
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122249302
第1章 SPP-Net网络概述
1.1 什么是SPP-Net?
SPP-Net是一种可以不用考虑图像大小,输出图像固定长度网络结构,并且可以做到在图像变形情况下表现稳定。SPP-Net是出自论文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》。
在SPP-Net之前,所有的神经网络都是需要输入固定尺寸的图片,比如224224(ImageNet)、3232(LenNet)、96*96等。这样对于我们希望检测各种大小的图片的时候,需要经过resize、crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。而且,从生理学角度出发,人眼看到一个图片时,大脑会首先认为这是一个整体,而不会进行crop和warp,所以更有可能的是,我们的大脑通过搜集一些浅层的信息,在更深层才识别出这些任意形状的目标。
1.2 SPP-Net的基本思想
SPP-Net对这些网络中存在的缺点进行了改进,基本思想是:输入整张图像,提取出整张图像的特征图,然后利用空间关系从整张图像的特征图中,在spatial pyramid pooling layer提取各个region proposal的特征。

一个正常的深度网络由两部分组成,卷积部分和全连接部分,要求输入图像需要固定size的原因并不是卷积部分而是全连接部分。所以SPP层就作用在最后一层卷积之后,SPP层的输出就是固定大小。
1.3 SPP-Net的好处与优点
- SPP-net不仅允许测试的时候输入不同大小的图片,
- 训练的时候也允许输入不同大小的图片,
- 通过不同尺度的图片同时可以防止overfit(过拟合)
- SPP-net的效果已经在不同的数据集上面得到验证,速度上比R-CNN快24-102倍。在ImageNet 2014的比赛中,此方法检测中第二,分类中第三。
第2章 SPP网络结构
2.1 SPP 金字塔池化层的位置
卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系,只是对不同大小的图片卷积出不同大小的特征图。
但是全连接层的参数就和输入图像大小有关,因为它要把输入的所有像素点连接起来,需要指定输入层神经元个数和输出层神经元个数,所以需要规定输入的feature的大小。因此,固定长度的约束仅限于全连接层。
SPP-Net在最后一个卷积层后,接入了金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。因此,SPP网络的核心就是金字塔池化层。
2.2 SPP的特征提取
我们先从空间金字塔特征提取说起(这边先不考虑“池化”),空间金字塔是很久以前的一种特征提取方法,跟Sift、Hog等特征息息相关。为了简单起见,我们假设一个很简单两层网络:
输入层:一张任意大小的图片,假设其大小为(w,h)。
输出层:21个神经元。
也就是我们输入一张任意大小的特征图的时候,我们希望提取出21个特征。
空间金字塔特征提取的过程如下:
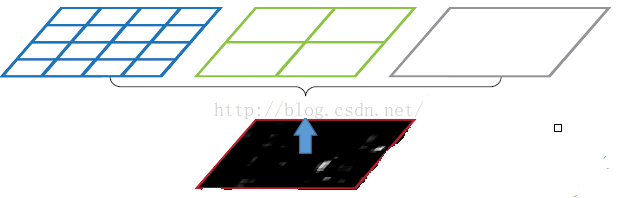
(1)图片输入
黑色图片代表卷积之后的特征图,其尺寸是任意的,该特征作为SPP网络的输入。
(2)特征提取网格的定义(SPP池化层网格的定义)
生成三个SPP池化核,每个SPP池化核代表的是输出特征的网格,网格的大小,不同的应用,大小不同,这里假设为:44, 22, 1*1。
SPP池化核网格的个数,决定了输出的大小,而不是输入的大小。
SPP池化核网格的作用是均分任意长度尺寸图片的像素,如:
4 * 4的网络,就是把输入图片均分成 4 * 4 = 16个块,而不管输入图片的尺寸到底是多少。
1 * 1的网络,就是把输入图片均分成 1 * 1 = 01个块,而不管输入图片的尺寸到底是多少。
这样可以得到16+4+1=21种不同的固定长度的输出块(Spatial bins)。
注意:SPP的池化层与CNN网络中的池化层的定义是不同的。
- CNN的池化层:定义的是池化核的大小和stride的大小。
- SPP的池化层: 首先, SPP定义三个池化核。其二,SPP池化核网格的大小,如4 * 4,不是池化核的大小,而是输出特征的大小。
(3)对任何长度的输入图片的重新切分/划分

如上图所示,当我们输入一张任意尺寸的图片的时候,我们利用不同网格大小的池化核,对一张图片进行了划分。
第1个SPP池化核=(4 * 4), 把一张完整的任意长度的输入图片,分成了16个块,也就是每个块的大小就是(w/4,h/4);
第2个SPP池化核=(2 * 2), , 把一张完整的任意长度的输入图片,分成了4个块,也就是每个块的大小就是(w/2,h/2);
第3个SPP池化核=(1 * 1), , 把一张完整的任意长度的输入图片,分成了1个块,也就是每个块的大小就是(w,h);
经过上述的切分,可以得到最后总共可以得到16+4+1=21个块,即一个固定长度的特殊输出。
(4)最大池化特征提取
对每个网格,按照各自占用输入特征的范围,各自独立的进行池化,支持的算法算法有:
- 最大池化
- 最小池化
- 平均池化
(5)固定长度的特征输出
最大池化后,每个网格输出一个最大池化值,一共输出21个最大特征值,这21个输出特征值组成了最终的输出。这样就可以把任意长度的特征值,转化为一个固定大小的特征值了,由于SPP采用了三层不同的池化核,因此转化后的特征值,既包含了高层抽象特征,也包含了低层的具体特征。
当然你可以设计其它维数的输出,增加金字塔的层数,或者改变划分网格的大小)。
上面的三种不同刻度的划分,每一种刻度我们称之为:金字塔的一层。
空间金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的奥义(多尺度特征提取出固定大小的特征向量)。
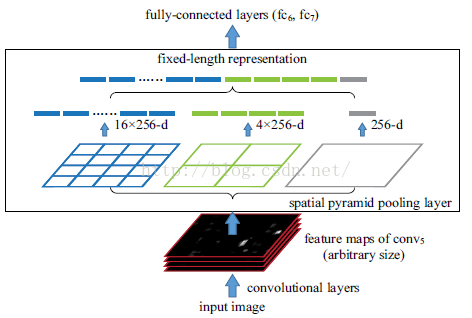
备注:空间金字塔池化,与其他池化一样,对channel维度没有影响。
第3章 包含SPN结构的网络的训练
3.1 Multi-size training
使用两个尺度进行训练:比如,224224 和180180。
训练的时候,224x224的图片通过crop原始图片得到,180x180的图片通过进一步缩放224x224的图片得到。
之后,迭代训练,即用224224的图片训练一个epoch,然后在用180180的图片训练一个epoch,交替地进行。
两种尺度下,在SPP结构后,输出的特征维度都是(9+4+1)x256,参数是共享的,之后接全连接层即可。
3.2 single-size
理论上说,SPP-net支持直接以多尺度的原始图片作为输入。
实际上,深度学习框架,为了计算的方便,GPU,CUDA等比较适合固定尺寸的输入,所以训练的时候输入是固定了尺度了的。
第4章 SPP网络的pytorch实现
待续。。。。。。。
参考:
https://blog.csdn.net/hjimce/article/details/50187655
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122249302
版权归原作者 文火冰糖的硅基工坊 所有, 如有侵权,请联系我们删除。