
逻辑回归和感知器算法进行线性分类
代码使用了LogisticRegression和Perceptron两种分类方法
# 使用LogisticRegreeion分类器学习和测试
lr = LogisticRegression()
lr.fit(X_train_scaler, y_train)
y_pred_lr = lr.predict(X_test_scaler)#定义感知机
perceptron = Perceptron(fit_intercept=False, max_iter=200, shuffle=False)
函数中的max_iter通过源码查看为The maximum number of passes over the training data,指的是设定的最大迭代次数,但是并不是迭代次数越多越好,因为迭代次数多可能会使模型的准确率降低,因为很可能会出现过拟合的现象;或者是虽然迭代很多次但是模型的准确率没有变化,这样就造成了计算量因迭代多次而会很大。
当max_iter设置为30的结果为
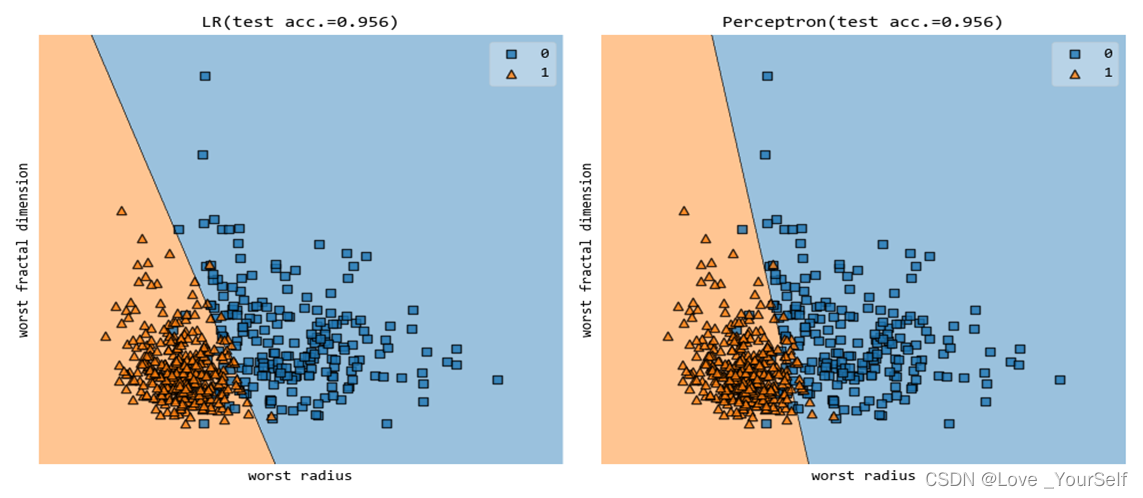
当max_iter设置为50的结果为
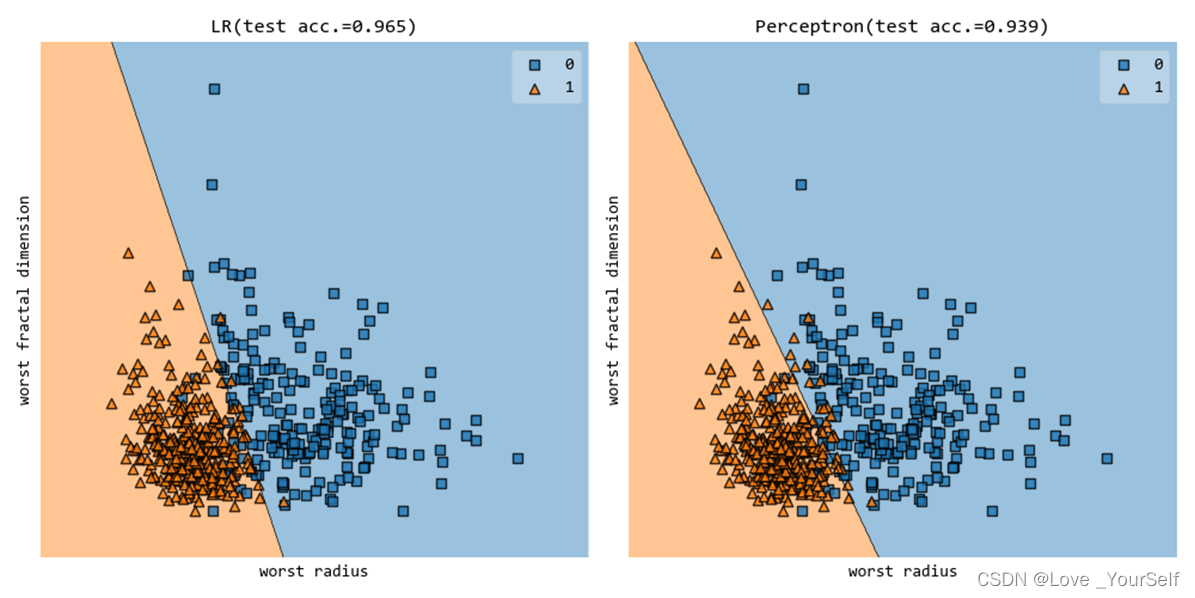
当max_iter设置为100的结果为
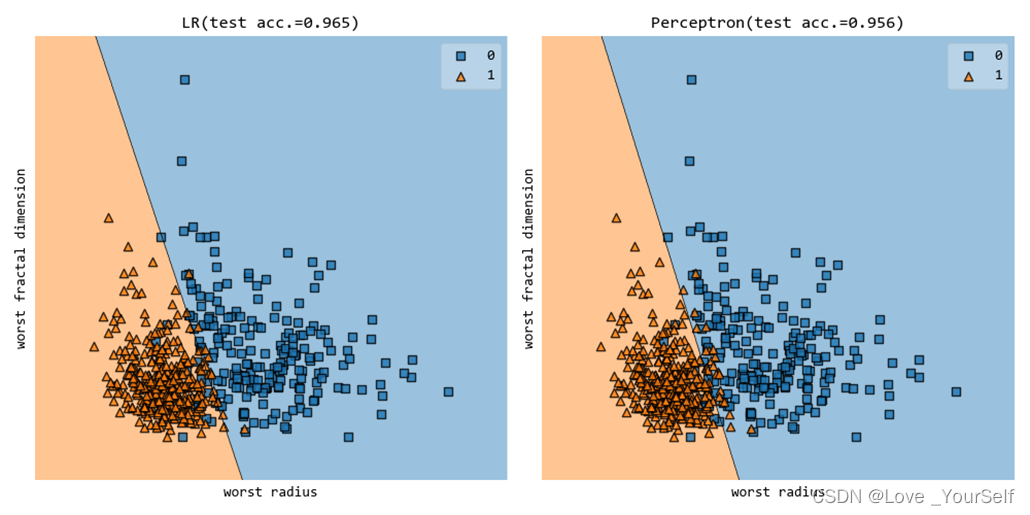
当max_iter设置为200的结果为
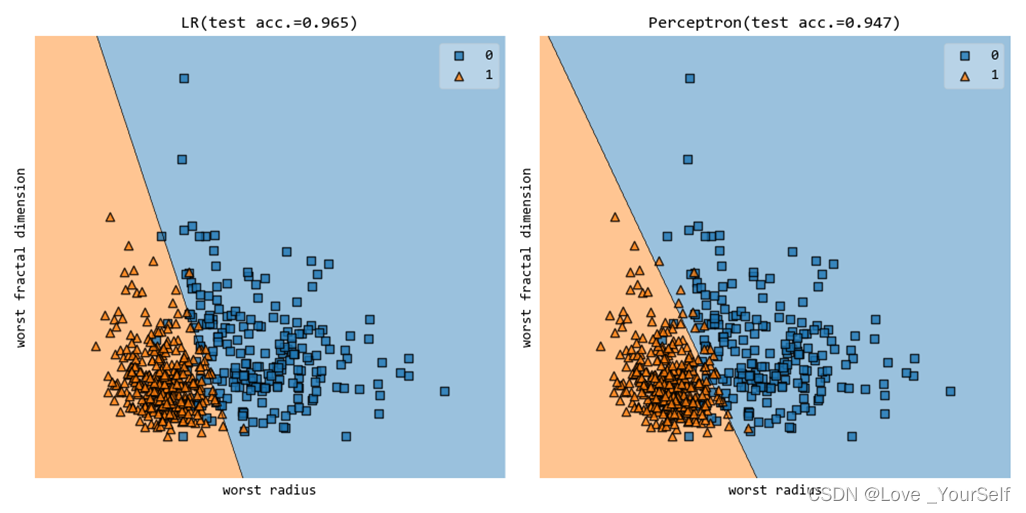
随着迭代次数的增加使用logisticRegression的模型准确率能提高一点,但是对于perceptron模型出现了迭代次数增加模型的准确率降低的情况。
当使用全部的特征值进行训练的时候,两个模型的准确率都有很大的提高,LogisticRegression模型准确率达到了98.2%,而Perceptron模型准确率达到了97.4%,这相比只使用第20维和第29维特征得到的模型准确率提升了很多。
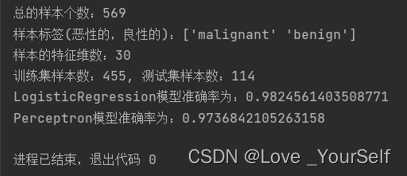
实验结果看出两个分类器中logisticRegression的准确率是比perceptron要高一些,但是不能就说perceptron一定不如logisticRegression,因为它们都各有优势。它们一般都是用于分类问题的分类器算法,逻辑回归是将线性回归的输出作为sigmoid函数的输入,而且他的回归模型比较复杂,使用的是对数形式的cost函数,因而带来的时间花费较大,也就是需要更多的计算量;而perceptron使用的是均方差形式的cost函数,同时它的激活函数为阶跃函数,比较简单,因此需要花费的时间短,因为计算简单,计算量小,模型的训练快。因此No free lunch在这里指出了用大量的计算来换取了模型的准确率的提高,计算量大模型的精度随之提高。这就证明了No free lunch原理。
版权归原作者 Love _YourSelf 所有, 如有侵权,请联系我们删除。