
博主介绍: ✌博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家✌
Java知识图谱点击链接:体系化学习Java(Java面试专题)
💕💕 感兴趣的同学可以收藏关注下 ,不然下次找不到哟💕💕

文章目录
1、Kafka 的特性是什么
Kafka 是一种高性能、分布式的消息系统,具有以下特性:
- 高吞吐量:Kafka 可以处理大规模的消息流,并具有很高的吞吐量。它能够支持每秒数百万条消息的读写操作。
- 可扩展性:Kafka 的设计允许用户在集群中添加或删除节点,以满足不断增长的消息流量需求。它可以水平扩展,以适应更大规模的数据处理。
- 持久性:Kafka 将消息持久化到磁盘上,确保消息的持久性和可靠性。即使消费者离线,也可以通过重新读取存储的消息来进行消费。
- 分布式:Kafka 是一个分布式系统,它将消息分布在多个节点上,实现了高可用性和容错性。它使用分布式存储和复制机制来确保数据的可靠性。
- 多样的数据流处理:Kafka 不仅仅是一个消息队列,还具备了流处理的能力。它支持实时流处理、批处理和交互式查询等多种数据处理场景。
- 可靠性:Kafka 提供了副本机制,确保消息在集群中的冗余存储和故障恢复。它具有高可靠性,即使在节点故障的情况下,也能保证消息的可用性。
- 可定制性:Kafka 提供了可定制的消息保留策略、分区策略和一致性保证等功能,可以根据不同的需求进行配置和调整。
总之,Kafka 是一个高性能、可扩展、持久化、分布式的消息系统,适用于处理大规模的实时数据流和构建实时数据处理应用。
2、Kafka 为什么高吞吐
Kafka 之所以能够实现高吞吐量,主要归功于以下几个方面的设计和特性:
- 分区机制:Kafka 将每个主题的消息分为多个分区,并将这些分区分布在不同的节点上。这样可以实现消息的并行处理和读写操作。每个分区都可以独立地进行读写,从而提高了吞吐量。
- 批量发送:Kafka 允许生产者将消息进行批量发送,而不是一条一条地发送。批量发送可以减少网络开销和系统调用的次数,从而提高了生产者的吞吐量。
- 零拷贝技术:Kafka 使用零拷贝技术来提高数据传输的效率。它通过直接操作内核缓冲区,避免了数据在用户空间和内核空间之间的拷贝,从而减少了数据传输的开销。
- 内存和磁盘结合:Kafka 将消息同时存储在内存和磁盘上。消息首先写入内存中的消息缓冲区,然后定期将缓冲区中的消息批量写入磁盘。这种内存和磁盘结合的方式,既保证了高吞吐量,又保证了消息的持久性。
- 集群架构:Kafka 可以通过添加更多的节点来扩展集群,从而实现分布式的消息处理。多个节点之间可以并行地处理消息,从而提高了整个系统的吞吐量。
综上所述,Kafka 通过分区机制、批量发送、零拷贝技术、内存和磁盘结合以及集群架构等设计和特性,实现了高吞吐量的消息处理能力。
3、如何测试 Kafka 的性能到底有多高呢?
3.1、单台 Kafka 两块磁盘做压测
测试命令:
4c 8g 2块独立磁盘(高性能云硬盘)
压测的命令:
./kafka-producer-perf-test.sh --topic aiocloud_test --num-records 50000000 --throughput -1 --payload-file ./record --payload-delimiter secsmart --producer-props bootstrap.servers=127.0.0.1:9092 acks=1 linger.ms=3 batch.size=20000 compression.type=lz4 max.request.size=26214400 buffer.memory=52428800
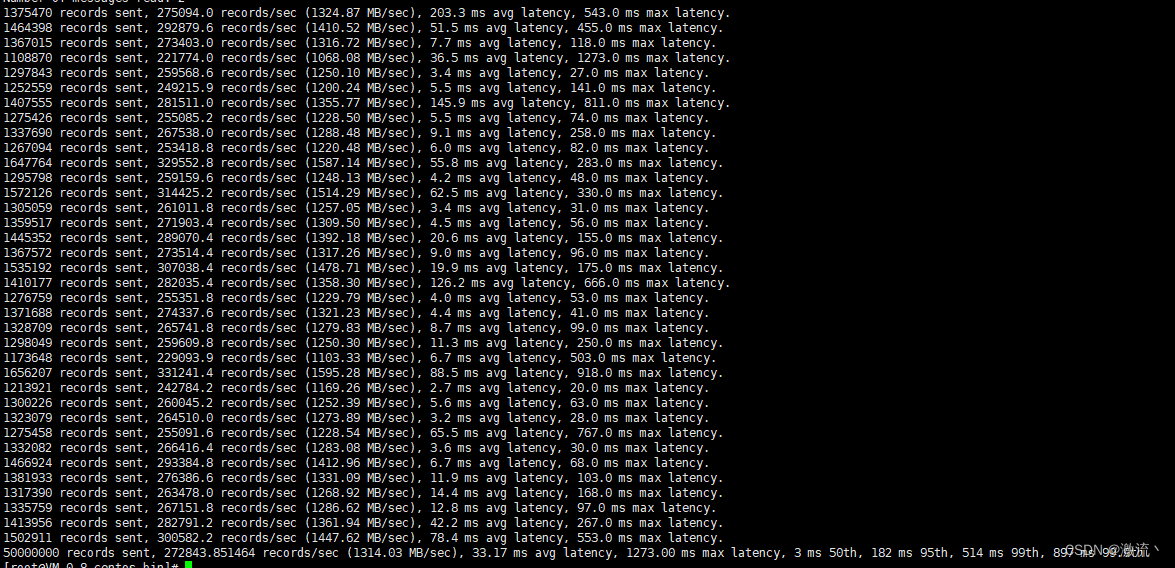
50000000 records sent, 272843.851464 records/sec (1314.03 MB/sec), 33.17 ms avg latency, 1273.00 ms max latency, 3 ms 50th, 182 ms 95th, 514 ms 99th, 897 ms 99.9th.
吞吐量: 272843.851464 records/sec (1314.03 MB/sec)
磁盘IO数据: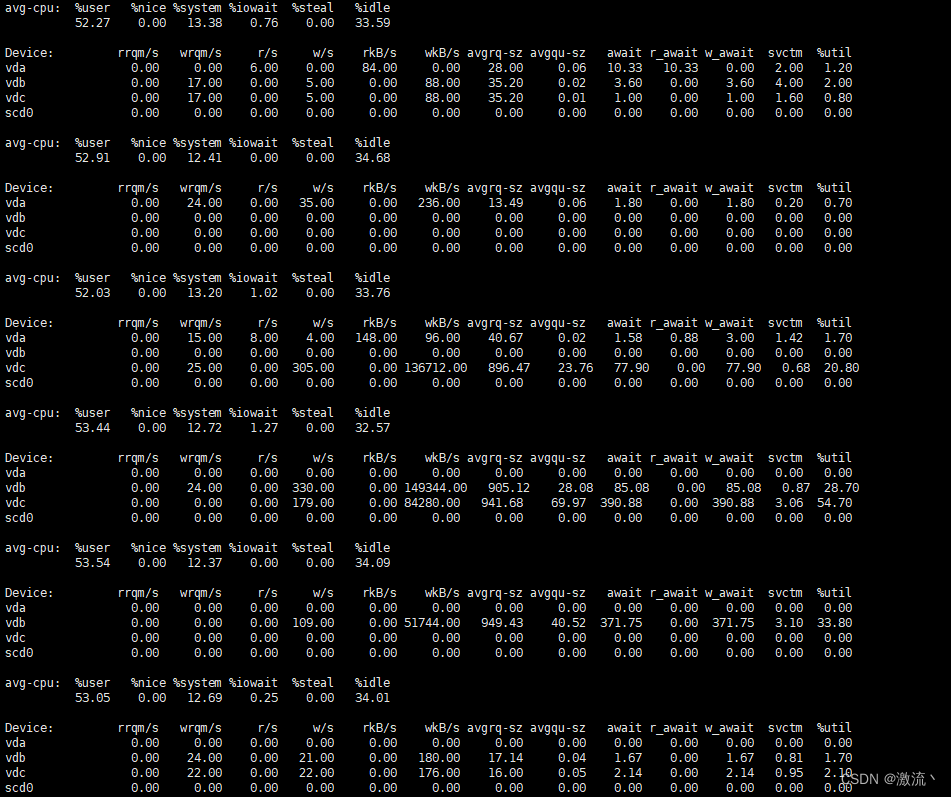
3.1、单台 Kafka 单块磁盘做压测
测试三组的数据: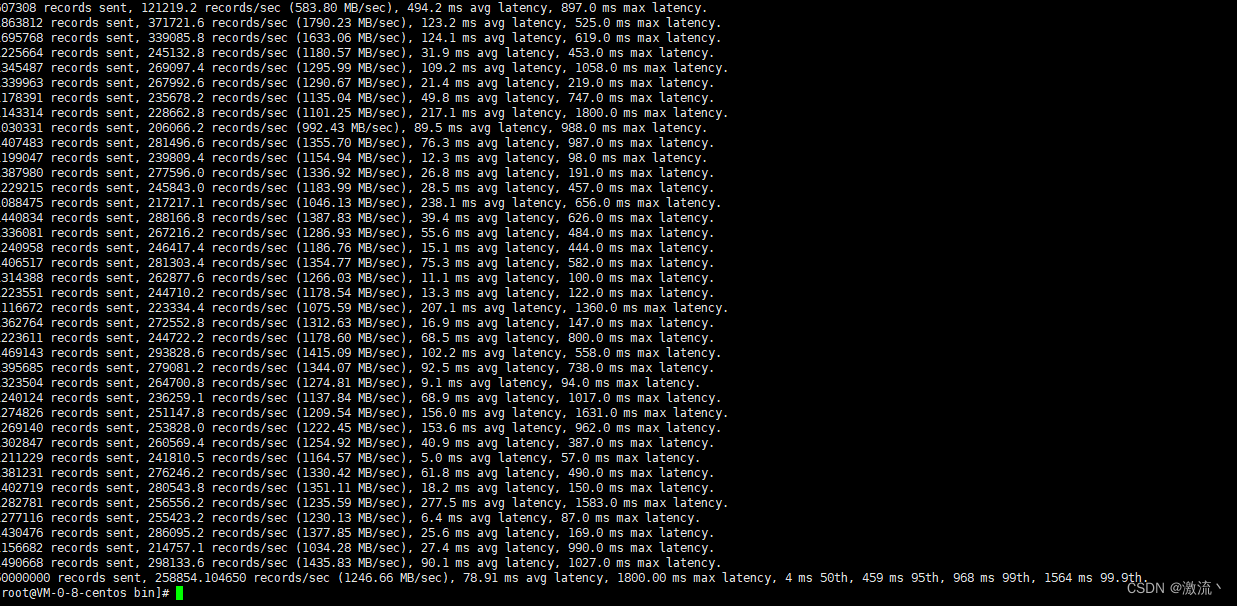



3.3、结论总结
一块盘相对两块盘,写入的吞吐量差距不大,1~2w的吞吐量,总体也有25w的吞吐量,但是写入的时间大概是两块盘的两倍。
3.4、压测参数命令介绍
分析下这个命令:
./kafka-producer-perf-test.sh --topic aiocloud_test --num-records 50000000 --throughput -1 --payload-file ./record --payload-delimiter secsmart --producer-props bootstrap.servers=127.0.0.1:9092 acks=1 linger.ms=3 batch.size=20000 compression.type=lz4 max.request.size=26214400 buffer.memory=52428800
- –topic aiocloud_test :指定要发送消息的主题名称为 “aiocloud_test”。
- –num-records 50000000 :指定要发送的消息数量为 5000 万条。
- –throughput -1 :指定发送速率为无限制,即尽可能快地发送。
- –payload-file ./record :指定消息的内容来源于名为 “record” 的文件。
- –payload-delimiter secsmart :指定消息内容的分隔符为 “secsmart”。
- –producer-props bootstrap.servers=127.0.0.1:9092 acks=1 linger.ms=3 batch.size=20000 compression.type=lz4 max.request.size=26214400 buffer.memory=52428800 :指定生产者的配置属性。具体的配置如下:
- bootstrap.servers=127.0.0.1:9092 :指定 Kafka 集群的连接地址为 127.0.0.1:9092。
- acks=1 :指定生产者在发送消息时等待的确认数为 1,表示只需要 Leader 副本确认即可。
- linger.ms=3 :指定生产者在发送消息前等待的时间,单位为毫秒,这里设置为 3 毫秒。
- batch.size=20000 :指定生产者在发送消息前等待的消息批次大小,单位为字节,这里设置为 20000 字节。
- compression.type=lz4 :指定消息的压缩类型为 lz4。
- max.request.size=26214400 :指定生产者发送的最大请求大小为 26214400 字节。
- buffer.memory=52428800 :指定生产者的缓冲区大小为 52428800 字节。

💕💕 本文由激流原创,首发于CSDN博客,博客主页 https://blog.csdn.net/qq_37967783?spm=1010.2135.3001.5421
💕💕喜欢的话记得点赞收藏啊
版权归原作者 激流丶 所有, 如有侵权,请联系我们删除。