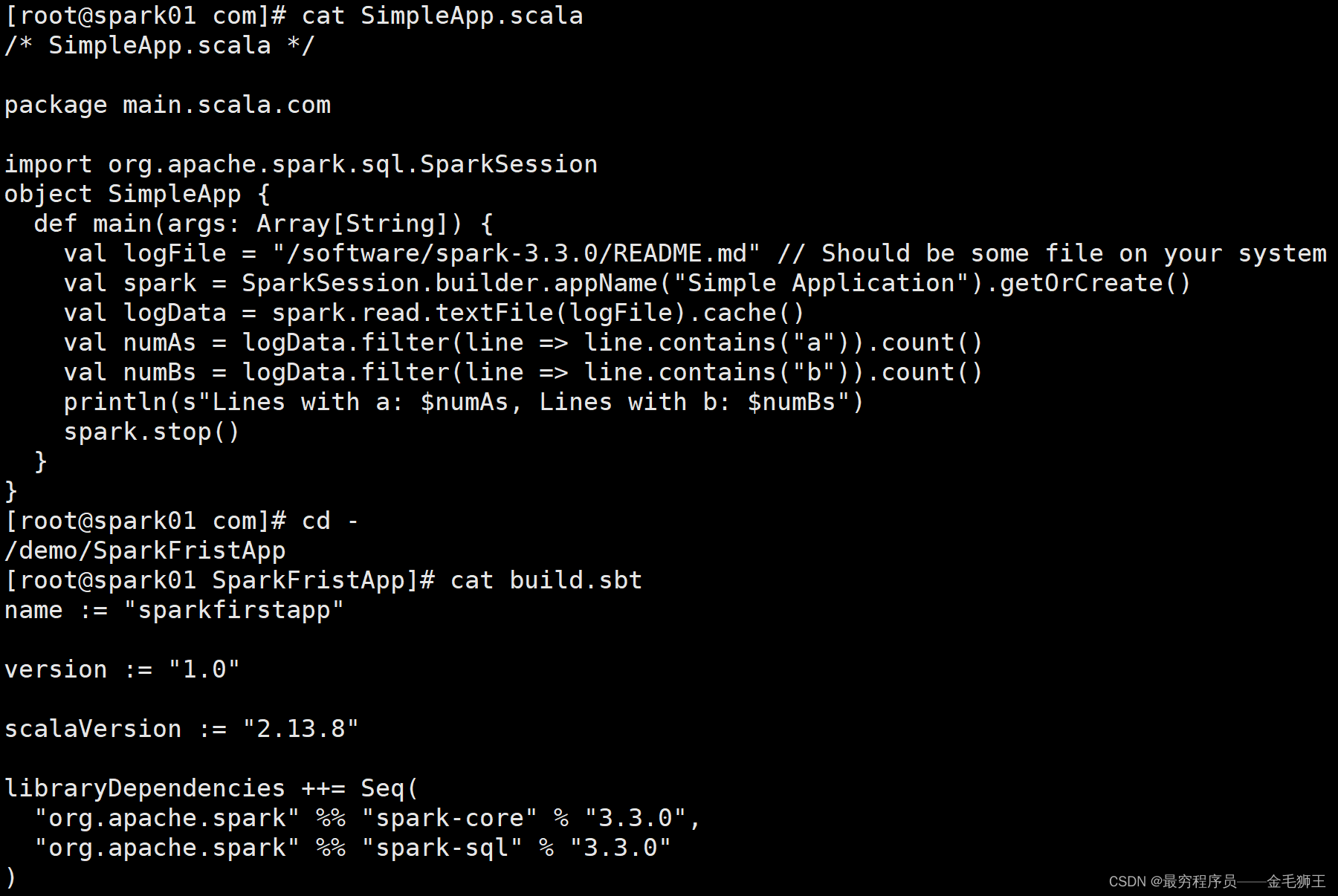
[root@spark01 com]# vim SimpleApp.scala[root@spark01 com]# cat SimpleApp.scala
/* SimpleApp.scala */package main.scala.com
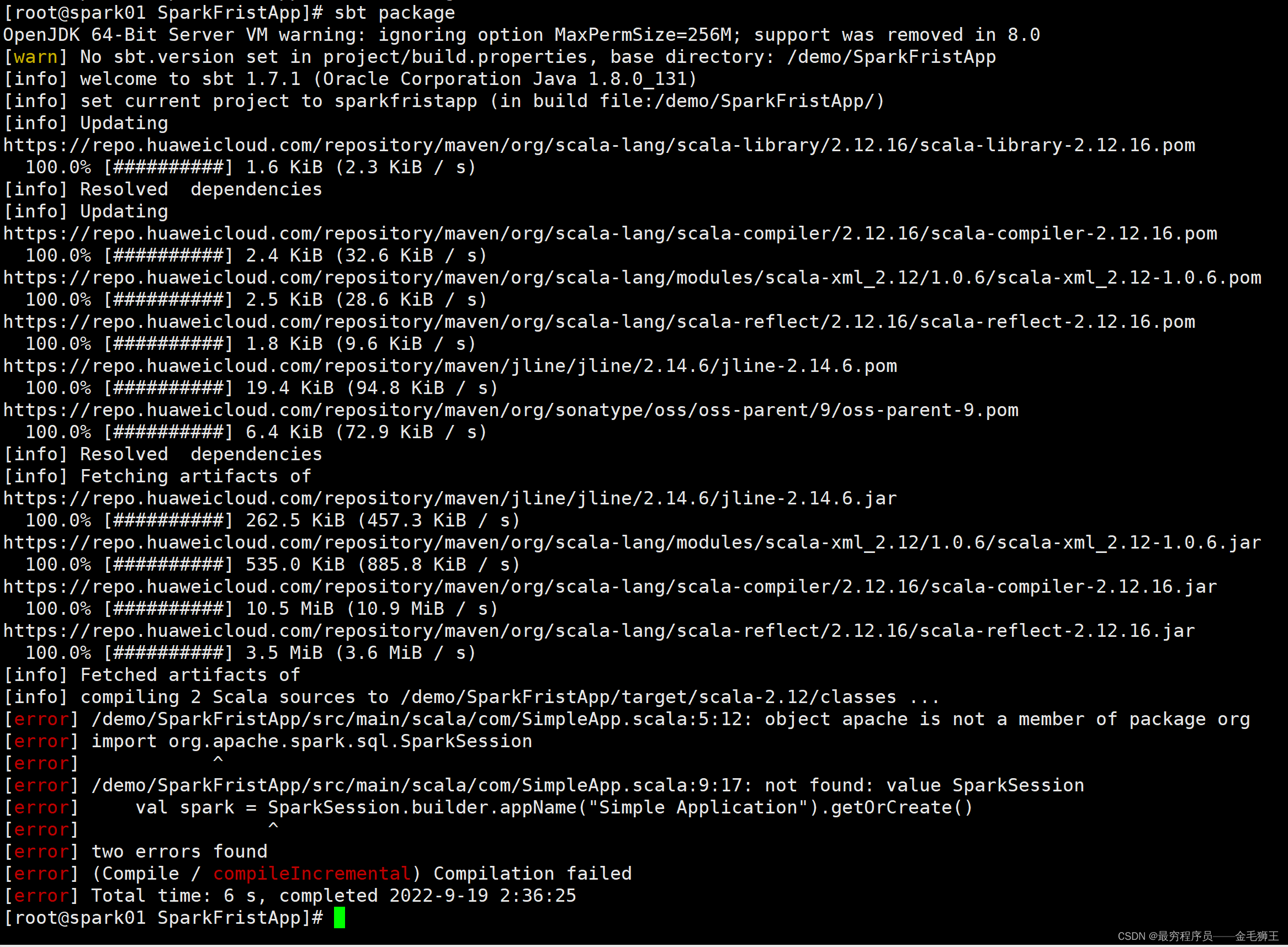
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]) {
val logFile = "/software/spark-3.3.0/README.md" // Should be some file on your system
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
}然后开始sbt打包,由于你每个代码块用的依赖包都不一定是一致的,所以打包时创建的build.sbt依赖库也是不一致的,上面的build.sbt依赖库在这里是可以用的,所以不需要重新编写build.sbt文件,该处注意上下文紫色文字
[root@spark01 com]# cd -
/demo/SparkFristApp
[root@spark01 SparkFristApp]# cat sbt
name := "sparkfirstapp"
version := "1.0"
scalaVersion := "2.13.8"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.3.0",
"org.apache.spark" %% "spark-sql" % "3.3.0"
)
执行sbt打包,需要配置一下源,这样能加快下载包的速,编辑~/.sbt/repositories的文件,换成阿里的,这个库源很玄学,有时候能下,有时候不能下,我遇到的问题记录最后有说明。
[root@spark01 SparkFristApp]# vim ~/.sbt/repositories
[root@spark01 SparkFristApp]# cat ~/.sbt/repositories
[repositories]
local
maven-central: https://maven.aliyun.com/repository/central
然后就是sbt打包
[root@spark01 SparkFristApp]# ll
总用量 4
-rw-r--r--. 1 root root 194 9月 19 03:51 build.sbt
drwxr-xr-x. 3 root root 44 9月 19 04:03 project
drwxr-xr-x. 3 root root 18 9月 19 01:21 src
drwxr-xr-x. 6 root root 88 9月 19 04:03 target[root@spark01 SparkFristApp]# sbt package
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] welcome to sbt 1.7.1 (Oracle Corporation Java 1.8.0_131)
[info] loading project definition from /demo/SparkFristApp/project
[info] loading settings for project sparkfristapp from build.sbt ...
[info] set current project to sparkfirstapp (in build file:/demo/SparkFristApp/)
[info] compiling 2 Scala sources to /demo/SparkFristApp/target/scala-2.13/classes ...
[warn] 1 deprecation (since 2.13.0)
[warn] 1 deprecation (since 2.13.3)
[warn] 2 deprecations in total; re-run with -deprecation for details
[warn] three warnings found
[warn] multiple main classes detected: run 'show discoveredMainClasses' to see the list
[success] Total time: 8 s, completed 2022-9-19 4:13:08上面标红这是最后一行,表明打包时间与完成时间
下面是当前目录结构
[root@spark01 SparkFristApp]# ll
总用量 4
-rw-r--r--. 1 root root 137 9月 19 03:19 build.sbt
drwxr-xr-x. 3 root root 44 9月 19 03:19 project
drwxr-xr-x. 3 root root 18 9月 19 01:21 src
drwxr-xr-x. 6 root root 88 9月 19 03:19 target
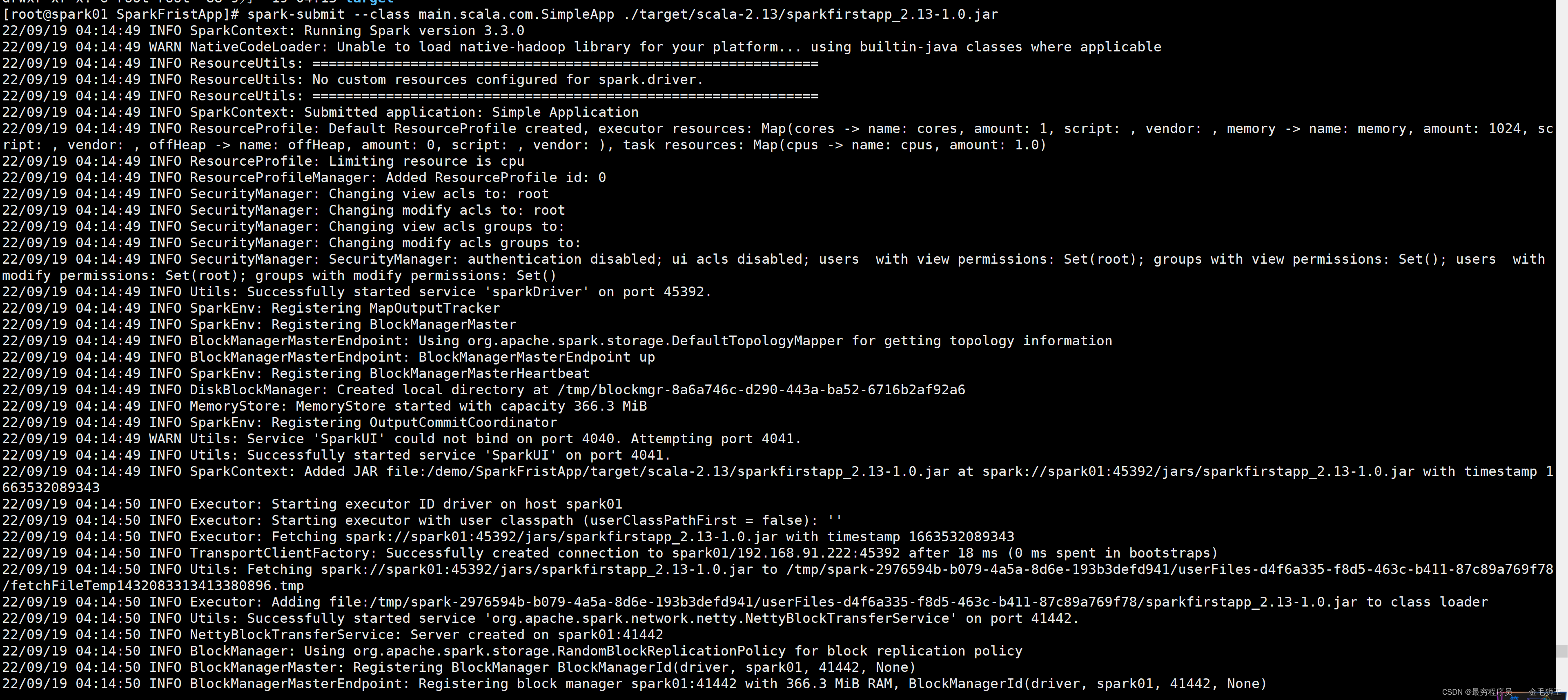
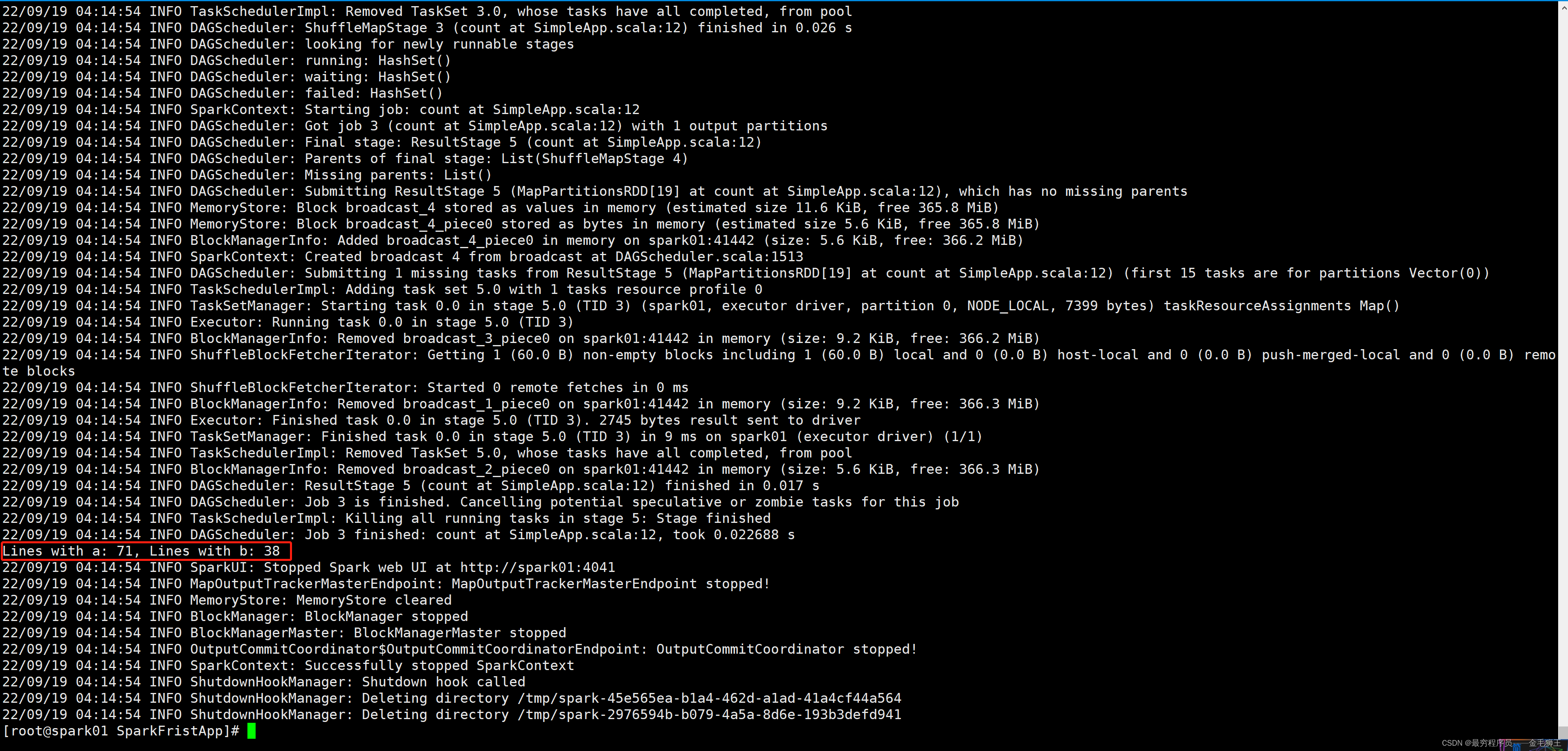
现在运行官方的这个案例,这里日志太多了,只贴前文截图与后文截图
注:具体INFO与ERR输出需要配置log4j,本文暂不做讲解
[root@spark01 SparkFristApp]# spark-submit --class main.scala.com.SimpleApp ./target/scala-2.13/sparkfirstapp_2.13-1.0.jar
五、实战案例
[root@spark01 SparkFristApp]# cd src/main/scala/com/
[root@spark01 com]# cat MnMcount.scala
package main.scala.com import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions._ /** * Usage: MnMcount <mnm_file_dataset> */ object MnMcount { def main(args: Array[String]) { val spark = SparkSession .builder .appName("MnMCount") .getOrCreate() if (args.length < 1) { print("Usage: MnMcount <mnm_file_dataset>") sys.exit(1) } // 读取文件名 val mnmFile = args(0) // 将数据读到 Spark DataFrame val mnmDF = spark.read.format("csv") .option("header", "true") .option("inferSchema", "true") .load(mnmFile) mnmDF.show(5, false) // 通过 State Color分组聚合求出所有颜色总计数,然后降序排列 val countMnMDF = mnmDF.select("State", "Color", "Count") .groupBy("State", "Color") .sum("Count") .orderBy(desc("sum(Count)")) // 展示State Color聚合对应的结果 countMnMDF.show(60) println(s"Total Rows = ${countMnMDF.count()}") println() // 通过过滤得到聚合数据 val caCountMnNDF = mnmDF.select("*") .where(col("State") === "CA") .groupBy("State", "Color") .sum("Count") .orderBy(desc("sum(Count)")) // 展示聚合结果 caCountMnNDF.show(10) } }代码撸完就该打包上路了
[root@spark01 com]# cd -
/demo/SparkFristApp
[root@spark01 SparkFristApp]# sbt package
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] welcome to sbt 1.7.1 (Oracle Corporation Java 1.8.0_131)
[info] loading project definition from /demo/SparkFristApp/project
[info] loading settings for project sparkfristapp from build.sbt ...
[info] set current project to sparkfirstapp (in build file:/demo/SparkFristApp/)
[info] compiling 1 Scala source to /demo/SparkFristApp/target/scala-2.13/classes ...
[warn] 1 deprecation (since 2.13.0)
[warn] 1 deprecation (since 2.13.3)
[warn] 2 deprecations in total; re-run with -deprecation for details
[warn] three warnings found
[warn] multiple main classes detected: run 'show discoveredMainClasses' to see the list
[success] Total time: 5 s, completed 2022-9-19 4:34:26打包安全,现在把数据文件扔到/data (mnm_dataset.csv是一个测试数据文件,放在/data下面)
[root@spark01 com]# mkdir /data
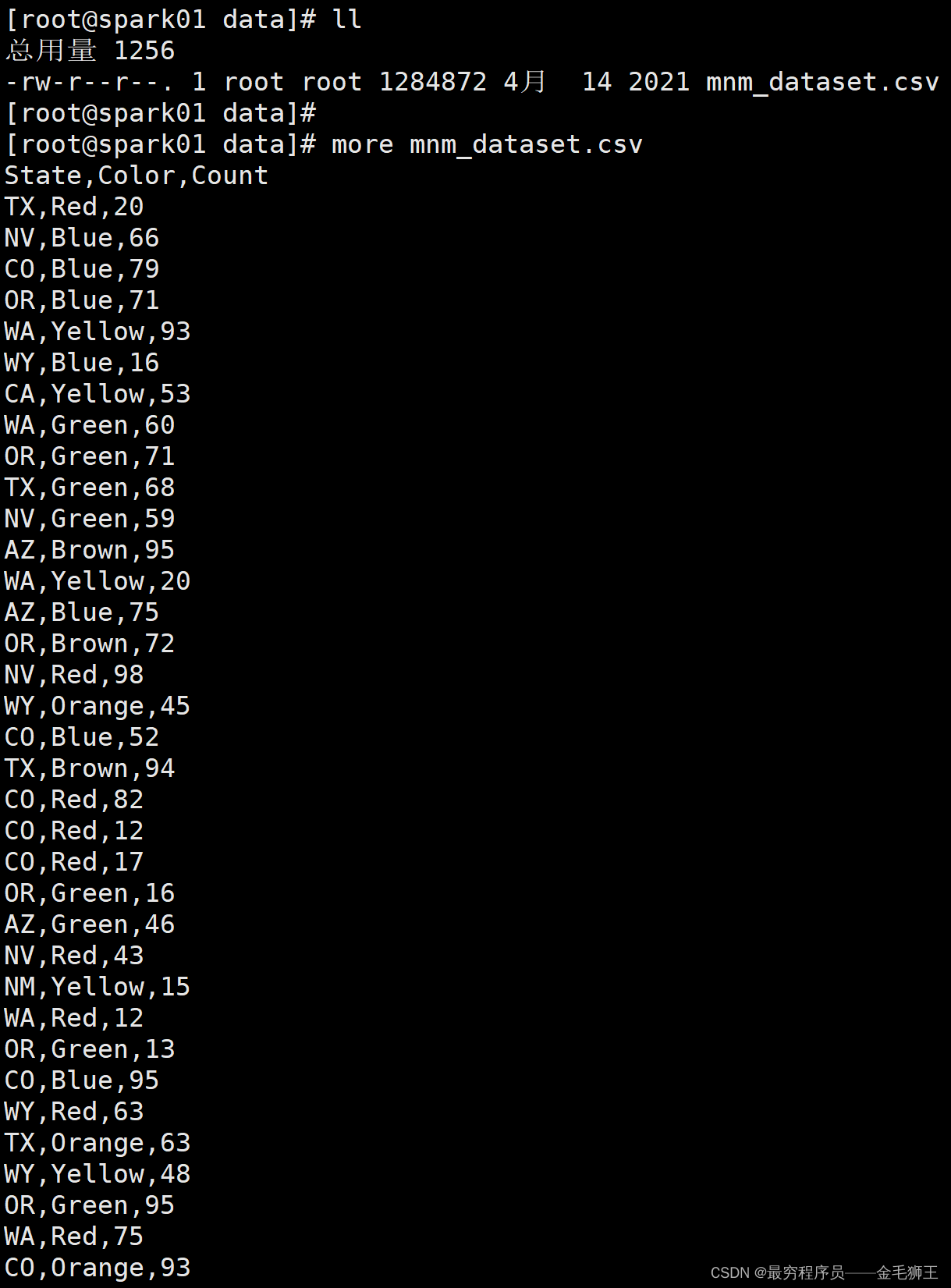
[root@spark01 SparkFristApp]# more /data/mnm_dataset.csv
State,Color,Count
TX,Red,20
NV,Blue,66
CO,Blue,79
OR,Blue,71
WA,Yellow,93
WY,Blue,16
CA,Yellow,53
WA,Green,60
OR,Green,71
TX,Green,68
NV,Green,59
AZ,Brown,95
WA,Yellow,20
AZ,Blue,75
OR,Brown,72
NV,Red,98
WY,Orange,45
CO,Blue,52
TX,Brown,94
CO,Red,82
CO,Red,12
CO,Red,17
OR,Green,16
AZ,Green,46
NV,Red,43
NM,Yellow,15
WA,Red,12
OR,Green,13
CO,Blue,95
WY,Red,63
TX,Orange,63
WY,Yellow,48
OR,Green,95
WA,Red,75
CO,Orange,93
NV,Orange,10
WY,Green,15
WA,Green,99
CO,Blue,98
CA,Green,86
UT,Red,92
......................[root@spark01 data]# wc -l mnm_dataset.csv
100000 mnm_dataset.csv
程序执行(带部分截图)
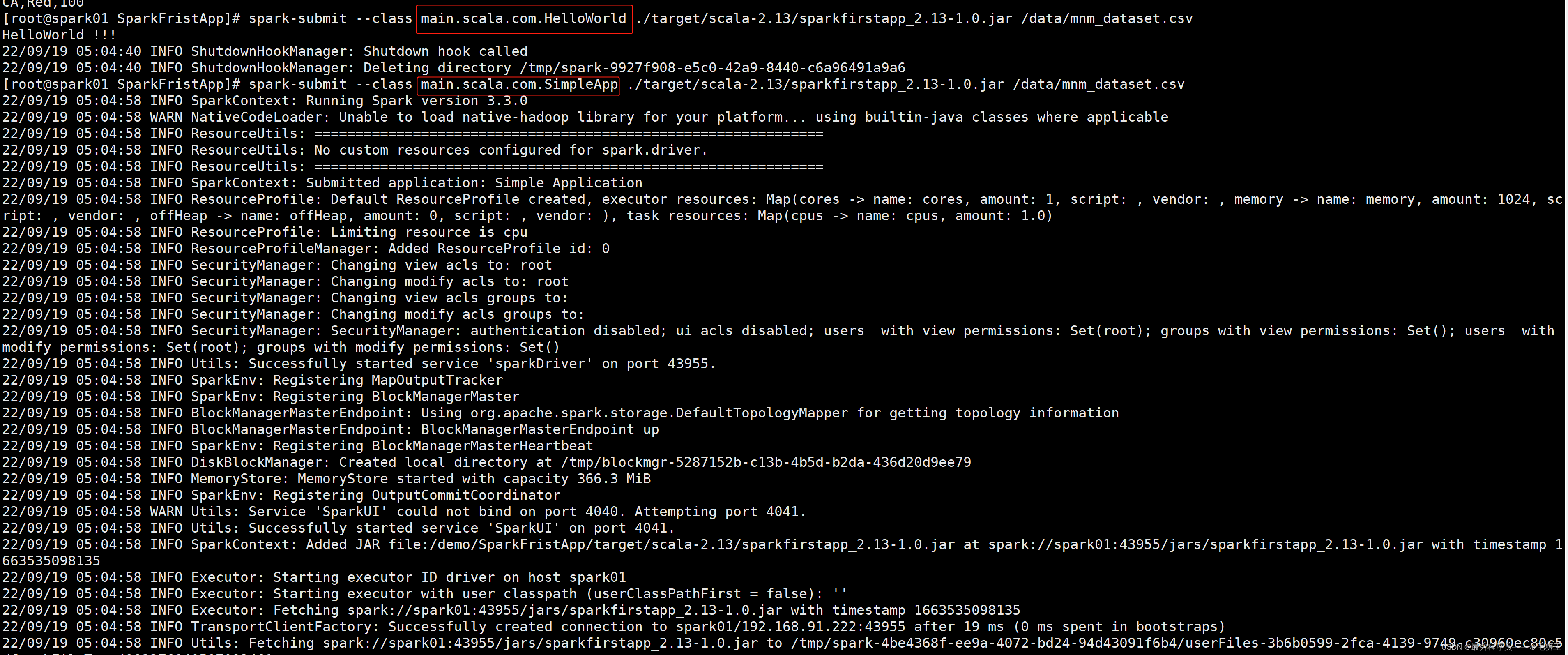
[root@spark01 SparkFristApp]# spark-submit --class main.scala.com.MnMcount ./target/scala-2.13/ /data/mnm_dataset.csv
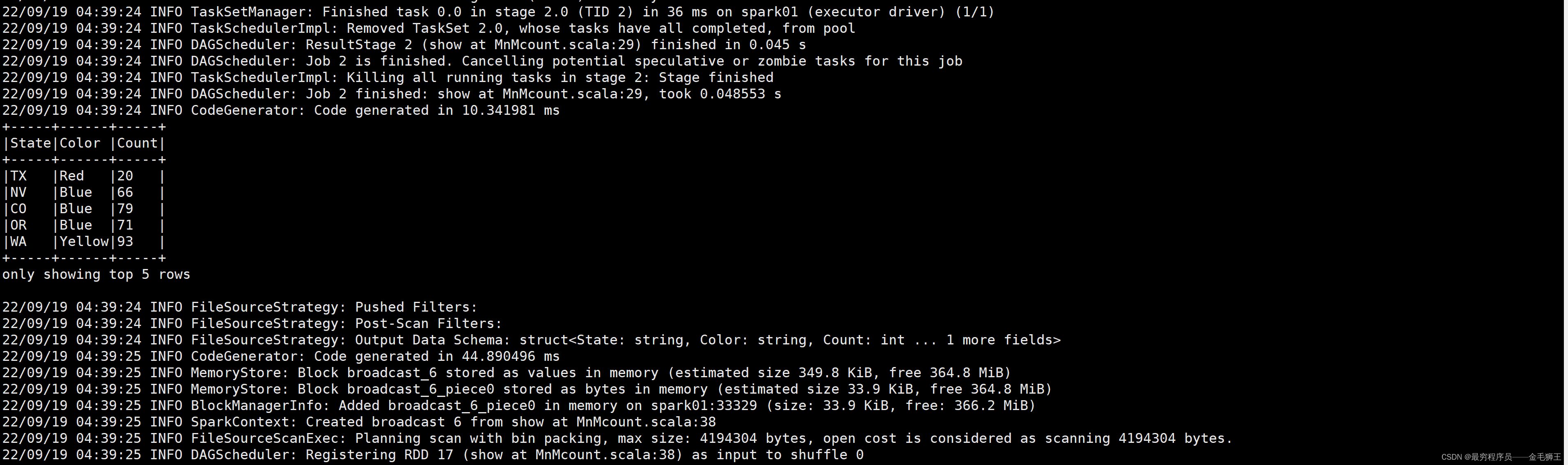
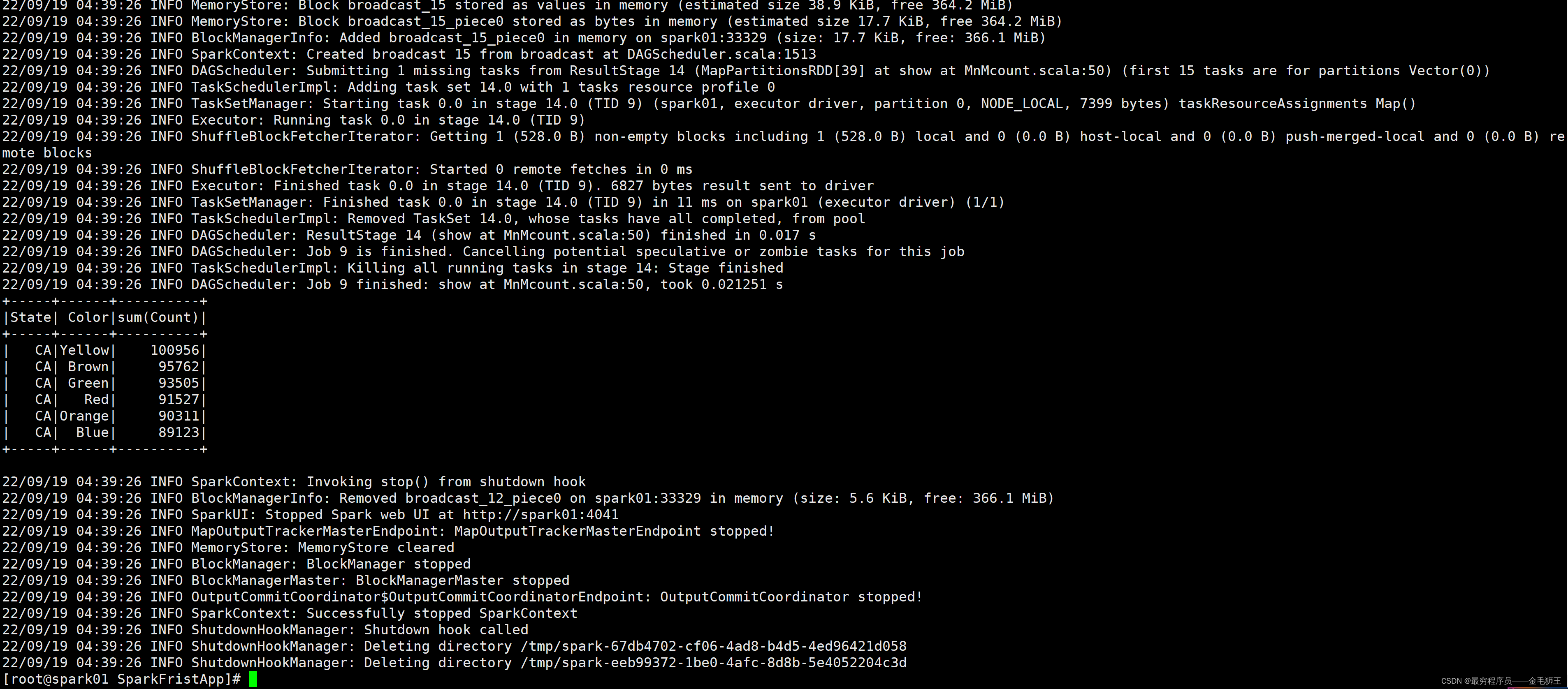
至此,这个sparkfirstapp_2.13-1.0.jar不仅能跑入门的HelloWorld,还能跑入入门的SimpleApp,还能跑入入入门的MnMcount。
六、问题记录——玄学

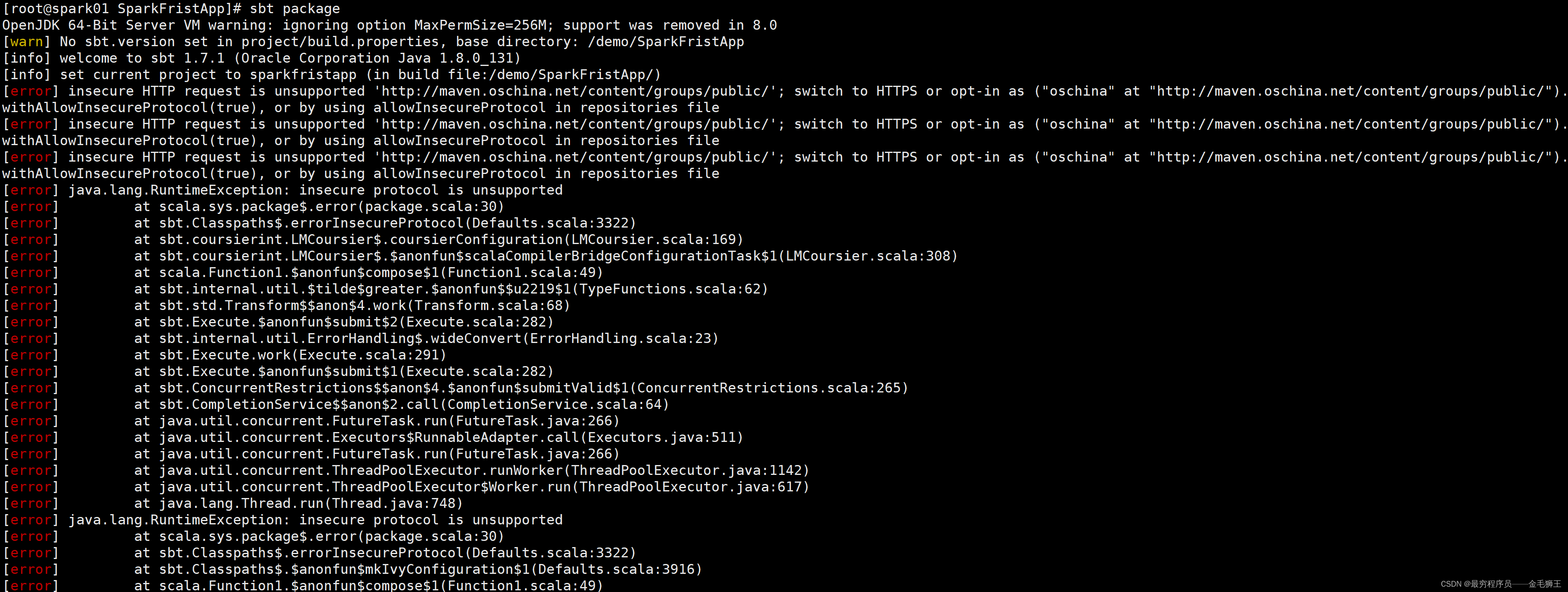
原因一:sbt写的有问题,如版本、换行(Linux跟Windows换行不一样的,在Linux vim sbt 建议一个个字母敲,不要cv,不然你就会很玄学的,可以自己再测测,hhhh~)
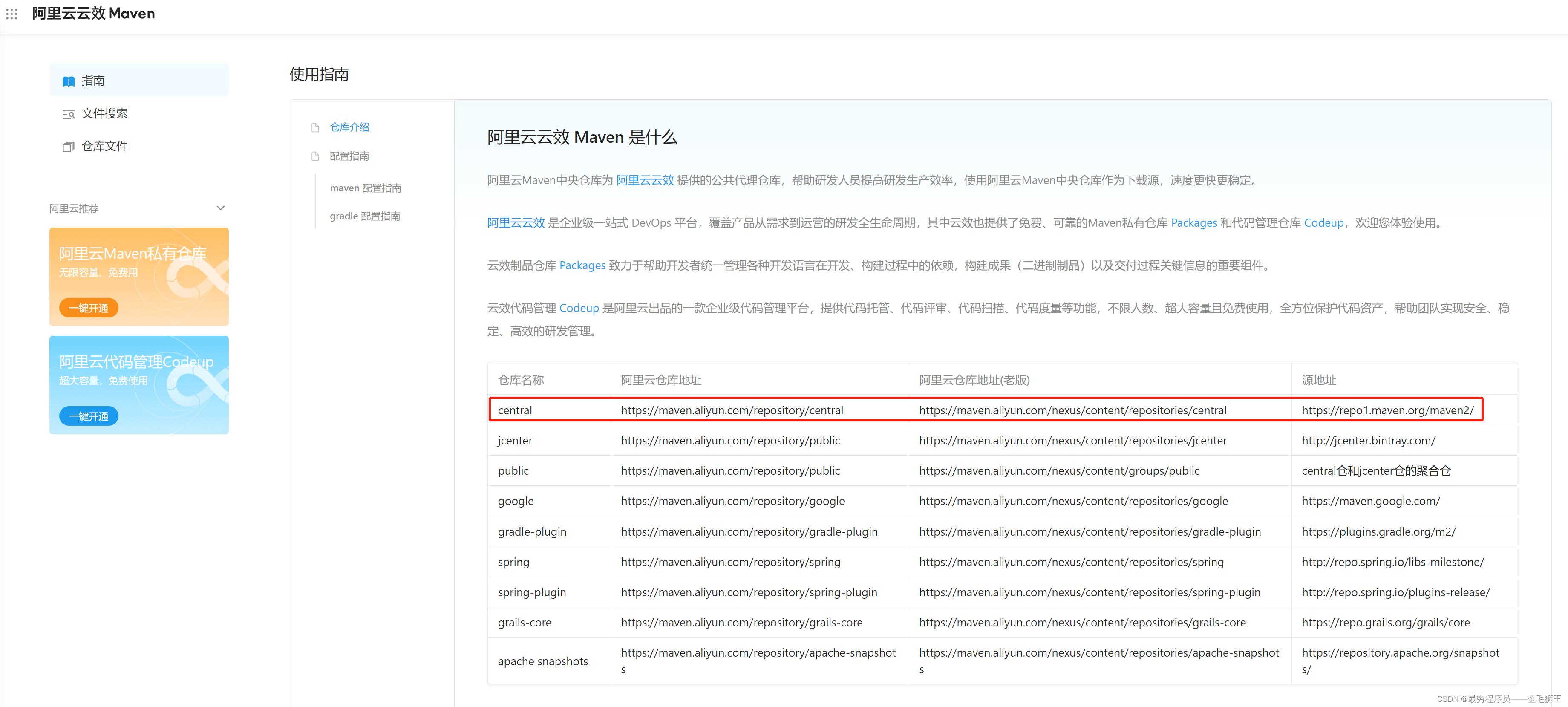
原因二:那个lj库源有问题,建议去看看官方:Central Repository: org/apache/spark
这里推荐用阿里的central(上面的~/.sbt/repositories也是配置的这个):https://maven.aliyun.com/repository/central
阿里仓库:仓库服务
当然了,哪个用着舒服你就用哪个
原因三:你代码有问题,这个测试最容易,就是直接cv到spark-shell里面去,导不进去会直接报红
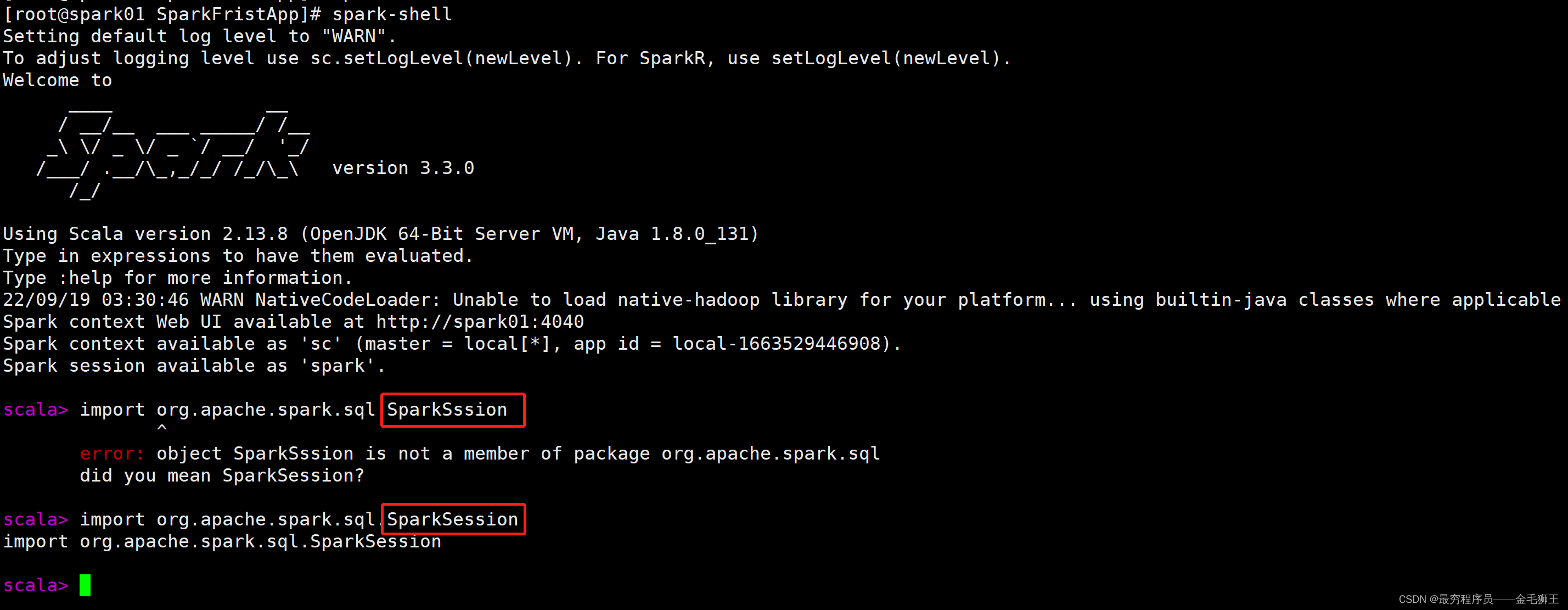
至此,你的程序打包还有问题吗?可以在spark上跑起来了吧?祝好运没ERR。
“火花”的学习之路才刚刚开始,加油!
~~~~~~~~~~~~~~~~~~~创作不易,转载请说明~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~用心写好每一篇技术文章~~~~~~~~~~~~~~~~~~~~~~~~~~~
版权归原作者 最穷程序员——金毛狮王 所有, 如有侵权,请联系我们删除。