
意义:
`搭建pycharm远程开发spark 意义在于。我们只需要在pycharm来手动生成执行spark python项目,在linux下默认会生成spark 项目的python文件。不需要在linux下手动新建spark python文件,然后再执行。总之比较方便。
版本
- pycharm 2022 专业版
- jdk 1.8
- spark 2.4.4
- scala 2.12
- hadoop 2.7.7
- python解释器 (3.8.10) (3.7.0) (3.6.1) (3.5.3)(我这里有四个python解释器,系统默认3.8.10,另外三个是我自己装的)
- Ubuntu系统 20.04.5
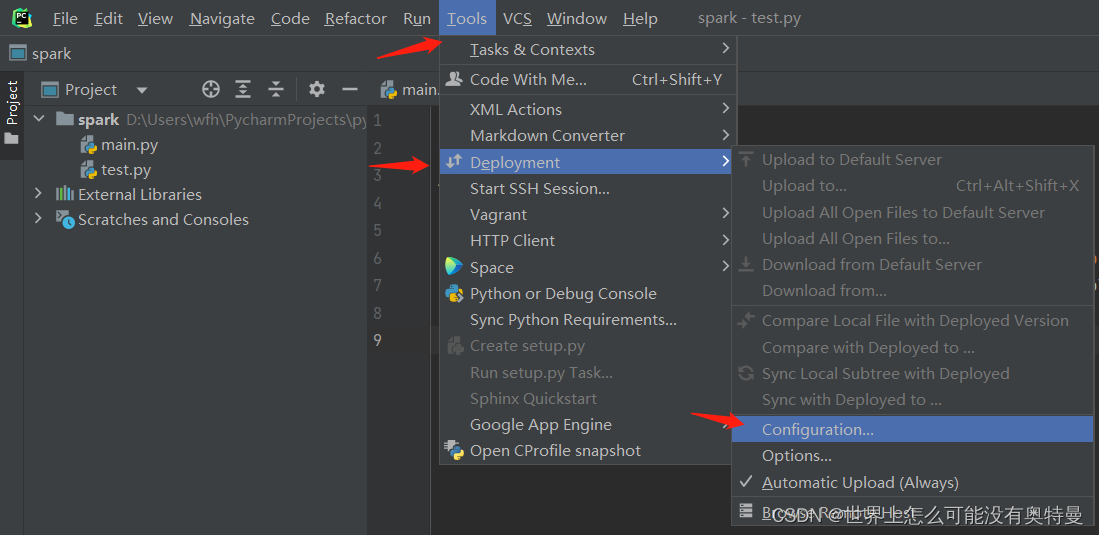
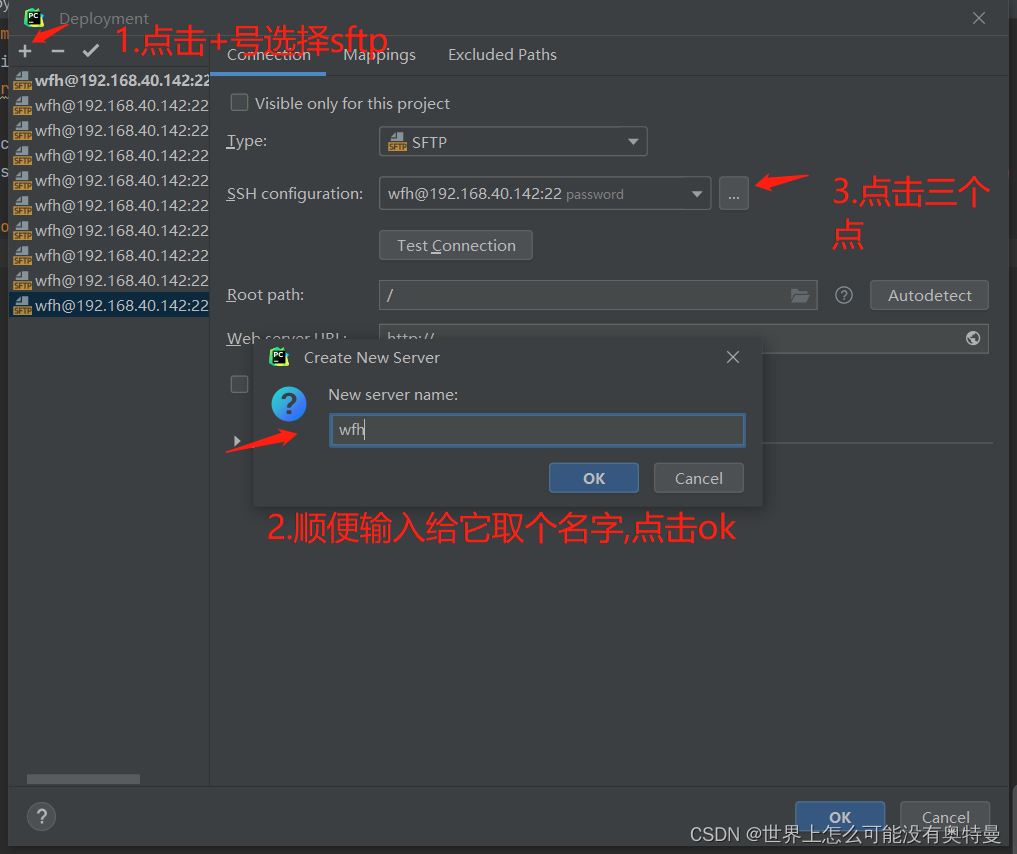
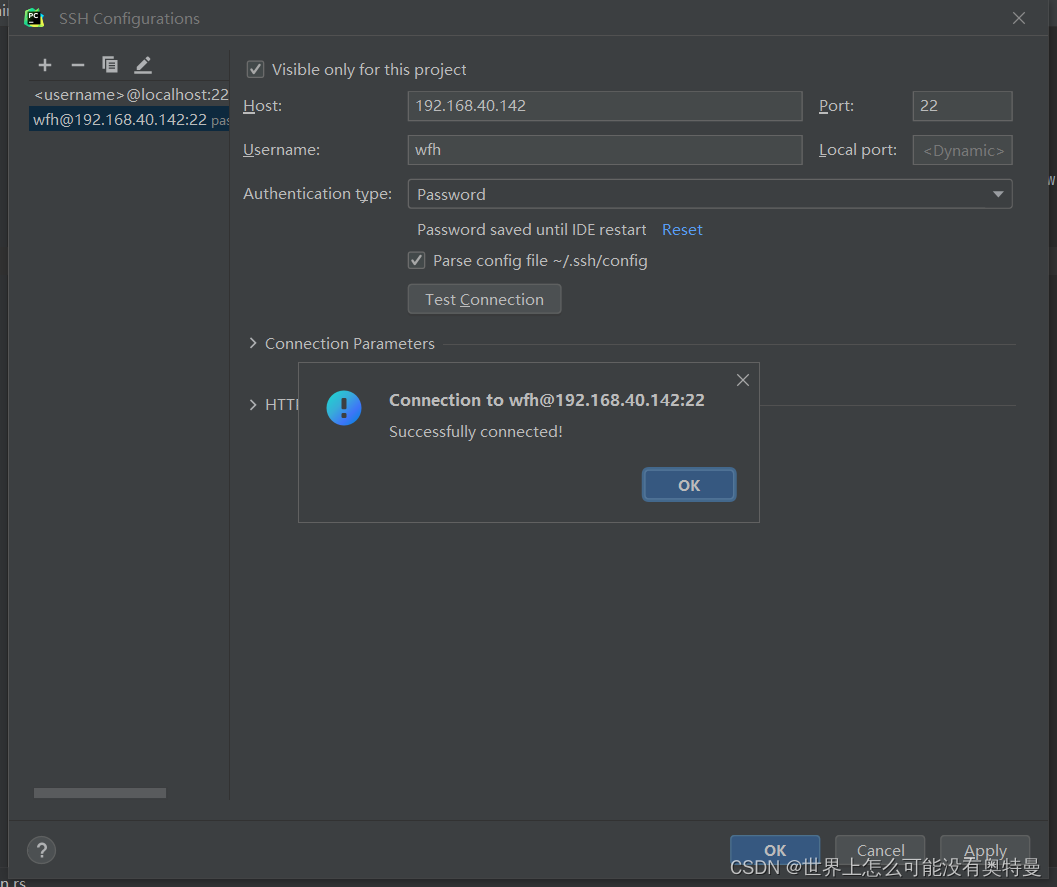
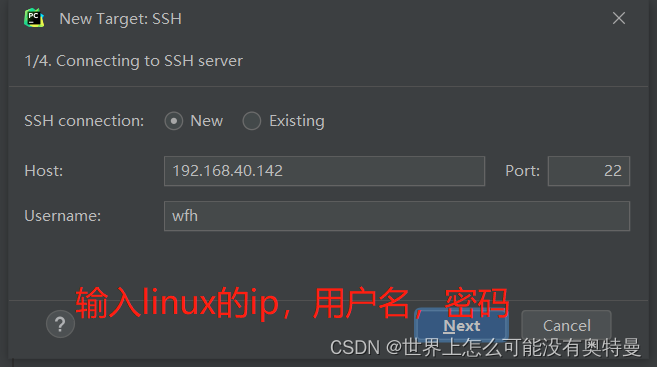
pycharm连接linux:
2.

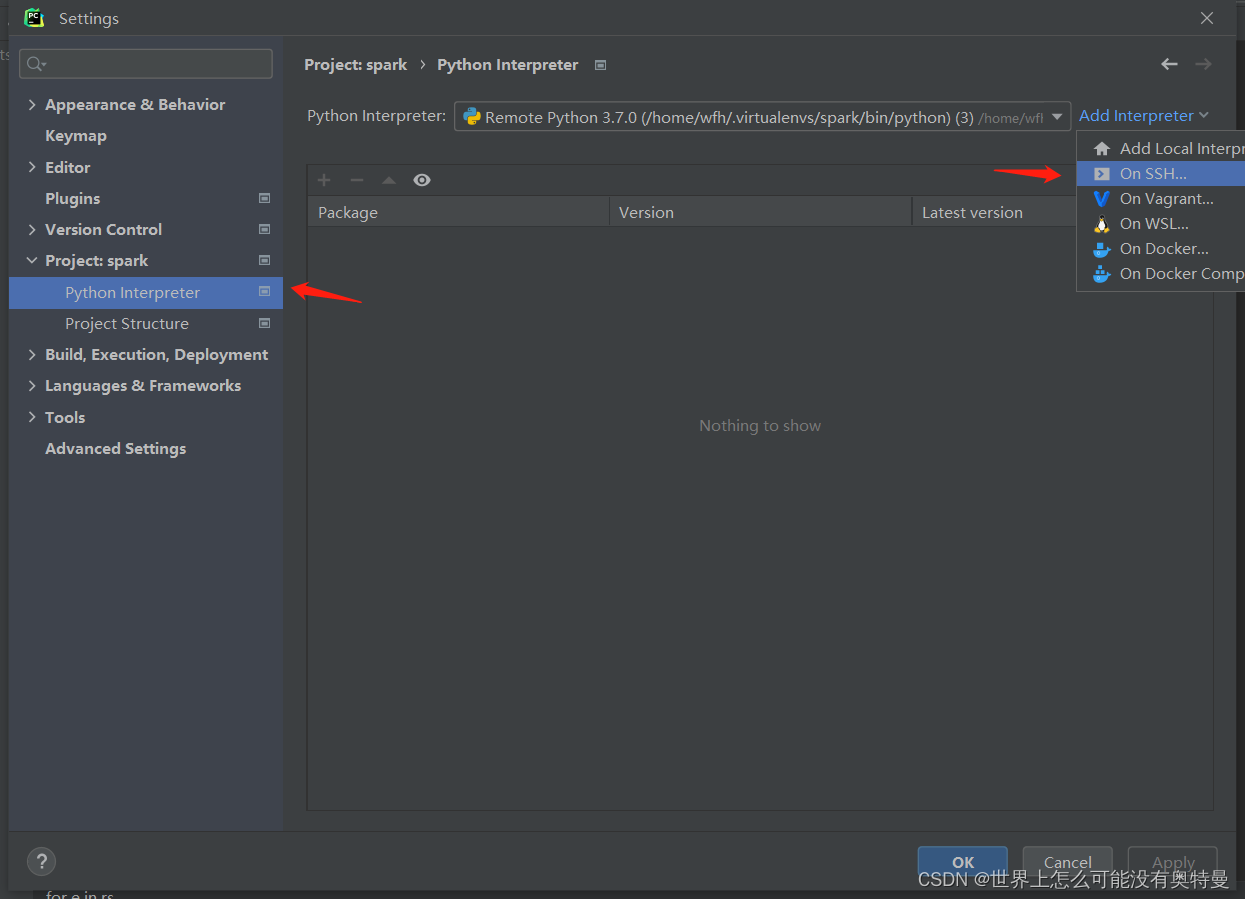
pycharm部署linux下的python环境:
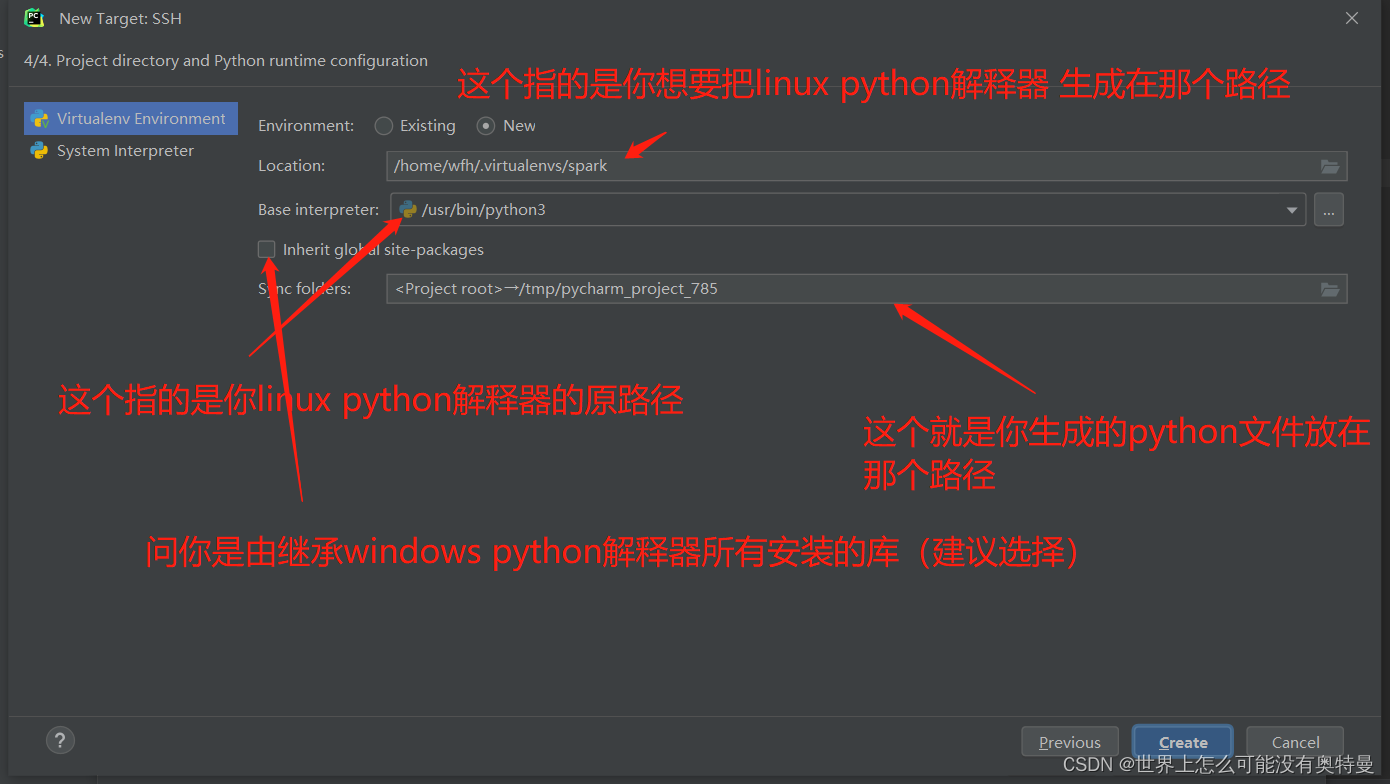
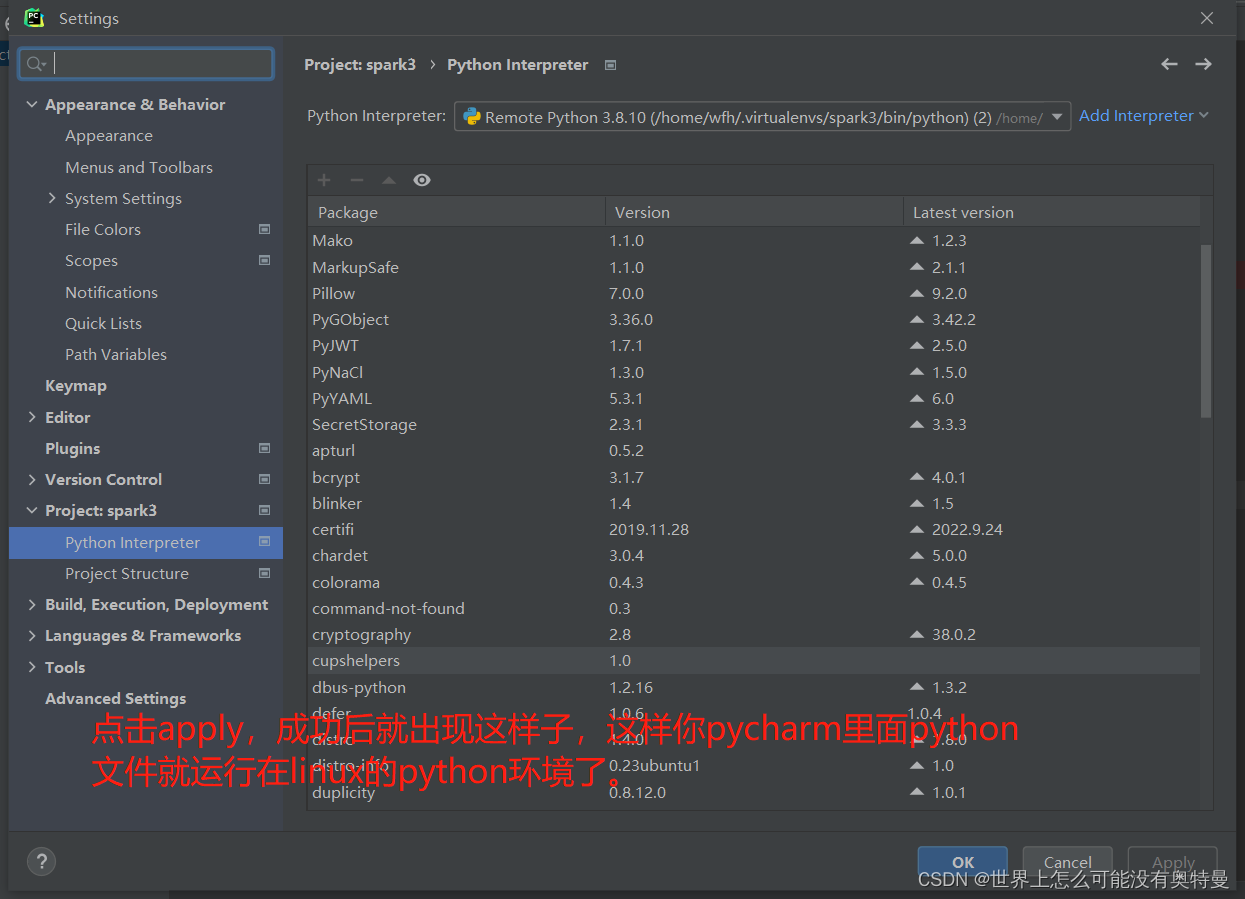
编写spark程序
接着在pycharm新建python文件 编写python spark程序
from pyspark import SparkContext
sc = SparkContext("spark://192.168.40.142:7077", "WordCountApp")
rs = sc.textFile("/home/test/wc.txt").flatMap(lambda line: line.split(" ")).map(lambda w: (w, 1)).reduceByKey(lambda x, y: x+y).sortBy(lambda x:x[1], False).collect()
for e in rs:
print(e)
运行报了个错误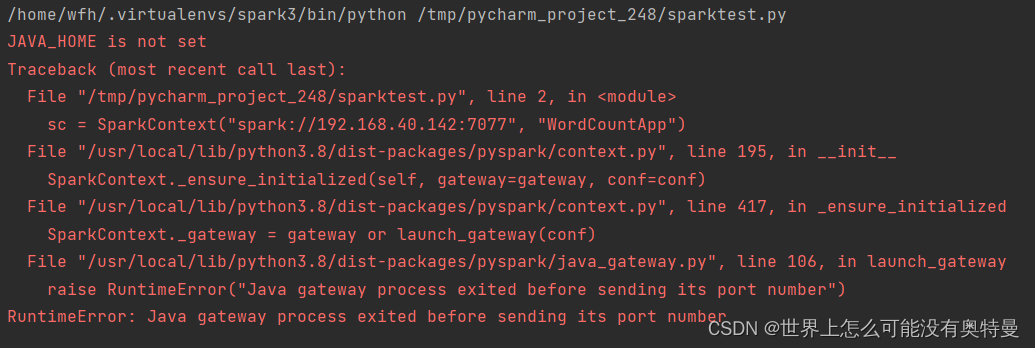
错误1 :JAVA_HOME is not set,RuntimeError
报错一个主要信息就是 JAVA_HOME is not set,RuntimeError。意思是没有设置Java环境变量。我们知道,spark底层是由Scala语言编写的。而Scala是运行在jvm上的。而pyspark只需要用python语言就能够执行spark项目,不需要用用Scala语言来编写。减少学习成本,这里我多插两嘴,简单说说spark,pyspark的执行过程。
- 比如我想要统计单词出现次数频率的spark项目。它整个过程是怎么样的呢?在driver program中,首先创建sparkcontext对象,这个spark context就是整个过程的指挥官,里面写的该怎么执行单词统计,计算需要的cpu,内存空间资源的多少等等。然后spark context会向cluster manager申请注册资源。cluster manager收到来自spark context所需要资源,就会分配给两个executor运行资源,然后并向spark context指挥官申请工作内容并交给task执行。executor监控task的运行状态,并向cluster manager发送心跳信息,告诉cluster manager我还活着,我在还工作。 在整个过程 spark context就好比与项目经理,写着整个过程要做什么。cluster manager就是人力资源,或者说是中介,给经理提供人力物力。worker node类比于个车间,车间里面有task,task就是打工仔,专门来干活的,而executor 比task高一个等级,他就是task组长监控task有没有在工作。
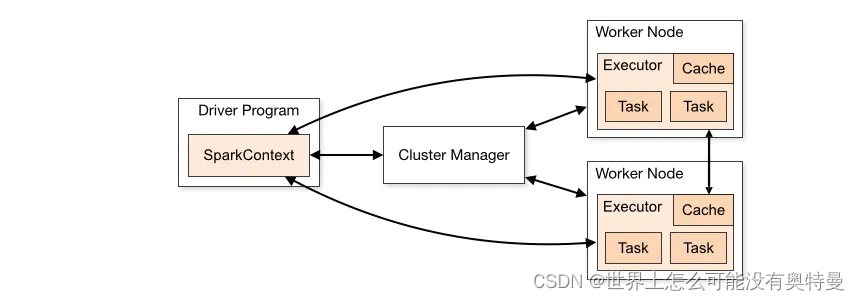
- pyspark整个过程是这样的。py4j是python和scala之间的桥梁。python创建spark context对象会通过py4j在jvm实例化生成spark context对象,实质上就是python通过py4j调用Java的方法。然后生成 spark context对象,spark context把工作内容代码交给spark worker执行。而在spark node当中,executor执行不了python文件,只能执行java文件。所以必须配置python环境变量,单独开辟python进程,通过socket通信将python语句交给python进程来执行。
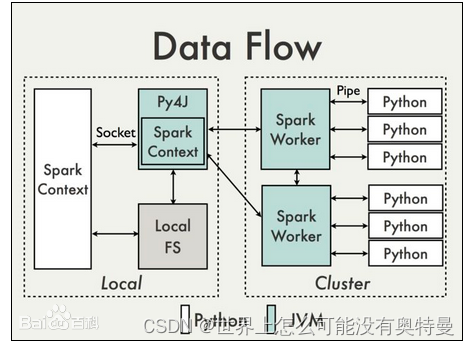
解决办法
根据上述spark,和pyspark执行过程。这个错误就很容易解决了。只需在python文件配置Linux下java环境。因为你一开始实例化spark contex对象是在jvm上面实例化的,而jdk包含jvm,因此要配置jdk环境变量。
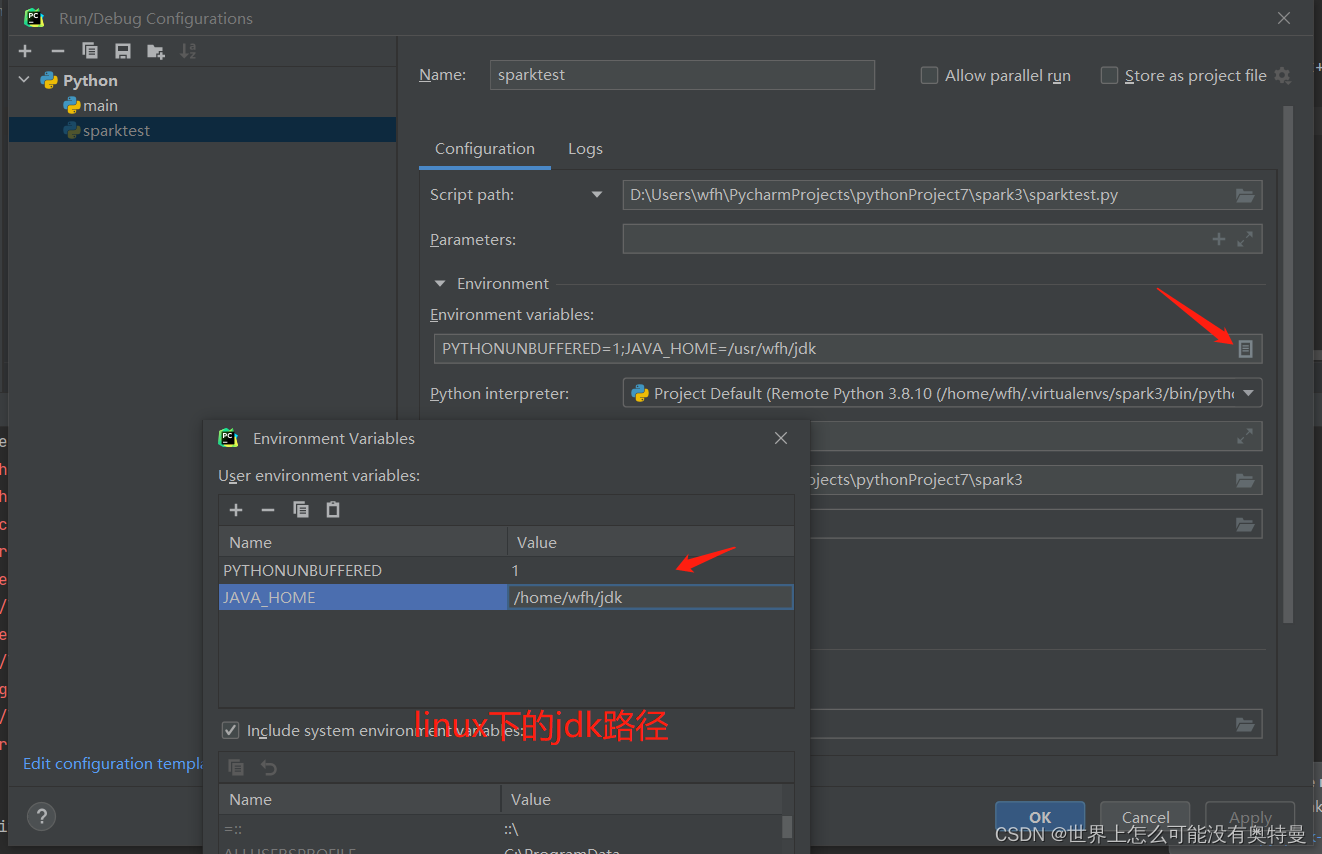
运行之前保证你的linux下Hadoop,和spark进程都要开启。
之后又报错
错误2:22/10/14 20:28:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
22/10/14 20:29:36 ERROR StandaloneSchedulerBackend: Application has been killed. Reason: All masters are unresponsive! Giving up.
22/10/14 20:29:36 WARN StandaloneSchedulerBackend: Application ID is not initialized yet.
报错内容意思是:1.无法加载hadoop库2.应用进程被杀死,原因 因为所有master进程没回应,放弃。3.应用没有被初始化。
解决办法:在python文件配置spark环境变量即可,原因在于python执行的是spark项目,需要spark环境才可以运行。意思是上述python代码 需要python环境+spark环境+jdk环境才可以执行。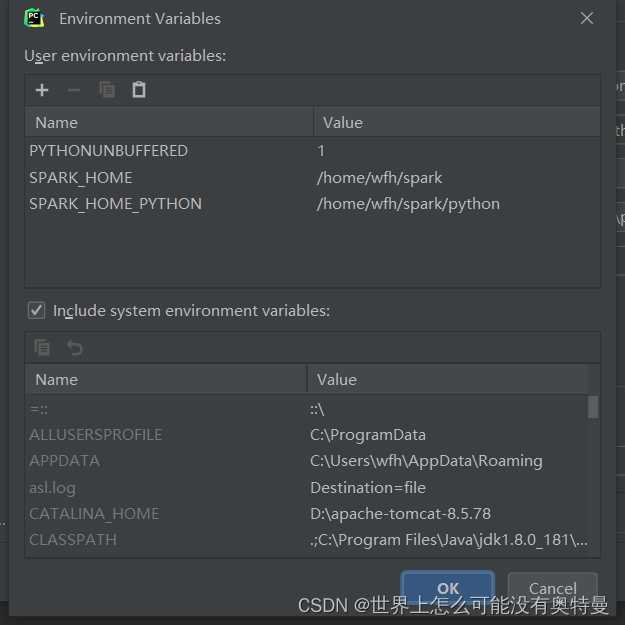
接着运行又报了个错误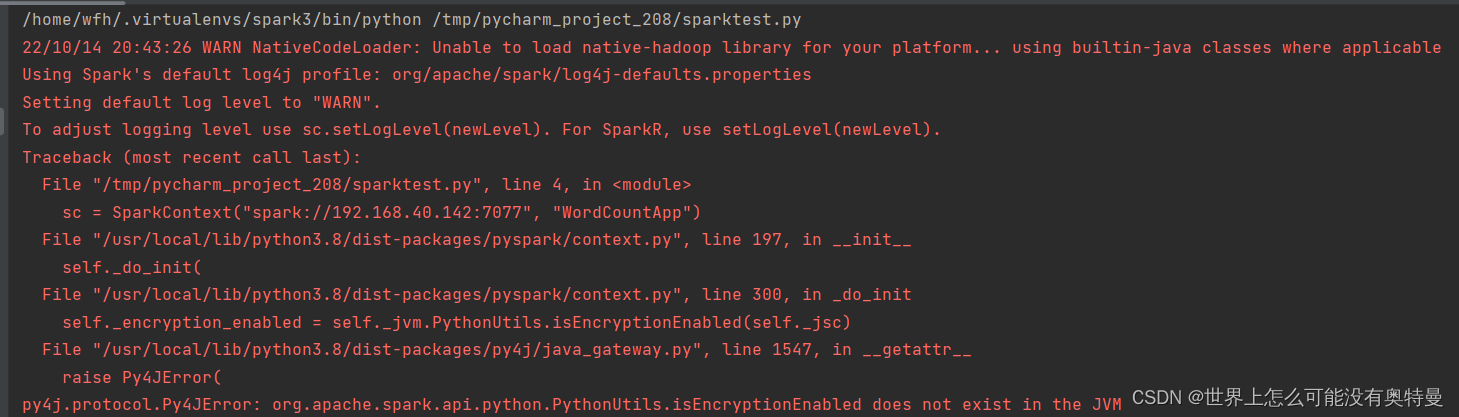
错误3.py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.isEncryptionEnabled does not exist in the JVM
jvm当中没有isEncryptionEnabled。解决办法在最上面添加两行代码
#添加此代码
import findspark
findspark.init()
#添加此代码
from pyspark import SparkConf, SparkContext
作用就是初始化找到本机安装的spark的环境
这里要注意你inux下python要有findspark库。不然也会报错,no modular name findspark。一般默认没有的,这是你要下载个findspark,但是有些python版本是不自带pip,所有首先第一步先下载pip
关于下载pip可以参考这个博客
下载完会在你当前路径下生成 get-pip.py 文件。在之前这条命令之前要先安装curl,照着错误提示安装curl,安装curl过程会报很多错误,那个可以不用管。
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # 下载安装脚本
这里注意,你用那个版本python运行安装脚本,pip会自动安装到那个python版本
sudo python get-pip.py # 运行安装脚本
你用那个版本python,就用对应的pip
pip install findspark 下载findspark库
下载完后运行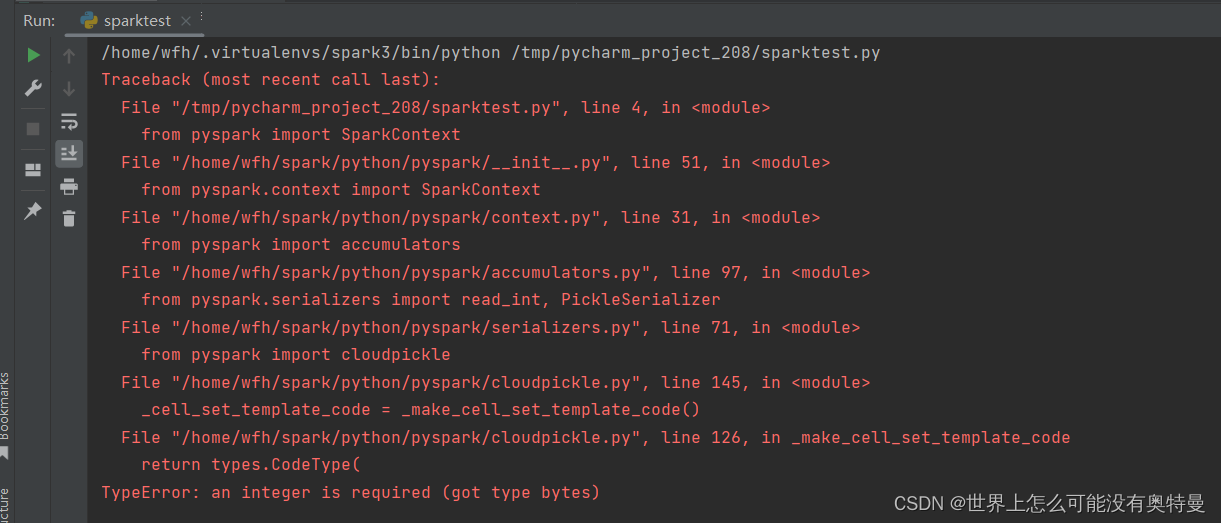
错误4TypeError: an integer is required (got type bytes)
上网查找原因他们说 spark2.4.4不支持python3.8,只需要另外安装python3.8一下的版本。选择python3.8以下的解释器运行这个文件就可以了
关于如何安装python可以参考别的博客
(https://blog.csdn.net/weixin_48960305/article/details/125143116)
接着一顿操作,安装完python,重新配置linux下的python环境。选择python3.8以下的解释器
这里注意在编译和安装python过程中会报一下小错误,要留意错误信息。但是并不影响你安装成功。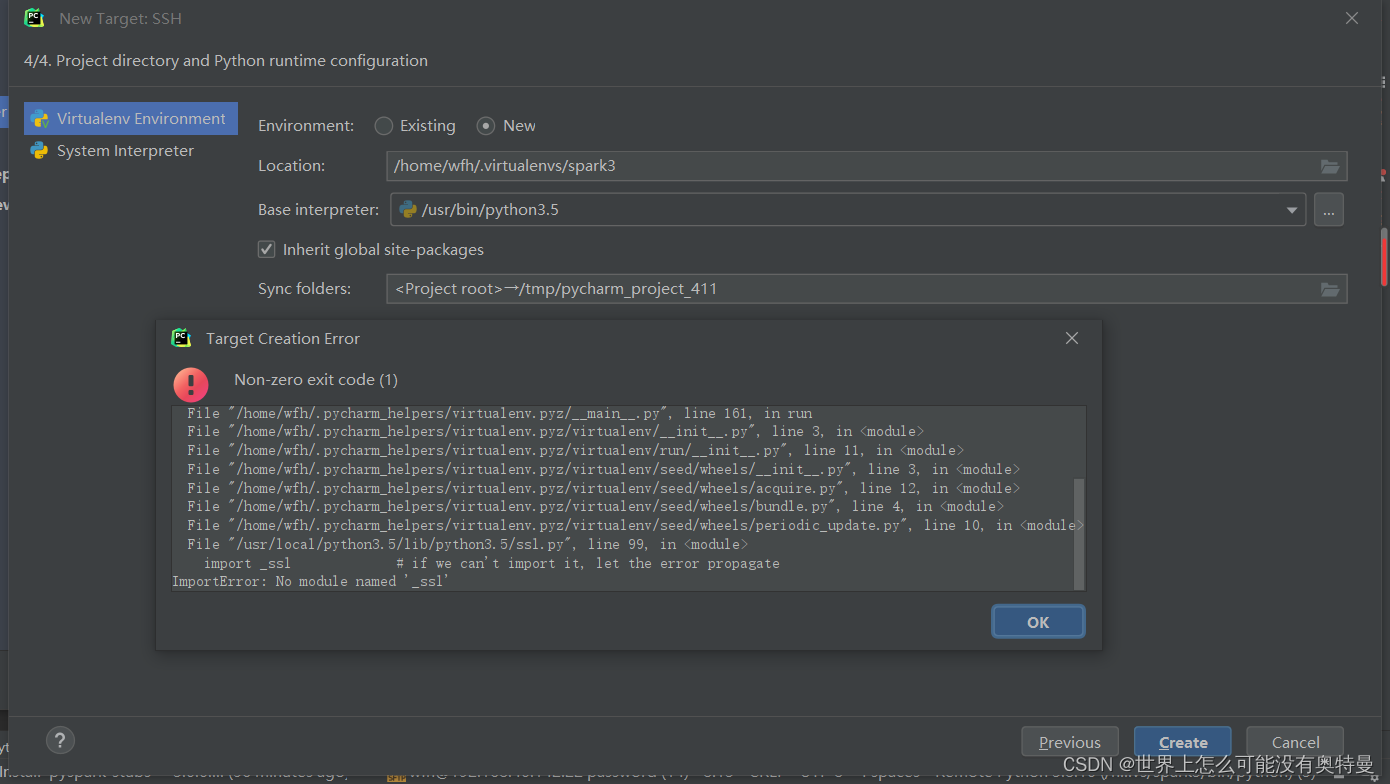
接着又报错。哈哈哈哈哈笑拉了
错误5 ImportError: No module named ‘_ssl’
原因在于在编译安装python时候,没有把ssl模块编译进去。而ssl模块编译需要一些依赖环境
解决办法:先安装下面两个依赖环境。一开始在网上搜索说要安装openssl-delvel。我试了报了个错误,无法地位软件报e 结果发现这个只有在centos7才有的,而ubuntu是下载下面对应两个《可以参考这个博客》,《关于安装openssl另外一种方法》
sudo apt-get install openssl
sudo apt-get install libssl-dev
sudo apt-get install libffi-dev #这个不安装会报 错误6
安装完进入python配置目录 我这里是是/home/wfh/Python3.5/Modules
修改两个文件
vim Setup.dist
vim Setup
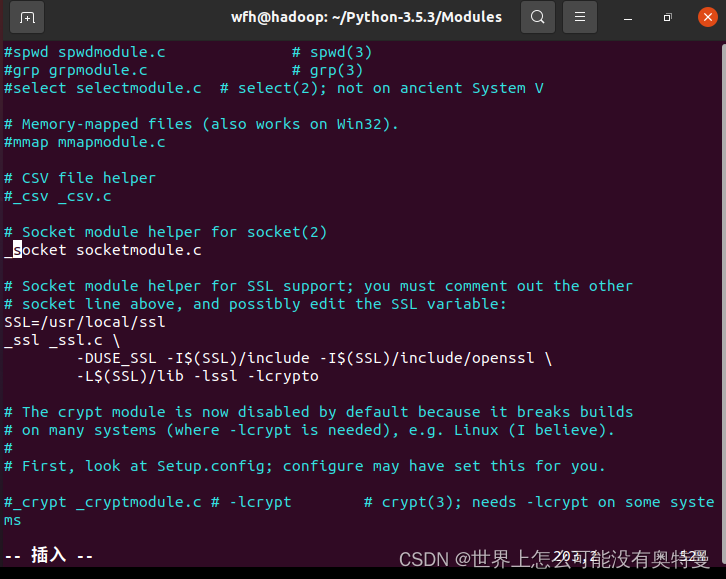
将这五行注释全部去掉,然后重新编译安装python。在pychram 部署linux下python3.7解释器。可以部署成功不报刚刚那个错误。接着运行程序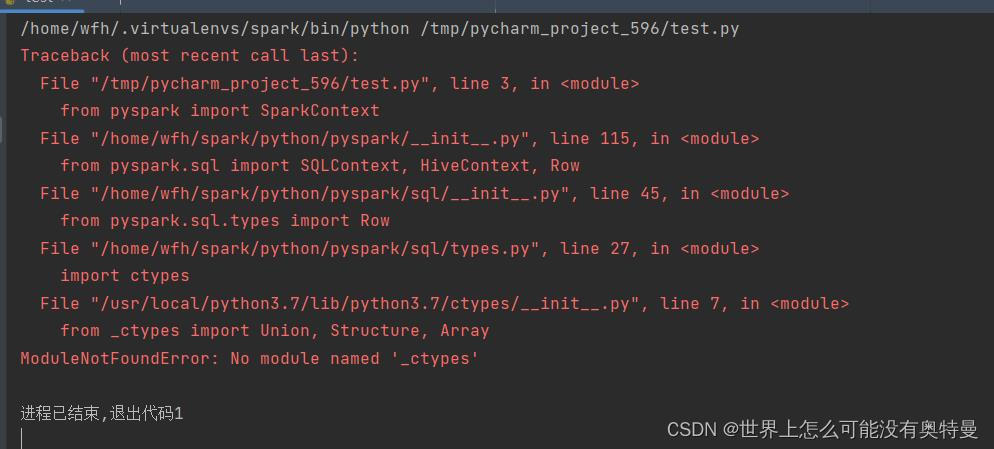
又报另外一个错误。也是没有_ctypes这个模块
错误6 NO module named ‘_ctypes’
上网寻找解决办法,和上一个no module ssl很相似。只需要安装环境依赖就可以了,重头编译安装python
sudo apt-get install libffi-dev
最后重新运行程序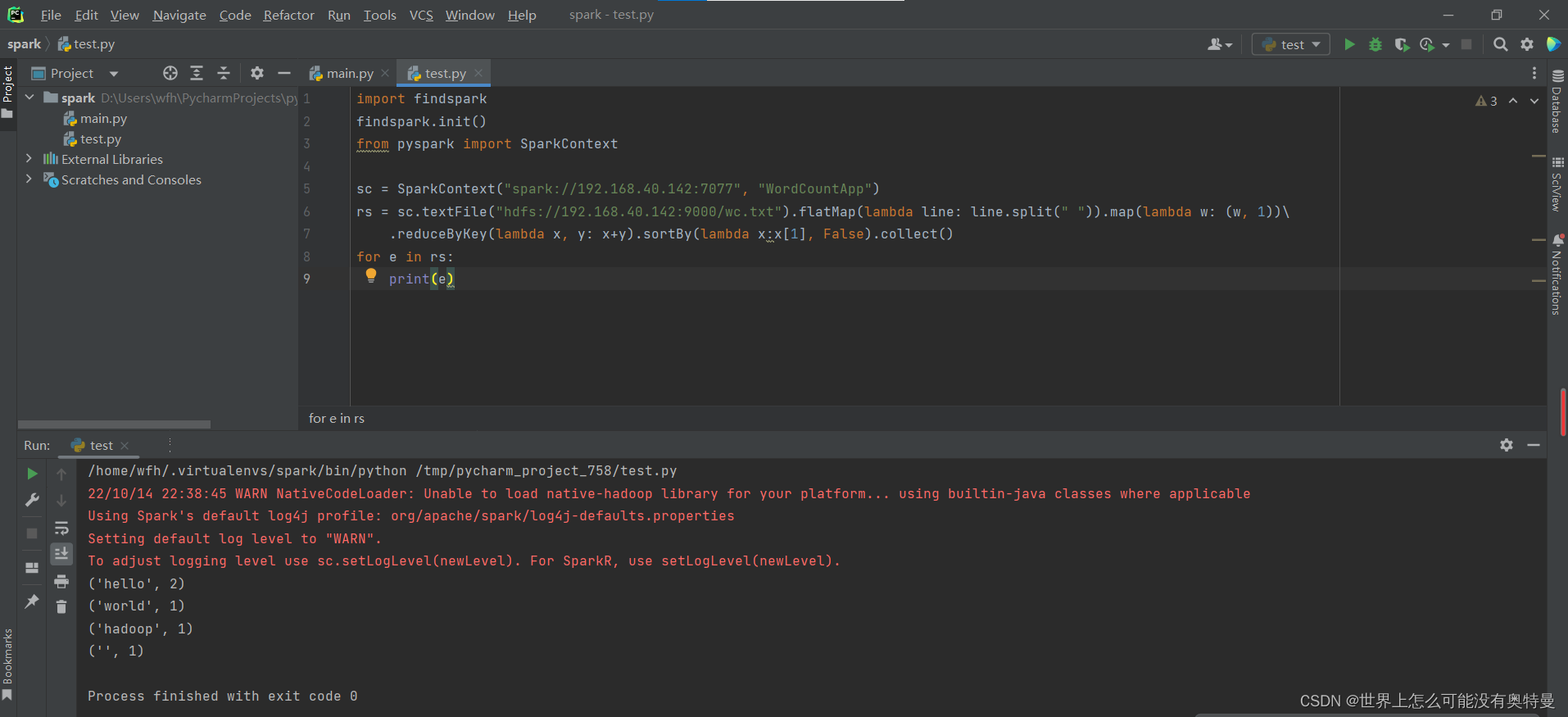
成功!!! 呜呜呜呜呜
写于 -2022/10/15 13:39 秋 —by wfh
版权归原作者 世界上怎么可能没有奥特曼 所有, 如有侵权,请联系我们删除。