
部分知识(可略过)
Kafka
Kafka是一种分布式流处理平台,它是一个高吞吐量、可扩展、持久化的消息队列系统,用于处理实时数据流。Kafka的核心概念包括生产者(Producer)、消费者(Consumer)和主题(Topic)。生产者负责将数据发布到Kafka集群,消费者则从Kafka集群中订阅并消费数据。主题是数据的分类或者分区,每个主题可以有多个分区,而每个分区又可以有多个副本。这种分区和复制的机制使得Kafka具备了高可用性和容错性。同时,Kafka还提供了丰富的API和生态系统,使得开发者可以方便地构建基于Kafka的实时数据处理应用。
Redis
Redis是一个开源的内存数据结构存储系统,它可以用作数据库、缓存和消息中间件。Redis支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等。它以键值对的形式存储数据,并且数据存储在内存中,因此具有快速的读写性能。Redis还提供持久化功能,可以将数据保存到磁盘上,以便在重启后恢复数据。由于其高性能、灵活性和丰富的功能,Redis被广泛应用于各种场景,如缓存加速、实时计数、排行榜、消息队列等。
Scala
Scala是一种面向对象的编程语言,也是一种函数式编程语言,它结合了面向对象编程和函数式编程的特性。Scala运行在Java虚拟机上,因此可以与Java代码无缝地集成。Scala具有静态类型系统,支持类型推断,可以提高代码的可读性和可维护性。Scala还提供了许多高级特性,如高阶函数、模式匹配、类型类等,使得编写高效、简洁、可重用的代码变得更加容易。Scala在大数据处理、Web应用程序、分布式系统等领域得到了广泛应用。
Spark Streaming(DStream)
Spark Streaming是Apache Spark的一个组件,它提供了实时数据处理和流式计算的功能。它允许开发人员使用Spark的强大的批处理引擎来处理实时数据流。Spark Streaming可以从多种数据源(如Kafka、Flume、HDFS等)接收实时数据,并将其分成小的批次进行处理。每个批次都可以像处理静态数据一样使用Spark的高级API进行处理,包括使用SQL查询、机器学习算法和图处理等。
RDD
RDD是Apache Spark中的一个核心概念。RDD是一个可分区、可并行计算的数据集合,它可以在分布式计算环境中进行高效的数据处理和分析。RDD具有容错性,即在计算过程中可以自动恢复失败的节点,并且可以在内存中缓存数据,以提高计算性能。RDD提供了一系列的转换操作(如map、filter、reduce等)和行动操作(如count、collect、save等),可以对数据集进行各种复杂的计算和操作。通过使用RDD,可以方便地进行大规模数据处理和分析。
Jedis
Jedis是一个Java语言编写的用于操作Redis数据库的客户端库。Jedis客户端库可以让Java开发者通过简单的API调用来连接、操作和管理Redis数据库。它提供了丰富的功能和灵活的接口,使得开发者可以方便地在Java应用程序中使用Redis。
Scala编程
目的
使用Scala编程,用Spark Streaming采集Kafka消费者端口接收到的信息,对信息进行处理求出每个电影ID对应的平均分数并写入到Redis数据库中。
导入Maven依赖
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.22</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.28</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
</dependencies>
创建Scala文件导入依赖
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import redis.clients.jedis.Jedis
创建Spark相关对象
// 创建SparkConf对象,名称为"KafkaToRedis",并将运行模式设置为本地模式
val sparkConf = new SparkConf().setAppName("KafkaToRedis").setMaster("local")
// 创建SparkContext对象
val sc = new SparkContext(sparkConf)
// 创建StreamingContext对象, 设置每个批次的时间间隔为1秒
val ssc = new StreamingContext(sc, Seconds(1))
创建Kafka数据流
bootstrap.servers:Kafka消费者的IP地址以及端口号auto.offset.reset:对偏移量的采集设置,latest:最新偏移量,即程序运行后会从Kafka消费者接收到的最新的消息开始采集。earliest:最早偏移量,即程序运行后会从Kafka消费者接收的第一条消息开始采集。- group.id:消费者组ID,需要到kafka/config/consumer.properties中去查看

// 定义了Kafka的相关参数,包括Kafka的地址、键和值的反序列化器、偏移量重置方式和消费者组ID
val kafkaParams = Map("bootstrap.servers" -> "192.168.181.128:9092",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"auto.offset.reset" -> "latest",//latest:最新偏移量,earliest:最早偏移量
"group.id" -> "test-consumer-group")
// 定义了要订阅的主题集合
val topics = Set("order")
// 创建了一个直接流,将Kafka的消息流转换为DStream
val kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))
处理数据流
** (通过kafka的API调用使用JAVA编写kafka生产者实现每秒向消费者发送一条消息,该程序本文未展出)**
** ** 消费者接收端数据如下
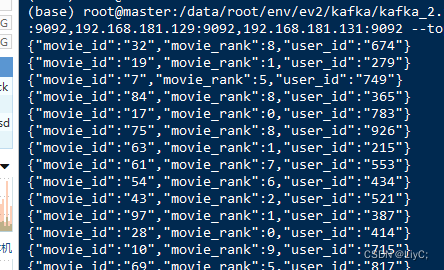
处理方法:
1.因为采集到的一行data数据为{"movie_id":"84","movie_rank":8,"user_id":"365"},需要对数据进行分割提取处理。
2.以data.split(",")(0).split(":")(1).replaceAll("\"", "").trim()为例
split(",")(0)将data按逗号分割提取第一个,得到{"movie_id":"84"
split(":")(1)将上一步得到的数据按‘:’经行分割提取第二个,得到"84"
replaceAll("\"", "")将上一步得到的数据中的所有双引号替换为空字符串,得到 84
.trim()去除上一步得到的数据的两端的空格,得到84
按照这个方法将提取到的数据存入movieId,movieRank,userId中
3. 计算平均值
读取redis数据库中键为movie_rank,字段为movieId的值。
如果数据库中查不到,则将这条数据存入数据库中,格式为(电影平均分,评论次数)。
如果找到了,则读取电影平均分和评论次数设置为旧参数
计算公式:新的平均分=((旧平均分*旧评论次数)+ 新的评论分数)/(旧评论次数+1)
存入计算结果,(新电影平均分,旧评论次数+1)
// 对每行数据进行处理
kafkaStream.foreachRDD { rdd =>
rdd.foreach { record =>
//设置jedis客户端连接redis数据库
val jedis = new Jedis("192.168.181.128", 6379)
//创建data对象储存采集到的value值
val data = record.value()
//处理数据提取出movie_id,movie_rank,user_id的值
val movieId = data.split(",")(0).split(":")(1).replaceAll("\"", "").trim()
val movieRank = data.split(",")(1).split(":")(1).trim()
val userId = data.split(",")(2).split(":")(1).replaceAll("\"", "").replaceAll("}", "").trim()
// 读取redis中哈希表键为movie_rank,字段为movieId的值(读取对应电影ID的平均分)
val movieRankInfo = jedis.hget("movie_rank", movieId)
// 如果Redis中没有该电影的评分信息,则将该电影的评分信息存入Redis
if (movieRankInfo == null) {
jedis.hset("movie_rank", movieId, s"$movieRank,1")
} else {
// 如果Redis中已经有该电影的评分信息,则更新该电影的评分信息
val oldRank = movieRankInfo.split(",")(0).toDouble
val oldCount = movieRankInfo.split(",")(1).toInt
val newRank = (oldRank * oldCount + movieRank.toDouble) / (oldCount + 1)
jedis.hset("movie_rank", movieId, s"$newRank,${oldCount + 1}")
}
}
}
启动Spark Streaming
ssc.start()
ssc.awaitTermination()
完整代码
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import redis.clients.jedis.Jedis
object KafkaToRedis {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,名称为"KafkaToRedis",并将运行模式设置为本地模式
val sparkConf = new SparkConf().setAppName("KafkaToRedis").setMaster("local")
// 创建SparkContext对象
val sc = new SparkContext(sparkConf)
// 创建StreamingContext对象, 设置每个批次的时间间隔为1秒
val ssc = new StreamingContext(sc, Seconds(1))
// 定义了Kafka的相关参数,包括Kafka的地址、键和值的反序列化器、偏移量重置方式和消费者组ID
val kafkaParams = Map("bootstrap.servers" -> "192.168.181.128:9092",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"auto.offset.reset" -> "latest",//latest:最新偏移量,earliest:最早偏移量
"group.id" -> "test-consumer-group")
// 定义了要订阅的主题集合
val topics = Set("order")
// 创建了一个直接流,将Kafka的消息流转换为DStream
val kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))
// 对每行数据进行处理
kafkaStream.foreachRDD { rdd =>
rdd.foreach { record =>
val jedis = new Jedis("192.168.181.128", 6379)
val data = record.value()
val movieId = data.split(",")(0).split(":")(1).replaceAll("\"", "").trim()
val movieRank = data.split(",")(1).split(":")(1).trim()
val userId = data.split(",")(2).split(":")(1).replaceAll("\"", "").replaceAll("}", "").trim()
val movieRankInfo = jedis.hget("movie_rank", movieId)
// 如果Redis中没有该电影的评分信息,则将该电影的评分信息存入Redis
if (movieRankInfo == null) {
jedis.hset("movie_rank", movieId, s"$movieRank,1")
} else {
// 如果Redis中已经有该电影的评分信息,则更新该电影的评分信息
val oldRank = movieRankInfo.split(",")(0).toDouble
val oldCount = movieRankInfo.split(",")(1).toInt
val newRank = (oldRank * oldCount + movieRank.toDouble) / (oldCount + 1)
jedis.hset("movie_rank", movieId, s"$newRank,${oldCount + 1}")
}
}
}
ssc.start()
ssc.awaitTermination()
}
}
测试结果
代码运行结果
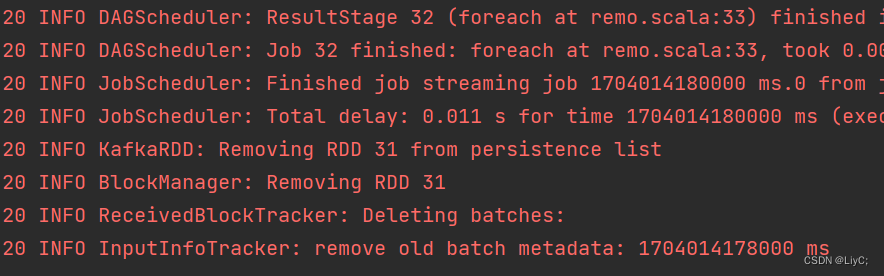
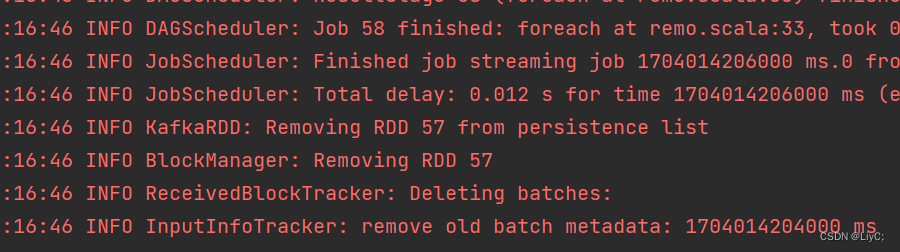
Scala程序正常运行,每秒都在抓取数据计算并写入Redis
Redis 查询结果
进入redis/bin目录,登录redis数据库
./redis-cli -h 192.168.181.128
选择0号数据库,查看该数据库中的键
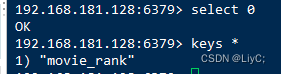
查看movie_rank哈希表的所有值
192.168.181.128:6379> hgetall movie_rank
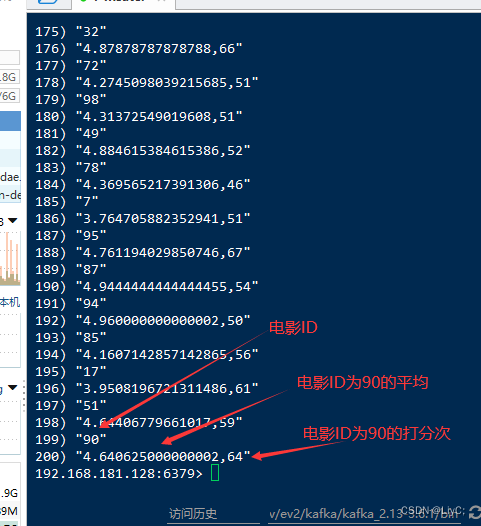
让Scala程序运行一段时间再次查询
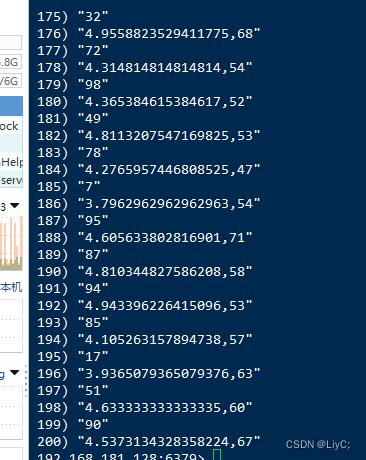
数据库的内容正在实时改变,说明程序正常运行
本文转载自: https://blog.csdn.net/qq_65960840/article/details/135316818
版权归原作者 LiyC; 所有, 如有侵权,请联系我们删除。
版权归原作者 LiyC; 所有, 如有侵权,请联系我们删除。